Переосмысление стоимости и производительности систем баз данных
Даниела Флореску, Дональд Коссман
Перевод: Сергей Кузнецов
Оригинал: Daniela Florescu, Donald Kossmann. Rethinking Cost and Performance of Database Systems. SIGMOD Record, Vol. 38, No. 1, March 2009
От переводчика, или XQuery и эластичность Web-приложений баз данных
Хотя "облачные" вычисления (cloud computing) постепенно входят в практику все большего числа разработчиков приложений, остается открытым вопрос, какими должны быть средства управления данными "в облаках"? Некоторые люди полагаются на использование распределенных файловых систем и подхода map/reduce, другие говорят о целесообразности использования массивно-параллельных систем баз данных (см., например, статью Майкла Стоунбрейкера и др. "Сравнение подходов к крупномасштабному анализу данных"), третьи пытаются приспособить к облачной инфраструктуре традиционные SQL-ориентированные СУБД (например, SQL Azur от Microsoft).Даниела Флореску и Дональд Коссман предлагают начать с критериев, на которые должна опираться архитектура "облачных" систем управления данными. И в качестве основного такого критерия они выставляют минимизацию расходов при заданных требованиях к производительности приложений баз данных. Для сервис-ориентированной архитектуры, на которую опирается cloud computing в целом, это очень естественно.
На мой взгляд, статья написана очень последовательно и логично. Единственное, что меня несколько смущает, – это сходство предлагаемой архитектуры приложений баз данных с архитектурами файл-серверных СУБД. Фактически, в подходе Флореску и Коссмана Amazon S3 выполняет роль файл-сервера, а вынесение службы запросов и других функций СУБД на уровень приложения до боли напоминает организацию, например, Informix SE.
И, конечно, некоторые сомнения вызывает передача по Internet от узлов Amazon S3 в узлы серверов приложений, как минимум, XML-документов целиком (а может быть, и коллекций XML-документов). Непонятно, как при этом удается гарантировать, что время ответа на запрос не превышает заданные ограничения (если, конечно, не считать, что пользователи могут спокойно подождать и несколько минут).
Кроме того, я не уверен, что разработчики приложений придут в полный восторг от необходимости использования XQuery не только для запросов XML-данных, но и для написания логики приложений. Для системы это, конечно, очень удобно, а на месте разработчиков я бы, пожалуй, предпочел использовать для программирования что-нибудь более привычное.
Хотя, конечно, здесь нужно учитывать, что Флореску и Коссман входят в число родоначальников XQuery, и с их точки зрения, по-видимому, программирование приложений на XQuery является вполне естественным и удобным. Кстати, по этому поводу полезно почитать статью Мартина Кауфмана (Martin Kaufmann) и Дональда Коссмана "Developing an Enterprise Web Application in XQuery".
А может быть, я напрасно сомневаюсь, этот возврат к архитектурному прошлому закономерен, очень большие XML-документы в Web-приложениях не встречаются, а разработчики Web-приложений с энтузиазмом перейдут от программирования на PHP и Python к программированию на XQuery. Авторы достаточно убедительно демонстрируют, что их "новая" архитектура (а любое "новое", как известно, – это хорошо забытое "старое") обеспечивает неограниченное масштабирование приложений, гибкость системы и предсказуемость ее поведения. В конце концов, в старые и добрые времена файл-серверных СУБД не было облачных вычислений, не было Web-приложений, и требования к системам баз данных были другими. И жизнеспособность идей Флореску и Коссмана подтверждается разработкой в компании 28msec (одним из основателей которой является Коссман; имеет ли к ней формальное отношение Флореску, мне неизвестно) "облачной" среды Web-приложений баз данных Sausalito, технические аспекты которой более подробно описаны в статье [3].
В любом случае, статья Флореску и Коссмана является явным шагом вперед на пути к созданию нового поколения систем управления данными, пригодных для использования в облачной инфраструктуре. Хорошо, что новые идеи исходят не только от Стоунбрейкера и Co.
Аннотация
Традиционно системы баз данных оптимизировались следующим образом: "При заданном наборе машин следует постараться минимизировать время ответа на каждый запрос". В этой статье утверждается, что сегодня пользователи хотели бы, чтобы в системах баз данных требование к оптимизации формулировалось бы противоположным образом: "При заданных ограничениях на время ответа на каждый запрос следует постараться минимизировать число машин (т.е. денежные расходы)". Кроме того, в статье приводится пример, демонстрирующий, что новая проблема оптимизации может привести к полностью иной архитектуре системы.1. Введение
Если вы выполняете исследование в области баз данных, вы всегда что-нибудь оптимизируете. При исследовании здорово определить свое собственное "что-нибудь", т.е. ввести ограничения и метрику своей оптимизационной проблемы. Однако, честно говоря, в сообществе баз данных, как правило, обеспечивается ответ на один и тот же вопрос: "Как сделать СУБД быстрее?", и на это же направлена вся оптимизация. Допускаются только те "сценарии" исследований, которые направлены на то, чтобы сделать СУБД быстрее. Возможные сценарии включали новые виды запросов (например, аналитику), новые типы данных (например, изображения, многоугольники, XML) и новые архитектуры (например, потоковые данные). Тем не менее, оси y на графиках в статьях с конференций SIGMOD и VLDB одни и те же, показывающие время ответа в секундах или пропускную способность в числе транзакций в секунду. Кроме того, фиксируются такие ограничения, как строгая согласованность (т.е. ACID-транзакции) и доступные аппаратные ресурсы.Целью статьи является переосмысление понятия лучше в контексте систем баз данных, т.е. в ней делается попытка определить, как должны выглядеть оси y на графиках в статьях будущих конференций SIGMOD и VLDB. Утверждается, что в будущем единицы измерения оси y должны измениться. Вместо времени ответа или пропускной способности оси y должны показывать расходы в денежных единицах. Кроме того, согласованность должна быть параметром, изменяемым при проведении экспериментов с системой. Другими словами, цель статьи состоит в переопределении проблемы оптимизации баз данных: определении новых ограничений и других показателей оптимизации.
Эта статья мотивируется несколькими тенденциями. Очевидно, что наиболее важной тенденцией является изменение требований многих приложений. Для многих приложений в Web строгая согласованность в соответствии с парадигмой ACID просто не требуется. Вместо этого таким приложениям требуется масштабируемость до миллионов пользователей, и ни один пользователь не должен когда-либо блокироваться каким-либо другим пользователем. Кроме того, для этих приложений требуется, чтобы все пользователи получали ответы на свои запросы в пределах секунды. В Internet нет пакетной обработки, и пользователи Web не понимают, почему для обработки сложного запроса может потребоваться больше времени, чем для обработки простого запроса. Другой тенденцией является возрастающая сложность программных систем и распределенная, сервис-ориентированная архитектура большей их части. Кроме того, имеются технологические тенденции, такие как "облачные" вычисления (cloud computing) и крупные центры данных с дешевыми аппаратными средствами, которые вынуждают изменять представления о современных архитектурах программного обеспечения. Первый вклад этой статьи состоит в детализации того, как эти тенденции изменяют проблему оптимизации баз данных.
Вторым вкладом статьи является обсуждение того, как эта новая проблема оптимизации баз данных могла бы повлиять на архитектуру современной системы баз данных и, возможно, изменить некоторые фиксированные параметры традиционных исследований в области баз данных. В качестве отправной точки описывается архитектура сервера приложений 28msec, в котором интегрируется система баз данных, Web-сервер и виртуальная машина, и который сам работает на платформе Amazon Web Services (AWS).
Основная часть статьи структурирована следующим образом. В разд. 2 перечисляются новые требования к современным системам баз данных. В разд. 3 представлена архитектура сервера приложений 28msec как примера системы, отвечающей этим новым требованиям. В разд. 4 обсуждаются родственные работы. В разд. 5 содержатся заключительные замечания.
2. Что заботит пользователей?
По существу, требования пользователей не изменяются: они хотят всего сразу. И определение этого "всего" тоже не слишком изменяется: они хотят нулевых расходов, мгновенных ответов, бесконечной пропускной способности, бесконечной масштабируемости по отношению к числу поддерживаемых пользователей, линейной масштабируемости при добавлении машин, стопроцентной предсказуемости затрат и производительности, транзакций в стиле ACID, 100-процентной пригодности для чтения и написания запросов и возможности настройки системы к индивидуальным потребностям в любой момент времени с минимальными усилиями. В условиях, когда пользователи не могут иметь все сразу, изменяются приоритеты и ограничения. Коротко говоря, традиционную проблему оптимизации баз данных можно определить следующим образом:При заданном наборе аппаратных ресурсов и гарантировании полной согласованности данных (т.е. при поддержке ACID-транзакций) требуется минимизировать время ответа за запросы и максимизировать пропускную способность системы по отношению к поступающим запросам.
Новую проблему оптимизиции баз данных можно определить следующим образом:
При заданных требованиях к производительности приложений (пиковая пропускная способность, предельно допустимое время ответа) требуется минимизировать требуемые аппаратные ресурсы и максимизировать согласованность данных.
Эти две проблемы не конфликтуют, и, очевидно, в новом мире применимы многие методы оптимизации традиционных систем баз данных. Однако, как показано в разд. 3 и 4, имеющиеся тонкие различия могут существенно повлиять на архитектуру системы. В табл.1 приведена сводка этих различий в формулировке проблемы. Эти различия немного более подробно описываются далее в этом разделе.
| Характеристика | Традиционные базы данных | Новые базы данных |
| Затраты [$] | фиксированные | минимизируются |
| Производительность [секунды, число транзаций в секунду] | оптимизируется | фиксированная |
| Масштабируемость [число машин] | максимизируется | фиксированная |
| Предсказуемость [$ и секунды] | - | фиксированная |
| Согласованность [%] | фиксированная | максимизируется |
| Гибкость [число вариантов] | - | максимизируется |
Таблица 1. Сопоставление традиционной и новой проблем оптимизации
Затраты. Повторим: в этой статье утверждается, что именно денежная оценка затрат является основным показателем, нуждающимся в оптимизации. Теперь уже не столь важно, насколько быстро может выполниться рабочая нагрузка базы данных, или можно ли достичь заданной пропускной способности; основной вопрос состоит в том, сколько требуется машин, чтобы удовлетворить требования к производительности на заданной рабочей нагрузке. Это наблюдение в значительной степени основывается на развитии облачных вычислений, возрастающих расходов на электропитание и охлаждение и популярности таких служб, как Amazon Web Services (AWS). Кроме того, аппаратные ресурсы – это теперь не одноразовая инвестиция; это отдельная существенная статья ежемесячных расходов IT. При этом облачные вычисления и AWS делают показатель этих расходов непрерывным (а не дискретным): чем больше аппартных ресурсов вы потребляете, тем больше платите, и расходы оцениваются мелкоструктурным способом, по мере потребления циклов центрального процессора и байтов памяти. При использовании AWS расходы измеряются в миллидолларах. Традиционно аппаратные ресурсы обеспечивались с детализацией уровня машины; в результате дополнительные расходы измерялись в килодолларах.
Потребность во включении стоимости в показатели производительности давно уже частично учитывается в эталонных тестовых наборах TPC [1]. Этот подход также применялся в проекте Mariposa [12]. К сожалению, этот показатель все еще игноируется в большинстве сегоднящних исследований в области баз данных, и даже в эталонных тестовых наборах TPC стоимость и производительность смешивается в показателе числа транзакций в секунду на один доллар. В данной статье приводятся доводы в пользу более бескомпромиссного подхода, при котором стоимость является единственным показателем для большинства экспериментов. При этом наличие сервисов облачных вычислений, подобных AWS, делает этот показатель адекватным. Любой человек может произвести эксперименты с различными алгоритмами в среде AWS и отчитаться о затратах в "долларах Amazon". В отчетах о проведении испытаний на тестах TPC денежные показатели часто бывают сомнительными и противоречивыми.
Производительность (время ответа и пропускная способность). На большинстве предприятий производительность является заданным ограничением, а не целью оптимизации. Например, поисковая система Google и так достаточно быстра, сокращение времени ее ответов ничему бы не помогло. Имеется лишь немного приложений, для которых "быстрее" означает "лучше" без каких-либо ограничений. Одним из таких редких примеров является алгоритмический трейдинг (algorithmic trading) в финансовом секторе. Во всех интерактивных приложениях (например, Web-приложениях) времени ответа в несколько сотен миллисекунд вполне достаточно, чтобы пользователи были счастливы. Что касается пропускной способности, то требованием является поддержка заданной пиковой рабочей нагрузки. И опять, в большинстве IT-сценариев больше не стоит вопрос о том, имеется ли возможность поддерживать данную нагрузку: возможно (почти) все. И в этом случае основным вопросом является то, во что это обойдется; "чем дешевле, тем лучше".
Еще одним доводом в пользу того, чтобы уделять меньшее внимание производительности СУБД, является то, что на практике многие проблемы производительности возникают вовсе не из-за СУБД. Современные IT-системы очень сложны, и СУБД является всего лишь одним из их компонентов. И повышение производитеьности СУБД может ничему не помочь.
Масштабируемость. В настоящее время принято считать (и на этом допущении основывается обсуждение стоимости и производительности в предыдущих двух параграфах), что любую IT-проблему можно решить путем применения достаточно мощных аппаратных ресурсов (т.е. путем соответствующих денежных затрат). Поэтому неограниченная масштабируемость является насущной потребностью любой современной IT-системы. В конце концов, любому бизнесу свойственно стремление к росту, даже если вначале он очень небольшой. Масштабируемость означает, что расходы на IT возрастают линейно по мере роста бизнеса, и что этот рост ничем не ограничивается. К сожалению, это требование не удовлетворяется многими традиционными системами баз данных, для которых функция стоимости является ступенчатой, и масштабируемость – ограничена.
Предсказуемость. Для многих предприятий предсказуемость настолько же обязательна, что и масштабируемость. Другими словами, оптимизация 99% операций более важна, чем оптимизация в среднем. Здесь имеется в виду предсказуемость как производительности, так и стоимости. Большинство поставщиков СУБД прилагает огромные усилия для сокращения расходов на администрирование и достижения более устойчивой производительности своих систем; тем не менее, администрирование баз данных и обеспечение аппаратных ресурсов для крупномасштабных приложений баз данных по-прежнему является своего рода "черной магией".
Согласованность. ACID – это замечательно! Но SOA – лучше!
При использовании ACID разработчикам не нужно заботиться о согласованности данных, и они могут сфокусироваться на логике приложений. SOA (service-oriented architecture – сервис-ориентированная архитектура) помогает разработчикам структурировать и, что более важно, развивать свои приложения.
К сожалению, ACID и SOA – что вода и масло: они плохо перемешиваются. При применении подхода ACID требуется полный контроль надо всеми активностями управления данными, производимыми в данной транзакции, а SOA диктует автономию всех сервисов, участвующих в транзакции.
Хотя стандарты, такие как XA, помогают поддерживать распределенные транзакции в стиле ACID в сервис-ориентированной инфраструктуре, поддержка ACID-транзакций в крупномасштабных распределенных системах по-прежнему затруднена. К счастью, как отмечалось в недавнем докладе В. Вогелса (W. Vogels) [16] и в статье П. Хелланда (P. Helland) [8], ACID-транзакции и строгая согласованность требуются нечасто. Даже в критически важных приложениях часто достаточен более низкий уровень согласованности. В [3] утверждается, что уровень согласованности должен быть гибким, и что должен существовать компромисс между объемом расходов и согласованностью данных. Кроме того, в [16] и [3] приводятся доводы в пользу применения при разработке крупномасштабных распределенных систем определения уровней согласованности в духе предложений [15], а не определений, содержащихся в стандарте языка SQL и реализуемых в коммерческих системах баз данных текущего поколения. Опять же, эта точка зрения диктуется важностью SOA как принципа разработки.
Требование стопроцентной доступности данных по чтению и записи для всех пользователей также отодвигает на задний план важность парадигмы ACID как золотого стандарта согласованности данных. В крупных Web-приложениях (например, Amazon, eBay, expedia и т.д.) не допускается блокировка ни одного пользователя; в частности, ни один пользователь не может быть блокирован из-за действий какого-либо другого пользователя. И это требование также более приоритетно, чем достижение строгой согласованности. В результате оказывается лучше разрабатывать систему, которая умеет обращаться с несогласованными данными и помогает устранять их несогласованность, чем систему, которая предотвращает несогласованность в любых ситуациях. Неприятности случаются и при использовании ACID, и игнорирование этих соображений ограничивает возможности системы. В результате в современных IT-системах согласованность данных является целью оптимизации, а не ограничением, как в традиционных системах баз данных.
Гибкость. Гибкость – это возможность настройки программной системы к индивидуальным требованиям пользователя. Гибкость также облегчает, ускоряет и удешевляет выпуск новых версий системы. Таким образом, гибкость системы измеряется числом ее внедренных вариантов. Гибкость особенно важна для приложений с разнотипным контингентом пользователей; типичными примерами являются корпоративные приложения, такие как SAP R/3 и Oracle Finance. По мере усложения приложений гибкость как цель разработки становится все более важной. На важность этого требования, в частности, указывает успех технологии AppExchange компании Salesforce. В традиционных системах OLTP, таких как системы поддержки кредитных и дебетовых транзакций 1970-х, это требование отсутствовало, так что гибкость не являлась настоятельной целью оптимизации в традиционных системах управления данными. Очевидно, что гораздо проще обеспечить должные производительность и масштабируемость, если система не обладает гибкостью.
3. К чему это ведет?
В этом разделе пересматривается классическая архитектура систем баз данных, которая была разработана для оптимизации традиционной проблемы баз данных (табл. 1). Кроме того, описывается новая архитектура систем баз данных, разработанная для оптимизации новой проблемы баз данных.3.1 Пересмотр традиционных систем баз данных
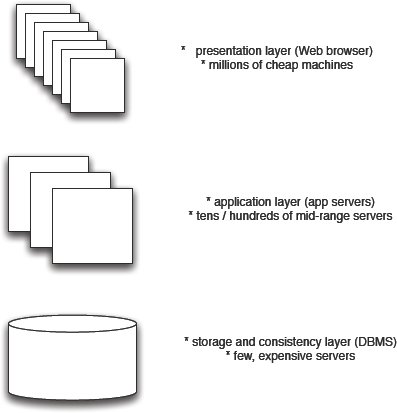
Рис. 1. Классическая архитектура системы баз данных
На рис. 1 показана классическая трехзвенная архитектура построения приложений баз данных. Эта архитектура была впервые применена компанией SAP, и ее варианты по-прежнему широко используются для создания приложений баз данных. Все запросы инициируются пользователями на уровне представления, например, с использованием Web-браузера. Логика приложения программируется на среднем уровне; на среднем же уровне поддерживаются такие функциональные средства, как Web-сервер. Все управление данными производится на низшем уровне с использованием СУБД (например, IBM DB2, Microsoft SQL Server, MySQL, Oracle и т.д.).
Вся прелесть этой архитектуры кроется в том, что она чрезвычайно хорошо приспособлена к требованиям традиционных систем баз данных (табл. 1). Основное требование поддержки согласованности данных поддерживается в нижнем звене, внутри сервера баз данных. Основная цель оптимизации (минимизация времени ответов и максимизация пропускной способности) достигается за счет применения во всех звеньях ряда методов, разработанных за последние четыре десятилетия: кэширование, индексация, разделение данных и многое другое. Кроме того, масштабируемость достигается на двух верхних уровнях: на этих уровнях архитектура с рис. 1 масштабируется почти неограниченно. Однако в нижнем звене масштабируемость является ограниченной.
К сожалению, трехзвенная архитектура с рис. 1 не слишком хорошо подходит для удовлетворения новых требований из табл. 1. Еще более важно то, что эта архитектура является дорогостоящей. Обычно требуются значительные инвестиции в нижнее звено, включающее дорогостоящую (а не дешевую) аппаратуру. Аппаратные средства должны быть расчитаны на поддержку ожидаемой пиковой производительности, которая может на порядки величин превосходить реальную среднюю производительность. В результате громадная часть аппаратных ресурсов тратится впустую, и весьма затруднительно использовать эти простаивающие ресурсы для каких-либо других целей. Кроме того, поддержка инфраструктуры баз данных обходится недешево, и она, как все прочее, автоматически не удешевляется. Наконец, фактором расходов может быть само программное обеспечение баз данных. Большая часть его функциональных средств не требуется конкретному приложению, так что клиентам приходится платить за ненужные им возможности. Эта ситуация несколько улучшается при использовании систем баз данных с открытыми кодами, таких как PostgreSQL and MySQL; но, тем не менее, многие организации все еще замкнуты на использовании дорогостоящих коммерческих систем баз данных.
Классическая трехзвенная архитектура систем баз данных и способ ее сегодняшней реализации не отвечают требованиям предсказуемости. При наличии многих клиентов, одновременно производящих доступ к базе данных, практически невозможно понять, что происходит на уровне базы данных. Кроме того, как отмечалось выше, масштабируемость в этой архитектуре ограничивается двумя верхними уровнями.
Еще одной целью разработки, не поддерживаемой должным образом в традиционных архитектурах систем данных, является гибкость. Причина этого состоит в том, что в настоящее время на всех трех уровнях используются разные технологии. В нижнем звене применяются SQL и реляционная модель; в среднем звене – объектно-ориентированный подход; в верхнем же звене – XML/HTML и клиентские скрипты. В результате изменение функциональности (т.е. настройка) должно производиться во всех трех звеньях с использованием трех разных технологий. Такие настройки трудно реализовывать и тестировать.
Полезно напомнить два принципа разработки приложений баз данных в классической трехзвенной архитектуре. Первым принципом является контроль. В нижнем звене СУБД контролирует все аппаратные ресурсы и весь доступ к данным. Второй принцип обычно называется принципом "передачи запросов" ("query shipping") [6]. Этот принцип означает, что как можно больше функций выталкивается в нижнее звено за счет использования хранимых процедур или других средств современных систем баз данных (например, новых типов данных или новых возможностей запросов). С положительной стороны, оба эти принципа помогают достичь наиболее важных целей разработки традиционных систем баз данных: согласованности и производительности. Передача запросов также стимулируется бизнес-моделью большинства поставщиков СУБД: лицензии на использование новых СУБД будут покупаться только в тех случаях, когда в этих СУБД обеспечивается больше функциональных возможностей. С отрицательной стороны, эти два принципа разработки превращают СУБД в монолитных монстров, которые становятся все больше и больше и никогда не уменьшаются. Эта тенденция наносит вред предсказуемости, гибкости и масштабируемости. Кроме того, эти два принципа делают системы IT дорогостоящими, поскольку для поддержки нагрузки в нижнем звене требуется дорогостоящая аппаратура, и сама сложность современных СУБД обходится совсем не даром. Поэтому неудивительно, что в архитектуре, представляемой в следующем подразделе, предлагаются в точности противоположные принципы разработки.
3.2 Новая архитектура
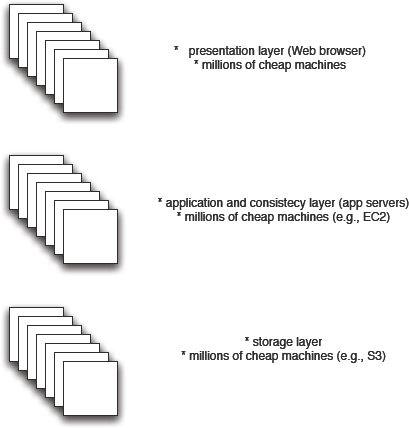
Рис. 2. Архитектура 28msec
На рис. 2 показана архитектура, разработанная для решения новой проблемы оптимизации. Если сравнить рис. 1 и рис. 2, то на первый взгляд архитектуры кажутся похожими. Но между ними имеются существенные различия:
- Проблема согласованости данных решается не на уровне хранения, а на прикладном уровне. На нижнем уровне поддерживается только крупномасштабное распределенное хранение данных за счет использования, например, Amazon S3.
- Согласованность на среднем уровне достигается путем применения распределенных протоколов типа тех, которые предлагаются в [15]. Отсутствует какой-либо объект, контролирующий весь доступ к данным. Вместо этого, все серверы приложений, которые производят доступ к данным, придерживаются общих соглашений при чтении и обновлении данных, хранимых на нижнем уровне.
- На всех уровнях можно использовать дешевую аппаратуру. Все уровни разрабатываются в расчете на возможность масштабирования до тысяч, если не миллионов машин. Архитектура в целом разрабатывается таким образом, что в любой момент времени допускается выход из строя любого узла. В нижнем звене отказоустойчивость достигается за счет репликации данных и предоставления гарантий только слабой согласованности (согласованности "рано или поздно", eventual consistency). На верхних уровнях машины работают без сохранения состояния, так что худшее, что может произойти при выходе машины из строя, – это потеря работы транзакций, активных к этому времени.
- По существу, в архитектуре с рис. 2 исчезает традиционная СУБД. Основные функциональные средства СУБД, т.е. управление транзакциями и обработка запросов, переносятся на прикладной уровень.
- Можно выполнять программные средства прикладного уровня и уровня представления на машине конечного пользователя. Процессы, выполняемые на обоих этих уровнях, не сохраняют состояние, и допускается аварийное завершение любого из этих процессов в любой момент времени.
Эта архитектура реализована компанией 28msec в продукте Sausalito. В Sausalito в единую переносимую платформу интегрируются виртуальная машина, система управления данными, процессор потоков данных, система управления очередями и Web-сервер. Это производит впечатление еще одного монстра, даже более ужасного, чем СУБД, но на самом деле это не так. В настоящее время размер всей платформы составляет всего около 140 мегабайт, в основном, за счет того, что она обладает более скудными и целенаправленными функциональными возможностями.
В Sausalito все данные и (откомпилированный) код приложения хранятся в виде BLOB'ов с использованием Amazon S3. Каждый HTTP-запрос (например, инициируемый пользователем из Web-браузера или путем вызова Web-сервиса из некоторого приложения) обрабатывается следующим образом. На основе использования службы Amazon EC2 и ее сервиса планирования и балансировки нагрузки для обработки этого запроса выбирается доступный сервер EC2. Для обработки запроса этот сервер загружает из S3 откомпилированный код. Затем этот код интерпретируется на данном сервере EC2 подсистемой Sausalito поддержки времени выполнения, возможно, производя доступ к объектам базы данных, которые также сохраняется в виде BLOB'ов в S3. Во всех серверах EC2 не сохраняется состояние, и допускается выход из строя каждого из них в любой момент времени. При повышении (уменьшении) нагрузки, число серверов EC2 может быть увеличено (соответственно, сокращено). В Amazon S3 на уровне хранения данных используются дешевые аппаратные средства, и доступность данных достигается путем репликации всех BLOB'ов в нескольких узлах разных центров данных. Синхронизация параллельного доступа к одним и тем же данным (от нескольких серверов EC2) производится на основе использования протоколов, описанных в [3].
В качестве языка программирования для реализации логики приложения и обеспечения доступа к базе данных в Sausalito используется XQuery (с расширениями для обновления данных и применения скриптов). В Sausalito применяется XQuery, потому что в этом языке хорошо поддерживаются все стандарты Web (в частности, стандарты REST и Web-сервисов), имеются развитые средства запросов к базам данных, и возможностей этого языка достаточно для создания развитых Web-приложений. Для тех же целей в AppEngine компании Google используется Python со встраиваемым диалектом SQL для доступа к базам данных. Компания же Microsoft опирается на языки семейства .NET и LINQ.
Очевидно, что у любой системы (включая Sausalito), основанной на архитектуре с рис. 2, мало шансов сравняться с современными системами баз данных в отношении производительности и согласованности данных. Что касается согласованности, то в соответствии с теоремой Бревера (Eric A. Brewer) [7] невозможно одновременно реализовать строгую согласованность, высокую доступность и масштабируемость. Если же говорить о производительности, то современные СУБД оптимизировались для достижения этой цели в течение, фактически, сорока лет. Однако архитектура с рис. 2 хорошо соответствует остальным характеристикам из табл. 1. Как показывает опыт Sausalito, эту архитектуру можно где угодно экономически эффективно реализовать с использованием дешевых аппаратных средств. Кроме того, в этом случае масштабируемость обеспечивается автоматически. Гибкость достигается за счет упрощения платформы, а также использования на всех уровнях одной модели программирования и данных, а не разных моделей на каждом уровне. Как показано в [3], для многих рабочих нагрузок можно добиться предсказуемых расходов и производительности.
Из сказанного в этом разделе должно стать ясно, что архитектура с рис. 2 создавалась в противоположность принципам разработки, свойственным архитектуре с рис. 1. Вместо централизованного контроля всех чтений и записи данных используются соглашения, регулирующие доступ к данным в распределенной, слабо связанной среде. Эти соглашения реализуются как распределенные протоколы [15, 3]. Вместо того чтобы перемещать как можно больше функциональных средств ближе к данным, на уровне хранения поддерживается минимальный интерфейс "get" и "put". Вся остальная функциональность реализуется на прикладном уровне. Особым аспектом является безопасность. Средства безопасности должны реализовываться на прикладном уровне с шифрованием всех данных, хранящихся на нижнем уровне, и контролированием распространения ключей для доступа к этим данным. Мы ожидаем, что реализовать средства безопасности в архитектуре с рис. 2 будет не намного сложнее, чем в архитектуре с рис. 1, поскольку в любом случае безопасность учитывается на уровнях и приложения и представления.
Родственные работы
Очевидно, что мы не первые подвергаем сомнению архитектуры современных СУБД. Все идеи, представленные в этой статье, уже существовали в течение некоторого времени, и в статье лишь предпринимается попытка собрать из этих разрозненных фрагментов некоторую общую картину. Очевидно, что наблюдаемый в последнее время интерес к облачным вычислениям и Web-сервисам компании Amazon (например, S3 и EC2), а также сервисам AppEngine компании Google проясняет путь к переосмыслению стоимости современных информационных систем. Влияние принципов разработки на основе SOA на архитектуру приложений баз данных обсуждалось в недавних выступлениях Вогелса [16] и Хелланда [8]. Кроме того, имеется ряд важных методов нетрадиционной оптимизации запросов (например, Eddies [2] и оптимизация запросов в предполагаемом и худшем случаях [4]).В конце 1990-х гг. годов стало понятно, что в крупных прикладных системах, таких как SAP, СУБД используются всего лишь как приукрашенная файловая система со встроенной поддержкой персистентных B-деревьев [5]. В то время реакция поставщиков СУБД состояла в том, что они спрашивали SAP, каким образом они могли бы расширить свои продукты, чтобы они в большей степени отвечали требованиям SAP? Правильнее было бы спрашивать, как переоформить функциональные средства СУБД для их лучшей интеграции в архитектуру приложения? К сожалению, этот вопрос никогда не ставился.
Среди последних работ в области архитектуры систем баз данных наиболее важным является наблюдение Стоунбрейкера (Michael Stonebraker) и др. о том, что "один размер непригоден для всех" [14, 13]. В этой работе демонстрируются недостатки современных СУБД при их использовании в нескольких прикладных областях: обработке потоковых данных, поддержке принятия решений (т.е. OLAP) и обработке транзакций (т.е. OLTP). При сравнении этой работы с наблюдениями, представленными в данной статье, обнаруживается значительное совпадение точек зрения. Во-первых, в обеих работах отмечается, что современные системы баз данных более не производят впечатление оптимальных для чего бы то ни было. Вторая, и более важная, точка согласия состоит в том, что функциональность систем баз данных может быть эффективно перегруппирована и сокращена, чтобы в большей степени отвечать потребностям приложений. В-третьих, хотя работа Стоубоейкера и др. фокусируется на производительности и достижении ее повышения на несколько порядков, те же доводы можно было бы применить к затратам, на которых фокусируется наша работа. В-четвертых, архитектурные принципы, обсуждавшиеся в подразделе 3.2, никаким образом не противоречат технологии, предлагаемой в [14, 13]. В некотором смысле, наша работа основывается на результатах Стоунбрейкера и др. и вовсе не конфликтует с их работой. В работе Стоунбрейкера и др. ищутся пути построения современных СУБД (например, систем с поколоночных хранением, обработкой данных "на лету" и упрощенной синхронизацией), в то время как целью нашей статьи является формирование более крупной картины и поиск путей интеграции технологии баз данных в приложения в целом и в общий стек технологий.
Имеется также много работ, посвященных повышению масштабирования средств управления данными для Web. Наиболее важными являются работы по кэшированию и материализации Web-представлений (например, [10, 17, 11]). Цель всех этих работ состоит в повышении уровня масштабируемости современных систем, основанных на использовании Web, путем снижения нагрузки на базы данных. Кроме того, как отмечалось ранее, денежная стоимость играет некоторую роль в эталонных тестовых наборах TPC. Она также используется в ряде инфраструктур для повышения производительности и качества сервисов в распределенных информационных системах. Показательными примерами являются система Mariposa [12] и инфраструктура "Quality Contracts (QC)" [9].
Заключение
Назначением системы баз данных является поддержка разработчиков при написании, внедрении и запуске приложений. В 1960-х гг. большинство приложений баз данных ориентировалось на поддержку кредитных и дебетовых транзакций: базы данных были исключительно полезны и почти полностью решали всю проблему. Вполне допустимо было потратить на программное обеспечение и администрирование баз данных большую часть бюджета IT. С тех пор приложения значительно выросли и усложнились, и базы данных (а также промежуточное программное обеспечение) позволяют решать только относительно небольшую часть проблемы. В результате системы баз данных часто приносят больше беспокойств, чем реальной пользы, поскольку они являются всего лишь одним из многих компонентов, но при этом зачастую диктуют всю архитектуру приложения. Коротко говоря, условия и цели использования систем баз данных за сорок лет, прошедшие после создания первого поколения систем баз данных, изменились.Задачей этой статьи является переосмысление этих условий и целей и, таким образом, переопределение проблемы баз данных. Авторы попытались сделать это для Web-приложений, таких как, например, онлайновый магазин или служба по совместному использованию автомобилей (car-pooling service). В результате появились новая формулировка проблемы, новая архитектура (что неудивительно) и новая раскладка функциональных средств управления базами данных. Очевидно, что на эти результаты повлияли конкретные сценарии интерактивных Web-приложений. Анализ потребностей других приложений, таких как организация хранилищ данных или поддержка принятия решений, мог бы привести к другим результатам. Кроме того, предложенная новая архитектура приложений баз данных не является зрелой. Хотя похоже, что и крупные игроки, такие как Google, и начинающие компании типа 28msec склоняются к такой архитектуре, требуется еще проделать большую работу, прежде чем появятся продукты, пригодные для массового использования. Тем не менее, это не меняет основную мысль данной статьи. Словами Гоца Грейфа (Goetz Graefe), "Поставщикам баз данных не следует производить Феррари – им следует производить Форд Таурус" (середина 1990-х).
Благодарности
Мы хотели бы поблагодарить Пола Хофманна (Paul Hofmann) за обсуждения и многие полезные комментарии по поводу этой статьи.Литература
[1] Anon et al. A measure of transaction processing power. Datamation, 1984.[2] R. Avnur and J. Hellerstein. Eddies: Continuously adaptive query processing. In Proc. of ACM SIGMOD, pages 261–272, Jun 2000.
[3] M. Brantner, D. Florescu, D. Graf, D. Kossmann, and T. Kraska. Building a database on S3. In Proc. of ACM SIGMOD, pages 251–264, Jun 2008.
[4] F. Chu, J. Halpern, and J. Gehrke. Least expected cost query optimization: What can we expect? In Proc. of ACM PODS, pages 293–302, Jun 2002.
[5] J. Doppelhammer, T. Hoppler, A. Kemper, and D. Kossmann. Database performance in the real world: TPC-D and SAP R/3. In Proc. of ACM SIGMOD, pages 219–230, Jun 1997.
[6] M. Franklin, B. Jonsson, and D. Kossmann. Performance tradeoffs for client-server query processing. In Proc. of ACM SIGMOD, pages 149–160, Jun 1996.
[7] S. Gilbert and N. Lynch. Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant Web services. SIGACT News, 33(2):51–59, 2002.
[8] P. Helland. Life beyond distributed transactions: An apostate’s opinion. In Proc. of CIDR Conf., pages 132–141, Jan 2007.
[9] A. Labrinidis, H. Qu, and J. Xu. Quality contracts for real-time enterpises. In Business Intelligence for the Real-Time Enterprises, pages 143–156, August 2007.
[10] A. Labrinidis and N. Roussoupoulos. WebView materialization. In Proc. of ACM SIGMOD, pages 367–378, Jun 2000.
[11] Q. Luo, S. Krishnamurthy, C. Mohan, H. Pirahesh, H. Woo, B. Lindsay, and J. Naughton. Middle-tier database caching for e-business. In Proc. of ACM SIGMOD, pages 600–611, Jun 2002.
[12] M. Stonebraker, P. Aoki, W. Litwin, A. Pfeffer, A. Sah, J. Sidell, C. Staelin, and A. Yu. Mariposa: A wide-area distributed database system. VLDB Journal, 5(1):48–63, 1996.
[13] M. Stonebraker, C. Bear, U. Cetintemel, M. Cherniack, T. Ge, N. Hachem, S. Harizopoulos, J. Lifter, J. Rogers, and S. Zdonik. One size fits all? Part 2: Benchmarking studies. In Proc. of CIDR Conf., pages 173–184, Jan 2007. Имеется перевод на русский язык: Пригоден ли один размер для всех? Часть 2: результаты тестовых испытаний.
[14] M. Stonebraker, S. Madden, D. Abadi, S. Harizopoulos, N. Hachem, and P. Helland. The end of an architectural era (it’s time for a complete rewrite). In Proc. of VLDB Conf., pages 1150–1160, Sep 2007. Имеется перевод на русский язык: Конец архитектурной эпохи, или Наступило время полностью переписывать системы управления данными.
[15] A. Tanenbaum and M. van Steen. Distributed Systems: Principles and Paradigms. Prentice Hall, Upper Saddle River, NJ, 2002.
[16] W. Vogels. Data access patterns in the Amazon.com technology platform. In Proc. of VLDB, page 1, Sep 2007.
[17] K. Yagoub, D. Florescu, V. Issarny, and P. Valduriez. Caching strategies for data-intensive web sites. In Proc. of VLDB, pages 188–199, Sep 2000.