Оценка протоколов управления распределенными транзакциями
Ричард Хардинг, Дана Ван Акен, Эндрю Павло, Майкл Стоунбрейкер
Перевод: С.Д. Кузнецов
An Evaluation of Distributed Concurrency Control
Rachael Harding MIT CSAIL, rhardin@mit.edu, Dana Van Aken, Carnegie Mellon University, dvanaken@cs.cmu.edu, Andrew Pavlo, Carnegie Mellon University, pavlo@cs.cmu.edu, Michael Stonebraker, MIT CSAIL, stonebraker@csail.mit.edu
Proceedings of the VLDB Endowment, Vol. 10, No. 5, 2017, pp. 553-564
Аннотация
Возрастающее число обрабатываемых транзакций привело к возрождению интереса к распределенной обработке транзакций. В частности, разделение данных между несколькими серверами может повысить пропускную способность за счет параллельной обработки транзакций этими серверами. Но параллельное выполнение транзакций несколькими серверами ограничивает масштабируемость и производительность таких систем.
В этой статье мы количественно оцениваем влияние распределенности на протоколы управления параллельным выполнением транзакций в распределенной среде. Оцениваются шесть классических и современных протоколов в инфраструктуре Deneva, предназначенной для сравнения распределенных систем управления базами данных с хранением данных в основной памяти (in-memory СУБД). Протоколы сравниваются каждый с каждым. Результаты демонстрируют наличие строгих ограничений на распределенные системы обработки транзакций. Кроме того, в ходе анализа мы устанавливаем наличие нескольких узких мест у конкретных протоколов. В заключение статьи мы утверждаем, что для достижения истинной масштабируемости механизмы распределенного управления параллелизмом должны быть более тесно связаны с новыми сетевыми аппаратными средствами (локальных сетей) или приложениями.
1. Введение
Объемы генерируемых и запрашиваемых данных превышают возможности односерверных систем управления данными (СУБД) [20, 47, 17]. В результате организации вынуждены разделять данные между несколькими серверами; в каждом разделе содержится только часть базы данных. У распределенных СУБД имеется потенциал для снижения уровня конкуренции и достижения высокой пропускной способности, если для выполнения запросов требуется доступ только к одному разделу [33, 49]. Однако для многих приложений оперативной обработки транзакций (on-line transaction processing, OLTP) проблематично (если вообще возможно) разделить данные таким образом, чтобы при обработке каждого запроса требовался доступ только к одному разделу [22, 43]. При выполнении некоторых запросов неизбежно потребуется доступ к нескольким разделам.
К сожалению, применение многораздельных сериализуемых протоколов управления параллелизмом вызывает значительное ухудшение производительности [54, 49]. Если в некоторой транзакции производится доступ к нескольким серверам в сети, любой другой транзакции, которая с ней конкурирует, может потребоваться ждать завершения первой транзакции [6] – ситуация, потенциально катастрофическая для масштабируемости системы.
В данной статье исследуется это явление: когда распределенное управление параллелизмом идет на пользу производительности, а в каких случаях распределенность определенно вредит имеющейся рабочей нагрузке? Хотя хорошо известны затраты на распределенную обработку транзакций [9, 52], недостаточно изучены издержки, возникающие в современных облачных средах, которые обеспечивают высокие уровни и масштабируемости, и эластичности. Лишь в немногих современных публикациях, в которых предлагаются новые распределенные протоколы, приводится сравнение с более чем одним другим подходом. Например, ни в одной из статей, опубликованных после 2012-го года (табл. 1), нет сравнения с протоколами, основанными на временных метках, или мультиверсионными протоколами, а в семи статьях отсутствует сравнение с каким бы то ни было протоколом сериализации. В результате предлагаемые протоколы трудно сравнивать, учитывая еще и то, что авторы разных публикаций опираются на разные конфигурации аппаратуры и рабочей нагрузки.
Наша цель состоит в том, чтобы количественно оценить и сравнить распределенные протоколы управления параллелизмом для СУБД, хранящих базы данных в основной памяти (in-memory). На основе экспериментов мы обеспечиваем понимание поведения распределенных транзакций в современной инфраструктуре облачных вычислений при использовании классических и заново предложенных протоколов управления параллелизмом, включая некоторые протоколы из табл. 1. Мы разработали легковесный фреймворк Deneva для распределенных in-memory СУБД, который позволяет оценивать производительность и накладные расходы различных распределенных протоколов управления параллелизмом, обеспечивающих сериализацию транзакций. Единая платформа, позволяющая справедливым образом сравнивать и количественно оценивать протоколы, дает возможность выявить поведение каждого из них при разных рабочих нагрузках. Насколько нам известно, результаты нашей работы предоставляют самую полную оценку эффективности протоколов управления параллелизмом в инфраструктуре облачных вычислений. Расширяемый фреймворк Deneva свободно доступен вместе с исходными кодами для сообщества исследователей обработки транзакций[1].
Табл. 1. Сравнение экспериментальных оценок недавно опубликованных протоколов сериализации распределенных транзакций (Lock: двухфазные блокировки, TS: протоколы на основе временных меток; MV: многоверсионные протоколы управления параооеоищмом; OCC: оптимистическое управление параллелизмом; Det: детерминированные методы)
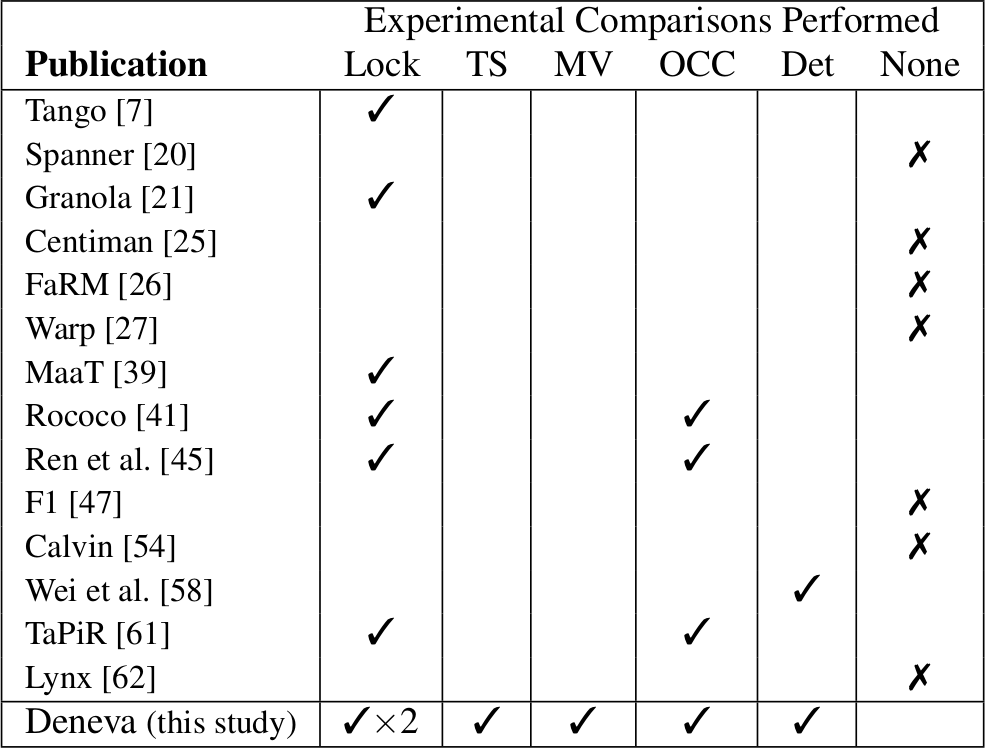
С использованием Deneva мы анализировали поведение шести протоколов управление параллелизмом в общедоступной облачной инфрастуктуре с применением комбинации микробенчмарков и стандартной рабочей нагрузки OLTP. Мы обнаружили, что масштабируемость всех протоколов является ограниченной. Наши результаты показывают, что в распределенной среде при разных характеристиках рабочей нагрузки более пригодными оказываются разные существующие протоколы. При низком уровне конкуренции и рабочей нагрузке с небольшим числом операций изменения базы данных все протоколы работают хорошо. Но на рабочих нагрузках с большим числом изменений двухфазные блокировки без ожидания показывают производительность, которая на 54% превосходит производительность других недетерминированных протоколов, а на рабочих нагрузках с высоким уровнем конкуренции этот разрыв в производительности достигает 78%. Детерминированные протоколы превосходят по производительности все другие протоколы при наличии наиболее высокого уровня конкуренции и наибольшего числа операций изменения в рабочих нагрузках из простых транзакций. Но если в рабочей нагрузке содержатся транзакции, использующие внешние ключи, детерминированный протокол является единственным протоколом, у которого производительность не масштабируется при росте размеров кластера.
Оставшаяся часть статьи организована следующим образом: в разд. 2 представлены архитектура и реализация легковесного фреймворка Deneva, предназначенного для оценки поведения распределенных протоколов управления параллелизмом. В разд. 3 приводится обзор протоколов управления параллелизмом и их оптимизаций, исследуемых в данной статье. В разд. 4 каждый из протоколов оценивается, и в разд. 5 выявляются их слабые места, ограничивающие масштабируемость, и предлагаются способы устранения этих недостатков. В разд. 6 обсуждаются родственные работы, и в разд. 7 описываются планы дальнейших исследований.
2. Обзор системы
Приложения OLTP сегодня распространены повсеместно, включая банковскую деятельность, электронную коммерцию и обработку заказов в Internet-магазинах [52]. Транзакционные СУБД обеспечивают для этих приложений поддержку транзакций: возможность обработки транзакций – последовательностей операций над наборами совместно используемых записей данных. На практике транзакции в приложениях OLTP (1) являются непродолжительными, (2) в каждой операции обращаются к небольшому числу записей и (3) многократно выполняются с разными входными параметрами [33].
В данной работе исследуется наивысший идеал обработки транзакций: сериализуемое выполнение. В этой модели транзакции ведут себя так, как если бы они выполнялись поочередно над одним экземпляром состояния базы данных [9]. Поскольку каждая транзакция поддерживает критерии корректности (или целостности) приложений, сериальное выполнение гарантирует целостность приложений. Используемый в СУБД протокол управления параллелизмом отвечает за максимизацию уровня параллельности выполнения транзакций при соблюдении строгих требований семантики сериализации. На практике, в большом числе транзакционных СУБД не используется семантика сериализации, применяются, например, подходы Read Committed или Snapshot Isolation [4]. Но поскольку использование этих уровней изолированности транзакций может привести к нарушению целостности приложений, мы уделяем основное внимание исследованию сериализуемых методов выполнения транзакций.
Начиная с 1970-х, было разработано много методов поддержки сериализации транзакций как в одноузловых, так и распределенных средах. Через несколько десятков лет продолжают появляться новые варианты методов распределенного сериализуемого управления параллелизмом как в университетских [33, 53], так и в коммерческих [20, 35] СУБД (см. разд. 6). При наличии такого разнообразия трудно определить, когда одна стратегия доминирует над другой. Как показывает табл. 1, в большинстве современных исследований производится сравнение всего лишь с одной или двумя альтернативами (чаше всего, с двухфазными блокировками). Исходя из этого, целью нашей работы является количественное сравнение с использованием одного и того же фреймворка как классических, так и предложенных в последнее десятилетие протоколов, включая и пессимистические стратегии, и стратегии на основе временных меток [11].
Для проведения точного сравнения этих протоколов мы реализовали легковесный распределенный тестовый фреймворк для in-memory СУБД, который обсуждается далее в этом разделе.
2.1 Принципы и архитектура
Поскольку мы стремились обнаружить узкие места в распределенных протоколах, нам требовалась архитектура, позволяющая изолировать эффект управления параллелизмом и изучать его в контролируемой среде. Соответственно, мы создали фреймворк Deneva, поддерживающий возможность реализации и развертывания нескольких протоколов на одной платформе. В Deneva используется специализированное ядро СУБД (а не адаптирована какая-либо существующая система), чтобы избежать накладных расходов, связанных с поддержкой не относящихся к делу функциональных возможностей. Кроме того, этот подход обеспечивает оценку протоколов в распределенной среде при отсутствии узких мест, распространенных среди существующих реализаций.
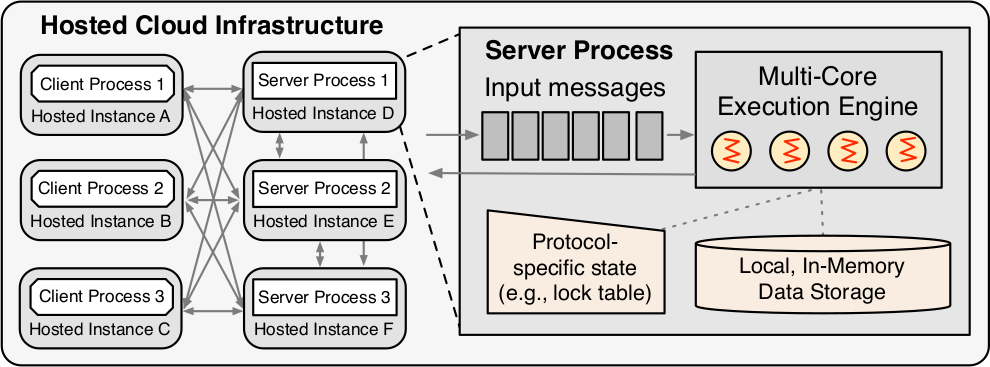
Рис. 1. Архитектура фреймворка Deneva. Набор клиентских и серверных процессов размещается на наборе арендуемых узлов (виртуальных машин или выделенных серверов) в общедоступной облачной инфраструктуре. Многопоточное, многоядерное исполнительное ядро поддерживает хранилище данных в основной памяти без совместного использования ресурсов между узлами, а также вспомогательные структуры данных в основной памяти для хранения метаданных конкретных протоколов
На рис. 1 показана общая архитектура Deneva. Набор клиентских и серверных процессов обрабатывает транзакционные рабочие нагрузки с использованием разных предопределенных, но расширяемых протоколов. Система относится к категории shared-nothing, т.е. каждый сервер отвечает за один или несколько разделов данных, и ни один раздел не обслуживается более чем одним сервером. В Deneva поддерживаются распределенные транзакции, но не обеспечиваются репликация и отказоустойчивость; в данном исследовании мы ограничиваемся рассмотрением сценариев без сбоев. Потенциальные расширения обсуждаются в разд. 7.
Прежде чем описывать модель транзакций, модель выполнения и системную архитектуру Deneva, заметим, что система разрабатывалась для расширяемой, модульной реализации распределенных протоколов управления параллелизмом. При добавлении протокола требуется реализовать новые логику координации транзакций, вызовы удаленных процедур и серверные программы обработки событий. Компоненты хранения данных, управления сетью и выполнения транзакций остаются неизменными. По нашему опыту, для реализации нового протокола требуется одна неделя.
2.2 Модель транзакций
Все транзакции в Deneva выполняются как хранимые процедуры, запускаемые на серверах. Каждая процедура содержит программную логику, перемешанную с запросами, которые читают или изменяют записи в базе данных. Для некоторых протоколов – а именно, тех, которые полагаются на детерминированное выполнение (например, Calvin [54], VoltDB [1], H-Store [33]) – требуется, чтобы наборы чтения и записи всех транзакций были известны заранее или определялись на отдельном дорогостоящем шаге «принятия» («reconnaissance») транзакции. Для обеспечения справедливого и реалистичного сравнения протоколов в Deneva эта информация получается для тех протоколов, которые в ней нуждаются.
2.3 Модель выполнения
Клиенты и серверы размещаются в полностью связанной сетевой топологии на основе набора развернутых виртуальных узлов облачной инфраструктуры. Для связи между узлами с использованием TCP/IP применяется масштабируемая, поточно-ориентированная библиотека сокетов nanomsg [51]. Если явно не оговаривается иное, можно считать, что клиентские и серверные процессы размещаются в разных узлах. Данные разделяются между серверами с использованием согласованного хэширования (consistent hashing [34]), и клиентам это разделение известно (оно не изменяется в процессе работы).
В Deneva обеспечиваются рабочие нагрузки, затрагивающие разные аспекты протоколов (подраздел 4.1). Фреймворк допускает наличие нескольких недовыполненных транзакций, которые образованы по инициативе одного клиентского процесса. Общее число недообработанных клиентских запросов мы называем предлагаемой загрузкой системы. Когда клиент желает выполнить транзакцию, он, прежде всего, генерирует входные параметры целевой хранимой процедуры в соответствии со спецификацией рабочей нагрузки. Затем он посылает запрос серверу, управляющему разделом, к которому происходит первое обращение в транзакции и который мы называем координатором. Если в транзакции производится доступ к нескольким разделам, она называется многораздельной транзакцией (multi-partition transaction, MPT). Серверы, участвующие в выполнении MTP, называются участниками.
2.4 Выполнении транзакций на серверах
Каждый сервер обрабатывает запросы от имени клиентов и других серверов. Когда сервер получает новый запрос на выполнение транзакции, он вызывает хранимую процедуру, которая затем генерирует запросы, требующие доступа к данным либо в локальном разделе, либо в каком-либо удаленном разделе, которым управляет другой сервер. Если какая-то активная транзакция аварийно завершается в связи с поведением протокола, координатор посылает другим участвующим серверам соответствующее сообщение. Затем каждый участник откатывает все изменения, которые внесла транзакция в его локальный раздел. После этого координатор снова помещает запрос на выполнение аварийно завершенной транзакции в свою очередь работ. Для уменьшения вероятности повторного отказа при обработке этого запроса из-за того же конфликта между транзакциями координатор применяет экспоненциально возрастающую задержку (начиная с 10 мсек) перед повторным выполнением аварийно завершенной транзакции. После успешного завершения транзакции координатор отправляет клиенту подтверждение и освобождает память, занимаемую внутренними структурами данных, которые использовались при выполнении этой транзакции
Приоритетная очередь работ: Вызовы удаленных процедур обрабатываются набором нитей ввода-вывода (в нашем случае по восемь нитей в каждом сервере), отвечающих за маршалинг и демаршалинг[2] транзакций, операций и их возвращаемых значений. Когда запрос на выполнение транзакции или операции поступает на сервер, он помещается в очередь работ, в которой операции уже выполняемых транзакций более приоритетны, чем новые транзакции, запрашиваемые клиентами. Без учета этого обстоятельства транзакции и операции обрабатываются по принципу «первый пришел – первым обслуживается» (first-come, first-served).
Исполнительный механизм: Исполнительные нити (в нашем случае по четыре нити в каждом сервере, каждая в отдельном процессорном ядре) опрашивают очередь работ и выполняют параллельные операции в неблокирующем режиме. СУБД выполняет активную транзакцию операция за операцией, пока она не заблокируется в ожидании совместно используемого ресурса (например, блокировки некоторой записи) или ей не потребуется доступ к данным в каком-либо удаленном разделе. В последнем случае СУБД доставляет в удаленный сервер параметры транзакции, требуемые для выполнения удаленных операций (определяющие, например, какие записи нужно прочитать). После этого нить может быть возвращена в пул свободных нитей и нагружена другой работой. Это означает, что хотя транзакции могут блокироваться, нити – не могут. Когда транзакция оказывается готовой продолжить выполнение на данном сервере, ее следующий набор операций добавляется в приоритетную очередь и обрабатывается первой доступной рабочей нитью. Мы выбрали эту безблокировочную событийную модель, поскольку она обеспечивает улучшенную масштабируемость и уменьшает уровень «пробуксовки нитей» (thread thrashing) в условиях тяжелой нагрузки [59], хотя и за счет более сложной реализации.
Механизм хранения данных: Каждый сервер хранит данные своего раздела в хэш-таблице в основной памяти: поддерживается эффективный поиск по первичному ключу при минимальных накладных расходах памяти. Для устранения избыточных накладных расходов механизм хранения не поддерживает журнализацию для обеспечения долговечности результатов транзакций (durability). Интересным направление будущих работ является исследование влияния на характеристики распределенных СУБД механизмов восстановления и поддержки контрольных точек. Для поддержки в Deneva нескольких протоколов управления параллелизмом также поддерживается набор разнообразных структур данных, специфичных для конкретных протоколов, таких как локальная таблица блокировок и метаданные для валидации. Эти структуры подробно обсуждаются в следующем разделе, однако здесь следует заметить, что мы отделяем от них механизм хранения баз данных (например, хэш-индекс). Мы выбрали этот подход к организации системы, потому что он обеспечивает модульность реализации за счет относительно небольшой потери эффективности.
Генерация временных меток: В нескольких протоколах требуются физические временные метки. В фреймворке Deneva временные метки обеспечиваются как базовый примитив. В каждом сервере генерируются собственные временные метки путем чтения показаний часов локальной системы, и Deneva обеспечивает уникальность этих временных меток, добавляя к каждой из них идентификаторы сервера и соответствующей нити. Расхождения в показаниях часов разных серверов устраняются путем синхронизации серверов с использованием ntpdate, что в нашем случае не приводит к изменению пропускной способности.
3. Протоколы управления транзакциями
Далее мы опишем исследуемые нами протоколы, а также оптимизации, примененные для повышения их эффективности в распределенной среде. В число рассматриваемых протоколов входят как классические протоколы, применяемые в настоящее время в реальных СУБД, так и современные протоколы, предложенные в последние годы.
3.1 Двухфазные блокировки
Вероятно, первым сериализующим протоколом управления параллелизмом был двухфазный протокол синхронизационных блокировок (two-phase locking, 2PL). На первой фазе, называемой фазой роста (growing phase), транзакция запрашивает блокировку каждой записи, к которой ей требуется обратиться. Блокировки запрашиваются в совместном (shared) или монопольном (exclusive) в зависимости от того, нужно ли транзакции читать или записывать данные соответственно. Совместные блокировки совместимы, т.е. две транзакции, читающие одни и те же данные, могут успешно одновременно запрашивать их блокировку. Монопольные блокировки не совместимы ни с совместными, ни с другими монопольными блокировками тех же данных. Если требуемый транзакции фрагмент данных уже заблокирован в несовместимом режиме, эта транзакция должна ждать, пока ее запрос блокировки не удовлетворится.
Транзакция входит во вторую фазу 2PL, называемую фазой спада (shrinking phase), как только отпустит одну из своих блокировок. После входа в эту фазу транзакции не разрешается запрашивать новые блокировки, но она может выполнять операции чтения и записи над любым объектом, блокировка которого еще удерживается. В нашей реализации СУБД удерживает блокировки до тех пор, пока транзакция не фиксируется или аварийно завершается (т.е. используется строгий вариант 2PL). Для максимизации уровня параллелизма мы используем блокировки на уровне записей [30]. Во внутренних таблицах каждого сервера сохраняется только информация о блокировках записей в его локальном разделе.
Реализации 2PL различаются применяемыми подходами к обработке тупиковых ситуаций (deadlock) путем изменения поведения транзакций, которые пытаются получить доступ к данным с применением конфликтующих типов блокировок. Мы исследовали следующие два варианта.
В варианте протокола NO_WAIT, если некоторая транзакция пытается получить доступ к некоторой уже заблокированной записи, и режим установленной блокировки не совместим с режимом запрашиваемой блокировки, то СУБД аварийно завершает транзакцию, запрашивающую блокировку. Все блокировки, удерживаемые аварийно завершаемой транзакцией, снимаются, позволяя другим конфликтующим транзакциям получить доступ к нужным записям. Аварийно завершая транзакции, наталкивающиеся на конфликт, вариант NO_WAIT предотвращает возникновение тупиков. Но появление таких транзакций не обязательно приводит к возникновению цикла зависимостей по блокировкам, так что многие аварийные завершения транзакций могут быть ненужными.
Вариант протокола WAIT_DIE аналогичен описанному выше, не считая того, что аварийные завершения избегаются за счет упорядочивания транзакций на основе временных меток, которые назначаются СУБД при начале транзакций. СУБД ставит в очередь конфликтующую транзакцию, если ее временная метка меньше, чем у любой транзакции, которая в настоящее время владеет блокировкой (т.е. транзакция, запрашивающая блокировку, старше всех транзакций, удерживающих блокировку) [11]. Если транзакция пытается получить совместную блокировку записи, которая уже блокирована в совместном режиме, она может обойти очередь и немедленно войти в число владельцев блокировки. Хотя этот подход может ставить в невыгодное положение пишущие транзакции, мы сочли такую оптимизацию полезной.
Можно было бы реализовать выявление тупиков путем проверки наличия циклов в графе удовлетворенных и ожидаемых блокировок [30]. Однако для обнаружения циклов потребовалось бы значительное число сетевых пересылок между серверами. Поэтому в распределенной среде этот способ выявления тупиков является слишком дорогостоящим, и мы не включили его в число исследуемых подходов.
3.2 Упорядочивание по временным меткам (Timestamp Ordering)
Другое семейство протоколов управления параллелизмом опирается на временные метки. В этих протоколах уникальные временные метки используются для упорядочивания транзакций и предотвращения тупиков. Как и для всех протоколов в этой статье, использующих временные метки, эти временные метки генерируются на основе механизма Deneva, описанного в 2.4.
В самом базовом алгоритме этого класса (TIMESTAMP) операции транзакций упорядочиваются в соответствии с назначенными транзакциям временными метками [11]. Временная метка транзакции определяет возможность доступа к записи. В отличие от WAIT_DIE, транзакции не могут обойти очередь ожидания транзакций, которую СУБД хранит в структурах данных, специфичных для протокола. Протокол позволяет избежать возникновения тупиков за счет аварийного завершения транзакций с временными метками, меньшими, чем у транзакции, которая последней обновила соответствующую запись (более старых транзакций). При рестарте транзакции СУБД назначает ей новую уникальную временную метку на основе текущих показаний системных часов.
В мультиверсионном варианте протокола временных меток (multi-version concurrency control, MVCC) поддерживается несколько помеченных временными метками копий каждой записи [12]. Это позволяет выполнять операции чтения и записи с минимальными конфликтами, поскольку операции чтения могут получать доступ к предыдущим копиям данных, если запись не зафиксирована. В Deneva несколько копий каждой записи сохраняются в структуре данных основной памяти, и число сохраняемых копий ограничено. Транзакции, пытающиеся обратиться к уже удаленным копиям, аварийно завершаются.
3.3 Оптимистические протоколы
Оптимистические протоколы управления параллелизмом (optimistic concurrency control, OCC) выполняют транзакции параллельно и определяют во время фиксации транзакции, был ли результат транзакции действительно сериализуемым [38]. Другими словами, до фиксации транзакции СУБД производит ее валидацию по отношению ко всем транзакциям, зафиксированным с момента ее начала или находящимся в настоящее время на этапе валидации. Если транзакцию можно зафиксировать, СУБД копирует все ее изменения из локальной памяти транзакции в базу данных и возвращает клиенту результаты. Иначе транзакция завершается аварийно с очисткой локальной памяти.
Наш вариант протокола OCC основан на протоколе MaaT [39]. Основным преимуществом MaaT над традиционными протоколами OCC является то, что он позволяет уменьшить число конфликтов, приводящих к излишним аварийным завершениям транзакций. В реализации Deneva требуются три специфичных для протокола структуры данных:
- частное рабочее пространство транзакции для отслеживания набора данных, которые транзакция хотела бы записать в базу данных;
- по одной таблице на сервер, называемой расписанием (timetable) и содержащей диапазон (т.е. верхнюю и нижнюю границы) значений временных меток фиксации каждой активной транзакции;
- метаданные для каждой записи, сохраняющие два набора – набор идентификаторов транзакций-читателей и набор идентификаторов транзакций-писателей – для транзакций, которые намериваются читать или писать запись, а также временные метки фиксации последних транзакций, обращавшихся к этой записи.
Перед началом выполнения каждая транзакция получает уникальный идентификатор, который затем помещается в локальное расписание сервера, причем нижняя граница диапазона значений временной метки фиксации инициализируется нулем, а верхняя – бесконечностью. При выполнении транзакции СУБД помещает все измененные ею записи в частное рабочее пространство. Это позволяет транзакциям выполняться без блокировок или затрат времени на проверку наличия конфликтов. При каждом обращении транзакции к записи СУБД обновляет метаданные этой записи. Если запись транзакцией читается, СУБД добавляет идентификатор транзакции к набору идентификаторов транзакций-читателей, а также помещает в частное рабочее пространство копию набора идентификаторов транзакций-читателей и последнюю временную метку транзакции-читателя (эти данные используются на этапе валидации). При выполнении операций записи СУБД добавляет идентификатор транзакции к набору идентификаторов транзакций-писателей, а также помещает в частное рабочее пространство копию наборов идентификаторов транзакций-читателей и транзакций-писателей и последнюю временную метку транзакции-читателя. Когда транзакция первый раз читает или пишет запись в удаленном сервере, СУБД создает для этой транзакции элемент в расписании удаленного сервера.
Фаза валидации протокола OCC наступает при завершении транзакции, когда она вызывает протокол атомарной фиксации (см. 3.5). Начиная с начальных диапазонов временных меток, хранимых в расписании, каждый участвующий в транзакции сервер корректирует диапазоны временных меток валидируемой транзакции, а также транзакций, идентификаторы которых входят в ее наборы чтения/записи, таким образом, чтобы диапазоны конфликтующих транзакций не перекрывались. Все откорректированные диапазоны помещаются в расписание, и транзакция переходит в состояние валидации, в котором ее диапазон не может быть изменен другими транзакциями. Если в конце этого процесса диапазон временных меток валидируемой транзакции остается допустимым (т.е. значение верхней границы диапазона больше значения нижней границы), то сервер принимает положительное решение о валидации и посылает координатору сообщение COMMIT. В противном случае серверу посылается сообщение ABORT. Если координатор получает от всех серверов-участников сообщение COMMIT, то он принимает окончательное решение о фиксации и информирует об этом все сервера-участники. На этой стадии идентификатор транзакции может быть удален из наборов чтения и записи всех записей, к которым обращалась транзакция. Если транзакция фиксируется, то можно изменить и временные метки всех этих записей.
3.4 Детерминированные протоколы
Детерминированное планирование транзакций – это недавно предложенная альтернатива традиционным протоколам управления параллелизмом [45]. Централизованные координаторы, определяющие детерминированный порядок выполнения транзакций, могут устранить нужду в координации серверов, которая требуется при применении других протоколов управления параллелизмом. В связи с этим у детерминированных протоколов имеются два преимущества. Во-первых, они не нуждаются в протоколе атомарной фиксации (подраздел 3.5) для определения судьбы транзакции. Во-вторых, они поддерживают более простые стратегии репликации.
Реализация детерминированного координатора блокировок в Deneva (CALVIN) основана на фреймворке Calvin [54]. Все клиенты посылают свои запросы в распределенный уровень координации, состоящий из секвенсеров (sequencer), которые упорядочивают транзакции и назначают им уникальные идентификаторы. Время делится на периоды (epoch) по 5 мсек. В конце каждого периода каждый секвенсер пересылает пакеты запросов на образование транзакций, полученные им за этот период, на серверы, которые управляют разделами, содержащими записи, к которым этим транзакциям требуется доступ. В каждом сервере компонент, называемый планировщиком (scheduler), запрашивает блокировки уровня записей у каждого секвенсера в некотором предопределенном порядке. Это означает, что каждый планировщик обрабатывает весь пакет транзакций от одного и того же секвенсера в порядке, предопределенном этим секвенсером, до перехода у следующему пакету от другого секвенсера. Если транзакция не может получить блокировку, СУБД ставит ее в очередь в этой блокировке, а планировщик продолжает обработку.
СУБД может выполнить транзакцию, как только она получит все требуемые ей блокировки уровня записей. Выполнение происходит по фазам. Сначала анализируется набор чтений/записей транзакции для определения всех участвующих серверов (т.е. всех серверов, которые читают или обновляют записи) и активных серверов (т.е. серверов, производящих обновления). После этого система выполняет все локальные чтения. Если прочитанные данные нужны при выполнении транзакции в других серверах (например, для определения того, не следует ли аварийно завершить транзакцию из-за наличия соответствующих значений в базе данных), система пересылает эти данные в активные серверы. На этой стадии неактивные серверы, не производящие обновлений, завершают выполнение и освобождают блокировки. Активный сервер после получения сообщений от всех участников, от которых он ожидает получить данные, производит обновления своего локального раздела. На этом этапе активные сервера детерминированным образом принимают решения о фиксации или аварийном завершении транзакции, и блокировки снимаются. Серверы посылают свои ответы секвенсеру, который отправляет клиенту подтверждение, как только получит все ответы.
У только читающих (read-only) транзакций в CALVIN нет активных серверов, и поэтому они завершаются после фазы локальных чтений. Это означает, что для таких транзакций требуется обмен сообщениями только между секвенсерами и серверами (между самими серверами обмен сообщениями не требуется).
Поскольку CALVIN является детерминированным протоколом, для его применения требуется априорное знание наборов чтения/записи всех транзакций. Если наборы чтения/записи неизвестны, фреймворк должен вычислить их на стадии выполнения транзакции. Это приводит к тому, что некоторые транзакции выполняются два раза: сначала спекулятивно для определения наборов чтения/записи, а потом уже в соответствии с детерминированным протоколом. На первом, разведывательном шаге (reconnaissance step) транзакция может выполняться без запросов блокировок. Но если какая-либо требуемая транзакции запись изменяется между разведывательным и исполнительным шагами, транзакция аварийно завершается, и весь процесс выполняется заново.
В своей версии CALVIN в Deneva мы реализовали секвенсер, планировщик и рабочие уровни как отдельные нити, сосуществующие на одних и тех же серверах. Две нити-обработчика были заменены на нити секвенсера и планировщика.
3.5 Двухфазная фиксация
Для обеспечения того, чтобы серверы-участники транзакции либо все ее фиксировали, либо все не фиксировали (т.е. для решения проблемы атомарной фиксации [52, 9]), во всех протоколах, реализованных в Deneva (кроме CALVIN), используется двухфазный протокол фиксации (two-phase commit, 2PC). Протокол 2PC требуется только для тех транзакций, которые выполняют операции обновления в нескольких разделах. Для только читающих и однораздельных (single-partition) транзакций система пропускает этот шаг и сразу посылает ответ клиенту. Исключением является протокол OCC, поскольку он должен валидировать и чтения.
После завершения выполнения транзакции, обновлявшей несколько разделов (multi-partition update transaction), сервер-координатор посылает всем серверам-участникам сообщение PREPARE. На фазе подготовки участники голосуют за фиксацию или аварийное завершение транзакции. Поскольку в этой статье не рассматриваются сбойные ситуации, во всех протоколах, кроме OCC, все транзакции, достигшие фазы подготовки, фиксируются. В протоколе OCC на этой фазе происходит валидация, что может привести к аварийному завершению транзакции. Участники в своих ответных сообщениях информируют координатор о своем решении зафиксировать или аварийно завершить транзакцию. После получения координатором ответных сообщений от всех участников протокол входит во вторую, заключительную фазу фиксации. Если какой-либо участник (включая координатора) проголосовал за аварийное завершение, сервер-координатор рассылает всем серверам-участникам сообщение ABORT. Иначе всем участникам посылается сообщение COMMIT. При получении финального сообщения участники фиксируют или аварийно завершают свою часть транзакции и производят чистку, освобождая, в частности, все удерживаемые транзакцией блокировки. После этого координатору посылается подтверждение. В течение этой фазы координатор тоже производит чистку, но только он может ответить клиенту, получив окончательные подтверждения от всех участников.
4. Сравнение
Теперь мы представим сравнение и анализ шести протоколов управления параллелизмом, осаждавшихся в разд. 3. Не считая специально оговариваемых случаев, мы развертывали фреймворк Deneva на Amazon EC2, используя инстансы типа m4.2xlarge в восточном регионе США. Мы использовали разное число клиентских и серверных инстансов. Каждый инстанс содержит восемь виртуализированных ядер, 32 Гб основной памяти и характеризуется «высокой» производительности сети (среднее время отклика – 1 мсек).
Перед проведением каждого эксперимента разделы таблиц загружались в каждый сервер. В течение эксперимента применялась нагрузка в 10000 открытых клиентских подключений к каждому серверу. Первые 60 сек. являлись периодом разогрева, а в следующие 60 сек. производились измерения. Измерялась пропускная способность как число успешно завершенных транзакций после периода разогрева. Если какая-то транзакция аварийно завершалась из-за конфликтов, обнаруженных протоколом управления параллелизмом, она перезапускалась по прошествии некоторого штрафного периода. В первых четырех экспериментах, описанных в подразделах 4.2-4.4, мы использовали микробенчмарк, позволяющий настаивать характерные компоненты рабочей нагрузки OLTP для оценки эффективности протоколов. Затем в 4.5 мы описываем результаты оценки масштабируемости и обсуждаем, на что тратит время СУБД при выполнении транзакций. Наконец, в подразделах 4.7-4.9 рассматриваются эксперименты, моделирующие разные сценарии приложений.
4.1 Рабочие нагрузки
Обсудим рабочие нагрузки, используемые в наших экспериментах.
YCSB: The Yahoo! Cloud Serving Benchmark (YCSB) [19] предназначен для оценки крупномасштабных Internet-приложений. В этом бенчмарке имеется одна таблица с первичным ключом и 10 дополнительными столбцами, каждый из которых содержит 100 байт случайных символов. В своих экспериментах мы использовали таблицу YCSB с 16 миллионами записей в каждом разделе, т.е. размер базы данных составлял 16 Гб на узел. Таблица разделялась с использованием хэширования первичного ключа. Каждая транзакция в YCSB обращается к 10 записям (если не оговаривается иное) с независимыми операциями чтения и записи в случайном порядке. Обращения к данным следуют распределению Зипфа, где частота доступа к наборам горячих записей настаивается путем использования параметра скашивания (theta)[3]. Если theta равно 0, доступ к данным производится с равномерной частотой, а если 0.9, частота очень скошена.
TPC-C: Этот бенчмарк моделирует приложение обработки складских заказов и является промышленным стандартом для оценки баз данных OLTP [55]. В тестовом наборе содержатся девять таблиц, разделяемых по идентификаторам складов, за исключением таблицы видов продукции, которая является только читаемой и реплицируется в каждом сервере [50]. В наших экспериментах использовались две транзакции из TPC-C – Payment и NewOrder, составляющие 88% смешанной рабочей нагрузки, которая в TPC-C применяется по умолчанию. Для выполнения других транзакций требуются функциональные возможности (в частности, сканы), которые во время проведения экспериментов в Deneva не поддерживались, и поэтому в рабочую нагрузку эти транзакции не включались. Мы также не имитировали «время на размышление» пользователей и ошибки в поставляемых ими данных, которые приводят к аварийному завершению 1% транзакций NewOrder.
Транзакции Payment обращаются к данным не более двух разделов. На первом шаге в этой транзакции обновляется сумма платежа для соответствующих склада и района сбыта. В каждой транзакции требуется монопольный доступ к ее складу. Во второй части транзакции обновляется информация о заказчике. С вероятностью 15% заказчик относится к удаленному складу.
В первой части транзакции NewOrder читаются записи ее склада и района сбыта. Затем запись о районе сбыта обновляется. Во второй части транзакция обновляет 5-15 элементов в таблице наличных товаров. В целом, 99% всех элементов, обновляемых в транзакции, являются локальными по отношению к ее «родному» разделу, а 1% относится к удаленному разделу. Это означает, что 10% всех транзакций NewOrder являются многораздельными.
PPS: Product-Parts-Supplier (PPS) – это еще один бенчмарк OLTP, содержащий транзакции, в которых выполняется поиск внешних ключей. Имеются пять таблиц: по одной для продуктов (Product), их комплектующих деталях (Parts) и их поставщиках (Supplier) с разделением по соответствующим первичным ключам (идентификаторам продуктов, деталей и поставщиков), таблица, отображающая на комплектующие, и таблица, отображающая поставщиков на поставляемые детали. В этом бенчмарке комплектующие детали назначаются продуктам и поставщикам случайным образом с равномерным распределением.
Рабочая нагрузка бенчмарка состоит из смеси однораздельных и многораздельных транзакций. Многраздельная транзакция OrderProduct сначала выбирает все комплектующие для некоторого продукта, а затем уменьшает их количество среди наличных товаров. Транзакция LookupProduct, аналогичным образом, выбирает комплектующие заданного продукта и наличное число деталей каждого типа, но не изменяет никаких записей. В транзакций обоих типов выполняется один или более поисков внешних ключей, которые могут распространяться на несколько разделов. Последняя транзакция (UpdateProductPart) изменяет в базе данных случайное отображение продуктов на комплектующие.
4.2 Конкуренция
Начнем с оценки влияния на протоколы увеличения конкуренции в системе, поскольку часто это является одним из наиболее важных факторов, влияющих на производительность приложений баз данных категории OLTP. Конкуренция возникает, если транзакции пытаются читать или изменять одну и ту же запись. Для этого эксперимента мы использовали рабочую нагрузку YCSB и изменяли параметр скашивания в шаблонах доступа транзакций к записям.
![]()
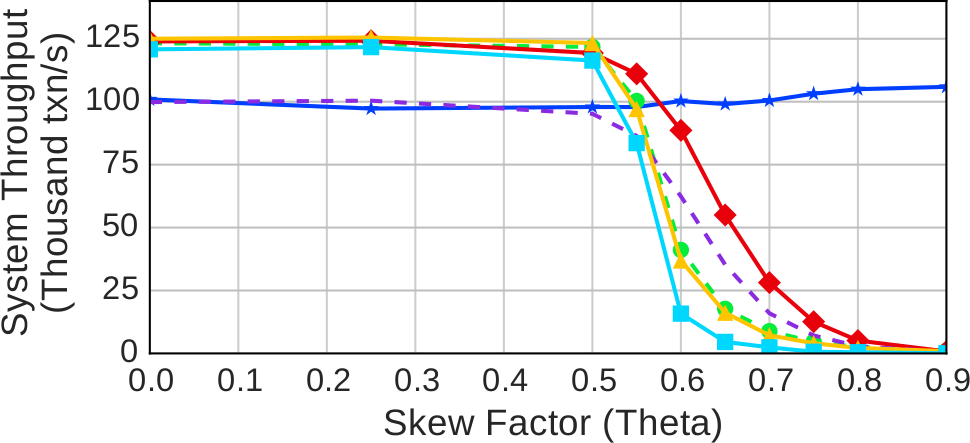
Рис. 2. Конкуренция – измеренная пропускная способность протоколов на 16 серверах при изменении фактора скашивания на рабочей нагрузке YCSB
Рис. 2 показывает, что скашивание относительно мало влияет на пропускную способность при значениях theta от 0 до 0.5. После этой точки почти у всех протоколов производительность падает, но с разной скоростью. После достижения значения theta 0.8 все, кроме одного, протоколы показывают одну и ту же низкую производительность. CALVIN – это единственный протокол, поддерживающий хорошую производительность несмотря на большие значения параметра скашивания. Во-первых, узким местом в CALVIN является уровень планирования. Как только транзакция получит все требуемые ей блокировки, рабочая нить сразу ее выполняет, а после завершения выполнения немедленно отпускает блокировки. Это означает, что блокировки не удерживаются достаточно долго, чтобы планировщик должен был обрабатывать конфликтующие транзакции. Во-вторых, поскольку все обращения транзакций к данным являются независимыми, CALVIN не нуждается в посылке сообщений между фазами чтения и выполнения. Поэтому, в отличие от других протоколов, ему не требуется удерживать блокировки во время ожидания сообщений от удаленных серверов.
При небольшой конкуренции протокол OCC показывает производительность, худшую, чем другие недетерминированные протоколы, из-за накладных расходов на валидацию и копирование данных при выполнении транзакций [60]. Однако в условиях высокой конкуренции возможность справляться с большим числом конфликтов и, тем самым, избегать излишних аварийных завершений транзакций перевешивает эти накладные расходы.
Производительность протоколов MVCC и TIMESTAMP после достижения значения theta 0.5 деградирует быстрее, чем у других протоколов, потому что они не дают выполняться более новым транзакциям до фиксации более старых транзакций. Хотя при использовании MVCC некоторым транзакциям удается избежать этого за счет чтения более старых версий, для этого требуется, чтобы читающие транзакции были старше всех транзакций с незафиксированными записями тех же данных, а в используемой рабочей нагрузке это условие часто не выполняется.
4.3 Процент обновлений
Далее мы сравниваем способы, применяемые в протоколах для поддержки в транзакциях операций обновления базы данных. В этом эксперименте мы изменяли в рабочей нагрузке YCSB процентное соотношение пишущих транзакций, сохраняя конфигурацию из 16 серверов. Каждая транзакция обращается к 10 разным записям. Некоторые транзакции являются «только читающими». «Обновляющие» транзакции читают пять записей и обновляют пять записей. Эти операции обновления выполняются в случайных точках транзакции и никогда не обновляют записи, читаемые той же транзакцией. Использовалась настройка среднего скашивания (theta = 0.6), поскольку предыдущий эксперимент показал, что при этом возникает заметная конкуренция без перегрузки протоколов.
![]()
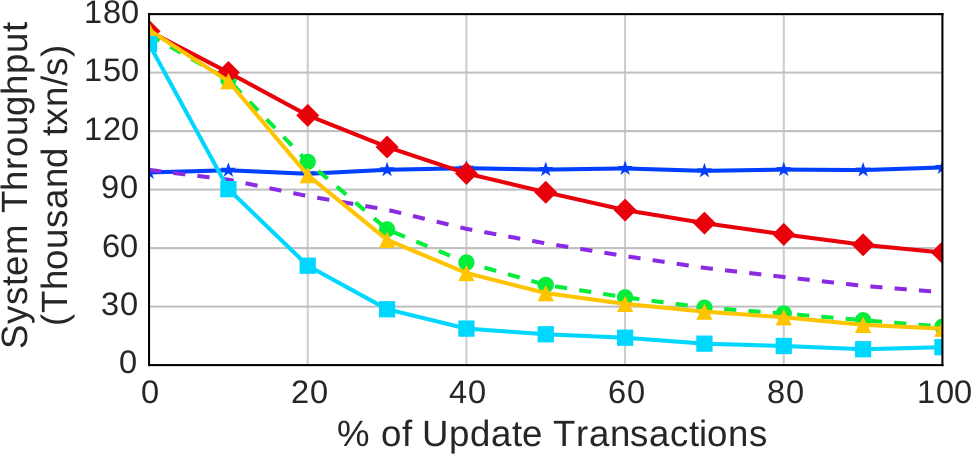
Рис. 3. Процент обновлений – измеренная пропускная способность на 16 серверах в зависимости от процентного соотношения в рабочей нагрузке только читающих транзакций (10 чтений в транзакции) и обновляющих транзакций (5 операций чтения и 5 операций записи) на смешанной рабочей нагрузке YCSB со средним уровнем конкуренции (theta = 0.6)
Результаты, представленные на рис. 3, показывают, что производительность большинства протоколов падает при возрастании относительного числа обновляющих транзакций. Внесение в рабочую нагрузку небольшого числа обновляющих транзакций приводит к резкому падению пропускной способности протокола WAIT_DIE. Это связано с тем, что большее число транзакций аварийно завершается, пытаясь обратиться к горячей записи до того, как она достаточно состарится, чтобы можно было ждать ее блокировки (при 10% обновляющих транзакций в среднем приходится 1.4 аварийных завершения на транзакцию[4]). Кроме того, при использовании WAIT_DIE транзакции часто тратят время на получение блокировок только для того, чтобы позже аварийно завершиться. Протокол NO_WAIT этому явлению не подвержен, потому что, если требуемая блокировка недоступна, транзакция сразу аварийно заканчивается.
Протоколы NO_WAIT, MVCC и TIMESTAMP показывают почти одинаковую производительность, пока относительное число обновляющих транзакций не превысит 10%. В этой точке графики производительности MVCC и TIMESTAMP расходятся с графиком NO_WAIT. При 100% обновляющих транзакций MVCC и TIMESTAMP демонстрируют производительность в 33% от производительности NO_WAIT. При наличии большого относительного числа читающих транзакций MVCC и TIMESTAMP выигрывают благодаря возможности параллельного выполнения транзакций. Но по мере возрастания относительного числа обновляющих транзакций эти протоколы мешают выполняться все большему числу транзакций. При использовании MVCC относительное число завершенных транзакций, которые перезапускались, изменяется от 3% до 16% при росте относительного числа обновляющих транзакций от 10% до 100%. Это отрицательно влияет на производительность, поскольку перезапуск транзакций может привести к аварийному завершению других транзакций при доступе к другим записям. При использовании NO_WAIT этот эффект не настолько серьезен, поскольку доступ к записям по чтению происходит после установки соответствующих блокировок в совместном режиме. Если рабочая нагрузка на 100% состоит из обновляющих транзакций, NO_WAIT обеспечивает производительность, на 54% более высокую, чем OCC, занявший второе место среди недетерминированных протоколов.
Рис. 3 также показывает, что OCC и CALVIN обеспечивают меньшую производительность, чем другие протоколы, при малом относительном числе обновляющих транзакций в рабочей нагрузке. В случае OCC это объясняется накладными расходами на копирование данных и валидацию. При использовании OCC производительность падает при увеличении относительного числа обновляющих транзакций, поскольку для таких транзакций требуется больше шагов валидации. Но поскольку OCC часто может согласовать параллельные обновления с одной и той же записью за счет гибкости при назначении временной метки фиксации, падение производительности происходит не так резко, как при использовании других протоколов.
Наконец, при использовании CALVIN производительность ведет себя не так, как для других протоколов. Производительность на рабочей нагрузке из только читающих транзакций почти не отличается от производительности на рабочей нагрузке из только обновляющих транзакций. Вместо этого производительность CALVIN ограничивается использованием однопотокового планировщика, который не может обрабатывать транзакции с той же скоростью, которую обеспечивают несколько рабочих нитей при использовании других протоколов. Каждая транзакция выполняется сразу после того, как получит все требуемые блокировки. Это означает, что блокировки освобождаются, как только транзакция завершает выполнение, так что СУБД не удерживает блокировки настолько долго, чтобы вызвать конкуренцию в планировщике. При использовании CALVIN отсутствует потребность в удержании блокировок в течение какого-либо обмена сообщениями. Все чтения в рабочей нагрузке YCSB независимы, поэтому протоколу CALVIN не требуется передавать какие-либо сообщения между серверами.
4.4 Многораздельные транзакции
В нашем следующем эксперименте оценивается влияние на производительность накладных расходов координатора многораздельных транзакций. Для каждой транзакции менялось число уникальных разделов, к данным которых обращалась транзакция, при сохранении числа серверов в кластере равным 16. В каждой транзакции выполнялись 16 операций: 50% – чтение, 50% – запись. Число разделов, к которым обращалась каждая транзакция, задавалось на уровне параметризации рабочей нагрузки, а сами разделы назначались случайным образом.
![]()
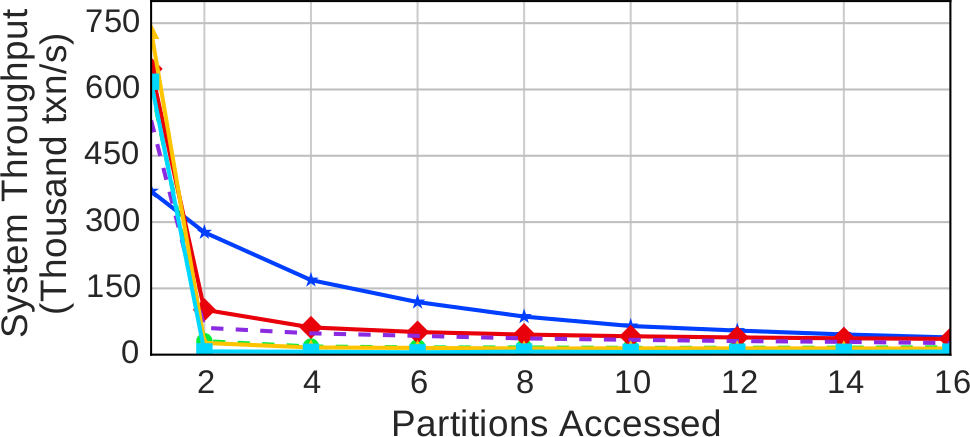
Рис. 4. Многораздельные транзакции – Пропускная способность при изменении числа разделов, к которым обращается каждая транзакция рабочей нагрузки YCSB
Наши результаты, представленные на рис. 4, показывают производительность протоколов при изменении числа разделов, к данным которых обращаются транзакции. За исключением CALVIN, пропускная способность протоколов стремительно падает, когда транзакции затрагивают более одного раздела. При увеличении числа разделов от двух до четырех производительность сокращается на 12-40%. Эта деградация происходит по двум причинам:
- наличие накладных расходов на посылку удаленных запросов и возобновление выполнения транзакций;
- наличие накладных расходов на поддержку протокола 2PC и влияние удержания блокировок на время нескольких обменов сообщениями в соответствии с этим протоколом.
Производительность CALVIN при переходе от однораздельных к многораздельным транзакциям падает не так резко, как при использовании других протоколов. При использовании CALVIN серверы синхронизуются в конце каждого периода (epoch). Даже при отсутствии многораздельных транзакций до начала обработки планировщик должен дождаться подтверждения от каждого секвенсера, чтобы обеспечить детерминированное упорядочивание транзакций. Если какие-то секвенсеры отстают от других, это приводит к замедлению работы системы. Поэтому CALVIN не так хорошо масштабируется до 16 узлов, как другие протоколы, когда в Deneva выполняются только однораздельные транзакции.
4.5 Масштабируемость
В предыдущих трех экспериментах исследовались эффекты разных конфигураций рабочей нагрузки при фиксированном размере кластера. В эксперименте, описываемом в данном подразделе, мы фиксируем рабочую нагрузку и меняем размер кластера, чтобы оценить, как масштабируются протоколы при увеличении числа серверов. В этом эксперименте снова использовался бенчмарк YCSB, и размеры таблицы изменялись пропорционально числу серверов. Каждая транзакция обращалась к 10 записям, следуя распределению Зипфа, из разделов, выбираемых случайным образом. Сначала выполнялась рабочая нагрузка из только читающих транзакций без конкуренции (theta = 0.0) для получения верхней границы производительности каждого протокола. После этого оценивалась производительность на рабочих нагрузках со средней конкуренцией (theta = 0.6) и высокой конкуренцией (theta = 0.7); у 50% транзакций 50% операций обновляли одну запись.
Кроме статистики времени выполнения, наш фреймворк также определял, сколько времени каждая транзакция провела в разных компонентах системы [60]. Мы сгруппировали эти измерения в шесть категорий:
USEFUL WORK: Все время, которое рабочие нити тратят на выполнение операций чтения или записи.
TXN MANAGER: Время, затраченное на обновление метаданных транзакций или на чистку следов зафиксированных транзакций.
CC MANAGER: Время, затраченное на получение блокировок или валидацию. В случае CALVIN сюда входит время, потраченное секвенсером и планировщиком на вычисление порядков выполнения.
2PC: Накладные расходы на двузфазную фиксацию.
ABORT: Время, затраченное на чистку следов аварийно завершенных транзакций.
IDLE: Время, затрачиваемое нитями на ожидание работы.
![]()
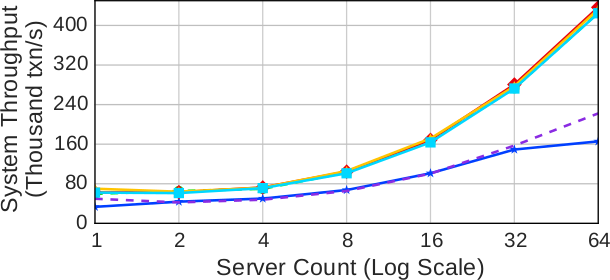
(a) Только читающие транзакции (нет конкуренции)
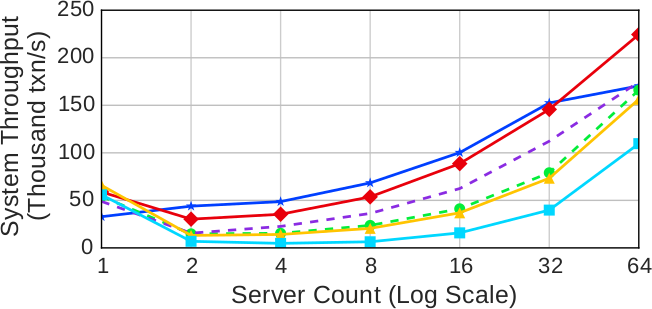
(b) Читающие и обновляющие транзакции (средняя конкуренция)
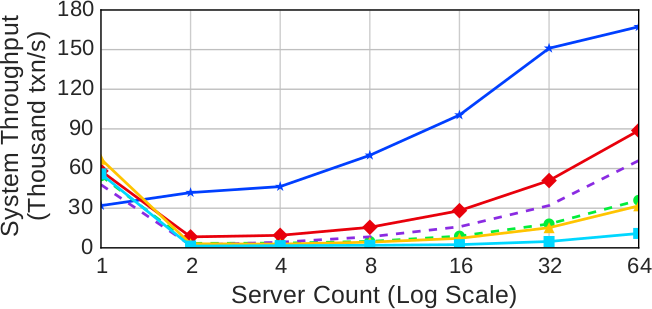
(с) Читающие и обновляющие транзакции (высокая конкуренция)
Рис. 5. Масштабируемость (пропускная способность) – Измерения производительности протоколов с использованием разных вариантов рабочей нагрузки YCSB при разных размерах кластера
Рабочая нагрузка из только читающих транзакций: Результаты, представленные на рис. 5a, показывают, что все протоколы обеспечивают выполнение операций чтения без блокировок, так что пропускная способность близка к той, которую можно было бы получить в отсутствие какого бы то ни было управления параллелизмом. Для всех протоколов пропускная способность почти одна и та же за исключением OCC и CALVIN. При использовании OCC пропускная способность ограничена накладными расходами на копирование метаданных записей для использования на фазе валидации, а также расходами на саму эту фазу. В случае CALVIN самая низкая пропускная способность является следствием «узкого места» в планировщике.
Рабочая нагрузка с умеренной конкуренцией: Как показывает рис. 5b, при наличии рабочей нагрузки со смесью читающих и обновляющих транзакций картина начинает меняться. Если рабочая нагрузка содержит обновляющие транзакции, проблемой становится конкуренция. Хотя при использовании всех протоколов пропускная способность системы с 64 серверами выше, чем на одном сервере, получаемый выигрыш ограничен. Пропускная способность возрастает в 1.7-3.8 раз. Хотя относительное повышение производительности лучше всех других протоколов демонстрирует CALVIN, наиболее высокую производительность при любом числе серверов обеспечивает NO_WAIT. В отличие от результатов на рабочей нагрузке из только читающих транзакций, при наличии более чем одного сервера OCC превосходит по производительности все другие протоколы, кроме NO_WAIT и CALVIN, поскольку выгода от того, что этот протокол допускает большее число конфликтов, перевешивает потребность в расходах на копирование и валидацию.
![]()
(a) Только читающие транзакции (нет конкуренции)
(b) Читающие и обновляющие транзакции (средняя конкуренция)
(с) Читающие и обновляющие транзакции (высокая конкуренция)
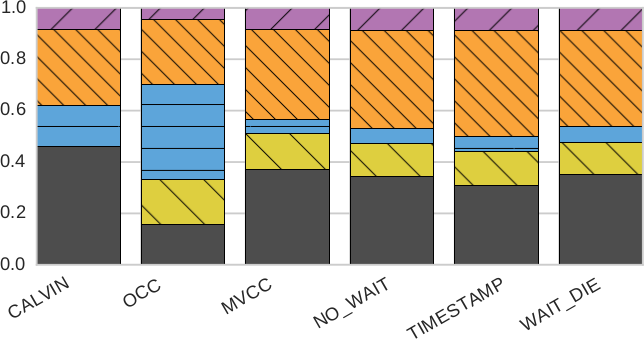
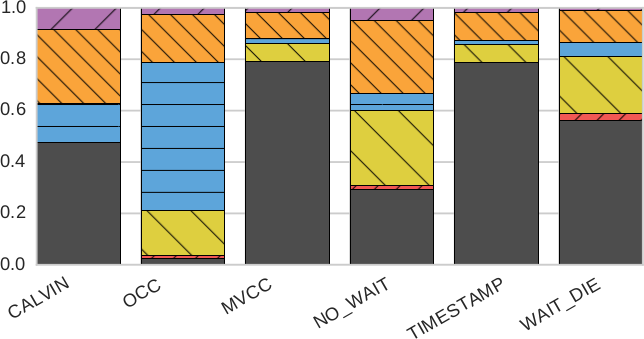
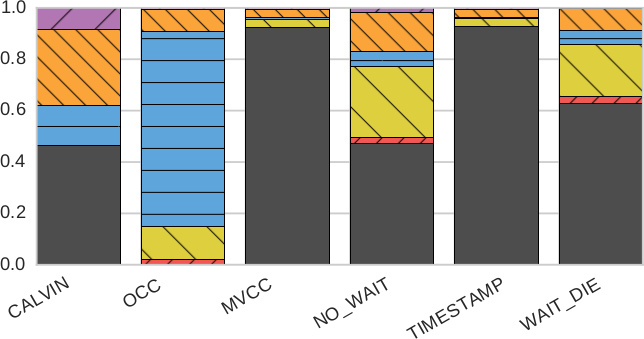
Рис. 6. Масштабируемость (разбиение по компонентам): процентное отношение времени, проведенного в разных компонентах Deneva, для разных протоколов управления параллелизмом с использованием одних и тех же вариантов рабочей нагрузки YCSB, что и на рис. 5, на 16 серверах
Если сравнить рис. 6a и 6b, то видно, что при наличии обновляющих транзакций для протоколов MVCC и TIMESTAMP возрастает доля времени простоя (IDLE). Это объясняется тем, что эти протоколы буферизуют большее число транзакций при ожидании завершения более старых транзакций.
![]()
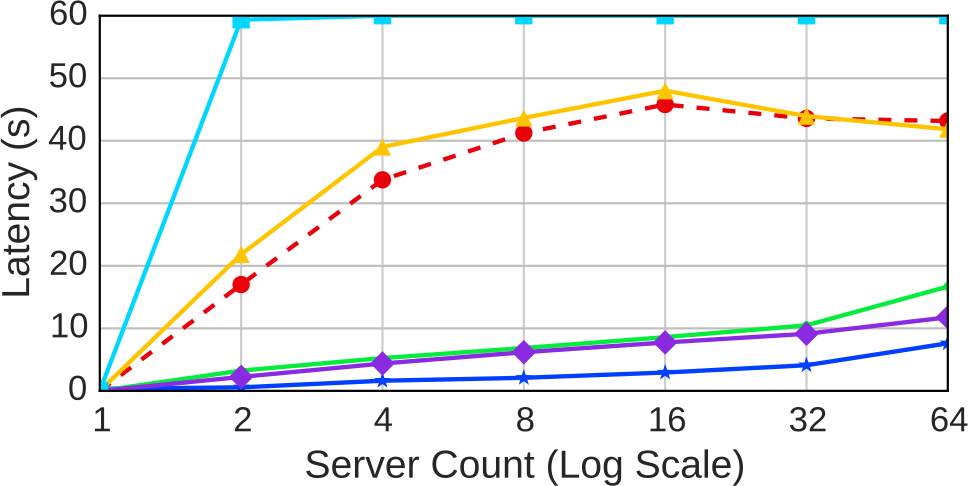
Рис. 7. 99-й процентиль задержки: задержка от первого старта транзакции до ее окончательной фиксации при изменении размера кластера
На рис. 7 показано, как возрастает 99-й процентиль[5] задержки при увеличении размеров кластера. Застывшее значение задержки для протокола WAIT_DIE получилось из-за того, что наивысшие значения задержек превышают время экспериментов[6].
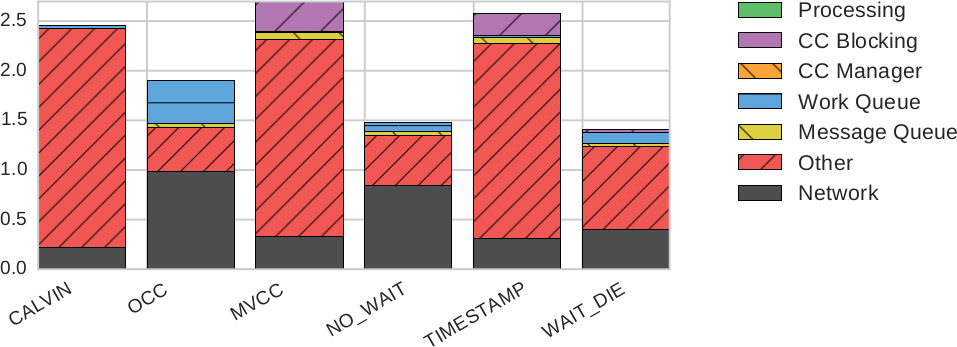
Рис. 8. Разбиение задержки по компонентам: среднее время задержки транзакции до фиксации
Для лучшего понимания того, где каждая транзакция тратит свое время, на рис. 8 показано разбиение по компонентам среднего значения задержки успешных транзакций (от самого последнего рестарта до окончательной фиксации) в кластере с 16 узлами. Время, затрачиваемое на обработку транзакций и управление параллелизмом, несравненно меньше времени блокирования транзакций в соответствии с протоколом, времени ожидания в очередях на обработку и сетевых задержек. Мы видим, что при использовании OCC транзакции проводят большую часть времени в очередях. Хотя поначалу в это трудно поверить, заметим, что в случае OCC рабочие нити тратят более половины времени на валидацию. Очереди на обработку возникают, когда транзакции по естественным причинам откатываются и ожидают доступности следующей рабочей нити. Так что в случае OCC валидация является узким местом и производительности, и задержек.
При использовании протоколов на основе временных меток (MVCC и TIMESTAMP) наибольшая часть задержки связана с блокировками, свойственными этим протоколам. Это подтверждает гипотезу, что эти протоколы в принципе плохо работают при наличии высокого уровня конкуренции за записи, даже если транзакции не слишком часто аварийно завершаются. При успешном выполнении транзакций по протоколу NO_WAIT на величину задержки влияет только ожидание доступных рабочих нитей. Транзакции, успешно выполняемые по протоколу WAIT_DIE, также могут блокироваться.
Рабочая нагрузка с высоким уровнем конкуренции: Как показано на рис. 5c, повышение конкуренции еще больше ухудшает производительность всех протоколов, за исключением CALVIN. На кластере с наибольшим числом серверов недетерминированные протоколы обеспечивают изменение пропускной способности всего в 0.2-1.5 раза. Это означает, что при использовании таких протоколов система показывает производительность в 10% от той, какой бы она была в идеальном случае при линейной масштабируемости от числа серверов в кластере. При высокой конкуренции CALVIN показывает на кластере с наибольшим числом серверов повышение пропускной способности в 5.2 раз. Производительность этого протокола остается почти неизменной для всех результатов, представленных на рис. 5 и 6, независимо от уровня конкуренции и особенностей рабочей нагрузки.
Мы обнаружили, что протоколы чувствительны к модели транзакции. Поскольку мы допускаем в каждой транзакции выполнение не более 10 операций над базой данных и поддерживаем по одному разделу в каждом сервере, мы наблюдаем разное поведение системы в кластерных конфигурациях с более чем 10 серверами и в конфигурациях с меньшим числом серверов. Протоколы чувствительных и к конфигурации испытательного стенда. Например, протоколы 2PL чувствительны к величине временной задержки перезапуска транзакции после ее аварийного завершения. На пропускную способность влияет и объем загрузки системы. В частности, при использовании протоколов MVCC и TIMESTAMP увеличение загрузки позволяет обрабатывать и буферизовать большее число транзакций.
4.6 Скорость сети
В этом подразделе мы изолируем влияние задержки территориально распределенной сети (wide-area network, WAN) на производительность распределенной базы данных. Мы развернули два сервера и два клиента на одной двухпроцессорной машине с Intel Xeon CPU E7-4830 (16 ядер на процессор, 32 при использовании гиперпотоковой обработки). Мы внесли искусственную задержку между экземплярами серверов на стороне отправителя путем буферизации каждого сообщения на установленное время задержки до его посылки получателю. Коммуникации между клиентами и серверами не влияли на задержку сети.
![]()
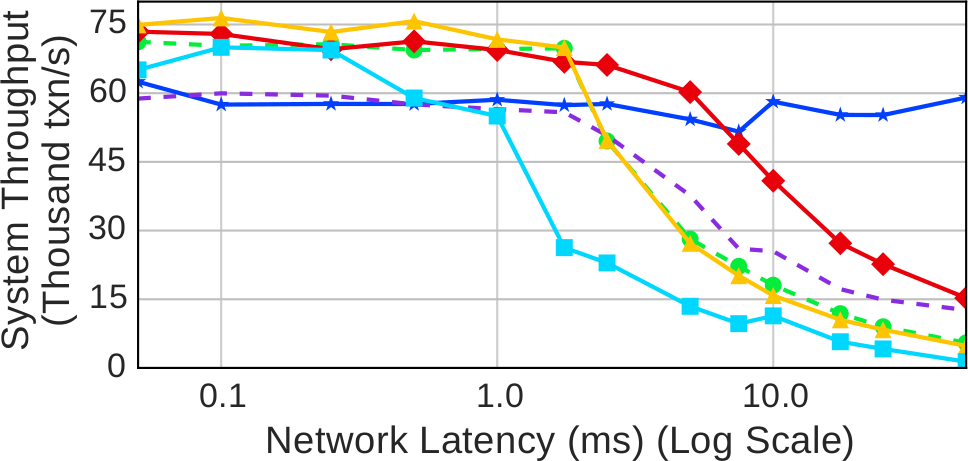
Рис. 9. Скорость сети – Устойчивая пропускная способность, измеренная при использовании разных протоколов управления параллелизмом на рабочей нагрузке YCSB при наличии искусственных задержек сети
Результаты на рис. 9 показывают, как падает производительность при увеличении задержки сети. В данном случае использовалась рабочая нагрузка YCSB со средним уровнем конкуренции и половиной обновляющих базу данных транзакций. Из-за большой изменчивости производительности системы в этой вычислительной среде результаты, представленные в этом разделе, представляют собой средние значения измерений в пяти экспериментах с удалением минимальной и максимальной пропускной способности.
Увеличение сетевой задержки приводит к увеличению длительности процесса двухфазной фиксации транзакций, что является основной причиной падения пропускной способности при наличии сетевой задержки, большей 1 мсек. Поскольку на тестовом наборе YCSB в протоколе CALVIN 2PC не используется, отсутствуют обмены сообщениями между серверами, и в этом случае при увеличении сетевой задержки пропускная способность не деградирует. Однако при использовании других протоколов протокол 2PC увеличивает время передачи блокировок между транзакциями. Удержание транзакциями блокировок 2PL в течение более продолжительных периодов времени, приводит в аварийному завершению или блокировке других транзакций. При использовании WAIT_DIE, поскольку блокировки в распределенных транзакциях удерживаются в течение большего времени, при наличии сетевой задержки, большей 1 мсек, относительное число конфликтующих транзакций, которые можно буферизовать, сокращается с примерно 45% до примерно 12%, что значительно увеличивает долю аварийно завершающихся транзакций. Кроме того, при увеличении сетевой задержки транзакция может дольше буферизоваться, прежде чем она аварийно завершится при следующем доступе к данным. При использовании TIMESTAMP и MVCC операции чтения и записи могут блокироваться еще не зафиксированными более старыми транзакциями. Однако эти протоколы более устойчивы к изменениям в задержке сети, чем WAIT_DIE, поскольку они буферизуют большинство транзакций и редко приводят к их аварийному завершению. Протокол NO_WAIT чаще вызывает аварийное завершение транзакций, чем протоколы на основе временных меток, но поскольку этот протокол не приводит к блокировке транзакций, блокировки удерживаются в течение меньшего времени, что позволяет продвигаться большему числу транзакций.
Табл. 2. Многорегиональный кластер – Пропускная способность двухузлового кластера с серверами в восточном и западном регионах AWS в США
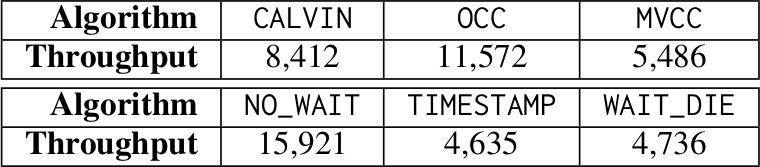
В табл. 2 приведены результаты измерения пропускной способности при рабочей нагрузке YCSB и реальных скоростях WAN. В этом эксперименте мы использовали узлы AWS регионов восточного побережья (Вирджиния) и западного побережья (Калифорния) для образования двухузлового кластера со связью на основе VPN. При сравнении с рис. 5b можно видеть, что протоколы работают хуже, чем в локальной сети. Влияние скорости сети обсуждается в подразделе 5.2.
4.7 Аварийное завершение в зависимости от данных
В описанных ранее экспериментах преимуществом протокола CALVIN было то, что он не нуждается в использовании двухфазной фиксации транзакций, и обмен сообщениями происходит только с секвенсором. Поскольку операции чтения и записи в рабочей нагрузке YCSB независимы и аварийные завершения транзакций не связаны с прочитанными ими данными, при использовании CALVIN не нужны сообщения между серверами в промежутке между фазами чтения и записи. Но при обработке рабочей нагрузки с такими свойствами на основе протокола CALVIN до завершения транзакции требуется обмен сообщениями между теми серверами, которые выполняют операции чтения для посылки сообщений другим серверами, и теми, которые принимают сообщения для последующего выполнения операций записи.
Для оценки эффекта аварийных завершений в зависимости от данных мы добавили в YCSB условный оператор, позволяющий моделировать логику выполнения транзакций, связанную с принятием решений об аварийном завершении. Затем эксперименты были повторены с использованием измененной рабочей нагрузки YCSB. Хотя для большинства протоколов влияние на пропускную способность ограничивалось 2-10%, при использовании CALVIN производительность на 16 серверах со средним уровнем конкуренции упала на 36% (theta=0.6, 50% обновляющих транзакций) по сравнению с исходной рабочей нагрузкой YCSB. Мы также обнаружили, что при возрастании уровня конкуренции с theta=0.8 до theta=0.9 пропускная способность CALVIN упала с 73k транзакций в секунду для 19k транзакций в секунду.
4.8 TPC-C
Затем мы тестировали протоколы с использованием более реалистичной рабочей нагрузки. Бенчмарк TPC-C показывает, как работают протоколы на рабочей нагрузки, в которой транзакции в основном являются однораздельными, а распределенные транзакции в основном затрагивают два раздела. На каждом сервере хранились разделы базы данных с информацией о 128 складах. Поскольку на каждом сервере хранились данные о нескольких складах, распределенная транзакция могла затрагивать два раздела, размещенных на одном и том же сервере.
![]()
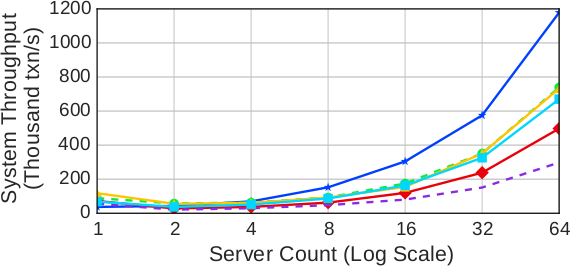
(a) Транзакция Payment
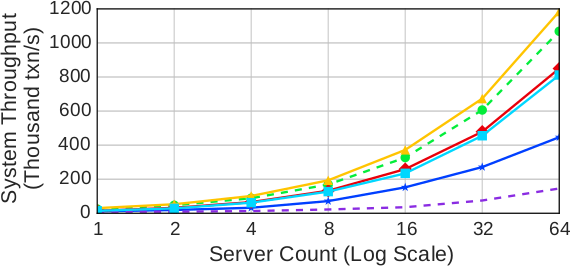
(b) Транзакция NewOrder
Рис. 10. TPC-C – Измеренная пропускная способность протоколов при масштабировании кластера со 128 складами на сервер
Результаты первого эксперимента на рис. 10a показывают, как масштабируется транзакция Payment. Узким местом является исходный склад, потому что для обновления платежных данных этого склада требуется монопольный доступ. Хотя это свойство ограничивает пропускную способность, оно не препятствует линейному масштабированию протоколов при возрастании числа серверов, уровня загрузки и числа складов. При использовании NO_WAIT и WAIT_DIE велика частота аварийных завершений транзакций из-за конфликтов по поводу исходного склада, что приводит к неоднократному перезапуску транзакций до их успешного завершения. У OCC тоже имеется высокая частота аварийных завершений из-за конфликтов по поводу исходного склада, что мешает находить бесконфликтные диапазоны для валидации транзакций. TIMESTAMP и MVCC в основном работают лучше других протоколов, поскольку при их использовании не тратится время на транзакции, которые будут аварийно завершены.
На рис. 10b показаны результаты для транзакции NewOrder. Здесь узким местом является обновление номера заказа D_NEXT_O_ID в районе сбыта транзакции. Но поскольку для каждого склада имеются 10 районов сбыта, возникающая конкуренция немного ниже, чем для транзакции Payment. Поэтому этой рабочей нагрузке недетерминированные протоколы, за исключением OCC, работают лучше, чем CALVIN.
4.9 Product-Parts-Supplier
В заключение мы исследовали масштабируемость протоколов с использованием тестового набора PPS. В отличие от других рабочих нагрузок, PPS содержит транзакции, обновляющие таблицы на основе поиска в внешнему ключу. Этот аспект рабочей нагрузки напрягает протокол CALVIN, поскольку для поиска внешних ключей он должен произвести разведку, а транзакции могут завершиться аварийным образом. Почти все протоколы масштабируются. CALVIN демонстрирует близкую к постоянной пропускную способность около 7k транзакций в секунду. Это вызвано несколькими факторами. Во-первых, для двух транзакций в рабочей нагрузке требуются разведывательные запросы для определения полного набора чтения и записи. Во-вторых, случайные обновления таблицы, отображающей продукты на компоненты, приводят к аварийному завершению других транзакций, поскольку их наборы чтения и записи становятся недействительными при выполнении обновляющей транзакции. Другим протоколам не свойственны аварийные завершения транзакций из-за изменения номеров компонентов. У OCC, как и у NO_WAIT, доля аварийно завершающихся транзакций составляет 15%. Однако, в отличие от NO_WAIT, протокол OCC должен откатывать полностью завершенную транзакцию, что приводит к непроизводительным затратам вычислительных и других ресурсов.
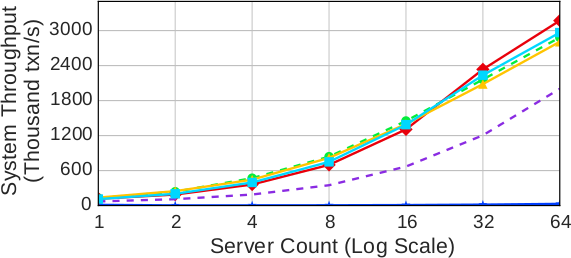
Рис. 11. Product-Parts-Supplier – пропускная способность при увеличении количества серверов на рабочей нагрузке PPS с поиском по внешнему ключу в 80% транзакций
5. Обсуждение
Экспериментальные результаты, представленные в предыдущем разделе, приводят к неоднозначным выводам по поводу общеупотребительных и недавно разработанных механизмов поддержки распределенных транзакций OLTP. С одной стороны, рабочие нагрузки с распределенными транзакциями могут масштабироваться, но в зависимости от свойств рабочей нагрузки может потребоваться крупный кластер, чтобы можно было превзойти производительность системы на одиночной машине. В этом разделе мы обсудим проблемы масштабирования, стоящие перед распределенными СУБД, а также некоторые следствия этих проблем.
Табл. 3. Сводка результатов – Обзор результатов экспериментов с протоколами управления параллелизмом, обобщенные по наличию узких мест (▼), преимуществ нал другими протоколами (▲) или оказанию минимального эффекта на производительность (–)

5.1 Узкие места распределенных СУБД
Наши результаты показывают, что всем протоколам, которые мы оценивали, свойственны проблемы масштабируемости. Наблюдавшиеся нами ограничивающие факторы резюмируются в табл. 3. Прежде всего, одним из основных факторов, ограничивающих пропускную способность, является протокол фиксации транзакций. В большинстве протоколов до фиксации требуется два цикла обменов сообщениями. Протокол CALVIN специально разрабатывался для смягчения влияния 2PC, но при наличии возможности аварийного завершения транзакции требуется широковещательная рассылка сообщений и сбор ответных сообщений до того, как транзакцию можно будет зафиксировать в ее локальном узле и освободить блокировки. Во всех случаях блокировки, удерживаемые при выполнении 2PC или при ожидании сообщений, ограничивают пропускную способность.
Другим узким местом распределенных СУБД является конфликты по данным. Здесь существенны два фактора. Во-первых, нет конфликтов при отсутствии изменений записей. Когда мы меняли долю операций обновления в рабочей нагрузке YCSB, мы обнаружили, что при наличии небольшого числа обновлений наиболее разумно использовать протокол с минимальными накладными расходами (2PL или протокол на основе временных меток). Эти протоколы быстро деградируют при возрастании числа операций записи, и при превышении некоторого порогового значения лучшим выбором становятся оптимистический или детерминированный протоколы. Во-вторых, частота возникновения конфликтов определяется частотой чтения и изменения наиболее востребованных записей. На рабочей нагрузке YCSB 2PL и протокол на основе временных меток работали лучше всего при наличии малой скошенности. Как только скошенность становится достаточно большой, чтобы одновременно выполняемые транзакции обращались к одним и тем же записям, производительность этих протоколов резко падает. Оптимистический протокол немного более устойчив к высокому уровню скошенности, но когда он достигает критической точки, наиболее устойчивым протоколом становится CALVIN.
5.2 Потенциальные решения
С учетом этой мрачной перспективы обсудим потенциальные решения проблем распределенных протоколов управления параллелизмом.
Совершенствование сети: В конечном счете, масштабированию препятствует использование сети – определяющее свойство распределенных транзакций. Соответственно, естественным направлением к улучшению масштабируемости является повышение производительности сети. Доступная сегодня публичная облачная инфраструктура обеспечивает разумную производительность, но она далека от новейших достижений. В наилучших сегодняшних частных центрах данных обеспечивается полная пропускная способность сечения между серверами и значительно меньшие задержки. При использовании ранее экзотической, но все более распространенной аппаратной поддержки, включая RDMA и RoCE[7], накладные расходы на поддержку распределенных транзакций также могут резко снижаться: задержка доставки сообщения в 5 мс позволяет добиться значительно большего параллелизма, чем задержки в 500 мс, которые возникают в сегодняшней облачной инфраструктуре. В ряде современных протоколов поддерживаются эти аппаратные возможности (разд. 6).
Хотя совершенствование сетевого оборудования приносит значительную пользу современным системам обработки транзакций в пределах одного центра данных, работа c несколькими центрами данных остается проблематичной. Несмотря на недавнюю впечатляющую демонстрацию возможностей квантовой запутанности[8], скорость света устанавливает труднопреодолимую верхнюю границу скорости работы сети. При отсутствии каналов прямой видимости широкомасштабные коммуникации являются намного более дорогими. Поэтому сериализация транзакций в глобальной сети, по-видимому, останется дорогостоящей в течение неопределенного времени.
В результате мы можем получить возможность улучшений в пределах одного центра данных – при условии принятия, доступности и стабильности ранее нерыночных аппаратных средств, – для при использовании нескольких центров данных это нетривиально. Связанный сценарий развертывания, заслуживающий, по нашему мнению, более пристального внимания, опирается на все более активное распространение мобильных сенсорных устройств. В то время как Интернет вещей продолжает оставаться туманным, для обеспечения его распределенности и параллелизма в будущем требуется решать проблемы масштабируемости, связанные с ограничениями функционирования сетей.
Настройка модели данных: Распределенные транзакции являются дорогостоящими, но транзакции, выполняемые в одном узле, обходятся относительно дешево. В результате приложения, в которых транзакции выражаются способом, делающим их пригодными для одноузлового выполнения, не подвергаются издержкам, исследуемым в нашей статье.
Первичной стратегией для достижения одноузлового функционирования является разделение данных (partitioning) в рамках модели данных. Примером может служить подход Хелланда [31], в котором любой транзакции разрешается обновлять данные только из одного набора данных, возможно, иерархического и помещающегося на одном сервере. Это неизбежно ограничивает класс возможных приложений (например, СУБД не может поддерживать ссылочные ограничения между группами сущностей) и по существу переносит бремя на плечи разработчиков приложений. Тем не менее, для легко разделяемых приложений (один из авторов в середине 1980-х называл такие приложения «восхитительными» (delightful)) модель групп сущностей позволяет решить проблему распределенных транзакций.
В то же время, исследовательское сообщество разработало методы автоматического разделения приложений, как статические, так и динамические [22, 43, 23]. Эти методы являются многообещающими, хотя их массового применения еще предстоит добиться.
Поиск альтернативных моделей программирования: Если принимать во внимание стоимость сериализации, разумно пробовать найти альтернативные подходы. Часто в обсуждениях несериализуемого поведения сериализуемость и согласованность приложений противопоставляется трудным для понимания и чреватых ошибками альтернативам. Полезно помнить, что сериализуемость – это средство достижения согласованности на уровне приложений, но это средство не является строго необходимым. Несмотря на то, что многие существующие определения несериализуемой изоляции (например, изоляция с чтением зафиксированных данных (Read Committed isolation) [2] и согласованность в конечном счете (eventual consistency) [10]) являются сложны для использования, это не обязательно значит, что такими же обязательно должны являться сериализуемые интерфейсы программирования. Например, недавно предложенный протокол Homeostasis [46] анализирует возможности несериализуемого выполнения программ и выполняет части пользовательского кода несериализуемым способом, не заставляя выявлять эти части программиста или пользователя. Анализ конфлюентности инвариантов [6] показывает, что многие общие ограничения баз данных можно поддерживать без распределенной координации, допуская масштабируемое, но согласующееся со спецификацией выполнение TPC-C без потребности в распределенных транзакциях. Соответствующие результаты сообществ систем [8] и языков программирования [48] показывают схожие перспективы.
На самом деле, эта альтернатива дает толчок к повторному исследованию так называемых методов управления параллелизмом на основе семантики [52]. При отсутствии информации о семантике приложений сериализуемость, по сути, является «оптимальной» стратегией для обеспечения согласованности приложений [37]. Учитывая наблюдаемые нами проблемы с масштабируемостью, мы полагаем целесообразным исследовать методы проталкивания дополнительной семантики в сервер баз данных. Фактически, в одном из исследований было отмечено, что разработчики приложений для веб-фреймворков (например, Ruby on Rails) уже используют нетранзакционные интерфейсы для выражения критериев согласованности своих приложений [5]. Это создает прекрасную возможность для пересмотра понятия транзакции и использования альтернативных моделей программирования.
Резюме: Имеются несколько направлений для поиска решений: применение новых аппаратных средств, использование усовершенствованных моделей данных или анализа программ. Мы считаем, что каждое из этих направлений потенциально плодотворно, обеспечивает много возможностей как для инновационных исследований, так и для значительных улучшений производительности и масштабируемости
6. Родственные работы
Начиная с 1980-х гг., предпринималось несколько попыток сравнения архитектур систем обработки транзакций. Во многих ранних исследованиях использовались методы моделирования [42, 3, 14, 13, 16], но иногда выполнялся сравнительный экспериментальный анализ, подобный описываемому в данной статье [32]. Позднее в проекте OLTP-Bench был разработан стандартизованный набор рабочих нагрузок OLTP [24], а в BigBench [29], BigDataBench [57] и Chen et al. [18] был представлен ряд тестовых наборов и рабочих нагрузок для аналитических сред Big Data. В родственных работах [15, 56, 36] исследуются платформы облачных вычислений и многоарендаторные (multi-tenant) рабочие нагрузки, а в Rabl et al. [44] исследуются различные распределенные базы данных, только одна из которых является транзакционной. Мы продолжаем эту традицию эмпирического анализа систем, разрабатывая фреймворк Deneva и оценивая производительность шести протоколов в инфраструктуре облачных вычислений. Насколько нам известно, это наиболее глубокое исследование с использованием современной аппаратуры. Видимо, наиболее близким к нашей работе является недавнее исследование протоколов управления параллелизмом на одиночном сервере с 1000 процессорных ядер [60].
Наши результаты согласуются с выводами предыдущих исследований, но содержат важные отличия из-за масштабности и особенностей операционной среды облачной инфраструктуры. Например, Agrawal et al. [3] утверждают, что оптимистические методы являются исключительно дорогими при наличии аварийного завершения транзакций, и что пессимистические методы могут обеспечить более устойчивое поведение. Наши результаты показывают, что оптимистические методы работают хорошо, но только в идеальных условиях. Кроме того, в распределенной среде к важным последствиям приводят задержки сообщений в то время, как, например, Carey and Livny [16] анализируют процессорные расходы на посылку и принятие сообщений вместо задержек сообщений. Мы показали, что сетевые задержки существенно влияют на эффективность, и это привело к заключению, что более быстрая сетевая аппаратура является перспективным средством повышения производительности. В облачной среде рабочая нагрузка, для которой обеспечивается максимальная производительность, часто отличается от той, которая уместна для одиночного сервера или имитируемой сети (особенно явственно это заметно при сравнении со средой 1000-ядерного процессора [60]).
В своей работе мы исследовали шесть протоколов управления параллелизмом для поддержки сериализуемости в распределенной среде. Как мы отмечали в табл. 1, имеется множество альтернатив, и новые протоколы предлагаются каждый год [7, 20, 21, 25, 26, 27, 39, 41, 47, 54, 58, 61, 62]. Во многих из них используются варианты подходов, исследуемых в нашей работе: например, Spanner [20] and Wei et al. [58] реализуют двухфазную блокировку, Granola [21], VoltDB [1], H-Store [33] и Calvin [54] (протокол, который мы оценивали) основаны на детерминированных методах, а в Centiman [25], FaRM [26], Warp [27], MaaT [39], Rococo [41], F1 [47] и Tapir [61] реализуются варианты OCC. При наличии этой паноплии новых протоколов мы считаем, что это полностью созрела возможность провести анализ, подобный оригинальной деконструкции Бернштейна и Гудмана 1981 года тогдашних современных протоколов управления параллелизмом [11], когда они показали, как можно выразить почти все предлагаемые протоколы как варианты блокировок или временных меток. Мы считаем, что Deneva обеспечивает основу для количественной оценки производительности, обеспечиваемой этими протоколами, а также, как это обсуждается в разделе 7, заинтересованы в проведении такого анализа в будущем.
7. Направления дальнейших исследований
Мы видим несколько перспективных направлений будущих исследований применительно как к нашей оценочной инфраструктуре, так и к новым протоколам распределенного управления параллелизмом.
Во-первых, наше исследование фокусировалось на управлении параллелизмом для разделенных баз данных. Это решение позволило выделить узкие места масштабируемости в подсистеме управления параллелизмом и повлияло на организацию нашей инфраструктуры, которая поддерживает многораздельные сериализуемые транзакции. Мы заинтересованы в исследовании влияния как репликации (например, в сравнении протоколов «ведущий-ведущий» и «ведущий-ведомый»), так и восстановления после отказов (например, обход отказа (failover) – поведение при потери связности сети). В обоих случаях имеются нетривиальные воздействия на масштабируемость, которые мы намерены исследовать в будущем.
Во-вторых, наше исследование фокусируется на шести конкретных протоколах управления параллелизмом. Хотя это исследование является более полным, чем любое другое, отраженное в литературе, имеются недавно предложенные протоколы, эффективность которых (в лучшем случае) сравнивалась лишь с несколькими другими схемами. Мы заинтересованы в количественной оценке наиболее перспективных новых схем. Мы надеемся, что наличие инфраструктуры Deneva с открытыми кодами будет побуждать исследовательское сообщество интегрировать с ней их собственные протоколы. Для увеличения числа поддерживаемых рабочих нагрузок мы собираемся интегрировать инфраструктуру Deneva со средой бенчмаркинга OLTP-Bench [24]. Для этой интеграции придется позаботиться о некоторых протоколах, подобных CALVIN, для которых требуется заранее объявлять наборы чтения-записи, но это оправданная инженерная работа.
В-третьих, мы хотим исследовать эффект потенциальных решений, описанных в подразделе 5.2. Например, интеграция в Deneva RDMA и альтернативных сетевых технологий позволило бы справедливо оценить соответствующие расходы и выгоды. Было бы также интересно произвести прямое сравнительное исследование предложений по управлению параллелизмом на основе семантики, чтобы количественно проверить их обещанный в литературе потенциал для ускорений.
8. Заключение
Мы исследовали поведение сериализуемых распределенных транзакций в современной среде облачных вычислений. Мы изучили поведение шести классических и современных протоколов управления параллелизмом и показали, что для многих рабочих нагрузок пропускная способность распределенных транзакций в кластере лишь ненамного превосходит пропускную способность не распределенных транзакций в одиночной машине. Факторы, ограничивающие масштабируемость, различны для разных протоколов: двухфазные блокировки плохо работают при высоком уровне конкуренции из-за аварийных завершений транзакций, управление параллелизмом на основе временных меток плохо работает при высоком уровне конкуренции из-за буферизации, у оптимистического управления параллелизмов имеются большие накладные расходы на валидацию, и детерминированный протокол сохраняет производительность при наличии неблагоприятных рабочих нагрузок и скашивания данных, на эта производительность ограничена из-за потребности в планировании транзакций. По сути, эти результаты демонстрируют наличие серьезных проблем с масштабируемостью распределенных транзакций. Мы полагаем, что решение состоит в более тесной увязке механизмов управления параллелизмом как с аппаратными средствами, так и с приложениями путем комбинирования совершенствования сетевых средств в облачной инфраструктуре (хотя бы в пределах одного центра данных), моделирования данных и применения методов управления параллелизмом на основе семантики. Кроме того, мы хотим, чтобы инфраструктура Deneva стала платформой, открытой для других исследователей для получения строгих оценок новых и альтернативных методов управления параллелизмом и внесения ясности в часто запутанное пространство протоколов управления параллелизмом.
9. Благодарности
Мы хотели бы поблагодарить анонимных рецензентов VLDB за из полезные замечания и комментарии. Мы хотели бы также поблагодарить Питера Бэйлиса (Peter Bailis) за помощь в подготовке предварительного варианта этой статьи, а также Сянгяо Ю (Xiangyao Yu), Дэниеля Абади (Daniel Abadi), Алексендра Томпсона (Alexander Thomson) и Хосе Фалейро (Jose Faleiro) за ценные обсуждения.
10. Список литературы
- VoltDB. http://voltdb.com.
- A. Adya. Weak consistency: a generalized theory and optimistic implementations for distributed transactions. PhD thesis, MIT, 1999.
- R. Agrawal, M. J. Carey, and M. Livny. Concurrency control performance modeling: alternatives and implications. TODS, 12(4):609–654, 1987.
- P. Bailis, A. Davidson, A. Fekete, A. Ghodsi, J. M. Hellerstein, and I. Stoica. Highly Available Transactions: Virtues and limitations. In VLDB, 2014.
- P. Bailis et al. Feral Concurrency Control: An empirical investigation of modern application integrity. In SIGMOD, 2015.
- P. Bailis, A. Fekete, M. J. Franklin, A. Ghodsi, J. M. Hellerstein, and I. Stoica. Coordination Avoidance in Database Systems. In VLDB, 2015.
- M. Balakrishnan et al. Tango: Distributed data structures over a shared log. In SOSP, 2013.
- V. Balegas, S. Duarte, C. Ferreira, R. Rodrigues, N. Preguiça, M. Najafzadeh, and M. Shapiro. Putting consistency back into eventual consistency. In EuroSys, 2015.
- P. Bernstein, V. Hadzilacos, and N. Goodman. Concurrency control and recovery in database systems, volume 370. Addison-Wesley, 1987.
- P. A. Bernstein and S. Das. Rethinking eventual consistency. In SIGMOD, pages 923–928. ACM, 2013.
- P. A. Bernstein and N. Goodman. Concurrency control in distributed database systems. ACM Comput. Surv., 13(2):185–221, June 1981.
- P. A. Bernstein and N. Goodman. Multiversion Concurrency Control – Theory and Algorithms. ACM Trans. Database Syst., 8(4):465–483, Dec. 1983.
- A. Bhide, F. Bancilhon, and D. Dewitt. An analysis of three transaction processing architectures. In VLDB, 1988.
- A. Bhide and M. Stonebraker. A performance comparison of two architectures for fast transaction processing. In ICDE, 1988.
- C. Binnig, D. Kossmann, T. Kraska, and S. Loesing. How is the weather tomorrow? towards a benchmark for the cloud. In DBTest, 2009.
- M. J. Carey and M. Livny. Distributed concurrency control performance: A study of algorithms, distribution, and replication. In VLDB, pages 13–25, 1988.
- F. Chang, J. Dean, S. Ghemawat, et al. Bigtable: A distributed storage system for structured data. In OSDI, 2006.
- Y. Chen, S. Alspaugh, and R. Katz. Interactive analytical processing in big data systems: A cross-industry study of mapreduce workloads. In VLDB, 2012.
- B. F. Cooper, A. Silberstein, E. Tam, R. Ramakrishnan, and R. Sears. Benchmarking cloud serving systems with ycsb. SoCC, pages 143–154, 2010.
- J. C. Corbett et al. Spanner: Google’s globally-distributed database. In OSDI, 2012.
- J. Cowling and B. Liskov. Granola: low-overhead distributed transaction coordination. In USENIX ATC, 2012.
- C. Curino, E. Jones, Y. Zhang, and S. Madden. Schism: a workload-driven approach to database replication and partitioning. VLDB, 3(1-2):48–57, 2010.
- S. Das, D. Agrawal, and A. El Abbadi. G-store: a scalable data store for transactional multi key access in the cloud. In SoCC, pages 163–174, 2010.
- D. E. Difallah, A. Pavlo, C. Curino, and P. Cudre-Mauroux. OLTP-Bench: An extensible testbed for benchmarking relational databases. In VLDB, 2014.
- B. Ding, L. Kot, A. Demers, and J. Gehrke. Centiman: elastic, high performance optimistic concurrency control by watermarking. In SoCC, 2015.
- A. Dragojevi´c, D. Narayanan, E. B. Nightingale, M. Renzelmann, A. Shamis, A. Badam, and M. Castro. No compromises: distributed transactions with consistency, availability, and performance. In SOSP, 2015.
- R. Escriva, B. Wong, and E. G. Sirer. Warp: Multi-key transactions for keyvalue stores. United Networks, LLC, Tech. Rep, 5, 2013.
- K. P. Eswaran et al. The notions of consistency and predicate locks in a database system. Communications of the ACM, 19(11):624–633, 1976.
- A. Ghazal, T. Rabl, M. Hu, F. Raab, M. Poess, A. Crolotte, and H.-A. Jacobsen. Bigbench: towards an industry standard benchmark for big data analytics. In SIGMOD, pages 1197–1208, 2013.
- J. Gray, R. Lorie, G. Putzolu, and I. Traiger. Granularity of locks and degrees of consistency in a shared data base. Technical report, IBM, 1976.
- P. Helland. Life beyond distributed transactions: an apostate’s opinion. In CIDR, pages 132–141, 2007.
- J. Huang, J. A. Stankovic, K. Ramamritham, and D. F. Towsley. Experimental evaluation of real-time optimistic concurrency control schemes. In VLDB, 1991.
- R. Kallman et al. H-store: a high-performance, distributed main memory transaction processing system. In VLDB, 2008.
- D. Karger, E. Lehman, T. Leighton, R. Panigrahy, M. Levine, and D. Lewin. Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the world wide web. In STOC, pages 654–663, 1997.
- S. Kimball. Living without atomic clocks. https: //www.cockroachlabs.com/blog/living-without-atomic-clocks/, February 2016.
- R. Krebs, A. Wert, and S. Kounev. Multi-tenancy performance benchmark for web application platforms. In Web Engineering, pages 424–438. Springer, 2013.
- H.-T. Kung and C. H. Papadimitriou. An optimality theory of concurrency control for databases. In SIGMOD, 1979.
- H. T. Kung and J. T. Robinson. On Optimistic Methods for Concurrency Control. ACM Trans. Database Syst., 6(2):213–226, June 1981.
- H. A. Mahmoud, V. Arora, F. Nawab, D. Agrawal, and A. El Abbadi. Maat: Effective and scalable coordination of distributed transactions in the cloud. In VLDB, 2014.
- N. Malviya, A. Weisberg, S. Madden, and M. Stonebraker. Rethinking main memory oltp recovery. In ICDE, pages 604–615. IEEE, 2014.
- S. Mu, Y. Cui, Y. Zhang, W. Lloyd, and J. Li. Extracting more concurrency from distributed transactions. In OSDI, 2014.
- M. Nicola and M. Jarke. Performance modeling of distributed and replicated databases. TKDE, 12(4):645–672, 2000.
- A. Pavlo et al. Skew-aware automatic database partitioning in shared-nothing, parallel oltp systems. In SIGMOD, pages 61–72, 2012.
- T. Rabl, S. Gómez-Villamor, M. Sadoghi, V. Muntés-Mulero, H.-A. Jacobsen, and S. Mankovskii. Solving big data challenges for enterprise application performance management. In VLDB, 2012.
- K. Ren, A. Thomson, and D. J. Abadi. An Evaluation of the Advantages and Disadvantages of Deterministic Database Systems. Proc. VLDB Endow., 7(10):821–832, June 2014.
- S. Roy, L. Kot, G. Bender, B. Ding, H. Hojjat, C. Koch, N. Foster, and J. Gehrke. The homeostasis protocol: Avoiding transaction coordination through program analysis. In SIGMOD, 2015.
- J. Shute et al. F1: A distributed SQL database that scales. In VLDB, 2013.
- K. Sivaramakrishnan, G. Kaki, and S. Jagannathan. Declarative programming over eventually consistent data stores. In PLDI, 2015.
- M. Stonebraker. The case for shared nothing. IEEE Database Eng. Bull., 9, 1986.
- M. Stonebraker, S. Madden, D. J. Abadi, S. Harizopoulos, N. Hachem, and P. Helland. The end of an architectural era: (it’s time for a complete rewrite). VLDB, pages 1150–1160, 2007.
- M. Sustrik. nanomsg. http://nanomsg.org.
- M. Tamer Özsu and P. Valduriez. Principles of distributed database systems. Springer, 2011.
- A. Thomson and D. J. Abadi. The case for determinism in database systems. Proc. VLDB Endow., 3:70–80, September 2010.
- A. Thomson, T. Diamond, S.-C. Weng, K. Ren, P. Shao, and D. J. Abadi. Calvin: Fast distributed transactions for partitioned database systems. In SIGMOD, 2012.
- Transaction Processing Performance Council. TPC Benchmark C (Revision 5.11), February 2010.
- A. Turner, A. Fox, J. Payne, and H. S. Kim. C-mart: Benchmarking the cloud. IEEE TPDS, 24(6):1256–1266, 2013.
- L. Wang, J. Zhan, C. Luo, Y. Zhu, Q. Yang, Y. He, W. Gao, Z. Jia, Y. Shi, S. Zhang, et al. BigDataBench: A big data benchmark suite from internet services. In HPCA, pages 488–499. IEEE, 2014.
- X. Wei, J. Shi, Y. Chen, R. Chen, and H. Chen. Fast in-memory transaction processing using RDMA and HTM. In SOSP, 2015.
- M. Welsh, D. Culler, and E. Brewer. Seda: an architecture for well-conditioned, scalable internet services. In SOSP, pages 230–243, 2001.
- X. Yu, G. Bezerra, A. Pavlo, S. Devadas, and M. Stonebraker. Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores. In VLDB, 2014.
- I. Zhang, N. K. Sharma, A. Szekeres, A. Krishnamurthy, and D. R. Ports. Building consistent transactions with inconsistent replication. In SOSP, 2015.
- Y. Zhang et al. Transaction chains: achieving serializability with low latency in geo-distributed storage systems. In SOSP, 2013.
https://github.com/mitdbg/deneva ↑
https://en.wikipedia.org/wiki/Marshalling_(computer_science) (прим. переводчика) ↑
По поводу распределения, или закона Зипфа авторы [19] ссылаются на статью J. Gray et al. Quickly generating billion-record synthetic databases, ACM SIGMOD Record, vol. 23, no. 2, June 1994, pp. 243-252. Статья доступна, например, здесь: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/syntheticdatagen.pdf (прим. переводчика). ↑
Так в тексте статьи. Понятно, что это среднее значение не может быть больше единицы. К сожалению, мне не удалось найти исправление этой опечатки (прим. переводчика). ↑
Вот самое простое, какое удалось мне найти, определение термина «процентиль»: «Процентиль — мера, в которой процентное значение общих значений равно этой мере или меньше ее. Например, 90 % значений данных находятся ниже 90-го процентиля, а 10 % значений данных находятся ниже 10-го процентиля.», https://docs.tibco.com/pub/spotfire_web_player/6.0.0-november-2013/ru-RU/WebHelp/GUID-10AD38BA-A888-4CEB-B716-44E2E02C8B03.html (прим. переводчика) ↑
В оригинале статьи написано «OCC’s 99%ile latency appears to drop because the longest transaction latencies would exceed the duration of the experiment», но по цвету «застывшего» графика можно судить, что он относится к WAIT_DIE. В чем в точности состоит ошибка авторов, мне установить не удалось (прим. переводчика). ↑
RDMA (remote direct memory access, удалённый прямой доступ к памяти) – аппаратное решение для обеспечения прямого доступа к оперативной памяти другого компьютера (https://en.wikipedia.org/wiki/Remote_direct_memory_access). RoCE (RDMA over Converged Ethernet) – сетевой протокол, обеспечивающий удалённый прямой доступ к памяти в сетях Etnernet (https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet) (прим. переводчика). ↑
Quantum entanglement (https://en.wikipedia.org/wiki/Quantum_entanglement) (прим. переводчика). ↑