Состояние и перспективы Microsoft SQL Server
Алексей Шуленин, MicrosoftНовые и обновленные утилиты
- SQL Enterprise Manager
- Интегрирован с MMC, включает средства взуализации из Visual Data Tools (создание структуры, протягивание отношений, редактирование данных в таблицах по ходу дела, ...)
- Больше wizard'ов, хороших и разных:
- Создание базы, поддержка базы, управление предупреждениями (alerts), импорт/экспорт данных, тиражирование, хранимые процедуры, ...
- Index Tuning Wizard- моделирование рабочей нагрузки (множества запросов и определение наиболее подходящих индексов. Взаимодействует с Query Optimizer. Не учитывает одновременных пользователей.
- Нельзя администрить предыдущие версии SQL Server- они не понимают новую модель SQL-DMO
- Использовать старый Enterprise Manager или написать свой snap-in для 4.2, 6.х
- SQL Server Agent (бывший SQL Executive)
- Основные понятия: jobs (бывшие tasks), operators и alerts
- Job- последовательность шагов
- Каждый шаг - batch на T-SQL
- Выбор действия в зависимости от удачного / неудачного выполнения шага (выход с сообщением, переход на шаг № ...)
- Время и частота выполнения задач планируется администратором
- Operator - лицо, которому посылается сообщение по сети, e-mail или пэйджингу о результатах выполнения job или наступления alert
- Назначение выполнения job и/или отправки сообщения для operator
- на возникновение ошибки с определенным номером в определенной БД
- на достижение порогового значения каким-либо показателем в SQL Performance Monitor
- SQL Server Profiler (бывший SQL Trace)
- В отличие от Trace, кот. использовал ODS, Profiler встроен в Engine и обладает большими возможностями
- Может смотреть, что делают SP, проигрывать ранее записанную последовательность действий, имеет лучшие возможности фильтрации и группирования событий
- SQL Query Analyzer (бывший isql/w)
- Улучшенный Showplan и графический план выполнения запроса
- Выделение языковых конструкций цветом
- Настройка вида результатов для удобочитаемости (grid)
Механизм хранения
- Механизм хранения управляет
- размещением данных на жестких носителях
- распределением памяти
- вводом / выводом
- контролем одновременного доступа к данным
- журналированием транзакций
- резервным копированием и восстановлением
- Цель - полностью отделить реляционный engine (процессор запросов) от механизма хранения
- и заставить QP общаться с ним только через уровень OLE DB
Базы данных и файлы
- Понятие "device" уходит
- Device => file, БД может лежать на нескольких файлах, обратное теперь неверно
- БД и журнал транзакций теперь обязательно лежат на разных файлах (.mdf / .ndf и .ldf)
- Всего три типа файлов в БД:
- primary (.mdf)- cтартовая точка БД, содержит данные + указатели на остальные файлы, может быть только один на БД
- secondary (.ndf)- необязателен, содержит данные, не поместившиеся в primary, в одной БД может быть много
- log file (.ldf)- как минимум, один, содержит transaction log
- Объекты БД не могут быть приписаны конкретному файлу, для этих целей используется группа
Базы данных и группы файлов
- Понятие "сегмент" уходит
- Файлы могут объединяться в file groups для удобства размещения данных на определенные диски и администрирования
- Группе файлов могут назначаться отдельные таблицы, индексы и данные типов text, ntext, image
- Каждый файл может быть членом только одной группы
- Два типа file groups
- Default- для primary файлов, системных таблиц и файлов, для которых группа не определена. Всегда одна на БД
- User-defined- для остальных. Может быть несколько групп на БД
- Logи не являются частью групп и управляются отдельно от базы
Динамическое управление размером

Новые форматы хранения

Хранение text и image

Полнотекстовый поиск
- Расширения DML
- Предикаты CONTAINS, FREETEXT, функция RELEVANCE, ...
- SELECT publication, pub_date, writer FROM magazines WHERE CONTAINS ( article, ' Edison NEAR(WORD,20) "electric%" ' )
- Этапы развития
- Ноябрь 1997- OLE DB провайдер для Index Server 2.0- поиск данных в файловой системе
- Март 1998- OLE DB провайдер для Site Server 3.0- поиск по документам на Web
- 2-я половина 1998 г.- поиск по BLOB-полям в Sphinx
- Возможности легко доступны из приложений
Set rstMain = CreateObject(ADODB.RecordSet) rstMain.Open "SELECT DocAuthor,
FileName FROM SCOPE(' DEEP TRAVERSAL OF ( "D:\Sphinx\tsql\specs") ') WHERE size > 50000", "Provider = MSIDXS;"
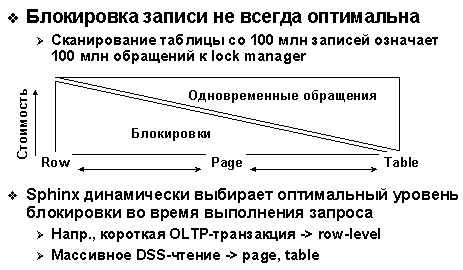
Блокировка уровня записи
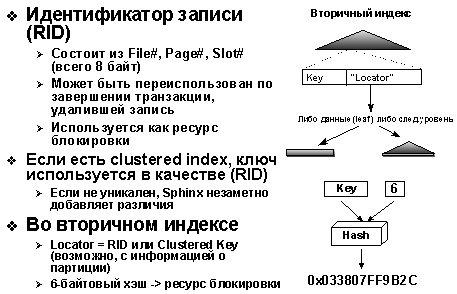
Key Range Locking
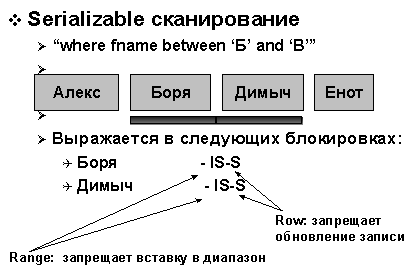
Динамическая блокировка
Log Manager

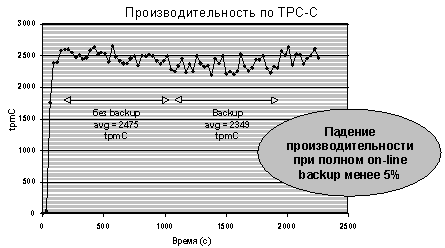
Резервное копирование

Производительность SQL Server 7.0 при on-line backup
Кое-что новое в T-SQL
- В связи с введением распределенных запросов имя состоит из 4-х частей
- Отложенное разрешение имен
- Можно создать таблицу и тут же сослаться на нее в хранимой процедуре
- Новое в поддержке курсоров
- Тип Cursor, переменные можно передавать как параметры
- Процедуры sp_cursor_list, sp_describe_cursor_columns / _tables
- Процедуры управления заданиями и предупреждениями
- sp_add_alert, sp_add_job, sp_add_operator, ...
- Процедуры управления SQL Profiler xp_trace_*
- Добавлены новые указания оптимизатору (hash, merge, loop, robust plan, ... ) для операторов DML
- Новые clauses TOP, PERCENT, WITH TIES для SELECT
- ALTER PROCEDURE (TRIGGER, VIEW) без изменения прав
- Опция DROP COLUMN появилась в ALTER TABLE
- Добавлены новые функции
- Системные: ObjectProperty, ColumnProperty, DatabaseProperty, ...
- Статистические: StDev, Var, ...
- Секьюрные: Is_Member, Is_SrvRoleMember, ...
- Операции над датами (+/-)
- Новые типы данных
- Unicode'овские nchar, nvarchar, ntext
- длина char, varchar, binary, varbinary- до 8К
- Тип Uniqueidentifier (GUID), поле ROWGUIDCOL и функция NewID()
- Substring от данных TEXT и IMAGE
Новое в безопасности
- Улучшенная интеграция с безопасностью NT
- Аутентификация средствами NT (как текущий пользователь- без пароля, как другой- login+pwd)
- Mixed (возможна аутентификация средствами SQL Srv)
- Полная поддержка пользователей, групп и ролей
- Роли могут быть приписаны пользователям и группам NT, а также пользователям Sphinx
- Роли могут быть вложены
- Прикладные роли для 3-уровневых систем
- Позволяют назначать права при доступе через приложение, а не isql
- Гибкая гранулярность прав и системных ролей
- Предопределенные роли ServerAdmin, SecurityOfficer, ...
- Поддержка делегирования в NT 5.0
- На 2-м сервере не как удаленный пользователь, а под тем же именем
- Простое и мощное администрирование
Новое в QP
- Multi-index - одновременное использование нескольких индексов (в т.ч. над одной таблицей)
- пересечение двух множеств RID по каждому индексу для получения результирующего множества (например, SELECT * FROM orders WHERE cust_id = 987 and order_value >= 10000- индексы по cust_id и order_value)
- создание covering index из нескольких имеющихся, которые в отдельности не являются covering для данного запроса (covering index позволяет читать значения колонок с leaf-уровня, не залезая в саму таблицу)
- Merge Join
- Получить row из outer table
- Получить row с таким же ключом из inner table
- Если найден, далее- по inner table, если нет- по внешней
- Выглядит как обычная nested iteration, но проходится за один шаг и потому выполняется быстрее
- Hash Join
- Хэш-функция - свертка ключа, на выходе- значение меньшего размера, основное требование- равномерное распределение, главное преимущество- доступ к записи за одно обращение к таблице
- Пример - алфавитная записная книжка, первая буква- хэш-функция, буквенные секции - букеты
- Применяется, когда не задан порядок сортировки или нет подходящих индексов
- Прочитать меньшую таблицу, нарезать ключи и RID в букеты хэш-таблицы
- Читать большую таблицу. Хэшировать ключ, проверить хэш-таблицу, повторить.
- Hash aggregation (sum, ...)
- Из входной таблицы хэшировать ключ в букет
- Если он там уже лежит, вычислить агрегат
- Зациклить, в конце выдать окончательный агрегат
Оптимизация запросов
- Запросы оптимизируются по условной стоимости
- Учитываются факторы количества операций чтения/записи и времени работы процессора
- А также целевые записи (напр., построить оптимальный план для выбора первых 10 записей)
- При этом используются
- Статистика по хранимым данным (плотности и гистограммы)
- Индексы (например, наличие уникального индекса о чем-то говорит?)
- Ограничения (DRI, сonstraints, nulls)
- Constraints и разбиение данных
- Имеем несколько таблиц: январь, февраль, март
- Построили совокупный view- union
- Делаем из него select за один месяц, QP ищет только в одной таблице (при условии, что на нее был определен месячный constraint)
- Auto partitioning при вводе by value между несколькими таблицами - в следующей версии
- Обработка массивных обновлений- QP поддерживает индексы
- При массовых insert, update, delete изменения сортируются по индексу и применяются за один проход (на один индекс)
- Технология используется в ВСР, DBCC
Модель оптимизации
- Определение самого дешевого дерева на основе пула альтернатив
- Изменение порядка join'ов
- (R JOIN S) JOIN T = (R JOIN T) JOIN S
- Раннее применение условий фильтрации
- Классы эквивалентности для колонок и другие неявные предикаты
- Если a=b, то sort(a), очевидно, такой же, как sort(b)
- Функциональная избыточность
- Group(e#,ename) = group(e#)
- ...
Параллельная обработка запросов
- Параллельная обработка- одновременное выполнение одного запроса несколькими процессорами
- Асинхронный ввод/вывод, обслуживание клиентов на разных потоках не рассматривается
- Дает преимущество только на машинах с >1 СPU
- Запрос компилируется для параллельного выполнения, формируется параллельный план
- Единый параллельный план для нескольких процессоров
- К операторам последовательного плана добавлены Exchange Operators (Distribute, Gather, Repartition)
Exchange Operator

Степень параллелизма
- Кол-во процессоров, на которых выполняется данный шаг плана запроса
- Может отличаться для разных шагов, например, при вычислении результирующего агрегата из промежуточных DOP=1
- Insert / update / delete выполняются на одном потоке
- Но их части, относящиеся к SELECT могут выполняться с DOP>1
- Выигрывают долгоиграющие запросы с массивными агрегатами, joinами, unionами и т.д.
- Не выигрывают OLTP-запросы
- Число одновременных пользователей >> числа процессоров - предпочтительнее межзапросный параллелизм
Настройка DOP
- В конфигурации max DOP меняется от 0 до 32
- Default=1- отключить параллельное выполнение
- Default=0 (автоматическая настройка в зависимости от конкретного запроса
- Учет затрат на инициализацию параллельного плана, перемещение данных между потоками
- При высокой загрузке, росте коннектов, нехватке памяти Sphinx будет стремиться понизить DOP
- Сost threshold of parallelism- генерировать параллельные планы только для запросов с более высокой стоимостью (конфигурация 0-32767, default=5)
- Showplan показывает Exchange-итераторы
- DOP каждого конкретного запроса можно видеть в SQL Profiler
Сравнение производительности QP

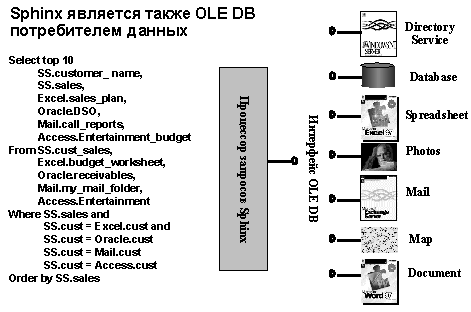
Универсальный доступ к данным
- Данные хранятся по-разному, а нужны зачастую все и сразу
- Руководитель сидит в MS Project, хочет прочитать переписку (e-mail), поднять документ (файловая система) увидеть баланс (СУБД), послушать музыку...
- Качать это все в базу всякий раз, чтобы воспользоваться ее механизмами обработки?
- Потом обратно, а источники уже могли независимо измениться... Целостность?
- QP СУБД заведомо не оптимизирован под новые типы
- Выход - не универсальное хранение, а универсальная обработка
- Никто, лучше самих данных, не знает, как их обрабатывать
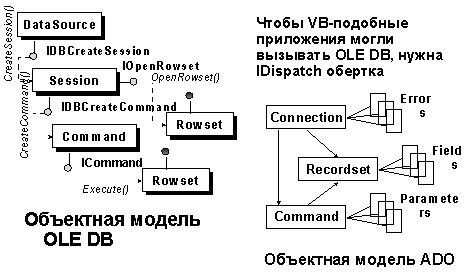
- OLE DB - набор стандартных интерфейсов: что должна уметь делать компонента обработки данных
- Аналогия с ODBC, но для данных произвольной природы
- OLE DB является "родным" интерфейсом Sphinx
- QP общается с Data Storage через OLE DB
- DB-Lib эмулируется средствами OLE DB и больше развиваться не будет
Универсальный доступ к данным (3)
Гетерогенные запросы
Распределенные операции в Sphinx

Sphinx и Data Warehousing
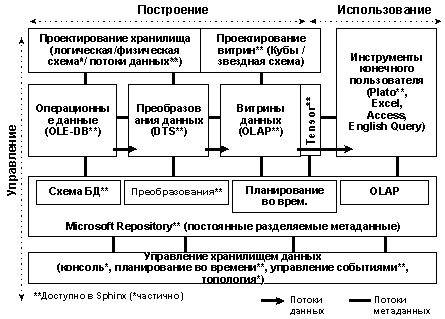
Объектная модель службы преобразования данных
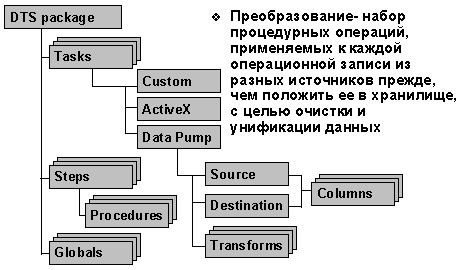
Понятие пакета DTS

DTS Designer в Sphinx
Microsoft Data Cube Service
- Базовая архитектура:
- Кэшировать не дисковые страницы, а результаты запросов и метаданные
- Мгновенный ответ на кэшированные запросы
- Алгоритмы выведения пропущенных данных и преобразования запросов
- Агрегация, фильтрация, комбинирование
- Эффективное распределение обработки запросов и промежуточных вычислений между клиентом и сервером
- Объединяет серверные и настольные платформы
- Унифицирует доступ к многомерным данным из Excel, Plato, SQL Server ...
Microsoft
Алексей Шуленин
Тел.: (095) 967-8585 Факс (095) 967-8500