МОГучие способности: новые приемы анализа больших данных
Джеффри Коэн, Брайен Долэн, Марк Данлэп, Джозеф Хеллерстейн, Кейлэб Велтон.
Перевод: Сергей Кузнецов
5.3. Функционалы
Базовая статистика не нова для реляционных баз данных – в большинстве систем поддерживаются средние значения, дисперсии и некоторые виды квантилей. Но моделирующие и сравнительные статистические средства в системы обычно не встраиваются. В этом подразделе мы представляем параллельные по данным реализации ряда методов сравнительной статистики, выраженные на SQL.В предыдущем подразделе скаляры и векторы являлись атомарными единицами. Здесь основным объектом является функция плотности распределения вероятностей. Например, плотность нормального (Гауссова) распределения 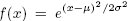 считается математиками одной "сущностью" с двумя атрибутами: средним значением μ и дисперсией σ. Распространенный статистический вопрос состоит в том, насколько хорошо некоторый набор данных соответствует целевой функции плотности. Z-показатель элемента данных x задается соотношением
считается математиками одной "сущностью" с двумя атрибутами: средним значением μ и дисперсией σ. Распространенный статистический вопрос состоит в том, насколько хорошо некоторый набор данных соответствует целевой функции плотности. Z-показатель элемента данных x задается соотношением 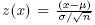 , и его легко получить с использованием стандартного SQL:
, и его легко получить с использованием стандартного SQL:
SELECT x.value, (x.value - d.mu) * d.n / d.sigma AS z_score FROM x, design d
5.3.1. U-тест Манна-Уитни
Ранговая и порядковая статистика (rank and order statistics) вполне поддается реляционной обработке, поскольку основной целью здесь является единовременная обработка некоторого набора данных, а не какого-либо одного элемента данных. В следующем примере иллюстрируется сравнение двух полных наборов данных без накладных расходов на описание параметризуемой плотности.U-тест Манна-Уитни (Mann-Whitney U Test, MWU) – это популярная замена t-теста Стьюдента (Student) в случае непараметрических данных. Основная идея состоит в том, чтобы взять две популяции A и B и решить, происходят ли они из одной и той же основной популяции, путем изучения рангового порядка, в котором элементы A и B обнаруживаются в общем порядке. Если элементы A находятся "впереди" этой последовательности, а элементы B – позади, то A и B являются разными популяциями. В рекламной среде отклики баннеров (click-through rate) в Web-рекламе склонны не подчиняться простым параметрическим моделям, таким как Гауссово или логарифмически-нормальным распределениям. Но часто оказывается полезно сравнивать распределения откликов баннеров разных рекламных компаний, чтобы, например, выбрать одну из них с лучшим средним откликом баннеров. MWU позволяет решить эту задачу.
При заданной таблице T со столбцами SAMPLE ID, VALUE получаются номера строк, и они суммируются посредством оконных функций SQL.
CREATE VIEW R AS
SELECT sample_id, avg(value) AS sample_avg
sum(rown) AS rank_sum, count(*) AS sample_n,
sum(rown) - count(*) * (count(*) + 1) AS sample_us
FROM (SELECT sample_id, row_number() OVER
(ORDER BY value DESC) AS rown,
value
FROM T) AS ordered
GROUP BY sample_id
Если размеры образцов достаточно велики, например, больше 5000, можно принять аппроксимацию нормальным распределением. Используя ранее определенное представление R, заключительный этап вычисления статистических данных можно выразить на SQL следующим образом:
SELECT r.sample_u, r.sample_avg, r.sample_n
(r.sample_u - a.sum_u / 2) /
sqrt(a.sum_u * (a.sum_n + 1) / 12) AS z_score
FROM R as r, (SELECT sum(sample_u) AS sum_u,
sum(sample_n) AS sum_n
FROM R) AS a
GROUP BY r.sample_u, r.sample_avg, r.sample_n,
a.sum_n, a.sum_u
Окончательный результат представляет собой набор чисел, описывающих связи между функциями. Эту простую программу можно инкапсулировать хранимыми процедурами и сделать ее доступной аналитикам путем простого вызова SELECT mann whitney(value) FROM table, что чрезвычайно способствует развитию словаря базы данных.
5.3.2. Логарифмические отношения правдоподобия
Отношения правдоподобия полезны для сравнения некоторой подсовокупности с совокупностью в целом по некоторым конкретным характеристикам. Например, в области рекламы могут учитываться такие характеристики пользователей, как любимый напиток и семейное положение. Могло бы потребоваться узнать, привлекает ли кофе молодых родителей в большей степени, чем популяцию в целом.Здесь мы имеем две функции плотности (или распределения масс) для одного и того же набора данных X. Назовем одно распределение основной гипотезой f0, а другое – альтернативной гипотезой f1. Обычно f0 и f1 являются разными параметризациями одной и той же плотности. Например, N(μ0, σ0) и N(μA, σA). Сходство L относительно fi задается следующим соотношением:
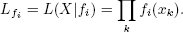
Логарифмическое отношение подобия (log-likelihood ratio, LLR) определяется как 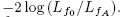 Взятие логарифма позволяет нам использовать хорошо известную χ2-аппроксимацию для больших n. Кроме того, произведения приятным образом превращаются в суммы, и РСУБД может легко производить вычисления параллельно.
Взятие логарифма позволяет нам использовать хорошо известную χ2-аппроксимацию для больших n. Кроме того, произведения приятным образом превращаются в суммы, и РСУБД может легко производить вычисления параллельно.
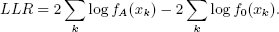
Эти вычисления хорошо распределяются, если 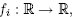 а в большинстве случаев это именно так. Если же то к работе с векторами как с распределенными объектами нужно относиться с осторожностью. Предположим, что значения содержатся в таблице T, и что функция fA(·) реализована как определяемая пользователями функция
а в большинстве случаев это именно так. Если же то к работе с векторами как с распределенными объектами нужно относиться с осторожностью. Предположим, что значения содержатся в таблице T, и что функция fA(·) реализована как определяемая пользователями функция f_llk(x numeric, param numeric). Тогда все вычисление может быть произведено посредством вызова
SELECT 2 * sum(log(f_llk(T.value, d.alt_param))) -
2 * sum(log(f_llk(T.value, d.null_param))) AS llr
FROM T, design AS d
Для вычисления такого запроса от РСУБД требуется значительная гибкость и изощренность.
Пример: полиномиальное распределение
Полиномиальное (multinomial) распределение является расширением биномиального распределения. Рассмотрим случайную переменную X с k дискретными исходами. Для них имеются вероятности p = (p1, ...,pk1). При n попытках суммарное распределение вероятности выражается следующим образом:
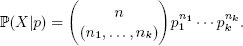
Чтобы получить pi, предположим, что базисная совокупность представлена в таблице outcome со столбцом outcome.
CREATE VIEW B AS
SELECT outcome,
outcome_count / sum(outcome_count) over () AS p
FROM (SELECT outcome, count(*)::numeric AS outcome_count
FROM input
GROUP BY outcome) AS a
В контексте выбора модели часто бывает удобно сравнить один и тот же набор данных при наличии двух разных полиномиальных распределений.
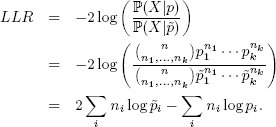
Или на SQL:
SELECT 2 * sum(T.outcome_count * log B.p)
- 2 * sum(T.outcome_count * log T.p)
FROM B, test_population AS T
WHERE B.outcome = T.outcome
5.4. Методы повторного взятия образцов
Параметрическое моделирование предполагает, что данные поступают от некоторого процесса, который полностью представляется математическими моделями с рядом параметров – например, средним значением и дисперсией нормального распределения. Параметры реального процесса требуется оценивать на основе существующих данных служащих "образцом" этого процесса. При получении таких параметров для крупных данных можно было бы склониться к простому использованию агрегатов SQLAVERAGE и STDDEV, но обычно этого бывает недостаточно. В реальных наборах данных, подобных тем, которые существуют в FAN, неизменно содержатся аномальные значения и другие артефакты. Наивная "простая статистика" над такими данными (т.е. использование агрегатов SQL) не является устойчивой (robust) [10] и приводит к "сверхподгонке" ("overfitting") модели по отношению к этим артефактам. Это может препятствовать тому, чтобы в модели должным образом отражались свойства реальных процессов.
Основная идея повторного взятия образцов состоит в том, что из некоторого набора данных управляемым образом постоянно берутся образцы, над каждым образцом вычисляется сводная статистика, и образцы тщательно комбинируются, чтобы получить более устойчивые оценки свойств всего набора данных. Интуитивно понятно, что редкие аномальные данных будут появляться лишь не в многих образцах (или вообще не будут появляться) и не будут приводить к искажению оценок.
В литературе по статистике описываются два стандартных метода повторного взятия образцов. Метод раскрутки очень прост: из совокупности размера N выбираются k элементов (подобразец размера k) и над ними вычисляется требуемая статистика Θ0. Теперь сменим подобразец и выберем другие случайные k элементов. Новая статистика Θ1 будет отличаться от предыдущей. Повторим это "взятие образцов" десятки или сотни раз. Распределение результирующих Θi называется выборочным распределением (sampling distribution). В соответствии с центральной предельной теоремой (Central Limit Theorem) выборочное распределение является нормальным, и поэтому среднее значение крупного выборочного распределения является точной оценкой Θ*. Альтернативой раскрутки является метод расщепления выборки (jackknife), который постоянно перевычисляет сводную статистику Θi путем исключения одного или нескольких элементов данных из общего набора данных для определения влияния некоторых подсовокупностей. Результирующий набор наблюдений используется как выборочное распределение таким же образом, как и в методе раскрутки, для получения хорошей оценки интересующей статистики.
Важно то, что не требуется, чтобы все подобразцы были в точности одного и того же размера, хотя использование образцов сильно различающегося размера может привести к некорректным пределам погрешности.
В предположении, что интересующую статистику Θ легко получить посредством применения SQL, например, путем вычисления среднего значения набора значений, единственное, что требуется, – это организация повторного взятия образцов на основе генератора достаточно случайных чисел. Проиллюстрируем это на примере метода раскрутки. Рассмотрим таблицу T с двумя столбцами (row_id, value) и N строками. Предположим, что столбец row_id содержит значения 1, ..., N. Поскольку взятие каждого следующего образца производится с полной заменой предыдущего образца, мы можем заранее определить повторное взятие образцов. Это означает, что если мы производим M взятий образцов, что мы можем заранее решить, что запись i будет присутствовать в подобразцах 1, 2, 25, ... и т.д.
Функция random() генерирует равномерно распределенные случайные элементы из (0,1), а функция floor(x) выдает целую часть x. Мы используем эти функции при разработке эксперимента с повторным взятием образцом. Предположим, что у нас имеется N = 100 объектов изучения, и мы хотим произвести 10000 попыток взятия образцов размером 3.
CREATE VIEW design AS
SELECT a.trial_id,
floor (100 * random()) AS row_id
FROM generate_series(1,10000) AS a (trial_id),
generate_series(1,3) AS b (subsample_id)
Уровень доверия к генератору случайных чисел здесь зависит от системы и исследователю нужно проверить, что при масштабировании функции random() она по-прежнему возвращает равномерно распределенные случайные значения нужного масштаба. Для выполнения эксперимента на этим представлением достаточного одного запроса:
CREATE VIEW trials AS SELECT d.trial_id, AVG(a.values) AS avg_value FROM design d, T WHERE d.row_id = T.row_id GROUP BY d.trial_id
Это представление формирует выборочное распределение: средние значения каждого подобразца. Окончательные результат процесса раскрутки выдается простым запросом над этим представлением:
SELECT AVG(avg_value), STDDEV(avg_value) FROM trials;
Этот запрос возвращает представляющую интерес статистику на заданным числом подобразцов. Для функций AVG() и STDDEV() уже имеется параллельная реализация, так что и весь метод работает параллельно. Заметим, что представление design имеет относительно небольшой размер (примерно 30000 строк), и поэтому может размещаться в основной памяти; следовательно, все 10000 "экспериментов" выполняются за один параллельный проход по таблице T, т.е. с теми же расходами, которые требуются для вычисления одного наивного SQL-агрегата.
При реализации метода расщепления выборки используется аналогичный прием для выполнения нескольких экспериментов за один проход по таблице, не считая взятия случайной подсовокупности на каждом проходе.