Доводы в пользу детерминизма в системах баз данных
Дэниел Абади и Александер Томсон
Перевод: Сергей Кузнецов
5. TPC-C и разделенные данные
Для изучения характеристик производительности своего детерминированного протокола выполнения транзакций в распределенной и разделенной системе мы реализовали подмножество тестового набора TPC-C, на 100% состоящее из транзакцийNew Order. Транзакция New Order имитирует клиента, размещающего некоторый электронный заказ, вставляющего несколько записей и изменяющего уровень запасов для 5-15 типов товаров (из 100000 видов товаров, имеющихся на каждом складе).
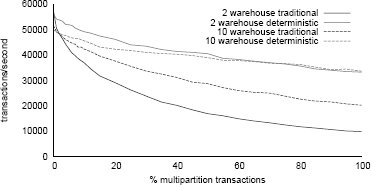
Рис.3. Детерминированная и традиционная пропускная способность рабочей нагрузки TPC-C (100% транзакций New Order) при изменении частоты многораздельных транзакций.
На рис. 3 показана пропускная способность для детерминированного и традиционного выполнения рабочей нагрузки, состоящей из транзакций New Order тестового набора TPC-C, при изменении частоты появления многораздельных транзакций (в которых часть заказа клиента должна заполняться за счет склада, данные которого располагаются в удаленном узле). В этих экспериментах данные распределялись по двум разделам. В показанные результаты включены измерения для двух и десяти складов (в первом случае по одному складу на каждый раздел, во втором – по пять складов). Более подробное обсуждение экспериментальной установки см. в приложении.
Пока частота появления многораздельных транзакций невелика, транзакции New Order остаются исключительно короткими, и обе схемы выполнения при заданном размере набора данных обеспечивают сравнимую пропускную способность – как и в экспериментах, описанных в разд. 3, когда в среде выполнения отсутствовали аномально медленные транзакции. При наличии всего двух складов обе схемы обеспечивают лучшее использование кэша, чем в случае десяти складов, что приводит в более высокой пропускной способности при отсутствии многораздельных транзакций. Однако чем меньше имеется записей, тем больше наблюдается конфликтов блокировок. Транзакции New Order конфликтуют с вероятностью примерно 0,05 при наличии двух складов и с вероятностью около 0,01 при наличии десяти складов. Поэтому для обеих систем общее падение производительности при возрастании частоты появления многораздельных транзакций оказывается большим при наличии двух складов, чем в случае десяти складов (поскольку многораздельные транзакции выполняются дольше, и это усиливает эффект конфликта блокировок).
При сравнении пропускной способности систем, основанных на двух разных моделях выполнения, можно было бы ожидать, что, как только сетевые задержки начнут приводить к более продолжительному удержанию блокировок, застопоренное поведение детерминированной систем приведет к большему падению ее производительности, чем у традиционной системы (особенно в случае двух складов, в котором вероятность конфликта блокировок очень высока). На самом же деле, вы видим обратное: независимо от числа складов (и, следовательно, вероятности конфликтов) при появлении многораздельных транзакций производительность детерминированного протокола падает медленнее производительности традиционных блокировок.
Этот эффект можно объяснить тем, что при использовании традиционной схемы выполнения блокировки удерживаются дополнительное время при выполнении двухфазного протокола фиксации. В традиционном случае все блокировки удерживаются на все время двухфазной фиксации. Однако при использовании детерминированного выполнения наш препроцессор направляет каждую новую транзакцию в каждый узел, участвующий в ее обработке. Фрагмент транзакции, посылаемый в каждый узел, снабжается информацией о том, какие данные потребуются из каждого другого узла (например, потребуется ли удаленное чтение, и могут ли произойти условные аварийные завершения), прежде чем обновления, производимые этим фрагментом можно будет "зафиксировать". После получения всех требуемых данных из всех ожидаемых узлов данный узел может безопасным образом освободить блокировки текущей транзакции и перейти к следующей транзакции. Не требуется никакого протокола фиксации, чтобы гарантировать, что отказ узла не влияет на окончательное решение о фиксации или аварийном завершении, потому что отказ узла – это недетерминированное событие, а недетерминированные события не могут служить причиной аварийного завершения транзакции (транзакция зафиксируется в некоторой реплике, которую, как отмечалось ранее, можно будет использовать для восстановления отказавшего узла).
Это означает, что при обработке многораздельной транзакции с использованием детерминированного управления параллелизмом каждому узлу, участвующему в обработке транзакции, требуется послать по одному сообщению в каждый другой узел, участвующий в обработке той же транзакции, и получить от каждого такого узла не более одного сообщения. Если все узлы, участвующие в выполнении многораздельной транзакции, посылают сообщения примерно в одно и то же время (как часто бывало в наших экспериментах, поскольку многораздельные транзакции естественным образом порождают синхронизационные события в рабочей нагрузке), блокировки удерживаются только в течение дополнительного времени, требуемого для однонаправленной передачи одного сетевого сообщения.
При применении традиционной модели выполнения каждая поступающая транзакция, которая блокируется незавершенной многораздельной транзакцией New Order вынуждена оставаться блокированной на все время выполнения двухфазной фиксации, что приводит к загромождению системы неработающими транзакциями и еще больше повышает вероятность конфликтов блокировок у последующих поступающих транзакций. Измерения реальной вероятности конфликтов блокировок и средней задержки транзакций, выполненные в ходе этих экспериментов, приведены в приложении. Они показывают, что увеличение продолжительности распределенных транзакций приводит как к большей вероятности конфликтов блокировок, чем та, которая наблюдается при использовании детерминированной схемы, так и к более высокой стоимости, связанной с каждым проявлением конфликта блокировок.
6. Родственные исследования
Системы баз данных, в которых обеспечиваются более строгие гарантии сериализуемости, чем эквивалентность некоторому порядку следования, существуют более трех десятилетий. Например, предлагалось гарантировать эквивалентность заданному порядку временных меток транзакций с использованием разновидности схемы управления параллелизмом с упорядочиванием на основе временных меток, называемой консервативной схемой упорядочивания по временным меткам (conservative T/O) [3]. (Позже эту схему стали называть "предельной консервативной схемой временных меток" ("ultimate conservative T/O" )[5], чтобы отличать ее от других схем управления параллелизмом с упорядочиванием по временным меткам, в которых допускается аварийное завершение транзакций и переупорядочивание.) Conservative T/O задерживает выполнение любой операции над базой данных до тех пор, пока заведомо не будут выполнены все потенциально конфликтующие операции с меньшими значениями временных меток. Как правило, это реализуется за счет того, что планировщик операций ожидает получения сообщений от всех возможных источников транзакций, а затем планирует выполнение операции чтения или записи с наименьшей временной меткой среди всех источников.Эта бесхитростная реализация чрезмерно консервативна, поскольку, как правило, сериализует все операции записи в базу данных. Однако можно добиться дополнительного параллелизма метода разбиения транзакций на классы, использованного в SDD-1 [6], где каждая транзакция включалась в некоторый класс транзакций, и только для потенциально конфликтующих классов транзакций требовалась консервативная обработка. Такому подходу способствует заблаговременное объявление наборов чтения и записи транзакций. В нашей работе совершенствуются эти старые методы для обеспечения эквивалентности одному порядку следования. Однако мы решили реализовать свою детерминированную систему баз данных с использованием техники блокировок и оптимистических методов, позволяющих обойтись без заблаговременного знания наборов чтения и записи, поскольку в большинстве современных систем баз данных управление параллелизмом основывается на технике блокировок, а не технике временных меток.
Теоретическое обоснование того, что детерминированное выполнение внутри каждой системы, содержащей реплику базы данных, облегчает активную репликацию, можно найти в работе Шнейдера (Schneider) [23]. В этой работе демонстрируется, что если каждая система, содержащая реплику базы данных, получает транзакции в одном и том же порядке и обрабатывает их детерминированным, последовательным образом, то все реплики останутся согласованными. К сожалению, то требование, что каждая система с репликой базы данных выполняет транзакции с использованием одного потока управления, для сегодняшних высокопараллельных систем баз данных не является реалистичным. К аналогичному выводу пришли и Хименес-Перис (Jimenez-Peris) и др. [11]. Поэтому они применили детерминированный планировщик потоков управления, позволяющей системе с репликой базы данных выполнять транзакции с использованием нескольких потоков управления. Каждый поток управления одинаково планируется в каждой системе-реплике (с тщательным учетом возможности чередования работы локальных потоков управления с работой, возникающей в результате получения сообщений от других серверов в ходе выполнения распределенных транзакций). Наша работа отличается от работы Хименеса-Периса и др., поскольку мы допускаем произвольное планирование потоков управления (что обеспечивает планировщику большую гибкость и позволяет незамедлительно обрабатывать приходящие сетевые сообщения, а не ждать, пока не завершится работа локальных потоков управления) и обеспечиваем детерминизим за счет изменения протокола управления параллелизмом в системе баз данных.
В недавней работе Басиле (Basile) и др. [1] подход Хименеса-Периса и др. расширяется за счет перехвата запросов взаимного исключения (mutex), поступающих от потоков управления перед тем, как они обращаются к совместно используемым данным. Это позволяет повысить уровень параллелизма, позволяя планировать произвольным образом потоки управления, в которых не производится доступ к одним и тем же данным. Однако в этом решении требуется посылка сетевых сообщений от ведущих узлов в узлы-реплики для обеспечения взаимного исключения конфликтующих потоков управления, в то время как в нашем решении для управления параллелизмом обмен сетевыми сообщениями между репликами не требуется.
Идея упорядочивания тразакций и предоставлении блокировок на запись в соответствии с этим порядком была представлена в работе Кемме (Kemme) и Алонсо (Alonso) [13]. Наша работа отличается от предложенного ими подхода тем, что в нашем случае не используются теневые копии (shadow copy), и требуется всего лишь надежный протокол обмена груповыми сообщениями, гарантирующий порядок их доставки, при посылке сообщений от препроцессора к базе данных – никогда внутри многораздельных транзакций, поскольку в детерминированной системе это привело бы к недопустимо долгим интервалам удержания блокировок. Кроме того, мы обрабатываем зависимые транзакции с использованием оптимистического метода.
Гарсиа-Молина (Garcia-Molina) и Салем (Salem) [9] заметили, что использование систем баз данных в основной памяти (main memory database system) приводит к убыстрению транзакций и снижению вероятности конфликтов блокировок. Кроме того, они утверждают, что во многих случаях лучше всего выполнять транзакции полностью последовательно и полностью избегать накладных расходов блокировок. В нашей работе приходится не только учитывать, что транзакции над данными основной памяти выполняются быстрее транзакций, которым приходится обращаться к дискам, но и принимать во внимание, что продолжительность некоторых транзакций увеличивается из-за потребности в передачи и приеме сетевых сообщений (требуемых для выполнения распределенных транзакций). Кроме того, мы не требуем, чтобы транзакции выполнялись последовательно (хотя обеспечиваем эквивалентность заданному порядку следования); несколько разных транзакций может параллельно выполняться в нескольких потоках управления.
Уитни (Whitney) и др. [26], Пачитти (Pacitti) и др. [18], Стоунбрейкер (Stonebraker) и др. [24] и Джонс (Jones) и др. [12] предлагают обрабатывать транзакции в распределенных системах баз данных без управления параллелизмом путем последовательного выполнения транзакций в одном потоке управления на каждом узле (где в некоторых случаях узел может являться одним ядром процессора в многоядерном сервере [24]). Уитни и др. не поддерживают активную репликацию (обновления для реплик сначала журнализуются), но авторы двух последних статей используют преимущества детерминизма для выполнения активной репликации. Однако в обоих случаях проблему представляют многоузловые (распределенные) транзакции. В нашей схеме детерминированное управление параллелизмом позволяет обойтись без двухфазной фиксации, что существенно снижает стоимость многоузловых транзакций и обеспечивает высокий уровень параллелизма потоков управления.
Разработчики решений уровня промежуточного программного обеспечения (middleware), таких как, например, разработка компании xkoto (недавно поглощенной компанией Teradata) и Tashkent-API [8], пытаются производить репликацию в нескольких системах баз данных путем выполнения в каждой системе одних и тех же транзакций в одном и том же порядке. Однако поскольку системы баз данных не обеспечивают эквивалентности какому-либо заданному порядку следования, в этих системах middleware для предотвращения расхождения реплик снижается уровень параллелизма транзакций, отправляемых в системы баз данных, что потенциально приводит к понижению пропускной способности. Наше решение реализуется внутри баз данных, что позволяет избежать чрезмерной сложности систем, основанных на промежуточном программном обеспечении.
Тэй (Tay) и др. с использованием детальной аналитической модели сравнивают традиционную динамическую схему блокировок со статической схемой (когда все блокировки в транзакции запрашиваются при ее начале) [25]. Однако в случае статической схемы, если невозможно получить все блокировки сразу, транзакция аварийно завершается и запускается заново (и, следовательно, протокол не является детерминированным). Кроме того, эта модель не работает в том случае, когда местоположение данных, которые требуется блокировать, заранее не известно.
7. Заключение
В этой статье мы заново рассмотрели плюсы и минусы наличия недетерминированного поведения в системах баз данных.Мы показали, что в свете современных технологических тенденций модель выполнения транзакций в системах баз данных, гарантирующая эквивалентность некоторому предопределенному последовательному порядку выполнения с целью обеспечения детерминированного поведения, является жизнеспособной при наличии рабочих нагрузок OLTP над базами данных в основной памяти, значительно облегчая активную репликацию. Кроме того, в детерминированных системах баз данных становится ненужной двухфазная фиксация, что снимает преграды на пути наращивания их производительности.
8. Благодарности
Мы чрезвычайно благодарны Филу Бернштейну (Phil Bernstein), Аззе Абузейду (Azza Abouzeid), Эвану Джонсу (Evan P. C. Jones) и Расселу Серсу (Russell Sears) за то, что они прочитали начальные варианты этой статьи и предложили ряд замечаний и исправлений.Описанная работа частично поддерживалась грантом № IIS-0845643 Национального научного фонда США.
9. Литература
[1] C. Basile, Z. Kalbarczyk, and R. K. Iyer. Active replication of multithreaded applications. IEEE Transactions on Parallel and Distributed Systems, 17:448–465, 2006.
[2] P. A. Bernstein, A. Fekete, H. Guo, R. Ramakrishnan, and P. Tamma. Relaxed-currency serializability for middle-tier caching and replication. In Proc. of SIGMOD, pages 599–610, 2006.
[3] P. A. Bernstein and N. Goodman. Timestamp-based algorithms for concurrency control in distributed database systems. In Proc. of VLDB, pages 285–300, 1980.
[4] P. A. Bernstein and N. Goodman. Concurrency control in distributed database systems. ACM Comput. Surv., 13(2):185–221, 1981.
[5] P. A. Bernstein, V. Hadzilacos, and N. Goodman. Concurrency Control and Recovery in Database Systems. Addison-Wesley, 1987.
[6] P. A. Bernstein, D. W. Shipman, and J. B. Rothnie, Jr. Concurrency control in a system for distributed databases (sdd-1). ACM Trans. Database Syst., 5(1):18–51, 1980.
[7] Y. Breitbart, R. Komondoor, R. Rastogi, S. Seshadri, and A. Silberschatz. Update propagation protocols for replicated databates. SIGMOD Rec., 28(2):97–108, 1999.
[8] S. Elnikety, S. Dropsho, and F. Pedone. Tashkent: uniting durability with transaction ordering for high-performance scalable database replication. In Proc. of EuroSys, pages 117–130, 2006.
[9] H. Garcia-Molina and K. Salem. Main memory database systems: An overview. IEEE Transactions on Knowledge and Data Engineering, 4(6), 1992.
[10] J. Gray, P. Helland, P. O’Neil, and D. Shasha. The dangers of replication and a solution. In Proc. of SIGMOD, pages 173–182, 1996.
[11] R. Jimenez-Peris, M. Patino-Martinez, and S. Arevalo. Deterministic scheduling for transactional multithreaded replicas. In Proc. of IEEE Int. Symp. on Reliable Distributed Systems, 2000.
[12] E. P. C. Jones, D. J. Abadi, and S. R. Madden. Low Overhead Concurrency Control for Partitioned Main Memory Databases. In Proc. of SIGMOD, 2010.
Имеется перевод на русский язык: Эван Джонс, Дэниэль Абади и Сэмуэль Мэдден. Управление параллелизмом с низкими накладными расходами для разделенных баз данных в основной памяти, 2010.
[13] B. Kemme and G. Alonso. Don’t be lazy, be consistent: Postgres-r, a new way to implement database replication. In Proc. of VLDB, pages 134–143, 2000.
[14] R. P. King, N. Halim, H. Garcia-Molina, and C. A. Polyzois. Management of a remote backup copy for disaster recovery. ACM Trans. Database Syst., 16(2):338–368, 1991.
[15] K. Krikellas, S. Elnikety, Z. Vagena, and O. Hodson. Strongly consistent replication for a bargain. In ICDE, pages 52–63, 2010.
[16] E. Lau and S. Madden. An integrated approach to recovery and high availability in an updatable, distributed data warehouse. In Proc. of VLDB, pages 703–714, 2006.
[17] E. Pacitti, P. Minet, and E. Simon.Fast algorithms for maintaining replica consistency in lazy master replicated databases. In Proc. VLDB, pages 126–137, 1999.
[18] E. Pacitti, M. T. Ozsu, and C. Coulon. Preventive multi-master replication in a cluster of autonomous databases. In Euro-Par, pages 318–327, 2003.
[19] C. Plattner and G. Alonso. Ganymed: scalable replication for transactional web applications. In Proc. of Middleware, pages 155–174, 2004.
[20] C. A. Polyzois and H. Garcia-Molina. Evaluation of remote backup algorithms for transaction-processing systems. ACM Trans. Database Syst., 19(3):423–449, 1994.
[21] C. A. Polyzois and H. Garcia-Molina. Evaluation of remote backup algorithms for transaction-processing systems. ACM Trans. Database Syst., 19(3):423–449, 1994.
[22] U. Rohm, K. Bohm, H.-J. Schek, and H. Schuldt. Fas: a freshness-sensitive coordination middleware for a cluster of olap components. In Proc. of VLDB, pages 754–765, 2002.
[23] F. Schneider. Implementing fault-tolerant services using the state machine approach: A tutorial. ACM Comput. Surv., 22(4), 1990.
[24] M. Stonebraker, S. R. Madden, D. J. Abadi, S. Harizopoulos, N. Hachem, and P. Helland. The end of an architectural era (it’s time for a complete rewrite). In Proc. of VLDB, 2007.
Имеется перевод на русский язык: Майкл Стоунбрейкер, Сэмюэль Мэдден, Дэниэль Абади, Ставрос Харизопулос, Набил Хачем, Пат Хеллэнд. Конец архитектурной эпохи, или Наступило время полностью переписывать системы управления данными, 2007.
[25] Y. C. Tay, R. Suri, and N. Goodman. A mean value performance model for locking in databases: the no-waiting case. J. ACM, 32(3):618–651, 1985.
[26] A. Whitney, D. Shasha, and S. Apter. High volume transaction processing without concurrency control, two phase commit, SQL or C++. In HPTS, 1997.