Пригоден ли один размер для всех?
Часть 2: результаты тестовых испытаний
Майкл Стоунбрейкер, Чак Беэ, Угур Кетинтемел, Мич Черняк, Тиньян Ге, Набил Хачем, Ставрос Харизопулос, Джон Лифтер, Дженни Роджерс, Стэн Здоник
Перевод: Сергей Кузнецов
Оригинал: Michael Stonebraker, Chuck Bear, Uğur Çetintemel, Mitch Cherniack, Tingjian Ge, Nabil Hachem, Stavros Harizopoulos, John Lifter, Jennie Rogers, and Stan Zdonik. One Size Fits All? – Part 2: Benchmarking Results, http://nms.csail.mit.edu/~stavros/pubs/osfa.pdf.
This article is published under a Creative Commons License Agreement.
You may copy, distribute, display, and perform the work, make derivative works and make commercial use of the work, but you must attribute the work to the author and CIDR 2007.
3rd Biennial Conference on Innovative Data Systems Research (CIDR)
January 7-10, 2007, Asilomar, California, USA.
Аннотация
Два года назад двое из нас написали статью, в которой предсказывалась кончина «безразмерности» («One Size Fits All, OSFA») [Sto05a]. В этой статье мы анализировали рынки систем обработки потоков данных и хранилищ данных и объясняли причины существенно более высокой производительности специализированных архитектур в обеих этих областях. В данной статье описываются три новых результата. Во-первых, мы анализируем причины того, что специализированные реализации обеспечивают аналогичные преимущества в производительности систем обработки текстов. Во-вторых, мы приводим количественные показатели производительности коммерческих реализаций специализированных архитектур и реляционных СУБД при использовании их в приложениях обработки потоков данных и хранилищ данных. Наконец, мы сравниваем числовые показатели производительности академического прототипа специализированной архитектуры для научных приложений, реляционной СУБД и широко используемого математического вычислительного инструментального средства. В итоге оказывается, что специализированные архитектуры обеспечивают преимущества в производительности, по крайней мере, в трех областях.
- 1. История архитектуры OSFA
- 2. Текстовые базы данных – показатель 10
- 3. Хранилища данных – еще одна десятка
- 4. Обработка потоковых данных – и снова десятка
- 5. Научные приложения – и еще раз десятка
- 6. Другие возможности ASAP и потенциальные затруднения при достижении высокой производительности
- 7. И что теперь?
- Благодарности
- Ссылки
1. История архитектуры OSFA
Технология реляционных систем управления базами данных (РСУБД) берет начало от работ над System R [Ast76] и Ingres [Sto76]. В то время (1970-е гг.) основная цель архитекторов этих систем состояла в том, чтобы доказать преимущество реляционной технологии над иерархическими и сетевыми системами при решении тех задач, которые тогда являлись наиболее распространенными, а именно задач обработки бизнес-данных. Поэтому архитектурные решения в этих ранних прототипах ориентировались на обработку транзакций. Практически все коммерческие РСУБД являются прямыми потомками этих ранних систем и основываются на их общей архитектуре (хранение данных по строкам, индексация на основе B-деревьев, небольшой размер дисковых блоков и выполнение, ориентированное на строки).
С годами поставщики крупных РСУБД усовершенствовали эту исходную архитектуру в нескольких отношениях, включая следующее:
- Мультипроцессорные конфигурации. Исходно разработанные в расчете на использование мультипроцессоров с разделяемой памяти, коммерческие РСУБД были расширены для поддержки систем с совместно используемыми дисками (дисковые кластеры), систем без общих ресурсов (shared nothing, блейды) или того и другого.
- XML. В последнее время несколько РСУБД было расширено возможностями поддержки SQL или XQuery над таблицами или данными, представленными в соответствии с XML Schema.
- Хранилища данных. Несколько коммерческих систем было расширено средствами, обеспечивающими улучшенное выполнение аналитических запросов. При этом использовались такие методы, как сжатие данных, материализованные представления, таблицы с доступом только через индекс и индексы соединения.
Основная цель этих усовершенствований состоит в том, чтобы продолжать продавать единственную линию кода, поддерживающую все требования к СУБД. В число причин приверженности поставщиков к этой стратегии «безразмерности» («one size fits all», OSFA) входит следующее:
- Технические затраты. При поддержке нескольких линий кода линейно возрастает требуемый объем технической работы. Кроме того, часто требуется синхронизация нескольких линий кода, что приводит к необходимости дополнительных трудозатрат.
- Затраты на продажи. Продавец РСУБД должен быть обучен тому, какую линию кода следует пытаться продавать в каждой конкретной ситуации. Поскольку различия между продуктами быстро становятся достаточно сложными (а продавцы редко являются выдающимися учеными), эта задача устрашает.
- Затраты на маркетинг. Для нескольких линий кода должно иметься правильное позиционирование на рынке. Часто это является трудной проблемой. Гораздо проще позиционировать OSFA: «У меня есть молоток, и я могу забить им любой гвоздь».
Стратегия единственной линии кода будет преуспевать до тех пор, пока у целевой клиентской базы имеются однородные требования к возможностям системы. Можно легко утверждать, что такая однородность имеется в области обработки бизнес-данных. Однако в последней четверти столетия появился ряд новых рынков с новыми требованиями. Кроме того, постоянное развитие технологии приводит к периодическому изменению тактик оптимизации.
При возникновении подобных ситуаций появляется возможность того, что некоторая новая линия кода, основанная совсем на другой архитектуре, значительно превзойдет по производительности традиционную линию кода. Обычно это является результатом использования некоторой новой архитектуры хранения данных, которая обладает преимуществами над архитектурой OSFA. В данной статье «существенное превосходство в производительности» означает демонстрацию производительности, по меньшей мере, в десять раз большей, чем у традиционной системы, на той же самой (или сопоставимой) аппаратуре. В десять раз, например, отличается время отклика системы в одну минуту от времени отклика в 10 секунд. Примером несопоставимых аппаратных средств является двухпроцессорный ПК стоимостью в 800 долларов, с одной стороны, и 20-процессорный блейд-сервер, с другой стороны. При возникновении такого различия в производительности заказчики, которых заботят вопросы производительности, будут склоняться к тому, чтобы испробовать новую архитектуру. Хотя можно спорить о том, не является ли показатель 10 слишком высоким барьером, который требуется преодолеть новой архитектуре, очевидно, что показатель 2 или 3 является недостаточным. В последнем случае заказчик может принять решение просто подождать год или два, пока произойдет следующий виток развития аппаратных средств или увеличится бюджет на приобретение аппаратуры. Десятикратное различие в производительности приводит к непригодности подобной тактики.
Предпосылка данной статьи состоит в том, что в настоящее время существуют, по крайней мере, четыре рынка, для которых этот барьер десятикратного превышения производительности традиционных систем уже превзойден. В следующих четырех разделах мы детально обосновываем свои утверждения на основе проведения сравнительных тестовых испытаний или использования результатов таких испытаний, проведенных другими исследователями. В последнем разделе статьи мы размышляем о нескольких возможных путях будущего развития рынка коммерческих СУБД.
2. Текстовые базы данных – показатель 10
К разочарованию многих специалистов, в системах хранения и поиска текста не используются РСУБД; это замечание повторяется на большинстве конференций, посвященных СУБД. И на самом деле, в этой области не используются никакие СУБД, а предпочитается организация систем прямо над уровнем файловых систем. Один из первых сигналов о появлении этого феномена «самокрутки» («roll your own») поступил к одному из нас в середине 1990-х гг. от основателя Inktomi Эрика Брювера (Eric Brewer). Он пытался использовать коммерческую РСУБД в ранней версии своего продукта, но быстро отказался от этой идеи, когда понял, что в Inktomi всегда выполняется запрос одного и того же вида – соединение трех таблиц с использованием констант, соответствующих поисковым терминам из запроса пользователя. Этот единственный запрос можно было легко закодировать вручную, и он выполнялся в 100 раз быстрее, чем при использовании РСУБД.
Для этого различия в производительности имеется несметное число причин. Среди них (i) отсутствие потребности в блокировках транзакций, в поддержке типов данных, кроме одного текстового типа данных, в повторяющихся и полных ответах; (ii) потребность в горизонтальном разделении данных, в специализированном сжатии данных, в списках переменного размера.
Брювер [Bre04] задним числом довольно детально исследовал эти причины. Кроме того, разработчики последующих поисковых машин (например, Google, Lycos и т.д.) пришли к аналогичным заключениям и создали проприетарные поисковые машины. Более того, компания Google построила полный стек системного программного обеспечения, включающий файловую систему (GFS [Ghe03]), специальную СУБД (Bigtable [Cha06]) и соответствующие ее потребностям абстракции параллельной обработки данных (MapReduce [Dea04] and Sawzall [Pik05]). Bigtable массовым образом применяется для организации внутреннего хранения данных.
Вероятно, какая-либо поисковая компания предоставит свою систему внутреннего хранения для управления данными клиентов либо в виде специализированной системы, устанавливаемой на компьютерах заказчиков, (аналогично локальному средству поиска Google Appliance, существующему в настоящее время), либо в виде сервиса. Когда это произойдет, появится одна или несколько заметных архитектур, отличных от архитектуры РСУБД и используемых для хранения данных заказчиков.
3. Хранилища данных – еще одна десятка
По оценкам хранилища данных в 2005 г. занимали треть рынка РСУБД [Gar06, Ola06]. В настоящее время на рынке хранилищ данных преобладают поставщики РСУБД, продающие системы, в которых используется традиционная архитектура с поддержкой хранения данных по строкам. В системах C-Store [Sto05b] и Monet [Bon04] для приложений хранилищ данных поддерживается хранение данных по столбцам, и в [Har06] приводятся некоторые предварительные показатели производительности. В этом разделе мы представим дополнительные факты, полученные в ходе двух исследований производительности с использованием недавно выпущенной системы Vertica [Ver06], которая основана на идеях C-Store и является завершенной СУБД с хранением данных по столбцам; эти факты подтверждают наши утверждения о выигрыше в производительности подобных систем.
3.1 Детальная информация о вызовах телефонных компаний
В большинстве приложений хранилищ данных (если не во всех них) используются схемы «звезда» или «снежинка»; и схема одного из таких хранилищ данных показана на рис. 1. Эта схема используется в производственном режиме некоторой компанией, специализирующейся на бизнес-анализе детальной информации о вызовах телефонных компаний. Здесь в центральной таблице фактов (usage) поддерживаются записи с разнообразными детальными данными о вызовах; в таблице account содержатся номера телефонов, являющихся субъектами биллинга; source содержит информацию о сети, из которой поступили детали вызова, и toll содержит информацию биллинга.
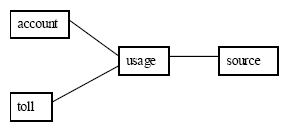
Рис.1. Схема телефонной компании
Кроме этой схемы,телефонная компания предоставила компании Vertica 600 гигабайт реальных данных и набор примеров запросов, которые используются в их повседневной работе. Кроме того, они также предоставили Vertica приблизительные времена выполнения этих запросов при использовании их текущего решения – 28-процессорного блейд-сервера с СУБД одного из ведущих поставщиков; эта установка стоит примерно 300000 долларов, а СУБД основывается на традиционной архитектуре с хранением данных по строкам. На рис. 2 показаны эти значения времени выполнения запросов, а также соответствующие показатели системы Vertica, полученные при использовании двухпроцессорного компьютера с двухъядерным процессором Opteron стоимостью около 2500 долларов.
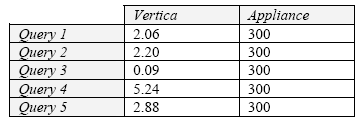
Рис. 2. Время выполнения запросов (в секундах)
На рис. 3 показан код на языке SQL запроса 2 этого тестового набора над звездообразной схемой, показанной на рис. 1. Этот запрос является типичным для запросов над хранилищами данных: сначала в нем производится фильтрация таблицы фактов с использованием предикатов, определенных над ее столбцами или столбцами таблиц измерений; затем ограниченная таблица фактов группируется на основе некоторых атрибутов и агрегатов. При выполнении этого запроса производительность системы с хранением данных по столбцам в 47 раз превосходит производительность системы с хранением данных по строкам при использовании в семь раз меньшего числа процессоров. Имеется несколько причин этой поразительной разницы в производительности, но особо выделяются три из них.

Рис. 3. Запрос 2
Во-первых, в таблице usage содержится несметное число деталей о вызовах, включая информацию о перенаправлении вызовов, о сетях, через которые проходил данный вызов, о длине вызова и причинах его завершения и т.д. В целом в таблице имеется более 200 столбцов. Хотя о разумности появления такой «откормленной» таблицы можно было бы поспорить с разработчиками схемы, следует заметить, что в данной компании в различных непредвиденных запросах используется много разных полей. Поэтому декомпозиция этой таблицы фактов на несколько таблиц привела бы к потребности в соединениях, которые могли бы замедлить выполнение запросов. Кроме того, в действительности таблица фактов была предварительно соединена по соответствующим атрибутам с таблицами измерений, чтобы избежать соединений во время выполнения запросов, что является распространенным приемом в средах хранилищ данных; в результате появилось материализованное представление, содержащее 212 столбцов. Заметим также, что в данном запросе читается 7 столбцов из 212-ти. Следовательно, система, основанная на хранении данных по столбцам, прочитает ровно 7 столбцов, в то время как система, хранящая данные по строкам, будет читать все 212 столбцов – впечатляющее различие в два порядка в объеме данных, перемещаемых с диска.
Второе соображение – это сжатие. Как отмечалось в [Aba06], сжатие обычно является более эффективным при хранении данных по строкам, чем при их хранении по столбцам. Здесь существенно не только то, что все объекты, располагающиеся в одном дисковом блоке, имеют один и тот же тип данных, но и то, что становятся возможными дополнительные варианты сжатия, такие как дельта-кодирование (delta encoding) и групповое кодирование (run-length encoding). При проведении нескольких испытаний на тестовых наборах оказывалось, что в Vertica поддерживается коэффициент сжатие 10, что почти в три раза превосходило возможности сжатия тех же данных в системах с хранением по строкам.
Третья причина связана с сортировкой и индексацией, которые использовались в Vertica и не применялись в решении, основанном на хранении по строкам. Это объясняет константное время выполнения запросов при использовании традиционной системы, в то время как в Vertica поддержка упорядоченного хранения значений столбцов позволяла сократить время выполнения некоторых запросов.
Теперь легко привести пояснения к рис. 2. В решении, основанном на хранении данных по строкам, не использовались ни сжатие, ни индексация. Поэтому в этом случае время выполнения запроса – это время чтения с диска 600 гигабайт данных при наличии впечатляющей пропускной способности дисковой подсистемы и процессоров в 70 Мб/сек. В базе данных Vertica хранилось менее 60 гигабайт данных, а действительно считывалось около 3 гигабайт. 200-кратное сокращение объема ввода-вывода гарантированно приводит к существенному повышению производительности!
Хотя очевидно, что на результаты этого сравнения производительности существенно повлияло наличие у этой компании очень широкой таблицы фактов, аналогичные, хотя и менее эффектные результаты наблюдались и в различных других исследованиях. В нашем следующем примере используется «тощая» таблица фактов.
3.2 Упрощенный TPC-H
Известный эталонный тестовый набор TPC-H используется многими поставщиками для подтверждения своего превосходства в производительности хранилищ данных. Этот тестовый набор искусно строился таким образом, чтобы избежать использования схемы «снежинка» и сделать бесполезным применение материализованных приложений. При опросе двух десятков директоров по информатизации различных компаний авторы данной статьи установили, что никто из них не встречал хранилище данных, в котором бы не использовалась схема «снежинка». Поэтому Пэт О’Нейл (Pat O’Neil) упростил схему TPC-H до вида снежинки и определил над этой схемой 12 вариантов запросов TPC-H [One06]. Полученная схема приведена на рис. 4, а несколько запросов из этого набора – на рис. 5. Наконец, на рис. 6 показано время выполнения этих 12 запросов на компьютере с 4-ядерным процессором Opteron стоимостью в 2500 долларов с использованием Vertica и популярной системы с хранением данных по строкам.
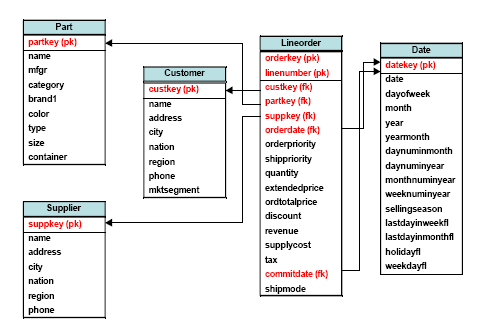
Рис. 4. Схема для упрощенного тестового набора TPC-H
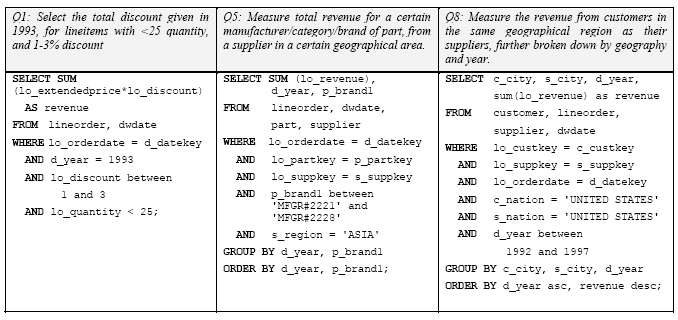
Рис. 5. Примеры запросов из упрощенного тестового набора TPC-H
В обеих системах использовались сжатие и горизонтальное разделение. Кроме того, хранилище по строкам оптимизировалось опытным администратором баз данных, профессией которого является настройка именно этого продукта. На рис. 6 приведены результаты, полученные при использовании двух физических схем. Первая схема называется «low space» и ориентирована на использование очень ограниченной избыточности, в то время как во второй схеме, называемой «medium space», создаются три материализованные представления, так что при выполнении запросов не требуется полное сканирование. Наконец, в данном тестовом наборе использовались объемы данных, соответствующие масштабному коэффициенту (scale factor) 100 в соответствии со спецификацией TPC-H, и объем исходных данных составлял примерно 60 гигабайт.
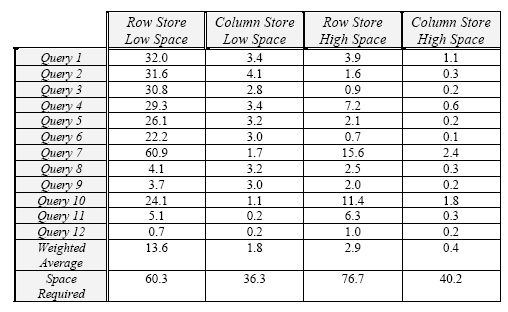
Рис. 6. Время выполнения запросов (в секундах) и требования к объему дисковой памяти (в гигабайтах)
Рис. 6 позволяет сравнить две системы, использующие идентичные физические схемы. Заметим, что при использовании хранения по столбцам удается добиться ускорения запросов примерно в 7 раз при использовании менее чем половины объема дисковой памяти. Можно было бы сравнить эти системы при предоставлении каждой из них одного и того же объема дисковой памяти. В этом случае система с хранением данных по столбцам оказывается намного быстрее системы с хранением по строкам. Хотя эти результаты оказываются не настолько впечатляющими, как те, что были приведены в подразделе 3.1, они аналогичны результатам, приведенным в [Sto05b].
4. Обработка потоковых данных – и снова десятка
В последнее время имеется значительный интерес к обеспечению низких показателей задержки при обработке потоков сообщений с использованием высокоуровневого инструментария. Имеются коммерческие продукты, в которых применяется нотация правил (например, Apama [Apa06]), а также системы, основанные на использовании нотации SQL (например, StreamBase [Str06] и Coral8 [Cor06]). Хотя ведется некоторая полемика вокруг того, какая из парадигм в конце концов выиграет, у нотации SQL есть одно большое преимущество, а именно, то, при решении большинства проблем обработки потоковых данных требуется сохранять и производить доступ к существенным объемам информации о состоянии. Поскольку SQL является универсальной парадигмой хранения данных, естественно использовать расширенный вариант SQL для требуемой смеси данных реального времени и исторических данных.
Сегодняшние коммерческие системы происходят от академических прототипов, таких как [Aba03] и STREAM [Mot03]. К настоящему времени имеется значительный опыт представления этих коммерческих систем на рынке и сравнения их производительности с производительностью альтернативных систем, основанных на использовании самодельного кода или реляционных СУБД. В этом разделе мы также обсудим два тестовых набора, использовавшихся для сравнения специализированной системы с реляционной СУБД. Хотя было бы естественно использовать тестовый набор Linear Road [Ara04], мы предпочли воспользоваться двумя сценариями, заимствованными у реальных заказчиков.
4.1 Скорректированная цена дробления
Вычисления подобного рода часто производится в приложениях на Уолл-стрит. Имеется входной канал данных о разовых изменениях цены акций:
Ticks (symbol = C6, time = double, volume = integer, price = double),
которые могут поступать от одного из популярных поставщиков данных или через прямое соединение с биржей. Кроме того, имеется второй канал:
Splits (symbol = C6, time = double, split_factor = float).
Во втором канале поступают данные о моменте времени дробления акций, а также значение коэффициента дробления; т.е. для дробления 2 вместо 1 коэффициентом дробления является 1, а для дробления 1 вместо 2 (обратного) коэффициентом дробления будет 0.5. Целью этих вычислений является получение скорректированной цены дробления для канала Ticks. Поскольку акция с данным символом может дробиться более чем один раз, необходимо поддерживать текущую композицию всех коэффициентов дробления, наблюдавшихся до данного момента. Это состояние сохраняется в таблице Storage:
Storage (symbol = C6, total_split = float)
С помощью следующих операторов StreamSQL определяется требуемая обработка хранимой таблицы Storage и двух каналов Ticks и Splits:
UPDATE Storage
FROM Splits S
SET (total_split = total_splits * S.split_factor)
WHERE S.symbol = Storage.Symbol
SELECT T.symbol, price = T.price * S.factor,
T.volume, T.time
FROM Ticks T, Storage S
WHERE S.symbol = T.symbol
Приведенный код выполнялся в системе StreamBase на компьютере стоимостью в 1000 долларов (Pentium D 820 с частотой 2.8 Мгц, RAM объемом в 3 Гб и четыре дисковых устройства SATAII по 200 Гбт), и при этом была продемонстрирована пропускная способность в 333000 сообщений в секунду. Логика РСУБД, позволяющая решить ту же задачу, является немного более замысловатой. Один вариант состоит в создании хранимой таблицы Storage и выполнении оставшейся части приложения в некоторой хранимой процедуре. Этот подход позволяет обрабатывать 12640 сообщений в секунду. Второй подход заключается в том, чтобы заносить в базу данных данные из обоих каналов и потом использовать триггеры для выполнения требуемой обработки. Этот подход позволяет более полно использовать функциональные возможности СУБД, но значительно снижает производительность.
Чтобы показать РСУБД в лучшем свете, мы также реализовали третью альтернативу, разместив таблицу Splits в массиве внутри хранимой процедуры. В первом приближении в этом решении все приложение кодируется в виде хранимой процедуры, без использования каких-либо средств СУБД. Очевидно, более предпочтительным вариантом является собственная реализация приложения полностью вне СУБД. Однако мы сообщаем о результате этой попытки из категории «будет лучше всего, если вы встанете на голову», и в ней нам удалось добиться пропускной способности в 38000 сообщений в секунду.
4.2 Доставка сообщений, поступивших первыми
В компаниях с Уолл-стрит принято подписываться на несколько каналов информации о разовом изменении цены акций: Reuters, Comstock или Infodyne. Распространенным приложением является доставка первого поступившего сообщения об изменении цены акции из канала, у которого в данный момент имеется наименьшая задержка. Поступающие позже дубликаты отбрасываются, и в результате создается единый виртуальный канал, содержащий информацию об изменении цены акции, которая поступила первой.
Очевидно, что нужно доставлять сообщения, поступившие первыми, без ожидания запаздывающих дубликатов. В противном случае будет утрачен весь смысл приложения – сокращение времени задержки. Для краткости мы опускаем код StreamSQL для этого приложения. Однако в реализации на основе StreamBase с использованием персонального компьютера с процессором Pentium стоимостью в 1000 долларов удалось получить пропускную способность в 281000 сообщений в секунду. В отличие от этого, для поддержки логики РСУБД пришлось создать таблицу недавно поступивших сообщений об изменении цены акций и производить поиск в этой таблицы для проверки того, что поступившее сообщение не является дубликатом. Если сообщение оказывается дубликатом, оно отбрасывается, иначе доставляется и заносится в таблицу. С помощью нашего кудесника-администратора нам удалось на основе РСУБД добиться пропускной способности в 11790 сообщений в секунду при использовании таблицы недавно поступивших сообщений и 51700 сообщений в секунду при использовании массива внутри хранимой процедуры.
В [Sto05a] мы обсуждали причины того, что специализированные средства обработки потоков данных обеспечивают гораздо более высокую производительность таких приложений, чем РСУБД. Здесь мы приведем краткую сводку этих причин:
- Средства StreamSQL не выполняются в режиме «клиент-сервер». Поэтому отсутствуют переключения процессов. В отличие от этого, РСУБД построены в расчете на недоверие к приложениям, и поэтому они должны выполняться в адресных пространствах, отделенных от адресных пространств приложений.
- Большая часть средств StreamSQL производит обработку исключительно в виртуальной памяти. Отсутствует потребность в надежном сохранении данных на дисках, что является источником дополнительных накладных расходов.
- В средствах StreamSQL естественным образом поддерживаются временные окна, и не приходится моделировать их с использованием традиционных понятий SQL.
- Для достижения максимальной производительности в StreamSQL предикаты компилируются в машинные команды, в то время как в РСУБД операции обычно компилируются в некоторую промежуточную форму для облегчения поддержки.
- РСУБД оптимизируются в расчете на соединение миллионов записей таблицы-источника с миллионами записей целевой таблицы. В отличие от этого, средства StreamSQL оптимизируются в расчете на обработку одного сообщения (кортежа) несколькими операциями с минимизацией задержки. Поэтому хорошей идеей является избегание очередей между операциями, в то время как в РСУБД очереди являются повсеместными.
Коротко говоря, внутрипроцессный механизм, использующий хранение в основной памяти и оптимизированный в расчете на наличие последовательности операций над одним сообщением, всегда окажется более производительным, чем механизм, основанный на использовании дисковой памяти, обслуживаемый внепроцессными средствами хранения данных и оптимизированный в расчете на обработку наборов данных.
5. Научные приложения – и еще раз десятка
Научные пользователи исторически избегают применения коммерческих продуктов управления базами данных, предпочитая использовать специализированные решения, такие как HDF-5 [Hdf06], MatLab [Mat06] и NetCDF [Net06]. Для этого имеется превеликое множество причин. В этом разделе мы кратко изложим уроки, полученные при выполнении проекта Sequoia в середине 1990-х гг. [Seq93]. После этого мы представим результаты сравнения специализированного прототипа ASAP ([A]rray [S]treaming [A]nd [P]rocessing) с популярной коммерческой РСУБД.
5.1 Проект Sequoia
В проекте Sequoia [Seq93], спонсировавшемся компанией DEC, предпринималась попытка поддержать пользователей научных баз данных (более точно, исследовательскую группу в области наук о Земле Калифорнийского университета в Санта-Барбара, которой руководил Джефф Дозье (Jeff Dozier), и группу моделирования климата в Калифорнийском университете в Лос-Анджелесе, возглавлявшуюся Роберто Мекоза (Roberto Mechosa)) путем применения POSTGRES для решения их проблем. Результат не был успешным. Основная причина состояла в том, что в POSTGRES отсутствовала поддержка больших многомерных массивов, а обе группы, главным образом, работали с массивами данных. Моделирование массивов над таблицами POSTGRES оказалось неэффективным и негибким. Второй, менее важной причиной являлось отсутствие в POSTGRES встроенной поддержки управления метаданными. Ученым в Санта-Барбара требовалась информация о шагах обработки, которые должны были применяться к их каждому набору данных; в основном, это были алгоритмы очистки и редукции данных, которые «стряпали» полезную информацию из необработанных изображений, полученных со спутников. Кроме того, практически все научные данные, происходящие из наблюдений реального мира, были принципиально неточными, и для таких наборов данных требовались показатели ошибок. В POSTGRES отсутствовали возможности хранения и обновления метаданных, характеризующих точность или происхождение данных.
Повторный анализ этой проблемы спустя десятилетие позволяет увериться в необходимости подхода, отличного от того, который обеспечивают объектно-реляционные СУБД. Для удовлетворения потребностей этого сообщества мы создаем новую СУБД ASAP, в которой базовым объектом хранения и обработки являются многомерные массивы. СУБД ASAP уже настолько работоспособна, что на ней удалось пропустить два тестовых набора. Хотя эти тестовые наборы созданы искусственным образом, они содержат черты того, что действительно нужно научным пользователям.
5.2 Тестовые наборы для массивов
5.2.1 Скалярное произведение
В двухмерном случае скалярное произведение определяется следующим образом. Для двух массивов A[I, J] и B[I, J] результатом их скалярного произведения по измерению J является вектор C [I], где C[i] = ∑j (A[i, j] * B [i, j]).
Заметим, что это определение является естественным обобщением стандартного определения скалярного произведения векторов на случай массивов: мы вычисляем скалярное произведение всех пар векторов, получаемых путем итерирования по всем значениям остающихся измерений.
Тестовый набор состоит в вычислении скалярного произведения двух целочисленных массивов A и B с числом измерений, изменяющимся от 3 до 6. Сначала тестовый набор пропускался с использованием систем ASAP и Matlab, в которых массивы поддерживаются как прирожденный тип данных. В этом эксперименте в каждом массиве содержалось 250 миллионов элементов (2Гб исходных целочисленных данных двойной точности), равномерно распределенных по всем измерениям. Мы вычисляли скалярное произведение для всех возможных измерений и подсчитывали среднее время выполнения этого набора матричных вычислений. Результаты были получены на машине с 64-битовым процессором Athlon, работавшим на частоте 2 Ггц, и 1 Гб основной памяти.
Аналогичный тестовый набор пропускался с использованием ASAP и одной из популярных коммерческих РСУБД, в базе данных которой каждый массив представлялся как таблица с атрибутами dimension-1, …, dimension-n, значение. В этом случае каждый массив состоял из 25 миллионов элементов (100 Мб исходных целочисленных данных с одинарной точностью), и использовалась машина с процессором Pentium, работавшим на частоте 3.2 Ггц, и 1 Гб основной памяти. РСУБД использовала 502-680 Мб для каждого массива в зависимости от числа измерений, и значения измерений также нужно было сохранять.
Наконец, мы исследовали два сценария: (i) сценарий «малого шага» («low stride»), в котором все элементы обрабатываемого вектора хранятся поблизости один от другого (насколько это возможно), и (ii) сценарий «большого шага» («high stride»), в котором элементы обрабатываемого вектора рассредоточены по массиву. Первый сценарий моделирует простой, почти последовательный стиль доступа к массиву; второй сценарий моделирует некоторый более сложный стиль доступа.
На рис. 7 показано, во сколько раз скорость выполнения тестовых наборов при использовании ASAP превосходит скорость выполнения соответствующих тестовых наборов при использовании Matlab и RDBMS для случая малого шага. ASAP всегда выигрывает и достигает превосходства в скорости над Matlab в 83 раза. При возрастании числа измерений уменьшается размер векторов-операндов, что приводит к уменьшению показателя соотношения скоростей, поскольку при меньших размерах операндов Matlab лучше использует память. В случае большого шага (значения сравнительных показателей не приведены), а также в ситуациях, когда размеры наборов данных превышают объем основной памяти, Matlab в большой степени зависит от поведения системы управления виртуальной памятью, и вычисления, по существу, останавливаются.
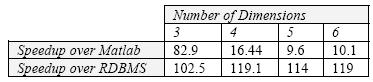
Рис. 7. Соотношение скоростей ASAP для скалярного произведения (случай малого шага)
При сравнении с РСУБД показатель соотношения скоростей устойчиво принимает значение 100 и больше (аналогичные результаты получаются в случаях большого шага).
Основой первого тестового набора было выбрано скалярное произведение, потому что для выполнения этой операции требуются умеренные вычисления, и для выполнения этой функции легко придумать простой однопроходный алгоритм. Поэтому для этого тестового набора имеются сравнительно умеренные требования как к объему ввода-вывода, так и к объему вычислений центрального процессора. В следующем пункте тестовый набор расширяется более сложной операцией над массивами.
5.2.2 Умножение матриц
В двухмерном случае результат умножения двух матриц A[I, J] и B[J, L] определяется как матрица C [I, L], где C[i, l] = j (A[i, j] * B [j, l]).
Тестовый набор состоит в вычислении произведения двух целочисленных матриц A и B с числом измерений, изменяющимся от 3 до 6. Для заданного набора двух общих измерений мы вычисляем произведения всех пар матриц, получаемых путем итерирования по всем значениям оставшегося набора измерений. Заметим, что эта операция является в N раз более трудоемкой, чем скалярное произведение (где N – это средний размер измерения).
Вычисления производились с использованием ASAP, а также Matlab и той же самой РСУБД. На рис. 8 в табличной форме показаны соотношения скоростей для случая малого шага, полученные на тех же аппаратных конфигурациях, что и при вычислениях скалярного произведения.
Мы видим еще более существенное преимущество ASAP над РСУБД (примерно в 800 раз), поскольку для умножения матриц отсутствует однопроходный алгоритм. С другой стороны, Matlab для этого тестового набора работает гораздо лучше, поскольку для этой системы умножение матриц является встроенной, сильно оптимизированной операцией.
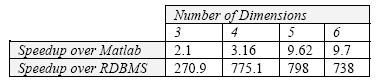
Рис. 8. Соотношение скоростей ASAP для умножения матриц (случай малого шага)
Несмотря на это, ASAP превосходит Matlab во всех случаях. Однако в случаях большого шага и наборов данных большого объема производительность Matlab очень быстро деградирует из-за интенсивного свопинга.
5.2.3 Замечание относительно реализации на основе РСУБД
Оба тестовых набора над массивами реализовывались в форме одного SQL-запроса, в котором использовалась группировка для вычисления суммы результатов перемножения элементов матриц-операндов. Возложение на РСУБД вычисления всех результатов умножения приводит к некоторым накладным расходам, поскольку на протяжении вычислений внутри раздела GROUP BY требуется копирование всей информации измерений.
Возможно, более эффективным подходом было бы использование РСУБД для выполнения корректной сортировки всех пар векторов (или матриц) с последующей реализацией обоих типов вычислений в пользовательском процессе. Тем не менее, мы думаем, что и этот подход привел бы к гораздо более медленным вычислениям, чем те, которые производит ASAP, поскольку ASAP вообще не производит сортировку. Кроме того, как мы покажем в следующем подразделе, ASAP приходится считывать только часть тех байтов, которые считываются РСУБД.
5.3 Причины большого различия в производительности
Исследуем причины различия в скорости выполнения этих двух тестовых наборов. Кроме того, мы приведем рассуждения относительно ожидаемых различий в скорости выполнения третьего тестового набора, который мы не успели пропустить ко времени написания этой статьи. Этот третий тестовый набор состоит в обработке последовательности массивов, которые могут поступать из системы наблюдения, такой как видеокамера, радиолокационная система или система спутникового наблюдения. Цель состоит в поиске некоторого предопределенного паттерна P [I, J], где P может являться, например, некоторым представляющим интерес изображением, таким как конкретный тип транспортного средства. Все случаи обнаружения соответствия заданному паттерну должны фиксироваться.
5.3.1 ChunkyStore
Основным объектом в ASAP является многомерный массив A (I, J, …, K). I, J, …, K называются индексами или измерениями, и их может иметься произвольное (конечное) число. В ASAP поддерживается набор примитивных типов данных (например, целые и плавающие числа, строки символов). Вероятно, в будущем появится средство определения абстрактных типов данных в стиле POSTGRES. Соответственно, измерения могут иметь любой тип, поддерживаемый системой. Кроме того, в ASAP предполагается, что для любого типа данных поддерживается линейная упорядоченность значений в стиле POSTGRES. Поэтому всегда известно следующее значение любого измерения. У измерения может иметься регулярный шаг (regular stride) (например, 1, 2, 3…) или нерегулярный шаг (irregular stride) (например, 1.2, 2.76, 4.3, …). Значением массива для любого набора значений измерений является кортеж значений атрибутов (tuple of attribute values). У каждого атрибута имеется имя, он содержит значения некоторого простого примитивного типа и может содержать неопределенное значение (NULL). Следовательно, значение массива, по существу, является реляционной таблицей.
В ASAP имеется система хранения ChunkyStore, в которой массивы представляются следующим образом:
- Плотные массивы с регулярными шагами. В этом случае значения измерений не хранятся, и элементы данных упаковываются в память очевидным образом. Затем такие массивы декомпозируются в «чанки» («chunk»), которые содержат все значения для «супершага» в каждом измерении. Это делается аналогично тому, что делал Сунита Сараваги (Sunita Sarawagi, [Sar94]) при фрагментировании больших массивов. Чанки размещаются в крупных дисковых блоках (размером, например, от 64 Кб до 1 Мб), так что элементы массива легко адресуются.
- Плотные массивы с нерегулярными шагами. В этом случае для каждого измерения имеется индекс, который упорядочивает значения этого измерения. Этот индекс сохраняется в дополнение к фрагментированным массивам.
- Разреженные массивы с регулярными и нерегулярными шагами. Сохраняются только значения, отличные от неопределенных, вместе со значениями их измерений. Снова данные фрагментируются по дисковым блокам. Однако должен иметься индекс уровня блоков, задающий ограничивающий блок, который определяет подмассив в каждом чанке.
- Гибридная схема. Если распределение неопределенных значений в массиве является сильно скошенным, может иметь смысл сохранять массив как набор подмассивов, представление каждого из которых выбирается в соответствии с его содержимым.
Заметим, что супершаг для разреженных массивов будет переменным. Заметим также, что имеется автоматическое индексирование для всех измерений, но индексирование значений массивов не поддерживается. Если пользователи ASAP будут часто выполнять фильтрацию значений массивов, то в будущем мы можем пересмотреть это решение.
На обоих тестовых наборах подсистема ChunkyStore показала себя наилучшим образом. Во-первых, значения измерений массивов A и B не сохраняются. По существу, объем дисковой памяти, потребляемой ASAP, составляет малую долю объема, потребляемого РСУБД. Даже если бы паттерны доступа в обеих системах были одинаковыми, система ASAP прочитала бы малую долю от числа байт, читаемого РСУБД. Во-вторых, для обоих тестовых наборов фрагментация массивов существенно сокращает число требуемых операций ввода-вывода. В каждом из случаев можно использовать линейный алгоритм, который прочитает каждый чанк только один раз. В отличие от этого, в РСУБД такая фрагментация не поддерживается, и при лучшем стечении обстоятельств потребуется алгоритм со сложностью N * log N.
5.3.2 Операции
Кроме очевидных операций в реляционном стиле (например, фильтрация и агрегация), в ASAP поддерживается набор примитивных операций, ориентированных на научные вычисления. Этот набор включает следующие операции:
- Традиционные операции над массивами. В их число входят умножение, сложение, вычисление собственных значений, преобразования Фурье и т.д.
- Поворот (Pivot). Эта операция изменяет измерения массива путем превращения нуля или большего числа измерений в обычное значение или нуля или большего числа значений в измерения. Конечно, при выполнении этой операции регулярный массив может стать нерегулярным и наоборот. Кроме того, если одно из новых измерений не является ключом (т.е. его значения не уникальны), то результат операции поворота не представляет собой массив, и такое преобразование должно запрещаться.
- Изменение координатной сетки (Regrid). В массивах может иметься система координат. В ASAP поддерживается любое число именованных систем координат. С каждой системой координат ассоциируется набор функций, отображающих точку в данной системе координат к другим системам координат. Для преобразования массива из одной системы координат в другую систему требуется выполнить операцию Regrid, отображающую каждую точку в исходной системе координат в целевую систему координат. Можно отобразить в целевое пространство самый нижний левый угол и все шаги. Однако ячейка в исходной системе координат редко соответствует ячейке в целевой системе координат. Поэтому необходимо производить интерполяцию. Для этого требуется поддерживать функцию Intersect (source_cell, target_cell), возвращающую степень перекрытия ячеек. Затем функция интерполяции может принять решение о размещении значений по целевым ячейкам путем выполнения некоторых вычислений над пересекающимися с ними исходными ячейками.
- Конкатенация. Два массива являются совместимыми, если у них имеется одно и то же число измерений с совпадающими типами. Используя операцию Concatenate, из наборов совместимых массивов можно образовывать группы путем добавления дополнительного измерения, содержащего имена массивов. Заметим, что отсутствует понятие множества массивов; такое множество моделируется как массив с одним дополнительным измерением.
- Определение расположения (Locate). Эта операция является обобщением операции соединения (join) на случай использования неточного соответствия (fuzzy matching) и групп элементов. Операция Locate производит поиск в крупном массиве array_1 областей, которые «неточно соответствуют» меньшему массиву array_2. Критерий соответствия определяется некоторой задаваемой функцией, которая должна возвращать значение true для области массива array_1, соответствующей массиву array_2. Эта операция полезна для извлечения признаков, когда в массиве array_2 содержатся признаки, искомые в массиве данных array_1. Кроме того, операция Locate должна выполнять эвристический поиск в более крупном массиве экземпляров мелкого массива. Поскольку при поиске можно использовать произвольное число методов, в последнем параметре операции Locate указывается метод поиска, который следует применить при ее выполнении. В ASAP реализуется ряд распространенных методов, и этот набор может расширяться заинтересованными пользователями.
При выполнении обоих тестовых наборов в ASAP успешно использовалась примитивная операция умножения матриц, которая была оптимизирована в расчете на использование ChunkyStore. Кроме того, в третьем тестовом наборе можно было использовать операцию Locate с использованием эвристического метода поиска с ограниченным числом сравнений. Такие оптимизации невозможны в РСУБД, в которой операции над массивами должны моделироваться на основе традиционных реляционных операций.
5.3.3 Сжатие
Очевидно, что плотные массивы можно хранить без явных измерений. Кроме того, в некоторых средах имеет смысл их дальнейшее сжатие. Например, к значениям массива в чанке можно применить дельта-кодирование относительно некоторого базового значения, что позволит тратить на хранение этих значений меньшее число бит. В качестве альтернативы можно применить к значениям массива дельта-кодирование относительно значения их предшественника в некотором измерении. В MPEG для видеоданных делается именно это в измерении времени, а в ASAP подобный подход будет применяться более общим образом.
Хотя такое сжатие бесполезно для двух рассмотренных выше тестовых наборов, оно может с пользой применяться в третьем сценарии. Если система подвергает дельта-кодированию последовательные изображения во временом измерении, то операция Locate может игнорировать все части изображения, которые идентичны соответствующим частям предыдущего изображения (распространенная ситуация для стационарных платформ наблюдения), что существенно снижает расходы на обработку. Такого сжатия исключительно трудно добиться при использовании РСУБД, поскольку значение, к которому требуется применить дельта-кодирование, может не находиться в соседнем кортеже или даже в том же дисковом блоке.
5.3.4 Бесшовная интеграция подготовки данных в реальном времени и их хранения
Большинство ученых получает исходные данные от инструментов, а затем выполняет поток шагов обработки для «приготовления» данных. Эти шаги включают операции для преобразования систем координат и очистки данных. Одним из важных компонентов родословной данных является «рецепт» их подготовки, который должен корректно сохраняться в любой системе.
Кроме того, важно, чтобы у системы подготовки имелась та же модель данных, что и у системы хранения. В противном случае будут требоваться постоянные преобразования данных. В добавок к этому, на тот случай, если система подготовки окажется чрезмерно нагруженной, должна иметься возможность сохранения частично подготовленных данных для их последующей обработки, что также является аргументом в пользу поддержки в обоих компонентах одной и той же модели данных. В ASAP содержится компонент подготовки данных в реальном времени, который получен путем перенастройки линии кода Aurora/Borealis для поддержки массивов.
Эта интеграция подготовки данных в реальном времени и их хранения была бесполезна для двух рассмотренных тестовых наборов. Однако в третьем случае мы могли бы выполнять всю требуемую обработку даже без сохранения данных на дисках и выполнения каких-либо переключений задач. В отличие от этого, в РСУБД требуется сначала сохранить данные, а потом выбирать их для обработки, что приводит к появлению значительных накладных расходов.
Как показывают результаты прогона тестовых наборов скалярного произведения и умножения матриц, эти архитектурные изменения позволили добиться повышения производительности в 10 и более раз. Мы думаем, что получили бы еще более впечатляющие результаты, если бы успели пропустить тестовый набор анализа изображений.
6. Другие возможности ASAP и потенциальные затруднения при достижении высокой производительности
Как отмечалось выше, одним из уроков проекта Sequoia является потребность в прирожденной поддержке в базе данных информации о неточности данных и их происхождении. Система обработки должна фиксировать эти данные и автоматически передавать их по всему конвейеру обработки, что может оказаться чрезмерно дорогостоящим делом, если выполнять его по-простому. В частности, работа с неточными, вероятностными данными может легко привести к появлению узких мест (чрезмерной загруженности ЦП или основной памяти), снижающих производительность системы. Требуется разработка практически пригодных методов, особенно для компонента подготовки данных в реальном времени.
В этом разделе описываются настраиваемые подходы, которые будут использоваться в ASAP для работы с неточными данными и данными о происхождении данных. Целью является достижение высокой эффективности за счет некоторой (ограниченной) потери точности, что отвечает потребностям большой части научных приложений.
6.1 Вероятностная трактовка данных
По существу, все научные данные, происходящие из наблюдений над реальным миром, являются принципиально неточными. В предыдущих работах (например, [Bar92], [Wid05]) затрагивались проблемы хранения и обработки неточных или вероятностных данных в традиционных базах данных. В ASAP мы сосредотачиваемся на неточности при обработке многомерных массивов. В этом контексте неточность может появиться по нескольким причинам:
- Неточность данных. У значений массива неизменно имеется ошибка измерения, причиной которой является неточность реальных значений. Этот случай относится к типичной поддержке вероятностных данных в базе данных.
- Неточность позиции (значения измерения). В некоторых случаях неточной является сама позиция измерения, а не полученное значение данных. Соответственно, в этом случае неточными являются значения измерений массива.
- Неточность результатов функций или предикатов. Некоторые функции или предикаты даже при применении к детерминированным данным производят неточные результаты. Например, операция LOCATE, производящая сопоставление с образцом, может производить неточные результаты из-за природы данных и алгоритмов сопоставления.
Давнишней открытой проблемой является лаконичное представление неточных данных и их эффективная обработка в базах данных. Именно на этом мы в основном фокусируемся при работе с неточными значениями. У нас имеются три способа представления неточных значений данных:
- R1: пары «значение-вероятность». Значение элемента массива представляется как (v1, p1), (v2, p2),…, (vn, pn), где (vi, pi) означает, что вероятность того, что значением данного элемента является vi, равна pi. Если сумма psum значений pi оказывается меньше единицы, то (1-psum) является вероятностью того, что значение вообще не присутствует в массиве.
- R2: пара «математическое ожидание, дисперсия». Значение элемента массива, которое, вообще говоря, может являться результатом некоторой операции, представляется как пара (E, Var), содержащая статистическую информацию о данном значении. По сравнению с представлением R1 это представление менее информативно, но зато намного более лаконично и позволяет эффективно обрабатывать запросы. Можно утверждать, что информации о неточности, которую обеспечивает представление R2, достаточно для большинства приложений ASAP. Например, для суммы или среднего значения огромного числа значений индивидуальные возможные значения являются несущественными; скорее могут понадобиться математическое ожидание и дисперсия.
- R3: верхняя и нижняя границы. Это представление аналогично R2, но статистическая информация представляется в виде границ: ([E], UB, p1, LB, p2), где E (математическое ожидание) является необязательным, а UB, LB – верхняя и нижняя границы соответственно. Выполняются соотношения Pr[v > UB] < p1 и Pr[v < LB] < p2. Как и в случае R2, целью этого представления является поддержка эффективной обработки запросов при обеспечении достаточного объема информации о неточности, возвращаемой конечным пользователям.
Представление R1 аналогично тому, что ранее предлагалось в литературе [Bar92]; однако оно не слишком хорошо подходит для поддержки большинства операций запросов. Стоимость обработки запроса, генерирующего большое число пар «значение-вероятность», может оказаться недопустимо высокой. Например, вычисление SUM или AVG может привести к экспоненциальному росту числа дискретных значений в распределении (все возможные пары), что сильно затрудняет выполнение подобных операций. Возможной альтернативой является снижение уровня гранулированности точек дискретной вероятности при применении операций запросов. Однако и это затруднительно, если требуется получить то же распределение значений результата.
В модели неточности ASAP поддерживается много вариантов представления значений. Выбор представления очень сильно влияет на производительность системы. Основная новизна подхода ASAP состоит в том, что точность меры неопределенных данных приносится в жертву простоте обработки, поскольку системе позволяется выбирать представление и осуществлять преобразования между разнообразными представлениями.
Один из способов изменения представления состоит в выборе между R1, R2 и R3. Например, запрос над двумя массивами, для представления значений которых используется R1, мог бы более эффективно произвести результат с использованием представления R2 или R3. Такие преобразования представлений могут производиться при применении любой операции запроса. Эти менее детальные представления кажутся не только достаточными, но, может быть, даже и более подходящими для большинства наших целевых приложений, но они также позволяют добиться умеренно трудоемкой обработки запросов над вероятностными данными (т.е. стоимость обработки линейно зависит от числа обрабатываемых кортежей).
В качестве другой стратегии ASAP будет использоваться выбор уровня гранулированности, на котором назначаются значения неопределенности. Например, мы можем ассоциировать неточность с каждой ячейкой массива или с массивом целиком. В промежутке между этими крайними вариантами мы можем разделять массив на прямоугольники и назначать меру неопределенности каждой такой области. Например, мы можем поделить квадратный массив на 4 равных квадранта, для каждого из которых будет поддерживаться собственное распределение. Тогда будет предполагаться, что для каждой ячейки в данном квадранте имеется одна и та же «форма» распределения, и они будут различаться только своими значениями математического ожидания.
6.2 Отслеживание родословной
В ASAP также поддерживается специальный массив происхождения данных, в котором запоминается информация о запросах, вводившихся для генерации всех целевых массивов, а также об исходных массивах, на основе которых порождались эти целевые массивы. В сущности, эту информацию можно считать историей порождения всех материализованных представлений. Если бы это делалось на уровне индивидуальных кортежей, то отслеживание родословной было бы очень дорогой и даже NP-полной процедурой для некоторых операций [Wid05]. Поэтому в ASAP принят подход к сохранению информации только о шагах обработки («кулинарном рецепте»), которые привели к появлению любого заданного массива. Эта возможность также позволяет расходовать меньший объем дискового пространства и в настоящее время кажется нам отвечающей потребностям многих научных приложений, с которыми мы знакомы.
7. И что теперь?
В предыдущих разделах было охарактеризовано несколько областей, в которых можно добиться существенного выигрыша в производительности за счет применения специализированной архитектуры. Очевидно, что в этих областях имеются взаимно противоречащие архитектурные требования. Следовательно, эти требования невозможно удовлетворить путем применения «безразмерных» СУБД.
В результате имеется несколько возможных путей развития архитектур СУБД в будущем:
- Скучища (без изменений). Можно было бы утверждать, что РСУБД являются достаточно быстрыми, чтобы быть в состоянии отвечать потребностям большинства заказчиков во всех четырех областях. Поэтому будет иметься несколько нишевых решений, удовлетворяющих наиболее требовательных заказчиков, а остальные заказчики будут использовать РСУБД.
Хотя эту точку зрению можно было бы отстаивать для рынков 3 и 4, довольно трудно доказать ее правоту для рынков 1 и 2. Эту позицию особенно трудно защитить для приложений хранилищ данных, где объемы данных и сложность запросов приближаются к пределу.
- K систем, объединенных общим языковым интерфейсом. Можно было бы утверждать, что будет иметься K разных специализированных систем, где K – это число нетривиальных областей со специальными требованиями. Однако все эти системы будут скрыты за общим языковым интерфейсом, и реальные команды пользователя будут направляться в соответствующую систему.
Работа по созданию общего варианта StreamSQL, который объединяет исторические и потоковые данные, является шагом в этом направлении. Кто знает, закрепится ли этот подход в области обработки потоковых данных, не говоря уже о других областях, упоминавшихся в этой статье?
- K систем с использованием абстрактных типов данных. Еще одной возможностью является построение того, что является равнозначным полной системе, внутри системы расширений, присутствующей в современных РСУБД. Например, в виде расширения можно было бы реализовать законченное хранилище данных по столбцам. В конечном результате будет иметься некоторый отличный от предыдущего, менее приятный синтаксис для доступа к чему-то, напоминающему предыдущее решение.
- Федерация данных. Можно было бы просто ухватиться на тот факт, что будет иметься несколько, по существу, несовместимых систем, и что для их взаимного отображения понадобятся «адаптеры». Это был бы просто «закон о полной занятости» для компьютерных ученых на долгое время, поскольку за последние 30 лет была выявлена семантическая трудность построения отображений между различными системами, и не видно никаких признаков того, что в обозримом будущем эта задача станет проще.
- Переписывание с нуля. Существует ненулевая вероятность того, что можно было бы создать единую линию кода, достаточно общую для того, чтобы удовлетворить все требования, отмечавшиеся в этой статье. Например, можно было бы разработать «трансформирующуюся» систему, подобную ChunkyStore, которая могла бы работать и с хранением по строкам, и с хранением по столбцам с поддержкой различных альтернатив в промежутке между этими крайностями. Для такой системы хранения потребуется оптимизатор и исполнитель планов запросов, существенно более общие, чем те, которые поддерживаются в современных системах. Также не исключено, что можно было бы построить систему, которая может выполняться и в клиент-серверном, и во встроенном режиме, а также поддерживает возможности быстрого текстового поиска.
Здесь на ум приходит старое китайское проклятие «чтоб вам пришлось жить в эпоху перемен». С нашей точки зрения, следующее десятилетие станет временем перемен в области СУБД, поскольку поставщикам придется иметь дело с альтернативными архитектурами, рассмотренными в этой статье. Кроме того, у исследователей СУБД появляется очевидное новое занятие – поиск прикладных областей, в которых не работает принцип OSFA, и нахождение приемлемых решений.
Благодарности
Части этой работы поддерживаются грантами NSF IIS-0086057 и IIS-0325838.
Ссылки
[Aba03] D. Abadi, D. Carney, U. Cetintemel, M. Cherniack, C. Convey, S. Lee, M. Stonebraker, N. Tatbul, and S. Zdonik. “Aurora: A New Model and Architecture for Data Stream Management”. In VLDB Journal, 2003.
[Aba06] D. Abadi, S. Madden, and M. Ferreira. “Integrating Compression and Execution in Column-Oriented Database Systems”. In Proc. of the ACM International Conference on Management of Data (SIGMOD), 2006.
[Apa06] http://www.progress.com/apama/index.ssp
[Ara04] A. Arasu, M. Cherniack, E. Galvez, D. Maier, A. Maskey, E. Ryvkina, M. Stonebraker, and R. Tibbetts. “Linear Road: A Benchmark for Stream Data Management Systems”. In Proceedings of the VLDB, 2004.
[Ast76] M. M. Astrahan, M. W. Blasgen, D. D. Chamberlin, K. P. Eswaran, J. N. Gray, P. P. Griffiths, W. F. King, R. A. Lorie, P. R. McJones, J. W. Mehl, G. R. Putzolu, I. L. Traiger, B. Wade, and V. Watson. "System R: A Relational Approach to Database Management". ACM Transactions on Database Systems, June 1976.
[Bar92] D. Barbara, H. Garcia-Molina, and D. Porter. “The Management of Probabilistic Data”. IEEE Trans. Knowl. Data Eng., 4(5):487-502, 1992.
[Bon05] P. Boncz, M. Zukowski, N. Nes. “MonetDB/X100: Hyper-pipelining Query Execution”. In Proceedings of the Conference on Innovative Database Research (CIDR), 2005.
[Bre04] E. Brewer. “Combining Systems and Databases: A Search Engine Retrospective,” in Readings in Database Systems, M. Stonebraker and J. Hellerstein, Eds., 4 ed, 2004.
[Cha06] F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber. “Bigtable: A Distributed Storage System for Structured Data”. In Proc. of the Conference on Operating System Design and Implementation (OSDI), 2006.
[Cor06] http://www.coral8.com/
[Dea04] J. Dean and S. Ghemawat. “MapReduce: Simplified Data Processing on Large Clusters”. In Proceedings of the Conference on Operating Systems Design and Implementation (OSDI), 2004.
[Ghe03] S. Ghemawat, H. Gobioff, and S.-T. Leung. “The Google File System”. In Proceedings of the nineteenth ACM SOSP, 2003.
[Gra06] C. Graham. Market Share: Relational Database Management Systems by Operating System, Worldwide, 2005”. Gartner Report No: G00141017, May 2006.
[Har06] S. Harizopoulos, V. Liang, D. Abadi, and S. Madden. “Performance Tradeoffs in Read-Optimized Databases.” In Proceedings of the 32nd Very Large Databases Conference (VLDB), 2006.
[Hdf06] http://hdf.ncsa.uiuc.edu/HDF5/
[Mat06] http://www.mathworks.com/
[Mot03] R. Motwani, J. Widom, A. Arasu, B. Babcock, S. Babu, M. Datar, G. Manku, C. Olston, J. Rosenstein, and R. Varma. “Query Processing, Resource Management, and Approximation and in a Data Stream Management System”. In Proceedings of the First Biennial Conference on Innovative Data Systems Research (CIDR 2003), Asilomar, CA, 2003.
[Net06] http://www.unidata.ucar.edu/software/netcdf/
[Ola06] OLAP Market Report. Online manuscript.
[One06] P. O’Neil, E. O’Neil, and X. Chen. “A Star Schema Data Warehouse Benchmark”. Online Manuscript.
[Pik05] R. Pike, S. Dorward, R. Griesemer, S. Quinlan. “Interpreting the Data: Parallel Analysis with Sawzall”. In Scientific Programming Journal, Special Issue on Grids and Worldwide Computing Programming Models and Infrastructure 13:4, pp. 227-298.
[Sar94] S. Sarawagi and M. Stonebraker. “Efficient Organization of Large Multidimensional Arrays”. In Proceedings of the 10th International Conference on Data Engineering (ICDE), 1994.
[Seq93] http://s2k-ftp.cs.berkeley.edu:8000/index.html
[Sto05a] M. Stonebraker and U. Cetintemel. “One Size Fits All: An Idea Whose Time has Come and Gone”. In Proceedings of the International Conference on Data Engineering (ICDE), 2005. См. перевод на русский язык.
[Sto05b] M. Stonebraker, D. J. Abadi, A. Batkin, X. Chen, M. Cherniack, M. Ferreira, E. Lau, A. Lin, S. Madden, E. O’Neil, P. O’Neil, A. Rasin, N. Tran, S. Zdonik. “C-Store: A Column Oriented DBMS”. In Proceedings of the Conference on Very Large Databases (VLDB), 2005.
[Sto76] M. Stonebraker, E. Wong, P. Kreps, and G. Held. “The Design and Implementation of Ingres”. ACM Journal on Transactions on Database Systems (TODS), 1(3), 1976.
[Stre06] http://www.streambase.com/
[Ver06] Vertica Inc.
[Wid05] J. Widom. “Trio: A System for Integrated Management of Data, Accuracy, and Lineage”. In Proc. of the International Conference on Innovative Database Research (CIDR), 2005.