Schism: управляемый рабочей нагрузкой подход к репликации и разделению баз данных
Карло Курино, Эван Джонс, Янг Жанг и Сэм Мэдден
Перевод: Сергей Кузнецов
6. Экспериментальная оценка
В этом разделе мы представим результаты экспериментальной оценки Schism.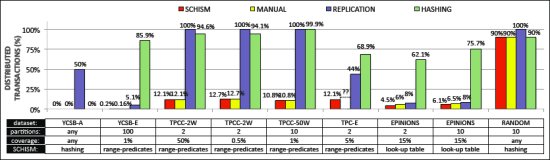
Рис. 4. Эффективность разделения баз данных с использованием Schism.
6.1. Алгоритм разделения
Чтобы оценить качество разделения, обеспечиваемого нашим алгоритмом, мы экспериментировали с различными рабочими нагрузками из искусствено созданных и реальных приложений, описываемых ниже. Мы сравниваем качество разделений по числу получаемых распределенных транзакций. Краткая сводка результатов приведена на рис. 4. Диаграмма в верхней части рисунка позволяет сравнить число распределенных транзакций, получаемое вследствие применения алгоритма разделения графов в системе Schism, с соответствующим показателем 1) наилучшего разделения вручную, какое только нам удалось придумать (manual), 2) репликации всех таблиц replication) и 3) хэш-разделения по первичному ключу или идентификаторам кортежей (hashing). Таблицы в нижней части рисунка показывают число использованных разделов, долю базы данных, которая была отобрана в "образцы", и рекомендацию схемы валидации Schism.Ниже мы описываем каждый из девяти экспериментов. Все эксперименты заключались в сборе больших трасс транзакций, разделении этих трасс на обучающую и тестовую выборки и применении методов взятия образцов и сокращения рабочей нагрузки, описанных в разд. 5. Наборы данных подробно обсуждаются в Приложении D.
- YCSB-A – Cloud Serving Benchmark (YCSB) компании Yahoo! является семейством тестовых наборов, достаточно простых, но отражающих специфику рабочих нагрузок Yahoo! [4]. Рабочая нагрузка A состоит из чтений (50%) и обновлений (50%) одиночных кортежей, случайным образом выбираемых из таблицы со 100000 кортежей с использованием распределения Зипфа. Мы использовали трассы с 10000 запросов. Результаты эксперимента показывают, что Schism может справиться с простыми сценариями, для которых хорошо подходит любое разделение. В частности, мы хотели показать, что на фазе валидации выясняется предпочтительность простого хэш-разделения над более сложными методами разделения с использованием поисковых таблиц или диапазонов значений.
- YCSB-E – рабочая нагрузка из 10000 транзакций, выполняющих либо короткое сканирование с равномерной случайной длиной от 0 до 10 кортежей (95%), либо обновление одного кортежа (5%). Кортежи случайным образом выбирались из таблицы с 100000 кортежей с использованием распределения Зипфа. Из-за сканирований хэш-разделение для этой рабочей нагрузки становится неэффективным. На фазе толкования Schism производит набор предикатов диапазонов значения, которые обеспечиваются настолько же хорошее разделение, что и получаемое вручную (путем тщательного изучения рабочей нагрузки).
-
TPC-C 2W – в этом эксперименте использовалась рабочая нагрузка OLTP с большим числом записей (2 склада, 100000 транзакций в обучающей выборке). Эксперимент показал, что Schism может произвести высококачественное разделение на основе предикатов. Кортежи разделяются на основе идентиифкаторов складов, а таблица
itemреплицируется – это та же стратегия, что была найдена экспертами [21]. - TPC-C 2W со взятием образцов – этот эксперимент также основывался на TPC-C, но он посвящался проверке устойчивости Schism к взятию образцов: разделялся граф, созданный из 3% кортежей, а в обучающей выборке участвовало всего 20000 транзакций. Обучение дерева решений производилось на образце, включавшем по 250 кортежей из каждой таблицы. Тем не менее, система Schism все равно сумела обнаружить "идеальную" схему разделения/репликацию, описанную выше.
-
TPC-C 50W – в этом эксперименте мы увеличили число складов в TPC-C до 50 (размер базы данных составил 25 миллионов кортежей), чтобы показать, как масштабируется Schism при росте размеров базы данных. Мы также увеличили число разделов до 10. С использованием обучающей выборки из 150 тысяч транзакций и образца, включающего 1% кортежей базы данных, мы получили то же разделение по идентификаторам складов и репликацию таблицы
item. В этом эксперименте с 50 складами и 10 разделами разделение Schism и разделение вручную привели к меньшему числу распределенных транзакций, чем в эксперименте с двумя складами и двумя разделами. Это объясняется тем, что некоторые транзакции TPC-C обращаются к нескольким складам (10,7% от общего числа транзакций в рабочей нагрузке). При разделении на два раздела базы данных с двумя складами каждая такая транзакция будет обращаться к нескольким (двум) разделам. Однако в конфигурации с 50 складами и 10 разделами у такой транзакции имеется шанс, что все требуемые ей склады окажутся в одном разделе. Поэтому в такой конфигурации имеется меньшее число многораздельных транзакций. Это была самая крупная рабочая нагрузка из всех, с которыми мы экспериментировали, и общее время работы Schism (построение графа, разделение, толкование и валидация) составило 11 минут 38 секунд. - TPC-E – рабочая нагрузка OLTP с большим числом операций чтения, основанная на популярном тестовом наборе. Эксперимент выполнялся с 1000 клиентов и обучающей выборкой из 100 тысяч транзакций. Проверялась работа системы при наличии более сложной рабочей нагрузки OLTP. Разделение на основе предикатов диапазонов, полученное системой, оказывается лучше хэш-разделения и полной репликации. Из-за сложности тестового набора (33 таблицы, 188 столбцов, 10 видов транзакций) мы не смогли найти высококачественное разделение вручную, с которым можно было бы сравнить другие результаты. Однако полученный результат в 12,1% распределенных транзакций кажется нам вполне приличным.
-
Epinions.com, два раздела – набор данных основан на данных соответствующего Web-сайта социальной сети [15]. Искусственным образом был сгенерирован набор из девяти транзакций, моделирующий наиболее популярные функциональные возможности Web-сайта – подробности см. в Приложении D. Чтобы получить возможность сравнить свои результатами с результатами разделения вручную, мы попросили заняться этим двух студентов магистратуры MIT. Они обнаружили, что наличие в схеме базы данных нескольких связей n-к-n (в которых фиксируются пользовательские рейтинги товаров и доверительные отношения между пользователями), а также существование нескольких паттернов доступа к данным в транзакциях делают эту задачу достаточно сложной. После нескольких часов анализа базы данных и рабочей нагрузки они нашли смешанную стратегию разделения и репликации, приводящую к 6% распределенных транзакций.
При наличии той же информации система Schism получила схему разделения на основе поисковой таблицы, обеспечивающую всего 4,5% распределенных транзакций. Это оказалось возможно, потому что система смогла обследовать социальный граф на уровне кортежей и обнаружила кластеры пользователей и товаров, к которым часто происходят совместные обращения, а обращения к кортежам за пределами этих кластеров редки. Поскольку в этой рабочей нагрузке в основном содержатся только читающие транзакции, кортежи, не присутствующие в исходной поисковой таблице (т.е. не затронутые транзакциями из обучающей выборки), реплицировались во всех разделах. Хэш-разделение и разделение по диапазонам значений привели к получению значительно худших результатов и не были выбраны Schism на фазе окончательной валидации. - Epinions.com, десять разделов – тот же набор данных, что и в предыдущем эксперименте, но число разделов увеличено до 10. Результаты Schism (6% распределенных транзакций) лучше, чем у хэш-разделения (75,7%), у полной репликации (8%) и у разделения вручную (6,5%).
- Random – в этом эксперименте, как и в первом, проверялась способность системы к выбору простой стратегии в ситуации, когда более сложные решения не обеспечивают лучшего разделения. Рабочая нагрузка состояла из простой транзакции, которая обновляла два кортежа, выбранные случайным равномерным образом из таблицы, содержащей миллион кортежей. Для этого сценария хорошее разделение не существует, одинаково плохо работают поисковая таблица, разделение по диапазону значений и хэш-разделение. Полная репликация показывает еще худшие результаты, поскольку в каждой транзакции имеется операция обновления. В результате был выбран самый простой метод хэш-разделения.
6.2. Масштабируемость и устойчивость
Чтобы продемонстрировать масштабируемость своего подхода, мы исследовали влияние на производительность системы (i) увеличения числа разделов и (ii) роста размера и сложности базы данных.Табл. 1. Размеры графов.

На всех стадиях работы нашей системы, за исключением фазы разделения графа, производительность, по существу, не зависит от числа разделов и линейно возрастает в зависимости от размеров базы данных и трассы рабочей нагрузки. Поэтому чтобы продемонстрировать масштабируемость мы фокусируемся на производительности фазы разделения графа. Для этого эксперимента мы использовали три графа, характеристики которых приведены в табл. 1.
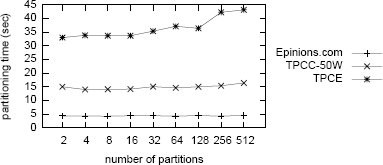
Рис. 5. Масштабируемость реализации разделения графов METIS при росте числа разделов и размеров графа.
На рис. 5 показано время работы последовательной реализации алгоритма разделения графов kmetis при возрастании числа разделов (детали экспериментальной установки см. в Приложении A). Стоимость разделения немного повышается при возрастании числа разделов. Рост размера графа оказывает гораздо более сильное воздействие на время выполнения (оно увеличивается почти линейно в зависимости от роста числа дуг), что оправдывает наши усилия на сокращение размеров графов на основе эвристик, представленных в подразделе 5.1.
Наиболее важной эвристикой для сокращения размеров графов является взятие образцов (sampling). Трудно точно сказать, до какого уровня можно довести взятие образцов при построении графа, чтобы с его помощью все еще можно было получать хорошую схему разделения базы данных. Однако наши эксперименты свидетельствуют о том, что Schism производит хорошие результаты даже при работе с небольшим образцом базы данных. Например, для TPC-C с двумя складами образца, состоящего из одного процента вершин и дуг полного графа, нам хватило для того, чтобы произвести такой же результат, что и при разделении вручную. Качественный анализ наших экспериментов показывает, что минимально требуемый размер графа возрастает по мере роста сложности рабочей нагрузки, размера базы данных и числа разделов. Интуитивно ясно, что для более сложной рабочей нагрузки требуется тщательно моделировать большее число транзакций (и тем самым дуг). Для базы данных большего размера в графе требуется больше вершин (кортежей). Требуется и больше дуг (т.е. больше транзакций), чтобы в графе правильно отражалось то, как производится доступ к данным. Наконец, чем больше разделов, тем более плотным должен быть граф (больше дуг). К сожалению, для формализации всего этого в виде количественной модели требуется более полный набор примеров, и такая работа находится за рамками данной статьи. Простая стратегия выбора степени сэмплинга состоит в том, чтобы пропускать нашу систему над образцами увеличивающегося размера до тех пор, пока качество разделения не перестанет повышаться. В наших простых примерах эта стратегия привела к хорошим результатам.
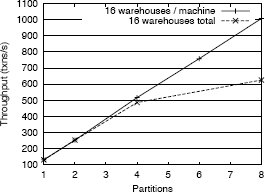
Рис. 6. Масштабируемость пропускной способности TPC-C.
6.3. Сквозная проверка
Чтобы проверить свой сквозной подход и продемонстрировать, что Schism производит сбалансированные разделы, максимизирующие пропускную способность, мы пропускали тестовый набор, основанный на TPC-C, на кластере из 8 машин (подробное описание конфигурации см. в Приложении A). Мы использовали Schism для разделения базы данных на 1, 2, 4 и 8 разделов. Затем каждому разделу назначался отдельный кластер. Система Schism конфигурировалась в расчете на балансировку нагрузки между разделами, что в случае TPC-C приводит также к образованию разделов с почти одинаковыми размерами данных. Произведенные системой предикаты разделения по диапазонам были такими же, как полученные в описанных ранее экспериментах с TPC-C. Мы использовали две конфигурации. В первой из них 16 складов распределялись по узлам кластера. Это демонстрирует горизонтальное масштабирование одного приложения при добавлении больших аппаратных ресурсов. Во второй конфигурации одновременно с добавлением узлов мы добавляли и склады, так что на каждой машине всегда имелись данные о 16 складах. Это демонстрирует возможность Schism поддерживать рост масштаба приложения при добавлении аппаратуры. Использовалось достаточное число клиентов TPC-C, чтобы можно было насытить пропускную способность TPC-C. Пропускная способность показана на рис. 6.Результаты показывают, что при наличии 16 складов один сервер способен достичь пропускной способности в 131 транзакцию в секунду. При горизонтальном масштабировании этой конфигурации производительность возрастала почти линейно при росте числа машин до четырех, но при наличии восьми машин достигалось повышение пропускной способности только в 4,7 раза. Это объсняется тем, что реализации TPC-C свойственны конфликты, которые образуют узкое место при хранении в одной машине данных только о двух складах. Невозможно насытить пропускную способность какой-либо одной машины, поскольку почти все транзакции конфликтуют, и это ограничивает максимально возможную пропускную способность. В конфигурации с постоянным хранением в каждой машине данных о шестнадцати складах это узкое место не возникает, и в этом случае демонстрируемая масштабируемость очень близка к линейной (при использовании восьми машин пропускная способность увеличивается в 7,7 раза – коэффициент 0,96).
Этот эксперимент показывает, что Schism может произвести высококачественную схему разделения, позволяющую добиться хорошей масштабируемости. Наши результаты показывают, что при применении к этой рабочей нагрузке хэш-разделения, мы получили бы 99% распределенных транзакций, что привело бы к значительному уменьшению пропускной способности.
7. Родственные работы
Методы разделения баз данных активно исследовались как для одномашинных серверов (например, [1]), так и для систем без совместно используемых ресурсов (например, [23, 18]). В этих подходах обычно используется схема базы данных для получения возможных разделений по диапазонам значений или хэш-разделений, которые затем оцениваются с применением эвристик или оценочных моделей. Обеспечивается ограниченная поддержка рабочих нагрузок OLTP, и обычно отсутствует возможность генерации осмысленных стратегий разделения для схем, содержащих несколько связей n-к-n.Стохастический подход Цангариса (Tsangaris) и Нотона (Naughton) для кластеризации объектно-ориентированных баз данных опирается на эвристики разделения графов [22]. В нашей же системе, кроме того, интегрируется репликация, и система разрабатывается в расчете на выполнение совсем других требований распределенных баз данных.
В последнее время имеется значительный интерес к "упрощенным" распределенным системам хранения данных, таким как BigTable [2] или PNUTS [3]. В этих системах постоянно выполняется переразделение данных для балансировки объемов данных и рабочей нагрузки между несколькими серверами. Будучи более динамичными, эти методы не имеют дела с транзакциями над несколькими таблицами.
Широко известна сложность проблемы масштабирования приложений социальных сетей из-за сильной взаимосвязанности соответствующих данных. Подход One Hop Replication направлен на масштабируемость таких приложений путем репликации связей, обеспечивая немедленный доступ ко всем элементам данных в пределах "одного скачка" ("one hop") от заданной записи [16]. В этом подходе требуется алгоритм начального разделения данных, и Schism можно было бы использовать вместе с этой системой.
Гибридно-диапазонная стратегия разделения (hybrid-range partitioning strategy, HRPS) – это гибрид хэш-разделения и разделения по диапазонам значений, основанный на анализе запросов. Схема направлена на декластеризацию (параллельное выполнение на нескольких узлах путем распределения данных между ними) долговременных запросов и локализацию мелких запросов с условиями вхождения в диапазон значений. HRPS применима только к однотабличным запросам с условиями вхождения в диапазоны значений одного атрибута, и в этой стратегии репликация не предусматривается.
На противоположном конце спектра по отношению к Schism находятся исследовательские работы по чистой декластеризации [19] и "советчики по разделению" (partitioning advisor), часто включаемые в коммерческие СУБД [7, 18], которые, главным образом, ориентированы на поддержку рабочих нагрузок OLAP и на оптимизацию расположения данных на дисках в одной системе. В работе Лиу (Liu) и др., как и в нашей работе, используется разделение графов, но для противоположной цели (декластеризация). Кроме того, в работе Лиу и др. не учитывается возможность репликации и не предлагается толкование на основе предикатов.
8. Заключение
Мы представили Schism – систему для мелкоструктурного разделения баз данных OLTP. В нашем подходе записи базы данных представляются как вершины графа, а дуги соединяют вершины, к которым обращается одна и та же транзакция. Затем мы используем алгоритм разделения графов для нахождения разделений, минимизирующих число распределенных транзакций. Кроме того, мы предлагаем ряд эвристик, включающих взятие образцов и группировку записей, позволяющих уменьшить сложность графа и оптимизировать производительность. Мы также вводим метод, основанный на деревьях решений, для толкования разделения в терминах компактного набора предикатов, позволяющего установить, к какому разделу относится заданный кортеж.Наши результаты показывают практичность подхода Schism, обеспечивающего (i) умеренное время работы (в пределах нескольких минут во всех наших тестах), (ii) отличное качество разделения, находя разделения разнообразных баз данных OLTP, в которых только немногие транзакции являются многораздельными (часто автоматическое разделение, выполняемое Schism оказывается не хуже наилучших схем разделения вручную), (iii) простую интеграцию с существующими СУБД за счет поддержки разделения по диапазонам значений в параллельных системах баз данных типа DB2 или за счет использования промежуточного программного обеспечения для управления распределенными транзакциями.