|

Книги: [Классика] [Базы данных] [Internet/WWW] [Сети] [Программирование] [UNIX] [Windows] [Безопасность] [Графика] [Software Engineering] [ERP-системы] [Hardware]
Отрывок
6.2. Шина PCI
PCI (Peripheral Component Interconnect) local bus — шина соединения периферийных компонентов является основной шиной расширения современных компьютеров. Она разрабатывалась в расчете на Pentium, но хорошо сочеталась и с процессорами 486. Сейчас PCI является четко стандартизованной высокопроизводительной и надежной шиной расширения. Первая версия PCI 1.0 появилась в 1992 г. В PCI 2.0 (1993 г.) введена спецификация коннекторов и карт расширения. В версии 2.1 (1995 г.) введена частота 66 МГц. В настоящее время действует спецификация PCI 2.2 (декабрь 1998 г.), которая уточняет и разъясняет некоторые положения предшествующей версии 2.1. Данное описание основано на тексте стандарта «PCI Local Bus Specification. Revision 2.2» от 18.12.1998, опубликованного организацией PCI SIG (Special Interest Group).
Поначалу шина PCI вводилась как пристройка (mezzanine bus) к системам с основной шиной ISA, став позже центральной шиной: она соединяется с системной шиной процессора высокопроизводительным мостом («северным»), входящим в состав чипсета системной платы. Остальные шины расширения ввода-вывода (ISA/EISA или MCA), а также локальная ISA-подобная шина X-BUS и интерфейс LPC, к которым подключаются микросхемы системной платы (ROM BIOS, контроллеры прерываний, клавиатуры, DMA, портов COM и LPT, НГМД и прочие «мелочи»), подключаются к шине PCI через «южный» мост. В современных системных платах с хабовой архитектурой шину PCI отодвинули на периферию, не ущемляя ее в мощности канала связи с процессором и памятью, но и не нагружая транзитным трафиком устройств других шин.
Шина является синхронной — фиксация всех сигналов выполняется по положительному перепаду (фронту) сигнала CLK. Номинальной частотой синхронизации считается 33 МГц, при необходимости частота может быть понижена (на машинах с процессором 486 использовали частоты 20–33 МГц). Во многих случаях частоту успешно разгоняют и до 41,5 МГц (половина типовой частоты системной шины 83 МГц). Начиная с версии 2.1 допускается повышение частоты до 66 МГц при согласии всех устройств на шине.
Номинальная разрядность шины данных — 32 бита, спецификация определяет и расширение разрядности до 64 бит. При частоте шины 33 МГц теоретическая пропускная способность достигает 132 Mбайт/с для 32-битной шины и 264 Мбайт/с для 64-битной; при частоте синхронизации 66 МГц — 264 и 528 соответственно. Однако эти пиковые значения достигаются лишь во время передачи пакета, а из-за протокольных накладных расходов реальная средняя суммарная (для всех задатчиков) пропускная способность шины оказывается ниже.
С устройствами PCI процессор может взаимодействовать командами обращения к памяти и портам ввода-вывода, адресованным к областям, выделенным каждому такому устройству при конфигурировании. Устройства могут вырабатывать запросы маскируемых и немаскируемых прерываний. Понятия каналов DMA для шины PCI нет, но агент шины может сам выступать в роли задатчика, поддерживая высокопроизводительный обмен с памятью (и не только), не занимая ресурсов центрального процессора. Таким образом, к примеру, может быть реализован обмен в режиме DMA с устройствами ATA, подключенными к контролеру PCI IDE (см. п. 9.2.1). Спецификация PCI требует от устройств способности перемещать все занимаемые ресурсы в пределах доступного пространства адресации. Это позволяет обеспечивать бесконфликтное распределение ресурсов для многих устройств (функций). Для управления устройствами рекомендуется вместо портов ввода-вывода по возможности использовать ячейки памяти. Одно и то же функциональное устройство может быть сконфигурировано по-разному, отображая свои регистры либо на пространство памяти, либо на пространство ввода-вывода. Драйвер может определить текущую настройку, прочитав содержимое регистра базового адреса устройства, — признаком пространства ввода-вывода будет единичное значение бита 0 (см. п. 6.2.12). Драйвер также может определить и номер запроса прерывания, который используется устройством.
6.2.1. Адресация устройств PCI
Для шины PCI принята иерархия понятий адресации: шина, устройство, функция. Эти понятия фигурируют только при обращении к регистрам конфигурационного пространства (см. п. 6.2.12). К этим регистрам обращаются на этапе конфигурирования — переучета обнаруженных устройств, выделения им непересекающихся ресурсов (областей памяти и пространства ввода-вывода) и назначения номеров аппаратных прерываний. При дальнейшей регулярной работе устройства будут отзываться на обращения по назначенным им адресам памяти и ввода-вывода, доведенным до сведения связанных с ними модулей ПО. Эти адреса принимаются с шины AD в начале каждой транзакции. Для доступа к конфигурационному пространству используются отдельные линии IDSEL.
Устройством PCI называется микросхема или карта расширения, подключенная к одной из шин PCI и использующая для идентификации выделенную ей линию IDSEL, принадлежащую этой шине. Устройство может быть многофункциональным, то есть состоять из множества (от 1 до 8) так называемых функций. Каждой функции отводится конфигурационное пространство в 256 байт (см. п. 6.2.12). Многофункциональные устройства должны отзываться только на конфигурационные циклы с номерами функций, для которых имеется конфигурационное пространство. При этом функция с номером 0 должна быть обязательно, номера остальных функций назначаются разработчиком устройства произвольно (в диапазоне 1–7). Простые (однофункциональные) устройства, в зависимости от реализации, могут отзываться либо на любой номер функции, либо только на номер функции 0.
Шина PCI — набор сигнальных линий (см. п. 6.2.2), непосредственно соединяющих интерфейсные выводы группы устройств (слотов, микросхем на системной плате). В системе может присутствовать несколько шин PCI, соединенных мостами PCI (см. п. 6.2.10). Мосты электрически отделяют интерфейсные сигналы одной шины от другой, соединяя их логически; главный мост соединяет главную шину с ядром системы (процессором и памятью). Каждая шина имеет свой номер шины (PCI bus number). Шины нумеруются последовательно; главная шина имеет нулевой номер.
С точки зрения конфигурирования, минимальной адресуемой единицей этой иерархии является функция; ее полный адрес состоит из трех частей: номера шины, номера устройства и номера функции. Короткая форма идентификации вида PCI0:1:2 (например, в сообщениях ОС Unix) означает функцию 2 устройства 1, подключенного к главной (0) шине PCI.
В шине PCI принята географическая адресация — номер устройства определяется местом его подключения. Номер устройства (device number или dev) определяется той линией шины AD, к которой подключена линия сигнала IDSEL данного слота: к AD11 — dev0 (мост), AD12 — dev1, ... AD31 — dev20. В соседних слотах PCI, как правило, задействуются соседние номера устройств; их нумерация определяется разработчиком системной платы (или пассивной кросс-платы в промышленных компьютерах). Часто для слотов используются убывающие номера устройств, начиная с 20. Группы соседних слотов могут подключаться к разным шинам; на каждой шине PCI нумерация устройств независимая (могут быть и устройства с совпадающими номерами dev, но разными номерами шин). Устройства PCI, интегрированные в системную плату, используют ту же систему адресации. Их номера «запаяны намертво», в то время как адреса карт расширения можно изменять перестановкой их в разные слоты.
Одна карта PCI может содержать только одно устройство шины, к которой она подключается, поскольку ей в слоте выделяется только одна линия IDSEL. Если на карте размещают несколько устройств (например, 4-портовая карта Ethernet), то на ней приходится устанавливать мост — тоже устройство PCI, к которому и обращаются по линии IDSEL, выделенной данной карте. Этот мост организует на карте дополнительную шину PCI, к которой можно подключить множество устройств.
С точки зрения обращения к пространствам памяти и ввода-вывода, географический адрес (номер шины и устройства) безразличен (не принимая во внимание разницу в производительности, связанную с подключением устройств к разным шинам PCI). Однако номер устройства определяет номер линии запроса прерывания, которой может пользоваться устройство. Подробнее об этом см. в п. 6.2.6, здесь же отметим, что на одной шине устройства с номерами, отличающимися друг от друга на 4, будут использовать одну и ту же линию прерывания. Возможность развести их по разным линиям прерывания может появиться лишь, если они находятся на разных шинах (это зависит от системной платы).
Разобраться с нумерацией устройств и полученных ими линий прерываний на конкретной плате можно просто: устанавливать одну карту PCI поочередно в каждый из слотов (отключая питание) и смотреть на сообщения об обнаруженных устройствах PCI, выводимых на дисплей в конце теста POST. В этих сообщениях будут фигурировать и устройства PCI, установленные непосредственно на системной плате (и не отключенные параметрами CMOS Setup).
Но чтобы не было иллюзий простоты и прозрачности, отметим, что «особо умные» операционные системы (Windows) не довольствуются полученными назначениями номеров прерываний и изменяют их по своему усмотрению (что никак не может отразиться на разделяемости линий).
6.2.2. Протокол шины PCI
В каждой транзакции (обмене по шине) участвуют два устройства — инициатор (initiator) обмена, он же ведущее (master) устройство, и целевое (target) устройство (ЦУ), оно же ведомое (slave). Шина PCI все транзакции трактует как пакетные: каждая транзакция начинается фазой адреса, за которой может следовать одна или несколько фаз данных. Состав и назначение интерфейсных сигналов шины приведены в табл. 6.11.
Таблица 6.11. Сигналы шины PCI
| Сигнал | Назначение
| | AD[31:0] | Address/Data — мультиплексированная шина адреса/данных. В начале транзакции передается адрес, в последующих тактах — данные
| | C/BE[3:0]# | Command/Byte Enable — команда/разрешение обращения к байтам. Команда, определяющая тип очередного цикла шины, задается четырехбитным кодом в фазе адреса
| | FRAME# | Кадр. Введением сигнала отмечается начало транзакции (фаза адреса), снятие сигнала указывает на то, что последующий цикл передачи данных является последним в транзакции
| | DEVSEL# | Device Select — устройство выбрано (ответ ЦУ на адресованную к нему транзакцию)
| | IRDY# | Initiator Ready — готовность ведущего устройства к обмену данными
| | TRDY# | Target Ready — готовность ЦУ к обмену данными
| | STOP# | Запрос ЦУ к ведущему устройству на остановку текущей транзакции
| | LOCK# | Сигнал захвата шины для обеспечения целостного выполнения операции. Используется мостом, которому для выполнения одной операции требуется выполнить несколько транзакций PCI
| | REQ# | Request — запрос от ведущего устройства на захват шины
| | GNT# | Grant — предоставление ведущему устройству управления шиной
| | PAR | Parity — общий бит паритета для линий AD[31:0] и C/BE[3:0]#
| | PERR# | Parity Error — сигнал об ошибке паритета (для всех циклов, кроме специальных). Вырабатывается любым устройством, обнаружившим ошибку
| | PME# | Power Management Event — сигнал о событиях, вызывающих изменение режима потребления (дополнительный сигнал, введенный в PCI 2.2)
| | CLKRUN# | Clock running — шина работает на номинальной частоте синхронизации. Снятие сигнала означает замедление или остановку синхронизации с целью снижения потребления (для мобильных применений)
| | PRSNT[1,2]# | Present — индикаторы присутствия платы, кодирующие запрос потребляемой мощности. На карте расширения одна или две линии индикаторов соединяются с шиной GND, что воспринимается системной платой
| | RST# | Reset — сброс всех регистров в начальное состояние
| | IDSEL | Initialization Device Select — выбор устройства в циклах конфигурационного считывания и записи
| | SERR# | System Error — системная ошибка. Ошибка паритета адреса данных в специальном цикле или иная катастрофическая ошибка, обнаруженная устройством. Активизируется любым устройством PCI и вызывает NMI
| | REQ64# | Request 64 bit — запрос на 64-битный обмен. Сигнал вводится 64-битным инициатором, по времени он совпадает с сигналом FRAME#. Во время окончания сброса (сигналом RST#) сигнализирует 64-битному устройству о том, что оно подключено к 64-битной шине. Если 64-битное устройство не обнаружит этого сигнала, оно должно переконфигурироваться на 32-битный режим, отключив буферные схемы старших байтов
| | ACK64# | Подтверждение 64-битного обмена. Сигнал вводится 64-битным ЦУ, опознавшим свой адрес, одновременно с DEVSEL#. Отсутствие этого подтверждения заставит инициатор выполнять обмен с 32-битной разрядностью
| | INTA#, INTB#, | Interrupt A, B, C, D — линии запросов прерывания, чувствительность к уровню,
| | INTC#, INTD# | активный уровень — низкий, что допускает разделяемость (совместное использование) линий
| | CLK | Clock — тактовая частота шины. Должна лежать в пределах 20—33 МГц, в PCI 2.1 — до 66 МГц
| | M66EN | 66MHz Enable — разрешение частоты синхронизации до 66 МГц
| | SDONE | Snoop Done — сигнал завершенности цикла слежения для текущей транзакции. Низкий уровень указывает на незавершенность цикла слежения за когерентностью памяти и кэша. Необязательный сигнал, используется только устройствами шины с кэшируемой памятью
| | SBO# | Snoop Backoff — попадание текущего обращения к памяти абонента шины в модифицированную строку кэша. Необязательный сигнал, используется только абонентами шины с кэшируемой памятью при алгоритме обратной записи
| | TCK | Test Clock — синхронизация тестового интерфейса JTAG
| | TDI | Test Data Input — входные данные тестового интерфейса JTAG
| | TDO | Test Data Output — выходные данные тестового интерфейса JTAG
| | TMS | Test Mode Select — выбор режима для тестового интерфейса JTAG
| | TRST | Test Logic Reset — сброс тестовой логики
|
В каждый момент времени шиной может управлять только одно ведущее устройство, получившее на это право от арбитра. Каждое ведущее устройство имеет пару сигналов — REQ# для запроса на управление шиной и GNT# для подтверждения предоставления управления шиной. Устройство может начинать транзакцию (устанавливать сигнал FRAME#) только при активном полученном сигнале GNT#. Снятие сигнала GNT# не позволяет устройству начать следующую транзакцию, а при определенных условиях (см. ниже) заставляет прекратить начатую транзакцию. Арбитражем запросов на использование шины занимается специальный узел, входящий в чипсет системной платы. Схема приоритетов (фиксированный, циклический, комбинированный) определяется программированием арбитра.
Для адреса и данных используются общие мультиплексированные линии AD. Четыре мультиплексированные линии C/BE[3:0] обеспечивают кодирование команд в фазе адреса и разрешения байт в фазе данных. В начале транзакции ведущее устройство активизирует сигнал FRAME#, по шине AD передает целевой адрес, а по линиям C/BE# — информацию о типе транзакции (команде). Адресованное ЦУ отзывается сигналом DEVSEL#. Ведущее устройство указывает на свою готовность к обмену данными сигналом IRDY#, эта готовность может быть выставлена и раньше получения DEVSEL#. Когда к обмену данными будет готово и ЦУ, оно установит сигнал TRDY#. Данные по шине AD передаются только при одновременном наличии сигналов IRDY# и TRDY#. С помощью этих сигналов ведущее устройство и ЦУ согласуют свои скорости, вводя такты ожидания. На рис. 6.7 приведена временная диаграмма обмена, в которой и ведущее устройство, и ЦУ вводят такты ожидания. Если бы они оба ввели сигналы готовности в конце фазы адреса и не снимали их до конца обмена, то в каждом такте после фазы адреса передавались бы по 32 бита данных, что обеспечило бы выход на предельную производительность обмена.
Количество фаз данных в пакете явно не указывается, но перед последней фазой данных ведущее устройство при введенном сигнале IRDY# снимает сигнал FRAME#. В одиночных транзакциях сигнал FRAME# активен лишь один такт. Если устройство не поддерживает пакетные транзакции в ведомом режиме, то оно должно потребовать прекращения пакетной транзакции во время первой фазы данных (введя сигнал STOP# одновременно с TRDY#). В ответ на это ведущее устройство завершит данную транзакцию и продолжит обмен последующей транзакцией с новым значением адреса. После последней фазы данных ведущее устройство снимает сигнал IRDY#, и шина переходит в состояние покоя (PCI Idle) — оба сигнала FRAME# и IRDY# находятся в пассивном состоянии. Инициатор может начать следующую транзакцию и без такта покоя, введя FRAME# одновременно со снятием IRDY#. Такие быстрые смежные транзакции (Fast Back-to-Back) могут быть обращены как к одному, так и к разным ЦУ. Первый тип поддерживается всеми устройствами PCI, выступающими в роли ЦУ. На поддержку второго типа (она необязательна) указывает бит 7 регистра состояния (см. п. 6.2.12). Инициатору разрешают (если он умеет) использовать быстрые смежные транзакции с разными устройствами (битом 9 регистра команд), только если все агенты шины допускают быстрые обращения.
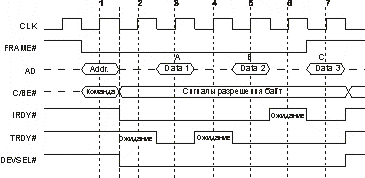
Рис. 6.7. Цикл обмена на шине PCI
Шина позволяет уменьшить мощность (ток), потребляемую устройствами, ценой снижения производительности, применяя пошаговое переключение линий AD[31:0] и PAR (address/data stepping). Здесь возможны два варианта.
Плавный шаг (continuous stepping) — начало формирования сигналов слаботочными формирователями за несколько тактов до введения сигнала-квалификатора действительной информации (FRAME# в фазе адреса, IRDY# или TRDY# в фазе данных). За эти несколько тактов сигналы «доползут» до требуемого значения при меньшем токе.
Дискретный шаг (diskrete stepping) — нормальные формирователи срабатывают не все сразу, а группами (например, побайтно), в каждом такте по группе. При этом снижаются броски тока, поскольку одновременно переключается меньше формирователей.
Устройство само может и не пользоваться этими возможностями (см. бит 7 регистра команд), но должно «понимать» такие циклы. Задерживая сигнал FRAME#, устройство рискует потерять право доступа к шине, если арбитр получит запрос от более приоритетного устройства.
Протокол квитирования обеспечивает надежность обмена — ведущее устройство всегда получает информацию об отработке транзакции ЦУ. Средством повышения надежности (достоверности) является применение контроля паритета: линии AD[31:0] и C/BE[3:0]# и в фазе адреса, и в фазе данных защищены битом паритета PAR (количество единичных бит этих линий, включая PAR, должно быть четным). Действительное значение PAR появляется на шине с задержкой в один такт относительно линий AD и C/BE#. При обнаружении ошибки ЦУ вырабатывается сигнал PERR# (со сдвигом на такт после действительности бита паритета). В подсчете паритета при передаче данных учитываются все байты, включая и недействительные (отмеченные высоким уровнем сигнала C/BEx#). Состояние бит, даже и в недействительных байтах данных, во время фазы данных должно оставаться стабильным.
Каждая транзакция на шине должна быть завершена планово или прекращена, при этом шина должна перейти в состояние покоя (сигналы FRAME# и IRDY# пассивны). Завершение транзакции выполняется либо по инициативе ведущего устройства, либо по инициативе ПУ.
Ведущее устройство может завершить транзакцию одним из следующих способов.
Нормальное завершение (Comletion) выполняется по окончании обмена данными.
Завершение по тайм-ауту (Time-out) происходит, когда во время транзакции у ведущего устройства отбирают право на управление шиной (снятием сигнала GNT#) и истекает время, указанное в его таймере Latency Timer. Это может случиться, если адресованное ЦУ оказалось непредвиденно медленным или запланирована слишком длинная транзакция. Короткие транзакции (с одной-двумя фазами данных) даже в случае снятия сигнала GNT# и срабатывания таймера завершаются нормально.
Транзакция отвергается (Master-Abort), когда в течение заданного времени ведущее устройство не получает ответа ЦУ (DEVSEL#).
Транзакция может быть прекращена по инициативе ЦУ; для этого оно может ввести сигнал STOP#. Возможны три типа прекращения.
Повтор (Retry) — сигнал STOP# вводится при пассивном сигнале TRDY# до первой фазы данных. Эта ситуация возникает, когда ЦУ из-за внутренней занятости не успевает выдать первые данные в положенный срок (16 тактов). Повтор является указанием ведущему устройству на необходимость нового запуска той же транзакции.
Отключение (Disconnect) — сигнал STOP# вводится во время или после первой фазы данных. Если сигнал STOP# введен при активном сигнале TRDY# очередной фазы данных, то эти данные передаются и на том транзакция завершается. Если сигнал STOP# введен при пассивном сигнале TRDY#, то транзакция завершается без передачи данных очередной фазы. Отключение производится, когда ЦУ неспособно своевременно выдать или принять очередную порцию данных пакета.
Отказ (Target-Abort) — сигнал STOP# вводится одновременно со снятием сигнала DEVSEL# (в предыдущих случаях во время появление сигнала STOP# сигнал DEVSEL# был активен). После этого данные уже не передаются. Отказ вводится, когда ЦУ обнаруживает фатальную ошибку или иные условия, по которым оно уже никак не сможет обслужить данный запрос.
Использование трех типов прекращения вовсе не обязательно для всех ЦУ, однако любое ведущее устройство должно быть готово к завершению транзакций по любой из этих причин.
6.2.3. Команды шины, адресация памяти и ввода-вывода
Работа шины контролируется несколькими таймерами, не позволяющими попусту расходовать такты шины и планировать распределение полосы пропускания.
Каждое ЦУ должно достаточно быстро отвечать на адресованную ему транзакцию. Задержка первой фазы данных (target initial latency), то есть задержка появления сигнала TRDY# относительно FRAME#, не должна превышать 16 тактов шины. Если устройство по своей природе иногда может не успевать уложиться в этот интервал, оно должно формировать сигнал STOP#, прекращая транзакцию. Это заставит ведущее устройство повторить транзакцию, и с большой вероятностью эта попытка окажется успешной. Если устройство медленное и часто не укладывается в 16 тактов, то оно должно откладывать транзакцию (Delayed Transaction). Кроме того, ЦУ имеет инкрементный механизм слежения за длительностью циклов (Incremental Latency Mechanism), который не позволяет интервалу между соседними фазами данных в пакете (target subsequent latency) превышать 8 тактов шины. Если ЦУ не успевает работать в таком темпе, оно обязано остановить транзакцию. Желательно, чтобы устройство сообщало о своем «неуспевании» как можно раньше, не выжидая предельных 16 или 8 тактов, — это экономит полосу пропускания шины.
Инициатор тоже не должен задерживать поток — допустимая задержка от начала FRAME# до сигнала IRDY# (master data latency) и между фазами данных не должна превышать 8 тактов. Если ЦУ время от времени отвергает операцию записи в память с запросом повтора (это, к примеру, может происходить при записи в видеопамять), то есть «предел терпения» для завершения операции. Таймер максимального времени исполнения (maximum complete time) имеет порог 10 мкс — 334 такта при 33 МГц или 668 тактов на 66 МГц, за которое инициатор должен иметь возможность «протолкнуть» хоть одну фазу данных. Таймер начинает отсчет с момента запроса повтора операции записи в память и сбрасывается при последующем завершении транзакции записи в память, отличном от запроса повтора. Устройства, не способные выдерживать ограничение на максимальное время исполнения записи в память, должны предоставлять драйверу возможность определять их состояние, в котором достаточно быстрая запись в память невозможна. Драйвер, естественно, должен учитывать это состояние и не «напрягать» шину и устройство бесплодными попытками записи.
Каждое ведущее устройство, способное сформировать пакет с более чем двумя фазами данных, должно иметь собственный программируемый таймер задержки (Latency Timer), регулирующий поведение ведущего устройства, когда у него отбирают право управления шиной. Таймер запускается по каждому сигналу FRAME#, введенному этим ведущим устройством. Поведение ведущего устройства по достижении порога зависит от типа команды и состояния сигналов FRAME# и GNT# на момент срабатывания таймера.
Если ведущее устройство снимает сигнал FRAME# до срабатывания таймера, транзакция завершается нормально.
Если сигнал GNT# снят и исполняемая команда не является записью памяти с инвалидацией, то инициатор обязан сократить транзакцию, сняв сигнал FRAME#. При этом ему позволяется завершить текущую и выполнить еще одну фазу данных.
Если сигнал GNT# снят и исполняется запись в память с инвалидацией, то инициатор должен завершить транзакцию по концу текущей (если передается не последнее двойное слово строки) или следующей (если двойное слово — последнее) строки кэша.
Задержка арбитража (arbitration latency) определяется как число тактов от подачи инициатором запроса REQ# до получения права управления шиной GNT#. Эта задержка зависит от активности других инициаторов, быстродействия устройств (чем меньше они вводят тактов ожидания, тем лучше) и «проворности» собственно арбитра. В зависимости от исполняемой команды и состояния сигналов ведущее устройство должно либо сократить транзакцию, либо продолжать ее до запланированного завершения.
При конфигурировании ведущие устройства сообщают свои потребности, указывая максимально допустимую задержку предоставления доступа к шине (Max_Lat) и минимальное время, на которое им должно предоставляться управление шиной (Min_GNT). Эти потребности определяются присущим устройству темпом передачи данных и его организацией.
Для максимального использования возможностей шины устройства должны иметь буферы, чтобы накапливать в них данные для пакетных транзакций. Рекомендуется для устройств со скоростью передачи данных до 5 Мбайт/с иметь буфер, по крайней мере, на 4 двойных слова. Для более высоких скоростей рекомендуется буфер на 32 двойных слова. Для обмена с системной памятью наиболее эффективны транзакции, работающие с целыми строками кэша, что тоже учитывают при определении размера буфера. Однако увеличение размера буфера может вызвать трудности при обработке ошибок, а также вести к увеличению задержек доставки данных (пока устройство не заполнит определенный объем буфера, оно не начнет передачу этих данных по шине, и их потребители будут ожидать).
В спецификации приводится пример организации карты Fast Ethernet (скорость передачи — 10 Мбайт/с), у которой для каждого направления передачи имеется 64-байтный буфер, поделенный на две половины. Когда адаптер заполняет одну половину буфера приходящим кадром, он выводит в память накопленное содержимое другой половины, после чего они меняются местами. Каждая половина выводится в память за 8 фаз данных (около 0,25 мкс на частоте 33 МГц), что соответствует установке MIN_GNT=1. При скорости прихода данных 10 Мбайт/с каждая половина заполняется за 3,2 мкс, что соответствует установке MAX_LAT=12 (здесь время задается в интервалах по 0,25 мкс).
6.2.4. Таймеры, задержки и буферы
В каждой команде шины указывается адрес данных, передаваемых в первой фазе данных пакета. Адрес для каждой последующей фазы данных пакета увеличиваветствует установке MAX_LAT=12 (здесь время задается в интервалах по 0,25 мкс).
6.2.4. Таймеры, задержки и буферы
В каждой команде шины указывается адрес данных, передаваемых в первой фазе данных пакета. Адрес для каждой последующей фазы данных пакета увеличивается на 4 (следующее двойное слово), но в командах обращения к памяти порядок может быть иным (см. ниже). Байты шины AD, несущие действительную информацию, выбираются сигналами C/BE[3:0]# в фазах данных. Внутри пакета эти сигналы могут менять состояние от фазы к фазе произвольным образом. Разрешенные байты могут быть разрозненными; возможны фазы данных, в которых не разрешено ни одного байта. В отличие от шины ISA, на PCI нет динамического изменения разрядности — все устройства должны подключаться к шине 32-разрядным способом. Если в устройстве PCI применяются функциональные схемы иной разрядности (к примеру, нужно подключить микросхему 8255, имеющую 8-битную шину данных и четыре регистра), то приходится принимать схемотехнические методы преобразования, отображающие все регистры на 32-разрядную шину AD.
Адресация памяти, портов и конфигурационных регистров различна.
В циклах обращения к памяти адрес, выровненный по границе двойного слова, передается по линиям AD[31:2]; линии AD[1:0] задают порядок адресов в пакете:
00 — линейное инкрементирование; адрес последующей фазы отличается от предыдущего на число байтов шины (4 для 32-битной и 8 для 64-битной шины).
10 — Cacheline Wrap mode, сворачивание адресов с учетом длины строки кэш-памяти. В транзакции адрес для очередной фазы увеличивается до достижения границы строки кэша, после чего переходит на начало этой строки и увеличивается до адреса, предшествующего начальному. Если транзакция длиннее строки кэша, то она продолжится в следующей строке с того же смещения, что и началась. Так, при длине строки 16 байт и 32-битной шине транзакция, начавшаяся с адреса xxxxxx08h, будет иметь последующие фазы данных, относящиеся к адресам xxxxxx0Ch, xxxxxx00h, xxxxxx04h; и далее к xxxxxx18h, xxxxxx1Ch, xxxxxx10h, xxxxxx14h. Длина строки кэша прописывается в конфигурационном пространстве устройства (см. п. 6.2.12). Если устройства не имеет регистра Cache Line Size, то оно должно прекратить транзакцию после первой фазы данных;
01 и 11 — зарезервировано, может использоваться как указание на отключение (Disconnect) после первой фазы данных.
В циклах обращения к портам ввода-вывода для адресации любого байта используются все линии AD[31:0]. При этом биты адреса AD[31:2] указывают на адрес двойного слова, к которому принадлежат передаваемые данные, а младшие биты адреса AD[1:0] должны соответствовать байтам, которые могут быть разрешены сигналами C/BE[3:0]#. При AD[1:0]=00 допустимо C/BE[3:0]# = xxx0 или 1111, при AD[1:0]=01 — C/BE[3:0]# = xx01 или 1111, при AD[1:0]=10 — C/BE[3:0]# = x011 или 1111, при AD[1:0]=11 — C/BE[3:0]# = 0111 (передается лишь байт 3) или 1111 (ни один байт не разрешен). Эти циклы тоже могут быть пакетными, хотя на практике эта возможность используется редко.
В циклах конфигурационной записи/считывания устройство (карта расширения) выбирается индивидуальным сигналом IDSEL; функция адресуется битами AD[10:8], а конфигурационные регистры (только двойные слова) адресуются битами AD[7:2], при этом AD[1:0]=00.
Команды шины PCI определяются значениями бит C/BE# в фазе адреса (табл. 6.12).
Команда подтверждения прерывания предназначена для чтения вектора прерываний. По протоколу она выглядит как команда чтения, неявно адресованная к системному контроллеру прерываний. Здесь в фазе адреса по шине AD полезная информация не передается, но ее инициатор (главный мост) должен обеспечить стабильность сигналов и корректность паритета. В PC 8-битный вектор передается в байте 0 по готовности контроллера прерываний (по сигналу TRDY#). Подтверждение прерываний выполняется за один цикл (первый холостой цикл, который процессоры x86 делают в дань совместимости со стариной, мостом подавляется).
Специальный цикл отличается от всех других тем, что является широковещательным. Однако ни один агент на него не отвечает, а главный мост или иное устройство, вводящее этот цикл, всегда завершает его способом Master Abort (на него требуется 6 тактов шины). Специальный цикл предназначен для генерации широковещательных сообщений — их могут читать любые «заинтересованные» агенты шины. Тип сообщения декодируется содержимым линий AD[15:0], на линиях AD[31:16] могут помещаться данные, передаваемые в сообщении. Фаза адреса в этом цикле для обычных устройств отсутствует, но мосты используют ее информацию для управления распространением сообщения. Сообщения с кодами 0000h, 0001h и 0002h требуются для указания на отключение (Shutdown), остановку (Halt) процессора или специфические функции процессора x86, связанные с кэшем и трассировкой. Коды 0003-FFFFh зарезервированы. Специальный цикл может генерироваться тем же аппаратно-программным механизмом, что и конфигурационные циклы (см. п. 6.2.11), но со специфическим значением адреса.
Команды чтения и записи ввода-вывода служат для обращения к пространству портов. Линии AD содержат адрес байта, причем декодированию подлежат и биты AD0 и AD1 (несмотря на то, что имеются сигналы BEx#). Порты PCI могут быть 16- или 32-битными. Для адресации портов на шине PCI доступны все 32 бита адреса, но процессоры x86 могут использовать только младшие 16 бит.
Команды обращения к памяти, кроме обычного чтения и записи, включают чтение строк кэш-памяти, множественное чтение (нескольких строк), запись с инвалидацией.
Команды конфигурационного чтения и записи адресуются к конфигурационному пространству устройств (см. п. 6.2.12). Обращение производится только двойными словами. Структура содержит идентификатор устройства и производителя, состояние и команду, информацию о занимаемых ресурсах и ограничения на использование шины. Для генерации данных команд требуется специальный аппаратно-программный механизм (см. п. 6.2.11).
Чтение строк памяти применяется, когда в транзакции планируется более двух 32-битных передач (обычно это чтение до конца строки кэша).
Множественное чтение памяти используется для транзакций, пересекающих границы строк кэш-памяти.
Запись с инвалидацией применяется к целым строкам кэша и позволяет оптимизировать циклы обратной записи «грязных» строк кэша.
Двухадресный цикл позволяет по 32-битной шине обращаться к устройствам с 64-битной адресацией. В этом случае младшие 32 бита адреса передаются в цикле данного типа, а за ним следует обычный цикл, определяющий тип обмена и несущий старшие 32 бита адреса. Шина PCI допускает 64-битную адресацию портов ввода-вывода (для x86 это бесполезно, но PCI существует и на других платформах).
Таблица 6.12. Декодирование команд шины PCI
| C/BE[3:0] | Тип команды |
| 0000 | Interrupt Acknowledge — подтверждение прерывания |
| 0001 | Special Cycle — специальный цикл |
| 0010 | I/O Read — чтение порта ввода-вывода |
| 0011 | I/O Write — запись в порт ввода-вывода |
| 0100 | Зарезервировано |
| 0101 | Зарезервировано |
| 0110 | Memory Read — чтение памяти |
| 0111 | Memory Write — запись в память |
| 1000 | Зарезервировано |
| 1001 | Зарезервировано |
| 1010 | Configuration Read — конфигурационное считывание |
| 1011 | Configuration Write — конфигурационная запись |
| 1100 | Multiple Memory Read — множественное чтение памяти |
| 1101 | Dual Address Cycle (DAC) — двухадресный цикл |
| 1110 | Memory-Read Line — чтение строки памяти |
| 1111 | Memory Write and Invalidate — запись с инвалидацией |
6.2.5. Пропускная способность шины
Шина PCI является самой высокоскоростной шиной расширения современных ПК, однако и ее реальная пропускная способность, увы, не так уж и высока. Рассмотрим наиболее распространенный вариант: разрядность 32 бита, частота 33 МГц. Как указывалось выше, пиковая скорость передачи данных внутри пакетного цикла составляет 132 Мбайт/с, то есть за каждый такт шины передаются 4 байта данных (33ґ4=132). Однако пакетные циклы выполняются далеко не всегда. Процессор общается с устройствами PCI инструкциями обращения к памяти или вводу-выводу через главный мост, который шинные транзакции процессора транслирует в транзакции шины PCI. Поскольку у процессоров x86 основные регистры 32-разрядные, то одна инструкция порождает транзакцию с устройством PCI, в которой передается не более 4 байт данных, что соответствует одиночной передаче. Если же адрес передаваемого (двойного) слова не выровнен по соответствующей границе, то будут порождены два одиночных цикла или один пакетный с двумя фазами данных, но в любом случае это обращение будет выполняться дольше, чем при выровненном адресе.
Однако при записи массива данных в устройство PCI (передача с последовательно нарастающим адресом) мост может пытаться организовать пакетные циклы. У современных процессоров (начиная с Pentium) шина данных 64-битная и применяется буферизация записи, так что два последовательных 32-битных запроса записи объединятся в один 64-битный. Этот запрос, если он адресован к 32-битному устройству, мост попытается передать пакетом с двумя фазами данных. «Продвинутый» мост может пытаться собирать в пакет и последовательные запросы, что может породить пакет существенной длины. Пакетные циклы записи можно наблюдать, например, передавая массив данных из ОЗУ в устройство PCI строковой инструкцией MOVSD, используя префикс повтора REP. Тот же эффект даст и цикл последовательных операций LODSW, STOSW (и иных инструкциях обращения к памяти). Поскольку у современных процессоров ядро исполняет инструкции гораздо быстрее, чем шина способна вывести их результаты, между инструкциями, порождающими объединяемые записи, процессор может успеть выполнить еще несколько операций. Однако если пересылка данных организуется директивой языка высокого уровня, которая ради универсальности работает гораздо сложнее вышеприведенных ассемблерных примитивов, транзакции, скорее всего, будут уже одиночными (у буферов записи процессора не хватит «терпения» придержать один 32-битный запрос до появления следующего, или же произойдет принудительная выгрузка буферов записи процессора или моста по запросу чтения, см. п. 6.2.10).
Что касается чтения из устройства PCI, то здесь пакетный режим организовать сложнее. Буферизации чтения у процессора, естественно, нет (операцию чтения можно считать выполненной лишь по получению реальных данных), и даже строковые инструкции будут порождать одиночные циклы. Однако у современных процессоров имеются возможности генерации запросов чтения более 4 байт. Для этого можно использовать инструкции загрузки данных в регистры MMX (8 байт) или XMM (16 байт), а из них уже выгружать данные в ОЗУ (которое работает много быстрее устройств PCI).
Строковые инструкции ввода-вывода (INSW, OUTSW с префиксом повторения REP), используемые для программированного ввода-вывода блоков данных (PIO), порождают серии одиночных транзакций, поскольку все данные блока относятся к одному адресу PCI.
Посмотреть, каким образом происходит обращение к устройству, несложно при наличии осциллографа: в одиночных транзакциях сигнал FRAME# активен всего 1 такт, в пакетных он длиннее. Число фаз данных в пакете соответствует числу тактов, во время которых активны оба сигнала IRDY# и TRDY#.
Стремиться к пакетизации транзакций записи стоит только в том случае, если устройство PCI поддерживает пакетные передачи в ведомом (target) режиме. Если это не так, то попытка пакетизации приведет даже к небольшой потере производительности, поскольку транзакция будет завершаться по инициативе ведомого устройства (сигналом STOP#), а не инициатора обмена, на чем теряется один такт шины. Так, к примеру, можно наблюдать, как при записи массива в память PCI, выполняемой директивой языка высокого уровня, устройство среднего быстродействия (вводящее лишь 3 такта ожидания готовности) принимает данные каждые 7 тактов, что при частоте 33 МГц и разрядности 32 бита дает скорость 33ґ4/7=18,8 Мбайт/с. Здесь 4 такта занимает активная часть транзакции (от сигнала FRAME# до снятия сигнала IRDY#) и 3 такта паузы. То же устройство по инструкции MOVSD принимает данные каждые 8 тактов шины (33ґ4/8=16,5 Мбайт/с). Эти данные — результат наблюдения работы PCI-ядра, выполненного на основе микросхемы FPGA фирмы Altera, не поддерживающего пакетные транзакции в ведомом режиме. То же самое устройство при чтении памяти PCI работает существенно медленнее — инструкцией REP MOWSW с него удалось получать данные каждые 19–21 тактов шины (скорость 33ґ4/20=6,6 Мбайт/с). Здесь сказывается и большая задержка устройства (оно выдает данные лишь в 8 такте после появления сигнала FRAME#), и то, что процессор начинает следующую пересылку лишь дождавшись данных от предыдущей. Трюк с использованием регистра XMM здесь дает положительный эффект, несмотря на потерю такта (на прекращение транзакции непакетным устройством), поскольку каждый 64-битный запрос процессора выполняется парой смежных транзакций PCI, между которыми пауза всего в пару тактов.
Для определения теоретического предела пропускной способности вернемся к рис. 6.7, чтобы определить минимальное время (число тактов) транзакций чтения и записи. В транзакции чтения после подачи команды и адреса инициатором (такт 1) меняется текущий «владелец» шины AD. На этот «разворот», или «пируэт» (turnaround), уходит такт 2, что обусловливается задержкой сигнала TRDY# целевым устройством. Далее может следовать фаза данных (такт 3), если целевое устройство достаточно расторопно. После последней фазы данных требуется еще 1 такт на обратный «пируэт» шины AD (в нашем случае это такт 4). Таким образом, чтение одного слова (4 байта) занимает минимум 4 такта по 30 нс (33 МГц). Если эти транзакции следуют непосредственно друг за другом (если на такое способен инициатор и у него не отбирают право на управление шиной), то можно говорить о максимальной скорости чтения в 33 Мбайт/с при одиночных транзакциях. В транзакциях записи шиной AD все время управляет инициатор, так что здесь нет потери тактов на «пируэт». При расторопном целевом устройстве, не вносящем дополнительных тактов ожидания, скорость записи может достигать 66 Мбайт/с.
Скорость, соизмеримую с максимальной пиковой, можно получить только при пакетных передачах, когда имеют место дополнительные 3 такта при чтении и 1 при записи. Так, для чтения пакета с числом фаз данных 4 требуется 7 тактов (V=16/(7ґ30) байт/нс = 76 Мбайт/с), а для записи — 5 (V=16/(5ґ30) байт/нс = 106,6 Мбайт/с). При числе фаз данных в 16 скорость чтения может достигать 112 Мбайт/с, а записи — 125 Мбайт/с.
В этих выкладках не учитывались потери времени, связанны со сменой инициатора. Инициатор может начинать транзакцию по получении сигнала GNT#, только убедившись в том, что шина находится в покое (сигналы FRAME# и IRDY# пассивны); на фиксацию покоя уходит один такт. Как видно, захватывать для одного инициатора большую часть пропускной способности шины можно, увеличивая длину пакета. Однако при этом возрастет задержка получения управления шиной для других устройств, что не всегда допустимо. Отметим также, что далеко не все устройства способны отвечать на транзакции без тактов ожидания, так что реальные цифры будут скромнее.
Итак, для выхода на максимальную производительность обмена устройства PCI сами должны быть ведущими устройствами шины, причем способными генерировать пакетные циклы. Поддержку пакетного режима имеют далеко не все устройства PCI, а у имеющих, как правило, есть существенные ограничения на максимальную длину пакета. Радикально повысить пропускную способность позволяет переход на частоту 66 МГц и разрядность 64 бита, что обходится недешево. Для того, чтобы на шине могли нормально работать устройства, критичные к времени доставки данных (сетевые адаптеры, устройства, участвующие в записи и воспроизведении аудио-видеоданных и др.), не следует пытаться выжать из шины ее декларированную полосу пропускания полностью. Перегрузка шины может привести, например, к потере пакетов из-за несвоевременности доставки данных. Заметим, что адаптер Fast Ethernet (100 Мбит/с) в полудуплексном режиме занимает полосу около 13 Мбайт/с (10% декларируемой полосы обычной шины), а в полнодуплексном — уже 26 Мбайт/с. Адаптер Gigabit Ethernet даже в полудуплексном режиме вписывается в полосу шины уже с натяжкой (он «выживает» лишь за счет больших внутренних буферов), для него больше подходит 64 бит/66 МГц.
6.2.6. Прерывания
В PC-совместимых компьютерах прерывания от устройств PCI обслуживаются с помощью традиционной связки пары контроллеров 8259A, расположенных на системной плате (см. п. 12.4), к которым обращается команда «подтверждение прерывания». Прерывания на шине PCI свободны от одной из нелепостей системы прерываний ISA. Устройство PCI вводит сигнал прерывания низким уровнем (выходом с открытым коллектором или стоком) на выбранную линию INTA#, INTB#, INTC# или INTD#. Этот сигнал должен удерживаться до тех пор, пока программный драйвер, вызванный по прерыванию, не сбросит запрос прерывания, обратившись по шине к данному устройству. Если после этого контроллер прерываний снова обнаруживает низкий уровень на линии запроса, это означает, что запрос на ту же линию ввело другое устройство, разделяющее данную линию с первым, и оно тоже требует обслуживания. Линии запросов от слотов PCI и PCI-устройств системной платы коммутируются на входы контроллеров прерываний относительно произвольно. Конфигурационное ПО может определить и указать занятые линии запросов и номер входа контроллера прерываний обращением к конфигурационному пространству устройства (см. п. 6.2.12). Программный драйвер, прочитав конфигурационные регистры, тоже может определить эти параметры для того, чтобы установить обработчик прерываний на нужный вектор и при обслуживании сбрасывать запрос с требуемой линии. К сожалению, в конфигурационных регистрах не нашлось стандартного места для бита, индицирующего введение запроса прерывания данным устройством, — тогда бы в прерываниях для PCI не было бы проблем с унификацией поддержки разделяемых прерываний.
Каждая функция устройства PCI может задействовать свою линию запроса прерывания, но должно быть готовым к ее разделению (совместному использованию) с другими устройствами. Если устройству требуется только одна линия запроса, то оно должно занимать линию INTA#, если две — INTA# и INTB#, и так далее. С учетом циклического сдвига линий запроса это правило позволяет установить в 4 соседних слота 4 простых устройства, и каждое из них будет занимать отдельную линию запроса прерывания. Если какой-то карте требуется две линии, то для монопольного использования прерываний нужно оставить соседний слот свободным. PCI-устройства системной платы тоже задействуют прерывания с той же закономерностью (кроме контроллера IDE, который, к счастью, держится особняком).
Назначение прерываний устройствам (функциям) выполняет процедура POST, и этот процесс управляем лишь частично. Параметрами CMOS Setup (PCI/PNP Configuration) пользователь определяет номера запросов прерываний, доступных шине PCI. В зависимости от версии BIOS это может выглядеть по-разному: либо каждой линии INTA#...INTD# явно назначается свой номер, либо ряд номеров отдается «на откуп» устройствам PCI вместе с устройствами ISA PnP (в противоположность устройствам «Legacy ISA»). В итоге POST определяет соответствие линий INTA#...INTD# номерам запросов контроллера и соответствующим образом программирует коммутатор запросов. По воле пользователя может оказаться так, что не каждой линии запроса шины PCI достается отдельный вход контроллера прерываний. Тогда коммутатор организует объединение нескольких линий запросов PCI на один вход контроллера, то есть разделяемые прерывания. В самом худшем случае устройствам PCI не достанется ни одного входа контроллера прерываний. Заметим, что BIOS вряд ли отдаст шине PCI прерывания 14 и 15 (их забирает контроллер IDE, если он не отключен), а также 3 и 4 (COM-порты).
Драйвер (или иное ПО), работающий с устройством PCI, определяет вектор прерывания, доставшийся устройству (точнее, функции), чтением конфигурационного регистра Interrupt Line. В этом регистре указывается номер входа контроллера прерывания (255 — номер не назначен), и по нему определяется вектор (см. п. 12.4). Номер входа каждому устройству заносит тест POST. Для этого он считывает регистр Interrupt Pin каждой обнаруженной функции и по адресу устройства (!) определяет, какая из линий (PCI_I1...PCI_4) используется. Заметим, что правила, по которым на системной плате определяется соответствие между Interrupt Pin и входными линиями коммутатора запросов в зависимости от номера устройства, строго не регламентированы (деление номера устройства на 4 — это всего лишь рекомендация), но их твердо знает версия BIOS данной системной платы. К этому моменту тест POST уже определил таблицу соответствия этих линий номерам входов; пользуясь этой таблицей, он записывает нужное значение в конфигурационный регистр Interrupt Line. Определить, есть ли еще претенденты на тот же номер прерывания, можно, лишь просмотрев конфигурационные регистры функций всех устройств, обнаруженных на шине (это не так уж сложно сделать, пользуясь функциями PCI BIOS). «Прелести» разделяемых прерываний обсуждаются в п. 12.4.1.
Спасением от бед «разделяемости» может быть перестановка карт в подходящий слот. Однако попадаются «подарки разработчиков» интегрированных плат, у которых из нескольких слотов PCI неразделяемая линия прерывания есть только у одного (а то и нет вообще). Такие недуги без скальпеля и паяльника, как правило, не лечатся.
На шине PCI имеется и иной механизм оповещения об асинхронных событиях, основанный на передаче сообщений (PCI Message-Based Interrupts). Для сигнализации запроса прерывания устройство запрашивает управление шиной и, получив его, выполняет запись номера прерывания по заранее оговоренному адресу. Этот механизм может использоваться на системных платах, имеющих «продвинутый» контроллер прерываний APIC. Запись номера запроса производится в соответствующий регистр APIC. Для системных плат на чипсете с хабом ICH2 82801 этот регистр находится по адресу памяти FEC00020h, а номер прерывания может быть в диапазоне 0–23h. Однако одновременно оба механизма работать не могут; если разрешена работа APIC, то логика контроллеров 8259 не используется, и наоборот.
6.2.7. Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI)
Как было сказано выше, шина PCI не предоставляет возможности прямого доступа к памяти с использованием централизованного контроллера в стиле 8237A (как для шины ISA). Для разгрузки центрального процессора от рутинных перекачек данных предлагается прямое управление шиной со стороны устройств, называемых ведущими устройствами шины (PCI Bus Master). Степень интеллектуальности ведущего устройства может быть различной. В простейшем варианте ведущее устройство обеспечивает пересылку блоков данных между устройством и системной памятью (или памятью других устройств) по указанию от CPU. Здесь CPU командами обращения к определенным регистрам ведущего устройства задает начальный адрес, длину блока, направление пересылки и разрешает запуск передачи. После этого пересылка выполняется по готовности (или инициативе) устройства, без отвлечения CPU. Таким образом выполняется прямой доступ к памяти (DMA). Более сложный контроллер DMA может организовывать сцепку буферов при чтении, разбросанную запись и т. п. — возможности, знакомые еще по «продвинутым» контроллерам DMA для ISA/EISA. Более интеллектуальное ведущее устройство, как правило, обладающее собственным микроконтроллером, не ограничивается такой простой работой по указке CPU — оно выполняет обмены уже по программе своего контроллера.
Для совместимости устройств PCI со старым PC-ориентированным ПО и упрощения устройств PCI фирма Intel разработала специальный протокол PC/PCI DMA, изменяющий назначение пары сигналов REQi# и GNTi# для заранее выбранного агента шины, являющегося «проводником» DMA. Этот агент имеет внешние (по отношению к шине PCI) пары сигналов DRQx# и DACKx# с логикой, аналогичной одноименным сигналам ISA (см. п. 6.1), а линии REQi# и GNTi# в процессе запроса управления шиной использует особым образом. Когда агент получает запрос DRQx (один или несколько), он по линии REQi# передает в последовательном коде номера активных линий запросов DRQx, с синхронизацией по линии CLK. В первом такте CLK передается старт-бит — низкий уровень REQi#, во втором — активность запроса DRQ0, затем DRQ1 и так далее до DRQ7, после чего сохраняется низкий уровень REQ#. На это сообщение арбитр ответит по линии GNTi# посылкой, также начинающейся со старт-бита, за которой последуют три бита кода номера канала, которому дается подтверждение DACK# для передачи данных в этой транзакции. Агент должен сообщать арбитру обо всех изменениях линий запроса, в том числе и о снятии сигналов запроса. Механизм PC/PCI DMA может быть реализован только в чипсете системной платы.
6.2.8. Электрический интерфейс, слоты и карты PCI
Для работы на шине PCI используются микросхемы КМОП (CMOS), причем имеются две спецификации: с напряжениями питания интерфейсных схем 5 и 3,3 В. Для них применимы параметры сигналов на постоянном токе, приведенные в табл. 6.13. Однако мощность интерфейсных элементов (транзисторов для вентилей) выбрана меньшей, чем требовалось бы для переключения сигналов на высокой частоте (33 или 66 МГц). Здесь используется эффект отражения сигналов, формируемых микросхемами на проводниках шины, от несогласованных концов этих проводников, являющихся для таких высоких частот длинными линиями. На согласованных концов этих проводников, являющихся для таких высоких частот длинными линиями. На концах проводников шины нет терминаторов, поэтому от них приходящая волна сигнала отражается с тем же знаком и с той же амплитудой. Складываясь с прямым сигналом, обратная волна и обеспечивает нужный приемнику уровень сигнала. Таким образом, передатчик генерирует сигнал, который до прихода отраженного находится между уровнями переключения.
Линии управляющих сигналов FRAME#, TRDY#, IRDY#, DEVSEL#, STOP#, SERR#, PERR#, LOCK#, INTA#, INTB#, INTC#, INTD#, REQ64# и ACK64# на системной плате подтягиваются к шине питания резисторами (типично 2,7 кОм для версии 5 В и 8,2 кОм для 3,3 В), чтобы не было ложных срабатываний при пассивности всех агентов шины.
Таблица 6.13. Параметры интерфейсных сигналов на постоянном токе
| Параметр | 5 В | 3,3 В |
| Входное напряжение низкого уровня, В | –0,5ЈUIL Ј0,8 | –0,5ЈUIL Ј0,3ґVCC |
| Входное напряжение высокого уровня, В | 2ЈUIH ЈVCC+0,5 | VCC/2ЈUIH Ј VCC +0,5 |
| Выходное напряжение низкого уровня, В | UOLЈ0,55 | UOLЈ0,1ґVCC |
| Выходное напряжение высокого уровня, В | UOH і0,8 | UOH і0,9ґVCC |
| Напряжение питания VCC, В | 4,75ЈUCC Ј5,25 | 3,3ЈUCC Ј3,6 |
Электрическая спецификация рассчитана на два предельных варианта нагрузки одной шины: 2 устройства PCI на системной плате плюс 4 слота или 4 устройства и 2 слота. При этом подразумевается, что одно устройство на каждую линию шины PCI дает только единичную КМОП-нагрузку. В слоты могут устанавливаться карты, тоже дающие только единичную нагрузку. На длину проводников, а также топологию расположения элементов и проводников на картах расширения накладываются жесткие ограничения. Из-за этого изготовление самодельных карт PCI на логических микросхемах средней степени интеграции становится проблематичным.
Слоты PCI представляют собой щелевые разъемы, имеющие контакты с шагом 0,05 дюйма. Слоты расположены несколько дальше от задней панели, чем ISA/EISA или MCA. Компоненты карт PCI расположены на левой поверхности плат. По этой причине крайний PCI-слот обычно совместно использует посадочное место адаптера (прорезь на задней стенке корпуса) с соседним ISA-слотом. Такой слот называют разделяемым (shared slot), в него может устанавливаться либо карта ISA, либо PCI.
Карты PCI могут предназначаться для уровня интерфейсных сигналов 5 В и 3,3 В, а также быть универсальными. Слоты PCI имеют уровни сигналов, соответствующие питанию микросхем PCI-устройств системной платы: либо 5 В, либо 3,3 В. Во избежании ошибочного подключения слоты имеют ключи, определяющие номинал напряжения. Ключами являются пропущенные ряды контактов 12, 13 и 50, 51. Для слота на 5 В ключ расположен на месте контактов 50, 51; для 3,3 В — 12, 13. На краевых разъемах карт PCI имеются ответные прорези на месте контактов 50, 51 (5 В) и 12,13 (3,3 В); на универсальной карте имеется оба ключа. Ключи не позволяют установить карту в слот с неподходящим напряжением питания. Карты и слоты различаются лишь питанием буферных схем, которое поступает с линий +V I/O:
на слоте «5 В» на линии +V I/O подается +5 В;
на слоте «3,3 В» на линии +V I/O подается +(3,3–3,6) В;
на карте «5 В» буферные микросхемы рассчитаны только на питание +5 В;
на карте «3,3 В» буферные микросхемы рассчитаны только на питание +(3,3–3,6) В;
на универсальной карте буферные микросхемы допускают оба варианта питания и будут нормально формировать и воспринимать сигналы по спецификациям 5 или 3,3 В, в зависимости от типа слота, в который установлена карта.
На слотах обоих типов присутствуют питающие напряжения +3,3, +5, +12 и –12 В на одноименных линиях. В PCI 2.2 определена дополнительная линия 3.3Vaux — «дежурное» питание +3,3 В для устройств, формирующих сигнал PME# при отключенном основном питании.
На системных платах чаще всего встречаются 5-вольтовые 32-битные слоты, заканчивающиеся контактами A62/B62; 64-битные слоты встречаются реже, они длиннее и заканчиваются контактами A94/B94. Конструкция разъемов и протокол позволяют устанавливать 64-битные карты и в 32-битные разъемы, и наоборот, но при этом, естественно, обмен будет в 32-битном режиме.
Тактовая частота шины определяется по возможностям чипсета и всех абонентов шины. Высокая частота 66 МГц может устанавливаться тактовым генератором только при высоком уровне на линии M66EN. Таким образом, установка любой карты, не поддерживающей 66 МГц (с заземленным контактом B49), приведет к понижению частоты, шины до 33 МГц. Серверные системные платы, на которых имеется несколько шин PCI, позволяют использовать на разных шинах разные частоты (66 и 33 МГц). Так, например, можно на 64-битных слотах использовать частоту 66 МГц, а на 32-битных — 33. Разгон нормальной частоты 33 МГц до 40–50 МГц аппаратно не контролируется, но может приводить к ошибкам работы карт расширения.
На рис. 6.8 изображена 32-битная карта максимального размера (Long Card), длина короткой платы (Short Card) — 175 мм, но многие карты имеют и меньшие размеры. Карта имеет обрамление (скобку), стандартное для конструктива ISA (раньше встречались карты и с обрамлением в стиле MCA IBM PS/2). Назначение выводов универсального разъема приведено в табл. 6.14.
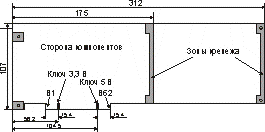
Рис. 6.8. Карта расширения для шины PCI
Таблица 6.14. Разъемы шины PCI
| Ряд B | № | Ряд A | Ряд B | № | Ряд A |
| –12 В | 1 | TRST# | GND/M66EN1 | 49 | AD 9 |
| TCK | 2 | +12 В | GND/Ключ 5 В | 50 | GND/Ключ 5 В |
| GND | 3 | TMS | GND/Ключ 5 В | 51 | GND/Ключ 5 В |
| TDO | 4 | TDI | AD 8 | 52 | C/BE0# |
| +5 В | 5 | +5 В | AD 7 | 53 | +3,3 В |
| +5 В | 6 | INTA# | +3,3 В | 54 | AD 6 |
| INTB# | 7 | INTC# | AD 5 | 55 | AD 4 |
| INTD# | 8 | +5 В | AD 3 | 56 | GND |
| PRSNT1# | 9 | Резерв | GND | 57 | AD 2 |
| Резерв | 10 | +V I/O | AD 1 | 58 | AD 0 |
| PRSNT2# | 11 | Резерв | +V I/O | 59 | +V I/O |
| GND/Ключ 3,3 В | 12 | GND/Ключ 3,3 В | ACK64# | 60 | REQ64# |
| GND/Ключ 3,3 В | 13 | GND/Ключ 3,3 В | +5 В | 61 | +5 В |
| Резерв | 14 | 3.3Vaux 2 | +5 В | 62 | +5 В |
| GND | 15 | RST# | Конец 32-битного разъема | |
| CLK | 16 | +V I/O | Резерв | 63 | GND |
| GND | 17 | GNT# | GND | 64 | C/BE7# |
| REQ# | 18 | GND | C/BE6# | 65 | C/BE5# |
| +V I/O | 19 | PME# 2 | C/BE4# | 66 | +V I/O |
| AD 31 | 20 | AD 30 | GND | 67 | PAR64 |
| AD 29 | 21 | +3,3 В | AD 63 | 68 | AD 62 |
| GND | 22 | AD 28 | AD 61 | 69 | GND |
| AD 27 | 23 | AD 26 | +V I/O | 70 | AD 60 |
| AD 25 | 24 | GND | AD 59 | 71 | AD 58 |
| +3,3 В | 25 | AD 24 | AD 57 | 72 | GND |
| C/BE3# | 26 | IDSEL | GND | 73 | AD 56 |
| AD 23 | 27 | +3,3 В | AD 55 | 74 | AD 54 |
| GND | 28 | AD 22 | AD 53 | 75 | +V I/O |
| AD 21 | 29 | AD 20 | GND | 76 | AD 52 |
| AD 19 | 30 | GND | AD 51 | 77 | AD 50 |
| +3.3 В | 31 | AD 18 | AD 49 | 78 | GND |
| AD 17 | 32 | AD 16 | +V I/O | 79 | AD 48 |
| C/BE2# | 33 | +3,3 В | AD 47 | 80 | AD 46 |
| GND | 34 | FRAME# | AD 45 | 81 | GND |
| IRDY# | 35 | GND | GND | 82 | AD 44 |
| +3,3 В | 36 | TRDY# | AD 43 | 83 | AD 42 |
| DEVSEL# | 37 | GND | AD 41 | 84 | +V I/O |
| GND | 38 | STOP# | GND | 85 | AD 40 |
| LOCK# | 39 | +3,3 В | AD 39 | 86 | AD 38 |
| PERR# | 40 | (SDONE#) 3 | AD 37 | 87 | GND |
| +3,3 В | 41 | (SBOFF#) 3 | +V I/O | 88 | AD 36 |
| SERR# | 42 | GND | AD 35 | 89 | AD 34 |
| +3,3 В | 43 | PAR | AD 33 | 90 | GND |
| C/BE1# | 44 | AD 15 | GND | 91 | AD 32 |
| AD 14 | 45 | +3,3 В | Резерв | 92 | Резерв |
| GND | 46 | AD 13 | Резерв | 93 | GND |
| AD 12 | 47 | AD 11 | GND | 94 | Резерв |
| AD 10 | 48 | GND | Конец 64-битного разъема | |
1.Сигнал M66EN определен в PCI 2.1 только для слотов на 3,3 В.
2. Сигнал введен в PCI 2.2 (прежде был резерв).
3. Сигналы упразднены в PCI 2.2 (для совместимости на системной плате подтягиваются к высокому уровню резисторами 5 кОм).
На слотах PCI имеются контакты для тестирования адаптеров по интерфейсу JTAG (сигналы TCK, TDI, TDO, TMS и TRST#). На системной плате эти сигналы задействованы не всегда, но они могут и организовывать логическую цепочку тестируемых адаптеров, к которой можно подключить внешнее тестовое оборудование. Для непрерывности цепочки на карте, не использующей JTAG, должна быть связь TDI–TDO.
На некоторых старых системных платах позади одного из слотов PCI имеется разъем Media Bus, на который выводятся сигналы ISA. Он предназначен для размещения на графическом адаптере PCI звукового чипсета, предназначенного для шины ISA.
6.2.9. Иные конструктивы с шиной PCI
Шина PCI имеет и другие конструктивные исполнения; их спецификации доступны на сайте www.pcisig.org (правда, только для членов данной организации либо за деньги).
Low-Profile PCI — низкопрофильный вариант карты PCI с обычным разъемом, но измененной крепежной скобкой. Эти карты можно устанавливать вертикально (без переходника riser card) даже в низкопрофильные корпуса (например, 19" формата высотой 2U). Для этих карт предусматривается напряжение питания интерфейсных схем только 3,3 В (но шина питания 5 В сохраняется).
Small PCI (SPCI) — спецификация PCI в миниатюрном исполнении, прежде называвшаяся SFF PCI (Small Form-Factor). Эта спецификация, предназначенная, в основном, для портативных компьютеров, логически совпадает с обычной шиной PCI. Шина 32-битная, 64-битное расширение не предусматривается, и при частоте 33 МГц обеспечивается пропускная способность 132 Мбайт/с. Как и на всех шинах PCI, здесь поддерживается прямое управление (bus mastering). В дополнение к обычному набору сигналов появился новый CLKRUN, с помощью которого хост и устройства могут управлять частотой синхронизации в интересах энергосбережения. По размерам карта SPCI совпадает с PC Card и Card Bus, но специальные ключи предотвращают ошибки подключения. Для подключения карт SPCI на системной плате устанавливается двухрядный 108-контактный штырьковый разъем с шагом контактов 2 мм. Карта расширения может подключаться к нему непосредственно, но также может использоваться переходник с двусторонними ленточными контактами с шагом 0,8 мм. Шина SPCI является внутренней (карты расширения находятся под крышкой корпуса и устанавливаются изготовителем при выключенном питании) и поэтому не нацелена на замену Card BUS (шина для внешних подключений с возможностью горячей замены). Карты SPCI могут быть трех видов: с питанием 5 В, 3,3 В и универсальные 5/3,3 В. Благодаря уменьшению размеров (длины проводников) понижены требования к мощности сигналов. Карты SPCI позволяют использовать преимущества модульных решений (можно разгрузить системную плату), обеспечивая высокую производительность обмена (чего не обеспечивает Card Bus).
Mini PCI Specification — малогабаритный вариант карт PCI (2,75"ґ1,81"ґ0,22"). Логически и электрически соответствует PCI (32 бит), дополнительно используя сигнал CLKRUN для снижения энергопотребления и без сигналов JTAG. Имеет дополнительные сигналы для аудио- и видео-применений.
Начало
Cодержание
Отрывок
[Заказать книгу в магазине "Мистраль"]
|
|

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
