Безопасность программного обеспечения компьютерных систем.
Казарин О.В.
www.cryptography.ru
ГЛАВА 3. ОБЕСПЕЧЕНИЕ ЭКСПЛУАТАЦИОННОЙ БЕЗОПАСНОСТИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
3.1. МЕТОДЫ И СРЕДСТВА ЗАЩИТЫ ПРОГРАММ ОТ КОМПЬЮТЕРНЫХ ВИРУСОВ
3.1.1. Общая характеристика и классификация компьютерных вирусов
Под компьютерным вирусом (или просто вирусом) понимается автономно функционирующая программа, обладающая способностью к самостоятельному внедрению в тела других программ и последующему самовоспроизведению и самораспространению в информационно-вычислительных сетях и отдельных ЭВМ [3,5,16,59,65]. Предшественниками вирусов принято считать так называемые троянские программы, тела которых содержат скрытые последовательности команд (модули), выполняющие действия, наносящие вред пользователям. Наиболее распространенной разновидностью троянских программ являются широко известные программы массового применения (редакторы, игры, трансляторы и т.д.), в которые встроены так называемые "логические бомбы", срабатывающие по наступлении некоторого события. Следует отметить, что троянские программы не являются саморазмножающимися.
Принципиальное отличие вируса от троянской программы состоит в том, что вирус после его активизации существует самостоятельно (автономно) и в процессе своего функционирования заражает (инфицирует) программы путем включения (имплантации) в них своего текста. Таким образом, компьютерный вирус можно рассматривать как своеобразный "генератор троянских программ". Программы, зараженные вирусом, называются вирусоносителями.
Заражение программы, как правило, выполняется таким образом, что-бы вирус получил управление раньше самой программы. Для этого он либо встраивается в начало программы, либо имплантируется в ее тело так, что первой командой зараженной программы является безусловный переход на компьютерный вирус, текст которой заканчивается аналогичной командой безусловного перехода на команду вирусоносителя, бывшую первой до заражения. Получив управление, вирус выбирает следующий файл, заражает его, возможно, выполняет какие-либо другие действия, после чего отдает управление вирусоносителю.
"Первичное" заражение происходит в процессе поступления инфицированных программ из памяти одной машины в память другой, причем в качестве средства перемещения этих программ могут использоваться как магнитные носители (дискеты), так и каналы вычислительных сетей. Ви-русы, использующие для размножения сетевые средства, принято называть сетевыми. Цикл жизни вируса обычно включает следующие периоды: внедрение, инкубационный, репликации (саморазмножения) и проявления. В течение инкубационного периода вирус пассивен, что усложняет задачу его поиска и нейтрализации. На этапе проявления вирус выполняет свойственные ему целевые функции, например необратимую коррекцию информации в компьютере или на магнитных носителях.
Физическая структура компьютерного вируса достаточно проста. Он состоит из головы и, возможно, хвоста. Под головой вируса понимается его компонента, получающая управление первой. Хвост - это часть вируса, расположенная в тексте зараженной программы отдельно от головы. Вирусы, состоящие из одной головы, называют несегментированными, тогда как вирусы, содержащие голову и хвост - сегментированными.
Наиболее существенные признаки компьютерных вирусов позволяют провести следующую их классификацию. По режиму функционирования:
- резидентные вирусы - вирусы, которые после активизации посто-янно находятся в оперативной памяти компьютера и контролируют доступ к его ресурсам;
- транзитные вирусы - вирусы, которые выполняются только в момент запуска зараженной программы.
По объекту внедрения:
- файловые вирусы - вирусы, заражающие файлы с программами;
- загрузочные (бутовые) вирусы - вирусы, заражающие программы, хранящиеся в системных областях дисков.
В свою очередь файловые вирусы подразделяются на вирусы, заражающие:
- исполняемые файлы;
- командные файлы и файлы конфигурации;
- составляемые на макроязыках программирования, или файлы, содержащие макросы (макровирусы);
- файлы с драйверами устройств;
- файлы с библиотеками исходных, объектных, загрузочных и оверлейных модулей, библиотеками динамической компоновки и т.п.
Загрузочные вирусы подразделяются на вирусы, заражающие:
- системный загрузчик, расположенный в загрузочном секторе дискет и логических дисков;
- внесистемный загрузчик, расположенный в загрузочном секторе жестких дисков.
По степени и способу маскировки:
- вирусы, не использующие средств маскировки;
- stealth-вирусы - вирусы, пытающиеся быть невидимыми на основе контроля доступа к зараженным элементам данных;
- вирусы-мутанты (MtE-вирусы) - вирусы, содержащие в себе алгоритмы шифрования, обеспечивающие различие разных копий виру-са.
MtE-вирусы делятся на
- обычные вирусы-мутанты, в разных копиях которых различаются только зашифрованные тела, а расшифровщики совпадают;
- полиморфные вирусы, в разных копиях которых различаются не только зашифрованные тела, но их дешифровщики.
Наиболее распространенные типы вирусов характеризуются следующими основными особенностями.
Файловый транзитный вирус целиком размещается в исполняемом файле, в связи с чем он активизируется только в случае активизации вирусоносителя, а по выполнении необходимых действий возвращает управление самой программе. При этом выбор очередного файла для заражения осуществляется вирусом посредством поиска по каталогу. Файловый рези-дентный вирус отличается от нерезидентного логической структурой и общим алгоритмом функционирования. Резидентный вирус состоит из так называемого инсталлятора и программ обработки прерываний. Инсталлятор получает управление при активизации вирусоносителя и инфицирует оперативную память путем размещения в ней управляющей части вируса и замены адресов в элементах вектора прерываний на адреса своих программ, обрабатывающих эти прерывания. На так называемой фазе слежения, следующей за описанной фазой инсталляции, при возникновении ка-кого-либо прерывания управление получает соответствующая подпрограмма вируса. В связи с существенно более универсальной по сравнению с нерезидентными вирусами общей схемой функционирования, резидент-ные вирусы могут реализовывать самые разные способы инфицирования.
Наиболее распространенными способами являются инфицирование запускаемых программ, а также файлов при их открытии или чтении. Отличительной особенностью последних является инфицирование загрузочного сектора (бут-сектора) магнитного носителя. Голова бутового вируса всегда находится в бут-секторе (единственном для гибких дисков и одном из двух - для жестких), а хвост - в любой другой области носителя. Наиболее безопасным для вируса способом считается размещение хвоста в так называемых псевдосбойных кластерах, логически исключенных из числа доступных для использования.
Существенно, что хвост бутового вируса всегда содержит копию оригинального (исходного) бут-сектора. Механизм инфицирования, реализуемый бутовыми вирусами, например, при загрузке MS DOS, таков. При загрузке операционной системы с инфицированного диска вирус, в силу своего положения на нем (независимо от того, с дискеты или с винчестера производится загрузка), получает управление и копи-рует себя в оперативную память. Затем он модифицирует вектор прерываний таким образом, чтобы прерывание по обращению к диску обрабатывались собственным обработчиком прерываний вируса, и запускает загрузчик операционной системы. Благодаря перехвату прерываний бутовые вирусы могут реализовывать столь же широкий набор способов инфицирования и целевых функций, сколь и файловые резидентные вирусы.
Stealth-вирусы пользуются слабой защищенностью некоторых опера-ционных систем и заменяют некоторые их компоненты (драйверы дисков, прерывания) таким образом, что вирус становится невидимым (прозрачным) для других программ. Для этого заменяются функции DOS таким образом, что для зараженного файла подставляются его оригинальная копия и содержание, каким они были до заражения.
Полиморфные вирусы содержат алгоритм порождения дешифровщиков (с размером порождаемых дешифровщиков от 0 до 512 байтов) непохожих друг на друга. При этом в дешифровщиках могут встречаться практически все команды процессора Intel и даже использоваться некоторые специфические особенности его реального режимы функционирования.
Макровирусы распространяются под управлением прикладных про-грамм, что делает их независимыми от операционной системы. Подавляющее число макровирусов функционируют под управлением системы Microsoft Word for Windows. В то же время, известны макровирусы, рабо-тающие под управлением таких приложений как Microsoft Exel for Win-dows, Lotus Ami Pro, Lotus 1-2-3, Lotus Notes, в операционных системах фирм Microsoft и Apple [5].
Сетевые вирусы, называемые также автономными репликативными программами, или, для краткости, репликаторами, используют для размножения средства сетевых операционных систем. Наиболее просто реализуется размножение в тех случаях, когда сетевыми протоколами предусмотрен обмен программами. Однако, размножение возможно и в тех случаях, когда указанные протоколы ориентированы только на обмен сообщениями. Классическим примером реализации процесса размножения с использованием только стандартных средств электронной почты является уже упоминаемый репликатор Морриса [59]. Текст репликатора передается от одной ЭВМ к другой как обычное сообщение, постепенно заполняющее буфер, выделенный в оперативной памяти ЭВМ-адресата. В результате переполнения буфера, инициированного передачей, адрес возврата в программу, вызвавшую программу приема сообщения, замещается на адрес самого буфера, где к моменту возврата уже находится текст вируса.
Тем самым вирус получает управление и начинает функционировать на ЭВМ-адресате.
"Лазейки", подобные описанной выше и обусловленные особенностями реализации тех или иных функций в программном обеспечении, являются объективной предпосылкой для создания и внедрения репликаторов злоумышленниками. Эффекты, вызываемые вирусами в процессе реализации ими целевых функций, принято делить на следующие группы:
- искажение информации в файлах либо таблице размещения файлов (FAT-таблице), которое может привести к разрушению файловой системы в целом;
- имитация сбоев аппаратных средств;
- создание звуковых и визуальных эффектов, включая, например, отображение сообщений, вводящих оператора в заблуждение или затрудняющих его работу;
- инициирование ошибок в программах пользователей или операционной системы.
Теоретически возможно создание "вирусных червей" - разрушающих программ, которые незаметно перемещаются между узлами вычислительной сети, не нанося никакого вреда до тех пор, пока не доберутся до целевого узла. В нем программа размещается и перестает размножаться.
Поскольку в будущем следует ожидать появления все более и более скрытых форм компьютерных, уничтожение очагов инфекции в локальных и глобальных сетях не станет проще. Время компьютерных вирусов "общего назначения" уходит в прошлое.
3.1.2. Общая характеристика средств нейтрализации компьютерных вирусов
Наиболее распространенным средством нейтрализации ПВ являются антивирусные программы (антивирусы). Антивирусы, исходя из реализованного в них подхода к выявлению и нейтрализации вирусов, принято делить на следующие группы:
- детекторы;
- фаги;
- вакцины;
- прививки;
- ревизоры;
- мониторы.
Детекторы обеспечивают выявление вирусов посредством просмотра исполняемых файлов и поиска так называемых сигнатур - устойчивых последовательностей байтов, имеющихся в телах известных вирусов. Наличие сигнатуры в каком-либо файле свидетельствует о его заражении соответствующим вирусом. Антивирус, обеспечивающий возможность поиска различных сигнатур, называют полидетектором.
Фаги выполняют функции, свойственные детекторам, но, кроме того, "излечивают" инфицированные программы посредством "выкусывания" вирусов из их тел. По аналогии с полидетекторами, фаги, ориентированные на нейтрализацию различных вирусов, именуют полифагами.
В отличие от детекторов и фагов, вакцины по своему принципу действия подобны вирусам. Вакцина имплантируется в защищаемую программу и запоминает ряд количественных и структурных характеристик последней. Если вакцинированная программа не была к моменту вакцинации инфицированной, то при первом же после заражения запуске произойдет следующее. Активизация вирусоносителя приведет к получению управления вирусом, который, выполнив свои целевые функции, передаст управление вакцинированной программе. В последней, в свою очередь, сначала управление получит вакцина, которая выполнит проверку соответствия запомненных ею характеристик аналогичным характеристикам, полученным в текущий момент. Если указанные наборы характеристик не совпадают, то делается вывод об изменении текста вакцинированной программы вирусом. Характеристиками, используемыми вакцинами, могут быть длина программы, ее контрольная сумма и т.д.
Принцип действия прививок основан на учете того обстоятельства, что любой вирус, как правило, помечает инфицируемые программы каким-либо признаком с тем, чтобы не выполнять их повторное заражение. В ином случае имело бы место многократное инфицирование, сопровождаемое существенным и поэтому легко обнаруживаемым увеличением объема зараженных программ. Прививка, не внося никаких других изменений в текст защищаемой программы, помечает ее тем же признаком, что и вирус, который, таким образом, после активизации и проверки наличия указанного признака, считает ее инфицированной и "оставляет в покое".
Ревизоры обеспечивают слежение за состоянием файловой системы, используя для этого подход, аналогичный реализованному в вакцинах. Программа-ревизор в процессе своего функционирования выполняет применительно к каждому исполняемому файлу сравнение его текущих харак-теристик с аналогичными характеристиками, полученными в ходе предшествующего просмотра файлов. Если при этом обнаруживается, что, согласно имеющейся системной информации, файл с момента предшествующего просмотра не обновлялся пользователем, а сравниваемые наборы характеристик не совпадают, то файл считается инфицированным. Характеристики исполняемых файлов, получаемые в ходе очередного просмотра, запоминаются в отдельном файле (файлах), в связи с чем увеличения длин исполняемых файлов, имеющего место при вакцинации, в данном случае не происходит. Другое отличие ревизоров от вакцин состоит в том, что каждый просмотр исполняемых файлов ревизором требует его повторного запуска.
Монитор представляет собой резидентную программу, обеспечивающую перехват потенциально опасных прерываний, характерных для вирусов, и запрашивающую у пользователей подтверждение на выполнение операций, следующих за прерыванием. В случае запрета или отсутствия подтверждения монитор блокирует выполнение пользовательской программы. Антивирусы рассмотренных типов существенно повышают вирусозащищенность отдельных ПЭВМ и вычислительных сетей в целом, однако, в связи со свойственными им ограничениями, естественно, не являются панацеей. В работе [54] приведены основные недостатки при использовании антивирусов.
В связи с этим необходима реализация альтернативных подходов к нейтрализации вирусов: создание операционных систем, обладающих высокой вирусозащищенностью по сравнению с наиболее "вирусодружественной" MS DOS, разработка аппаратных средств защиты от вирусов и соблюдение технологии защиты от вирусов.
3.1.3. Классификация методов защиты от компьютерных вирусов
Проблему защиты от вирусов необходимо рассматривать в общем контексте проблемы защиты информации от несанкционированного доступа и технологической и эксплуатационной безопасности ПО в целом. Основной принцип, который должен быть положен в основу разработки технологии защиты от вирусов, состоит в создании многоуровневой распределенной системы защиты, включающей:
- регламентацию проведения работ на ПЭВМ,
- применение программных средств защиты,
- использование специальных аппаратных средств.
При этом количество уровней защиты зависит от ценности информации, которая обрабатывается на ПЭВМ. Для защиты от компьютерных вирусов в настоящее время использу-ются следующие методы: Архивирование. Заключается в копировании системных областей магнитных дисков и ежедневном ведении архивов измененных файлов.
Архивирование является одним из основных методов защиты от вирусов. Остальные методы защиты дополняют его, но не могут заменить полностью.
Входной контроль. Проверка всех поступающих программ детекторами, а также проверка длин и контрольных сумм вновь поступающих программ на соответствие значениям, указанным в документации. Большинство известных файловых и бутовых вирусов можно выявить на этапе входного контроля. Для этой цели используется батарея (несколько последовательно запускаемых программ) детекторов. Набор детекторов достаточно широк, и постоянно пополняется по мере появления новых вирусов. Однако при этом могут быть обнаружены не все вирусы, а только распознаваемые детектором. Следующим элементом входного контроля является контекстный поиск в файлах слов и сообщений, которые могут принадлежать вирусу (например, Virus, COMMAND.COM, Kill и т.д.). Подозрительным является отсутствие в последних 2-3 килобайтах файла текстовых строк - это может быть признаком вируса, который шифрует свое тело.
Рассмотренный контроль может быть выполнен с помощью специальной программы, которая работает с базой данных "подозрительных" слов и сообщений, и формирует список файлов для дальнейшего анализа. После проведенного анализа новые программы рекомендуется несколько дней эксплуатировать в карантинном режиме. При этом целесообразно использовать ускорение календаря, т.е. изменять текущую дату при повторных запусках программы. Это позволяет обнаружить вирусы, срабатывающие в определенные дни недели (пятница, 13 число месяца, воскресенье и т.д.).
Профилактика. Для профилактики заражения необходимо организовать раздельное хранение (на разных магнитных носителях) вновь поступающих и ранее эксплуатировавшихся программ, минимизация периодов доступности дискет для записи, разделение общих магнитных носителей между конкретными пользователями.
Ревизия. Анализ вновь полученных программ специальными средствами (детекторами), контроль целостности перед считыванием информации, а также периодический контроль состояния системных файлов.
Карантин. Каждая новая программа проверяется на известные типы вирусов в течение определенного промежутка времени. Для этих целей целесообразно выделить специальную ПЭВМ, на которой не проводятся другие работы. В случае невозможности выделения ПЭВМ для карантина программного обеспечения, для этой цели используется машина, отключенная от локальной сети и не содержащая особо ценной информации.
Сегментация. Предполагает разбиение магнитного диска на ряд логических томов (разделов), часть из которых имеет статус READ_ONLY (только чтение). В данных разделах хранятся выполняемые программы и системные файлы. Базы данных должны хранится в других секторах, отдельно от выполняемых программ. Важным профилактическим средством в борьбе с файловыми вирусами является исключение значительной части загрузочных модулей из сферы их досягаемости. Этот метод называется сегментацией и основан на разделении магнитного диска (винчестера) с помощью специального драйвера, обеспечивающего присвоение отдельным логическим томам атрибута READ_ONLY (только чтение), а также поддерживающего схемы парольного доступа. При этом в защищенные от записи разделы диска помещаются исполняемые программы и системные утилиты, а также системы управления базами данных и трансляторы, т.е. компоненты ПО, наиболее подверженные опасности заражения. В качестве такого драйвера целесообразно использовать программы типа ADVANCED DISK MANAGER (программа для форматирования и подготовки жесткого диска), которая не только позволяет разбить диск на разделы, но и организовать доступ к ним с помощью паролей. Количество ис-пользуемых логических томов и их размеры зависят от решаемых задач и объема винчестера. Рекомендуется использовать 3 - 4 логических тома, причем на системном диске, с которого выполняется загрузка, следует оставить минимальное количество файлов (системные файлы, командный процессор, а также программы - ловушки).
Фильтрация. Заключается в использовании программ - сторожей, для обнаружения попыток выполнить несанкционированные действия.
Вакцинация. Специальная обработка файлов и дисков, имитирующая сочетание условий, которые используются некоторым типом вируса для определения, заражена уже программа или нет.
Автоконтроль целостности. Заключается в использовании специальных алгоритмов, позволяющих после запуска программы определить, были ли внесены изменения в ее файл.
Терапия. Предполагает дезактивацию конкретного вируса в заражен-ных программах специальными программами (фагами). Программыфаги "выкусывают" вирус из зараженной программы и пытаются восстановить ее код в исходное состояние (состояние до момента заражения). В общем случае технологическая схема защиты может состоять из следующих этапов:
- входной контроль новых программ;
- сегментация информации на магнитном диске;
- защита операционной системы от заражения;
- систематический контроль целостности информации.
Необходимо отметить, что не следует стремиться обеспечить гло-бальную защиту всех файлов, имеющихся на диске. Это существенно затрудняет работу, снижает производительность системы и, в конечном счете, ухудшает защиту из-за частой работы в открытом режиме. Анализ по-казывает, что только 20-30% файлов должно быть защищено от записи.
При защите операционной системы от вирусов необходимо правиль-ное размещение ее и ряда утилит, которое можно гарантировать, что после начальной загрузки операционная система еще не заражена резидентным файловым вирусом. Это обеспечивается при размещении командного про-цессора на защищенном от записи диске, с которого после начальной загрузки выполняется копирование на виртуальный (электронный) диск. В этом случае при вирусной атаке будет заражен дубль командного процес-сора на виртуальном диске. При повторной загрузке информация на вирту-альном диске уничтожается, поэтому распространение вируса через командный процессор становится невозможным.
Кроме того, для защиты операционной системы может применяться нестандартный командный процессор (например, командный процессор 4DOS, разработанный фирмой J.P.Software), который более устойчив к за-ражению. Размещение рабочей копии командного процессора на виртуальном диске позволяет использовать его в качестве программы-ловушки. Для этого может использоваться специальная программа, которая периодиче-ски контролирует целостность командного процессора, и информирует о ее нарушении. Это позволяет организовать раннее обнаружение факта вирусной атаки.
В качестве альтернативы MS DOS было разработано несколько опера-ционных систем, которые являются более устойчивыми к заражению. Из них следует отметить DR DOS и Hi DOS. Любая из этих систем более "вирусоустойчива", чем MS DOS. При этом, чем сложнее и опаснее вирус, тем меньше вероятность, что он будет работать на альтернативной операцион-ной системе.
Анализ рассмотренных методов и средств защиты показывает, что эффективная защита может быть обеспечена при комплексном использовании различных средств в рамках единой операционной среды. Для этого необходимо разработать интегрированный программный комплекс, под-держивающий рассмотренную технологию защиты. В состав программного комплекса должны входить следующие компоненты.
- Каталог детекторов. Детекторы, включенные в каталог, должны запускаться из операционной среды комплекса. При этом должна быть обеспечена возможность подключения к каталогу новых детекторов, а также указание параметров их запуска из диалоговой среды. С помощью данной компоненты может быть организована проверка ПО на этапе входного контроля.
- Программа-ловушка вирусов. Данная программа порождается в процессе функционирования комплекса, т.е. не хранится на диске, поэтому оригинал не может быть заражен. В процессе тестирования ПЭВМ программа - ловушка неоднократно выполняется, изменяя при этом текущую дату и время (организует ускоренный кален-дарь). Наряду с этим программа-ловушка при каждом запуске контролирует свою целостность (размер, контрольную сумму, дату и время создания). В случае обнаружения заражения программный комплекс переходит в режим анализа зараженной программы - ловушки и пытается определить тип вируса.
- Программа для вакцинации. Предназначена для изменения среды функционирования вирусов таким образом, чтобы они теряли спо-собность к размножению. Известно, что ряд вирусов помечает зараженные файлы для предотвращения повторного заражения. Используя это свойство возможно создание программы, которая обрабатывала бы файлы таким образом, чтобы вирус считал, что они уже заражены.
- База данных о вирусах и их характеристиках. Предполагается, что в базе данных будет храниться информация о существующих виру-сах, их особенностях и сигнатурах, а также рекомендуемая стратегия лечения. Информация из БД может использоваться при анализе зараженной программы-ловушки, а также на этапе входного контроля ПО. Кроме того, на основе информации, хранящейся в БД, можно выработать рекомендации по использованию наиболее эффективных детекторов и фагов для лечения от конкретного типа вируса.
- Резидентные средства защиты. Отдельная компонента может ре-зидентно разместиться в памяти и постоянно контролировать целостность системных файлов и командного процессора. Проверка может выполняться по прерываниям от таймера или при выполнении операций чтения и записи в файл.
3.2. МЕТОДЫ ЗАЩИТЫ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ОТ ВНЕДРЕНИЯ НА ЭТАПЕ ЕГО ЭКСПЛУАТАЦИИ И СОПРОВОЖДЕНИЯ ПРОГРАММНЫХ ЗАКЛАДОК
3.2.1. Классификация средств исследования программ
В этом подразделе мы будем исходить из предположения, что на этапе разработки программная закладка была обнаружена и устранена, либо ее вообще не было. Для привнесения программных закладок в этом случае необходимо взять готовый исполняемый модуль, дизассемблировать его и после внесения закладки подвергнуть повторной компиляции. Другой способ заключается в незаконном получении текстов исходных программ, их анализе, внесении программных дефектов и дальнейшей замене оригинальных программ на программы с приобретенными закладками. И, наконец, может осуществляться полная замена прикладной исполняемой программы на исполняемую программу нарушителя, что впрочем, требует от последнего необходимость иметь точные и полные знания целевого назначения и конечных результатов прикладной программы.
Все средства исследования ПО можно разбить на 2 класса: статиче-ские и динамические. Первые оперируют исходным кодом программы как данными и строят ее алгоритм без исполнения, вторые же изучают программу, интерпретируя ее в реальной или виртуальной вычислительной среде. Отсюда следует, что первые являются более универсальными в том смысле, что теоретически могут получить алгоритм всей программы, в том числе и тех блоков, которые никогда не получат управления. Динамические средства могут строить алгоритм программы только на основании конкретной ее трассы, полученной при определенных входных данных. Поэтому задача получения полного алгоритма программы в этом случае эквивалентна построению исчерпывающего набора текстов для подтвер-ждения правильности программы, что практически невозможно, и вообще при динамическом исследовании можно говорить только о построении некоторой части алгоритма.
Два наиболее известных типа программ, предназначенных для иссле-дования ПО, как раз и относятся к разным классам: это отладчик (динамическое средство) и дизассемблер (средство статистического исследования). Если первый широко применяется пользователем для отладки собственных программ и задачи построения алгоритма для него вторичны и реализуются самим пользователем, то второй предназначен исключительно для их решения и формирует на выходе ассемблерный текст алгоритма.
Помимо этих двух основных инструментов исследования, можно ис-пользовать:
- "дискомпиляторы", программы, генерирующие из исполняемого кода программу на языке высокого уровня;
- "трассировщики", сначала запоминающие каждую инструкцию, проходящую через процессор, а затем переводящие набор инструкций в форму, удобную для статического исследования, автоматически выделяя циклы, подпрограммы и т.п.;
- "следящие системы", запоминающие и анализирующие трассу уже не инструкции, а других характеристик, например вызванных программой прерывания.
3.2.2. Методы защиты программ от исследования
Для защиты программ от исследования необходимо применять методы защиты от исследования файла с ее исполняемым кодом, хранящемся на внешнем носителе, а также методы защиты исполняемого кода, загружаемого в оперативную память для выполнения этой программы.
В первом случае защита может быть основана на шифровании секрет-ной части программы, а во втором - на блокировании доступа к исполняемому коду программы в оперативной памяти со стороны отладчиков [17]. Кроме того, перед завершением работы защищаемой программы должен обнуляться весь ее код в оперативной памяти. Это предотвратит возмож-ность несанкционированного копирования из оперативной памяти дешифрованного исполняемого кода после выполнения защищаемой программы.
Таким образом, защищаемая от исследования программа должна включать следующие компоненты:
- инициализатор;
- зашифрованную секретную часть;
- деструктор (деициниализатор).
Инициализатор должен обеспечивать выполнение следующих функ-ций:
- сохранение параметров операционной среды функционирования (векторов прерываний, содержимого регистров процессора и т.д.);
- запрет всех внутренних и внешних прерываний, обработка кото-рых не может быть запротоколирована в защищаемой программе;
- загрузка в оперативную память и дешифрование кода секретной части программы;
- передача управления секретной части программы.
Секретная часть программы предназначена для выполнения основных целевых функций программы и защищается шифрованием для предупреждения внесения в нее программной закладки.
Деструктор после выполнения секретной части программы должен выполнить следующие действия:
- обнуление секретного кода программы в оперативной памяти;
- восстановление параметров операционной системы (векторов пре-рываний, содержимого регистров процессора и т.д.), которые были установлены до запрета неконтролируемых прерываний;
- выполнение операций, которые невозможно было выполнить при запрете неконтролируемых прерываний;
- освобождение всех незадействованных ресурсов компьютера и завершение работы программы.
Для большей надежности инициализатор может быть частично зашифрован и по мере выполнения может дешифровать сам себя. Дешифроваться по мере выполнения может и секретная часть программы. Такое дешифрование называется динамическим дешифрованием исполняемого кода. В этом случае очередные участки программ перед непосредственным исполнением расшифровываются, а после исполнения сразу уничтожаются.
Для повышения эффективности защиты программ от исследования необходимо внесение в программу дополнительных функций безопасности, направленных на защиту от трассировки. К таким функциям можно отнести:
- периодический подсчет контрольной суммы области оперативной памяти, занимаемой защищаемым исходным кодом; сравнение текущей контрольной суммы с предварительно сформированной эталонной и принятие необходимых мер в случае несовпадения;
- проверку количества занимаемой защищаемой программой опера-тивной памяти; сравнение с объемом, к которому программа адаптирована, и принятие необходимых мер в случае несоответствия;
- контроль времени выполнения отдельных частей программы;
- блокировку клавиатуры на время отработки особо секретных алго-ритмов.
Для защиты программ от исследования с помощью дизассемблеров можно использовать и такой способ, как усложнение структуры самой программы с целью запутывания злоумышленника, который дизассемблирует эту программу. Например, можно использовать разные сегменты адреса для обращения к одной и той же области памяти. В этом случае злоумышленнику будет трудно догадаться, что на самом деле программа работает с одной и той же областью памяти.
3.2.3. Анализ программ на этапе их эксплуатации
В данном разделе будут рассмотрены методы поиска и нейтрализации РПС с помощью дизассемблеров и отладчиков на этапе эксплуатации программ. То есть задача защиты в отличии задач защиты в предыдущих раз-делах здесь решается "с точностью до наоборот".
Основная схема анализа исполняемого кода, в данном случае, может выглядеть следующим образом [45] (см. также раздел 2.2.):
- выделение чистого кода, то есть удаление кода, отвечающего за защиту этой программы от несанкционированного запуска, копирования и т.п. и преобразования остального кода в стандартный правильно интерпретируемый дизассемблером;
- лексический анализ;
- дизассемблирование;
- семантический анализ;
- перевод в форму, удобную для следующего этапа (в том числе и перевод на язык высокого уровня);
- синтаксический анализ.
После снятия защиты осуществляется поиск сигнатур (лексем) РПС. Примеры сигнатур РПС приведены в работе [45]. Окончание этапа дизассемблирования предшествует синтаксическому анализу, то есть процессу отождествлению лексем, найденных во входной цепочке, одной из языковых конструкций, задаваемых грамматикой языка, то есть синтаксический анализ исполняемого кода программ состоит в отождествлении сигнатур, найденных на этапе лексического анализа, одному из видов РПС.
При синтаксическом анализе могут встретиться следующие трудности:
- могут быть не распознаны некоторые лексемы. Это следует из то-го, что макроассемблерные конструкции могут быть представлены бесконечным числом регулярных ассемблерных выражений;
- порядок следования лексем может быть известен с некоторой вероятностью или вообще не известен;
- грамматика языка может пополняться, так как могут возникать новые типы РПС или механизмы их работы.
Таким образом, окончательное заключение об отсутствии или наличии РПС можно дать только на этапе семантического анализа, а задачу этого этапа можно конкретизировать как свертку терминальных символов в нетерминалы как можно более высокого уровня там, где входная цепочка задана строго.
Так как семантический анализ удобнее вести на языке высокого уровня далее проводится этап перевода ассемблерного текста в текст на языке более высокого уровня, например, на специализированном языке макроассемблера, который нацелен на выделение макроконструкций, используемых в РПС.
На этапе семантического анализа дается окончательный ответ на вопрос о том, содержит ли входной исполняемый код РПС, и если да, то какого типа. При этом используется вся информация, полученная на всех предыдущих этапах. Кроме того, необходимо учитывать, что эта информа-ция может считаться правильной лишь с некоторой вероятностью, причем не исключены вообще ложные факты, или умозаключения исследователей. В целом, задача семантического анализа является сложной и ресурсоемкой и скорее не может быть полностью автоматизирована.
3.3. МЕТОДЫ И СРЕДСТВА ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ И ДОСТОВЕРНОСТИ ИСПОЛЬЗУЕМОГО ПРОГРАММНОГО КОДА
3.3.1. Методы защиты программ от несанкционированных изменений
Решение проблемы обеспечения целостности и достоверности электронных данных включает в себя решение, по крайней мере, трех основных взаимосвязанных задач: подтверждения их авторства и подлинности, а также контроль целостности данных. Решение этих трех задач в случае защиты программного обеспечения вытекает из необходимости защищать программы от следующих злоумышленных действий:
- РПС может быть внедрены в авторскую программу или эта программа может быть полностью заменена на программу-носитель РПС;
- могут быть изменены характеристики (атрибуты) программы;
- злоумышленник может выдать себя за настоящего владельца программы;
- законный владелец программы может отказаться от факта правообладания ею.
Наиболее эффективными методами защиты от подобных злоумышленных действий предоставляют криптографические методы защиты. Это обусловлено тем, что хорошо известные способы контроля целостности программ, основанные на контрольной сумме, продольном контроле и контроле на четность, как правило, представляют собой довольно простые способы защиты от внесения изменений в код программ. Так как область значений, например, контрольной суммы сильно ограничена, а значения функции контроля на четность вообще представляются одним-двумя битами, то для опытного нарушителя не составляет труда найти следующую коллизию: f(k1)=f(k2), где k1 - код программы без внесенной нарушителем закладки, а k2 - с внесенной программным закладкой и f - функция контро-ля. В этом случае значения функции для разных аргументов совпадают при тестировании и, следовательно, закладка обнаружена не будет.
Для установления подлинности (неизменности) программ необходимо использовать более сложные методы, такие как аутентификация кода программ, с использованием криптографических способов, которые обнаруживают следы, остающиеся после внесения преднамеренных искажений.
В первом случае аутентифицируемой программе ставится в соответствие некоторый аутентификатор, который получен при помощи стойкой криптографической функции. Такой функцией может быть криптографически стойкая хэш-функция (например, функция ГОСТ Р 34.11-94) или функция электронной цифровой подписи (например, функция ГОСТ Р 34.10-94). И в том, и в другом случае аргументами функции может быть не только код аутентифицируемой программы, но и время и дата аутентификации, идентификатор программиста и/или предприятия - разработчика ПО, какой-либо случайный параметр и т.п. Может использоваться также любой симметричный шифр (например, DES или ГОСТ 28147-89) в режиме генерации имитовставки. Однако, это требует наличия секретного ключа при верификации программ на целостность, что бывает не всегда удобно и безопасно. В то время как при использовании метода цифровой подписи при верификации необходимо иметь только некоторую общедоступную информацию, в данном случае открытый ключ подписи. То есть контроль целостности ПО может осуществить любое заинтересованное лицо, имеющее доступ к открытым ключам используемой схемы цифровой подписи.
Можно еще более усложнить действия злоумышленника по нарушению целостности целевых программ, используя схемы подписи с верификацией по запросу [27,30]. В этом случае тестирование программ по ассоциированным с ними аутентификаторам можно осуществить только в присутствии лица, сгенерировавшего эту подпись, то есть в присутствии разработчика программ или представителей предприятия-изготовителя программного обеспечения. В этом случае, если даже злоумышленник и получил для данной программы некий аутентификатор, то ее обладатель может убедиться в достоверности программы только в присутствии специалистов-разработчиков, которые немедленно обнаружат нарушения целостности кода программы и (или) его подлинности.
3.3.2. Краткое описание криптографических средств контроля целостности и достоверности программ
Основные положения криптологии и базовые криптографические понятия
Термин "криптология" происходит от двух греческих слов: "крипто", что означает "тайный" и "логос", т.е. - учение.
Криптология как наука, состоит из двух тесно теоретически и практически связанных дисциплин: криптографии и криптоанализа. Криптография - наука о способах преобразования (шифрования) информации с целью ее защиты от незаконных пользователей. Криптоанализ - наука (и практика ее применения) о методах и способах вскрытия шифров. Криптография и криптоанализ очевидным образом связаны друг с другом, так как не бывает хороших криптографов, не владеющих методами криптоанализа, и наоборот - хороший криптоаналитик должен быть знаком со всеми известными способами построения шифров. Ниже даются базовые понятия и определения криптологии, в т.ч. используемые и в настоящем разделе.
Шифр (криптосистема) - способ, метод преобразования информации с целью ее защиты от незаконных пользователей (от противника). Для противника возникает сложная задача вскрытия шифра. Вскрытие (взламывание) шифра - процесс получения информации из шифрованного сообщения (шифртекста) без знания примененного шифра.
Шифрование - процесс применения шифра к защищаемой информации, т.е. преобразование информации в шифрованное сообщение с помощью определенных правил, содержащихся в шифре.
Дешифрование - процесс, обратный шифрованию, т.е. преобразование шифрованного сообщения в защищаемую информацию с помощью определенных правил, содержащихся в шифре.
Исходное сообщение, имеющее, как правило, смысловое (логически значимое) содержание, которое необходимо зашифровать называется открытым текстом. Зашифрованное сообщение, имеющее, как правило, вид случайного набора символов (цифр) называется шифртекстом или криптограммой.
Под ключом в криптографии понимают сменный элемент шифра, который применен для шифрования конкретного открытого текста (сообщения).
В криптографии обычно общепринято следующее допущение. Криптоаналитик (противник) почти всегда имеет полный шифртекст. Помимо этого в криптографии принято правило Керкхоффа, которое гласит, что "стойкость шифра должна определяться только секретностью его ключа".
В этом случае задача противника сводится к попытке раскрытия шифра (попытке осуществления атаки) на основе шифртекста. Если же противник имеет к тому же некоторые отрывки открытого текста и соответствующие им элементы шифртекста, тогда он пытается осуществлять атаку на основе открытого текста. Атака на основе выбранного открытого текста заключается в том, что противник, используя свой открытый текст, получает правильный шифртекст (например, используя "вслепую" некоторую шифрмашину) и пытается в этом случае вскрыть шифр. Попытку раскрытия шифра можно осуществить, если противник подставляет свой ложный шифртекст и при дешифровании получает необходимый для раскрытия шифра открытый текст. Такой способ раскрытия называется атакой на основе выбранного шифртекста.
Теоретически существует абсолютно стойкий шифр, но единственным таким шифром является какая-нибудь форма так называемой ленты однократного использования (или так называемый "одноразовый блокнот"), в которой открытый текст "объединяется" с полностью случайным ключом такой же длины. Этот результат был доказан К. Шенноном с помощью разработанного им теоретико-информационного метода исследования шифров.
Для абсолютной стойкости существенным является каждое из следующих требований к ленте однократного использования:
- полная случайность (равновероятность) ключа (это, в частности, означает, что ключ нельзя вырабатывать с помощью какого-либо детерминированного устройства);
- равенство длины ключа и длины открытого текста;
- однократность использования ключа.
В то же время, именно эти условия и делают абсолютно стойкий шифр очень ресурсозатратным и непрактичным. Прежде чем пользоваться таким шифром, необходимо обеспечить всех абонентов достаточным запасом случайных ключей и исключить возможность их повторного применения. А это сделать необычайно трудно и дорого. В силу данных причин абсолютно стойкие шифры применяются только в сетях связи с небольшим объемом передаваемой информации, обычно это сети для передачи особо важной государственной информации.
В 1976 г. опубликовав свою работу "Новые направления в криптографии", американские ученые У. Диффи и М. Хеллман выдвинули следующую удивительную гипотезу: "Возможно построение практически стойких криптосистем, вообще не требующих передачи секретного ключа". Такие криптосистемы, получившие название криптосистем с открытым ключом, основываются на введении понятий "односторонней функции" и "односторонней функции с секретом". Понятие односторонней функции было введено в подразделе 2.4
Вопрос о существовании односторонней функции с секретом является столь же гипотетическим, что и вопрос о существовании односторонней функции. Для практических целей было построено несколько функций, которые могут оказаться односторонними, а это означает, что задача инвертирования эквивалентна некоторой давно изучаемой трудной математической задаче (см., например, [70]).
Применение односторонних функций в криптографии позволяет: во-первых, организовать обмен шифрованными сообщениями с использованием только открытых каналов связи и, во-вторых, решать новые криптографические задачи, такие как электронная цифровая подпись.
В большинстве схем электронной подписи используются хэш-функции. Это объясняется тем, что практические схемы электронной подписи не способны подписывать сообщения произвольной длины, а процедура, состоящая в разбиении сообщения на блоки и в генерации подписи для каждого блока по отдельности, крайне неэффективна. Под термином "хэш-функция" понимается функция, отображающие сообщения произвольной длины в значение фиксированной длины, которое называется хэш-кодом.
Далее рассмотрим базовые криптографические методы, широко применяющиеся в современных системах обеспечения безопасности информации.
Краткое описание основных криптографических методов защиты данных
Симметричный шифр ГОСТ 28147-89
Пусть L и R - последовательности битов, LR означает их конкатенацию. Под обозначением 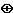 будет пониматься операция сложения по модулю 2 или логическая операция XOR (исключающая ИЛИ), символом [+] - операция сложения по модулю 232 двух 32-разрядных чисел. Числа суммируются по следующему правилу:
будет пониматься операция сложения по модулю 2 или логическая операция XOR (исключающая ИЛИ), символом [+] - операция сложения по модулю 232 двух 32-разрядных чисел. Числа суммируются по следующему правилу:
A[+]B=AB, если AB < 232
A[+]B=AB-232, если AB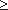 232.
232.
Символом {+} обозначается операция сложения по модуль 232-1 двух 32-разрядных чисел. Правила суммирования чисел следующие:
A{+}B=AB, если AB < 232-1
A{+}B=AB-232, если AB232-1.
Во всех режимах работы алгоритма используется ключ длиной 256 битов, который представляется в виде восьми 32-разрадных чисел X(i).Если обозначить ключ через W, то
W=X(7)X(6)X(5)X(4)X(3)X(2)X(1)X(0).
Дешифрование, как и в любой симметричной криптосистеме осуществляется на том же ключе, что и шифрование. Ниже приводится описание двух наиболее используемых режимов шифра: режима простой замены и режима генерации имитовставки [6].
Описание режима простой замены. Код программы T разбивается на блоки по 64 бита в каждом, которые обозначаются T(j). Очередная последовательность битов T(j) разбивается на две последовательности B(0) (левые или старшие биты) и A(0) (правые или младшие биты), каждая из которых содержит 32 бита. Затем выполняется итеративный процесс шифрования, который описывается следующими формулами:
при i=1,2,...,24; j=i-1(mod 8) A(i)=f(A(i-1)[+]X(j)(+)B(i-1)); B(i)-A(i-1); при i=25,26,...,31; j=32-i A(i)=f(A(i-1)[+]X(j)(+)B(i-1)); B(i)-A(i-1); при i=32 A(32)=A(31); B(32)=f(A(31)[+]X(0)(+)B(31)),
где i обозначает номер итерации (i=1,2,...,32). Функция f называется функцией шифрования. Ее аргументом является сумма по модулю 232 числа A(i), полученного на предыдущем шаге итерации, в числа X(j) ключа (размерность каждого из этих чисел 32 знакам).
Функция шифрования включает две операции над полученной 32-разрядной суммой. Первая операция называется подстановкой K. Блок подстановки K состоит из восьми узлов замены K(1)...K(8) с памятью 64 бита каждый. Поступающий на блок подстановки 32-разрядный вектор разбивается на 8 последовательно идущих 4-разрядных векторов, каждый из которых преобразуется в 4-разрядный вектор соответствующим узлом замены, представляющим собой таблицу из 16 целых чисел в диапазоне 0,...,15.
Входной вектор определяет адрес строки в таблице, число из которой является выходным вектором. Затем 4-разрядные выходные векторы последовательно объединяются в 32-разрядный вектор. Таблицы блока подстановки блока подстановки K содержат редко изменяемые ключевые элементы, общие для некоторой компьютерной системы.
Вторая операция - циклический сдвиг влево 32-разрядного вектора, полученного в результате подстановки K. 64-разрядный блок зашифрованных данных Тш представляется в виде:
Тш=A(32)B(32).
Остальные блоки кода программы в режиме простой замены шифруются аналогично.
Режим генерации имитовставки. Для получения имитовставки код программы представляется в виде 64-разрядных блоков T(i), =1,2,..,m. Где m определяет объем кода программы. Первый блок кода программы T(i) подвергается преобразованию, соответствующему первым 16 циклам алгоритма шифрования в режиме простой замены, причем в качестве ключа для выработки имитовставки используется ключ, по которому шифруются данные.
Полученное после 16 циклов работы 64-разрядное число суммируется по модулю 2 со вторым блоком открытых данных T(2). Результат суммирования снова подвергается преобразованию, соответствующему 16 циклам алгоритма шифрования в режиме простой замены. Полученное 64-разрядной число суммируется по модулю 2 с третьим блоком данных T(3) и т.д. Последний блок T(m), при необходимости дополненный до полного 64-разрядного блока нулями, суммируется по модулю 2 с результатом работы на шаге m-1, после чего шифруется в режиме простой замены по первым 16 циклам алгоритма. Из полученного 64-разрядного числа выбирается отрезок Ир длиной р битов. Данный отрезок и является имитовставкой Ир, полученной для кода программы T.
Открытый ключевой обмен Диффи-Хеллмана и криптосистемы с открытым ключом
Основная задача ключевого обмена Диффи-Хеллмана заключается в следующем: "Каким образом можно установить секретный ключ между абонентами А и В по открытому каналу связи а затем использовать его для шифрованной передачи сообщений?" Для этих целей, пусть абонент A выбирает какую-нибудь функцию fk с секретом k. Он публикует в открытом сертифицированном справочнике описание функции fk в качестве своего алгоритма шифрования. Однако, значение секрета k он никому не сообщает, т.е. держит его в тайне от других.
Если абонент B хочет послать А защищаемую информацию x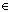 X, то он вычисляет y=fk(x) и посылает y по открытому каналу к A. Поскольку A для своего секрета k умеет инвертировать fk, то он вычисляет x по полученному y. Так как никто другой не знает k и поэтому в силу свойств функции с секретом не сможет за полиномиальное время по известному шифрованному сообщению y вычислить защищаемую информацию x.
X, то он вычисляет y=fk(x) и посылает y по открытому каналу к A. Поскольку A для своего секрета k умеет инвертировать fk, то он вычисляет x по полученному y. Так как никто другой не знает k и поэтому в силу свойств функции с секретом не сможет за полиномиальное время по известному шифрованному сообщению y вычислить защищаемую информацию x.
Описанная выше схема является криптосистемой с открытым ключом, поскольку алгоритм шифрования fk является общедоступным или открытым. Такие криптосистемы называют еще асимметричными, поскольку в них есть асимметрия в алгоритмах: алгоритмы шифрования и дешифрования различны. В отличие от таких систем традиционные шифры называют симметричными, так как в них ключ для шифрования и дешифрования один и тот же, и именно поэтому его нужно хранить в секрете. Для асимметричных систем алгоритм шифрования общеизвестен, но восстановить по нему алгоритм дешифрования за полиномиальное время невозможно.
Электронная цифровая подпись
Основные определения, обозначения и алгоритмы. Для реализации схем электронной цифровой подписи (или просто цифровой подписи) требуются три следующих эффективно функционирующих алгоритма:
- Ak - алгоритм генерации секретного и открытого ключей для подписи кода программы, а также проверки подписи, - s и p соответственно;
- As - алгоритм генерации (проставления) подписи с использованием секретного ключа s;
- Ap - алгоритм проверки (верификации) подписи с использованием открытого ключа p.
Алгоритмы должны быть разработаны так, чтобы выполнялось основное принципиальное свойство, - свойство невозможности получения нарушителем (противником) алгоритма As из алгоритма Ap.
Таким образом, если Ak - алгоритм генерации ключей, тогда определим значения (s,p)=Ak(α,β) как указанные выше сгенерированные ключи, где α - некоторый параметр безопасности (как правило, длина ключей), а β - параметр, характеризующий случайный характер работы алгоритма Ak при каждом его вызове.
Ключ s хранится в секрете, а открытый ключ p делается общедоступным. Это делается, как правило, путем помещения открытых ключей пользователей в открытый сертифицированный справочник. Сертификация открытых ключей справочника выполняется некоторым дополнительным надежным элементом, которому все пользователи системы доверяют обработку этих ключей. Обычно этот элемент называют Центром обеспечения безопасности или Центром доверия.
Непосредственно процесс подписи осуществляется посредством алгоритма As. В этом случае значение c=As(m) - есть подпись кода программы m, полученная при помощи алгоритма As и ключа s.
Процесс верификации выполняется следующим образом. Пусть m* и c* - код программы и подпись для этого кода соответственно, Ap - алгоритм верификации. Тогда, выбрав из справочника общедоступный открытый ключ p, можно выполнить алгоритм верификации: b=Ap(m*,c*), где предикат b{true,false}. Если b=true, то код m* действительно соответствует подписи c*, полученной при помощи секретного ключа s, который, в свою очередь, соответствует открытому ключу p, то есть m=m*, c=c* и наоборот если b=false, то код программы ложен и (или) код подписан ложным ключом.
Примеры схем электронной цифровой подписи. К наиболее известным схемам цифровой подписи с прикладной точки зрения относятся схемы RSA, схемы Рабина-Уильямса, Эль-Гамаля, Шнорра и Фиата-Шамира [15], а также схема электронной цифровой подписи отечественного стандарта ГОСТ Р 34.10-94 [7].
Рассмотрим несколько подробнее четыре наиболее известные схемы цифровой подписи:
Подпись RSA: Вход: Числа n, p, q, где p и q - большие l - разрядные простые числа, n=pq. Открытый ключ p=(e,n), секретный ключ s=d, такой, что ed 1(mod φ(n)) и наибольший общий делитель НОД(e,φ(n))=1, где
φ(n)=(p-1)(q-1).
1(mod φ(n)) и наибольший общий делитель НОД(e,φ(n))=1, где
φ(n)=(p-1)(q-1).
Генерация ключей:(d,(e,n))=Ak(l,b). Подпись:As: 1.md(mod n)
кода программы m. Верификация:Ap: 1.[c*]e(mod n)
Подпись Эль-Гамаля: Вход: Числа p и g, где p - простое l - разрядное число, а g - первообразный корень по модулю p. Секретный ключ s=d, открытый ключ p=e, такой, что egd (mod p), m - подписываемый код программы.
Генерация ключей:(d,(e,g,p))=Ak(l,b).
Подпись: As: 1.r
2.находится такое c, что
m
где (c,r) - подпись кода m.Верификация:Ap: 1.если gm*=errc*(mod p),
то подпись верна.
Подпись Фиата - Шамира: Вход: Числа n, p, и q, где p и q большие l - разрядные простые числа, открытый ключ p есть вектор (v1,v2,...,vk), где vj - квадратичные вычеты по модулю n, j=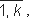 , секретный ключ p есть вектор (s1,s2,...,sk), где каждый sj - наименьший квадратный корень из v-1j, m - подписываемый код, f - псевдослучайная функция.
Генерация ключей: ((s1,s2,...,sk),(v1,v2,...,vk))=Ak(l,b).
, секретный ключ p есть вектор (s1,s2,...,sk), где каждый sj - наименьший квадратный корень из v-1j, m - подписываемый код, f - псевдослучайная функция.
Генерация ключей: ((s1,s2,...,sk),(v1,v2,...,vk))=Ak(l,b).
| Подпись: | As: 1.xi r2i(mod n), где {r1,r2,...,rk}RZn; 2.вычисляется значение a=f(m,x1,x2,...,xt); 3.выбирается первые kt битов числа a как матрица 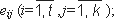 4.вычисляется: 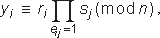 где 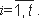 Тогда (eij,yi) - подпись кода m. |
| Верификация: | 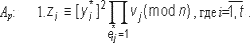 2.если первые kt битов значения функции f(m*,z1,z2,...,zt) равны e*ij, подпись верна. |
Подпись стандарта ГОСТ Р 34.10-94. Вход: Числа p, g и q где p - простое l -разрядное число, g - первообразный корень по модулю p, а q - большой простой делитель p-1. Пусть также gq1(mod p), g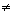 1. Секретный ключ подписи x (1 < x < q) и открытый ключ ygx(mod p).
1. Секретный ключ подписи x (1 < x < q) и открытый ключ ygx(mod p).
| Генерация ключей: | (x,(g,p,q,y))=Ak(l,b). |
| Подпись: | Ax: 1.r[gk(mod p)](mod q), где kRZq. 2.s [xr+km)](mod q), где m=h(M) -рассматривается как значение хэш-функции h, соответствующей отечественному стандарту на функцию хэширования сообщений ГОСТ Р 34.11-94. Таким образом, пара (r,s) - есть подпись кода программы M.
|
| Верификация: | Ay: 1.vm-1(mod q). 2.u [gsvy-rv(mod p)](mod q);
3.Если u=r, то (r,s) - есть подпись
кода программы M, где m=h(M).
|
Под стойкостью схемы цифровой подписи понимается стойкость в теоретико-сложностном смысле, то есть, как отсутствие эффективных алгоритмов ее подделки и (или) раскрытия [6]. По-видимому, до сих пор основной является следующая классификация:
- атака с открытым ключом, когда противник знает только открытый ключ схемы;
- атака на основе известного открытого текста (известного кода программы), когда противник получает подписи для некоторого (ограниченного) количества известных ему кодов (при этом противник никак не может повлиять на выбор этих кодов);
- атака на основе выбранного открытого текста, когда противник может получить подписи для некоторого ограниченного количества выбранных им кодов программы (предполагается, что коды выбираются независимо от открытого ключа, например, до того как открытый ключ станет известен);
- направленная атака на основе выбранного открытого текста (то же, что предыдущая, но противник, выбирая код программы, уже знает открытый ключ);
- адаптивная атака на основе выбранного открытого текста, когда противник выбирает коды программы последовательно, зная открытый ключ и зная на каждом шаге подписи для всех ранее выбранных кодов.
Атаки перечислены таким образом, что каждая последующая сильнее предыдущей.
Угрозами для схем цифровой подписи являются раскрытие схемы или подделка подписи. Определяются следующие типы угроз:
- полного раскрытия, когда противник в состоянии вычислить секретный ключ подписи;
- универсальной подделки, когда противник находит алгоритм, функционально эквивалентный алгоритму вычисления подписи;
- селективной подделки, когда осуществляется подделка подписи для кода программы, выбранного противником априори;
- экзистенциональной подделки, когда осуществляется подделка подписи хотя бы для одного кода программы (при этом противник не контролирует выбор этого кода, которое может быть вообще случайным или бессмысленным).
Угрозы перечислены в порядке ослабления. Стойкость схемы электронной подписи определяется относительно пары (тип атаки, угроза).
Если принять вышеописанную классификацию атак и угроз, то наиболее привлекательной является схема цифровой подписи, стойкая против самой слабой из угроз, в предположении, что противник может провести самую сильную из всех атак. В этом случае, такая схема должна быть стойкой против экзистенциональной подделки с адаптивной атакой на основе выбранного открытого текста.
Разновидности схем подписи электронных сообщений. Для обеспечения целостности и достоверности информации при ее передаче и хранении, а также для проведения аутентификации абонентов системы и решения других задач защиты существует достаточно много всевозможных разновидностей схем подписи [15]. Без подробного описания ниже приводится одна из разновидностей схем подписи, которая, как правило, использует рассмотренный выше математический аппарат и может использоваться для защиты программ.
Схема подписи с верификацией по запросу. В работах Д. Шаума (см., например, [27,30]) впервые была предложена схема подписи с верификацией по запросу, в которой абонент V не может осуществить верификацию подписи без участия абонента S. Такие схемы могут эффективно использоваться в том случае, когда фирма - изготовитель поставляет потребителю некоторый информационный продукт (например, программное обеспечение) с проставленной на нем подписью указанного вида [30]. Однако проверить эту подпись, которая гарантирует подлинность программы или отсутствие ее модификаций, можно только уплатив за нее. После факта оплаты фирма - изготовитель дает разрешение на верификацию корректности полученных программ.
Схема состоит из трех этапов (протоколов), к которым относятся непосредственно этап генерации подписи, этап верификации подписи с обязательным участием подписывающего (протокол верификации) и этап оспаривания, если подпись или целостность подписанных сообщений подверглась сомнению (отвергающий протокол).
I. Генерация подписи. Пусть каждый пользователь S имеет один открытый ключ P и два секретных ключа S1 и S2. Ключ S1 всегда остается в секрете, - он необходим для генерации подписи. Ключ S2 может быть открыт для того, чтобы конвертировать схему подписи с верификацией по запросу в обычную схему электронной цифровой подписи.
Вместе с обозначениями секретного и открытого ключей xRZq и yRZ*p (взятых из отечественного стандарта на электронную цифровую подпись) введем также обозначения S1=x и S2=u, uRZq, а также открытый ключ P=(g,y,w), где wgu(mod p). Открытый ключ P публикуется в открытом сертифицированном справочнике.
Подпись кода m вычисляется следующим образом. Выбирается kRZq и вычисляется rgk(mod p). Затем вычисляется s[xr+mku](mod q). Пара (r,s) является подписью для кода m. Подпись считается корректной тогда и только тогда, когда rugswy-rw , где wm-1(mod q).
Проверка подписи (с участием подписывающего) осуществляется посредством следующего интерактивного протокола.
II. Протокол верификации. Абонент вычисляет γgswy-rw(mod p) и просит абонента S доказать, что пара (r,s) есть его подпись под кодом m. Эта задача эквивалентна доказательству того, что дискретный логарифм γ по основанию r равен (по модулю p) дискретному логарифму w по основанию g, то есть, что logg(p)wlogr(p)γ. Для этого:
- Абонент V выбирает a,bRZq, вычисляет δragb(mod p) и посылает δ абоненту S.
- Абонент S выбирает tRZq, вычисляет h1δg1(mod p), h2h1u(mod p) и посылает h1 и h2 абоненту V.
- Абонент V высылает параметры a и b.
- Если δragb(mod p) , то абонент S посылает V параметр t; в противном случае - останавливается.
- Абонент V проверяет выполнение равенств h1ragb+1(mod p) и h2γawb+1(mod p) .
Если проверка завершена успешно, то подпись принимается как корректная.
III. Отвергающий протокол. В отвергающем протоколе S доказывает, что logg(p)wlogr(p)γ. Следующие шаги выполняются в цикле l раз.
- Абонент V выбирает d,eRZq, d1, βR{0,1}. Вычисляет age(mod p), bwe(mod p), если β=0 и are(mod p) , bγe(mod p), если β=1. Посылает S значения a, b, d.
- Абонент S проверяет соотношение au(mod p)b. Если оно выполняется, то a=0, в противном случае a=1. Выбирает RRZq, вычисляет cdagR(mod p) и посылает V значение c.
- Абонент V посылает абоненту S значение e.
- Абонент S проверяет, что выполняются соотношения из следующих двух их пар: age(mod p), bwe(mod p) и are(mod p), bγe(mod p). Если да, то посылает V значение R. Иначе останавливается.
- Абонент V проверяет, что dβgRc .
Если во всех l циклах проверка в п.5 выполнена успешно, то абонент V принимает доказательства.
Таблица 3.1. Протокол верификации является интерактивным протоколом доказательств с абсолютно нулевым разглашением.
Доказательство. Требуется доказать, что вышеприведенный протокол удовлетворяет трем свойствам: полноты, корректности и нулевого разглашения [27,29].
Полнота означает, что если оба участника (V и S) следуют протоколу и (r,s) - корректная подпись для сообщения m, то V примет доказательство с вероятностью близкой к 1. Из описания протокола верификации очевидно, что абонент S всегда может надлежащим образом ответить на запросы абонента V, то есть доказательство будет принято с вероятностью 1.
Корректность означает, что если V действует согласно протоколу, то какие действия не предпринимал бы S, он может обмануть V лишь с пренебрежимо малой вероятностью. Здесь под обманом понимается попытка S доказать, что logg(p)wlogr(p)γ, когда на самом деле эти логарифмы не равны.
Предположим, что logg(p)wlogr(p)γ. Ясно, что для каждого a существует единственное значение b, то которое дает данный запрос δ. Поэтому δ не содержит в себе никакой информации об a. Если S смог бы найти h1, h2, t1 и t2 такие, что
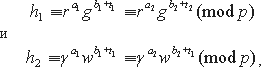
где a1a2, то тогда выполнялось бы соотношение
logg(p)r[(a1-a2)-1((b2-b1)+(t2-t1))](modq)logw(p)γ.
Отсюда, очевидно, следует, что logg(p)wlogr(p)γ. В самом деле, пусть logw(p)γlogg(p)r λ. Тогда

что противоречит предположению. Следовательно, какие бы h1, h2, t1 и t2 не выбрал S, проверка, которую проводит V, может быть выполнена только для одного значения a. Отсюда вероятность обмана не превосходит 1/q. Отметим, что протокол верификации является безусловно стойким для абонента V, то есть доказательство корректности не зависит ни от каких предположений о вычислительной мощности доказывающего (S).
Свойство нулевого разглашения означает, что в результате выполнения протокола абонент V не получает никакой полезной для себя информации (например, о секретных ключах, используемых S). Для доказательства нулевого разглашения необходимо для любого возможного проверяющего V* построить моделирующую машину MV , которая является вероятностной машиной Тьюринга, работает за полиномиальное в среднем время и создает на выходе (без участия S) такое же распределение случайных величин, которое возникает у V* в результате выполнения протокола. В нашем случае, случайные величины, которые "видит" V*, - это h1, h2, и t. Необходимо доказать, что протокол верификации является доказательством с абсолютно нулевым разглашением, то есть моделирующая машина создает распределение случайных величин (h1,h2,t), которое в точности совпадает с их распределением, возникающим при выполнении протокола. Моделирующая машина MV использует в своей работе V* в качестве "черного ящика".
Моделирующая машина
- Запоминает состояние машины V*, то есть содержимое всех ее лент, внутреннее состояние и позиции головок на лентах. Затем получает от V* значение δ и после этого снова запоминает состояние машины V*.
- Выбирает ηRZq и вычисляет h`1gη(modp) и h`2`rη(modp).
- Получает от V* значения a и b. Если δragb(modp) , то MV` останавливается.
- Машина MV` "отматывает" V* на состояние, которое было запомнено в конце шага 1. Выбирает tRZq и вычисляет h1ragb+1(modp) и h2γawb+1(modp).
- Машина MV` передает V* h1, h2 и получает ответ (a`,b`). Возможны два варианта:
- 5.1. a=a` , b=b` . В этом случае моделирование закончено и MV` записывает на выходную ленту тройку (h1,h2,t) и останавливается.
5.2. aa` или bb` . Отсюда следует, что δragbra`gb`(modp) . Предположим, что bb`. Из этого следует, что aa`. Следовательно, MV` может вычислить rg(b-b`)/(a-a`)(modp). Отсюда (b`-b)/(a-a`)=l - дискретный логарифм r по основанию g. - Машина MV` "отматывает" V* на состояние, которое было за-полнено в начале шага 1. Получает от V* значение δ.
- Выбирает ηRZq вычисляет h1gη(modp) и h2wη(modp) и передает их V*.
- Получает от V* значения a и b. Если δragb(modp) , то MV` останавливается. В противном случае вычисляет t=[η-al-b](mod q), выдает (h1,h2,t) на выходную ленту и останавливается.
К пп. 7 и 8 необходимо сделать следующее пояснение. Поскольку logg(p)wlogr(p)γ, из этого следует, что logw(p)γlogg(p)r. Отсюда
h2wηwb+1walwb+1γa(modp)
Из описания моделирующей машины MV` очевидно, что она работает за полиномиальное время. Величины (h1,h2,t) на шаге 5.1 выбираются в точности как в протоколе и поэтому имеют такое же распределение вероятностей. Кроме того, значения (h1,h2), выбираемые на шаге 7, имеют такое же распределение, как и в протоколе. Чтобы показать что и t имеет одинаковое распределение, достаточно заметить, что машина V* не может по h1 и h2 определить, с кем она имеет дело - с S или MV`.Поэтому, даже если бы V* могла каким-либо "хитрым" образом строить a и b с учетом (h1,h2), распределение вероятностей величин a и b в обоих случаях одинаковы. Но значение t определяется однозначно четверкой величин a, b, h1, h2, при условии выполнения проверки на шаге 5 протокола.
Таблица 3.2. Отвергающий протокол является протоколом доказательства с абсолютно нулевым разглашением.
Доказательство. Полнота протокола очевидна. Если абоненты S и V следуют протоколу, тогда абонент V всегда примет доказательства абонента S.
Для доказательства корректности прежде всего заметим, что если logg(p)wlogr(p)γ, то a и b, выбираемые абонентом V на шаге 1, не несут в себе никакой информации о значении β. Поэтому, если S может "открыть" c, сгенерированное им на шаге 2, лишь единственным образом (то есть выдать на шаге 4 единственное значение R, соответствующее данному a), то проверка на шаге 5 будет выполнена с вероятностью 1/2 в одном цикле и с вероятностью 1/2l во всех l циклах.
Если же S может сгенерировать c таким образом, что с вероятностью, которая не является пренебрежимо малой, он может на шаге 4 "открыть" оба значения α, то есть найти R1 и R2 такие, что 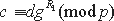 и
и 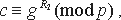 , то алгоритм, который использует S для этой цели, можно использовать для вычисления дискретных логарифмов: loggd=R2-R1. Так как при случайном выборе значения d логарифм loggd может быть вычислен с вероятностью, которая не является пренебрежимо малой, это противоречит гипотезе о трудности вычисления дискретных логарифмов.
, то алгоритм, который использует S для этой цели, можно использовать для вычисления дискретных логарифмов: loggd=R2-R1. Так как при случайном выборе значения d логарифм loggd может быть вычислен с вероятностью, которая не является пренебрежимо малой, это противоречит гипотезе о трудности вычисления дискретных логарифмов.
Далее доказывается, что отвергающий протокол является доказательством с абсолютно нулевым разглашением. Для этого необходимо для всякого возможного проверяющего V* построить моделирующую машину MV`, которая создает на выходе (без участия S) такое же распределение случайных величин (в данном случае, c и R), какое возникает у V* в результате выполнения протокола.
Моделирующая машина
Следующие шаги выполняются в цикле l раз.
- Машина MV` запоминает состояние машины V*.
- Получает от V* значения a, b и d.
- Выбирает αR{0,1}, RRZq и вычисляет cdagR(modp) . Посылает V* значение c.
- Получает от V* значение e.
- Проверяет, было ли "угадано" на шаге 2 значение α (это значение было "угадано", если age(modp), bwe(modp) и α=0, либо αre(modp), bγe(modp) и α=1). Если да, то записывает на входную ленту значение (c,R). В противном случае "отматывает" V* на то состояние, которое было запомнено на шаге 1, и переходит на шаг 2.
Легко видеть, что распределения случайных величин (c,R), возникающее в процессе выполнения протокола и создаваемые моделирующей машиной MV`, одинаковы, поскольку R в обоих случаях - чисто случайная величина, а величина c записывается на выходную ленту машины MV` только тогда, когда α совпало с β.
Поскольку значение α выбирается машиной MV` на шаге 3 случайным образом, а c не дает V* никакой информации о значении α, на каждой итерации α будет угадано с вероятностью 1/2. Отсюда следует, что машина MV` работает за полиномиальное в среднем время.
В работе [27] показано, как строить схемы конвертируемой и селективно конвертируемой подписи с верификацией по запросу на основе отечественного стандарта ГОСТ Р 34.10-94. В таких схемах открытие определенного секретного параметра некоторой схемы подписи с верификацией по запросу позволяет трансформировать последнюю в обычную схему цифровой подписи. При этом открытие секретного параметра в конвертируемой схеме подписи с верификацией по запросу дает возможность верифицировать все имеющиеся и сгенерированные в дальнейшем подписи, в то время как в селективно конвертируемых схемах подписи с верификацией по запросу можно верифицировать лишь какую-либо одну подпись.
Процедуры арбитража. Часто разработчиками схем цифровой подписи при их создании, наряду с процедурами генерации и верификации цифровой подписи, не приводятся процедуры арбитража, которые позволяют установить корректность/ некорректность подписи в случае возникновения споров между участниками схемы. Проблеме арбитража в литературе уделяется мало внимание еще по-видимому и потому, что разработка арбитражных процедур считается прерогативой конкретного пользователя системы.
В случае возникновения проблемы по поводу корректности подписи основные действия участников процесса должны сводиться к следующему:
- Абонент V предъявляет арбитру сообщение и его подпись.
- Арбитр требует предъявить секретный ключ подписи абоненту S. Если абонент S отказывается, тогда арбитр дает заключение, что подпись подлинная. (То есть, в данном случае возможное нарушение сводится к тому, что абонент отказывается признать представленную подпись своей).
- Арбитр выбирает из открытого сертифицированного справочника открытый ключ абонента S и проверяет его соответствие секретному ключу подписи. При обнаружения несоответствия (например, по вине службы ведения такого справочника) арбитр признает подпись, предъявленную абонентом V, подлинной.
- Арбитр проверяет корректность подписи при помощи проверочных соотношений, используемых как при генерации, так и при верификации данной подписи.
Одна из основных проблем при арбитраже связана с тем, что арбитр получает секретный ключ абонента S. В том случае, если арбитр является нечестным, то тогда никаких способов защиты пользователей системы от него не может быть в принципе. Помимо этого, следует также сказать о том, что желательно, чтобы пользователь генерировал свои секретные ключи самостоятельно, так как даже создание специального центра генерации ключей не может полностью обезопасить пользователей от слабых ключей и полностью исключает в данном случае возможность решения споров в суде.
Хэш-функции
Основные определения, обозначения и алгоритмы. Под термином "хэш-функция" понимается функция, отображающая электронные данные произвольной длины (иногда длина ограничена, но достаточно большим числом), в значения фиксированной длины. Последние часто называют хэш-кодами. Таким образом, у всякой хэш-функции h имеется большое количество коллизий, то есть пар значений x и y таких, что h(x)=h(y). Основное требование, предъявляемое криптографическими приложениями к хэш-функциям, состоит в отсутствии эффективных алгоритмов поиска коллизий. Хэш-функция, обладающая таким свойством, называется хэш-функцией, свободной от коллизий. Кроме того, хэш-функция должна быть односторонней, то есть функцией, по значению которой вычислительно трудно найти ее аргумент и, в то же время, функцией, для аргумента которой, вычислительно трудно найти другой аргумент, который давал бы то же самое значение функции.
Таким образом, хэш-функции вместе со схемами электронной цифровой подписи предназначены для решения задач обеспечения целостности и достоверности электронных данных. В прикладных компьютерных системах требуется применение так называемых криптографически стойких хэш-функций. Под термином "криптографически стойкая хэш-функция" понимается функция h, которая является односторонней и свободной от коллизий.
Введем следующие обозначения. Хэш-функция h обозначается как h(α) и h(α,β) для одного и двух аргументов соответственно. Хэш-код функции h обозначается как H. При этом H0=I обозначает начальное значение (вектор инициализации) хэш-функции. Под обозначением будет пониматься операция сложения по модулю 2 или логическая операция XOR (исключающая ИЛИ). Результат шифрования блока B блочным шифром на ключе k обозначается Ek(B).
Для лучшего понимания дальнейшего материала приведем небольшой пример построения хэш-функции. Предположим нам необходимо получить хэш-код для некоторой программы M. В качестве шифрующего преобразования в хэш-функции будут использоваться процедуры шифра DES с ключом k. Тогда, чтобы получить хэш-код H программы M при помощи хэш-функции h необходимо выполнить следующую итеративную операцию:
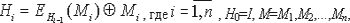
где код программы M разбит на n 64-битных блока. Хэш-кодом данной хэш-функции является значение H=h(M,I)=Hn.
Стойкость (безопасность) хэш-функций. Один из основных методов криптоанализа хэш-функций заключается в проведении криптоаналитиком (противником) атаки, основанной на "парадоксе дня рождения", основные идеи которой, излагаются ниже. Для понимания сущности предлагаемого метода криптоанализа достаточно знать элементарную теорию вероятностей.
Атака, основанная на "парадоксе дня рождения", заключается в следующем. Пусть a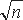 предметов выбираются с возвращением из некоторого множества с мощностью n. Тогда вероятность того, что два из них окажутся одинаковыми, составляют
предметов выбираются с возвращением из некоторого множества с мощностью n. Тогда вероятность того, что два из них окажутся одинаковыми, составляют 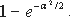
Практически это означает, что в случайно подобранной группе из 24 человек вероятность наличия двух лиц с одним и тем же днем рождения составляет значение примерно 1/2. Этот старый и хорошо изученный парадокс и положен в основу криптоанализа хэш-функций.
Например, для криптоанализа хэш-функций, основанных на использовании криптоалгоритма DES, указанная атака может быть проведена следующим образом. Пусть n - мощность области хэш-кодов (для криптоалгоритма DES она равна 264). Предположим, что есть две программы m1 и m2. Первая программа достоверна, а для второй криптоаналитик пытается получить то же самое значение хэш-кода, выдав таким образом программу m1 за программу m2 (то есть криптоаналитик пытается получить коллизию). Для этого криптоаналитик подготавливает порядка различных, незначительно отличающихся версий m1 и m2 и для каждой из них вычисляет хэш-код. С высокой вероятностью криптоаналитику удается обнаружить пару версий m`1 и m`2, имеющих один и тот же хэш-код. В дальнейшем при использовании данного хэш-кода можно выдать программу m`2 вместо программы m`1, содержание которой близко к содержанию программы m1.
К основным методам предотвращения данной атаки можно отнести: увеличение длины получаемых хэш-кодов (увеличение мощности области хэш-кодов) и выполнение требования итерированности шифрующего преобразования.
Методы построения криптографически стойких хэш-функций. Практические методы построения хэш-функций можно условно разделить на три группы: методы построения хэш-функций на основе какого-либо алгоритма шифрования (пример, приведенный выше), методы построения хэш-функций на основе какой-либо известной вычислительно трудной математической задачи и методы построения хэш-функций "с нуля" [28].
Рассмотрим примеры построения хэш-функций на основе алгоритмов шифрования. Наряду с примером, приведенным выше, покажем, как строить хэш-функции на основе наиболее известных блочных шифров ГОСТ 28147 - 89, DES и FEAL. В качестве шифрующего преобразования будут использоваться некоторые режимы шифров ГОСТ 28147-89, DES и FEAL с ключом k. Тогда, чтобы получить хэш-код H программы M при помощи хэш-функции h, необходимо выполнить следующую итеративную операцию (например, с использованием алгоритма ГОСТ 28147-89):
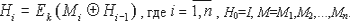
Таким образом, хэш-кодом данной хэш-функции является значение H=h(M,I)=Hn. При этом используется режим выработки имитовставки ГОСТ 28147-89, а шифрующее преобразование 64-битных блоков заключается в выполнении 16 циклов алгоритма шифрования в режиме простой замены.
Алгоритм ГОСТ 28147-89 в качестве базового используется в хэш-функции отечественного стандарта на функцию хэширования сообщений ГОСТ Р 34.11-94, являющегося основным практическим инструментом в компьютерных системах, требующих обеспечения достоверности и целостности электронных данных.
Алгоритм DES (в режиме CFB) можно использовать в качестве базового, например, в следующей хэш-функции (с получением хэш-кода H=h(M,I)=Hn):
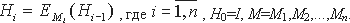
Другие примеры хэш-функций на основе алгоритмов шифрования. N-хэш алгоритм разработан фирмой Nippon Telephone Telegraph в 1990 году. N-хэш алгоритм использует блоки длиной 128 битов, шифрующую функцию, аналогичную функции алгоритма шифрования FEAL, и вырабатывает блок хэш-кода длиной 128 битов. На вход пошаговой хэш-функции в качестве аргументов поступают очередной блок кода Mi длиной 128 битов и хэш-код Hi-1 предыдущего шага также размером 128 битов. При этом H0=I, а Hi=Ek(Mi,Hi-1)MiHi-1. Хэш-кодом всего кода программы объявляется хэш-код, получаемый в результате преобразования последнего блока текста.
Идея использовать алгоритм блочного шифрования, стойкость которого общеизвестна, для построения надежных схем хэширования выглядит естественной. Однако для некоторых таких хэш-функций возникает следующая проблема. Предлагаемые методы могут требовать задания некоторого ключа, на котором происходит шифрование. В дальнейшем этот ключ необходимо держать в секрете, ибо противник, зная этот ключ и значение хэш-кода, может выполнить процедуру в обратном направлении. Еще одной слабостью указанных выше схем хэширования является то, что размер хэш-кода совпадает с размером блока алгоритма шифрования. Чаще всего размер блока недостаточен для того, чтобы схема была стойкой против атаки на основе "парадокса дня рождения". Поэтому были предприняты попытки построения хэш-функций на базе блочного шифра с размером хэш-кода в k раз (как правило, k=2) большим, чем размер блока алгоритма шифрования.
В качестве примера можно привести хэш-функции MDC2 и MDC4 фирмы IBM. Данные хэш-функции используют блочный шифр (в оригинале DES) для получения хэш-кода, длина которого в два раза больше длины блока шифра. Алгоритм MDC2 работает несколько быстрее, чем MDC4, но представляется несколько менее стойким.
Следует также отметить, что существует два основных режима применения хэш-функций: поточный и блочный. Выбор режима зависит от используемого в хэш-функции шифрующего преобразования.
В качестве примера хэш-функций, построенных на основе вычислительно трудной математической задачи можно привести функцию из рекомендаций MKKTT X.509.
Криптографическая стойкость данной функции основана на сложности решения следующей труднорешаемой теоретико-числовой задачи. Задача умножения двух больших (длиной в несколько сотен битов) простых чисел является простой с вычислительной точки зрения, в то время как факторизация (разложение на простые множители) полученного произведения является труднорешаемой задачей для указанных размерностей.
Следует отметить, что задача разложения числа на простые множители эквивалентна следующей труднорешаемой математической задаче. Пусть n=pq произведение двух простых чисел p и q. В этом случае можно легко вычислить квадрат числа по модулю n: x2(mod n), однако вычислительно трудно извлечь квадратный корень по этому модулю.
Таким образом, хэш-функцию МККТТ X.509 можно записать как:
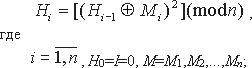
длина блока Mi представляется в октетах, каждый октет разбит пополам и к каждой половине спереди приписывается полуоктет, состоящий из двоичных единиц; n - произведение двух больших (512-битных) простых чисел p и q.
По-видимому, наиболее эффективными на сегодняшний день с точки зрения программной реализации и условий применения оказываются хэш-функции построенные "с нуля".
Алгоритм MD4 (Message Digest) был разработан Р. Ривестом [68,69]. Размер вырабатываемого хэш-кода - 128 битов. По заявлениям самого разработчика при создании алгоритма он стремился достичь следующих целей:
После того, как алгоритм был впервые опубликован, несколько криптоаналитиков построили коллизии для последних двух из трех раундов, используемых в MD4. Несмотря на то, что ни один из предложенных методов построения коллизий не приводит к успеху для полного MD4, автор усилил алгоритм и предложил новую схему хэширования MD5.
Алгоритм MD5 является доработанной версией алгоритма MD4. Аналогично MD4, в алгоритме MD5 размер хэш-кода равен 128 битам.
После ряда начальных действий MD5 разбивает текст на блоки длиной 512 битов, которые, в свою очередь, делятся на 16 подблоков по 32 бита. Выходом алгоритма являются 4 блока по 32 бита, конкатенация которых образует 128-битовый хэш-код. В 1993 году Национальный институт стандартов и технологий (NIST) США совместно с Агентством национальной безопасности США выпустил "Стандарт стойкой хэш-функции" (Secure Hash Standard), частью которого является алгоритм SHA. Предложенная процедура вырабатывает хэш-код длиной 160 битов для произвольного текста длиной менее 264 битов. Разработчики считают, что для SHA невозможно предложить алгоритм, имеющий разумную трудоемкость, который строил бы два различных набора данных, дающих один и тот же хэш-код (то есть алгоритм, находящий коллизии). Алгоритм SHA основан на тех же самых принципах, которые использовал Р. Ривест при разработке MD4, более того, алгоритмическая структура SHA очень похожа на структуру MD4. Процедура дополнения хэшируемого текста до кратного 512 битам полностью совпадает с процедурой дополнения алгоритма MD5.
Обобщая вышесказанное, следует отметить, что при выборе практически стойких и высокоэффективных криптографических хэш-функций можно руководствоваться следующими эвристическими принципами:
- любой из известных алгоритмов построения коллизий не должен быть эффективнее метода, основанного на "парадоксе дня рождения";
- алгоритм должен допускать эффективную программную реализацию на 32-разрядном процессоре;
- алгоритм не должен использовать сложных структур данных и подпрограмм;
- алгоритм должен быть оптимизирован с точки зрения его реализации на микропроцессорах типа Intel.
Криптографические протоколы
Базовым объектом исследований в криптологии являются криптографические протоколы. Криптографические протоколы относится к сравнительно новому направлению в криптографии, которое в последнее время переживает бурное развитие. В то же время, они являются весьма нетривиальным объектом исследований. Даже их формализация на сегодняшний день выглядит весьма затруднительной. Тем не менее, неформально под протоколом будем понимать распределенный алгоритм, т.е. совокупность алгоритмов для каждого из участников вычислений, плюс спецификации форматов сообщений, пересылаемых между участниками, плюс спецификации синхронизации действий участников, плюс описание действий при возникновении сбоев [6].
Объектом изучения теории криптографических протоколов являются удаленные абоненты, взаимодействующие по открытым каналам связи. Целью взаимодействия абонентов является решение какой-то задачи. Имеется также противник, который преследует собственные цели. При этом противниками могут быть один или даже несколько абонентов, вступивших в сговор.
Приведенная выше схема подписи с верификацией по запросу, а также схемы, представленные в разделе 2.4. есть не что иное, как сложные двухсторонние или многосторонние протоколы, которые используют, в том числе и криптографические примитивы.
3.4. ОСНОВНЫЕ ПОДХОДЫ К ЗАЩИТЕ ПРОГРАММ ОТ НЕСАНКЦИОНИРОВАННОГО КОПИРОВАНИЯ
3.4.1. Основные функции средств защиты от копирования
При защите программ от несанкционированного копирования применяются методы, которые позволяют привносить в защищаемую программу функции привязки процесса выполнения кода программы только на тех ЭВМ, на которые они были инсталлированы. Инсталлированная программа для защиты от копирования при каждом запуске должна выполнять следующие действия:
- анализ аппаратно-программной среды компьютера, на котором она запущена, формирование на основе этого анализа текущих характеристик своей среды выполнения;
- проверка подлинности среды выполнения путем сравнения ее текущих характеристик с эталонными, хранящимися на винчестере;
- блокирование дальнейшей работы программы при несовпадении текущих характеристик с эталонными.
Этап проверки подлинности среды является одним из самых уязвимых с точки зрения защиты. Можно детально не разбираться с логикой защиты, а немного "подправить" результат сравнения, и защита будет снята.
При выполнении процесса проверки подлинности среды возможны три варианта: с использованием множества операторов сравнения того, что есть, с тем, что должно быть, с использованием механизма генерации исполняемых команд в зависимости от результатов работы защитного механизма и с использованием арифметических операций. При использовании механизма генерации исполняемых команд в первом байте хранится исходная ключевая контрольная сумма BIOS, во второй байт записывается подсчитанная контрольная сумма в процессе выполнения задачи. Затем осуществляется вычитание из значения первого байта значение второго байта, а полученный результат добавляется к каждой ячейки оперативной памяти в области операционной системы. Понятно, что если суммы не совпадут, то операционная система функционировать не будет. При использовании арифметических операций осуществляется преобразование над данными арифметического характера в зависимости от результатов работы защитного механизма.
Для снятия защиты от копирования применяют два основных метода: статический и динамический [47].
Статические методы предусматривают анализ текстов защищенных программ в естественном или преобразованном виде. Динамические методы предусматривают слежение за выполнением программы с помощью специальных средств снятия защиты от копирования.
3.4.2. Основные методы защиты от копирования
Криптографические методы
Для защиты инсталлируемой программы от копирования при помощи криптографических методов инсталлятор программы должен выполнить следующие функции:
- анализ аппаратно-программной среды компьютера, на котором должна будет выполняться инсталлируемая программа, и формирование на основе этого анализа эталонных характеристик среды выполнения программы;
- запись криптографически преобразованных эталонных характеристик аппаратно-программной среды компьютер на винчестер.
Преобразованные эталонные характеристики аппаратно-программной среды могут быть занесены в следующие области жесткого диска:
- в любые места области данных (в созданный для этого отдельный файл, в отдельные кластеры, которые должны помечаться затем в FAT как зарезервированные под операционную систему или дефектные);
- в зарезервированные сектора системной области винчестера;
- непосредственно в файлы размещения защищаемой программной системы, например, в файл настройки ее параметров функционирования.
Можно выделить два основных метода защиты от копирования с использованием криптографических приемов:
- с использованием односторонней функции;
- с использованием шифрования.
Односторонние функции это функции, для которых при любом x из области определения легко вычислить f(x), однако почти для всех y из ее области значений, найти y=f(x) вычислительно трудно.
Если эталонные характеристики программно-аппаратной среды представить в виде аргумента односторонней функции x, то y - есть "образ" этих характеристик, который хранится на винчестере и по значению которого вычислительно невозможно получить сами характеристики. Примером такой односторонней функции может служить функция дискретного возведения в степень, описанная в разделах 2.1 и 3.3 с размерностью операндов не менее 512 битов.
При шифровании эталонные характеристики шифруются по ключу, совпадающему с этими текущими характеристиками, а текущие характеристики среды выполнения программы для сравнения с эталонными также зашифровываются, но по ключу, совпадающему с этими текущими характеристиками. Таким образом, при сравнении эталонные и текущие характеристики находятся в зашифрованном виде и будут совпадать только в том случае, если исходные эталонные характеристики совпадают с исходными текущими.
Метод привязки к идентификатору
В случае если характеристики аппаратно-программной среды отсутствуют в явном виде или их определение значительно замедляет запуск программ или снижает удобство их использования, то для защиты программ от несанкционированного копирования можно использовать методов привязки к идентификатору, формируемому инсталлятором. Суть данного метода заключается в том, что на винчестере при инсталляции защищаемой от копирования программы формируется уникальный идентификатор, наличие которого затем проверяется инсталлированной программой при каждом ее запуске. При отсутствии или несовпадении этого идентификатора программа блокирует свое дальнейшее выполнение.
Основным требованием к записанному на винчестер уникальному идентификатору является требование, согласно которому данный идентификатор не должен копироваться стандартным способом. Для этого идентификатор целесообразно записывать в следующие области жесткого диска:
- в отдельные кластеры области данных, которые должны помечаться затем в FAT как зарезервированные под операционную систему или как дефектные;
- в зарезервированные сектора системной области винчестера.
Некопируемый стандартным образом идентификатор может помещаться на дискету, к которой должна будет обращаться при каждом своем запуске программа. Такую дискету называют ключевой. Кроме того, защищаемая от копирования программа может быть привязана и к уникальным характеристикам ключевой дискеты. Следует учитывать, что при использовании ключевой дискеты значительно увеличивается неудобство пользователя, так как он всегда должен вставлять в дисковод эту дискету перед запуском защищаемой от копирования программы.
Методы, основанные на работа с переходами и стеком
Данные методы основаны на включение в тело программы переходов по динамически изменяемым адресам и прерываниям, а также самогенерирующихся команд (например, команд, полученных с помощью сложения и вычитания). Кроме того, вместо команды безусловного перехода (JMP) может использоваться возврат из подпрограммы (RET). Предварительно в стек записывается адрес перехода, который в процессе работы программы модифицируется непосредственно в стеке.
При работе со стеком, стек определяется непосредственно в области исполняемых команд, что приводит к затиранию при работе со стеком. Этот способ применяется, когда не требуется повторное исполнение кода программы. Таким же способом можно генерировать исполняемые команды до начала вычислительного процесса.
Манипуляции с кодом программы
При манипуляциях с кодом программы можно привести два следующих способа:
- включение в тело программы "пустых" модулей;
- изменение защищаемой программы.
Первый способ заключается во включении в тело программы модулей, на которые имитируется передача управления, но реально никогда не осуществляется. Эти модули содержат большое количество команд, не имеющих никакого отношения к логике работы программы. Но "ненужность" этих программ не должна быть очевидна потенциальному злоумышленнику.
Второй способ заключается в изменении начала защищаемой программы таким образом, чтобы стандартный дизассемблер не смог ее правильно дизассемблировать. Например, такие программы, как Nota и Copylock, внедряя защитный механизм в защищаемый файл, полностью модифицируют исходный заголовок EXE-файла.
Все перечисленные методы были, в основном направлены на противодействия статическим способам снятия защиты от копирования. В следующем подразделе рассмотрим методы противодействия динамическим способам снятия защиты.
3.4.2. Методы противодействия динамическим способам снятия защиты программ от копирования
Набор методов противодействия динамическим способам снятия защиты программ от копирования включает следующие методы [47].
- Периодический подсчет контрольной суммы, занимаемой образом задачи области оперативной памяти, в процессе выполнения. Это позволяет:
- заметить изменения, внесенные в загрузочный модуль;
- в случае, если программу пытаются "раздеть", выявить контрольные точки, установленные отладчиком.
- Проверка количества свободной памяти и сравнение и с тем объемом, к которому задача "привыкла" или "приучена". Это действия позволит застраховаться от слишком грубой слежки за программой с помощью резидентных модулей.
- Проверка содержимого незадействованных для решения защищаемой программы областей памяти, которые не попадают под общее распределение оперативной памяти, доступной для программиста, что позволяет добиться "монопольного" режима работы программы.
- Проверка содержимого векторов прерываний (особенно 13h и 21h) на наличие тех значений, к которым задача "приучена". Иногда бывает полезным сравнение первых команд операционной системы, отрабатывающих этим прерывания, с теми командами, которые там должны быть. Вместе с предварительной очисткой оперативной памяти проверка векторов прерываний и их принудительное восстановление позволяет избавиться от большинства присутствующих в памяти резидентных программ.
- Переустановка векторов прерываний. Содержимое некоторых векторов прерываний (например, 13h и 21h) копируется в область свободных векторов. Соответственно изменяются и обращения к прерываниям. При этом слежение за известными векторами не даст желаемого результата. Например, самыми первыми исполняемыми командами программы копируется содержимое вектора 21h (4 байта) в вектор 60h, а вместо команд int 21h в программе везде записывается команда int 60h. В результате в явном виде в тексте программы нет ни одной команды работы с прерыванием 21h.
- Постоянное чередование команд разрешения и запрещения прерывания, что затрудняет установку отладчиком контрольных точек.
- Контроль времени выполнения отдельных частей программы, что позволяет выявить "остановы" в теле исполняемого модуля.
Многие перечисленные защитные средства могут быть реализованы исключительно на языке Ассемблер. Одна из основных отличительных особенностей этого языка заключается в том, что для него не существует ограничений в области работы со стеком, регистрами, памятью, портами ввода/вывода и т.п.
Автокорреляция представляет значительный интерес, поскольку дает некоторую числовую характеристику программы. По всей вероятности автокорреляционные функции различного типа можно использовать и тестировании программ на технологическую безопасность, когда разработанную программу еще не с чем сравнивать на подобие с целью обнаружения программных дефектов. Таким образом, программы имеют целую иерархию структур, которые могут быть выявлены, измерены и использованы в качестве характеристик последовательности данных. При этом в ходе тестирования, измерения не должны зависеть от типа данных, хотя данные, имеющие структуру программы, должны обладать специфическими параметрами, позволяющими указать меру распознавания программы. Поэтому указанные методы позволяют в определенной мере выявить те изменения в программе, которые вносятся нарушителем либо в результате преднамеренной маскировки, либо преобразованием некоторых функций программы, либо включением модуля, характеристики которого отличаются от характеристик программы, а также позволяют оценить степень обеспечения безопасности программ при внесении программных закладок.
Оглавление Назад Вперед