Обзор алгоритмов MOLAP
Юрий Кудрявцев, факультет ВМиК МГУ
Подразделы
Многомерные кубы, определение и свойства
Рассмотрим базовую (фактическую) таблицу ![]() , на основе которой мы будем строить OLAP-куб. Множество атрибутов r условно делятся на 2 группы:
, на основе которой мы будем строить OLAP-куб. Множество атрибутов r условно делятся на 2 группы:
- Набор измерений (категорий, локаторов), которые служат критериями для анализа и определяют многомерное пространство OLAP-куба.
За счет фиксации значений измерений получаются срезы (гиперплоскости) куба. Каждый срез представляет собой запрос к данным, включающий агрегации.
- Набор мер — функции, которые каждой точке пространства ставят в соответствие данные.
Из атрибутов ![]() создаются измерения, содержащие проекцию r по атрибуту, с введенной иерархией (например, для таблицы, содержащей фактические данные по продажам магазина, возможно измерение ''Время'', содержащее иерархию вида ''Год-Месяц-Неделя-День''). Куб представляет собой декартово произведение измерений, где для каждого элемента произведения проставлен набор мер (существует проблема хранения неопределенных значений, подробнее см. Представление неопределенных данных). В кубе существуют отношения обобщения и специализации (roll-up/drill-down) по иерархиям измерений (подробнее об иерархиях см. Иерархии и агрегирование). Ячейка высокого уровня иерархии может ''спускаться'' (drill-down) к ячейке низкого уровня (для примера (R1, ALL, весна) может ''спуститься'' к ячейке (R1, книги, весна)) и наоборот, ''подняться'' (roll-up) (от (R1, книги, весна) к (R1, ALL, весна) по измерению ''продукты'').
создаются измерения, содержащие проекцию r по атрибуту, с введенной иерархией (например, для таблицы, содержащей фактические данные по продажам магазина, возможно измерение ''Время'', содержащее иерархию вида ''Год-Месяц-Неделя-День''). Куб представляет собой декартово произведение измерений, где для каждого элемента произведения проставлен набор мер (существует проблема хранения неопределенных значений, подробнее см. Представление неопределенных данных). В кубе существуют отношения обобщения и специализации (roll-up/drill-down) по иерархиям измерений (подробнее об иерархиях см. Иерархии и агрегирование). Ячейка высокого уровня иерархии может ''спускаться'' (drill-down) к ячейке низкого уровня (для примера (R1, ALL, весна) может ''спуститься'' к ячейке (R1, книги, весна)) и наоборот, ''подняться'' (roll-up) (от (R1, книги, весна) к (R1, ALL, весна) по измерению ''продукты'').
Пример
Рассмотрим пример, который будет и в дальнейшем использоваться в рамках данной работы.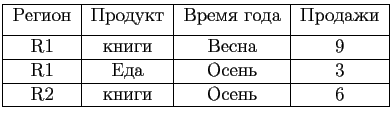

Размер куба данных определяется по формуле
![]() , где
, где ![]() -измерения (''столбцы''),
размерность измерения
-измерения (''столбцы''),
размерность измерения ![]() — количество различных значений кортежей по этому измерению (Select Count(distinct dimension) from table),
— количество различных значений кортежей по этому измерению (Select Count(distinct dimension) from table), ![]() отвечает за значение
отвечает за значение ![]() , агрегирующее все возможные значения измерения.
, агрегирующее все возможные значения измерения.
Таким образом, при базовой таблице в 3 кортежа результирующий куб в простой реляционной таблице (называемой Binary Storage Footprint), в которой напрямую хранятся все агрегаты, занимает 27 кортежей.
Измерения
Измерения куба — набор доменов, по которым создается многомерное пространство. Важной особенностью OLAP-моделей является разделение измерений на локаторы (задающие точки) и меры (задающие значение). Как отмечается в [23], данное разделение может носить как условный, так и жесткий характер. В случае условного разделения измерения можно ''разворачивать'' как данные и как аналитику, создавая новую аналитику куба по продажам — ''количество продаж''. Таким образом, возрастает гибкость моделей и уровень абстракции. Однако данный подход, несмотря на свою привлекательность, сложен в реализации (для примера отметим необходимость создания оптимальных алгоритмов хранения абстрактных типов данных) и, насколько нам известно, нигде промышленно не реализован. Теоретически, вкупе с моделированием решеток кубов логикой предикатов первого порядка, абстрагирование понятия ''измерение'' дает очень интересные результаты.
Локаторы куба отличаются иерархической структурой, и для получения значений мер на каждом уровне агрегирования вводятся агрегирующие функции.
Иерархии и агрегирование
Иерархичность данных — одно из важнейших свойств многомерных кубов. Иерархии призваны добавлять новые уровни в аналитическое пространство пользователя. Самым распространенным примером иерархии является ''день-неделя-месяц-год''. Соответственно, для уровней иерархии работают отношения обобщения и специализации (rollup/drilldown). Как правило, в научных работах рассматриваются простые примеры иерархий ''детальное значение — ALL'', однако, как мы увидим далее, подобного уровня детализации может быть недостаточно.
Все иерархии можно разбить на 2 типа, о которых пойдет речь ниже. Основой разбиения будет служить расстояние ![]() от корня (
от корня (
![]() ) до листьев. В случае, если
) до листьев. В случае, если ![]() , иерархии называются уровневыми (leveled), иначе — несбалансированными (ragged).
, иерархии называются уровневыми (leveled), иначе — несбалансированными (ragged).
Примеры типов иерархий:
- Уровневые:
- день-месяц-год; улица — город — страна
- Несбалансированные:
- Организационная диаграмма, различная группировка продуктов
Важным свойством уровневых иерархий является возможное наличие частичного порядка внутри каждого уровня иерархии, например, возможность сравнения месяцев по старшинству или городов по географическому положению. В большинстве современных средств (алгоритмов) данным свойством пренебрегают , удаляя, тем самым, потенциально полезные связи модели.
Агрегирующие функции, меры и формулы
Неотъемлемой частью OLAP-модели является задание функций агрегирования. Поскольку целью OLAP является создание многоуровневой модели анализа, данные на уровнях, отличных от фактического, должны быть соответствующим образом агрегированы. Важно отметить, что по каждому измерению можно задавать собственную (и не одну) функцию агрегации. Таким образом, в случае куба с ![]() измерениями функция агрегирования:
измерениями функция агрегирования:
где
В [7] приведена следующая классификация агрегирующих функций с точки зрения сложности распараллеливания.
- Дистрибутивные функции
- позволяют разбивать входные данные и вычислять отдельные итоги, которые потом можно объединять.
- Алгебраические функции
- можно представить комбинацией из дистрибутивных функций (например, Average() можно представить как

- Холистические функции
- невозможно вычислять на частичных данных или представлять каким-либо образом.
Эта классификация окажется полезной, когда мы будем рассматривать классы разбиения в алгоритме Quotient Cube (см. раздел Quotient Cube, работы [12],[11],[26]), в котором разбиение по покрытию применимо для дистрибутивных и алгебраических функций.