Schism: управляемый рабочей нагрузкой подход к репликации и разделению баз данных
Карло Курино, Эван Джонс, Янг Жанг и Сэм Мэдден
Перевод: Сергей Кузнецов
Оригинал: Carlo Curino, Evan Jones, Yang Zhang, Sam Madden. Schism: a Workload-Driven Approach to Database Replication and Partitioning. 36th International Conference on Very Large Data Bases, September 13-17, 2010, Singapore. Proceedings of the VLDB Endowment, Vol. 3, No. 1, 2010, pp. 48-57.
Содержание
- От переводчика: как хорошо разделить транзакционные данные?
- Аннотация
- 1. Введение
- 2. Общие сведения
- 3. Цена распределенности
- 4. Разделение и репликация
- Аннотация
- 5. Оптимизация и реализация
- 6. Экспериментальная оценка
- 7. Родственные работы
- 8. Заключение
- 9. Благодарности
- 10. Литература
- Приложения
- 8. Заключение
От переводчика: как хорошо разделить транзакционные данные?
Известно, что производительность параллельных систем баз данных, основанных на архитектуре sharing-nothing (без использования общих ресурсов между узлами), критически зависит от качества разделения данных между разными узлами. В аналитических параллельных СУБД критериями разделения являются балансировка нагрузки между узлами и оптимизация выполнения наиболее важных операций соединения.
А как разделять данные в транзакционных параллельных базах данных? В данном случае транзакции обычно короткие и включают смесь простых операций выборки и обновления данных. И в качестве критерия разделения авторы статьи выбирают минимизацию числа транзакций, затрагивающих данные, которые хранятся в разных узлах системы, т.е. являющихся распределенными. Авторы убедительно показывают, что накладные расходы на фиксацию распределенных транзакций значительно увеличивают время их выполнения (и тем больше, чем короче и проще транзакции).
В описываемом подходе полагается известной рабочая нагрузка транзакционной системы баз данных. Опираясь на знание рабочей нагрузки и традиционных характеристик используемой базы данных, авторы находят схему разделения (на основе графового представления рабочей нагрузки и базы данных), действительно минимизирующего число распределенных транзакций. Более того, по этой схеме строится набор таких условий вхождения атрибутов таблиц в диапазоны значения, что разделение базы данных на основе этих условий хорошо аппроксимирует схему, полученную путем разделения графа.
Хотя работа ориентирована на базы данных, хранящиеся в дисковой памяти, мне кажется, что она будет особенно полезна для транзакционных параллельных СУБД типа H-Store, в которых все разделы базы данных сохраняются в основной памяти узлов. Возможно, в этом случае придется несколько пересмотреть критерии репликации, поскольку в системах типа H-Store репликация требуется не только для повышения пропускной способности, но и для обеспечения высокого уровня доступности.
Сергей Кузнецов
Аннотация
Мы представляем Schism – новый, основанный на учете рабочей нагрузки подход к разделению и репликации, который разработан с целью повышения уровня масштабирования распределенных систем баз данных с архитектурой без совместно используемых ресурсов (shared-nothing). Поскольку в среде OLTP распределенные транзакции являются дорогостоящими (что мы демонстрируем с использованием ряда экспериментов), механизм разделения (partitioner) пытается минимизировать число распределенных транзакций, производя при этом сбалансированные разделы. Schism состоит из двух фаз: i) управляемая нагрузкой, основанная на использовании графов фаза репликации/разделения и ii) фаза толкования и валидации. На первой фазе создается граф, вершины которого соответствуют кортежам (или группам кортежей), а дуги соединяют вершины-кортежи, к которым обращается одна и та же транзакция. После этого механизм разделения расщепляет этот граф на k сбалансированных разделов, минимизируя число транзакций, обращающихся к данным из разных разделов (многораздельных транзакций). На второй фазе используются методы машинного обучения (machine learning) для нахождения основанного на предикатах толкования стратегии разделения (т.е. набора предикатов диапазонов значений (range predicate), представляющего такую же схему репликации/разделения, что и выданная механизмом разделения).Достоинствами Schism являются: i) независимость от вида схемы базы данных; ii) эффективность при работе со связями типа n-к-n, типичными в базах данных социальных сетей; iii) унифицированный и мелкоструктурный (fine-grained) подход к репликации и разделению. Мы реализовали прототип Schism и протестировали его с использованием широкого спектра тестовых наборов, от классических рабочих нагрузок OLTP (например, TPC-C и TPC-E) до более сложных сценариев, полученных с Web-сайтов социальных сетей (например, Epinions.com). В последнем случае в схеме базы данных имеется несколько связей n-к-n, которые, как известно, трудно поддаются разделению. Schism обеспечивает производительность, существенно превосходящую ту, которую можно достичь с использованием простых схем разделения, и в некоторых случаях обеспечивает более совершенные результаты, чем при использовании наилучших известных методов ручного разделения, что позволяет снизить стоимость выполнения распределенных транзакций на 30%.
1. Введение
Основным способом масштабирования систем баз данных за счет их выполнения на нескольких физических машинах является горизонтальное разделение (horizontal partitioning). За счет размещения разделов в разных узлах часто оказывается возможным достижение почти линейного возрастания скорости обработки запросов, в особенности, аналитических запросов, при обработке которых в узлах параллельно производится сканирование разделов. Кроме повышения уровня масштабируемости, разделение может способствовать и повышению уровня доступности, поскольку при отказе какого-либо узла некоторые транзакции по-прежнему можно выполнить над данными разделов, оставшихся доступными. Разделение также может повысить и уровень управляемости (manageability) системы баз данных, поскольку внесение апгрейтов в программное и аппаратное обеспечение узла и изменение его конфигурации можно производить для разных узлов по отдельности.Хотя исследовался ряд схем автматического разделения [1, 23, 18], наиболее распространенными подходами являются циклическое разделение (round-robin partitioning) (каждый следующий кортеж направляется в другой раздел), разделение по диапазонам (range partitioning) (кортежи разделяются в соответствии с набором предикатов диапазонов значений) и хэш-разделение (hash-partitioning) (каждому кортежу назначается раздел на основе его хэширования) [6]. Все эти подходы могут быть эффективными для поддержки выполнения аналитических запросов, когда приходится сканировать крупные наборы данных.
К сожалению, ни один из этих подходов не является идеальным при наличии рабочих нагрузок, которые состоят из небольших транзакций, затрагивающих всего несколько записей. Если транзакция обращается более к одному кортежу, то циклическое и хэш-разделения, как правило, приведут к потребности доступа к нескольким узлам. При выполнении распределенных транзакций производительность системы ниже, чем при выполнении локальных транзакций. Наши результаты, изложенные в разд. 3, показывают, что при обработке только локальных транзакций пропускная способность системы удваивается. Лучше может сработать разделение по диапазонам, но для этого нужно тщательно выбирать соответствующие диапазоны значений, что трудно делать вручную. Проблема разделения становится еще сложнее, если транзакции обращаются к нескольким таблицам, которые требуется разделять с учетом всех операций транзакций. Например, трудно разделять данные Web-сайтов социальных сетей, в схемах которых часто присутствует много связей n-к-n.
В этой статье мы представляем Schism – новую, основанную на использовании графов и управляемую данными систему разделения для транзакционных рабочих нагрузок. При использовании Schism база данных и рабочая нагрузка представляются в виде графа, в котором кортежам соответствуют вершины, а дуги связывают кортежи, используемые внутри одной транзакции. Затем мы применяем алгоритмы разделения графов для нахождения сбалансированного разделения, минимизирующего число многораздельных транзакций. Schism позволяет регулировать степень балансировки разделов в зависимости от характеристик рабочей нагрузки и размера базы данных, а также создавать разделы, содержащие записи нескольких таблиц.
Вкладом этой статьи, кроме описания нового метода разделения, основанного на использовании графов, является следующее:
- Мы демонстриуем, что пропускная способность при выполнении небольших распределенных транзакций значительно уступает пропускной способности при выполнении транзакций в одном узле.
- Мы демонстриуем способность Schism к репликации нечасто обновляемых записей. Это позволяет повысить долю в рабочих нагрузках "одноузловых" ("single-sited") транзакций (работающих в пределах только одного узла). В отличие от существующих методов разделения, в этом случае оказывается возможным реплицировать только часть таблицы.
- Мы представляем схему, основанную на деревьях решений (decision tree) для выявления предикатов (диапазонов), которые "растолковывают" разделение, обнаруженное графовыми алгоритмами.
- Мы показываем, что при работе с крупными наборами данных Schism разделяет их за приемлемое время. Для разделения базы данных из миллионов записей требуется всего несколько минут. Мы также предлагаем и оцениваем эвристики, включающие взятие образцов (sampling) и группировку кортежей, которые позволяют сократить размер графов для снижения времени разделения.
- Наконец, мы демонстрируем, что Schism может найти хорошие разделения для нескольких актуальных приложений, систематически выполняя такую работу не хуже или даже лучше хэш-разделения и разделения по диапазонам вручную. В наиболее сложном протестированном нами случае (сложный граф социальной сети со связями n-к-n) подход Schism обеспечил производительность, превосходящую производительность, которой удалось добиться при разделении вручную. Стоимость выполнения распределенных транзакций удалось сократить на дополнительные 30%.
Хотя в этой статье наш подход к разделению применяется к дисковым системам баз данных, основанным на архитектуре без совместно используемых ресурсов, он применим и в других случаях, включая системы баз данных в основной памяти типа H-Store [21], производительность которых сильно зависит от соответствия разделения базы данных имеющейся рабочей нагрузке, и автоматическое создание "кусочных" ("sharded") баз данных, для которых важно минимизировать число соединений между "кусочками".
Оставшаяся часть статьи организована следующим образом: в разд. 2 мы представляем общие сведения о своем подходе, в разд. 3 обсуждаем стоимость выполнения распределенных транзакций, в разд. 4 представляем ключевые идеи своей работы, в разд. 5 обсуждаем проблемы реализации и оптимизации, в разд. 6 приводим экспериментальное обоснование, в разд. 7 сравниваем свой подход с родственными работами и, наконец, в разд. 8 приводим свои выводы.
2. Общие сведения
На входе наша система получает базу данных, некоторое представление рабочей нагрузки (например, трассу SQL) и число требуемых разделов. На выходе получается стратегия разделения и репликации, балансирующая размеры разделов и минимизирующая общие ожидаемые расходы на выполнение рабочей нагрузки. Как мы увидим в следующем разделе, для рабочих нагрузок OLTP ожидаемые расходы прямо связаны с числом распределенных транзакций в рабочей нагрузке. Основной подход состоит из следующих пяти шагов.- Предварительная обработка данных: На основе входной трассы рабочей нагрузки система вычисляет наборы чтения и записи каждой транзакции.
- Создание графа: Создается графовое представление базы данных и рабочей нагрузки. Для каждого кортежа в этом графе создается вершина. Дуги представляют использование кортежей внутри транзакций. Две вершины-кортежа соединяются дугой, если к ним производится доступ в одной и той же транзакции. Как отмечается в разд. 4, простое расширение этой модели позволяет нам установить, какие кортежи следует реплицировать.
- Разделение графа: Алгоритм разделения графа используется для получения сбаланированного разделения с минимальными разрывами (balanced minimum-cut partitioning) графа на k разделов. Каждый кортеж приписывается к одному разделу (т.е. это разделение на уровне кортежей (per-tuple partitioning), и каждый раздел приписывается к одному физическому узлу.
-
Толкование разделения: Система анализирует операторы во входной трассе для формирования списка атрибутов, часто используемых в разделах
WHEREдля каждой таблицы; этот список мы называем набором часто используемых атрибутов (frequent attribute set). Используется алгоритм деревьев решений для извлечения набора правил, компактным образом представляющих полученное разделение на уровне кортежей. Эти правила представляют собой предикаты на значениях набора часто используемых атрибутов, которые производят отображение кортежей в номера разделов. Мы называем это разделением на основе предикатов диапазонов значений (range-predicate partitioning). - Заключительная валидация: С использованием в качестве показателя стоимости разделения общего числа распределенных транзакций сравнивается стоимость графового разделения на уровне кортежей и разделения на основе предикатов диапазонов значений со стоимостью хэш-разделения и разделения на уровне таблиц. Выбирается наилучшая стратегия, а в случае совпадения стоимости нескольких стратегий выбирается самая простая из них.
Результирующее разделение можно (i) напрямую использовать в СУБД, поддерживающей разделение данных в распределенной архитектуре без совместно используемых ресурсов, (ii) явным образом закодировать в приложении или (iii) реализовать в маршрутизирующем компоненте промежуточного программного обеспечения типа того, которое мы использовали для тестирования Schism.
3. Цена распределенности
Прежде, чем описывать детали своего подхода к разделению, мы представим серию экспериментов, которые мы выполнили для измерения стоимости распределенных транзакций. Эти результаты показывают, что распределенные транзакции являются дорогостоящими, и что нахождение правильного разделения критически важно для достижения хорошей производительности распределенной системы баз данных OLTP.В распределенной системе баз данных без общих ресурсов транзакции, обращающиеся к данным только одного узла, выполняются без дополнительных накладных расходов. Операторы этой транзакции обрабатываются над одной базой данных, а в завершение выполняются команды фиксации (commit) или аварийного завершения (abort). Однако если операторы распределяются по нескольким узлам, то для обеспечения атомарности и сериализуемости транзакций требуется использование двухфазной фиксации (two-phase commit) или какого-либо аналогичного распределенного протокола согласования. Это приводит к появлению дополнительных сетевых сообщений, снижению пропускной способности, увеличению задержки и потенциальному появлению распределенных тупиковых ситуаций. Поэтому мы хотим избегать распределенных транзакций.
Для количественной оценки влияния распределенных транзакций мы выполнили простой эксперимент с использованием MySQL. Мы создали таблицу simplecount с двумя столбцами целого типа: id и counter. Клиенты в одной транзакции читают две строки, выдавая два запроса вида SELECT * FROM simplecount WHERE id = ?. Каждый запрос возвращает одну строку. Мы исследовали производительность двух стратегий: (i) каждая транзакция выполняется на одном сервере и (ii) каждая транзакция распределяется между несколькими машинами с использованием поддерживаемой MySQL двухфазной фиксации (XA-транзакции) и нашего собственного координатора распределенных транзакций.
Каждый клиент выбирал строки случайным образом в соответствии с одной из этих стратегий и после получения ответа немедленно посылал следующий запрос. Мы тестировали эту рабочую нагрузку на вычислительном комплексе, включавшем до пяти серверов. См. подробное описание нашей экспериментальной конфигурации в Приложении A. Мы использовали 150 одновременно функционирующих клиентов, чего было достаточно для насыщения процессоров всех пяти серверов. Таблица simplecount содержала 150000 строк (по тысяче на каждого клиента), так что база данных полностью помещалась в буферных пулах наших серверов (128 мегабайт). Это имитировало рабочую нагрузку над базой данных, располагаемой в основной памяти, что не является редкой ситуацией для OLTP.
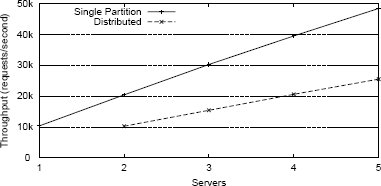
Рис. 1. Пропускная способность распределенных транзакций.
В идеальном мире локальные и распределенные транзакции в этом тесте достигали бы схожей производительности, поскольку они обращаются к одному и тому же числу записей с использованием одного и того же числа операторов. Однако результаты эксперимента, показанные на рис. 1, показывают, что распределенные транзакции оказывают большое влияние на пропускную способность, снижая ее почти в два раза. Поскольку фиксация распределенной транзакции задевает всех ее участников, возрастает и задержка. В этом эксперименте для распределенных транзакций средняя величина задержки примерно в два раза больше, чем у одноузловых транзакций. Например, при наличии пяти серверов задержка одноузловой транзакции составляет 3,5 микросекунды, а распределенной транзакции – 6,7 микросекунд. Мы выполняли аналогичные эксперименты с другими сценариями, включая обновляющие транзакции и транзакции, обращающиеся к большему числу кортежей, и результаты были аналогичными.
Реальные приложения OLTP намного сложнее этого простого эксперимента, потенциально включая: (i) конкуренцию транзакций за одновременный доступ с блокировкой к одним и тем же строкам – как мы увидим в TPC-C подразделе 6.3, (ii) распределенные тупиковые ситуации и (iii) сложные операторы, для выполнения которых требуются данные с нескольких серверов, например, распределенные соединения. Все это еще больше снижает пропускную способность системы при выполнении распределенных транзакций. С другой стороны, при выполнении более дорогостоящих транзакций меньше ощущается влияние распределенности, поскольку большой объем работы, выполняемой локально, затмевает стоимость обработки дополнительных сообщений двухфазной фиксации.
Schism разрабатывается в расчете на приложения OLTP и Web-приложения. Для таких рабочих нагрузок вывод состоит в том, что минимизация числа распределенных транзакций при балансировке нагрузки между узлами способствует значительному повышению транзакционной пропускной способности.