Доводы в пользу детерминизма в системах баз данных
Дэниел Абади и Александер Томсон
Перевод: Сергей Кузнецов
3. Доводы в пользу недетерминизма
Прежде чем приводить доводы в пользу запрета недерминированного поведения в системах баз данных, важно заново рассмотреть аргументы в пользу его допущения.Хорошая транзакционная система баз данных должна быть быстрой, гибкой и отказоустойчивой. Особо важной считается способность транзакционных систем обеспечивать высокие уровни изоляции, поддерживая при этом оптимальное использование компьютерных ресурсов. Также желательна поддержка по существу произвольных определяемых пользователями транзакций, представляемых на развитом и выразительном языке запросов.
Исторически решения многих проблем разработки таких систем в очень значительной степени основывались на обсуждавшихся ранее либеральных ограничениях сериализации. Чтобы проиллюстрировать значимость переупорядочивания транзакций для достижения этих целей, рассмотрим гипотетическую транзакционную систему баз данных, работающую под типичной транзакционной рабочей нагрузкой. Когда транзакция поступает в систему, ей назначается поток управления, в котором выполняются операции, составляющие эту транзакцию. В частности, в этом потоке управления запрашиваются нужные блокировки, а при фиксации транзакции накопленные блокировки освобождаются. Предположим, что эта гипотетическая система хорошо спроектирована, что в ней используются безупречная схема управления буферами, эффективный менеджер блокировок, поддерживается высокий уровень локальности, так что хорошо работает кэш. Тогда большинство транзакций выполняется очень быстро, удерживая свои блокировки в течение минимального времени. Конфликты по поводу блокировок возникают редко, и транзакции завершаются после сразу после входа в систему, обеспечивающую отличную пропускную способность.
Теперь предположим, что некоторая транзакция входит в систему, запрашивает некоторые блокировки и по какой-то причине сама блокируется (например, из-за возникновения синхронизационного тупика, из-за обращения к медленному устройству хранения данных или, если наша гипотетическая система баз данных работает на нескольких машинах, из-за потери критического сетевого пакета). Что бы ни привело к такой задержке, в подобной ситуации очень полезно наличие у системы небольшой гибкости. В случае синхронизационного тупика или аппаратного сбоя может оказаться разумным аварийным образом завершить транзакцию и перезапустить ее позже. В других случаях имеется много сценариев, в которых можно значительно повысить уровень использования ресурсов путем изменения порядка следования, которому будет эквивалентно наше (не сериальное) выполнение транзакций. Например, предположим, что наша система получает (в указанном порядке) последовательность из следующих трех транзакций:
T0: read(A); write(B); read(X);Если T0 откладывается при попытке прочитать X, то T1 не получит блокировку по чтению записи B и не сможет продолжать выполняться. В детерминированной системе T2 застрянет вслед за T1 из-за наличия зависимости "чтение-запись" на записи C. Но если мы можем изменить порядок следования, эквивалентность которому будет обеспечиваться, T2 сможет получить требуемую блокировку записи C (поскольку транзакция T1 заблокировалась до того, как запросила блокировку C) и завершить свое выполнение, заняв место перед T0 и T1 в эквивалентном порядке следования. Следовательно, если система требует эквивалентности только некоторому последовательному порядку выполнения, не обязательно тому порядку, в котором транзакции поступают в систему, простаивающие ресурсы можно немедленно начать эффективно использовать для выполнения T2.
T1: read(B); write(C); read(Y);
T2: read(C); write(D); read(Z);
Приведенный пример позволяет немного понять суть класса проблем, с которыми позволяет справиться динамическое переупорядочивание транзакций. Для количественной оценки преимуществ этого подхода мы создали аналитическую модель и выполнили эксперимент, в котором наблюдали эффекты от появления блокированной транзакции в традиционной системе и в системе, основанной на описанной выше детерминированной модели выполнения. Из-за ограничений на объем статьи аналитическая модель представлена только в приложении, но полученные на ее основе результаты согласуются с результатами описываемых здесь экспериментов.
В своем эксперименте мы реализовали простую рабочую нагрузку, в которой каждая транзакция обращается к 10 записям базы данных, содержащей 106 записей. После поиска каждой требуемой записи во вторичном индексе запрашивается ее блокировка, и запись обновляется. Транзакции являются достаточно короткими: по нашим измерениям, блокировки освобождаются примерно через 30 микросекунд после удовлетворения запроса последней из них. Выполнение рабочей нагрузки происходит в благоприятных условиях до тех пор, пока через одну секунду после начала работы в системе не появляется транзакция, которая запрашивает 10 блокировок, после чего полностью блокируется на одну секунду. После этого она активизируется, освобождает свои блокировки и фиксируется. Мы измеряли пропускную способность каждой системы как функцию от времени, а также вероятность того, что новая поступающая в систему транзакция не сможет полностью выполниться из-за конфликта блокировок. При использовании детерминированной схемы все 10 блокировок каждой транзакции запрашиваются сразу после входа транзакции в систему, а в традиционной системе блокировки запрашиваются последовательно, и выполнение транзакции приостанавливается, если очередную блокировку получить не удалось. В традиционной схеме также реализуется выявление тупиковых ситуаций на основе таймаутов: любая транзакция (кроме первой, медленной транзакции), которая не выполняется в течение заданного промежутка времени, аварийно завершается и запускается заново. Подробности об экспериментальной установке см. в приложении.
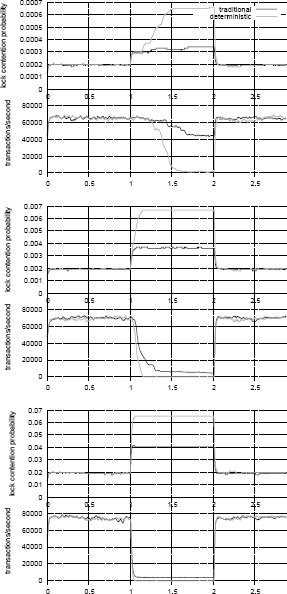
Рис.1. Измеренные вероятность конфликта блокировок и транзакционная пропускная способность за интервал времени в три секунды. Две транзакции конфликтуют с вероятностью 0,01%, 0,1% и 1% соответственно.
На рис. 1 показаны результаты нашего исследования застопоренного поведения при разных вероятностях конфликтов блокировок. На графиках показаны вероятности того, что поступающие транзакции не смогут сразу завершиться, а также общая транзакционная пропускная способность как функция от времени. Отчетливо видны три основных вида поведения:
-
Сравнимая производительность при отсутствии заблокированных транзакций. Пока все транзакции своевременно завершаются, имеются весьма незначительные отличия в производительности детерминированной и недетерминированной схем упорядочивания транзакций (независимо от вероятности конфликтов между их наборами чтения и записи). В действительности, оказывается, что в этом промежутке времени транзакционная система выполняет и фиксирует транзакции почти в том же порядке, что и детерминированная система.
-
Относительная чувствительность к наличию заблокированных транзакций. Когда одна из транзакций приостанавливает свое выполнение на одну секунду, детерминированная система быстро загромождается транзакциями, которые не могут ни завершиться (из-за конфликта блокировок), ни аварийно прекратить свое выполнение и перезапуститься. В традиционных случаях, в которых все блокировки сразу не запрашиваются, и реализуются другие недетерминированные механизмы переупорядочивания транзакций, производительность падает гораздо более плавно. Пологий участок кривой вероятности конфликтов блокировок, который намного быстрее достигается при наличии более высокой вероятности конфликтов двух транзакций, возникает из-за насыщенности системного пула потоков управления блокированными транзакциями.
В обеих системах чувствительность к застопориванию и серьезность его воздействия зависит от вероятности конфликтов транзакций. Во многих современных рабочих нагрузках OLTP эта вероятность невелика.
-
Поведение после исчезновения заблокированных транзакций. Независимо от модели поведения, после того, как приостановленная транзакция наконец-то завершается и освобождает свои блокировки, нагромождение запросов блокировки в менеджере блокировок почти мгновенно рассеивается, и пропускная способность восстанавливается до уровня, который наблюдался в первой фазе эксперимента.
Этот эксперимент ясно показывает, что в случаях, в которых возможны тупики или приостановка транзакций по каким-то другим причинам, схемы выполнения, обеспечивающие эквивалентность некоторому предопределенному порядку следования, непригодны. Следовательно, в эпоху, когда операции чтения с диска произвольным образом влияют на время выполнения транзакций, единственным жизнеспособным вариантом является недетерминированная схема переупорядочивания транзакций.
4. Прототип детерминированной СУБД
Поскольку все большее число транзакционных приложений полностью помещается в основной памяти, аппаратные средства становятся все более быстрыми, дешевыми и надежными, а в рабочих нагрузках OLTP все более преобладают короткие, четко организованные транзакции, реализуемые на основе хранимых процедур, мы предвидим все более редкое появление сценариев, вызывающих загромождение детерминированных систем. В пользу детерминированных систем также говорят следующие простые наблюдения:- Использование преимуществ согласованной активной репликации. Механизмы мгновенного преодоления отказов (failover) систем баз данных с активной репликацией могут радикально сократить воздействие отказов аппаратуры внутри системы, содержащей реплику. Сильно реплицированные системы могут также помочь скрыть падение производительности, затрагивающее только часть реплик.
- Распределенные запросы только по чтению. Запросы только по чтению требуется направлять только в одну реплику. В качестве варианта, более продолжительные запросы только по чтению часто можно расщепить по нескольким репликам для сокращения задержки, балансировки нагрузки и уменьшения эффекта загромождения, которое могло бы возникнуть, если бы запрос целиком выполнялся над одной репликой. Конечно, долговременные запросы только по чтению все чаще избегаются разработчиками сегодняшних транзакционных приложений – вместо этого они направляются в хранилища данных.
4.1. Архитектура системы
Наш прототип детерминированной системы баз данных состоит из препроцессора поступающих транзакций, объединенного с произвольным числом систем, хранящих реплики базы данных (рис. 2).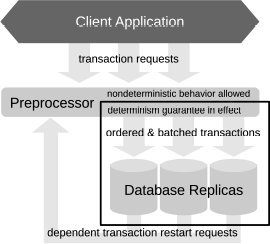
Рис.2. Архитектура детерминированной СУБД.
Препроцессор является границей внутренней детерминированной вселенной системы. Он принимает запросы на образование транзакций, упорядочивает их и заранее выполняет всю необходимую недерминированную работу (например, обрабатывает вызовы sys.random() и time.now, содержащиеся в коде транзакции), передавая свои результаты в качестве аргументов транзакции. Затем запросы на образование транзакции объединяются в пакет и синхронно записываются на диск, что гарантирует долговечность. В этот важнейший момент система берет на себя обязательство выполнить все зарегистрированные транзакции, и после этого все выполнение должно производиться в соответствии с выбранным порядком. Наконец, все собранные в пакет запросы на образование транзакции широковещательным образом отправляются во все системы, содержащие реплики базы данных, с использованием надежного, вполне упорядоченного коммуникационного уровня.
Каждая система, содержащая реплику базы данных, может включать одну машину или разделять данные между несколькими машинами. В любом случае, в ней должна быть реализована модель выполнения, гарантирующая отсутствие синхронизационных тупиков и эквивалентность порядку следования транзакций, заданному препроцессором. Разделенный вариант более подробно обсуждается в разд. 5.
При отказе системы, содержащей реплику базы данных, восстановление в нашей системе производится путем копирования базы данных из какой-либо работоспособной реплики. Возможны и другие схемы (например, повторное выполнение транзакций из долговечного списка транзакций препроцессора), лишь бы только схема восстановления соблюдала инвариант детерменизма.
4.2. Трудные классы транзакций
Не для всех транзакций можно запросить блокировки всех записей, к которым в ней будут происходить обращения, сразу после поступления транзакции в систему. Рассмотрим транзакцию
U(x):
y ← read(x)
write(y)
где x является первичным ключом записи, y – локальная переменная, и write(y) обновляет запись, первичный ключ которой содержится в y.
Очевидно, что для транзакций типа U невозможно запросить блокировки сразу после входа в систему (если только не заблокировать целиком таблицу, связанную с y), поскольку механизм исполнения никаким образом не может определить значение y, не выполнив до этого чтение записи x. Мы называем такие транзакции зависимыми транзакциями (dependent transactions). В нашей схеме проблема зависимых транзакций решается путем их разбиения на несколько транзакций, из которых все транзакции, кроме последней, работают с целью обнаружения полного набора чтения/записи, так что последняя транзакция может начать свое выполнение при наличии полного знания о том, к чему она будет обращаться. Например, транзакцию U можно разбить на транзакции:
U1(x):
y ← read(x)
newtxnrequest(U2(x, y))
и
U2(x, y):
y' ← read(x)
if (y' ≠ y)
newtxnrequest(U2(x, y'))
abort()
else
write(y)
U2 не включается в упорядоченные пакеты транзакций, направляемые препроцессором в системы, которые содержат реплики, до тех пор, пока в препроцессор не поступит результат U1 (в этот промежуток времени может выполняться произвольное число транзакций). В U2 имеется некоторая информация о том, что, вероятно, следует заблокировать, и соответствующие элементы данных немедленно блокируются. После этого U2 проверяет, что заблокированы корректные элементы данных (т.е. что никакая транзакция, выполнявшаяся в промежуток времени между завершением выполнения U1 и началом выполнения U2 не изменила зависимость). Если эта проверка удается, то выполнение U2 может продолжаться. Иначе U2 должна завершиться аварийным образом (и освободить свои блокировки). Препроцессор оповещается об этом аварийном завершении и снова включает U2 в следующий пакет транзакций, направляемый в системы с репликами базы данных. Заметим, что все действия "аварийно завершить и сделать новую попытку" являются детерминированными (в промежутке времени между завершением выполнения U1 и началом выполнения U2 над всеми репликами будут выполняться одни и те же транзакции, и, поскольку повторная попытка выполнить U2 после ее аварийного завершения делается препроцессором, все последующие действия "аварийно завершить и сделать новую попытку" также являются детерминированными).
Поскольку для разбиения U требуется всего одна дополнительная транзакция, вычисляющая полный набор чтения/записи, мы называем U зависимой транзакцией первого порядка. Зависимые транзакции первого порядка часто встречаются в рабочих нагрузках OLTP в виде последовательности "индексный поиск – доступ к записи". Зависимые транзакции более высокого порядка, такие как следующая зависимая транзакция второго порядка:
V(x):
y ← read(x)
z ← read(y)
write(z)
в реальных рабочих нагрузках встречаются гораздо реже, но тот же самый метод разбиения позволяет справиться с обработкой зависимых транзакций произвольного порядка.
Принцип работы этого метода похож на принцип оптимистического управления параллелизмом (optimistic concurrency control, OCC), и так же, как в в OCC, при выполнении декомпозированных зависимых транзакций имеется риск "зависания" (starvation), если их зависимости будут часто изменяться в промежутках между выполнением декомпозированных частей.
Чтобы лучше понять применимость и стоимость этого метода разбиения, мы выполнили ряд экспериментов и подкрепили их исследованиями на основе аналитической модели. Детали экспериментов и описание модели содержатся в приложении. Мы установили, что производительность при наличии рабочих нагрузок, насыщенных зависимыми транзакциями первого порядка, обратно пропорциональна интенсивности обновлений зависимостей декомпозированных транзакций. Например, при наличии рабочей нагрузки, состоящей из транзакций Payment из тестового набора TPC-C (в которых вместо первичного ключа часто задается имя заказчика, что делает необходимым индексный поиск), пропускная способность заметным образом пострадает только в том случае, если имя каждого заказчика будет обновляться исключительно часто – сотни или даже тысячи раз в секунду. Накладные расходы, вызываемые добавлением читающей транзакции, которая устанавливает зависимость, почти совсем незаметны. Поскольку в реальных рабочих нагрузках OLTP редко встречаются зависимости по часто обновляемым данным (например, над изменчивыми данными обычно не создаются вторичные индексы), мы заключаем, что наличие рабочих нагрузок с большим числом зависимостей не может служить основанием для отказа от детерминированной схемы управления параллелизмом.
Эта схема также хорошо встраивается в среды систем баз данных, позволяющие пользователям регулировать уровни изоляции своих транзакций для повышения производительности. Возможна простая оптимизация, приводящая к тому, что зависимые чтения будут выполняться на уровне изоляции чтения зафиксированных данных (read-committed) (а не на уровне изоляции полной сериализуемости (serializable)). Тогда зависимая транзакция будет по-прежнему разбиваться на две транзакции, но во второй транзакции больше не потребуется проверять, что ранее прочитанные данные по-прежнему являются точными. Тем самым, эта проверка (и потенциальное аварийное завершение транзакции) устраняется. Заметим, что в системах баз данных, основанных на традиционной двухфазной блокировке, также приходится бороться с высокой интенсивностью конфликтов, которые свойственны рабочим нагрузкам, насыщенным долговременными запросами только на чтение, и что во многих таких системах уже поддерживается выполнение транзакций на более низких уровнях изоляции3. Мы предвидим, что разработчикам приложений, предупрежденным о том, что производительность выполнения зависимых транзакций может быть повышена, если эти транзакции выполняются на более низком уровне изоляции, понадобится некоторый период времени для "выяснения отношений" с детерминированной системой баз данных.
3 В системах, основанных на поддержке версий (multiversion) и мгновенных снимков (snapshot), запросы только на чтение не порождают проблем, но этот подход ортогонален подходу, описываемому в данной статье, поскольку возможны версионные реализации детеминированных систем баз данных.