Оптимизатор
СУБД Teradata поддерживает наиболее развитый оптимизатор, какой только можно найти на рынке. Этот оптимизатор был специально спроектирован для рынка параллельных приложений в системах поддержки принятия решения (DSS) в 1983 году. Оптимизатор генерирует достаточно сложные планы выполнения SQL запросов, с целью максимального использования параллелизма системы. Оптимизатору известно сколько единиц параллелизма (виртуальных процессоров AMP) работает в системе. Оптимизатору также доступна собранная статистика и демография данных. Он использует эту информацию для выработки последовательности шагов для наиболее эффективного выполнения SQL запроса, которые скоординированно отправляются виртуальным процессорам AMP.
Оптимизатору доступны все сведения о работающей параллельной конфигурации аппаратного и программного обеспечения, поэтому он может весьма точно проводить сравнение планов выполнения запросов. Оценка плана выполнения SQL запроса полностью основывается на относительной "стоимости" по выполнению запроса, при этом оптимизатор выбирает тот план выполнения запроса, "стоимость" которого минимальна. Планирование обычных подзапросов, внешних соединений и коррелированных подзапросов полностью учитывается и оценивается планировщиком операций соединений таблиц. У оптимизатора имеется специальный алгоритм для оптимизации соединений типа "звезда" и "снежинка" для достижения максимальной производительности при онлайновой аналитической обработке транзакций. (On-Line Analytical Processing - OLAP). Эти алгоритмы полностью встроены в планировщик соединений таблиц.
Другим достоинством оптимизатора является то, что его не требуется настраивать, задавать степень распараллеливания запросов и т.п. Не допускается использование каких-либо вспомогательных операций, влияющих на работу оптимизатора. Единственный способ повлиять на работу оптимизатора - это запуск оператора COLLECT STATISTICS; назначение этого оператора - предоставление оптимизатору достаточных статистических сведений по демографии данных. Оптимизатор в СУБД Teradata - это хорошо спроектированный и устойчивый инструмент, который может обрабатывать незапланированные и повторяющиеся запросы конечных пользователей, запросы сделанные при помощи различных инструментов и утилит OLAP, при этом без вмешательства администратора БД или системного администратора. Администратор БД должен иметь достаточно хорошее представление о статистических характеристиках запроса, а также понимать демографию данных, их использование, чтобы определить то, что требуется индексировать, а также те индексы и колонки, по которым нужно собрать статистику с помощью оператора COLLECT STATISTICS. В обеих этих операциях полностью реализованы возможности параллелизма, и они выполняются достаточно быстро.
Далее представлен пример запроса SQL, который соединяет пять таблиц, выполняя при этом одно сравнение по полю Part Name (LIKE %GREEN) и вычисляя значение агрегатной функции по сумме фактических доходов. Сами доходы сначала вычисляются в агрегатной функции, и затем суммируются.
SELECT S_NATION, O_ORDERDATE / 10000, SUM(L_EXTENDEDPRICE * (L_DISCOUNT/100) - PS_SUPPLYCOST * L_QUANTITY) FROM PARTS, SUPPLIERS, LINEITEM, PARTSUPP, ORDERS WHERE S_SUPPKEY = L_SUPPKEY AND PS_SUPPKEY = L_SUPPKEY AND PS_PARTKEY = L_PARTKEY AND P_PARTKEY = L_PARTKEY AND O_ORDERKEY = L_ORDERKEY AND P_NAME LIKE '%GREEN%' GROUP BY S_NATION, O_ORDERDATE / 10000 ORDER BY S_NATION ASC, O_ORDERDATE / 10000 DESC;
Этот пример иллюстрируют достаточно типичный пример запроса систем поддержки решения. Таблица Lineitem - это очень большая таблица, с детализированными данными. Размер результата этого запроса невелик, поскольку собранная информация группируется по национальностям поставщиков (число национальностей < 100), и поэтому этот результат упорядочен так, чтобы его можно легко прочитать. На следующем рисунке наглядно показано, как оптимизатор Teradata использует всю мощь распараллеливания, предоставляемую виртуальными процессорами AMP.
Распараллеливание в оптимизаторе
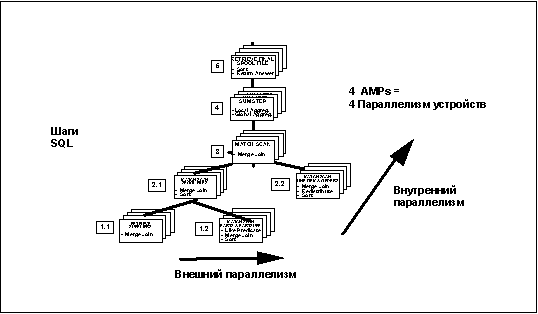
Стоит подчеркнуть, что оба типа распараллеливания выполнения запросов представлены в вышеприведенном запросе: Горизонтальный параллелизм (Inter-Vproc Parallelism) - Все четыре виртуальных процессора AMP выполняют каждый шаг запроса одновременно. Вертикальный параллелизм Intra-Vproc (Parse Step) parallelism -- При отсутствии зависимостей между шагами оптимизатор СУБД Teradata укажет, что множество шагов можно выполнять одновременно внутри каждого виртуального процессора AMP.
В СУБД Teradata имеется одно мощное средство, называемое "Explain" (Подробная информация о выполнении запроса). Результатом работы утилиты "Explain" является вывод информации на английском языке о том, как по шагам выполнялся SQL запрос. Гарантируется, что вывод команды "Explain" всегда совпадает с реальным планом выполнения запроса, сделанным оптимизатором. Для приведенного выше рисунка был использован вывод оператора EXPLAIN.
Соединение таблиц
СУБД Teradata поддерживает несколько стратегий соединения таблиц. Используемая при выполнении запроса стратегия выбирается на этапе компиляции. При этом оптимизатор сначала производит относительную оценку "стоимости" для каждого варианта соединения, а затем выбирает лучший из них. Большинство соединений в СУБД Teradata работают одновременно с двумя таблицами. Оптимизатор строит план запроса для соединений очередных двух таблиц, пока результирующее отношение не будет построено. Выполнение всех соединений полностью распараллелено.
Для выполнения обычных операций соединения таблиц, оптимизатор может выбрать один из следующих основных способов: Hash Merge Join, Nested Message Join и Standard Product Join. Hash Merge Join работает на двух отношениях (таблицах), которые отсортированы по хэш-значениям, соединение производится по совпадающим хэш-значениям. Если одно или оба отношения (таблицы), участвующие в соединении, не хэшированы, не распределены и не отсортированы по полям соединения, то они должны быть соответствующим образом подготовлены к операции соединения, и это будет учтено оптимизатором при оценке "стоимости" выполнения данной операции. Nested Message Join выбирает строку из одной таблицы и отправляет ее виртуальному процессору AMP, где уже хранится строка, с которой должно произойти соединение. На этом процессоре AMP и выполняется соединение, после чего производится выдача его результата.
Оптимизатор СУБД Teradata может использовать несколько вариантов для выбора способа соединения таблиц. Он может непосредственно производить соединение с подтаблицей индекса, а не с базовой таблицей, если все нужные поля уже представлены в индексной подтаблице. Оптимизатор может также выполнять соединение с подтаблицей индекса и извлекать значения идентификаторов строк (т.н. ROWID-значения) из таблицы индекса, помещая их во временную таблицу, чтобы позднее их отсортировать и соединить снова с базовой таблицей для извлечения других строк.
Существует также набор операторов, применяемых только для внешнего соединения (т.н. OUTER JOIN), причем один - для каждого типа "внешнего соединения". Каждый из этих операторов может быть использован для основных типов соединений таблиц, которые были перечислены выше. Существует набор операций для исключающих соединений, которые используются для реализации следующих операций над множествами: INTERSECT (пересечение) и MINUS (вычитание), а также отдельных операций с подзапросами. Последней по счету операцией (но не последней по важности) является специальная операция соединения, которая используется для соединения типа "звезда". Эта операция, известная как Hash Star Join, выполняет соединения типа - cross product joins за один шаг (запатентованный механизм). Оптимизатор выявляет соединения типа "звезда" и "снежинка" и генерирует специальный высокопроизводительный шаг по выполнению такого типа соединений, чтобы максимально повысить производительность системы.
Структуры, используемые для индексирования
Первичный индекс (Primary index)
В СУБД Терадата имеется два типа первичных индексов : Уникальный первичный индекс (Unique Primary Index) и неуникальный первичный индекс (Non Unique Primary Index). Как известно индексы используются для быстрого извлечения строк из таблиц БД, при этом можно избежать полного сканирования всей таблицы.
Первичный индекс в СУБД Терадата это механизм, использующий алгоритм хэширования, для поставки каждой строки таблицы БД конкретному виртуальному процессору АМР, а также использующийся для быстрого извлечения строк. Это позволяет большинство операций с БД выполнять очень быстро. В любой таблице БД имеется уникальный или неуникальный первичный индекс. Далее, при доступе к строке по первичному индексу или при вставке строки, используя некий "зашитый" алгоритм хэширования, система прогоняет через него значение первичного индекса. На выходе получается некое число из 32-х бит. (Т.н. Row hash). Первые 16 бит, называемые hash bucket, определяют, то к какому виртуальному процессору AMP пойдет вставляемая строка. Значение hash bucket варьируется от 0 до 65535. Данные значения равномерно распределены между всеми АМР-ми в системе. Таким образом каждый АМР знает какие значения hash bucket к нему относятся.
Если все значения колонки первичного индекса уникальны или почти уникальны, то данные будут равномерно распределены между всеми АМР. Все, что требуется от администратора БД это правильно выбрать колонку (или колонки) под первичный индекс.
Существует два уровня индексирования хэш-кодов. Первый уровень хранится в памяти. Это гарантирует, что в наихудшем с точки зрения оптимизации случае, при обращении к одной строке потребуются всего две операции ввода/вывода. При кэшировании ввода/вывода обеспечивается высокая вероятность того, что индекс второго уровня попадет в кэш-память, и что блок данных также окажется в памяти. Такой механизм хранения данных гарантирует, что при вставке или изменении строк не будут увеличиваться накладные расходы, связанные с выполнением этих операций (наличие хэш-цепочеки, block extensions и т.п.). Кроме того, работают специальные фоновые задачи, которые по мере необходимости устраняют фрагментацию.
Помимо возможности быстрого доступа к одной строке, хэшированные структуры сортируются по хэш-кодам и оптимизируются для использования алгоритмом Hash Merge Join. Если таблица соединяется по первичному индексу, то не требуется каких-либо действий для подготовки самой таблицы к этой операции - алгоритм соединения непосредственно считывает строки таблицы.
Вторичные индексы (Secondary index)
В СУБД Teradata используются два типа вторичных индексов: уникальные и неуникальные вторичные индексы. Данные в колонке (или в колонках), объявленных как вторичный индекс, поставляются в алгоритм хэширования. Получающийся на выходе Row Hash, указывает на строки в индексной подтаблице, в которой в свою очередь хранится идентификатор (Row ID) базовой строки. Таким образом, как и в случае первичных индексов, для быстрого поиска строк по вторичным индексам используется алгоритм хэширования.
Различие между уникальными и неуникальными вторичными индексами, в общем заключатся в том, что строки, уникальных вторичных индексов глобально распределены между всеми АМР-ми и извлекаются по тому же принципу, что и строки по первичному индексу. В этом случае как правило задействуются 2 виртуальных процессора АМР, так как строка базовой таблицы принадлежит одному АМР, а строка индексной подтаблицы другому АМР-у. В случае неуникальных вторичных индексов, строки индексной подтаблицы и соответствующие строки базовой таблицы принадлежат одному АМР-у. Таким образом, при доступе к строке по неуникальному вторичному индексу, всем АМР-ам системы посылается сообщение-запрос о наличии строк в индексной подтаблице с заданным значением. Если АМР не имеет таких строк в индексной подтаблице, то в базовую таблицу он не пойдет.
Глобальный параллелизм
Глобальный параллелизм - это те встроенные в СУБД Teradata возможности распараллеливания, при использовании которых все составляющие параллелизма (т.е. все виртуальные процессоры AMP на всех узлах системы) знают, что они работают совместно. Ни одна из известных СУБД, где реализованы способы распараллеливания, не имеет таких возможностей, и это отрицательно сказывается на их общей производительности.
В СУБД Teradata коммуникационный слой передачи сообщений (Message Passing Layer) предоставляет средства сигнализации, с помощью которых системе становится известно, какой из виртуальных процессоров AMP закончил работу по выполнению данного шага SQL первым, а какой - последним. Для всех процессоров AMP гарантируется, что пока не будет закончен предыдущий шаг, следующий шаг не будет инициирован PE. Эта глобальная синхронизация имеет важное значение для поддержки сбалансированной и скоординированной работы системы.
Возможность превращения локальных задач в глобальные требует взаимодействия между собой виртуальных процессоров. Если возможности глобального распараллеливания не встроены в СУБД, то в случае, если OLTP СУБД пытается выполнять задачи систем поддержки принятия решений, моделирование совместной работы или разделения данных среди составляющих параллелизма будет затруднено и вызовет явные проблемы с производительностью. После того как, та или иная СУБД уже сформировалась как зрелый продукт для решения определенного класса задач на конкретной платформе, определенные трудности будут представлять выявление ситуаций взаимной блокировки пользователей друг другом (Deadlock) и глобальной синхронизации блокировок среди всех составляющих параллелизма (т.е виртуальных процессоров).
Назад | Содержание | Вперед