Выполнение транзакций, ориентированное на данные
Иппократис Пандис, Райан Джонсон, Никос Харадавеллас и Анастасия Айламаки
Перевод: Сергей Кузнецов
Оригинал: Ippokratis Pandis, Ryan Johnson, Nikos Hardavellas, Anastasia Ailamaki. Data-Oriented Transaction Execution. 36th International Conference on Very Large Data Bases, September 13-17, 2010, Singapore. Proceedings of the VLDB Endowment, Vol. 3, No. 1, 2010, pp. 928-939.
Содержание
- Почти "shared-nothing" в среде "shared-everything" – от переводчика
- Аннотация
- 1. Введение
- Аннотация
- 2. Родственные работы
- 3. Менеджер блокировок как источник конкуренции
- 4. Ориентированная на данные архитектура для поддержки OLTP
- 3. Менеджер блокировок как источник конкуренции
- 5. Оценка производительности
- 6. Заключение
- 7. Благодарности
- 8. Литература
- A. Приложение
- 7. Благодарности
Почти "shared-nothing" в среде "shared-everything" – от переводчика
В последнее время специалисты в области баз данных больше всего говорят про архитектуры параллельных СУБД без совместного использования ресурсов, ориентированные на поддержку как аналитических, так и транзакционных приложений. Это, в частности, подтверждается выборкой статей, переводы которых были опубликованы в библиотеке CITForum в последние несколько лет. Активный интерес к архитектурам shared-nothing естественным образом объясняется возможностями неограниченного горизонтального масштабирования аппаратных средств за счет использования кластерных систем, в узлах которых применяются компьютеры из категории товаров широкого потребления (commodity).Но задумаемся, что такое сегодня "компьютер массового спроса"? Этот компьютер снабжается, как минимум, двухъядерным (а завтра четырехъядерным, а послезавтра восьмиядерным) процессором, в ядрах которого на аппаратном уровне поддерживается выполнение нескольких потоков управления. Т.е. это мощная параллельная машина, и не использовать ее параллелизм для поддержки локальных СУБД, входящих в состав параллельной СУБД без совместного использования ресурсов, по меньшей мере, безнравственно, а по большому счету, экономически нецелесообразно.
Кроме того, на переднем крае развития микропроцессорной технологии находятся такие процессоры, как использованный в работе авторов представляемой вам статьи процессор Sun T5220 "Niagara II", уже сегодня обеспечивающий (с точки зрения операционной системы) 64-процессорную систему с общей памятью. При наличии правильно спроектированной СУБД мощности "однопроцессорной" системы, оснащенной таким процессором (а послезавтра процессором "массового спроса"), хватит для поддержки системы OLTP не самого мелкого предприятия.
Так что развитие технологии СУБД, выполняемых на машинах с общим использованием всех ресурсов, является очень актуальной задачей. Однако, как показывают авторы статьи, по мере роста числа ядер и совершенствования реального использования параллелизма в СУБД узким местом становится традиционный централизованный менеджер блокировок. В представленной авторами архитектуре DORA эта проблема решается путем логического разделения таблиц базы данных по потокам управления. В каждом таком потоке управления (исполнителе) выполняются части транзакций (действия), обращающиеся только к данным соответствующего раздела, и логическая синхронизация доступа большей частью рассредоточена по исполнителям.
Иначе говоря, на основе аппаратной архитектуры с совместным использованием всех ресурсов строится архитектура СУБД, в которой на логическом уровне общие ресурсы не используются, хотя сам этот логический уровень реализуется с использованием общих ресурсов. Авторы особо подчеркивают, что именно наличие физической общности ресурсов позволяет добиться эффективности предлагаемой ими архитектуры СУБД.
Результаты экспериментов, приводимые в статье, убедительно показывают, что архитектура DORA обеспечивает производительность OLTP-ориентированной СУБД, существенно превосходящую производительность традиционных систем, в которых используются традиционные централизованные менеджеры блокировок. Однако при наличии массы технических подробностей (временами скрывающих суть архитектуры) некоторые важные, на мой взгляд, проблемы в статье затушевываются.
Во-первых, как и для всех архитектур с разделением данных (неважно, физических или логических) проблемой является выбор способа разделения (в статье соответствующие правила называются правилами маршрутизации). Авторы говорят об этих правилах, как о чем-то данном им свыше, хотя иногда говорится, что они могут меняться при работе системы. Как они будут меняться, в соответствии с каким критериями, остается непонятно.
Второе непонятное для меня место касается работы с индексами. Из контекста статьи понятно, что индексы организуются в виде B+-деревьев. Понятно, что для рабочих нагрузок OLTP, транзакции которых читают и изменяют считанные единицы записей, поиск в B+-дереве и особенно изменение B+-дерева могут составлять значительную часть работы, которую тоже было бы желательно распараллеливать. Однако в статье этот аспект полностью умалчивается.
Поскольку авторы статьи продолжают работу над DORA, очень может быть, что в будущих публикациях эти и другие темные места будут разумным образом прояснены. Пока же очевидно, что DORA прокладывает путь системам управления базами данных в будущий (не столь уж отдаленный) мир со сто- или даже тысячеядерными процессорами. И слава Богу, что становятся более понятными способы их использования.
Сергей Кузнецов
Аннотация
Хотя в последнее десятилетие технология компьютерной аппаратуры подверглась значительному развитию, системы обработки транзакций остались, в основном, неизменными. Следуя закону Мура, экспоненциально возрастает число ядер в чипе, что позволяет параллельно выполнять постоянно увеличивающееся число транзакций. По мере возрастания этого числа препятствием к масштабируемости становятся конфликтующие критические участки (critical section). В типичной системе обработки транзакций конфликтующим компонентом и фактором, ограничивающим масштабирование, прежде всего, является менеджер блокировок.В этой статье мы устанавливаем, что основной причиной конфликтов является традиционная политика назначения каждой транзакции своего потока управления. Затем мы описываем архитектуру системы DORA, которая разбивает транзакции на более мелкие действия и назначает действия потокам управления на основе того, к каким данным, вероятно, обратится каждое действие. Конструктивное решение DORA позволяет каждому потоку управления в основном обращаться к структурам данным, локальным для этого потока, что минимизирует чреватые конфликтами обращения к централизованному менеджеру блокировок. DORA строится поверх традиционного механизма хранения данных и поддерживает все свойства ACID. Экспериментальная оценка прототипной реализации DORA на многоядерной системе при прогонах различных искусственных и реальных рабочих нагрузок показали, что DORA обеспечивает производительность, более чем в 4,8 раз превышащую производительность современных механизмов хранения данных.
1. Введение
Снижающийся эффект повышения внутрикристальной частоты вкупе с ограничениями потребления энергии и отвода тепла заставляют поставщиков аппаратных средств размещать в одном кристалле несколько процессорных ядер и полагаться на параллелизм на уровне потоков управления для повышения производительности. В сегодняшних многоядерных процессорах в одном восьмиядерном чипе поддерживается 64 аппаратных контекста1, и спросом пользуются многоядерные процессоры с еще большим числом контекстов, ориентированные на специализированное использование. Эксперты из индустрии и академии предсказывают, что число ядер в одном кристалле будет возрастать в соответствии с законом Мура, т.е. в геометрической прогрессии.По мере экспоненциального роста числа аппаратных контекстов в одном чипе становится возможно параллельно выполнять небывалое число потоков управления, конкурурирующих за доступ к совместно используемым ресурсам. Приложениям, распараллеливаемым на уровне потоков управления, таким как приложения оперативной обработки транзакций (online transaction processing, OLTP), свойственны все более длительные задержки при вхождении в сильно конфликтные критические участки (critical section), что отрицательно влияет на производительность [14]. Для полезного использования вычислительной мощности многоядерных процессоров необходимо ослабить влияние таких конфликтных узких мест в программных системах и добиться соразмерного возрастания производительности при росте числа ядер.
OLTP необходима для большинства предприятий. В последние десятилетия системы обработки транзакций превратились в сложные программные системы, базы кода которых включают миллионы строк. Однако со времени зарождения таких систем почти неизменными остались основные принципы их разработки. При обработке транзакций имеется множество критических участков [14]. Поэтому при использовании высокопараллельной аппаратуры таким системам свойственны проблемы производительности и масштабирования. Чтобы справиться с проблемами масштабируемости, исследователи предлагают использовать конфигурации без совместного использования ресурсов [6] в одном чипе [21] и/или отказываться от каких-либо свойств ACID [5].
1.1. Поток управления для транзакции или поток управления для данных?
В этой статье мы утверждаем, что основной причиной проблемы конфликтов являются некоординированные обращения к данным, характерные для традиционных систем обработки транзакций. В этих системах каждой транзакции назначается некоторый рабочий поток управления; этот механизм мы называем назначением потоков управления транзакциям. Поскольку каждая транзакция выполняется в отдельном потоке управления, потоки управления конфликтуют между собой при доступе к совместно используемым данным.Схемы доступа к данным у каждой транзакции и, следовательно, у каждого потока управления являются произвольными и некоординированными. Для обеспечения целостности данных каждый поток управления при выполнении соответствующей транзакции на короткое время входит в большое число критических участков. Однако для входа в критический участок и выхода из него требуется закрытие и открытие соответствующей "защелки" (latch), и накладные расходы на совершение этих действий возрастают при росте числа параллельных потоков управления.
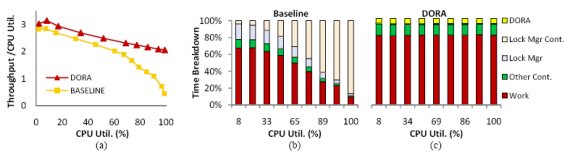
Рис. 1. DORA в сравнении с традиционной системой при рабочей нагрузке, состоящей из транзакций GetSubscriberData тестового набора TM1: (a) пропускная способность в соответствии с коэффициентом использования процессора при возрастании этого коэффициента; (b) распределение времени традиционной системы; (c) распределение времени прототипа DORA.
Чтобы можно было оценить влияние на производительность накладных расходов на конкуренцию за вход в критические участки, на рис. 1(a) показана производительность традиционного менеджера хранения данных в соответствии с коэффициентом использования процессора при возрастании этого коэффициента. Рабочая нагрузка основана на клиентах, постоянно запускающих транзакции GetSubscriberData из эталонного тестового набора TM1 (подробности об используемой методологии см. в разд. 5). По мере возрастания коэффициента использования машины производительность системы в соответствии с этим коэффициентом падает. При использовании всех 64 аппаратных контекстов производительность в расчете на один контекст падает более чем на 80%. Как показывает рис. 1(b), в общем времени работы системы быстро начинает доминировать конкуренция внутри менеджера блокировок. Каждый из 64 аппаратных контекстов тратит более 85% своего времени выполнения на потоки управления, ожидающие входа в критические участки внутри менеджера блокировок.
Основываясь на том наблюдении, что некоординированный доступ к данным приводит к высокому уровню конкуренции, мы предлагаем для снижения этого уровня архитектуру системы, ориентированную на данные (data-oriented architecture, DORA). Вместо связывания каждого потока управления с некоторой транзакцией, в DORA каждый поток управления связывается с некоторой отдельной частью базы данных. Транзакции переходят из одного потока управления в другой поток, когда им требуется обращаться к другим данным; мы называем этот механизм назначением потоков управления данным. DORA разбивает транзакции на более мелкие действия в соответствии с тем, к каким данным они обращаются, и направляет их для выполнения в соответствующие потоки управления. По сути, вместо "вытягивания" (pull) данных (записей базы данных) к вычислениям (транзакциям) DORA распределяет вычисления в соответствии с отображением данных на потоки управления.
В системе, основанной на назначении потоков управления данным, можно использовать регулярные паттерны доступа к данным, что снижает нагрузку конфликтующих компонентов. В DORA каждый поток управления координирует доступ к своей части данных с использованием частного механизма блокировок. За счет ограничения взаимодействий потоков управления с централизованным менеджером блокировок DORA устраняет конкуренцию внутри него (рис. 1(с)) и обеспечивает лучшую масштабируемость (рис 1(a)).
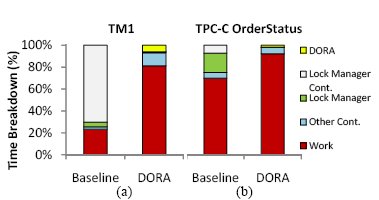
Рис. 2. Распределение времени традиционной системы обработки транзакций и прототипа DORA при полном использовании всех 64 аппаратных контекстов чипа Sun Niagara II при пропуске (a) тестового набора TM1 и (b) транзакций OrderStatus тестового набора TPC-C.
В DORA используется высокопропускной механизм коммуникаций с малыми задержками между ядрами многоядерной системы. Транзакции переходят от одного потока управления к другому потоку с минимальными накладными расходами, поскольку в каждом потоке управления производится доступ к отдельной части базы данных. На рис. 2 сравнивается распределение времени традиционной системы управления транзакциями и прототипной реализации DORA при использовании всех 64 аппаратных контекстов чипа Sun Niagara II при пропуске тестового набора TM1 компании Nokia и транзакций OrderStatus тестового набора TPC-C [20]. В прототипе DORA устраняется конкуренция в менеджере блокировок (рис. 2(a)). Кроме того, централизованное управление блокировками заменяется облегченным механизмом блокирования, локальным для потоков управления (рис. 2(b)).
1.2. Вклад и организация статьи
Вкладом статьи является следующее:- Мы демонстрируем, что традиционное назначение потоков управления транзакциям приводит к конкуренции в менеджере блокировок, что значительно ограничивает производительность и масштабируемость OLTP в многоядерных системах.
- Мы предлагаем ориентированную на данные архитектуру OLTP, которая обнаруживает предсказуемые схемы доступа к данным и позволяет заменить тежеловесный централизованный менеджер блокировок легковесным механизмом блокировок, локальным для потоков управления. Результатом является система с совместным использованием всех ресурсов (shared-everything), масштабируемая до большого числа ядер без ослабления свойств ACID.
- Мы оцениваем протитипный механизм обработки транзакций DORA и показываем, что он позволяет достичь пиковой производительности, на 82% превышающей пиковую производительность традиционного менеджера хранения данных. При отсутствии контроля доступа (admission control) выигрыш в производительности DORA может достичь более 4,8 раз. Кроме того, в неполностью нагруженном состоянии DORA обеспечивает сокращение времени ответа на 60%, поскольку используется внутритранзакционный параллелизм, естественный для многих транзакций.
Оставшаяся часть статьи организована следующим образом. В разд. 2 обсуждаются родственные работы. В разд. 3 объясняется, почему традиционная система обработки транзакций может испытывать трудности из-за конкуренци внутри своего менеджера блокировок. В разд. 4 представляется DORA – арихитектура, основанная на назначении потоков управления данным. В разд. 5 оценивается производительность протитипа DORA, и в разд. 6 содержатся заключительные выводы.
2. Родственные работы
Накладные расходы блокировок – это хорошо известная проблема даже однопотоковых систем. Харизопулос (Harizopoulos) и др. [9] анализируют поведение однопотокового менеджера хранения данных SHORE [3] при пропуске двух транзакций из тестового набора TPC-C. При пропуске транзакции Payment система тратит 25% времени на выполнение кода, имеющего отношение к блокировкам, а при пропуске транзакции NewOrder – 16%. Мы подтверждаем эти результаты и раскрываем скрытую проблему конкуренции за защелки, которая делает менеджер блокировок узким местом при возрастании уровня аппаратного параллелизма.
Организация параллельной системы баз данных Rdb/VMS [16] оптимизирована в расчете на устранение узкого места при коммуникации узлов. Чтобы сократить стоимость сетевых передач запросов блокировок, в Rdb/VMS логическая блокировка удерживается в том узле, который ее последним использовал, до тех пор, пока этот узел не возвратит ее узлу-владельцу, или пока не поступит запрос от другого узла. Система Cache Fusion [17], используемая в Oracle RAC, позволяет в кластерах с совместно используемыми дисками объединять буферные пулы узлов и сокращать число обращений к совместно используеым дискам. Подобно тому, как это делается в DORA, Cache Fusion не разделяет данные физическим образом, а распределяет логические блоки. Однако ни в Rdb/VMS, ни в Cache Fusion не затрагивается проблема конкуренции. Большое число потоков управления может обращаться в одно и то же время к одним и тем же ресурсам, что приводит к плохой масштабируемости. В DORA обеспечивается обращение к большинству ресурсов только в некотором одном потоке управления.
В традиционной системе потенциально можно было бы добиться наличия функциональных возможностей DORA, если бы в каждом потоке управления, выполняющем некоторую тразакцию, удерживалась монопольная блокировка некоторой области записей. Монопольная блокировка ассоциируется с потоком управления, а не с какой-либо транзакцией, и удерживается для нескольких транзакций. Для реализации такого поведения можно было бы использовать разделительные ключи (separator key) [8].
Метод спекулятивного наследования блокировок (speculative lock inheritance, SLI) [13] выявляет во время выполнения "ходовые" ("hot") блокировки, и эти блокировки могут удерживаться потоками управления, выполняющими транзакции, для нескольких транзакций. Как и DORA, SLI снижает конкуренцию в менеджере блокировок. Однако этот метод не позволяет существенно сократить другие накладные расходы внутри менеджера блокировок.
Достижения в области технологии виртуальных машин [2] позволяют применять в многоядерных установках системы без совместного использования ресурсов (shared-nothing). В конфигурациях без совместно используемых ресурсов база данных разделяется на физическом уровне, и имеется репликация как команд, так и данных. Для транзакций, затрагивающих несколько разделов, требуется применять распределенные алгоритмы консенсуса. В H-Store [21] подход отказа от совместного использования ресурсов доводится до крайности за счет использования набора однопотоковых серверов, которые последовательно обрабатывают запросы, избегая управления параллелизмом. В то же время Джонс (Jones) и др. [15] исследуют "спекулятивную" схему блокировок для H-Store, которая может применяться для рабочих нагрузок с многораздельными транзакциями. Значительными проблемами систем без совместного использования ресурсов являются сложность координации распределенных транзакций [11, 5] и неустойчивость, вызываемая "скошенными" (skewed) данными или запросами. Архитектура DORA с совместным использованием всех ресурсов менее чуствительна к таким проблемам и может легче адаптироваться к изменениям нагрузки. В приложении мы обсуждаем, в чем выигрывает DORA от возможности совместного использования ресурсов.
У систем баз данных с поэтапной обработкой запросов (staged database system) [10] имеются общие черты с подходом DORA. Такая система расщепляет запросы на несколько запросов, которые могут выполняться параллельно. Это расщепление ориентируется на операции и рассчитано на использование конвейерного параллелизма. Однако конвейерный параллелизм мало подходит для типичных рабочих нагрузок OLTP. С другой стороны, аналогично системам с поэтапной обработкой запросов, используются возможности разделения работы путем посылки родственных запросов в одну и ту же очередь. В будущих исследованиях мы постараемся изучить возможности межтранзакционных оптимизаций.
В DORA для снижения уровня конкуренции используется внутритранзакционный параллелизм. Внутритранзакционный параллелизм является темой исследований в течение более двух десятилетий (см., например, [7]). Колохэн (Colohan) и др. [4] используются для параллельного выполнения транзакций спекуляцию на уровне потоков управления. Они демонстрируют потенциал внутритранзакционного параллелизма, достигая времени ответа, на 75% меньшего, чем у традиционной системы. Однако спекуляция на уровне потоков управления – это метод, основанный на аппаратуре, и недоступный в сегодняшних аппаратных средствах. Для поддержки механизма DORA требуются только быстрые коммуникации между ядрами, которые уже поддерживаются в аппаратуре многоядерных процессоров.
1 В современных процессорных ядрах имеется несколько аппаратных контекстов, позволяющих им перемежать выполнение нескольких потоков команд.