Базы данных. Вводный курс
Сергей КузнецовЛекция 23. Объектные расширения
23.1. Введение
В последней лекции этого курса мы кратко изложим суть объектных расширений, которые включены в стандарт SQL:1999. Лекция основана не на официальном тексте стандарта (он очень формален и скучен), а на книге Джима Мелтона [4.2], которая, по сути, является неформальным описанием семантики (rationale) соответствующей части языка. В указанной книге объектным расширениям языка SQL посвящено более 200 страниц. Естественно, наше изложение будет гораздо более кратким.
Как отмечалось в лекциях 12 и 15, язык SQL появился в середине 1970-х гг. при выполнении экспериментального проекта реляционной СУБД System R. Проект выполнялся в компании IBM, и это вполне естественно, потому что именно сотрудник IBM Эдгар Кодд предложил миру идею реляционных баз данных. От System R исходит большинство традиционных средств стандарта SQL:1999 (и SQL:2003), которые мы обсуждали в восьми предыдущих лекциях. Однако в этой лекции речь пойдет о возможностях современных вариантов SQL, которые не имеют отношения к System R (за исключением некоторых экспериментов по представлению сложных объектов средствами SQL) и, вообще говоря, к реляционной модели данных, а именно — о так называемых объектно-реляционных расширениях языка. Чтобы у читателей не возникло впечатление, что объектные расширения появились в языке SQL внезапно, благодаря какому-то озарению разработчиков языка, мы начнем эту лекцию с небольшого (и крайне субъективного) очерка истории объектно-реляционного подхода к организации систем баз данных.
23.1.1. Истоки и краткая история объектно-реляционных баз данных
Пальму первенства в области объектно-реляционных систем управления базами данных (ОРСУБД) оспаривают два весьма известных специалиста в области технологии баз данных – Майкл Стоунбрейкер (Michael Stonebraker) и Вон Ким (Won Kim).
Первые ОРСУБД
Майкл Стоунбрейкер начал работать в области баз данных в начале 1970-х гг. прошлого века в университете Беркли. Его первым всемирно известным проектом была реляционная СУБД Ingres, которая существует и используется до сих пор в двух ипостасях – как свободно распространяемая система (университетская Ingres; код поддерживается в Беркли) и как коммерческая СУБД, принадлежащая компании Computer Associates. В исходном варианте СУБД Ingres отсутствовала поддержка языка SQL (поддерживался собственный язык запросов QUEL), но система уже обладала некоторыми уникальными чертами, которые, с небольшой натяжкой, можно было бы назвать объектными (например, в СУБД Ingres допускалось определение пользовательских процедур, выполняемых на стороне сервера). Кроме того, в проекте Ingres очень большое внимание уделялось управлению правилами.
В 1980-е гг. Майкл Стоунбрейкер возглавлял проект Postgres (вариант этой системы под названием PostgreSQL в настоящее время является весьма популярным свободно доступным продуктом). В Postgres были реализованы многие интересные средства: поддерживалась темпоральная модель хранения и доступа к данным, и в связи с этим был полностью пересмотрен механизм журнализации изменений, откатов транзакций и восстановления БД после сбоев; обеспечивался мощный механизм ограничений целостности; поддерживались ненормализованные отношения (работа в этом направлении началась еще в среде Ingres), хотя и довольно странным способом: в поле отношения мог храниться динамически выполняемый запрос к БД.
Одно свойство системы Postgres сближало ее со свойствами объектно-ориентированных СУБД (ООСУБД). В Postgres допускалось хранение в полях отношений данных абстрактных, определяемых пользователями типов. Это обеспечивало возможность внедрения поведенческого аспекта в БД, т. е. решало ту же задачу, что и ООСУБД, хотя, конечно, семантические возможности модели данных Postgres были существенно слабее, чем у объектно-ориентированных моделей данных. Основная разница состояла в том, что в Postgres не предполагалось наличие языка программирования, одинаково понимаемого как внешней системой программирования, так и системой управления базами данных. Как и в Ingres, в исходном варианте Postgres не поддерживался язык SQL (имелся собственный язык запросов Postquel). Кстати, во времена Postgres Майкл Стоунбрейкер не использовал термин объектно-реляционная система, предпочитая называть свою СУБД системой следующего поколения.
В начале 1990-х гг. Стоунбрейкер создал компанию Illustra, основной целью которой был выпуск коммерческого варианта СУБД Postgres, получившего название Illustra. В этой системе поддерживались основные идеи Postgres, но уже присутствовала и поддержка языка SQL. В конце 1995 г. компания Illustra была поглощена компанией Informix, и это привело к выпуску в 1996 г. СУБД Informix Universal Server (см. ниже).
Имя Вона Кима стало широко известно во второй половине 1970-х гг., когда он примкнул к участию в экспериментальном проекте компании IBM System R. Наиболее известная ранняя работа доктора Кима была посвящена преобразованию SQL-запросов с целью превращения запросов с вложенными подзапросами в запросы с соединениями.
В 1980-е гг. Вон Ким работал в компании MCC, где успешно выполнил реализацию серии прототипов ООСУБД Orion. В этих прототипах были опробованы многие идеи объектно-ориентированных СУБД. Одной из интересных особенностей проекта было то, что в качестве основного языка программирования использовался объектный вариант известного функционального языка Lisp.
В конце 80-х гг. д-р Ким основал компанию UniSQL, выпустившую в 1991 г. первую версию продукта UniSQL, который Вон Ким стал называть объектно-реляционной системой. Трудно оценивать коммерческий успех этой СУБД. В настоящее время она принадлежит Корейской национальной телекоммуникационной компании и, по всей видимости, продолжает использоваться. Поскольку UniSQL была первой СУБД, официально называемой объектно-реляционной системой, приведем ее краткое описание.
UniSQL обеспечивала возможность построения так называемых федеративных систем баз данных. При этом обеспечивалось единое представление данных, которые могли храниться либо в базе данных, непосредственно управляемой UniSQL, либо в какой-либо из реляционных баз данных, управляемой СУБД Oracle, Informix, Sybase и т. д., либо в какой-либо дореляционной базе данных. Сервер UniSQL обеспечивал интегрированный доступ к данным, управляемым разными СУБД. Одна из возможных конфигураций использования системы показана на рис. 23.1.
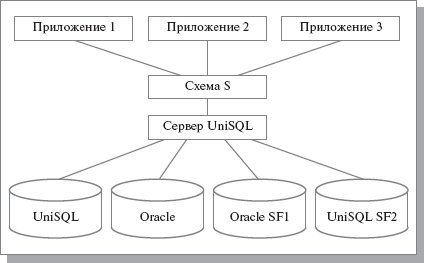
Рис. 23.1. Возможная конфигурация системы UniSQL
Как показывает рис. 23.1, сервер UniSQL позволяет представлениям работать через «глобальную» схему базы данных S, полученную из двух «фрагментарных» схем баз данных, которые управляются непосредственно UniSQL и СУБД Oracle190).
Разработчики UniSQL полагали, что построение полнофункциональной СУБД, основанной на принципиально новой модели данных, крайне проблематично. Был выбран подход к расширению реляционной модели, выражающийся в следующих четырех принципах:
- значениями атрибутов отношений могут быть не только литеральные значения, но и объекты;
- значения атрибутов отношений не обязательно являются атомарными;
- при построении таблиц (классов) может использоваться механизм наследования;
- классы включают операции.
В созданной компанией системе поддерживалось расширение стандарта SQL – SQL/X, одновременно включающее и объектно-ориентированные, и реляционные возможности. В одном языке поддерживались возможности и определения данных, и манипулирования ими. В качестве языковых средств программирования приложений поддерживались языки C++ и Smalltalk.
Внедрение объектных расширений в основные РСУБД
В конце 1989 г. группа известных специалистов в области языков программирования баз данных опубликовала документ под названием Манифест систем объектно-ориентированных баз данных [2.6] (для краткости будем называть его Первым манифестом). Основным поводом к написанию и публикации этого материала было то, что к тому времени существовал ряд систем управления базами данных, которые, по большому счету, объединяла только общая привязанность к объектно-ориентированным языкам программирования. В Первом манифесте была предпринята попытка дать определение системам объектно-ориентированных баз данных. Авторы стремились привести описание основных свойств и характеристик, которыми должна обладать система, претендующая на то, чтобы называться системой объектно-ориентированных баз данных. Первый манифест был написан академическими исследователями; почти все они являлись и являются профессорами различных университетов. Конечно, это нашло свое отражение в стиле Первого манифеста – очень мягком и умеренно рекомендательном (хотя по своему духу предложения этого манифеста были весьма радикальными).
Через год после публикации Первого манифеста вышел в свет Манифест систем баз данных третьего поколения [2.7], инициатором которого, очевидно, был Майкл Стоунбрейкер (хотя у документа формально имелось много авторов). Мы говорим об этом с уверенностью, поскольку в этом манифесте повсюду видны идеи Стоунбрейкера, использованные им в проектах Ingres и Postgres.
В некотором роде Манифест систем баз данных следующего поколения (для краткости мы будем называть его Вторым манифестом) стал ответом миру объектно-ориентированных баз данных со стороны мира SQL-ориентированных баз данных. Если Первый манифест был хотя и немного путанным, но все-таки носил научный характер, то Второй манифест является в большей степени инженерно-публицистическим документом. Второй манифест можно расценивать как реакцию индустрии СУБД на неприятные для нее измышления науки.
Второй манифест (или, вернее, работы, приведшие к его появлению) имел важные последствия. В 1995 г. компания Informix (ныне входящая в состав IBM) купила компанию Майкла Стоунбрейкера Illustra191), и Стоунбрейкер стал техническим директором Informix. В начале 1996 г. компания Informix объявила о выпуске принципиально нового продукта Informix Universal Server, в котором, как утверждалось, лучшие черты Informix Online Server сочетались с развитыми объектными чертами, присущими Illustra.
К выпуску Informix Universal Server очень ревниво отнеслась компания Oracle, которая немедленно заявила, что у нее готов собственный объектно-реляционный продукт, по всем параметрам превосходящий систему компании Informix. Эта система, получившая название Oracle8, была выпущена в конце лета 1996 г.
Годом позже к группе производителей объектно-реляционных СУБД (ОРСУБД) примкнула компания IBM, выпустившая продукт DB2 Universal Database. Как выяснилось позже, все наиболее важные свойства этого продукта были реализованы еще в 1995 г. в СУБД DB2 for Common Servers. Просто компания IBM предпочла до поры не афишировать свои расширения.
Первые пару лет вокруг объектно-реляционных СУБД стоял большой шум. Позже выяснилось, что маркетинговые ожидания компаний гигантов оказались преувеличенными. (В частности, это было одной из основных причин падения компании Informix.) Сегодня объектные расширения SQL-ориентированных СУБД предлагаются пользователям лишь в качестве дополнительных, хотя и важных возможностей.
Объектные расширения языка SQL были зафиксированы в стандарте SQL:1999 [3.9]. В той или иной мере эти расширения поддерживаются во всех трех перечисленных выше продуктах. В настоящее время ближе всех к стандарту находятся PostgreSQL, СУБД компании Oracle и DB2 компании IBM.
23.1.2. Объектная модель SQL
Объектные расширения SQL:1999 базируются на некоторой объектной модели, хотя эта модель в явном виде в стандарте не специфицируется. Объектная модель SQL192) не является тождественной объектным моделям какого-либо объектно-ориентированного языка программирования или какой-либо объектно-ориентрованной системы баз данных. Однако при определении объектной модели SQL участники процесса стандартизации тщательно проанализировали ряд других языков и систем с целью выяснения достоинств и недостатков их объектных моделей. По мнению авторов стандарта SQL:1999, выработанная ими объектная модель похожа на объектную модель языка Java193), но при этом адаптирована к природе языка SQL как языка СУБД с наличием стабильно хранимых метаданных и данных.
Объектная модель SQL:1999 включает два основных отличительных компонента – структурные, определяемые пользователями типы данных (User Defined Type – UDT) и типизированные таблицы (Typed Table). Первый компонент позволяет определять новые типы данных, которые могут быть гораздо более сложными, чем встроенные типы данных языка SQL. При определении структурного UDT требуется специфицировать не только содержащиеся в нем элементы данных, но и семантику типа данных, т. е. его поведение на основе интерфейса вызовов методов. Второй компонент – типизированные таблицы – позволяет определять таблицы, строки которых являются экземплярами (или значениями) UDT, с которым явно ассоциируется таблица. Во многих отношениях строка типизированной таблицы похожа на объект класса в объектно-ориентированной системе.
В стандарте SQL:1999 определены два пакета объектных свойств – минимальный (PKG006) и полный (PKG007), которым должны удовлетворять SQL-ориентированные ОРСУБД, претендующие на соответствие стандарту. Ниже будут перечислены свойства, включенные в каждый из пакетов, но смысл этих свойств будет понятен только после прочтения остальных разделов.
Пакет PKG006 включает всего пять свойств:
- свойство S023 («Basic structured types») – возможность определять UDT и их методы с ограниченными возможностями;
- свойство S041 («Basic reference types») – возможность определять и использовать ссылки на экземпляры UDT, входящие в типизированные таблицы;
- свойство S051 («Create table of type») – возможность создания типизированных таблиц;
- свойство S151 («Type predicate») – возможность определения точного типа (в иерархии типов) экземпляра UDT;
- свойство Т041 («Basic LOB data type support») – возможность определения LOB-типов в смысле SQL (с необязательной поддержкой операций, кроме операций сохранения и полной выборки).
Пакет PKG007 содержит девять дополнительных свойств:
- свойство S024 («Enhanced structured types») добавляет к свойству S023 ряд развитых возможностей, в число которых входят возможности кодирования методов на языках, отличных от SQL, сравнения экземпляров UDT и передача экземпляров UDT в качестве параметров различных процедур;
- свойство S043 («Enhanced reference types») расширяет свойство S041 возможностями определения ссылок с областью действия, автоматической проверки законности ссылок и т. д.;
- свойство S071 («SQL-paths in function and type name resolution») позволяет использовать путевые выражения SQL (SQL-path) в алгоритме разрешения типа;
- свойство S081 («Subtables») расширяет возможности свойства S051, допуская организацию иерархии таблиц, аналогичной иерархии типов соответствующих UDT;
- свойство S111 («ONLY in query expressions») обеспечивает возможность выборки только экземпляров указанного типа, без экземпляров любого из его подтипов;
- свойство S161 («Subtype treatment») позволяет информировать среду SQL о том, что некоторый экземпляр UDT в действительности является экземпляром указанного подтипа;
- свойство S211 («User-defined cast functions») разрешает определять подпрограммы, преобразующие экземпляры UDT к другим типам;
- свойство S231 («Structured type locators») способствует доступу к экземплярам UDT из прикладных программ;
- свойство S023 («Transform functions») позволяет определять подпрограммы, преобразующие значения UDT в значения предопределенных типов данных, и наоборот.
23.1.3. Цели лекции
Следует заметить, что в этой, безусловно, перегруженной материалом лекции мы преследуем две основные цели. Первая цель состоит в том, чтобы показать читателям, что в средствах определения структурных типов SQL используются, по сути, все базовые возможности определения объектов базы данных и выборки данных, которые обсуждались в предыдущих лекциях. Более того, определенные пользователями типы в SQL являются объектами первого класса; UDT можно использовать в любой конструкции языка, в которой допускается применение предопределенного или конструируемого типа данных. Очень важно отдавать себе отчет в том, что наличие возможности определять пользовательские типы не делает язык SQL менее реляционным или более объектным. Эта возможность «всего лишь» фантастически повышает выразительную мощность языка.
Второй целью является демонстрация того, как на основе базовых механизмов языка удалось ввести дополнительные конструкции, которые действительно вплотную приближают SQL к объектному миру. Здесь, конечно, основную роль играет связка UDT и механизма типизированных таблиц, которые играют в SQL своеобразную совмещенную роль классов и коллекций объектов.
Может оказаться, что материал этой лекции покажется сложным, поскольку для его усвоения не помешало бы иметь предварительную подготовку в области полнотиповых языков программирования, объектно-ориентированных языков и систем баз данных и т. д. Хочется надеяться, что возникновение трудностей при изучении лекции не отпугнет читателей от этой темы, а напротив, послужит стимулом к изучению дополнительной литературы.
Возможна и другая опасная ситуация. Краткость и некоторая формальность изложения может создать ложное впечатление тривиальности объектных расширений SQL. В этом случае могу посоветовать перечитать предыдущие лекции курса, относящиеся к SQL, считая, что везде, где используются предопределенные или конструируемые типы, применяются некоторые UDT, а в тех случаях, где имеются таблицы, связываемые естественным соединением, используются типизированные таблицы. Думаю, это позволит оценить мощь новых возможностей SQL.
Введя этот необходимый контекст, перейдем к описанию соответствующих механизмов SQL:1999.
190 Вопросы интеграции данных выходят за пределы тематики этого курса. Однако следует сделать два замечания. Во-первых, проблематика обеспечения доступа к разнородным данным через некоторую глобальную, или концептуальную схему интересует сообщество баз данных в течение нескольких десятков лет. Существовали многочисленные попытки обеспечить интеграцию баз данных, представленных во всех возможных моделях (сетевой, иерархической, реляционной, объектно-ориентированной). С точки зрения теории решение проблемы возможно, но на практике это приводит к очень сложным с технической точки зрения реализациям, обладающим крайне низкой производительностью. Во-вторых, в MCC в 1980-е годы был создан весьма успешный прототип системы, интегрирующей SQL-ориентированные базы данных. Должно быть понятно, что такая интеграция существенно проще в техническом смысле, поскольку глобальная и фрагментарные схемы представлены в близких понятиях. Похоже, что проект UniSQL в большой степени базировался и на этой работе.
191 Компания Illustra была создана Стоунбрейкером для коммерциализации разработанной под его руководством свободно доступной СУБД Postgres.
192 Конечно, это не модель данных в смысле Кодда.
193 Далеко не факт, что ориентация на язык Java была правильным решением. По мнению автора данного курса, причиной являются отнюдь не уникальные достоинства языка Java (обсуждение этого языка не является задачей автора), а то, что во время разработки стандарта SQL:1999 язык Java был особенно моден. Помимо прочего, заметим, что для языка Java (насколько известно автору) никогда не определялась формальная объектная модель.