NVIDIA заявила о 15-кратном ускорении инференса LLM с DFlash на Blackwell
23.06.2026
NVIDIA опубликовала результаты тестов DFlash — открытой легковесной блок-диффузионной модели для спекулятивного декодирования LLM. По данным компании, на системе DGX B300 с GPU Blackwell и TensorRT-LLM DFlash дал более чем 15-кратный рост пропускной способности для gpt-oss-120b при том же уровне интерактивности по сравнению с обычным авторегрессионным декодированием.
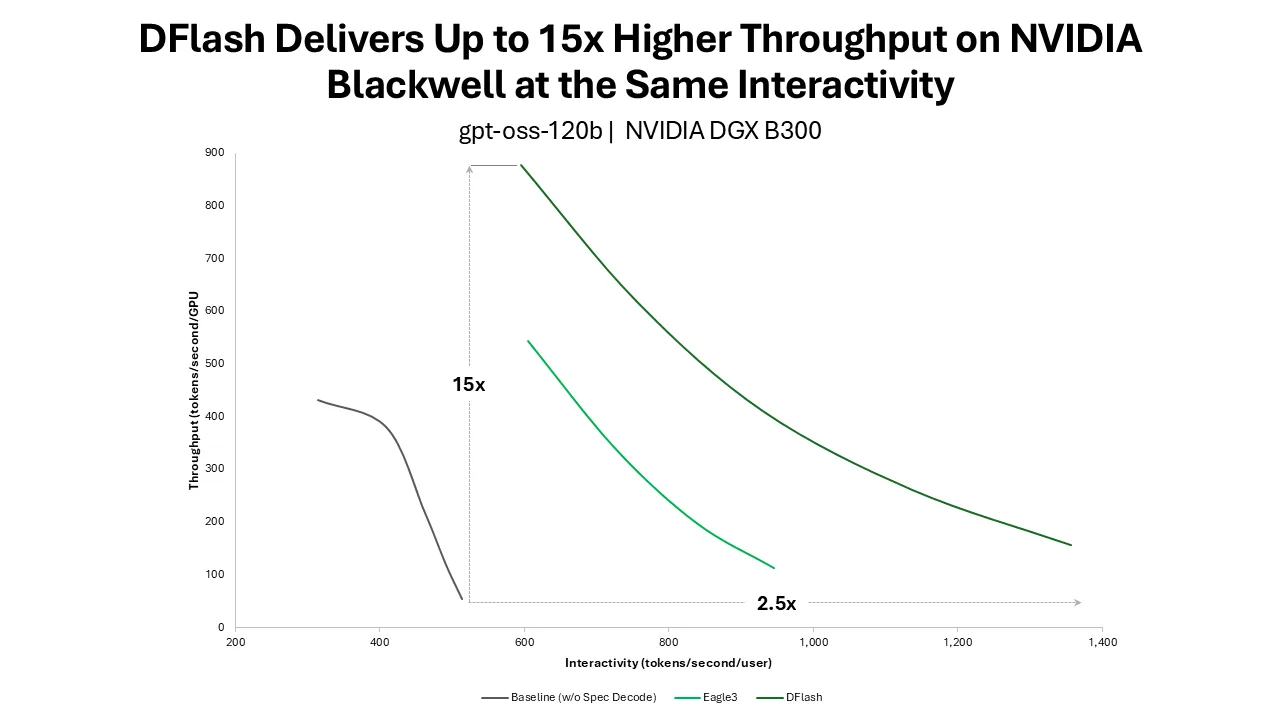
NVIDIA описала результаты применения DFlash для ускорения инференса больших языковых моделей на GPU Blackwell. DFlash использует спекулятивное декодирование: легковесная draft-модель заранее предлагает будущие токены, а целевая LLM проверяет их параллельно. В отличие от авторегрессивных draft-моделей, DFlash формирует кандидаты блоком, предсказывая несколько будущих токенов за один проход.
В тесте gpt-oss-120b на восьми GPU NVIDIA DGX B300 с TensorRT-LLM компания заявляет более чем 15-кратный рост пропускной способности при 500–600 токенах в секунду на пользователя по сравнению с авторегрессивным baseline. Относительно EAGLE-3, другого подхода к спекулятивному декодированию, NVIDIA указывает преимущество DFlash в 1,5 раза в той же зоне интерактивности.
Практически важная часть анонса — поддержка в распространенных стеках инференса. NVIDIA пишет, что DFlash доступен для SGLang, vLLM и TensorRT-LLM, а исследовательская команда выпустила 20 checkpoint-моделей на Hugging Face с рецептами для GPU Blackwell и Hopper. Это должно позволить командам, обслуживающим LLM, проверять оптимизацию в существующих пайплайнах без переработки прикладного кода.
Источник: developer.nvidia.com