2008 г.
Обзор алгоритмов MOLAP
Юрий Кудрявцев, факультет ВМиК МГУ
Вперед: Общие стратегии вычисления кубов
Выше: Введение. Анализ задачи
Назад: Виды запросов к кубам
Содержание
Подразделы
Основными задачами, возникающими при хранении OLAP-данных, считаются хранение разреженных данных и эффективный расчет экспоненциального количества агрегатов, возникающих при добавлении фактических данных (так называемый "взрыв данных", см. [17]).
Представление неопределенных данных
Одним из важнейших свойств OLAP-систем считается эффективное хранение ''неопределенных данных'' (см.
12 Признаков OLAP Данных), поскольку создание многомерных структур порождает появление большого числа точек многомерного пространства, не содержащих значений мер. Например, при формировании куба появляются точки, для которых не было фактических данных, вроде (R2, весна, еда) в примере
4.1.
В рассматриваемых ниже алгоритмах, как и во многих других, предлагается следующее решение: не хранить неопределенные значения и, в случае отсутствия данных в кубе, возвращать нулевые значения.
Однако данная проблема схожа с проблемой NULL-значений в базах данных. Возможны следующие случаи отсутствия данных в кубе:
- данных быть не может, значение не может
существовать;
- нулевые данные;
- данные еще не получены, необходимо
использовать некую формулу для получения
значения.
Оставим без рассмотрения случай 3, несмотря на то, что он очень важен для анализа (например, если пользоваться прогнозированием с поквартальным уточнением факта).
В первых двух случаях возникает следующая ситуация — отсутствие данных в кубе означает следующее: либо они нулевые, либо их быть не может. Разница между данными понятиями становится очевидной при необходимости применения функции Average(), т.к. от данного понятия зависит величина Count() (если магазин рапортовал о нулевых продажах товара, он все равно должен попасть в число магазинов, товар продававших).
Данный момент очень важен для построения корректной системы анализа, и, к сожалению, ни в одном из рассмотренных ниже алгоритмов ему не уделено должное внимание.
При добавлении исходных данных в куб объем данных и время вычисления куба растут экспоненциально, так как необходимо рассчитывать агрегаты по каждому из измерений. Например, десятимерный куб без иерархии внутри измерений с размерностью 100 для каждого измерения приводит к структуре со
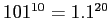 ячейками. Даже если мы положим разреженность 1 к
ячейками. Даже если мы положим разреженность 1 к 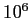 (т.е. пусть только одна из миллиона ячеек содержит данные), куб все равно будет иметь
(т.е. пусть только одна из миллиона ячеек содержит данные), куб все равно будет иметь 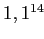 непустых ячеек. Если пустые значения достаточно легко сжимаются, то "взрывом данных" называют рост количества агрегатов по всем измерениям, которые необходимо вычислить. Т.е. добавление одной ячейки в куб с 10 измерениями, содержащими итоги, приводит к необходимости посчитать
непустых ячеек. Если пустые значения достаточно легко сжимаются, то "взрывом данных" называют рост количества агрегатов по всем измерениям, которые необходимо вычислить. Т.е. добавление одной ячейки в куб с 10 измерениями, содержащими итоги, приводит к необходимости посчитать 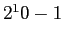 итоговых агрегатов (для устранения подобных cитуаций в каждом из алгоритмов используются специальные техники, к примеру, condensed-ячейки в алгоритме Condensed Cube).
итоговых агрегатов (для устранения подобных cитуаций в каждом из алгоритмов используются специальные техники, к примеру, condensed-ячейки в алгоритме Condensed Cube).
Главным свойством OLAP-систем считается возможность эффективно отвечать на запросы. Одной из мер повышения эффективности выполнения запросов является материализация кубов, а не вычисление их ''на лету'' (вычисление агрегаций непосредственно во время обработки запроса).
Считается стандартным представление куба в виде
так называемой структуры (cube lattice, см. также Quotient Cube)
— графа, в котором узлы определяют
представления (view) для ответа на запрос. Для каждого узла пометка обозначает
измерения, по которым в представлении имеются
фактические данные, по значениям ALL производится агрегация.
На рис. 1.2 показана структура куба из примера 1.1.
Таким образом, в получившейся структуре куба материализуется набор представлений, содержащий агрегированные данные. Подобные представления также называются подкубами (cuboids). Ячейки базового подкуба называются также базовыми ячейками, ячейки других подкубов называются агрегированными ячейками.
Выбор подкубов для материализации определяет будущую производительность системы. Мы можем получить набор представлений, при использовании которого для выполнения запросов будет не производиться более 1-2 агрегаций (по одному измерению), что означает очень быстрый ответ на запрос. И наоборот, возможна ситуация, в которой для ответа на запрос необходимо будет создавать все агрегации от фактических данных (базового куба). Однако количество подкубов экспоненциально зависит от количества измерения (как 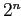 , где n — количество измерений), поэтому для полной материализации может требоваться огромный объем памяти и места на жестком диске.
, где n — количество измерений), поэтому для полной материализации может требоваться огромный объем памяти и места на жестком диске.
Изучение алгоритмов полной материализации помогает в расчетах индивидуальных подкубов, которые в дальнейшем можно хранить на второстепенных носителях, или же создавать полные кубы на основе подмножества измерений и осуществлять детализацию (drill-down) в исходные данные в случае необходимости. Подобные алгоритмы должны быть масштабируемыми, примимать во внимание ограниченное количество оперативной памяти, время вычисления и общий размер расчитанных данных.
Частичная материализация предлагает выбор между временем создания кубов и размером хранимых данных, с одной стороны, и временем отклика, с другой. Вместо вычисления полного куба мы можем вычислить лишь некоторые из его подкубов или даже частей подкубов.
Множество работ посвящено выбору набора представлений (подкубов) для материализации, из которых необходимо выделить [9], где впервые была приведена модель оценки стоимости материализации представлений и создания агрегаций. На базе подобных оценок создан алгоритм материализации представлений, оптимизирующий запросы по стоимости. Однако применимость алгоритма [9] и многих последующих алгоритмов сильно ограничена (например типами запросов, распределением данных, структурой куба и пр.). Ограничения накладываются самими авторами, за счет чего часто создаются эффективные алгоритмы. Доказано, что общая проблема выбора представлений для материализации NP-полна [10].
Многие ячейки кубов могут не представлять интереса для аналитиков, так как данные в них пренебрежимо малы. Подобная ситуация часто возникает, так как данные разреженно распределены в многомерном пространстве куба. К примеру, клиент покупает каждый раз лишь несколько товаров в одном магазине. Подобное событие будет отражено в виде набора ячеек с малыми показателями мер (объем покупки, количество предметов). В таких случаях полезно предвычислять лишь ячейки со значением меры, большим определенной границы. К примеру, нас будут интересовать лишь покупки на сумму свыше 500 рублей. Такой подход позволяет точнее сфокусировать анализ, не говоря о сокращении времени вычисления и времени отклика. Подобные частично вычисленные кубы называются кубами-айсбергами (англ. iceberg cubes), так как представляют собой вершину айсберга, большая часть которого скрыта под водой. Такие кубы создаются запросами
типа Iceberg (см.
Обратные запросы).
Простым представляется слежующий подход к вычислению кубов-айсбергов: сначала вычислить весь куб, затем применить условие и отрезать неудовлетворяющие ячейки. Однако это слишком расточительный подход, необходимо вычислять куб-айсберг, не вычисляя полный куб. Подробному анализу методов вычисления таких кубов посвящен раздел Вычисление Iceberg кубов.
Однако даже использование ограничений на значение меры может приводить к ситуациям, требующим бессмысленных повторных вычислений. К примеру, в 100-мерном кубе существуют всего 2 ячейки, отличающиеся по значениям одного из измерений. Если меры в этих ячейках больше заданной границы, то будут порождены множество дублирующих эти суммы ячеек (суммы по всем 99 измерениям), при том, что в кубе вообще 3 различных ячейки. Для обработки подобных случаев используется концепция покрытий ячеек, см. Quotient Cube.
Вперед: Общие стратегии вычисления кубов
Выше: Введение. Анализ задачи
Назад: Виды запросов к кубам
Содержание

