Решения "растут" на деревьях
Рон Хардман
Оригинал: Decisions Grow on Trees,
By Ron Hardman, Oracle Magazine March/April 2007
Перевод: Oracle Magazine - Русское издание (Июль-Август 2007)
[От редакции OM/RE: Корпорация Oracle последовательно развивает свои продукты класса Data Mining (принятый русский перевод этого термина - "глубинный анализ данных" - см. http://www.rdtex.ru/docs/glossary), наращивая их функциональность и делая их более "дружественными" и легкими в использовании. Чтобы эффективно эти продукты, необходимо понимание методов Data Mining. Помимо материалов корпорации Oracle на эту тему, уже есть немало материалов и на русском языке, в частности в Интернете, которые легко найти через поисковые системы.
Одним из наиболее понятных методов Data Mining являются деревья решений. Поддержка этого метода недавно была реализована в продукте Oracle Data Miner и она рассматривается в данной статье.]
Деревья решений в Oracle Data Miner: классификация и анализ данных
Вы когда-нибудь размышляли о том, кто из ваших потенциальных покупателей c высокой степенью вероятности станут вашими реальными покупателями, или кто обеспечит наиболее доходные сделки? На кого вы должны нацеливаться в своей маркетинговой компании и что будет важным для них, когда они начнут звонить? Какие продукты, версии продуктов, предоставят вашим клиентам то, что им нужно, а какие нет и, тем самым, негативно отразятся на вашей компании? Oracle Data Miner поможет перебросить мост между вопросами бизнеса, такими как эти, и техническими и статистическими задачами, которые имеют отношение к "раскопкам" (mining) данных для ответов.Oracle Data Miner может проанализировать существующий набор данных из вашего хранилища данных и классифицировать те данные, которые определяют или прямо соотносятся с желаемым результатом или целью. Конкретнее, при классификации данных (data classification) обнаруживаются patterns (паттерны, шаблоны) и отношения с целью группирования подобных записей для последующего более легкого и эффективного анализа. В этой статье рассматривается один конкретный тип классификации, называемый decision trees (деревья решений).
Деревья решений
Хотя многие задачи data mining резервируются за аналитиками данных, бизнес-пользователи, похоже, чувствуют себя комфортно с деревьями решений. Эти деревья логичны, хорошо воспринимаются визуально, и результат может быть объяснен в типичных бизнес-терминах.Использование дерева решений - это способ классификации существующих данных, определения факторов или правил, которые имеют отношение к целевому результату (target result), и их применения для прогнозирования результата, что означает:
- Бизнес-пользователи могут определять факторы, которые в наибольшей степени влияют на решения о покупках;
- Департаменты маркетинга могут "целиться" в "правильные" группы потенциальных клиентов, исключая тех, кто с малой вероятностью будет покупать;
- Аналитики данных и финансовые аналитики могут прогнозировать продажи благодаря анализу атрибутов потенциальных клиентов, о которых есть данные;
- Бизнес-аналитики могут корректировать цели и стратегии при изменениях тенденций;
- Компании могут реорганизовывать поддержку (support, enhancements, and desupport) для обеспечения максимального удовлетворения клиентов
И не нужно быть доктором философии (PhD) в математике, чтобы использовать и понимать деревья решений. Чтобы проиллюстрировать это, я проанализирую одну бизнес-задачу:
Производитель предлагает два продукта, A и B. В целом отзывы потребителей были положительны, но владелец предприятия-производителя хочет узнать, что-то можно изменить в поддержке, что может повысить уровень удовлетворения потребителей. У предприятия есть весьма ограниченная информация о своих потребителях, включая только данные о продукте, который они используют, его версии и времени получения его последней модификации.
С использованием этой информации, полученной от выборки по клиентской базе (sample customer population), и Oracle Data Miner это предприятие может создать модель дерева решения, показанную на рис. 1.
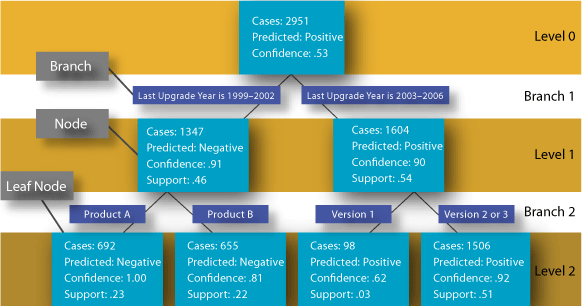
Рис. 1: Дерево решений
Каждый прямоугольник в дереве на рис. 1 называется узлом (node) и каждая линия называется веткой (branch) или ребром. Верхний прямоугольник в дереве (или его корень (root)) включает все значения (all cases) этой выборки.
Дерево решений разделяет данные по атрибутам в попытке определить лучших предсказателей (predictors) целевого значения (target value). Эти предсказатели формируют правило (rule) или набор правил, которые будучи применены к узлу, сформируют результат. Вы можете думать о них, как о предложениях IF-THEN для принятия решений.
Oracle Data Miner анализирует все атрибуты в наборе данных. Если, к примеру, в данном наборе данных три атрибута, то Oracle Data Miner анализирует эти три атрибута. Если же атрибутов 80, то Oracle Data Miner анализирует все эти 80 атрибутов. Он определяет атрибут для первого расщепления (split) дерева решения, которое наилучшим образом делит целевые данные (target data) на различные секции.
С эти набором данных, разделенным надвое, Oracle Data Miner может определить атрибуты для расщеплений на следующем уровне. Обратите внимание, что на рис. 1 Oracle Data Miner расщепил ветви 2-го уровня по разным атрибутам.
К последнему ряду узлов ссылаются как к терминальному узлу или листу (terminal node, or leaf). Вполне возможно продолжить анализ далее, чем изображено на рис. 1, но в данном случае два уровня были выбраны как максимум.
Как начать работать с Oracle Data Miner
Oracle Data Miner позволяет легко генерировать деревья решений. Чтобы показать это, я сгенерирую дерево решения на рис. 1. Для этого нужно скачать и установить Oracle Data Miner и выполнить следующие шаги по подготовке вашего источника данных для данного примера:1. Скачать sample data file.
2. Раскрыть (Unzip) содержание (contents), открыть подсказку и перейти (cd) к директории, содержащей скрипт create_user.sql.
3. Подключиться (Log in) к SQL*Plus под именем SYSDBA, и выполнить скрипт create_user.sql.
Этот скрипт создает пользователя SURVEYS с паролем SURVEYS, и предоставляет ему все необходимые полномочия (permissions). Он соединяется с SURVEYS, создает таблицу CUSTOMER_SATISFACTION и вносит в нее 4920 записей. Структура этой таблицы показана в Listing 1.
Code Listing 1: Описание таблицы CUSTOMER_SATISFACTION
SQL> desc CUSTOMER_SATISFACTION CUSTOMER_SATISFACTION_ID NOT NULL NUMBER(10) PRODUCT VARCHAR2(100) VERSION NUMBER(2) LAST_UPGRADE_YEAR VARCHAR2(4) FEEDBACK VARCHAR2(10)
Данные хранятся в этой таблице следующим образом:
- CUSTOMER_SATISFACTION_ID - это первичный ключ и, следовательно, уникальный идентификатор.
- PRODUCT - может быть A или B.
- VERSION - это 1, 2 или 3.
- LAST_UPGRADE_YEAR - это год последней модификации в диапазоне 1999-2006.
- FEEDBACK - это либо POSITIVE (положительно), либо NEGATIVE (отрицательно).
Чтобы запустить Oracle Data Miner, найдите bin-директорию, в которую вы распаковали этот скачанный продукт, и дважды нажмите по odminerw.exe. Предоставьте информацию о соединениях в схеме SURVEYS (SURVEYS/SURVEYS), когда появится соответствующая подсказка, и нажмите OK, чтобы сохранить детали соединений. Нажмите OK еще раз, чтобы соединиться и показать интерфейс Oracle Data Miner (см. рис. 2).
Рис. 2: Интерфейс Oracle Data Miner с выбранной таблицей CUSTOMER_SATISFACTION
Отметим, таблица CUSTOMER_SATISFACTION с данными выборки показана справа. Вы можете позднее посмотреть эту таблицу, нажав SURVEYS -> Data Sources -> Tables-> CUSTOMER_SATISFACTION.
Выполните следующие шаги для создания деревьев решений:
- В меню Activity выберите пункт Build.
- Первый экран мастера (wizard) содержит общую информацию. Нажмите Next.
- На шаге 1 из 5: Тип модели (Model Type), оставьте Function Type (тип функции) как Classification (классификация) и Algorithm (алгоритм) как Decision Tree. Нажмите Next. В продукте Oracle Data Miner классификация - это тип функции, или категория алгоритмов, относящихся к классификации, а дерево решений - это алгоритм, который принадлежит данному типу функций.
- На шаге 2 из 5: Данные (Data), удостоверьтесь, что выбранная схема - это SURVEYS и таблица/представление (table/view) - это CUSTOMER_SATISFACTION. Если они еще не выбраны, выберите их из списка. Уникальный идентификатор является в этом случае единственным значением. Удостоверьтесь, что выбран первичный ключ МCUSTOMER_SATISFACTION_ID. В секции Select Columns выберите все столбцы. Нажмите Next.
- На шаге 3 из 5: Использование данных (Data Usage), выберите все колонки, кроме CUSTOMER_SATISFACTION_ID, как ввод и выберите FEEDBACK как назначение. Нажмите Next. Столбец FEEDBACK в таблице содержит ответ как POSITIVE или NEGATIVE. Oracle Data Miner проанализирует этот двоичный ответ применительно ко всем атрибутам, чтобы определить те из них, которые влияют на отзывы клиентов в наибольшей степени.
- На шаге 4 из 5: Для выбора Preferred Target Value, выберите Negative. Нажмите Next. (Это значение может быть изменено в любой момент.) Выбор Negative настраивает Oracle Data Miner на поиск решений, результатом которых является отрицательный ответ, и дерево решений будет структурировано в соответствии с этим.
На шаге 5 из 5: Имя действия (Activity Name), измените имя на CUSTOMER_SAT_1 (увеличьте последнее число, если вы повторно выполняете это действие). Нажмите Next. - В шаге Finish оставьте выбранную опцию Run upon finish и нажмите Finish для начала этого процесса.
На этом этапе Oracle Data Miner определяет лучшие расщепления атрибутов, строит модель и тестирует правила, которые сгенерированы с этим набором данных. Рисунок 3 показывает шаги-действия (activity steps).
Рис. 3: Шаги-действия классификации CUSTOMER_SAT_1 classification activity steps
Щелкните Result link в Build activity, чтобы увидеть дерево решений, показанное на рис. 4. Отметим, что вы можете контролировать число показываемых уровней узлов. Чтобы увидеть расщепления и ветви, показанные на рис. 1, покажите только два уровня.
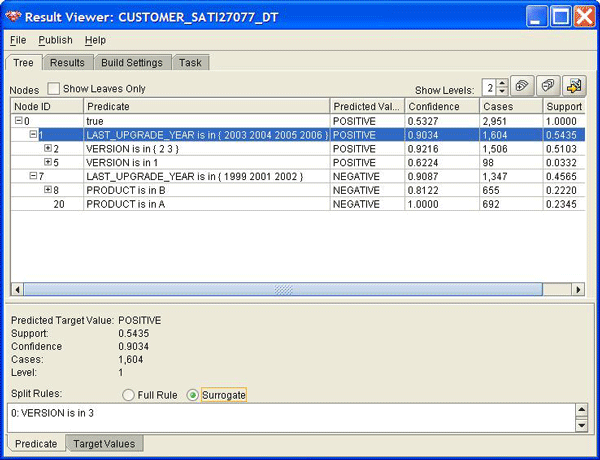
Рис. 4: Result Viewer показывает правила расщепления
Результаты на рис. 4 те же самые, что и на рис. 1. Отметим, что первое расщепление или ветвление имеет место на атрибуте Last Upgrade Year (год последней модификации). Если Last Upgrade Year больше или равен 2003, то ответ положителен с 90% уверенности. Отметим, что число значений в данном случае равно 1604 из 2951 в корне. Это примерно 54% от общего числа. Если Last Upgrade Year меньше или равен 2002, ответ предсказывается отрицательным с 91% уверенности. В этом случае в узле 1347 значений, что составляет 46% от общего числа.
Из 4-х узлов 2-го уровня один показывает, что клиенты, использующие версии 2 или 3 продукта A или B, к которым они перешли между 2003 и 2006, с 92% уверенности высказывают положительное мнение о продукте. Другой же узел показывает, что клиенты, использующие продукт A, к которому они перешли между 1999 и 2001, будут, как предсказывается, отрицательно относиться к этому продукту. Безусловно, эта информация будет полезной при планировании поддержки.
Но, очевидно, возможны варианты, когда значение атрибута неопределенно (null) для некоторых записей. Что тогда? Oracle Data Miner определяет не только отношения атрибутов к цели, но и их взаимные отношения. Обратите внимание на секцию Split Rules внизу рис. 4. она показывает замещающее (surrogate) значение для узла ID 1. Если для некоторой записи нет значения Last Upgrade Year, то Oracle Data Miner все-таки включит эту запись в этот узел, если версия 3. Oracle Data Miner определяет это автоматически, не требуя явного задания чего-либо.
Применение построения дерева решений
Чтобы увидеть, как построение этого дерева решений будет применено к индивидуальных записям, откройте результаты построения еще раз, переходя к Mining Activities -> Classification, выбирая CUSTOMER_SAT_1, нажимая Result link в Build activity, и нажимая Show Leaves Only в верху окна Result Viewer. С каждым листом ассоциируется правило расщепления, которое появляется внизу данного окна, если щелкнуть по соответствующему узлу.Например, последний лист (Node ID = 20 на Рис. 4) предсказывает отрицательный ответ со 100% уверенностью. Нажмите этот узел и следующее правило расщепления появится внизу:
PRODUCT is in A AND
LAST_UPGRADE_YEAR is
in { 1999 2001 2002 }
Для любой записи, соответствующей этому правилу, будет предсказан отрицательный ответ со 100% уверенностью.
Данные о клиентах, не попавших в выборку, хранятся в таблице CUSTOMER_SATISFACTION_NEW. Все колонки содержат значения, кроме FEEDBACK. Чтобы обнаружить, какие ответы, положительные или отрицательные, будут получены, применим правила построения CUSTOMER_SAT_1, следующим образом:
- Откройте главное окно Oracle Data Miner и выберите Activity -> Apply из главного меню.
- Первая страница для приветствий. Нажмите Next.
- На шаге 1 из 5: Создать действие (Build Activity), выберите CUSTOMER_SAT_1. Нажмите Next.
- В шаге 2 из 5: Примените данные (Apply Data), нажмите Select link вправо от таблицы и перейдите к SURVEYS -> CUSTOMER_SATISFACTION_NEW. Нажмите Next.
- В шаге 3 из 5: Дополнительные атрибуты (Supplemental Attributes), выберите только колонку CUSTOMER_SATISFACTION_ID. Нажмите Next.
- На шаге 4 из 5: Примените Опцию (Apply Option), Оставьте значения по умолчанию (default settings). Нажмите Next.
- На шаге 5 из 5: Дайте имя действию (Activity Name), назовите его CUSTOMER_SAT_APPLY_1. Нажмите Next.
- Нажмите Finish.
Когда это действие завершится, нажмите Result link в окне действий (activity window), чтобы увидеть предсказанное значение; вероятность, связанную с этим предсказанием; и стоимость (cost), которая похожа на ранжирование вероятностей, за исключением того, что меньшая стоимость означает лучшее предсказание.
Oracle Data Miner позволяет также увидеть, какие правила были использованы для каждой записи. Нажмите одну из записей, а затем Rule button справа от результатов. Просмотрщик правил Rule Viewer появится, как показано на рис. 5.
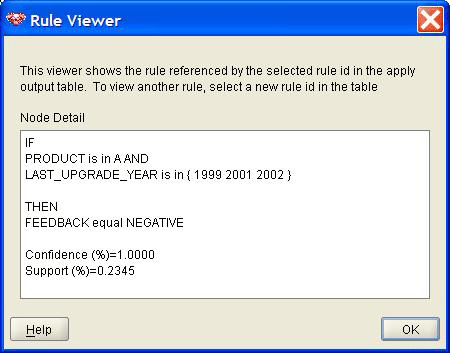
Рисунок 5: Просмотрщик правил Rule Viewer
Правовая оговорка о статистике
Одна из первых книг по бизнесу и статистике, которые я прочитал, называлась "Как врать, используя статистику" (How to Lie With Statistics), Даррелла Хаффа (Darrell Huff). Нет, это не учебник по тому, что заявлено в названии. Наоборот, в этой книжечке рассматривались распространенные ошибки, приводящие к неверным выводам, при применении статистического анализа - и не из-за ошибочных вычислений, а вследствие неправильных определений проблем, неаккуратных или неполных данных. Поиск смысла там, где его нет, и пропуск смысла там, где есть хоть какой-то, поиск неверного смысла в неверных статистических данных, все это обсуждается (в книге). Следующий полностью вымышленный пример показывает такой тип анализа:Люди с ростом более 2.25 метра намного менее вероятно пострадают в автоаварии, чем менее высокие . . . и заголовки новостей по всей стране кричат, "Исследование подтверждает, что действительно высокие люди намного сильнее и более стойки, чем невысокие."
А не могло ли дело обстоять так, высокие люди скорей чаще всего пользуются большими автомашинами? Либо вместо процентов при формировании статистики использовались "сырые" (raw) числа? Как много людей в группе очень высоких, особенно в сравнении с группой невысоких?
Oracle Data Miner легко выполняет анализ данных в части математики и программирования, но определение проблемы, отбор данных и корректное применение результатов целиком остается на пользователе. Но если проблема определена правильно, вы можете положиться на результаты.
Заключение
Деревья решений полезны для бизнес-пользователей, так как предоставляют логический результат, который можно обсуждать в бизнес-терминах. Они просто создаются с применением Oracle Data Miner, и очень эффективны и точны при обеспечении хорошим набором данных. Они могут предложить прогнозы с соответствующими вероятностями и единое место для просмотра прогнозов, вероятностей и правил, "стоящими" за этими прогнозами.Рон Хардман (Ron Hardman) работает со школами Academy District 20 в Colorado Springs, Colorado, и является основателем компании 5-Mile Software. Он соавтор книг Oracle Database 10g PL/SQL Programming и Expert PL/SQL, вышедших в Oracle Press, и консультант Oracle ACE.