Обзор алгоритмов MOLAP
Юрий Кудрявцев, факультет ВМиК МГУ
Подразделы
Quotient Cube
Разбиение на классы ячеек
Идея этого алгоритма состоит в том, чтобы вместо хранения всех ячеек куба хранить только классы ячеек с одинаковым значением агрегирующей функции. Если же указать выпуклое разбиение (т.е. если две ячейкиОднако разбиение только по значению агрегирующей функции разрушает семантику куба (и тем более не выпукло). Покажем это.
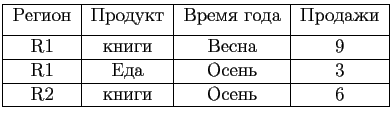
Например, рассмотрим еще раз таблицу Продажи из введения (Таблица 5.1). Получившиеся разбиение изображено на рис. 5.1.
У нас получается следующая схема (рисунок 5.2).
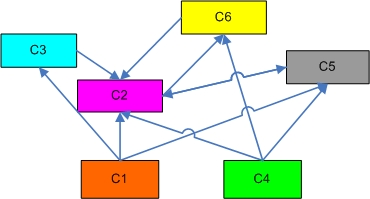
Выбор агрегирующей функции в данном случае не важен, т.к. у нас есть возможность двигаться в обе стороны по отношениям roll-up/drill-down. Например, можно пойти вверх от ячейки (ALL, ALL, ALL) в С2 в ячейку (ALL, книги, ALL) в C5, а потом в (R2, книги, ALL) в С2. Тем самым, нарушается семантика отношений roll-up/drill-down.
Таким образом, мы показали, что разбиение только по значению агрегирующей функции не порождает связанной решетки классов эквивалентности. Необходимы какие-то ограничения.
В первых работах по данному алгоритму в качестве разбиения предлагалось так называемое связанное разбиение, однако оно верно только для монотонных функций (Sum (слагаемые одного знака), Count и пр). Впоследствии было предложено разбиение по покрытию. Поэтому здесь в примерах используется AVG — немонотонная функция.
Будем рассматривать кортежи куба как решетку (CL(r), Cube Lattice над отношением r) с введенным порядком, определенным иерархиями измерений (т.е.
![]() ).
Введем определение покрытия для решетки (см [1],[2])
).
Введем определение покрытия для решетки (см [1],[2])
![]() .
.
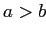
- не существует
 , такого, что
, такого, что 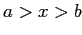
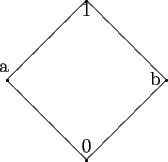
На диаграмме частично упорядоченного множества ![]() элементы изображаются в виде маленьких кружочков
элементы изображаются в виде маленьких кружочков ![]() ; кружки, соответствующие элементам x и у, соединяются прямой линией тогда и только тогда, когда один из них покрывает другой; если x покрывает y, то кружок, соответствующий элементу x, помещается выше кружка, соответствующего элементу y. Отметим, что в диаграмме пересечение двух линий не обозначает элемент. Диаграмма для решетки
; кружки, соответствующие элементам x и у, соединяются прямой линией тогда и только тогда, когда один из них покрывает другой; если x покрывает y, то кружок, соответствующий элементу x, помещается выше кружка, соответствующего элементу y. Отметим, что в диаграмме пересечение двух линий не обозначает элемент. Диаграмма для решетки ![]() изображена на рисунке 5.3.
изображена на рисунке 5.3.
Кортеж
![]() покрывает базовый (фактический) кортеж
покрывает базовый (фактический) кортеж ![]() , если
, если ![]() .
.
Определим отношение эквивалентности
![]() как транзитивное и рефлексивное замыкание
как транзитивное и рефлексивное замыкание ![]() , где:
, где:
![]()
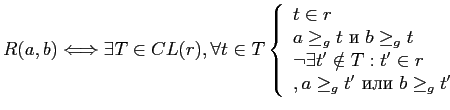
Введенные определения и теоремы позволяют утверждать, что разбиение по покрытию формирует полную решетку куба, только ячейками этой решетки будут являться классы ячеек обычной решетки. Причем у каждого класса будет существовать верхняя и нижняя грань, решетка будет связанной и выпуклой. Значения всех дистрибутивных и алгебраических функций для всех ячеек подобного класса эквивалентности будет совпадать.
Рассмотрим тот же пример, только на этот раз разбиение будет вестись по покрытию (рис. 5.4).
Соответствующая решетка по классам показана на рис. 5.5.
Таким образом, для получившегося куба нам нужно хранить только две ячейки на класс, верхнюю и нижнюю грань. Остальные ячейки выводятся из верхней и нижней грани, т.к. классы разбиения по покрытиям''полны'' в смысле введенного частичного порядка.
Для Quotient Cube предложено две структуры хранения данных: QC - Tables [12] и QC-Trees [11].
QC-Table — простая таблица, в которой для каждого класса хранится верхняя и нижняя грань. Предложены алгоритмы создания QC-Table и вставки/удаления классов. Такие таблицы неэффективны по времени обработки запросов, т.к. каждый запрос требует просмотра почти всей таблицы.
QC-Trees
QC-Tree — дерево с разделением префиксов, где грани представляются строчками, а связи отражают необходимые отношения drill-down. Основной идеей QC-деревьев является то, что верхние грани классов куба хранят всю необходимую информацию для выполнения запросов. Т.е. при данном подходе не хранятся даже нижние грани классов. При такой структуре хранения данных запросы над Quotient-кубами выполняются эффективнее запросов над DWARF-кубами. Достигается это превосходство на основе аналогичного по смыслу устранения суффиксной и префиксной избыточностей. QC-деревья позволяют устранять суффиксную избыточность за счет того, что хранятся только классы, а не отдельные ячейки. Префиксная избыточность устраняется за счет свойств самой структуры QC-tree.
-
 ребра и
ребра и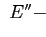 связи,
причем
связи,
причем 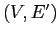 — это дерево;
— это дерево;
- каждая вершина содержит метку, равную значению одного из измерений;
- для каждой верхней грани
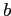 существует и единственна вершина
существует и единственна вершина 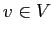 такая, что строчное представление
совпадает с последовательностью меток
вершин на пути от корня к
такая, что строчное представление
совпадает с последовательностью меток
вершин на пути от корня к 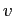 в (V,
в (V,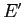 ); эта вершина хранит агрегирующее
значение для
.
); эта вершина хранит агрегирующее
значение для
.
- предположим, что
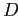 и
и 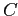 — классы в
— классы в 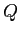 ,
,
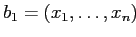 и
и
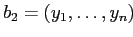 — их верхние грани, и что
— потомок
(например, что
напрямую специализирует (drills-down)
)
в
; тогда для каждого измерения
— их верхние грани, и что
— потомок
(например, что
напрямую специализирует (drills-down)
)
в
; тогда для каждого измерения 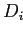 , на котором различаются
, на котором различаются 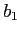 и
и 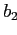 ,
существует либо ребро дерева, либо связь (маркированная
,
существует либо ребро дерева, либо связь (маркированная 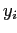 )
из вершины
)
из вершины
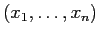 в вершину
в вершину
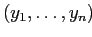 .
.
Доказана теорема, о том, что QC-дерево для каждого Quotient куба уникально. Существуют алгоритмы создания/поддержки QC-деревьев. Выполнение запросов на QC-деревьях сильно отличается от аналогичных алгоритмов в других методах, т.к. необходимо ''выводить'' содержимое ячейки из верхней и нижней гранях класса. Аналогично, поддержка изменений информации требует пересмотра решетки классов, что, в общем случае, замедляет внесение изменений. В таблице 5.2 показаны классы и верхние грани Quotient-куба для примерных данных из таблицы 5.1, а на рис. 5.6 — соответствующее QC-Tree.
Выполнение различных типов запросов
Точечные запросы
Алгоритм.
-
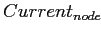 = корень;
= корень;
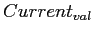 =
=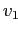
- На любом узле
искать дугу с меткой
,
если существует:
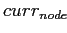 = потомок по найденной дуге;
= потомок по найденной дуге;
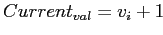
иначе: проверить последнее измерение j, по которому у
есть потомок.
Если
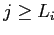 , тогда
, тогда 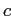 в кубе не появится.
в кубе не появится.
Иначе:
= потомок по измерению j, снова повторяем 2.
Примеры
- (R2,*,осень)
 начинаем с корня, находим вершину 7, в
вершине 7 ищем ''осень'', берем потомка по измерению, продукты,
попадаем в 9 — есть ответ.
начинаем с корня, находим вершину 7, в
вершине 7 ищем ''осень'', берем потомка по измерению, продукты,
попадаем в 9 — есть ответ.
- (R2,*,весна)
все тоже самое, но в 9 мы
будем пытаться найти ''весна''
такой ячейки нет
(*,еда,*)
в 5, но там нет значения, ''проваливаемся'' в 6 — ответ
Интервальные запросы
Запрос:Порядок обработки запроса (*, книги, еда, весна) следующий:
корень
![]() книги
книги
![]() весна — возвращается значение;
весна — возвращается значение;
корень
![]() еда — но не можем попасть в ''весну''.
еда — но не можем попасть в ''весну''.
Обратные запросы
Прямой оптимизации по выполнению обратных запросов метод не дает. Но возможно построение индексов B+ деревьев по мерам в QC-деревьях. Это поможет в выполнении обратных запросов, не накладывающих ограничений на измерения. В случае наличия ограничений в запросе можно оставить в QC-дереве только вершины, удовлетворяющие условию и их предков. Получится поддерево, на котором нужно выполнить интервальный запрос.Intelligent Roll-Up Queries
Также необходимо отметить, что метод Quotient-кубов дает быстрый ответ на так называемые "умные" roll-up запросы (Intelligent Roll-Up Queries). Ответ на данные запросы дается во время построения Quotient-кубов, т.к. это и есть верхние и нижние границы кубов.