Часть 5. Средства и методологии проектирования, разработки и сопровождения Intranet-приложений
Как мы отмечали в разделе 2.3, Intranet-приложение - это корпоративная система, для организации которой используются механизмы Internet. Intranet-система может основываться на локальной сети компьютеров, собственной корпоративной глобальной сети или виртуальной корпоративной подсети Internet. Различают несколько типов Intranet-систем, для реализации каждого из которых, вообще говоря, применяются разные средства:
- Коммуникационные Intranet-системы предназначены главным образом для связывания территориально разнесенных подразделений корпорации, уменьшая потребность в многочисленных выделенных линиях связи. При реализации систем этого типа следует обращать особое внимание на эффективность, соответствие стандартам и управляемость системы.
- Интегрирующие Intranet-системы служат для интеграции разнородных существующих коммуникационных и обрабатывающих корпоративных подсистем. С этой точки зрения достоинством Intranet-системы является поддержка общего интерфейса доступа к "унаследованным" системам и установление связи между ними за счет понимаемого всеми гипертекстового представления информации.
- Если от Intranet-системы требуется обеспечение широкого доступа к большим объемам информации, в частности, мультимедийной, то особое внимание требуется уделить выбору базового сервера баз данных. Нужно учитывать возможности сервера по части управления очень большими данными и поддержки сложных типов данных.
- Intranet-системы с упрощенной для пользователей процедурой доступа обычно основываются на механизме электронной подписи. Такие системы должны быть особенно надежно защищены от внешнего мира.
Конечно, в общем случае информационная Intranet-система может включать свойства каждого из перечисленных типов, и в этом случае при ее разработке придется учитывать все требования.
Естественно, эта часть курса не может заменить развернутого изложения принципов построения, администрирования и сопровождения Intranet-систем. Эта тема очень широка, и мы только бегло рассмотрим некоторые ее аспекты. 51
5.1. Основные понятия Intranet
Поскольку для разработки Intranet-систем используются методы и средства Internet, и главным образом, технология WWW, то и понятия и термины Internet и Intranet совпадают. Приведем некоторые из них:
HTTP (HyperText Transfer Protocol) - протокол обмена гипертекстовой информацией;
URL (Universal Resource Locator) - универсальный локатор ресурсов. Используется в качестве универсальной схемы адресации ресурсов в сети.
HTML (HyperText Markup Language) - язык гипертекстовой разметки документов. Специальная форма подготовки документов для их опубликования в World Wide Web.
CGI (Common Gateway Interface) - спецификация на формат обмена данными между сервером протокола HTTP и прикладной программой.
API (Application Program Interface) - в данном контексте это спецификация, определяющая правила обмена данными между сервером и программным модулем, который должен быть включен в состав сервера.
VRML (Virtual Reality Modeling Language) - язык описания трехмерных сцен и взаимодействия трехмерных объектов.
Javaapplets - мобильные (независимые от архитектуры "железа") программные коды, написанные на языке программирования Java.
Java - объектно-ориентированный язык программирования, разработанный компанией Sun Microsystems и используемый в качестве основного средства мобильного программирования.
MIME (Multipurpose Internet Mail Exchange) - формат почтового сообщения Internet. В данном контексте стандарт MIME используется для установления соответствия между типом информационного файла, именем этого файла и программой просмотра этого файла.
CCI (Common Client Interface) - спецификация обмена данными меду прикладной программой и браузером Mosaic. В случае применения программного обеспечения, выполненного согласно CCI, браузер превращается в сервер-посредник для программного обеспечения пользователя.
5.2. Языки и протоколы
К 1989 году гипертекст представлял новую, многообещающую технологию, которая имела относительно большое число реализаций с одной стороны, а с другой стороны делались попытки построить формальные модели гипертекстовых систем, которые носили скорее описательный характер и были навеяны успехом реляционного подхода описания данных. Идея Т.Бернерс-Ли заключалась в том, чтобы применить гипертекстовую модель к информационным ресурсам, распределенным в сети, и сделать это максимально простым способом. Он заложил три краеугольных камня системы, разработав: язык гипертекстовой разметки документов HTML (HyperText Markup Language), универсальный способ адресации ресурсов в сети URL (Universal Resource Locator), протокол обмена гипертекстовой информацией HTTP (HyperText Transfer Protocol). Позже команда NCSA (National Center of Supercomputer Applications) добавила к этим трем компонентам четвертый - универсальный интерфейс шлюзов CGI (Common Gateway Interface). Усовершенствования на этом не остановились. В 1995 году Netscape Communication предлагает включить в текст HTML-страниц программы на новом языке Liveware. Позже это название было изменено на JavaScript. Таким образом технология World Wide Web была дополнена еще одним компонентом - языком программирования просмотра гипертекстовых страниц JavaScript.
Исходя из важности технологии WWW для построения корпоративных Intranet-систем, мы для начала коротко рассмотрим два базовых компонента этой технологии - язык гипертекстовой разметки документов HTML и протокол обмена гипертекстовой информацией HTTP.
5.2.1. HTML
В 1989 году, когда Т.Бернерс-Ли предложил свою систему, в мире информационных технологий наблюдался повышенный интерес к новому и модному в то время направлению - гипертекстовым системам. Сама идея, но не термин, была введена В.Бушем (Vannevar Bush) в 1945 году в предложениях по созданию электромеханической информационной системы Memex. Несмотря на то, что Буш был советником по науке президента Рузвельта, идея не была реализована. В 1965 году Т.Нельсон (Ted Nelson) ввел в обращение сам термин "гипертекст", развил и даже реализовал некоторые идеи, связанные с работой с "нелинейными" текстами. В 1968 году изобретатель манипулятора "мышь" Д.Енжильбард (Doug Engelbart) продемонстрировал работу с системой, имеющей типичный гипертекстовый интерфейс, и, что интересно, проведена эта демонстрация была с использованием системы телекоммуникаций. Однако внятно описать свою систему он не смог. В 1975 году идея гипертекста нашла воплощение в информационной системе внутреннего распорядка атомного авианосца "Карл Винстон", которая получила название ZOG. В коммерческом варианте система известна как KMS. Работы в этом направлении продолжались, и время от времени появлялись реализации типа HyperCard фирмы Apple или HyperNode фирмы Xerox. В 1987 была проведена первая специализированная конференция Hypertext'87, материалам которой был посвящен специальный выпуск журнала "Communication ACM".
Идея гипертекстовой информационной системы состоит в том, что пользователь имеет возможность просматривать документы (страницы текста) в том порядке, в котором ему это больше нравится, а не последовательно, как это принято при чтении книг. Поэтому Т.Нельсон и определил гипертекст как нелинейный текст. Достигается это путем создания специального механизма связи различных страниц текста при помощи гипертекстовых ссылок, т.е. у обычного текста есть ссылки типа "следующий-предыдущий", а у гипертекста можно построить еще сколь угодно много других ссылок. Любимыми примерами специалистов по гипертексту являются энциклопедии, Библия, системы типа "Help".
Простой, на первый взгляд, механизм построения ссылок оказывается довольно сложной задачей, т.к. можно построить статические ссылки, динамические ссылки, ассоциированные с документом в целом или только с отдельными его частями, т.е. контекстные ссылки. Дальнейшее развитие этого подхода приводит к расширению понятия гипертекста за счет других информационных ресурсов, включая графику, аудио- и видео-информацию, до понятия гипермедиа. Тем, кто интересуется более подробно различными схемами и способами разработки гипертекстовых систем, стоит обратиться к специальной литературе.
При разработке HTML была поставлена задача решить две основных проблемы:
- дать дизайнерам гипертекстовых баз данных простое средство создания документов;
- сделать это средство достаточно мощным, чтобы отразить имевшиеся на тот момент представления об интерфейсе пользователя гипертекстовых баз данных.
Первая задача была решена за счет выбора таговой модели описания документа. Такая модель широко применяется в системах подготовки документов для печати. Примером такой системы является хорошо известный язык разметки научных документов TeX, предложенный Американским Математическим Обществом, и программы его интерпретации.
К моменту создания HTML существовал стандарт языка разметки печатных документов - Standard Generalised Markup Language, который и был взят в качестве основы HTML. Предполагалось, что такое решение поможет использовать существующее программное обеспечение для интерпретации нового языка. Однако, будучи доступным широкому кругу пользователей Internet, HTML зажил своей собственной жизнью. Вероятно, многие администраторы баз данных WWW и разработчики программного обеспечения для этой системы имеют довольно смутное представление о стандартном языке разметки SGML.
Вторым важным моментом, повлиявшим на судьбу HTML, стал выбор в качестве элемента гипертекстовой базы данных обычного текстового файла, который хранится средствами файловой системы операционной среды компьютера. Такой выбор был сделан под влиянием следующих факторов:
- такой файл можно создать в любом текстовом редакторе на любой аппаратной платформе в среде любой операционной системы.
- к моменту разработки HTML существовал американский стандарт для разработки сетевых информационных систем - Z39.50, в котором в качестве единицы хранения указывался простой текстовый файл в кодировке LATIN1, что соответствует US ASCII.
Таким образом, гипертекстовая база данных в концепции WWW - это набор текстовых файлов, написанных на языке HTML, который определяет форму представления информации (разметка) и структуру связей этих файлов (гипертекстовые ссылки). Но это только концепция, в реальной жизни все оказалось гораздо сложнее. В ряде случаев реальная страница Website собирается из различных файлов, записей баз данных и результатов выполнения скриптов, но в любом случае браузер получает правильно размеченный на HTML текст.
Такой подход предполагает наличие еще одной компоненты технологии - интерпретатора языка. В World Wide Web функции интерпретатора разделены между сервером гипертекстовой базы данных и интерфейсом пользователя.
Сервер, кроме доступа к документам и обработки гипертекстовых ссылок, осуществляет также предпроцессорную обработку документов, в то время как интерфейс пользователя осуществляет интерпретацию конструкций языка, связанных с представлением информации.
К настоящему времени известна уже третья версия языка - HTML 3.2, которая находится в стадии развития. Если первая версия языка (HTML 1.0) была направлена на представление языка как такового, где описание его возможностей носило скорее рекомендательный характер, вторая версия языка (HTML 2.0) фиксировала практику использования конструкций языка, версия ++ (HTML++) представляла новые возможности, расширяя набор элементов HTML в сторону отображения научной информации и таблиц, а также улучшения стиля компоновки изображений и текста, то версия 3.2 призвана упорядочить все нововведения и согласовать их с существующей практикой. Кроме этого, в версии 3.2 снова делается попытка формализации интерфейса пользователя гипертекстовой распределенной системы. Однако, коммерческое использование World Wide Web постепенно вытесняет или сильно замедляет использование научных расширений языка. Так математическую разметку документа поддерживает только один браузер Arena.
Главным следствием влияния программного обеспечения на развитие языка, является включение в HTML механизма форм заполнения (FILL-OUT FORMS).
Формы впервые были подробно описаны в инструкциях по использованию сервера NCSA. До введения форм в WWW был только один механизм передачи параметров - поле ключевых слов. WWW была информационно-справочной системой и только. Формы произвели революцию в технологии WWW и превратили ее в технологию открытой системы. Посредством форм стала возможна передача параметров внешним программам, которые вызываются сервером, что сделало WWW универсальным интерфейсом ко всем ресурсам сети.
Формы реализуются с помощью элемента FORM и ряда вложенных в него элементов:
| Элемент | Назначение |
| INPUT | поля ввода информации имеют множество типов |
| TEXTAREA | поле ввода многострочного текста |
| SELECT | описание меню |
| OPTION | описание элемента меню |
Все эти элементы имеют довольно большое количество атрибутов, которые далеко не все реализованы в большинстве интерфейсов.
Вторым краеугольным камнем WWW стала универсальная форма адресации информационных ресурсов. Universal Resource Identification (URI) представляет собой довольно стройную систему, учитывающую опыт адресации и идентификации e-mail, Gopher, WAIS, telnet, ftp и т. п. Но реально из всего, что описано в URI, для организации баз данных в WWW требуется только Universal Resource Locator (URL). Без наличия этой спецификации вся мощь HTML оказалась бы бесполезной. URL используется в гипертекстовых ссылках и обеспечивает доступ к распределенным ресурсам сети. В URL можно адресовать как другие гипертекстовые документы формата HTML, так и ресурсы e-mail, telnet, ftp, Gopher, WAIS. Различные интерфейсные программы по-разному осуществляют доступ к этим ресурсам. Одни, как, например, Netscape, сами способны поддерживать взаимодействие по протоколам, отличным от протокола HTTP, базового для WWW, другие, как например Chimera, вызывают для этой цели внешние программы. Однако, даже в первом случае, базовой формой представления отображаемой информации является HTML, а ссылки на другие ресурсы имеют форму URL. Следует отметить, что программы обработки электронной почты в формате MIME также имеют возможность отображать документы, представленные в формате HTML. Для этой цели в MIME зарезервирован тип "text/html".
5.2.2. HTTP
HTTP - это протокол прикладного уровня, разработанный для обмена гипертекстовой информацией в сети Internet. Протокол используется одной из популярнейших систем Сети - Word Wide Web - с 1990 года.
Реальная информационная система требует гораздо большего количества функций, чем просто поиск. HTTP позволяет реализовать в рамках обмена данными набор методов доступа, базирующихся на спецификации универсального идентификатора ресурсов (Universal Resource Identifier), применяемого в форме универсального локатора ресурсов (Universe Resource Locator) или универсального имени ресурса (Universal Resource Name). Сообщения по сети при использовании протокола HTTP передаются в формате, схожим с форматом почтового сообщения Internet (RFC-822) или с форматом сообщений MIME (Multiperposal Internet Mail Exchange). HTTP используется для взаимодействия программ-клиентов с программами-шлюзами, разрешающими доступ к ресурсам электронной почты Internet (SMTP), спискам новостей (NNTP), файловым архивам (FTP), системам Gopher и WAIS. Протокол разработан для доступа к этим ресурсам посредством промежуточных программ-серверов (proxy), которые позволяют передавать информацию между различными информационными службами без потерь. Протокол реализует принцип "запрос/ответ". Запрашивающая программа - клиент - инициирует взаимодействие с отвечающей программой - сервером, и посылает запрос, включающий в себя метод доступа, адрес URI, версию протокола, похожее по форме на MIME-сообщение с модификаторами типа передаваемой информации, информацию клиента, и, возможно, тело сообщения клиента. Сервер отвечает строкой состояния, включающей версию протокола и код возврата, за которой следует сообщение в форме, похожей на MIME. Данное сообщение содержит информацию сервера, метаинформацию и тело сообщения. Понятно, что в принципе, одна и та же программа может выступать и в роли сервера и в роли клиента (так собственно и происходит при использовании proxy-серверов).
При работе в Internet для обслуживания HTTP-запросов используется 80 порт TCP/IP. Практика использования протокола такова, что клиент устанавливает соединение и ждет ответа сервера. После отправки ответа сервер инициирует разрыв соединения. Таким образом, при передаче сложных гипертекстовых страниц соединение может устанавливаться несколько раз. Остановимся более подробно на механизме взаимодействия и форме передаваемой информации.
5.2.2.1. Форма запроса клиента
Программа-клиент посылает после установления соединения запрос серверу. Этот запрос может быть в двух формах: в форме полного запроса и в форме простого запроса. Простой запрос содержит метод доступа и запрос ресурса. Например:
GET http://polyn.net.kiae.su/
В этой записи слово GET обозначает метод доступа GET, а http://polyn.net.kiae.su/ - это запрос ресурса. Клиенты, которые способны поддерживать версии протокола выше 0.9 должны пользоваться полной формой запроса. При использовании полной формы в запросе указываются строка запроса, несколько заголовков (заголовок запроса или общий заголовок) и, возможно, тело обозначения ресурса. В форме Бекуса-Наура общий вид полного запроса выглядит так:
<Полный запрос> := <Строка Запроса> (<Общий заголовок> <Заголовок запроса> <Заголовок обозначения ресурса>)<символ новой строки>[<тело ресурса>]
Квадратные скобки здесь обозначают необязательные элементы заголовка. Строка запроса - это, практически, простой запрос ресурса. Отличие состоит в том, что в строке запроса можно указывать различные методы доступа и за запросом ресурса следует указывать версию протокола. Например, для вызова внешней программы можно использовать следующую строку запроса:
POST http://polyn.net.kiae.su/cgi-bin/test HTTP/1.0
В данном случае используется метод POST и протокол версии 1.0.
5.2.2.2. Методы доступа
В настоящее время в практике World Wide Web реально используются только три метода доступа: POST, GET, HEAD.
GET - метод, позволяющий получить данные, заданные в форме URI в запросе ресурса. Если ссылаются на программу, то возвращается результат выполнения этой программы, но не текст программы. Дополнительные данные, которые надо передать для обработки, кодируются в запрос ресурса. Имеется разновидность метода GET - условный GET. При использовании этого метода сервер ответит на запрос только в том случае, если будут выполнены условия передачи. Это позволяет разгрузить сеть, избавив ее от передачи ненужной информации. Условие указывается в поле "if-Modified-Since" заголовка запроса. При использовании метода GET в поле тела ресурса возвращается собственно затребованная информация (текст HTML-документа, например).
HEAD - метод, аналогичный GET, но не возвращает тела ресурса. Используется для получения информации о ресурсе. Условного HEAD не существует. Данный метод используется для тестирования гипертекстовых ссылок.
POST - этот метод разработан для передачи большого объема информации на сервер. Им пользуются для аннотирования существующих ресурсов, посылки почтовых сообщений, работы с формами интерфейсов к внешним базам данных и внешним исполняемым программам. В отличии от GET и HEAD, в POST передается тело ресурса, которое и является информацией из поля форм или других источников ввода. В первых версиях протокола были определены и другие методы доступа (DELETE, например), но они не нашли должного применения. Многие функции, которые возлагали на эти методы, можно успешно выполнять через POST.
Изменение числа методов доступа отражает практику использования HTTP. Однако, с исторической и методической точек зрения, первые версии протокола представляют несомненный интерес, особенно раздел, описывающий методы доступа. В версии 1993 года насчитывалось 13 различных методов доступа. Среди этих методов были такие, например, как:
- CHECKOUT - защита от несанкционированного доступа;
- PUT - замена содержания информационного ресурса;
- DELETE - удаление ресурса;
- LINK - создание гипертекстовой ссылки;
- UNLINK - удаление гипертекстовой ссылки;
- SPACEJUMP - переход по координатам;
- SEARCH - поиск.
Из этого списка видно, что протокол был действительно максимально ориентирован на работу с гипертекстовыми распределенными системами, причем не только с точки зрения потребителя, но и с точки зрения разработчика подобных систем. Однако, во-первых, как показывал опыт, практически не использовались методы доступа, связанные с изменением информации. Это объясняется прежде всего соображениями безопасности. Ни один администратор не позволит неизвестно кому менять информацию на его сервере. Во-вторых, методы SPACEJUMP и SEARCH были с успехом заменены на функционально аналогичные CGI-скрипты. Из этого не следует, что их возрождение невозможно, например, в язык гипертекстовой разметки вернулись ссылки, общие для всего документа, но пока их реализация в протоколе отложена. В-третьих, не нашли практической реализации методы установления/удаления ссылок LINK и UNLINK. Но необходимость в них растет и связана она с реорганизацией сети. Многие информационные ресурсы меняют свои адреса, что вносит беспорядок в структуру сети, где и без этого начинающему пользователю трудно что-либо найти. Одним словом, вопрос о новых методах доступа все еще открыт, поэтому, видимо, спецификация HTTP еще не вышла на стадию RFC и остается в виде Internet Draft.
В обеих формах запроса важное место занимает форма запроса ресурса, которая кодируется в соответствии со спецификацией URI. Применительно к World Wide Web эта спецификация получила название URL. При обращении к серверу можно использовать как полную форму URL, так и упрощенную.
Полная форма содержит тип протокола доступа, адрес сервера ресурса, и адрес ресурса на сервере (рисунок 5.1).
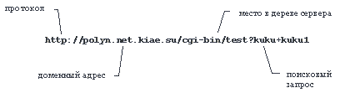
Рис. 5.1. Полный адрес ресурса
Однако такой адрес реально нужен для работы через промежуточный сервер, так как тот может пересылать запросы. При обращении к первичному серверу клиент может опускать протокол и адрес, устанавливая взаимодействие с сервером по адресу, указанному в URL (в исходном документе), и порту 80, передавая только путь от корня сервера.
Здесь пока оставим обсуждение элементов запроса и обратимся к структуре ответа сервера. Дело в том, что элементы заголовков запроса и ответа одинаковые, и поэтому их имеет смысл обсудить после определения структуры ответа сервера.
5.2.2.3. Ответ сервера
Ответ сервера может быть, как и запрос, упрощенным или полным. При упрощенном ответе сервер возвращает только тело ресурса (например, текст HTML-документа). При полном ответе клиенту возвращается строка состояния (Status-Line), общий заголовок, заголовок ответа, заголовок ресурса и тело ресурса. В форме Бекуса-Наура полный ответ представляется следующим образом:
<Полный ответ> := <Строка состояния> (<Общий заголовок> <Заголовок ответа> <Заголовок ресурса>) <символ новой строки>[<тело ресурса>]
Строка состояния состоит из версии протокола, кода возврата и краткого описания этого кода. Например, она может выглядеть так:
"HTTP/1.0 200 Success".
Заголовок ответа сервера может состоять из адреса URI запрашиваемого ресурса, и/или наименования программы сервера, и/или кода идентификации для работы в защищенном режиме. Состав полей заголовка ресурса является общим и для запроса клиента и для ответа сервера, и состоит из разрешения на метод доступа, типа кодировки тела ресурса (содержания ресурса), длины тела ресурса, типа ресурса, время действия данной копии ресурса, времени последнего изменения ресурса и расширения заголовка.
Рассмотрим более подробно поля заголовка, обращая внимание на реальное применение каждого из них и возможность проявления ошибок при обработке этих полей разными программами (серверами и клиентами).
Если в заголовке ответа сервера указано предложение Location, то это значит, что требуемый ресурс находится по другому адресу и его надо запросить заново. Такая процедура называется перенаправлением. Перенаправление в заголовке будет выглядеть как:
Location: http://apollo.polyn.kiae.su/risk/riskform.html
Имя и версия сервера указываются в поле Server. При использовании сервера CERN данное поле будет выглядеть как:
Server: CERN/3.0 libwww/2.17
В заголовке может встречаться и поле контроля доступа WWW-Authenticate, которое определяет способ доступа к закрытым ресурсам. Например, это поле может выглядеть как:
WWW-Authenticate: Basic realm="WallyWorld"
Кроме рассмотренных выше полей, в заголовке могут встретиться и другие поля, которые определяют содержание тела передаваемого ресурса. Эти поля относятся к заголовку ресурса, но в ответе сервера они встречаются вперемешку с общими полями. Поле Allow определяет разрешенные методы доступа к ресурсу:
Allow: GET,HEAD
Поле Сontent-Encoding определяет тип кодирования передаваемого ресурса:
Content-Encoding: x-gzip
В данном случае указывается, что ресурс является заархивированным файлом в формате zip. Обычно ресурсы хранятся в виде, указанном в данном поле, и при их получении клиент должен обеспечить их преобразование в приемлемый для отображения вид. Это своего рода предобработка данных, которая базируется обычно на MIME типах. В машинах, где недостаточно памяти на видео-адаптерах, используют предобработку для преобразования изображений в приемлемый для отображения вид. Так, например, для персональных компьютеров с 512 КБ памяти на видеоадаптере используют предобработку для преобразования 256-цветных картинок в 16-цветные. Если этого не делать, то можно наблюдать интересный эффект: в Unix-системах при работе с программами Chimera и Mosaic 256-цветные картинки удваиваются, т.е. вместо одной на экране отображаются последовательно две картинки. Это связано с тем, что для 256 цветов нужно ровно в два раза больше памяти, чем для 16. Для того, чтобы избежать двойного отображения встроенных в текст картинок, их следует преобразовать.
Другим полем, которое проявляет себя при работе в сети, порождая ошибки отображения ранними версиями программ просмотра или ранним версиями программ серверов, является поле Content-Length. Поле Content-Length указывает размер (количество байтов) передаваемого ресурса. Это поле указывается как клиентом при работе по методу POST, так и сервером при ответе на запросы клиентов. При этом в ранних версиях программ-серверов может порождаться ошибка, вызванная возможностью вставки сервером некоторой информации в текст ресурса. Например, сервер NCSA (1.3) позволяет вставлять в текст HTML-документов фрагменты текста из других файлов при помощи выражения типа:
<!--#includes virtual="/include/commonheader.html" -->
В данном случае речь идет об общей заставке для всех документов некоторого раздела. На сервере в директории документов хранится файл одного размера, но после выполнения подстановки размер файла увеличивается, однако, сервер сообщает клиенту старый размер файла. Новые программы-клиенты (Netscape, Mosaic) неправильно обрабатывают такой ответ и информация не отображается.
Поле Content-Type определяет тип информации, передаваемой сервером. Наиболее часто используются типы text/play - простой тест и text/html - документ в формате HTML. Для сокращения трафика по сети существует несколько полей, связанных со временем передачи информации и периодичностью ее изменения на серверах. Поле Date определяет время отправки сообщения. Информация из данного поля сохраняется в файле статистики сервера и может быть использована для анализа доступа к ресурсам сервера из сети.
Поле Expires определяет время годности ресурса для использования. Если время использования вышло, то ресурс не должен передаваться. Точнее, его не следует передавать и принимать. О поле if-Modified-Sience уже упоминалось. Оно предназначено для того, чтобы не передавать имеющиеся у клиента копии ресурса, если не были произведены его изменения. Поле Pragma используется при передаче сообщений с сервера на сервер. Реально известно только одно значение данного поля: no-cache, которое запрещает запоминать в буфере данные для последующего использования.
Поле Referer используется для того, чтобы указать, из какого ресурса была осуществлена ссылка на ресурс. Данное поле - это мечта любого администратора базы данных сети. При помощи информации из этого поля можно определить, в каких WWW-страницах прописан конкретный сервер. От этого зависит количество обращений к серверу, "качество" пользователей, время отклика на информацию, размещаемую на сервере. При необходимости можно связаться с администратором этого сервера и уведомить его об изменениях на вашем сервере.
5.2.2.4. Защита сервера от несанкционированного доступа
Отдельное место при обсуждении протокола занимают вопросы, связанные с обеспечением защиты ресурсов сервера от несанкционированного доступа. Как было отмечено в предыдущих разделах, первоначально разработка защищенных способов обмена данными в системе World Wide Web не предполагалась. Однако быстрое развитие популярности системы привело к тому, что многие коммерческие организации стали устанавливать серверы HTTP на свои машины. Кроме этого, конфиденциальной информации много и в научно-исследовательских государственных организациях. Таким образом, возникла необходимость в разработке механизмов защиты информации для системы WWW.
Проблема защиты информации на Internet - это отдельная большая тема. В данном разделе мы рассмотрим только обеспечение безопасности при использовании серверов HTTP.
Первая связана с чтением защищенных текстовых файлов. Для решения этой задачи имеется достаточно много традиционных механизмов, встроенных в операционные системы. Проблема возникает, если администратор системы решит использовать для размещения WWW-файлов и FTP-архива одно и тоже дисковое пространство. В этом случае защищенные WWW-файлы окажутся доступными для "анонимного" FTP-доступа. Многие серверы разрешают создавать в дереве поддерживаемых ими документов "домашние" страницы пользователей с помощью методов POST и GET. Это значит, что пользователи могут изменять информацию на компьютере сервера. Данные, вводимые пользователем, передаются как тело ресурса при методе POST через стандартный ввод, а методе GET через переменные окружения. Естественно, что разрешение создания файлов на сервере протокола HTTP создает потенциальную опасность доступа к защищенной информации лиц, не имеющих права доступа к ней. Решается эта проблема путем создания специальных файлов прав пользователей сервера WWW.
Рис. 5.2. Схема управления ресурсов сервером HTTP
Вторая возможность проникновения в компьютерную систему через сервер WWW связана с CGI-скриптами. CGI-скрипт - это программа, которую сервер HTTP может запускать для реализации механизмов, не предусмотренных в протоколе. Многие достаточно мощные информационные механизмы WWW реализованы посредством CGI-скриптов. К ним относятся: программы поиска по ключевым словам, программы реализации графических гипертекстовых ссылок - imagemap, программы сопряжения с системами управления базами данных и т.п. Естественно, что при этом появляется возможность получить доступ к системным ресурсам. Обычно внешняя программа запускается с идентификатором пользователя, отличным от идентификатора сервера. Данный идентификатор указывается при конфигурировании сервера. Наиболее безопасным здесь является идентификатор пользователя nobody (65534). Основная опасность скриптов заключена в том, что данные в скрипт посылаются программой-клиентом. Для того, чтобы в качестве параметров не передавали "подозрительных" данных, многие серверы производят проверку параметров на наличие допустимых символов. Особенно опасны скрипты для тех, кто использует сервер на персональном компьютере с MS-Windows 3.1. В этом случае файловая система практически не защищена. Одной из характерных для скриптов проблем является размер входных данных. Многие "умные" серверы обрезают слишком большие входные потоки и тем самым защищают скрипты от "поломки". Кроме перечисленных выше опасностей, порождаемых природой сети и системы WWW, существует еще одна, связанная с такой экзотикой, как мобильные коды. Мобильный код - это программа, которая может передаваться по сети для выполнения ее клиентом. Код встраивается в WWW-страницу при помощи тага <APP ...> - application. Например, Sun выпустила WWW-клиента HotJava, который позволяет интерпретировать язык Java. Существуют клиенты и для других языков, Safe-Tcl для Tcl, например. Главное назначение таких средств - реализация мультимедийных страниц и реализация работы в rеal-time. Опасность применения такого сорта страниц очевидна, так как повторяет способ распространения различного сорта вирусов. Однако пока речи о защите от такого сорта "взломов" не идет, видимо в силу довольно ограниченного применения данной возможности в сети.
Практически любой сервер имеет механизм назначения паролей и прав доступа для различных пользователей, который базируется на схеме идентификации протокола HTTP 1.0. Данная схема предполагает, что программа-клиент посылает серверу идентификатор пользователя и пароль. Понятно, что такой механизм не обеспечивает защиты передаваемой по сети информации, и она может стать легкой добычей злоумышленников.
Для того, чтобы этого не происходило, в рамках WWW ведется разработка других схем защиты. Они строятся на двух широко известных принципах: контроль доступа по IP-адресам и шифрация. Первый принцип реализован в программе типа "стена" (Firewall). Сервер разрешает обращаться к себе только с определенных IP-адресов и выполнять только определенные операции. Слабое место такого подхода с точки зрения WWW заключается в том, что обратиться могут через сервер-посредник, которому разрешен доступ к ресурсам защищенного первичного сервера. Поэтому применяют шифрование паролей и идентификаторов по аналогии с системой "Керберос". На принципе шифрования построен новый протокол SHTTP, который реализован в серверах Netsite (последние версии), Apachie и в новых серверах CERN и NCSA. Однако реально широкого применения это программное обеспечение еще не нашло и находится в стадии развития, а потому содержит достаточно большое количество ошибок.
Завершая обсуждение протокола HTTP и способов его реализации, нужно отметить, что в качестве широко доступного информационного ресурса WWW уже состоялась, следующий шаг - серьезные коммерческие применения. Но для этого необходимо еще внедрить в практику защищенные протоколы обмена, базирующиеся на HTTP. В последнее время появилось много новых программ, реализующих протокол HTTP. Это серверы и клиенты, написанные как для новых компьютерных платформ, так и для возможностей SHTTP. Реальную возможность попробовать свои силы в разработке различных WWW-приложений имеют и отечественные программисты.
5.3. Серверы Intranet
В Intranet можно использовать все возможные сервисы Internet (например, электронную почту, возможности удаленного терминала и т.д.). Но мы остановимся на трех разновидностях серверов, которые наиболее активно используются в настоящее время.
5.3.1. FTP-серверы
FTP-архивы являются одним из основных информационных ресурсов Internet. Фактически, это распределенный депозитарий текстов, программ, фильмов, фотографий, аудио записей и прочей информации, хранящейся в виде файлов на различных компьютерах во всем мире.
5.3.1.1. Типы информационных ресурсов
Информация в FTP-архивах разделена на три категории:
- Защищенная информация, режим доступа к которой определяется ее владельцами и разрешается по специальному соглашению с потребителем. К этому виду ресурсов относятся коммерческие архивы (например, коммерческие версии программ в архивах ftp.microsoft.com или ftp.bsdi.com), закрытые национальные и международные некоммерческие ресурсы (например, работы по международным проектам CES или IAEA), частная некоммерческая информация со специальными режимами доступа (частные благотворительные фонды, например).
- Информационные ресурсы ограниченного использования, к которым относятся, например, программы класса shareware (Trumpet Winsock, Atis Mail, Netscape, и т.п.). В данный класс могут входить ресурсы ограниченного времени использования (текущая версия Netscape перестанет работать в июне если только кто-то не сломает защиту) или ограниченного времени действия, т.е. пользователь может использовать текущую версию на свой страх и риск, но никто не будет оказывать ему поддержку.
- Свободно распространяемые информационные ресурсы или freeware, если речь идет о программном обеспечении. К этим ресурсам относится все, что можно свободно получить по сети без специальной регистрации. Это может быть документация, программы или что-либо еще. Наиболее известными свободно распространяемыми программами являются программы проекта GNU Free Software Foundation. Следует отметить, что свободно распространяемое программное обеспечение не имеет сертификата качества, но как правило, его разработчики открыты для обмена опытом.
Из выше перечисленных ресурсов наиболее интересными, по понятным причинам, являются две последних категории, которые, как правило, оформлены в виде FTP-архивов.
Технология FTP была разработана в рамках проекта ARPA и предназначена для обмена большими объемами информации между машинами с различной архитектурой. Главным в проекте было обеспечение надежной передачи и поэтому с современной точки зрения FTP кажется перегруженным излишними редко используемыми возможностями. Стержень технологии составляет FTP-протокол.
5.3.1.2. Протокол FTP
FTP (File Transfer Protocol или "Протокол Передачи Файлов") - один из старейших протоколов в Internet и входит в его стандарты. Обмен данными в FTP проходит по TCP-каналу. Построен обмен по технологии "клиент-сервер". На рисунке 5.3 изображена модель протокола.
В FTP соединение инициируется интерпретатором протокола пользователя. Управление обменом осуществляется по каналу управления в стандарте протокола TELNET. Команды FTP генерируются интерпретатором протокола пользователя и передаются на сервер. Ответы сервера отправляются пользователю также по каналу управления. В общем случае пользователь имеет возможность установить контакт с интерпретатором протокола сервера и отличными от интерпретатора пользователя средствами.
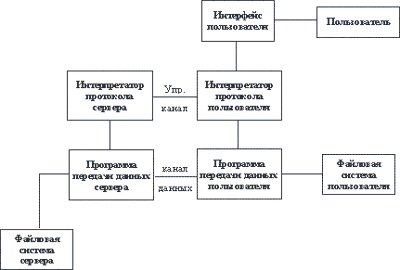
Рис. 5.3. Диаграмма протокола FTP
Команды FTP определяют параметры канала передачи данных и самого процесса передачи. Они также определяют и характер работы с удаленной и локальной файловыми системами.
Сессия управления инициализирует канал передачи данных. При организации канала передачи данных последовательность действий другая, отличная от организации канала управления. В этом случае сервер инициирует обмен данными в соответствии с согласованными в сессии управления параметрами.
Канал данных устанавливается для того же host'а, что и канал управления, через который ведется настройка канала данных. Канал данных может быть использован как для приема, так и для передачи данных.
Возможна ситуация, когда данные могут передаваться на третью машину. В этом случае пользователь организует канал управления с двумя серверами и организует прямой канал данных между ними. Команды управления идут через пользователя, а данные напрямую между серверами (рисунок 5.4).
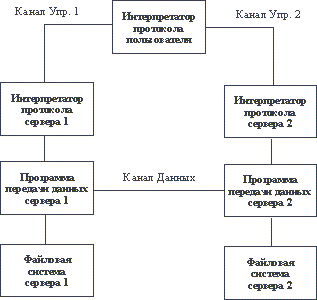
Рис. 5.4. Соединение с двумя разными серверами и передача данных между ними
Режимы обмена данными
В протоколе большое внимание уделяется различным способам обмена данными между машинами различных архитектур. Действительно, чего только нет в Internet, от персоналок и Mac'ов до суперкомпьютеров. Все они имеют различную длину слова и многие различный порядок битов в слове. Кроме этого, различные файловые системы работают с разной организацией данных, которая выражается в понятии метода доступа.
В общем случае, с точки зрения FTP, обмен может быть поточный или блоковый, с кодировкой в промежуточные форматы или без нее, текстовый или двоичный. При текстовом обмене все данные преобразуются в ASCII и в этом виде передаются по сети. Исключение составляют только данные IBM mainframe, которые по умолчанию передаются в EBCDIC, если обе взаимодействующие машины IBM. Двоичные данные передаются последовательностью битов или подвергаются определенным в процессе сеанса управления преобразованиям. Обычно, при поточной передаче данных за одну сессию передается один файл данных, при блоковом способе за одну сессию можно передать несколько файлов.
Описав в общих чертах протокол обмена, можно перейти к описанию средств обмена по протоколу FTP. Практически для любой платформы и операционной cреды существуют как серверы, так и клиенты. Ниже описываются стандартные сервер и клиент Unix-подобных систем.
5.3.1.3. Сервер протокола - программа ftpd
Команда ftpd предназначена для обслуживания запросов на обмен информацией по протоколу FTP. Сервер обычно стартует в момент загрузки компьютера. Синтаксис запуска сервера следующий:
ftpd [-d] [-1] [-t timeout] d - опция отладки; 1 - опция автоматической идентификации пользователя; t - время пассивного ожидания команд пользователя.
Каждый сервер имеет свое описание команд, которое можно получить по команде help. Автоматическая идентификация пользователей осуществляется при помощи файла /etc/passwd. Пароль пользователя не должен быть пустым.
Существует специальный файл, в котором содержатся запрещенные пользователи, т.е. те, кому обслуживание по протоколу FTP запрещено. Возможен вход в архив по идентификатору пользователя anonymous или ftp. В этом случае сервер принимает меры по ограничению доступа к ресурсам компьютера для данного пользователя. Обычно для таких пользователей создается специальная директория ftp, в которой размещают каталоги bin, etc и pub. В каталоге bin размещаются команды, разрешенные для использования, а в каталоге pub собственно сами файлы. Каталог etc закрыт для просмотра пользователем и в нем размещены файлы идентификации пользователей.
В ряде случаев в директории pub создают каталог incoming. Этот каталог предназначен для того, чтобы пользователь мог записать в этот каталог свои программы или любые другие файлы. Однако, это довольно небезобидная, с точки зрения безопасности, операция.
В директорию bin обычно записывается только одна команда ls. Данная команда позволяет выполнять просмотр текущей директории. Согласно правилам, анонимный пользователь должен иметь возможность выполнять только те команды, которые размещены в этой директории. Однако, в большинстве систем анонимный пользователь выполняет гораздо больший набор команд, при этом эти команды берутся из стандартных директорий системы. Способность этого пользователя создавать директории, удалять файлы и т.п. будет зависеть от прав, которые установлены администратором для той ветви, файловой системы, в которой располагается файловый архив FTP. Так, например, в Windows NT можно так назначить права, что при входе пользователя с консоли он сможет получить доступ к системе, а при доступе к своему архиву FTP пользователь таких прав не получает, точнее пользователь нормально идентифицируется и проходит аутентификацию, но после этого получает сообщение, что не обладает нужными правами для доступа к своей домашней директории. При этом данная проблема в рамках программ настроек Internet Information Services не решается. Приходится использовать стандартные средства Windows, определяющие эти права.
Другую опасность для системы представляют ссылки. Многие администраторы полагают, что взлом системы - это ситуация, когда злоумышленник проник в систему, однако это не так. Например, в классификации CERT тяжелый взлом - это, в том числе и выявление структуры файловой системы. В этом случае атакующий получает информацию о предмете атаки и может сосредоточить свои усилия на каком-то отдельном фрагменте системы.
Если в директорию etc не скопировать файл passwd, то никто не сможет получить доступ к данным FTP-архива. Однако, часто копируют настоящий файл паролей. Этого делать не следует. Во всяком случае следует убедиться в том, что поле паролей в записях описания пользователей должно быть пустым. Клиент FTP только проверяет наличие пользователя и наличие у него пароля, а идентификация проводится стандартным для системы способом через программу login.
Ниже приведена структура корня FTP-архива (рисунок 5.5).
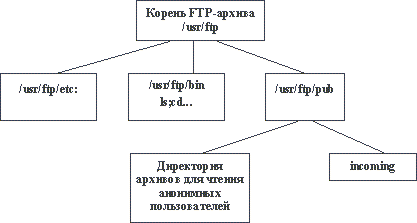
Рис. 5.5. Структура ftp-архива
5.3.2. WWW-серверы
Как уже было сказано выше, сервер World Wide Web - это программа, обслуживающая запросы клиентов по протоколу HTTP. Иногда серверами WWW называют и другие программы, например, поисковые машины Wide Area Information Server. Но это слишком вольное толкование понятия WWW-сервера. Главной задачей сервера "паутины" является обеспечение доступа пользователей к базе данных HTML-документов. Однако, в настоящее время функциональные возможности серверов значительно расширились и вышли за пределы простой отсылки документов на запросы клиентов. Наиболее типичными для современных серверов являются следующие функции:
- ведение иерархической базы данных документов,
- контроль за доступом к информации со стороны программ-клиентов,
- предварительная обработка данных перед ответом на запрос,
- взаимодействие с внешними программами через Common Gateway Interface,
- реализация взаимодействия с клиентами и другими серверами в режиме посредника,
- реализация встроенных или взаимодействие с внешними поисковыми машинами.
Кроме того, такие серверы как NetSite (Netscape Communication) и Apachie реализуют шифрованные протоколы HTTP для обмена информацией с клиентами. Рассмотрение перечисленных свойств и функций WWW-серверов полезно провести на примерах, основанных на практике эксплуатации серверов NCSA httpd, CERN httpd, Winhttpd и WN, Apachie.
5.3.2.1. Структура базы данных сервера WWW
Итак первой основной задачей для любого сервера является ведение его базы данных. База данных сервера - это часть файловой системы, отведенная для размещения файлов HTML-документов. Большинство современных файловых систем - это иерархические деревья, следовательно, и база данных HTTP-сервера также является таким деревом. Для любой базы данных необходимо ввести понятие единицы хранения - минимальный объект, к которому можно обратиться извне или получить в качестве ответа на запрос. Стандартным объектом хранения в базе данных HTTP-сервера является HTML-документ, который является обычном текстовым файлом. Кроме такого стандартного объекта многие серверы поддерживают различные комбинированные объекты хранения, создаваемые в ряде случаев из нескольких файлов или генерируемые программами "на лету".
Если обратиться к терминологии, которая принята в системах World Wide Web, то можно выделить следующие основные объекты, с которыми оперирует сервер и программа-клиент:
Страница базы данных World Wide Web - это законченный информационный объект, который отображается пользователю при обращении к информационному ресурсу World Wide Web по универсальному идентификатору этого ресурса (URI, URL).
База данных World Wide Web или Website - набор страниц базы данных World Wide Web. При более подробном рассмотрении Website - это вся совокупность данных и программного обеспечения, обеспечивающая отображение страниц информационной базы данных World Wide Web.
Если страница Website представляет из себя обычный файл в стандарте HTML, то тогда говорят об элементарном или стандартном элементе хранения. В этом случае URL указывает непосредственно на этот файл и сервер просто отправляет его в ответ на запрос пользователя.
Многие страницы содержат внутри себя контейнеры-формы, которые служат для передачи информации от программы клиента программе-серверу. В рамках данного рассмотрения эти страницы выделены в особую группу страниц World Wide Web.
Страницей-формой будем называть в данном контексте файл в формате HTML, который содержит в себе HTML-форму.
После обращения к странице-форме, как правило, следует вызов либо API-модуля, встроенного в сервер, либо CGI-программы. В свою очередь такое действие вызывает генерацию этим модулем или программой виртуальной страницы.
Виртуальной страницей Website будем называть страницу, которая в виде файла в файловой системе сервера не существует. Данная страница появляется только в момент обращения клиента к серверу.
Один из способов генерации виртуальной страницы - это генерация при помощи API-модуля или CGI-программы. При этом весь текст страницы может порождаться программой, либо для генерации могут использоваться файлы-заготовки. Генерируют не только текстовые файлы, но и графику. Одним из наиболее популярных способов генерации документов является обращение к стекам гипертекстовых ссылок и системам управления универсальными базами данных (СУБД).
Второй способ генерации виртуальной страницы - это генерация такой страницы сервером. В данном случае в тело документа и файлы описания иерархии документов сервера включаются команды преобразования документов. Сервер может, в общем случае, производить условную генерацию документов на основе информации, полученной от программы-клиента.
Другим типом объекта, который хранится в Website, являются страницы в формате Virtual Reality Modeling Language(VRML).VRML-страница - это такой же объект, как и обычные страницы Website, только написанная на другом языке. К VRML-страницам можно применять те же механизмы генерации, что и к страницам HTML.
Java-applet - это мобильный код, сгенерированный компилятором applet'ов. Applet'ы составляют в базе данных Website отдельную директорию в файловой системе сервера. В страницы HTML встраиваются специальные контейнеры applet'ов, которые позволяют программе-клиенту распознавать наличие applet'а и подгружать его в качестве части страницы.
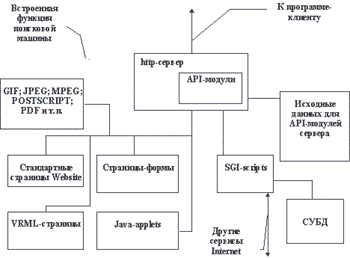
Рис. 5.6. Структура базы данных и программного обеспечения Website
Как видно из рисунка 5.6, кроме перечисленных выше компонентов, базу данных Website составляют еще и другие файлы. Главным образом, это файлы графических и мультимедийных форматов. Для просмотра этих файлов программа-клиент должна уметь запускать либо внешнюю программу, либо plug-ins, т.е. программу, которая отображает файл графического или мультимедийного формата внутрь рабочей области программы-клиента.
Совершенно очевидно, что для создания всего этого многообразия файлов и компонентов Website необходимо программное обеспечение, которое не входит в стандартный набор, представленный на рисунке 5.6. Самый минимальный набор инструментов, который необходим для поддержания страниц базы данных можно определить следующим образом:
- Редактор файлов формата HTML.
- Графический редактор, сохраняющий файлы в форматах GIF, в том числе и версии GIF89A, и JPEG.
- Редактор файлов формата MPEG.
- Редактор файлов VRML.
- Редактор аудиофайлов.
- Компилятор байткода Java.
- и др.
Кроме прочего, для того, чтобы тестировать страницы, необходимо иметь версии клиентского программного обеспечения различных производителей и различных версий. Определить какие именно программы и их версии необходимы, можно по файлу статистики сервера.
5.3.3. Поисковые серверы
Такие имена информационных служб как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и ряд других, хорошо известны пользователям Internet. Без пользования услугами этих систем практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Но что они из себя представляют, как устроены, почему результат поиска в терабайтах информации выдается так быстро, как устроено ранжирование документов при выдаче, что из себя представляют информационные массивы этих систем - этим вопросам посвящен этот раздел.
Предварительные замечания
Информационно-поисковые системы появились на свет достаточно давно. Теории и практике построения таких систем посвящено довольно большое количество статей, основная масса которых приходится на конец 70-х - начало 80-х годов. Среди отечественных источников следует выделить научно-технический сборник "Научно-техническая информация. Серия 2. Информационные процессы и системы", который выходит до сих пор. На русском языке издана так же и "библия" по разработке этого рода систем - "Динамические библиотечно-информационные системы" Жерарда Солтона (Gerard Salton), в которой рассмотрены основные принципы построения информационно-поисковых систем и моделирования процессов их функционирования. Таким образом нельзя сказать, что с появлением Internet и бурным вхождением его в практику информационного обеспечения, появилось нечто принципиально новое, чего не было раньше. Если быть точным, то информационно-поисковые системы в Internet - это признание того, что ни иерархическая модель Gopher, ни гипертекстовая модель World Wide Web не решают проблему поиска информации в больших объемах разнородных документов. И на сегодняшний день нет другого способа быстрого поиска данных, кроме поиска по ключевым словам.
При использовании иерархической модели Gopher приходится довольно долго бродить по дереву каталогов, пока не встретишь нужную информацию. Эти каталоги должны кем-то поддерживаться и при этом их тематическое разбиение должно совпадать с информационными потребностями пользователя. Учитывая анархичность Internet и огромное количество всевозможных интересов у пользователей Сети, понятно, что кому-то может и не повезти, и в сети не будет каталога отражающего конкретную предметную область. Именно по этой причине для множества серверов Gopher, которое называется GopherSpace была разработана информационно-поисковая программа Veronica (Very Easy Rodent-Oriented Net-wide Index of Computerized Archives).
Аналогичное развитие событий мы видим и в World Wide Web. Собственно еще в 1988 году в специальном выпуске "Communication of the acm" среди прочих проблем разработки гипертекстовых систем и их использования Франк Халаз назвал проблему организации поиска информации в больших гипертекстовых сетях в качестве первоочередной задачи для следующего поколения систем этого типа. До сих пор многие идеи, высказанные в этом разделе, не нашли еще своей реализации. Естественно, что система, предложенная Бернерсом-Ли и получившая такое широкое распространение в Internet, должна была столкнуться с теми же проблемами, что и ее локальные предшественники. Реальное подтверждение этому было продемонстрировано на второй конференции по World Wide Web осенью 1994 года, на которой были представлены доклады о разработке информационно-поисковых систем для Web, а система World Wide Web Worm, разработанная Оливером МакБрайном из Университета Колорадо, получила приз как лучшее навигационное средство. Следует также отметить, что все-таки долгая жизнь суждена не хорошим программам талантливых одиночек, а средствам, которые являются результатом долгосрочного планирования последовательного движения к поставленной цели научных и производственных коллективов. Рано или поздно этап исследований заканчивается и наступает этап эксплуатации систем, а это уже совсем другой род деятельности. Именно такая судьба ожидала два других проекта, представленных на той же конференции: Lycos, поддерживаемый компанией Microsoft, и WebCrawler, ставший собственностью America On-line.
Разработка новых информационных систем для Web не завершена. Причем как на стадии написания коммерческих систем, так и на стадии исследований. За прошедшие два года снят только верхний слой возможных решений. Однако, многие проблемы, которые ставит перед разработчиками ИПС Internet не решены до сих пор. Именно этим обстоятельством и вызвано появление проектов типа AltaVista компании Digital, главной целью которого является разработка программных средств информационного поиска для Web и подбор архитектуры для информационного сервера Web.
5.3.3.1. Архитектура современных информационно-поисковых систем World Wide Web
Прежде чем описать проблемы построения информационно-поисковых систем Web и пути их решения, рассмотрим типовую схему такой системы (рисунок 5.7). В различных публикациях, посвященных конкретным системам, приводятся схемы, которые отличаются друг от друга только применением конкретных программных решений, но не принципом организации различных компонентов системы.
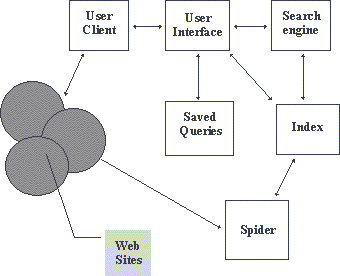
Рис. 5.7. Структура ИПС для Internet(Budi Yuwono, Dik L.Lee. Search and Ranking Algorims for Locating Resources on the World Wide Web)
На этой схеме обозначены:
userclient - это программа просмотра конкретного информационного ресурса. В настоящее время наиболее популярны мультипротокольные программы типа Netscape Navigator. Такая программа обеспечивает просмотр документов World Wide Web, Gopher, Wais, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
userinterface - интерфейс пользователя - это не просто программа просмотра. В случае информационно-поисковой системы под этим словосочетанием понимают и способ общения пользователя с поисковым аппаратом системы, т.е. с системой формирования запросов и просмотров результатов поиска. Просмотр результатов поиска и информационных ресурсов сети - это совершенно разные вещи, на которых остановимся чуть позже.
searchengine - поисковая машина служит для трансляции запроса пользователя, который подготавливается на информационно-поисковом языке (ИПЯ), в формальный запрос системы, поиска ссылок на информационные ресурсы Сети и выдачи результатов этого поиска пользователю.
indexdatabase - индекс - это основной массив данных информационно-поисковой системы. Он служит для поиска адреса информационного ресурса. Архитектура индекса устроена таким образом, чтобы поиск происходил максимально быстро и при этом можно было бы оценить ценность каждого из найденных информационных ресурсов сети.
queries - запросы пользователя сохраняются в его личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно хранить запросы, на которые система дает хорошие ответы.
indexrobot - робот-индексировщик служит для сканирования Internet и поддержки базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.
wwwsites - это весь Internet. А если говорить более точно, то это те информационные ресурсы, просмотр которых обеспечивается программами просмотра.
Рассмотрим теперь назначение и принцип построения каждой из этих компонент более подробно и определим, в чем отличие данной системы от традиционной информационно-поисковой системы локального типа.
5.3.3.2. Информационные ресурсы и их представление в информационно-поисковой системе
Как видно из схемы (рисунок 5.7) документальным массивом ИПС Internet является все множество документов шести основных типов: WWW-страницы, Gopher-файлы, документы Wais, записи архивов FTP, новости Usenet, статьи почтовых списков рассылки. Все это довольно разнородная информация, которая представлена в виде различных, никак несогласованных друг с другом форматов данных. Здесь есть и текстовая информация, и графическая информация, и аудио информация и вообще все, что есть в указанных выше хранилищах. Естественно встает вопрос, как информационно-поисковая система должна со всем этим работать. В традиционных системах есть понятие поискового образа документа - ПОД'а. ПОД (Поисковый Образ Документа)- это нечто, что заменяет собой документ и используется при поиске вместо реального документа. Поисковый образ является результатом применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель, в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Если быть более точным, то документу приписывается вектор, размерность которого равна числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия термина в ПОД'е документа или его отсутствия. В более сложных моделях термины взвешиваются, т.е. элемент вектора равен не 1 или 0, а некоторому числу, которое отражает соответствие данного термина документу. Именно последняя модель наиболее популярна в информационно-поисковых системах Internet. Вообще говоря, существуют и другие модели описания документов: вероятностная модель информационных потоков и поиска, и модель поиска в нечетких множествах. Анализ преимуществ и недостатков применения этих моделей при реализации информационно-поисковых систем в Internet - это тема специального исследования. Здесь имеет смысл обратить внимание читателя только на то, что пока именно линейная модель применяется в системах Lycos, WebCrawler, AltaVista, OpenText, AliWeb и ряде других. Исследования по применению других моделей также ведутся, например, в рамках проекта AltaVista или научными группами. Таким образом, первая задача, которою должна решить информационно-поисковая система - это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием. Часто, однако, индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов, в которых он встречается. Такая процедура является только частным случаем, а точнее техническим аспектом создания поискового аппарата информационно-поисковой системы.
Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы. Таким образом, все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако, на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
Теперь представим себе возможность такой процедуры в анархичном Internet, где ресурсы появляются и исчезают ежедневно. При создании программы Veronica для GopherSpace предполагалось, что все серверы должны быть зарегистрированы и таким образом велся учет наличия или отсутствия ресурса. Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных ПОД'ов документов Gopher. В World Wide Web ничего подобного нет. Для решения этой задачи используются программы сканирования сети или роботы-индексировщики. Разработка роботов - это довольно нетривиальная задача, т.к. существует опасность зацикливания робота или попадания на виртуальные страницы. Все системы имеют своего робота. Робот просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главный вопрос заключается в том, какие термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. В настоящее время различные роботы используют для индексирования следующие источники для пополнения своих виртуальных словарей: гипертекстовые ссылки, заголовки (title), заглавия (H1, H2 и т.п.), аннотации, списки ключевых слов и полные тексты документов, сообщения администраторов о своих Web-страницах. Для индексирования telnet, gopher, ftp, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков - поля Subject и Keywords. Наибольший простор для построения ПОД'ов дают HTML-документы. Однако не следует думать, что все термины из перечисленных выше элементов документов попадают в их поисковые образы. Очень активно используются списки запрещенных слов (stop-words), которые не могут быть использованы для индексирования, общих слов (предлоги, союзы и т.п.), а также часто производится нормализация лексики. Таким образом, даже то, что в OpenText, например, называется полнотекстовым индексированием реально является выбором слов из текста документа и сравнением с целым набором различных словарей, после которого термин попадает в поисковый образ документа, а потом и в индекс системы. Для того, чтобы не раздувать словарей и индексов, а индекс Lycos, например, равен 4TB, применяется такое понятие как "вес" термина. В документе обычно индексируется 40 - 100 наиболее "тяжелых" терминов.
После того, как ресурсы заиндексированы, т.е. система составила массив поисковых образов документов, начинается построение поискового аппарата системы. Совершенно очевидно, что лобовой просмотр файла или файлов ПОД'ов займет много времени, что абсолютно не приемлемо для интерактивной системы, которой является Web. Для того, чтобы можно было быстро находить информацию в базе данных ПОД'ов строится индекс. Индекс в большинстве систем - система связанных между собой файлов, которая нацелена на быстрый поиск данных по запросу пользователя. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов. К этим факторам можно отнести и размер массива поисковых образов, и информационно-поисковый язык системы, и размещения различных компонентов системы и т.п. Рассмотрим структуру индекса на примере системы. Этот проект выбран потому, что он позволяет реализовывать не только примитивный булевый поиск, но и контекстный поиск, взвешенный поиск и ряд других возможностей, которые отсутствуют во многих поисковых системах, например, Yahoo.
Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (page-ID), таблицы ключевых слов (Keyword-ID), таблицы модификации страниц, таблицы заголовков, таблицы гипертекстовых связей, инвертированного списка (IL) и прямого списка (FL).
Page-ID отображает идентификаторы станиц в URL этих страниц, Keyword-ID отображает каждое ключевое слово в уникальный идентификатор этого слова, таблица заголовков отображает идентификатор страницы в заголовок страницы, таблица гипертекстовых ссылок отображает идентификатор страниц в гипертекстовую ссылку на эту страницу. Инвертированный список ставит в соответствие каждому ключевому слову список пар (номер документа, идентификатор страницы, позиция слова в странице), а прямой список - это массив поисковых образов страниц. Все эти файлы так или иначе используются при поиске, но главным среди них, безусловно, является файл инвертированного списка. Результат поиска в этом файле - это объединение и/или пересечение списков идентификаторов страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками, возвращается пользователю в его программу просмотра Web. Для того, чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, с этих пар начинающихся, а также применяется механизм прямого доступа к данным - хеширование.
Для обновления индекса применяется комбинация двух подходов. Первый можно назвать коррекцией индекса "на ходу". Для этого служит таблица модификации страниц. Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса, т.е. его перезагрузка.
Успех информационно-поисковой системы с точки зрения скорости поиска, определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является "секретом фирмы" и гордостью компании.
5.4. Язык программирования Java
Весь 1996 год прошел под знаком внедрения в World Wide Web технологии Java. Однако реальные проекты, выполненные в этой технологии появились только к концу года. При обсуждении Java-технологии, как правило речь идет о ее безопасности, мобильности, и, как следствие, уменьшении размеров программного кода, выполняемого на машинах-клиентах.
Не смотря на то, что этот раздел называется "Язык программирования Java", в нем приходится говорить о гораздо более обширном понятии, которое принято обозначать термином "Java-технология". Если обратиться к публикациям о новых концепциях разработки программного обеспечения, то Java-язык и Java-технологии ценятся не только и не столько за то, что они дали возможность "оживить" Web, как часто можно прочитать в рекламных проспектах, а за то, что давняя идея мобильного программирования для различных аппаратных платформ наконец-то стала реальностью.
При этом все прекрасно понимают, что сама по себе Java-технология еще чрезвычайно сыра и использовать ее в нынешнем виде для серьезных проектов могут только самые отчаянные смельчаки, тем не менее многие из свойств Java чрезвычайно интересны и полезны.
5.4.1. Мобильность Java
Первым из свойств языка Java разберем мобильность. Суть мобильности заключается в том, что написанный на Java код может исполняться на любой компьютерной платформе. Под платформой в данном случае подразумевается программно-аппаратный комплекс, а проще собственно компьютер и операционная система, которая на нем работает. Однако, мобильность Java следует отличать от простого портирования кода с одной платформы на другую. При портировании передается исходный текст, который после этого компилируется и только затем выполняется. В Java передаются так называемые байт-коды. Байт-код - это универсальный формат программы, единый для всех аппаратных платформ. Байт-код един и для рабочих станций, и для больших универсальных ЭВМ, и для персональных компьютеров. Собственно, большинство из тех, кто работал с СУБД на персональных компьютерах с разновидностями байт-кодов наверняка встречался. Это, например, коды, которые выполняет FoxBASE. Конечно коды FoxBASE и Java - это абсолютно разные коды, но идея в общем - та же.
Надо сказать, что коды Java - это не единственные мобильные коды, которые предполагалось использовать в Internet, но благодаря большим усилиям со стороны Sun Microsystems именно они стали наиболее известными и, на сегодняшний день используемыми, хотя до сих пор подходят на эту роль слабо.
Сравнение с FoxBase было не случайным. Дело в том, что байт-код Java исполняется интерпретатором, а не является откомпилированной на данной платформе программой. Многие преимущества и недостатки Java проистекают именно из-за этого. Первый и очевидный недостаток - это скорость выполнения кода. Совершенно очевидно, что интерпретатор работает гораздо медленнее откомпилированного кода. И здесь не помогут никакие Java-процессоры. Вся элементная база все равно остается двоичной, а это значит, что программы оптимизированные для работы с этим типом вычислений будут работать все равно быстрее, чем какие-либо другие коды. Здесь можно говорить, только о сравнении Java-процессоров с универсальными процессорами при выполнении Java-кода.
Собственно, и другие свойства технологии (объектная ориентируемость, использование многопоточности, отсутствие адресной арифметики и т.п.) в большинстве случаев при стандартной комплектации оборудования, только тормозят выполнение программы.
Второй недостаток не столь очевиден, да и собственно для большинства современных разработчиков таковым не является - объектный подход к программированию. Что собственно имеется в виду, когда об объектном программировании говорится как о недостатке в данном контексте. Главным в Java-технологии являются небольшие программки-апплеты, которые передаются по сети. Размер такого апплета очень мал (до сотни строк текста). При этом разработчик должен весь вывод собрать в одну процедуру, перехват особых ситуаций в другую, порождение потоков в третью, и т. д. При этом некоторые из этих процедур будут вообще состоять из четырех - пяти строк. Это конечно дисциплинирует и ведет к построению стройных кодов, но при этом прокрутка текста на экране превращается в программу с порождением нового потока, что вместо сокращения издержек на ее выполнение приводит только к их увеличению. Одним словом, "Hello Java" также нудно писать, как и "Hello Windows".
Однако, мобильность Java имеет еще одно измерение. Апплеты передаются по сети в тот момент, когда их нужно выполнять. При этом они могут загружаться из разных мест и после загрузки взаимодействовать друг с другом. Девиз Sun "Сеть - это компьютер" здесь работает на все сто процентов. Действительно, если всю совокупность апплетов рассматривать как одну программу, состоящую из множества подгружаемых по мере необходимости модулей, то весь Internet становится одним большим компьютером, а точнее хранилищем данных и программ, т.к. все-таки программа выполняется на локальном процессоре. Хотя, и последнее не совсем точно. Java-апплеты могут обмениваться данными между собой по сети, что заставляет говорить о распределенных вычислениях, и в этом случае программа будет исполняться на многих компьютерах в сети. До Java можно было говорить о распределенных вычислениях только после трансляции кодов для каждой из машин и отладки всего комплекса в целом. Теперь отладиться можно и на локальном компьютере, а реально считать на разных.
Основной протокол обмена апплетами - HTTP. Это значит, что они передаются по сети точно также, как и другие ресурсы Website, и приобретают свое особое значение только в момент получения их браузером. Учитывая неэффективность реализации HTTP поверх TCP, можно сказать, что и обмен апплетами тоже неэффективен, если для каждого обмена устанавливается свое TCP-соединение. Пока сравнение скорости выполнения Java-апплетов и скриптов JavaScript не в пользу первых, т.е. интерпретация скриптов в Netscape Navigator реализована эффективнее. В любом случае загрузка страниц с Java происходит гораздо медленнее, чем без Java.
Часто можно слышать, что использование Java должно снизить затраты на обмен информацией по сети. Аргумент здесь следующий: для отображения информации в виде графиков и гистограмм, и даже трехмерных объектов не надо передавать по сети изображения этих объектов, а можно передать, только числовые характеристики. Это приводит к существенному сокращению трафика, и сокращению числа ошибок при передаче. Это справедливо в том случае, если апплеты Java не перегружаются часто. Пользователь загрузил группу страниц и все апплеты на них и только стартует или останавливает выполнение программ. В случае специализированных корпоративных вычислений может быть это и так, но если брать обычного пользователя, то он практически всегда, переходя на новую страницу, загружает новые апплеты, а вот это уже не сокращает трафик, а только увеличивает.
Мобильность имеет и свою обратную сторону. Некоторые авторы прежде, чем пустить пользователя на свои страницы с Java предупреждают: Are your going to be infected? Суть предупреждения в том, что, фактически, пользователь разрешает выполняться на своем компьютере программе, о свойствах которой он ничего не знает. При этом ссылки на безопасность Java не вполне корректны. Программа может вообще никак себя внешне не проявлять, но при этом выполнять массу нежелательных, с точки зрения пользователей, действий. Например, анализировать кэш браузера, идентифицировать компьютер пользователя и многое другое.
5.4.2. Безопасность, Java и Intranet
Раз уж затронули проблему безопасности, то следует назвать безопасность программирования на Java другим важным свойством этой технологии. Речь конечно идет не о личной безопасности, а о том, что программы, написанные на Java, являются безопасными. Дело в том, что многие источники проблем безопасности системы, связанные с программированием, как то: переполнение строковых массивов, адресная арифметика, отведение и освобождение памяти и т.п. в Java контролируются системой. Нельзя использовать метод (процедуру), если параметры ее вызова не совпадают с объявленными при ее описании. При этом длина передаваемых строк будет проверяться либо при компиляции, если речь идет о константах, либо на шаге исполнения.
При этом в угоду безопасности была даже урезана сетевая компонента системы. При программировании на Java можно получать данные и апплеты только с той машины, с которой был загружен выполняемый applet. Это серьезное препятствие на пути построения действительно распределенных вычислительных систем, тем более, что это ограничение обходится путем использования proxy-серверов (серверов-посредников), которые через себя способны транслировать запросы к информационным ресурсам, поддерживаемым другими серверами.
Данное ограничение обнажило действительную сферу применения Java - системы Intranet. Термин "Intranet" появился в начале 1995 года. Его появление было вызвано необходимостью обозначить сферу применения новой технологии компании Sun Microsystems - Java. Однако, часто он толкуется гораздо шире, чем область применения Java-приложений или Java-апплетов. Очень быстро об Intranet стали говорить как о применении информационных технологий Internet для создания внутрикорпоративных систем. Но это также не дает ответа на вопрос, вынесенный в заглавие раздела. Не претендуя на истину в последней инстанции, попробуем понять, что имеется в виду когда говорят об Intranet.
Введя в употребление термин "Intranet", Sun Microsystems стремилась придать своей новой технологии Java налет революционности. В течении 1996 года Java не сходила со страниц компьютерных изданий. Но постепенно стало расти понимание того, что Intranet - это не только Java, а гораздо более емкое понятие.
В то же самое время Sun заговорила о своей системе защиты от несанкционированного доступа Sunscreen как о компоненте Intranet-технологии. Sunscreen к технологии Java никакого отношения не имеет. Общим является только то, что Java - это, в данном контексте, среда безопасного программирования, и Sunscreen средство обеспечения безопасности.
Конечно, Sunscreen не единственное средство, назначение которого - защита локальной сети от непрошенных гостей. В настоящее время, согласно данным, опубликованным Эдвином Маером (Edwin Mier) в Network World, существует около двух десятков межсетевых экранов, которые используются для защиты локальных сетей. Из них наиболее удачными являются (по данным того же автора):
- BorderWare FireWall Server - наиболее удачное дешевое решение для сетей на персональных компьютерах с процессором Intel;
- Black Hole - наиболее удачное решение для небольших сетей, состоящих из разношерстного набора платформ. Данный межсетевой фильтр может быть установлен как на персоналке, так и на рабочей станции;
- Gauntlet Internet Firewall - одно из наиболее удачных решений, которое может применяться в сетях любого типа.
К слову сказать, последние две системы сертифицированы Гостехкомиссией России и могут на законном основании применяться в наших условиях.
Но межсетевые фильтры используются не только для защиты локальной сети, но и для организации виртуальных локальных сетей поверх публичных сетей. Обычно такое решение называют Virtual Private Network.
Очень похожее решение предлагает и компания CISCO, только называется оно VirtualLocal Area Network (VLAN). Используя маршрутизаторы и/или коммутаторы этой компании можно в рамках одной организации построить на базе ее опорной сети передачи данных несколько виртуальных локальных сетей подразделений. При этом каждую из этих сетей можно защитить.
Однако, защита сетей и организация виртуальных сетей - это тоже не весь Intranet. Производители Систем Управления Базами Данных также заявили, что они производят смычку своих технологий с Intranet-технологией. Informix заявил о добавлении средств Web-bludes к своим продуктам, а Oracle просто выпустил свой собственный Web-сервер. Такая активность производителей СУБД понятна. Раз уж речь идет о корпоративной информационной системе, то такой системы не бывает без баз данных.
И при упоминании Java, и при разговоре о СУБД постоянно появляется слово "Web". Действительно, в рамках технологии Intranet все технологические решения так или иначе вращаются либо вокруг сервера протокола HTTP (HyperText Transfer Protocol), либо вокруг программы-браузера документов World Wide Web. Таким образом, технология World Wide Web занимает центральное место в Inranet.
Однако, так ли уж устойчива эта конструкция? В рамках небольших компаний у Intranet-решений, выполненных с использованием Web-технологии, есть серьезные конкуренты в лице семейства продуктов Microsoft и Lotus. Очень часто приходится слышать вопрос: "Чем же все-таки Intranet лучше существующих корпоративных информационных систем?". Ответ на этот вопрос не так уж и очевиден.
На поверхности лежит только одно преимущество - единый интерфейс ко всем информационным ресурсам. Собственно, когда Тим Бернерс-Ли (Tim Berners Lee) предлагал руководству международного центра физики высоких энергий (CERN, Швейцария) свой проект "Гипертекст для CERN", который превратился в итоге во Всемирную паутину (World Wide Web), главной задачей называлась разработка единого простого интерфейса доступа к разнообразным информационным ресурсам Центра. Фактически, это была первая Intranet-система, только в то время ее так не называли.
Таким образом, Intranet - это решение, ориентированное на пользователей информационных систем, а не на их разработчиков. Количество программ, написанных в этой технологии будет не меньше того, что пишется, скажем, в рамках технологий Microsoft. Есть правда одно смутное предположение, что система, выполненная с опорой на Web, будет лучше переноситься с одной платформы на другую. На мой взгляд это иллюзия. Переносимость здесь такая же, как при переходе с одной реляционной СУБД на другую. Данные можно перенести без особых хлопот, а вот ПО придется переписать или, в лучшем случае, перетранслировать. Не помогут здесь и мобильные коды Java, т.к. обычно переход сопровождается изменением части базового программного обеспечения, что требует перепрограммирования сопряжений частей общей системы.
Можно сказать больше. Там где структура информационных потоков хорошо известна и для этой структуры имеются готовые решения городить огород Intranet вообще не имеет смысла. Особенно это касается сетей никак не связанных с Internet. В этом случае даже достоинство единого интерфейса не выглядит достаточно убедительным. Другое дело, когда пользователь ищет информацию не только в корпоративной базе данных, но во всем множестве ресурсов Internet. В этом случае единый интерфейс сразу показывает все свои достоинства.
Программирование в Intranet и для Intranet - это другая сторона вопроса. Какие собственно задачи должны решаться за счет создания программ Intranet. Как считают в компании Silicon Graphics, Intranet - это клей, связывающий различные технологические решения. Такая точка зрения базируется на том, что практически все элементы Web-технологии позволяют решать достаточно широкий класс задач без использования дополнительного ПО. Так, проблемы разработки интерфейса решаются средствами языка гипертекстовой разметки HTML, передача информации по сети - это забота протокола обмена гипертекстовой информацией HTTP, адрес ресурса в сети определен в спецификации CGI (Common Gateway Interface) и т. п. Разработчик системы будет писать программы, которые будут передавать данные от Web-сервера поисковой машине или серверу СУБД, или какой-либо другой внешней компоненте системы. При этом спецификации обмена данными также стандартизованы. Это заставляет обратить внимание еще на одну группу средств, связанных с проблематикой Intranet - средства разработки. Задача этих средств - облегчить создание программного обеспечения для Intranet.
Именно к этой группе и относятся интегрированные средства разработки Java-приложений. Собственно место Java в Intranet можно схематично показать в виде связей между отдельными компонентами, составляющими Intranet систему (рисунок 5.8).
Рис. 5.8. Место Java среди компонентов Intranet
На рисунке 5.8 не отображены другие источники информации, которые обычно входят в Intranet-системы, например, системы электронной почты, средства коллективной работы и т. п. Но, во-первых, эти системы можно реализовать и в рамках Web-технологии, а во-вторых, для их создания также можно использовать Java. Однако, пока мощь Java в качестве клея еще недостаточна для серьезного обсуждения. Единственный Java-пакет (набор инструментов: описания классов и методов работы с ними), который годится на эту роль - это пакет net, но там, кроме нижнего уровня обмена данными в сетях TCP/IP и обмена по http, пока еще ничего не реализовано. Действительно неплохо выполнен в Java пакет awt, который существенно облегчает разработку интерфейса пользователя, и здесь со всей очевидностью проступает тот факт, что первоначально Java не предназначалась для работы в Internet.
5.4.3. Миграция от средства программирования интерфейсов электронных устройств к языку мобильного программирования
Ломая копья вокруг предназначения и места Java в Internet вообще и в Web в частности, полезно обратить внимание на историю развития технологии. А история Java поучительна. Самое интересное ее изложение приведено в эпилоге книги Патрика Нотона "Java. Справочное руководство", одного из руководителей "Зеленого проекта" Sun, одним из результатов которого собственно и стал Java. С самого начала никакого Java не было. Был Oak (Дуб), да и весь проект никакого отношения к сетям вообще и к Internet в частности не имел. Собственно речь шла о технологии программирования электронных устройств широкого потребления. Одним из ключевых моментов этой технологии являлся язык программирования интерфейсов. Предполагалось, что все бытовые приборы (но не только они) будут иметь панель управления некоторым универсальным устройством, которое и будет уже управлять всем прибором в целом. Для программирования этого устройства, а точнее его панели управления и предназначался Oak. Из затеи создать устройство управления приборами ничего не вышло: уж больно дорогим оно получалось. Применить данную технологию к интерактивному телевидению также не удалось. В итоге, Нотон осознал, что устройство собственно уже есть - это персональный компьютер, который может управлять сразу всеми приборами, а его операционной системой является продукция Microsoft. Однако, в это время уже появились Web и Netscape. Развлечения ради написали свой собственный браузер на Oak, который в последствии получил название HotJava. Браузер умел делать то, что не умели другие программы этого класса - интерпретировать мобильные коды нового языка. При этом в качестве демонстрации возможностей использовался смешной человечек "Дюк", который махал рукой и прыгал по экрану. Вот когда это все заработало, тогда собственно и появилась Java.
Но к этому моменту, реально, до уровня стандартных инструментов были проработаны только элементы интерфейса пользователя, все остальное развивалось в рамках HotJava, а это не самый удачный браузер сети. Поэтому сейчас язык Java добирает то, в чем ему было отказано при рождении - возможность работать с сетью.
Но это только полбеды. Другим серьезным препятствием на пути новой технологии является отсутствие средств разработки прикладных программ для взаимодействия с СУБД. И здесь активность разработчиков этих средств просто поражает. Практически все производители СУБД лицензировали Java и начали разработку продуктов этого класса. К сожалению, пока о каких-либо стандартных решениях здесь говорить не приходится, хотя и есть определенные сдвиги.
5.5. Возможные архитектуры Intranet-приложений
Технологии Internet обеспечивают широкий диапазон возможных архитектур Intranet-систем. Мы очень коротко рассмотрим некоторые варианты.
5.5.1. Решения, ориентированные на клиентскую часть системы
Видимо, это наиболее тривиальная архитектура. Аналогично тому, как это было в файл-серверных решениях, вся прикладная часть системы находится в клиенте, который взаимодействует с разнообразными серверами Internet (электронной почты, ftp и т.д.) и серверами, управляющими файлами и/или базами данных. Клиент должен быть достаточно "толстым", чтобы быть в состоянии уметь работать с разными видами серверов (для каждого из них требуется индивидуальная клиентская часть) и одновременно выполнять прикладную обработку данных. Серверы могут быть разной толщины в зависимости от своей функциональной ориентированности (естественно, что сервер электронной почты нуждается в существенно меньшем числе ресурсов, чем мощный сервер баз данных) (рисунок 5.9).
Рис. 5.9. "Толстый" клиент и серверы разной толщины в Intranet-системах, ориентированных на клиента
5.5.2. Трехзвенные архитектуры (Web-ориентированные)
Ориентация на использование Web-технологии позволяет одновременно добиться двух эффектов. Во-первых, за счет использования CGI или API можно перенести на сторону сервера часть логики приложения. Во-вторых, используя технику шлюзования Web-сервера (опять же применяя CGI-шлюзы или API) можно работать через Web-сервер (в стандартном интерфейсе) с другими серверами. Клиента можно сделать очень "тонким", Web-сервер будет достаточно "толстым", а уж остальные такими, как велит судьба (рисунок 5.10).
Рис. 5.10. "Тонкий" клиент, "толстый" Web-сервер и сравнительно "стройный" дополнительный сервер
5.5.3. Решения, основанные на использовании языка Java
Язык Java можно использовать для программирования Java-апплетов, которые выполняются на стороне клиента, и Java-приложений, выполняемых на стороне сервера. Естественно, клиент, приспособленный к выполнению Java-апплетов, становится несколько толще. Что же касается использования Java-программ на стороне сервера, то большее значение может иметь сравнительная надежность этого языка (в том смысле, что интерпретируемая Java-программа с меньшей вероятностью может нанести вред серверу).
Назад | Содержание | Вперед