2010 г.
Выполнение транзакций, ориентированное на данные
Иппократис Пандис, Райан Джонсон, Никос Харадавеллас и Анастасия Айламаки
Перевод: Сергей Кузнецов
Назад Содержание
A. Приложение
Приложение содержит четыре раздела. Сначала для лучшего понимания системы DORA мы подробно описываем выполнение в среде DORA одной транзакции (разд. A.1). Затем мы обсуждаем два преимущества того, что DORA является системой с совместным использованием всех ресурсов (shared-everything), а не системой без совместного использования ресурсов (shared-nothing) (разд. A.2). Далее, чтобы обеспечть лучшее понимание различий между традиционным выполнением транзакций и их выполнением в среде DORA, мы графически демонстрируем различия в их паттернах доступа к данным и обсуждаем возможности использования регулярности паттернов доступа к данным в DORA (разд. A.3). Наконец, мы обсуждаем еще одну проблему DORA, которую составляет выполнение транзакций с заметной интенсивностью аварийных завершений и внутритранзакционным параллелизмом (разд. A4).
A.1. Детальный пример выполнения транзакции
В этом разделе подробно описывается выполнение в среде DORA транзакции
Payment из тестового набора TPC-C. Напомним, что транзакция
Payment обновляет остаток на счету клиента (
Customer), отражает факт совершения платежа в статистике округа (
District) и склада (
Warehouse) и фиксирует этот факт в журнале истории (
History). Граф потока транзакции для транзакции
Payment показан на рис. 4.
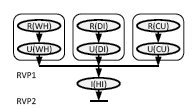
Рис. 4. Граф потока транзакции Payment из тестового набора TPC-C.
На рис. 9 показан поток выполнения в среде DORA транзакции Payment. Все круги раскрашены, чтобы показать потоки управления, выполняющий соответствующие шаги. При выполнении этой транзакции имеется всего 12 шагов.
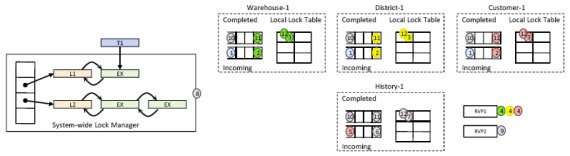
Рис. 9. Пример выполнения транзакции Payment из тестового набора TPC-C в среде DORA.
| Шаг 1: |
Выполнение транзакции начинается с потока управления, получающего запрос (например, из сети). Этот поток управления, называемый также диспетчером (dispatcher), ставит в очереди к соответствующим исполнителям действия первой фазы транзакции.
|
| Шаг 2: |
Когда действие достигает начала входной очереди, оно выбирается соответствующим исполнителем.
|
| Шаг 3: |
Каждый исполнитель производит поиск в своей локальной таблице блокировок, чтобы определить, может ли он обработать действие, обслуживаемое в данное время. Если имеется конфликт, то действие добавляется к списку заблокированных действий. Его выполнение возобновится, когда завершится транзакция, действие которой заблокировало данное действие. В противном случае исполнитель выполняет действие в основном без использования общесистемного управления параллелизмом.
|
| Шаг 4: |
Когда действие завершается, исполнитель уменьшает на единицу счетчик RVP первой фазы (RVP1).
|
| Шаг 5: |
Исполнитель, действие которого обнулило счетчик RVP1, инициирует следующую фазу, помещая соответствующее действие в очередь к исполнителю History.
|
| Шаг 6: |
Исполнитель History выбирает действие из начала входной очереди.
|
| Шаг 7: |
Исполнитель таблицы History производит поиск в локальной таблице блокировок.
|
| Шаг 8: |
Транзакция Payment вставляет запись в таблицу History, и по причине, которую мы объясняли в п. 4.2.1, исполнитель действия нуждается во взаимодействии с централизованным менеджером блокировок.
|
| Шаг 9: |
Когда действие завершается, исполнитель History обновляет последнюю RVP и вызывает фиксацию транзакции.
|
| Шаг 10: |
Когда основной сервер хранения данных производит возврат из общесистемной фиксации (с выталкиванием буфера журнала и освобождением всех централизованных блокировок), исполнитель History ставит идентификаторы всех действий в очереди к их исполнителям.
|
| Шаг 11: |
Исполнитель выбирает идентификатор зафиксированного действия.
|
| Шаг 12: |
Исполнители удаляют соответствующие элементы из своих локальных таблиц блокировок и ищут в списке отложенных действий действие, выполнение которого теперь можно продолжить.
|
Этот детальный пример выполнения транзакции, в особенности, его шаги 9-12 показывают, что операция фиксации в DORA похожа на двухфазный протокол фиксации (two-phase commit protocol, 2PC) в том смысле, что поток управления, вызывающий фиксацию (координатор в 2PC), также посылает сообщения различным исполнителям (участникам в 2PC) сообщения для освобождения локальных блокировок. Основное отличие от традиционного двухфазного протокола фиксации состоит в том, что рассылка сообщений происходит асинхронно, и что участники не вынуждаются голосовать. Поскольку все изменения журнализуются с одним и тем же идентификатором транзакции, нет потребности в дополнительных сообщениях и вставках в журнал (раздельных сообщениях и записях Prepare и Commit [A.3]). Иначе говоря, фиксация – это одиночная операция с точки зрения журнализации, хотя по-прежнему включает асинхронную посылку сообщений от координатора участникам для освобождения локальных блокировок.
Пример показывает, каким образом DORA преобразует выполнение каждой транзакции в коллективную работу нескольких потоков управления. Кроме того, он показывает, каким образом в DORA минимизируется число взаимодействий с чреватым конфликтами централизованным менеджером блокировок за счет наличия дополнительной межъядерной пропускной способности.
A.2. DORA и системы без совместного использования ресурсов
Одним из основных преимуществ архитектуры DORA является то, что система остается системой с совместным использованием всех ресурсов, но в то же время потоки управления б
ольшую часть времени работают со своими частными структурами данных. Другими словами, хотя каждая таблица разделяется на разъединенные поднаборы записей, и эти поднаборы назначаются разным потокам управления, это разделение является чисто логическим, а не физическим.
Система без совместного использования ресурсов может столкнуться с существенной проблемой производительности из-за несбалансированности, вызываемой "скошенностью" данных или запросов, или из-за наличия обращений к данным, которые не согласуются со схемой разделения. Следовательно, производительность таких систем чувствительна к архитектуре приложений [A2]. Системам без совместного использования ресурсов нужны приложения, рабочая нагрузка которых разделяется таким образом, что лишь небольшую ее часть составляют многораздельные транзакции, нагрузка балансируется между разделами и имеется минимальное число обращений к данным, не согласованных со схемой разделения (см., например, [A.8]).
В этом разделе мы приводим доводы в пользу того, что DORA, будучи системой с совместным использованием всех ресурсов, менее чувствительна к таким проблемам, чем системы без совмесного использования ресурсов. В следующих подразделах сравнивается, каким образом типичная система без совместного использования ресурсов и DORA приспосабливается во время выполнения к изменениям паттернов доступа к данным и к "перекашиванию" данных (подраздел A.2.1), и каким образом они обрабатывают обращения к данным, не согласованные со схемами разделения (подраздел A.2.2).
A.2.1. Балансировка нагрузки
Обычно реакцией системы без совместно используемых ресурсов на несбалансированность нагрузки являются изменение размеров или репликация частей таблиц в каждом разделе. Для изменения размеров частей таблицы такой системе приходится удалить некоторый фрагмент таблицы из одного раздела и вставить его в другой фрагмент. Во время пересылки записей выполнение запросов, содержащих обращения к таблице, размер частей которой изменяется, затруднено. С пересылкой записей связаны ощутимые расходы. Например, для таблицы, размер частей которой изменяется, требуется обновить все индексы. Чем больше записей требуется переслать, или чем больше индексов имеется на таблице, размер частей которой изменяется, тем дороже обходится ее переразделение.
С другой стороны, в DORA несбалансированность нагрузки устраняется путем изменения правила маршрутизации каждой таблицы и создания новых исполнителей, если это требуется. Менеджер ресурсов DORA отслеживет загрузку каждого исполнителя и реагирует на ситуацию, когда средняя нагрузка, назначаемая некоторому исполнителю, непропорционально больше нагрузки всех остальных исполнителей. Типичная реакция состоит в таком изменении размеров наборов данных, назначенных каждому исплнителю, чтобы нагрузка сбалансировалась.
Каждое изменение правила маршрутизации задевает двух исполнителей: того, область ответственности которого сокращается, или сокращаемого исполнителя (shrinking executor), и того, которому назначается большая доля таблицы, или расширяемого исполнителя (growing executor). Для изменения размеров наборов данных менеджер ресурсов ставит во входные очереди каждого из этих двух исполнителей некоторое системное действие и модифицирует правило маршрутизации. Когда это системное действие выбирается сокращаемым исполнителем, он прекращает обслуживать новые действия до тех пор, пока систему не покинут все действия, уже обслуженные этим исполнителем. Иначе говоря, сокращаемому исполнителю нужно завершить все выполняемые действия. Иначе он мог бы выполнить действия, направленные на модификацию части данных, за которые после изменения размеров отвечает расширяемый исполнитель. Расширяемый исполнитель может обычным образом продолжать обслуживать действия над своим "старым" набором данных. Когда все действия, выполняемые сокращаемым исполнителем, завершатся, расширяемый исполнитель сможет начать обслуживать действия, относящиеся к заново назначенному ему набору данных.
С изменением наборов данных во время выполнения связаны также и некоторые косвенные накладные расходы. Для данных, к которым должен теперь обращаться исполнитель, работающий на другом ядре, теряется локальность кэша. Данные должны переместиться в кэш другого ядра, и система претерпевает возрастающий трафик когерентности (coherence traffic) для сбора модифицированных данных, а также возрастающую интенсивность "непопаданий" (miss rate) во время "разогрева" кэша. Поэтому к восстановлению сбалансированности нагрузки во время выполнения системы следует относиться благоразумно, учитывая все упомянутые аспекты. И все равно эта процедура в DORA менее болезненна, чем в системах без совместного использования ресурсов.
A.2.2. Обращения к данным, не согласованные со схемами разделения
Некоторым приложениям может понадобиться доступ к данным, не согласованный со схемой разделения. Например, рассмотрим разделение таблицы
Customer из базы данных TPC-C на основе
Warehouse_id и транзакцию, пытающуюся обратиться к записям клиентов по именам клиентов. Если эта транзакция выполняется достаточно часто, требуется построить вторичный индекс на столбце имен клиентов таблицы
Customer. В системе без совместного использования ресурсов такой индекс пришлось бы построить для каждого раздела.
В выполнении этой транзакции в системе без совместного использования ресурсов участвовали бы все N разделов, и производилось бы N поисков во вторичном индексе, только немногие из которых действительно возвращали бы записи.
В DORA такие доступы к данным обычно являются вторичными действиями, и в п. 4.2.2 описывается, как они обрабатываются. Поддерживается один индекс. В каждом элементе листовых узлов этого индекса содержится не только RID, но и поля маршрутизации. Всякий раз при выполнении такой транзакции выполняется только один поиск. Собираются все RID, и затем доступ к каждой записи производится соответствующим исполнителем на основе полей маршрутизации каждого элемента индекса. В выполнении этой транзакции будут участвовать только те исполнители, наборы данных которых содержат записи, найденные при поиске по вторичному индексу.
A.3. Сравнение паттернов доступа и потенциальные возможности
DORA – это не система без совместного использования ресурсов. В то же время, это и не традиционная система с совместным использованием всех ресурсов. Основным отличием является способ назначения работы различным потокам управления.
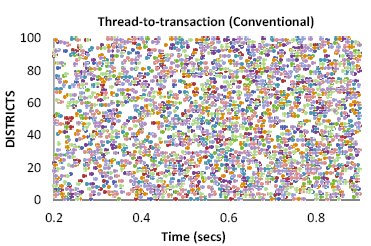
Рис. 10a. Трасса обращений потоков управления к записям в традиционной системе; обращения к данным являются некоординированными и сложными.
Различие между выполнением транзакций на основе политики назначения транзакций потокам управления (т.е. традиционной политики) и политики назначения потоков управления данным (т.е. политики DORA) становится очевидным, если прибегнуть к визуальному осмотру. На рис. 10(a) показаны обращения всех рабочих потоков управления традиционной системы обработки транзакций к записям таблицы District базы данных TPC-C c 10 складами. В системе имелось 10 рабочих потоков управления, и рабочая нагрузка задавалась 20 клиентами, непрерывно запрашивающими выполение транзакций Payment из тестового набора TPC-C5, хотя трассировка производилась только в течение 0,7 секунды работы системы. Обращения к данным являются полностью некоординированными. Для обеспечения согласованности данных системе приходится использовать защелки, расходы на поддержку которых возрастают при росте уровня параллелизма системы.
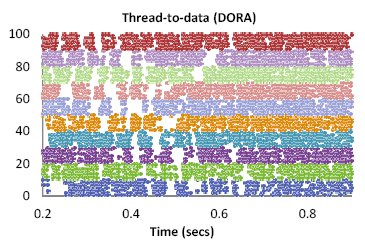
Рис. 10b. Трасса обращений потоков управления к записям в системе DORA; обращения к данным являются координированными и демонстрируют регулярность.
С другой стороны, рис. 10(b) иллюстрирует воздействие на паттерны доступа к данным политики назначения потоков управления данным. Здесь изображены паттерны доступа к данным в системе DORA при той же рабочей нагрузке, что в случае рис. 10(a). Доступы к данным в DORA являются координированными и демонстрируют регулярность.
В своей работе мы использовали эту регулярность для уменьшения числа взаимодействий с централизованным менеджером блокировок и, следовательно, для сокращения числа дорогостоящих операций "закрытия" и "открытия" защелок. Мы также использовали наличие этой регулярности для повышения производительности отдельных потоков управления, заменяя выполнение дорогостоящего кода менеджера блокировок выполнением более легковесного механизма блокировок, локального для потока управления. Но этим не исчерпываются потенциальные возможности оптимизации выполнения транзакций в среде DORA. Потенциально паттерны доступа DORA могут использоваться для совершенстования как поведения ввода-вывода, так и микроархитектурного поведения OLTP.
В частности, ввод-вывод, выполняемый в ходе традиционной OLTP, является произвольным и низкоэффективным.6. Исполнители DORA могут буферизовать запросы ввода-вывода и выдавать их в пакетном режиме, поскольку можно ожидать, что эти операции ввода-вывода будут затрагивать физически близкие страницы. Это позволит улучшить поведение ввода-вывода.
Кроме того, основной характеристикой микроархитектур традиционных систем OLTP является очень большое число обращений по чтению и записи к общей памяти от нескольких процессорных ядер [A1]. К сожалению, эти обращения производятся очень непредсказуемым образом [A6]. Поэтому существенному повышению производительности традиционных систем OLTP не слишком помогают даже такие новые аппаратные технологии, как распределенные на кристалле кэши с обратной связью (reactive
distributed on-chip cache) (см., например, [A4, A1]) и/или наиболее развитые средства аппаратного упреждающего чтения (hardware prefetcher) (см., например, [A7]). Поскольку архитектура DORA основана на том, что большая часть обращений к любой заданной части данных происходит из некоторого заданного потока управления, мы ожидаем от нее более "дружеского" поведения, которое позволит использовать все потенциальные возможности современных аппаратных средств за счет обеспечения более частного и предсказуемого доступа к основой памяти.
В будущей работе мы планируем исследовать возможности архитектуры DORA на этих двух фронтах.
A.4. Внутритранзакционный параллелизм при наличии аварийных завершений транзакций
DORA спроектирована в расчете на использование внутритранзакционного параллелизма. Возможности межъядерного взаимодействия современных многоядерных процессоров, обеспечивающие низкие задержки и высокую пропускную способность, позволяют выполнению транзакций в DORA переходить из одного потока управления в другой поток с минимальными накладными расходами, поскольку каждая транзакция обращается к разным частям данных. Одной из проблем внутритранзакционного параллелизма являются транзакции с заметной интенсивностью аварийных завершений. Например, тестовый набор TM1 отличается тем, что в нем большая часть транзакций (∼25%) аварийно завершается из-за неверных входных данных. При выполнении таких рабочих нагрузок DORA может оборвать выполнение действий аварийно завершенных транзакций.
Имеются две стратегии, которым может следовать DORA при выполнении таких внутренне параллельных транзакций с высокой интенсивностью аварийных завершений. Первая стратегия состоит в продолжении параллельного выполнения таких транзакций и частых проверках аварийного завершения. Вторая стратегия заключается в сериализации выполнения. Другими словами, даже при наличии возможности параллельного выполнения действий таких транзакций DORA может проявить пессимизм и выполнять их последовательно. Эта стратегия гарантирует, что если некоторое действие завершится аварийным образом, то не пропадет впустую работа какого-либо другого параллельно выполняемого действия.
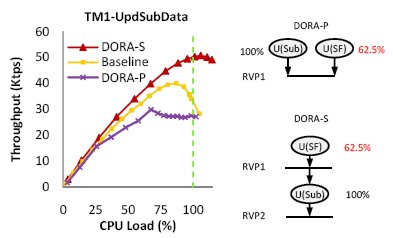
Рис. 11. Производительность при выполнении транзакции UpdateSubscriberData из тестового набора TM1, которой свойственна высокая интенсивность аварийных завершений.
На рис. 11 сравнивается пропускная способность базовой системы и двух вариантов DORA при возрастании числа клиентов, постоянно запрашивающих выполнение транзакции UpdateSubscriberData из тестового набора TM1. Эта транзакция, параллельный и последовательный графы потока которой изображены в правой части рисунка, состоит из двух независимых действий. Одно действие пытается обновить таблицу Subscriber и всегда успешно завершается. Другое действие пытается обновить соответствующий элемент таблицы SpecialFacility, и это удается ему в 62,5% случаев, а в остальных случаях приводит к аварийному завершению всей транзакции из-за неверных входных данных.
Мы представляем графики пропускной способности DORA при применении обеих стратегий выполнения транзакций. Параллельное выполнение обозначается как DORA-P, и последовательное выполнение, при котором сначала предпринимается попытка обновить SpecialFacility, и лишь в случае успешного завершения этого действия обновляется таблица Subscriber, обозначается как DORA-S. Как показывает рисунок, для этой рабочей нагрузки параллельное выполнение является плохим выбором. DORA-P демонстрирует худшую производительность даже по сравнению с базовой системой, в то время как DORA-S масштабируется, как и ожидалось.
Менеджер ресурсов DORA отслеживает интенсивность аварийных завершений транзакций целиком и индивидуальных действий каждого исполнителя. Если интенсивность аварийных завершений становится высокой, DORA переключается на использование планов последовательного выполнения путем расстановки точек рандеву между действиями одной и той же фазы. Тем не менее, остается проблемой применение оптимизаций, специфичных для транзакций DORA.
Литература к приложению
[A1] B. M. Beckmann, and D. A. Wood. Managing Wire Delay in Large Chip-Multiprocessor Caches. In Proc. MICRO, 2004.
[A2] C. Curino, Y. Zhang, E. Zones, and S. Madden. Schism: a Workload-Driven Approach to Database Replication and Partitioning. In Proc. VLDB, 2010.
Перевод на русский язык: Карло Курино, Эван Джонс, Янг Жанг и Сэм Мэдден. Schism: управляемый рабочей нагрузкой подход к репликации и разделению баз данных, 2010.
[A3] J. Gray, and A. Reuter. Transaction Processing: Concepts and Techniques. Morgan Kaufmann, 1993.
[A4] N. Hardavellas, M. Ferdman, B. Falsafi and A. Ailamaki. Reactive NUCA: Near-Optimal Block Placement and Replication in Distributed Caches. In Proc. ISCA, 2009.
[A5] S.-W. Lee, et al. A Case for Flash Memory SSD in Enterprise Database Applications. In Proc. SIGMOD, 2008.
[A6] S. Somogyi, et al. Memory Coherence Activity Prediction in Commercial Workloads. In Proc. WMPI, 2004.
[A7] S. Somogyi, T. F. Wenisch, A. Ailamaki, and B. Falsafi. Memory Coherence Activity Prediction in Commercial Workloads. In Proc. ISCA, 2009.
[A8] VoltDB. Developing VoltDB Applications.
5 Чтобы обеспечить наглядность диаграммы, выбраны небольшая конфигурация системы и умеренная рабочая нагрузка.
6 Это подтверждается тем, что производительность традиционных систем OLTP значительно повышается при использовании технологии хранения данных на основе флэш-накопителей, демонстрирующей высокую пропускную способность операций произвольного доступа к данным [A5].
Назад Содержание

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
