Ориентированные на приложения методы хранения XML-данных
Максим Гринев, Иван Щеклеин
Труды Института системного программирования РАН
Содержание
- 1. Введение
- 2. Мотивирующие примеры
- 3. Описание подхода
- 2. Мотивирующие примеры
- 4. Представление данных физического уровня
- 5. Близкие работы
- 6. Заключение и будущие работы
- Литература
- 5. Близкие работы
1. Введение
Модель данных XQuery [1] является стандартной моделью данных для работы со слабоструктурированными данными, представленными в формате XML. Поддержка слабоструктурированных данных делает эту модель достаточно универсальной и пригодной для преставления данных различной степени структурированности от регулярных реляционных данных до текстовых документов с размытой структурой.
Оборотной стороной такой универсальности является достаточно низкая эффективность существующих реализаций. На сегодняшний день уже сложился ряд подходов [2, 3, 4, 5] к реализации модели данных, но каждый из этих подходов обладает очевидными преимуществами и недостатками, что делает эти подходы применимыми только для достаточно узких классов приложений. Более того, модель данных XQuery поддерживает возможности, которые являются избыточными для каждого конкретного вида приложения.
Например, предположим, что приложение использует XML для представления реляционных данных. Запросы к таким данным обычно не требуют поддержки таких возможностей модели данных как братские (sibling) и родительские (parent) оси или порядок узлов в документе (document order).
Другой пример – это запросы к контент-ориентированным XML-данным, таким как энциклопедические статьи [7] или текстовый документ, представленный в формате Microsoft Word XML [6]. Зачастую такие запросы не адресуют XML-элементы, предназначенные для описания способов визуализации данных (примеры такие элементов: para, bold, emphasize и другие, которые составляют, как правило, большую часть элементов в документе), но адресуют семантически значимые элементы, такие как author, дата, библиография. Следовательно, элементы визуализации могут быть представлены на уровне хранения в сжатом незапрашиваемом виде для увеличения скорости операций модификации и сериализации XML данных (под сериализацией здесь и далее мы понимаем процесс трансляции внутреннего представления данных в строковое представление, соответствующее формату XML).
Приведенные выше рассуждения позволяют нам прийти к выводу, что эффективное внутреннее представление и обработка XML-данных не могут быть достигнуты с использованием какого-либо общего подхода. По нашему мнению, единственно возможным подходом, способным обеспечить высокую эффективность для такой универсальной модели данных, является выбор способов внутреннего представления и методов обработки данных под потребности конкретного приложения. При этом достаточной информацией для описания потребностей является схема XML-данных и рабочая нагрузка в виде возможных запросов и операций модификации данных.
То есть мы предлагаем пойти дальше построения планов выполнения запросов при фиксированных структурах хранения данных, как это делается в большинстве современных систем управления XML-данными, и, кроме того, выбирать структуры хранения данных, необходимые для эффективного выполнения запросов и модификаций для данного приложения. Такой подход позволит поддерживать XQuery модель данных на логическом уровне, но избежать излишних накладных расходов на физическом уровне хранения данных.
С использованием такого подхода можно добиться эффективности обработки регулярных реляционных данных в формате XML, сопоставимой с эффективностью, которая обеспечивается реляционными базами данных. При этом контент-ориентированные данные будут обрабатываться с эффективностью, сопоставимой с эффективностью систем хранения текстовых документов. В данной статье мы описываем наши первые результаты по разработки таких методов хранения и обработки XML-данных.
Статья имеет следующую структуру. В следующем разделе мы рассматриваем примеры, демонстрирующие преимущества предлагаемого подхода. В разд. 3 дается обзорное описание подхода. В разд. 4 описывается физическое представление данных и иллюстрируется на примерах. Разд. 5 посвящен обзору близких работ и существующих подходов хранения XML-данных. В заключительном, шестом разделе мы намечаем пути дальнейших исследований.
2. Мотивирующие примеры
Для демонстрации основных преимуществ и различных аспектов предлагаемого подхода мы выбрали упрощенную версию приложения, которое используется для создания электронной версии Большой Российской Энциклопедии (БРЭ) [7]. Иллюстрации 1 и 2 показывают фрагменты XML-документа, содержащего статью энциклопедии, и его описывающей схемы соответственно. По определению [9] описывающая схема содержит ровно один путь для каждого пути в документе, и каждый путь в описывающей схеме является путем хотя бы в одном из документов. В этом примере документ представляет собой том энциклопедии, который содержит, по крайней мере, три статьи. Каждая статья состоит из заголовка, списка авторов и тела, которое содержит текст статьи.
<volume>
<article id="2">
<title>Cyclotron resonance</title>
<authors>
<author>Century S.Edelman.</author>
<author>I. Kaganov</author>
</authors>
<body>
<p>
<b>Cyclotron resonance</b> Selective absorption of electromagnetic...
<link idref="1">Effective weight</link>
<p> ... <i> ... </i> ... <b> ... </b> ... </p>
<link idref="6">Lorentz force</link>...
</p>
</body>
</article>
...
<article id="3">
<title>Dorfman Jacob Grigorevich</title>
<authors>
<author>I. Ivanov</author>
</authors>
<body>
<p>
<b>Dorfman Jacob Grigorevich</b> the Soviet physicist, the doctor...
<link idref="2">Cyclotron resonance</link>
... <i> ... </i>...
</p>
</body>
</article>
...
<article id="1">
<title>Effective weight</title>
<authors>
<author>I. Kaganov</author>
</authors>
<body> ... </body>
</article>
</volume>
Рис. 1. Фрагмент Большой Российской Энциклопедии.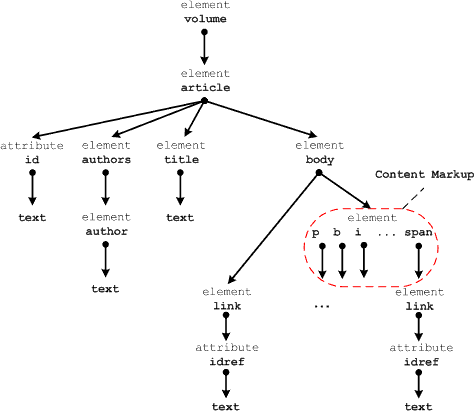
Рис. 2. Описывающая схема Большой Российской Энциклопедии
Для обработки энциклопедии в приложении используются набор запросов, которые являются предопределенными и могут изменяться только при переходе к новой версии системы. Ниже приводится список основных запросов.
(Q1) Получение списка названий статей
declare ordering unordered; volume/article/title
(Q2) Получение статьи по идентификатору
declare ordering unordered; volume/article[@id eq “...”]
(Q3) Получение статьи по названию
declare ordering unordered; volume/article[title eq “...”]
(Q4) Перечислить названия статьей, на которые ссылается статья с идентификатором равным 1
declare ordering unordered; for $i in volume/article [@id eq “1”]//link return volume/article [@id eq $i/@idref]/title
(Q5) Перечислить звания статей, которые ссылаются на статью с названием «Атом»
declare ordering unordered; let $j := volume/article [title eq “atom”]/@id for $i in volume/article where $i//link[@idref eq $j] return $i/title
Рассматривая этот пример, мы можем выделить несколько интересных моментов, которые являются общими для многих приложений.
- Элементы визуализации. Контент-ориентированные XML документы часто содержат большое количество XML-элементов, которые обрабатываются исключительно front-end-приложениями (такими как браузер или текстовый процессор) при отображении документа. В приведенном выше примере к таким элементам относятся p, i, b. Такие элементы, как правило, не адресуются запросами. Однако при хранении XML-документов с использование любого общего подхода такие элементы будут представляться таким же образом, как и семантически значимые элементы.
- Реляционные данные. Помимо элементов визуализации в приведенном примере можно выделить элементы и атрибуты с простыми значениями (например, атрибуты id, idef и title element), которые адресуются запросами. При этом значения этих элементов и атрибутов используются только как промежуточные данные при вычислении запросов в том смысле, что это эти элементы не извлекаются сами по себе, а только как часть другого элемента (например, атрибут id используется для нахождения статьи и извлекается из базы данных только как часть статьи).
- Порядок узлов документа (document order). По умолчанию результат вычисления запроса неявно сортируется в порядке узлов в документе. Однако очень часто этот порядок не имеет никакого значения для приложения. Например, в рассматриваемом примере не имеет смысла взаимный порядок следования названия статьи и авторов. В приведенных запросах неявная сортировка выключается в прологе.
- Известные наперед запросы (рабочая нагрузка). В приведенном приложении все запросы известны еще на этапе его создания, то есть система не поддерживает ad hoc запросов к данным. Это позволяет нам, в частности, построить список путевых выражений, которые составляют основу всех этих запросов: volume/article, volume/article/link, volume/article/title.
Далее в статье мы покажем, как приведенные выше соображения могут быть использованы для выбора структур хранения и планов выполнения запросов.