Нечеткое сравнение коллекций: семантический и алгоритмический аспекты
Семенов В.А., Морозов С.В., Тарлапан О.А., Энкович И.В.
Труды Института системного программирования РАН
Работа коллектива поддержана РФФИ (грант 07-01-00427).
Аннотация. Рассматривается задача нечеткого сравнения коллекций в приложениях реконсиляции. Задача возникает при оптимистической репликации структурированных данных и документов и имеет многочисленные приложения в таких актуальных областях, как управление конфигурацией программного обеспечения, управление мобильными базами данных, построение платформ и систем коллективной инженерии. В работе анализируются стандартные типы коллекций языков объектно-ориентированного моделирования, для которых описываются и обосновываются способы представления, журнализации, вычисления, принятия и согласования изменений. Для выделенных типов коллекций дается строгая, семантически содержательная интерпретация конфликтов и предлагаются конструктивные методы их идентификации и разрешения. Примеры иллюстрируют предлагаемые решения, а также служат мотивацией создания универсальной, основанной на модельном представлении оригинальной среды коллективной инженерии с развитыми возможностями семантически корректной и функционально содержательной реконсиляции дивергентных реплик данных.
Содержание
- 1. Введение
- 2. Задача нечеткого сравнения в приложениях семантической реконсиляции
- 3. Классификация коллекций
- 4. Сравнение множеств
- 5. Сравнение мультимножеств
- 6. Сравнение списков
- 7. Сравнение упорядоченных множеств
- 8. Сортированные последовательности
- 9. Последовательности фиксированной длины
- 10. Коллекции с ограниченной мощностью
- 11. Коллекции прямых и инверсных ассоциаций
- Заключение
- Литература
- 2. Задача нечеткого сравнения в приложениях семантической реконсиляции
1. Введение
Сравнение коллекций является одной из традиционных задач сопоставления версий и анализа изменений при оптимистической репликации структурированных данных и документов [1]. Программные средства сравнения, предоставляющие подобную функциональность, являются неотъемлемыми компонентами современных систем контроля версий. Подобные системы нашли применение в задачах управления конфигурацией программного обеспечения (software configuration management), управления мобильными базами данных (mobile database management), организации цифровых архивов, документооборота (document management), построения платформ и систем коллективной инженерии (collaboration workspaces, concurrent engineering environments), управления web–контентом (content management). Так, среди наиболее популярных решений коллективной программной инженерии следует отметить системы управления версиями ПО: CVS, Subversion, OpenCM, BitKeeper, Visual SourceSafe, Perforce, Synergy CM и т.п. [2].
Оформленные в виде программных утилит с пользовательским интерфейсом средства сравнения имеют многочисленные самостоятельные приложения. Например, утилиты командной строки cmp, diff, sdiff, diff3 известного проекта GNU [3] позволяют определить первый отличный байт для заданной пары файлов, вычислить минимальное множество отличий между двумя файлами, интерактивно объединить два файла в один общий, а также представить структуру изменений при одновременной модификации одного файла двумя пользователями или программами и сгенерировать файл, являющийся результатом слияния двух версий относительно базовой с предупреждениями о возникших конфликтах. GNU Diffutils работают преимущественно с текстовыми файлами, для бинарных файлов они могут лишь констатировать факт сходства или различия. Пакет JojoDiff включает набор утилит для сравнения бинарных файлов: jdiff — сравнивает два файла, jpatch — реконструирует второй файл из первого на основе списка изменений, сгенерированного jdiff, jsync — синхронизирует файлы или директории между двумя компьютерами. Приложения KDiff, Xxdiff, gtkdiff, tkdiff, Diffstat, ExamDiff предоставляют средства визуального сравнения произвольных текстовых файлов. Известная утилита UN*X dirdiff позволяет сравнивать деревья каталогов и синхронизировать изменения между ними. Развитые графические средства сравнения текстовых файлов, а также синхронизации директорий включает в себя популярный файловый менеджер TotalCommander.
Перечисленные программные средства производят сравнение произвольных текстовых или бинарных файлов без учета семантики их содержимого. Ряд программных утилит и приложений позволяет сравнивать документы в различных текстовых или бинарных форматах, HTML, XML, Multimedia данные. В частности, учитывая типизацию отдельных термов в текстовых данных, утилита spiff позволяет адекватно сравнивать числовые данные с плавающей точкой, а также исходные тексты на популярных языках программирования. Набор приложений CSDiff/CS-ExcelDiff/CS-HTMLDiff позволяет установить и отобразить изменения документов, представленных в форматах Microsoft Word, Microsoft Excel, HTML. Программы ExamDiff Pro, Compare Suite, Diff Doc поддерживают сравнение документов в различных форматах популярных офисных приложений, PDF, HTML, в том числе документов, хранящихся в архивах. Интегрированные пакеты Microsoft Office 2003 и 2007 имеют развитые встроенные средства сравнения и слияния версий документов. Наборы средств diffxml, 3dm, XMLComparator обеспечивают сравнение, коррекцию и слияние документов в XML разметке. Программы Image Comparer, ImageDupeless специализируются на сравнении графической, а Similarity — звуковой информации, хранимой в файлах наиболее распространенных форматов.
Средства сравнения реляционных данных позволяют определить изменения схем и содержимого популярных баз данных. В частности, программа DataDiff находит отличающиеся записи в альтернативных базах данных под управлением MySQL, утилита mysqldiff — находит отличия в определениях таблиц СУБД MySQL, утилита MDBDiff позволяет выявить структурные изменения в базах данных Microsoft Access, Oracle SchemaDiff — изменения в схемах Oracle, pgdiff — изменения в реляционных таблицах двух баз данных под управлением PostgreSQL с возможной генерацией команд конвертации схемы одной базы данных в другую. Универсальная программа с web-интерфейсом SQLDiff устанавливает и показывает отличия между двумя SQL таблицами для распространенных реляционных СУБД (Oracle, DB2, PostgreSQL).
Ряд программных компонентов сравнения обеспечивает работу с объектными моделями. В частности, библиотека difflib, реализованная на Python, позволяет вычислять изменения в объектных данных. Программный модуль UMLDiff [4], функционирующий в среде программной инженерии Eclipse, определяет структурные изменения статических UML моделей. Более подробные сведения о вышеперечисленных утилитах и библиотеках, а также об аналогичных программных средствах сравнения данных и документов можно найти в Интернет-обзорах и каталогах [5–8].
Несмотря на разнообразие приложений, в которых математические методы и программные средства сравнения находят содержательное применение, следует отметить строгую функциональную специализацию и определенную ограниченность перечисленных выше средств. Главной причиной этого является ориентация на конкретные классы приложений с предопределенной семантикой. Безусловно, подобная направленность делает данные средства чрезвычайно полезными при решении конкретных прикладных задач, однако не дает возможность распространить их на нетривиальные масштабные междисциплинарные информационные модели, описываемые сотнями (иногда тысячами) типами данных и ограничений.
Более того, часто и в простых случаях результаты сравнения оказываются неадекватными решаемой задаче. Например, сравнение документов в разметке XML позволяет идентифицировать изменения, связанные с появлением, удалением, модификацией элементов, однако не фиксирует изменения положения элементов относительно друг друга. Приложения, для которых порядок следования элементов данных существенен, не могут доверительно использовать результаты сравнения. Например, приложение, фиксирующее изменения в рейтинговом списке ученых, упорядоченном в соответствии с показателем результативности научной деятельности, не может корректно интерпретировать результаты сравнения и нуждается в более адекватном способе представления изменений в соответствии с семантикой модели данных.
В обобщенной постановке задача сравнения обычно не рассматривается, хотя все упомянутые выше виды документов, файлов, схем баз данных могли бы быть прозрачно представлены информационными моделями/метамоделями, и их сравнение могло бы быть проведено на более общей методологической и инструментальной основе. Подобная постановка является критично важной для приложений семантической реконсиляции, оперирующих произвольными типами данных при заданной прикладной модели с формально описанными структурой и алгебраическими ограничениями. В подходе, предложенном и развитом в наших работах [9–12], вычисление изменений данных рассматривается в качестве ключевого элемента реконструкции конкурентных транзакций и их семантически согласованной реконсиляции на основе заданной информационной модели. Учет семантики модели позволяет на формальной, математически строгой основе провести сравнительный анализ реплицируемых данных и выработать непротиворечивые (семантически корректные) и содержательные (обеспечивающие полноту итоговой транзакции) политики реконсиляции.
В определенном смысле подход следует важному доминирующему направлению информационных технологий, предполагающему активное использование моделей на всех этапах программной инженерии и анализа информации. Деятельность международных сообществ по разработке соответствующих информационных стандартов и многофакторных прикладных моделей, прежде всего, в рамках ISO 10303 STEP [13] и OMG MDA [14] также следует этой тенденции.
В настоящей работе обсуждаются проблемы сравнения коллекций — стандартных типов данных, поддерживаемых популярными языками моделирования и программирования, повсеместно используемых в приложениях и представляющих собой наиболее сложные и интересные конструкции для рассматриваемых задач реконсиляции. Главным лейтмотивом статьи является вопрос об адекватности способов представления изменений типам коллекций, а также о выборе эффективных алгоритмов нечеткого сравнения коллекций в соответствии с их семантикой.
2. Задача нечеткого сравнения в приложениях семантической реконсиляции
Обсудим особенности постановки задачи нечеткого сравнения коллекций в приложениях семантической реконсиляции. Напомним, что традиционная задача сравнения последовательностей обычно формулируется как задача отыскания минимального скрипта редактирования (последовательности элементарных команд, обеспечивающей преобразование исходной строки в заданную другую строку) [20, 21]. Множество найденных команд при соответствующей интерпретации может служить представлением изменений, внесенных в модифицированную версию коллекции относительно исходной. Отыскание наибольшей подпоследовательности также решает задачу нечеткого сравнения и позволяет представить изменения модифицированной коллекции в виде добавленных и удаленных фрагментов строк, дополняющих найденную общую подпоследовательность до заданных строк.
В отличие от традиционных постановок задач сравнения последовательностей, приложения реконсиляции оперируют с произвольными типами коллекций, и для адекватной реконструкции изменений требуется детальный семантический анализ. Другой важной особенностью рассматриваемой постановки является необходимость декомпозиции долгих транзакций на группы операций, которые могли бы быть представлены и применены независимым друг от друга образом. Это означает, что в ходе реконсиляции одна часть выявленных изменений может быть принята в итоговом представлении при отмене другой без каких-либо дополнительных ограничений. Выбранный базис элементарных операций должен удовлетворять данному требованию.
Итак, пусть ![]() — некоторые
версии коллекции элементов типа T, причем
— некоторые
версии коллекции элементов типа T, причем ![]() — базовая версия, а
— базовая версия, а ![]() ,
, ![]() — версии,
полученные в результате ее одновременной модификации в двух параллельных
ветвях. Задача реконсиляции в наиболее распространенной постановке заключается
в вычислении соответствующих изменений модифицированных версий относительно
базовой
— версии,
полученные в результате ее одновременной модификации в двух параллельных
ветвях. Задача реконсиляции в наиболее распространенной постановке заключается
в вычислении соответствующих изменений модифицированных версий относительно
базовой ![]() ,
, ![]() и в
консолидации изменений
и в
консолидации изменений ![]() таким образом,
чтобы сформировать итоговое представление коллекции
таким образом,
чтобы сформировать итоговое представление коллекции ![]() как результат применения
согласованных изменений к
базовой версии. Это, так называемая, классическая “3-way Merge” схема реконсиляции в отличие от
схем “2-way Merge” и “4-way Merge”, имеющих более узкое применение [15, 16].
как результат применения
согласованных изменений к
базовой версии. Это, так называемая, классическая “3-way Merge” схема реконсиляции в отличие от
схем “2-way Merge” и “4-way Merge”, имеющих более узкое применение [15, 16].
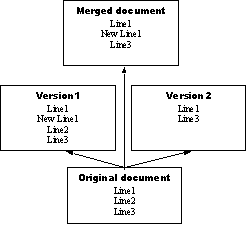
Рис. 1. Пример консолидации изменений в итоговом текстовом документе
Например, если при одновременной модификации текстового файла в ходе выполнения одной транзакции была вставлена новая строка, а в ходе выполнения другой транзакции одна из строк была удалена, результатом консолидации изменений должен стать итоговый документ с внесенными общими изменениями (см. рис. 1), дополняющий его существующие версии новым согласованным вариантом.
Корректная идентификация изменений и реализация функции
исполнения предполагают, что соответствующие тождества ![]() ,
, ![]() необходимо удовлетворены.
необходимо удовлетворены.
Тривиальными случаями реализации функции реконсиляции
являются ![]() ,
, ![]() и
и ![]() , приводящие к уже известным версиям коллекции
, приводящие к уже известным версиям коллекции ![]() ,
, ![]() и
и ![]() соответственно.
Содержательная реализация функции реконсиляции
соответственно.
Содержательная реализация функции реконсиляции ![]() нетривиальна,
поскольку
нетривиальна,
поскольку ![]() ,
, ![]() могут представлять собой
иерархически структурированные изменения
могут представлять собой
иерархически структурированные изменения ![]() ,
, ![]() ,
, ![]() ,
, ![]() и т.д. По существу, дельты
и т.д. По существу, дельты ![]() ,
, ![]() являются реконструируемым
представлением конкурентных транзакций, примененных к исходным данным
являются реконструируемым
представлением конкурентных транзакций, примененных к исходным данным ![]() и имеющих результатом
и имеющих результатом ![]() и
и ![]() соответственно. В силу указанных причин
реализация данной функции должна обеспечивать консолидацию как можно большего
числа изменений при условии сохранения частичного порядка операций,
индуцируемого семантикой приложений, и их бесконфликтности. В случаях, когда
все конфликты разрешаются путем принятия изменений из первой версии, функция
реконсиляции строится следующим образом:
соответственно. В силу указанных причин
реализация данной функции должна обеспечивать консолидацию как можно большего
числа изменений при условии сохранения частичного порядка операций,
индуцируемого семантикой приложений, и их бесконфликтности. В случаях, когда
все конфликты разрешаются путем принятия изменений из первой версии, функция
реконсиляции строится следующим образом:
![]() ,
,
где логическая функция ![]() истинна в
случае конфликта между изменениями
истинна в
случае конфликта между изменениями ![]() ,
, ![]() . Является открытым вопрос о
том, какие ситуации следует считать конфликтными, и каким
образом они могут быть разрешены: отменой всех операций, выделением и принятием
бесконфликтного подмножества операций, или путем их коррекции.
. Является открытым вопрос о
том, какие ситуации следует считать конфликтными, и каким
образом они могут быть разрешены: отменой всех операций, выделением и принятием
бесконфликтного подмножества операций, или путем их коррекции.
В дальнейшем под конфликтом будем понимать бинарное или
множественное отношение между наборами или последовательностями операций в
конкурентных транзакциях ![]() ,
, ![]() , одновременное принятие которых приводит к
некорректной интерпретации операций и неоднозначности результата, или к нарушению
семантических ограничений, накладываемых на результирующее представление данных
, одновременное принятие которых приводит к
некорректной интерпретации операций и неоднозначности результата, или к нарушению
семантических ограничений, накладываемых на результирующее представление данных ![]() , где
, где ![]() .
.
Стандартный
способ разрешения конфликта состоит в принятии одной из опций ![]() . При условии, что оригинальные транзакции приводят к корректным версиям
. При условии, что оригинальные транзакции приводят к корректным версиям ![]() и
и ![]() , а принимаемые операции не конфликтуют друг с другом, результирующая
транзакция также будет корректна. В случае выявления конфликтов они разрешаются
вплоть до достижения корректности итоговой транзакции. Заметим, что решение
всегда существует, поскольку в качестве итоговой транзакции могут быть приняты
, а принимаемые операции не конфликтуют друг с другом, результирующая
транзакция также будет корректна. В случае выявления конфликтов они разрешаются
вплоть до достижения корректности итоговой транзакции. Заметим, что решение
всегда существует, поскольку в качестве итоговой транзакции могут быть приняты ![]() ,
, ![]() или
или ![]() . Однако более содержательным была бы консолидация операций из обеих
конкурентных транзакций.
. Однако более содержательным была бы консолидация операций из обеих
конкурентных транзакций.
Важной особенностью задачи нечеткого сравнения коллекций в
приложениях реконсиляции является учет частичного порядка между операциями.
Например, если при одновременном редактировании текста в одну и ту же позицию
были добавлены отличные строки, то конфликт связан не с нарушением какого-либо
ограничения для результирующего документа, а с неоднозначностью исполнения
соответствующих операций ![]() ,
, ![]() и с неопределенностью
ожидаемого результата
и с неопределенностью
ожидаемого результата ![]() . Возможным способом разрешения конфликта в данном
случае являлась бы одна из опций:
. Возможным способом разрешения конфликта в данном
случае являлась бы одна из опций: ![]() , где символ
, где символ ![]() означает отношение
предшествования между исполняемыми операциями. Результатом может стать исходный документ, одна из
его модифицированных версий либо документ с двумя возможными вариантами вставки
строк (см. рис. 2). Заметим, что совпадение добавленных строк в обеих
версиях модифицируемого документа не приводит к конфликту, и вариантами
реконсиляции являются тривиальные решения
означает отношение
предшествования между исполняемыми операциями. Результатом может стать исходный документ, одна из
его модифицированных версий либо документ с двумя возможными вариантами вставки
строк (см. рис. 2). Заметим, что совпадение добавленных строк в обеих
версиях модифицируемого документа не приводит к конфликту, и вариантами
реконсиляции являются тривиальные решения ![]() , приводящие к уже существующим версиям документа.
, приводящие к уже существующим версиям документа.

Рис. 2. Пример многовариантной реконсиляции с учетом частичного порядка операций редактирования текстового документа
Приведем вариант предыдущего примера редактирования текстового документа, иллюстрирующего важность учета семантики модели данных при дополнительном ограничении уникальности элементов коллекции. Предположим, что документ представляет собой персонофицируемый список имен, формируемый путем согласования альтернативных рейтинговых показателей в параллельных версиях (см. рис. 3).
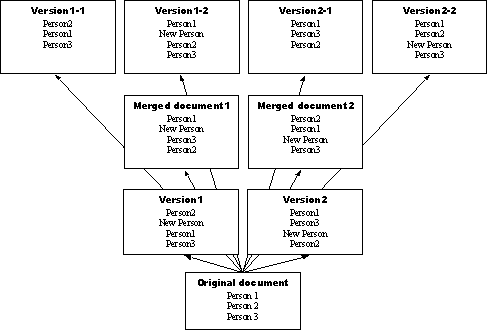
Рис. 3. Пример многовариантной реконсиляции с учетом семантики модели коллекции
В
первой модифицируемой версии документа между персонами на первых двух позициях
вставляется новое имя, после чего меняется порядок их следования. Дельта
представляется следующим образом: ![]() , где
, где ![]() — операция вставки нового элемента
в соответствующую позицию коллекции, а
— операция вставки нового элемента
в соответствующую позицию коллекции, а ![]() — операция транспозиции пары
элементов в заданных позициях коллекции. Во второй версии документа то же самое имя вставляется на
позицию между последними персонами, а также меняется порядок их следования:
— операция транспозиции пары
элементов в заданных позициях коллекции. Во второй версии документа то же самое имя вставляется на
позицию между последними персонами, а также меняется порядок их следования: ![]() . Заметим, что
изменение порядка следования элементов коллекции и вставка новых элементов
согласно репродуцируемой семантике множества не должна приводить к дублированию
имен в итоговом документе. Поэтому семантически корректными являются результаты
. Заметим, что
изменение порядка следования элементов коллекции и вставка новых элементов
согласно репродуцируемой семантике множества не должна приводить к дублированию
имен в итоговом документе. Поэтому семантически корректными являются результаты ![]() , приводящие, соответственно, к оригинальным версиям Original document, Version1, Version2,
версиям Version1-1, Version1-2, Version2-1, Version2-2, полученным частичным принятием
операций одной из транзакций, и версиям документа Merged document1, Merged document2, полученным возможной консолидацией операций из двух конкурентных
транзакций.
, приводящие, соответственно, к оригинальным версиям Original document, Version1, Version2,
версиям Version1-1, Version1-2, Version2-1, Version2-2, полученным частичным принятием
операций одной из транзакций, и версиям документа Merged document1, Merged document2, полученным возможной консолидацией операций из двух конкурентных
транзакций.