AISI: фиксированные лимиты вычислений занижают возможности ИИ-агентов на бенчмарках
04.07.2026
Британский AI Security Institute показал, что стандартные оценки ИИ-агентов с фиксированным лимитом вычислений могут систематически недооценивать их возможности. При увеличении бюджета токенов производительность на задачах программной инженерии выросла примерно на 25%, а новые модели выигрывают от дополнительного бюджета сильнее старых.
Британский AI Security Institute (AISI), исследовательская организация при Министерстве науки, инноваций и технологий Великобритании, опубликовал работу о том, как вычислительный бюджет на этапе вывода влияет на оценки ИИ-агентов. В исследовании, также доступном как техническая статья, до 12 передовых языковых моделей проверялись на семи сложных бенчмарках в областях кибербезопасности, разработки ПО, математики, академических задач и медицины.
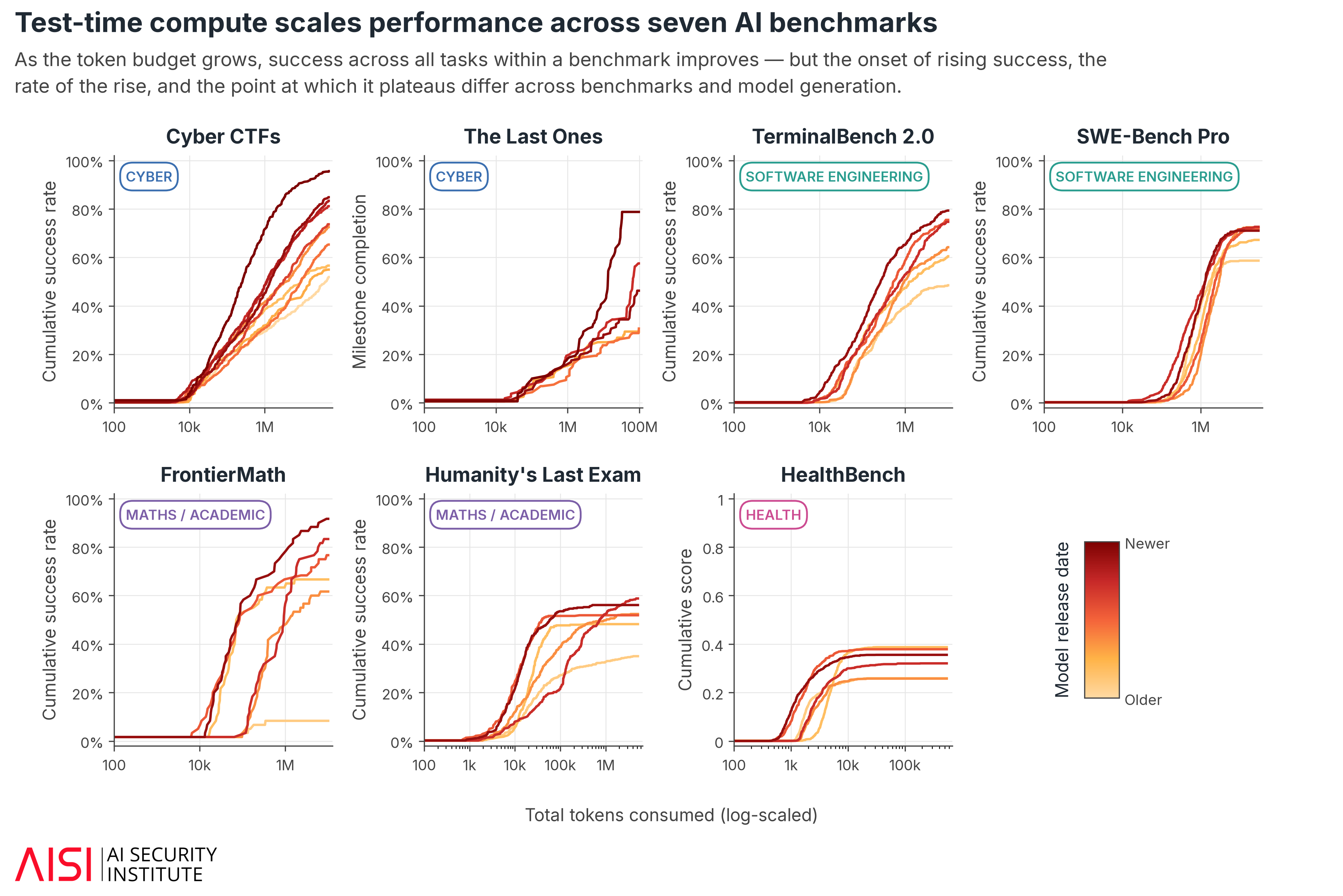
Главный вывод AISI: способность агента нельзя корректно описывать одним числом. Если бенчмарк ограничивает число токенов, попыток или длительность выполнения, он может остановить модель до того, как ее результативность вышла на плато; в таком случае оценка становится нижней границей возможностей, а не их пределом.
При увеличении бюджета с 1 млн до 10 млн токенов результаты на задачах программной инженерии TerminalBench 2.0 и SWE-Bench Pro выросли примерно на 25%. На математических и академических заданиях Humanity’s Last Exam прирост составил около 22% при бюджете до 5 млн токенов. В узких CTF-задачах по кибербезопасности около 8% заданий были решены только после повышения бюджета выше 10 млн токенов, а некоторым потребовалось до 50 млн токенов.
Эффект оказался неравномерным. AISI отмечает, что дополнительный бюджет особенно помогает там, где агент может проверять собственную работу и исправлять ошибки, например при запуске кода или тестировании эксплойта. В медицинском бенчмарке HealthBench модели выходили на плато уже в рамках обычного бюджета.
Новые модели, по данным AISI, сильнее выигрывают от дополнительного вычислительного бюджета: они решают более сложные задачи, чаще доводят уже доступные задачи до успеха и иногда требуют меньше токенов на те же задания. В оценке кибервозможностей переход от 2,5 млн к 50 млн токенов на задачу сделал измеренный темп прогресса примерно на 60% круче; для текущего фронтира оценочный горизонт вырос примерно с 2 до 14 часов человеческой работы.
AISI предлагает оценивать ИИ-агентов не только фиксированным score, а кривой зависимости результата от вычислительного бюджета и явно описывать протокол тестирования. Это важно для сравнений моделей, решений о внедрении и оценок риска: слишком жесткий лимит может показывать не слабость модели, а недостаточный бюджет теста.
Источник: aisi.gov.uk