Schism: управляемый рабочей нагрузкой подход к репликации и разделению баз данных
Карло Курино, Эван Джонс, Янг Жанг и Сэм Мэдден
Перевод: Сергей Кузнецов
4. Разделение и репликация
Установив стоимость распределенных транзакций, представим свой подход к разделению и репликации, направленный на то, чтобы транзакции обращались к данным только одного раздела.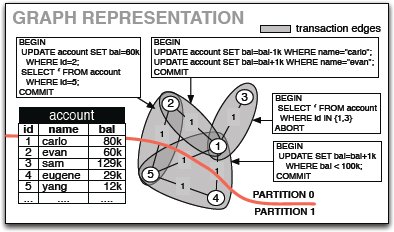
Рис. 2. Представление графа.
4.1. Представление графов
Мы описываем свое представление графов с использованием простого примера. Хотя в этом примере применяется всего одна таблица, наш подход работает с любой схемой и не зависит от сложности операторов SQL, присутствующих в рабочей нагрузке. Предположим, что имеются банковская база данных, состоящая из одной таблицы account с пятью кортежами, и рабочая нагрузка из четырех транзакций, как показано на рис. 2. Каждому кортежу соответствует вершина графа; дуги связывают кортежи, используемые в одной и той же транзакции. Вес дуги – это число транзакций, обращающихся к соответствующей паре кортежей. На рис. 2 веса дуг не показаны, поскольку к каждой паре кортежей обращается не более чем одна транзакция.
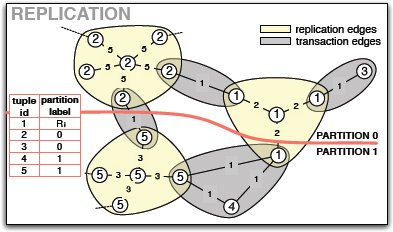
Рис. 3. Граф с репликацией.
На рис. 3 показано расширение основного представления графов, отражающее возможность репликации на уровне кортежей. Репликация представляется путем "развертывания" вершины, представляющей некоторый кортеж, в звездообразную конфигурацию из n+1 вершин, где n – число транзакций, обращающихся к соответствующему кортежу.
В качестве примера рассмотрим кортеж (1, carlo, 80k) с рис. 2. К этому кортежу обращаются три транзакции, и поэтому на рис. 3 он представляется четырьмя вершинами. Веса дуг репликации, соединяющих каждую реплику с центральным узлом, представляют стоимость репликации данного кортежа. Эта стоимость определяется как число транзакций в рабочей нагрузке, обновляющих данный кортеж (для кортежа, используемого в примере, их две). При репликции кортежа каждая операция чтения может выполняться локально, но каждое обновление становится распределенной транзакцией. Эта графовая структура позволяет алгоритму разбиения соблюдать баланс между стоимостью репликации и выгодой от ее использования.
Мы экспериментировали с другими представлениями графов, включая гиперграфы, но обнаружили, что для наших целей они недостаточно пригодны (дальнейшие подробности относительно нашего графового представления см. в Приложении B).
Стратегия разделения графов, обсуждаемая в следующем подразделе, эвристическим образом минимизирует стоимость разрезания графа, балансируя при этом веса каждого раздела (более точно, соблюдая ограничение допустимого перекоса). Вес раздела определяется как сумма весов вершин, отнесенных к этому разделу. Следовательно, путем назначения вершинам разных весов мы можем по-разному балансировать разделы. Мы экспериментировали с двумя важными показателями разбиения баз данных: (i) балансировка по размеру базы данных, когда вес вершины равен размеру соответствующего кортежа в байтах, и (ii) балансировка по рабочей нагрузке, когда вес вершины равен числу обращений к соответствующему кортежу.
4.2. Разделение графов
Представление графов в Schism характеризует как базу данных, так и операции над ней. При разделении граф расщепляется на k неперекрывающихся разделов таким образом, что общая стоимость разрезания дуг минимизируется (т.е. находится разделение с минимальными разрывами (mininimum-cut)). При этом веса разделов удерживаются в пределах допустимого отклонения от совершенной балансировки (коэффициент отклонения является параметром системы). Эта операция над графом приближенно минимизирует число распределенных транзакций, распределяя нагрузку или данные поровну между узлами.Наше единообразное представление разделения и репликации позволяет алгоритму разделения графов для каждого кортежа принимать решение о том, следует ли реплицировать его в нескольких разделах (как, например, кортеж 1 на рис. 3) и нести затраты на выполнение распределенных оперцаций обновления, или же лучше хранить его в одном разделе (как, например, кортеж 4 на рис. 3) и нести расходы на выполнение распределенных транзакций. Если все реплики некоторого кортежа оказываются в одном разделе, этот кортеж не реплицируется. В противном случае принимается решение о его репликации. Естественно, алгоритм разделения не принимает решения о репликации кортежей, которые часто обновляются, поскольку разрывы дуг, соединяющих вершины-кортежи с вершинами репликами, обладают высокой стоимостью, соответствующей стоимости распределенных обновлений. И наоборот, велика вероятность репликации редко обновляемых кортежей, если это приводит к снижению стоимости разрыва дуг транзакций. В подразделе 4.3 мы обсуждаем, каким образом подход к принятию решений на уровне кортежей можно обобщить для принятия решений при разделении на уровне таблиц или по диапазонам значений.
Известно, что разделение графа на k частей при наличии ограничений – это NP-полная проблема. Однако, поскольку подобные разделения часто требуются в области автоматизиции проектирования сверхбольших интегральных схем, в последние сорок лет в этом направлении было выполнено много исследований и разработок [12, 10, 13], в результате которых были получены сложные эвристические правила и созданы хорошо оптимизированные свободно доступные библиотеки программного обеспечения. В большинстве алгоритмов разделения графов используются методы многоуровневого огрубления (multilevel coarsening) и обеспечиваются параллельные реализации в распределенной среде, позволяющие обрабатывать исключительно крупные графы (сотни миллионов дуг). В Schism для разделения графов мы используем METIS [11].
Результатом фазы разделения графа является мелкозернистое отображение отдельных вершин (кортежей) на множество меток разделов. По причине наличия репликации один кортеж может быть приписан к нескольким разделам. Мелкозернистое разделение. Одним из способов использования результатов фазы разделения является сохранение этих результатов в поисковой таблице (lookup table) типа той, которая показана в левой части рис. 3.
В распространенном случае доступа по ключам к кортежам (т.е. когда разделы WHERE запросов содержат предикаты сравнения на равенство или вхождения в диапазон значений идентификаторов кортежей) эти таблицы можно напрямую использовать для направления запросов в соответствующий раздел. В нашем прототипе для этого используется компонент маршрутизации промежуточного программного обеспечения, который разбирает запросы и сравнивает предикаты их разделов WHERE с содержимым поисковых таблиц. На физическом уровне поисковые таблицы могут сохраняться в виде индексов, битовых массивов или фильтров Блюма (Bloom-filter) – детали организации поисковых таблиц см. в Приложении C. При наличии плотного множества идентификаторов кортежей и числа кортежей в пределах 256 в узле-координаторе с 16 гигайбатами основной памяти можно сохранять поисковую таблицу, тратя по одному байту на каждый идентификатор кортежа и сохраняя информацию от разделении более 15 миллиардов кортежей (других потребностей по использованию основной памяти у координатора нет). Этого более чем достаточно для подавляющего большинства приложений OLTP. Кроме того, при исчерпании основной памяти такие таблицы можно хранить распределенным образом в основной памяти на разных машинах или в виде индекса в дисковой памяти.
При использовании поисковых таблиц новые кортежи сначала вставляются в произвольный раздел, и сохраняются там, пока не будет заново подсчитано разделение, после чего их можно переместить в соответствующие разделы. Поскольку разделение графа выполняется быстро, эту процедуру можно будет выполнять часто, что будет препятствовать удорожанию распределенных транзакций из-за добавления новых кортежей.
Хотя этот подход эффективен, если требуется стратегия мелкоструктурного разделения (например, в некоторых приложениях социальных сетей), он не идеален для очень крупных систем баз данных с рабочими нагрузками с очень интенсивной вставкой кортежей. Поэтому мы разработали аналитическое инструментальное средство, которое может обнаружить более простое, основанное на использовании предикатов средство разделения, близко аппроксимирующее результат компонента разделения графов.
4.3. Фаза толкования
На фазе толкования система пытается найти компактную модель, в которой фиксируется отображение (tuple, partition), полученное на фазе разделения. Для выполнения этой задачи мы используем деревья решений (классификаторы в машинном обучении) поскольку они производят доступные для понимания основанные на правилах результаты, которые можно сразу применять для разделения по предикатам диапазонов. Классификатор на основе дерева решений на входе принимает набор пар (value, label), а в качестве результата производит дерево предикатов над значениями, ведущими к листовым вершинам с заданными метками. Для непомеченного значения метку можно обнаружить путем спуска по дереву и применения предикатов в каждом узле до тех пор, пока не будет достигнут помеченный лист.В Schism значения – это кортежи базы данных, а метки – разделы, назначенные кортежам алгоритмом разделения графов. Реплицируемые кортежи помечаются специальным идентификатором репликации, обозначающим набор разделов, в котором должен храниться данный кортеж (например, набор разделов {1, 3, 4} можно представить меткой R1).
В случае удачи классификатор обнаруживает простой набор правил, в котором в компактной форме фиксируется суть разделения, полученного алогоритмом разделения графов. Для примера с рис. 2 и 3 классификатор на основе дерева решений выводит следующие правила:
(id = 1 ) → partitions = {0, 1}
(2 ≤ id < 4) → partition = 0
(id ≥ 4) → partition = 1
Не всегда возможно получить толкование разделения, и не всякое толкование полезно. Толкование оказывается полезным только при выполнении следующих условий:
-
оно основывается на атрибутах, часто используемых в запросах (например, в нашем примере, атрибут
idиспользуется в разделеWHEREполовины запросов), – это требуется для того, чтобы можно было направлять транзакции в один узел и избегать дорогостоящей широковещательной рассылки; - оно не слишком снижает качество разделения за счет неправильной классифкации кортежей;
- оно работает для дополнительных запросов (при чрезмерно близкой подгонке может получиться толкование, работающее на обучающем наборе, но использующее атрибуты, не представленные в запросах приложения).
Для достижения этих целей мы:
- ограничиваем дерево решений таким образом, чтобы оно работало на атрибутах, часто используемых в запросах;
- измеряем стоимость как число распределенных транзакций и не допускаем толкований, ухудшающих графовое решение и
- активно используем отсечение и перекрестную проверку, чтобы избежать чремерно близкой подгонки.
В разд. 5.2 реализация процесса толкования описывается более подробно.
4.4. Окончательная валидация
Целью фазы валидации является сравнение решений, полученных на двух предыдущих фазах, и выбор итоговой схемы разделения. Более точно, мы сравниваем мелкозернистое разделение на уровне кортежей, получаемое путем разделения графа, схему разделения по предикатам диапазонов значений, получаемую на фазе толкования, хэш-разделение по наиболее часто используемым атрибутам и репликацию на уровне таблиц, используя число распределенных транзакций в качестве оценки стоимости выполнения рабочей нагрузки. Мы выбираем схему, приводящую к наименьшему числу распределенных транзакций, если только для нескольких схем не получаются близкие показатели стоимости. В последнем случае из этих схем выбирается наименее сложная схема (например, мы отдаем предпочтение хэш-разделению или репликации перед разделением на основе предикатов и разделению на основе предикатов перед разделением с использованием поисковых таблиц). Важность этого процесса была продемонстрирована в двух экспериментах, описываемых в разд. 6, в которых система выбирала простое хэш-разделение, а не разделение по предикатам для нескольких простых рабочих нагрузок, для которых хэш-разделение работало хорошо.5. Оптимизация и реализация
В этом разделе мы представим некоторые проблемы и проектные решения, с которыми нам пришлось встретиться при разработке Schism.5.1. Обеспечение масштабируемости
Практическое инструментальное средство разделения должно обладать способностью к обработке очень больших баз данных. С ростом размера базы данных и числа кортежей, к которым обращается каждая транзакция, растет и графовое представление. Чем больше разных транзакций содержится в рабочей нагрузке, тем больших размеров трасса рабочей нагрузки требуется для фиксации типичного поведения. С ростом числа разделов требуется обнаруживать больше разрезов в графе. Эти факторы могли бы ограничить размеры баз данных, с обработкой которых справляется наша система.Как мы покажем в разд. 6, средства разбиения графов хорошо масштабируются по отношению к числу разделов, но с ростом размера графа время их работы существенно возрастает. Поэтому мы сосредоточили усилия на уменьшении размеров графов. Интуитивно кажется, что это поможет уменьшить время работы алгоритма разделения, но ухудшит качество результата, поскольку входной граф меньшего размера содержит меньше информации. Однако мы разработали ряд эвристик, которые позволяют сократить размер графа с умеренным воздействием на качество разделения. Более точно, мы реализовали следующие эвристики:
- Взятие образцов на уровне транзакций (transaction-level sampling), что позволяет ограничить объем рабочей нагрузки, представляемой в графе, т.е. уменьшить число дуг.
- Взятие образцов на уровне кортежей (tuple-level sampling), что позволяет сократить число кортежей (узлов), представляемых в графе.
- Отбрасывание "ковровых" запросов (blanket statement filtering), что позволяет не учитывать редко встречающиеся запросы, приводящие к сканированию больших частей таблицы. Эта эвристика оправдывается тем, что (i) наличие таких запросов приводит к образованию в графе многих дуг, несущих мало информации, и (ii) выполнение подобных запросов эффективно распаллеливается по разделам, поскольку накладные расходы распределенных транзакций менее значительны, чем расходы на выполнение частей запроса в разных узлах.
- Фильтрация по релевантности (relevance filtering), когда удаляются кортежи, к которым обращения производятся очень редко (предельным случаем являются кортежи, к которым в рассматриваемой рабочей нагрузке вообще отсутствуют обращения). Соответствующие вершины графа мало информативны.
- Звездообразная репликация (star-shaped replication), когда вершины-реплики связываются в звездообразную конфигурацию, а не в полный подграф (clique), что ограничивает число дуг.
- Склеивание кортежей (tuple-coalescing), что позволяет представлять одной вершиной графа группу кортежей, к которым доступ всегда производится ко всем сразу. Это не вызывает потери информации и в некоторых случаях приводит к существенному сокращению размера графа.
Эти эвристики обеспечили эффективное сокращение размеров графов для наших тестовых наборов, сохранив при этом высокое качество результатов. Например, в подразделе 6.2 мы показываем, что (при наличии нескольких тысяч транзакций) в покрытии графа, включающем всего 0,5% от числа кортежей базы данных, остается достаточно информации, чтобы получить разделение, качество которого сопоставимо с наилучшим разделением базы данных, выполненным вручную.
5.2. Реализация толкования
Для реализации фазы толкования, описанной в подразделах 4.3 и 4.4, мы использовали свободно доступную библиотеку машинного обучения Weka [9]. Процесс толкования состоит из следующих шагов:- Создание обучающей выборки (training set): Schism извлекает из трассы рабочей нагрузки информацию о запросах и затрагиваемых ими кортежах – для сокращения времени работы используется взятие образцов (sampling) без ухудшения качества результата. Кортежи помечаются метками разделов, произведенных алгоритмом разделения графа. Как описывалось в подразделе 4.3, реплицируемые кортежи помечаются метками виртуальных разделов, соответствующими наборам целевых разделов. Таким образом образуется обучающая выборка, используемая классификатором на основе дерева решений.
-
Выбор атрибутов: Система разбирает операторы SQL, присутствующие в рабочей нагрузке, и для каждого атрибута фиксирует частоту его вхождений в разделы
WHERE. Редко используемые кортежи отбрасываются, поскольку они не годятся для марштрутизации запросов. Например, для таблицы TPC-Cstockмы получаем два часто используемых атрибута(s_i_id, s_w_id), представляющие идентификаторы вида товара и склада соответственно. Выбранные атрибуты подаются на вход основанного на учете корреляции компонента Weka отбора признаков (feature selection), который выбирает набор атрибутов, коррелирующих с метками разделов. Для TPC-C на этом шаге отвергается атрибутs_i_id, и для последующей классификации оставляется единственный атрибутs_w_id.
Более сложен тот сценарий, в котором доступ к кортежам одной таблицы часто производится на основе соединения с некоторой другой таблицей. В этом случае наша система подготавливает входные данные для классификатора в виде результата соединения двух таблиц. В результирующем разделении будет требоваться совместное расположение соединенных кортежей в одном и том же разделе, и в состав набора производимых предикатов войдут предикаты соединения, а также предикаты диапазонов значений другой таблицы. Результирующее разделение на основе предикатов будет поддерживать только запросы, выполняющие это соединение. Другие запросы придется отправлять во все разделы. Хотя подобные запросы не очень распространены (их нет ни в одном из приложений нашего тестового набора), такая ситуация поддерживается. -
Построение классификатора: Мы обучаем классификатор на основе дерева решений с использованием J48 – реализации на языке Java классификатора C4.5 [17]. Атрибутами классификации являются метки разделов, которые мы хотим узнать на основе атрибутов, отобранных на предыдущем шаге. На выходе классификатора получается набор предикатов, аппроксимирующих разделение на уровне кортежей, которое было произведено алгоритмом разделения графов. Чрезмерно близкой подгонки удается избежать за счет перекрестной проверки и управляемого применения эвристики сокращения дерева решений для устранения правил с малой поддержкой.
Например, для базы данных TPC-C с двумя складами, разбитой на два раздела, мы получили для таблицыstockследующие правила:s_w_id ≤ 1: partition: 1 (pred. error: 1.49%)
s_w_id > 1: partition: 2 (pred. error: 0.86%)Для таблицы
itemклассификатор произвел правило:<empty>: partition: 0 (pred. error: 24.8%)Это показывает, что все кортежи этой таблицы реплицируются. Высокое значение ошибки предсказания в этом примере появилось из-за взятия образцов: к некоторым кортежам таблицы
itemобращается всего несколько транзакций, в результате чего потребность в репликации оказалась необоснованной. Однако это не влияет на качество решения.
Общий результат для TPC-C состоит в разделении базы данных по складам и в репликации всей таблицы item. Такую же стратегию предлагали эксперты [21]. Как отмечается в разд. 6, аналогичное разделение находится для TPC-C с большим числом складов и разделов. Хотя для определения разделов в случае TPC-C не требуются несколько атрибутов, в случае надобности классификатор может производить правила соответствующего вида.
5.3. Получение трасс
Для создания графового представления для каждой транзакции нам требуется получить наборы кортежей, к которым она обращается. Мы разработали инструментальное средство, которое применяется к некоторому журналу операторов SQL (например, кgeneral log MySQL) и позволяет получить множества чтения и записи транзакций. Прежде всего, операторы SQL, содержащиеся в трассе, переписываются в операторы SELECT, извлекающие идентификаторы (т.е. первичные ключи) всех кортежей, к котором происходит обращение. Эти запросы выполняются, и производится список пар (tuple id, transaction), используемый для построения графа. Этот механизм может использоваться либо в режиме онлайн, когда идентификаторы кортежей извлекаются сразу после выполнения исходного оператора, либо в режиме офлайн. Извлечение идентификаторов кортежей намного позже выполнения исходных операторов все равно приводит к порождению хороших стратегий разделения наших экспериментальных данных, из чего следует, что наш подход не слишком чувствителен к тому, какие в точности кортежи используются. Мы полагаем, что за счет комбинирования этого свойства устойчивости к устаревшим данным со взятием образцов можно извлекать наборы чтения и записи в производственных системах с незначительным воздействием на их производительность.
5.4. Миграция данных и маршрутизация запросов
Осталось рассмотреть еще два аспекта реализации. Первый состоит в том, каким образом мы перемещаем данные из одного раздела в другой. Для этого в Schism генерируются SQL-скрипты миграции данных. Текущая версия системы разработана с целью разбиения на разделы одной базы данных. Мы расширяем эту возможность для решения более общей проблемы динамического переразделения данных. В качестве альтернативы выходные данные нашего инструментального средства могут подаваться на вход СУБД, поддерживающих разделение данных (например, DB2 или Oracle), которые могут производить перемещение данных.Второй важный аспект – это то, каким образом репликация и разделение, обеспечиваемые Schism, используются во время выполнения для маршрутизации запросов. Мы разработали маршрутизатор и координатор распределенных транзакций, которые обеспечивают следование стратегии репликации и разделения [5]. Поддерживаются хэш-разделение, разделение на основе предикатов и поисковые таблицы. Маршрутизатор является компонентом промежуточного программного обеспечения, разбирающим SQL-операторы и определяющим, какие разделы требуются для их выполнения. Для запросов только по чтению над реплицированными кортежами Schism пытается выбрать реплики в разделе, к которому данная транзакция уже обращалась. Эта стратегия позволяет сократить число распределенных транзакций. Другие подробности относительно маршрутизации см. в Приложении C.