AA-Briefcase показал слабость ИИ-агентов в долгих рабочих проектах
19.06.2026
Artificial Analysis представила AA-Briefcase — бенчмарк для оценки ИИ-агентов на длинных проектах с корпоративными документами, письмами, Slack-переписками и выгрузками данных. В опубликованных результатах даже лидер Claude Fable 5 полностью проходит критерии только в 3% задач, а стоимость выполнения одной задачи у разных моделей отличается более чем в 800 раз.
Artificial Analysis, компания, занимающаяся сравнительной оценкой ИИ-моделей, опубликовала AA-Briefcase — бенчмарк для проверки ИИ-агентов на длительных проектах интеллектуальной работы. В заданиях моделям приходится собирать требования и факты из разрозненных корпоративных источников: документов, писем, Slack-переписок, протоколов встреч и крупных выгрузок данных.
Официальная оценка строится на четырех закрытых сценариях и 91 задаче; данные рейтинга приведены на 18 июня 2026 года. Всего бенчмарк содержит почти 2000 исходных файлов, включая более 3500 писем и 25 000 сообщений Slack. Проверка сочетает бинарные критерии по рубрике с попарной оценкой аналитического качества и качества представления результата.
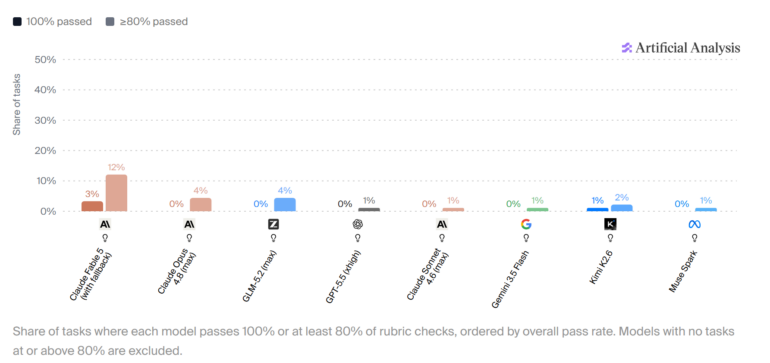
Лучший результат в опубликованном запуске показал Claude Fable 5 от Anthropic, но он прошел 100% рубричных критериев только в 3% задач. В 31 из 91 задачи ни одна модель не набрала больше 50% по рубрике.
Artificial Analysis также отмечает смену типов ошибок: менее сильные модели чаще не находят нужные входные файлы или сдают непригодные результаты, а более сильные выполняют очевидные требования, но пропускают детали, распределенные по нескольким источникам. Стоимость одной задачи различается более чем в 800 раз — примерно от $0,04 у DeepSeek V4 Flash (Max) до более $31 у Claude Fable 5; среди моделей с открытыми весами в статье выделен GLM-5.2 (max) как удачный компромисс между возможностями и ценой.
Источник: artificialanalysis.ai