Базы данных. Вводный курс
Сергей Кузнецов20.3. Рекурсивные запросы
Начнем этот раздел с нескольких определений, касающихся понятий, которые связаны с рекурсией. Эти понятия имеют общий характер, но в приведенных ниже определениях и комментариях к ним (там, где это уместно) подчеркивается контекст SQL.
20.3.1. Определения, относящиеся к рекурсии
Обход дерева в ширину. При этом способе обхода непосредственные потомки обходятся слева направо, до того как производится переход к потомкам следующего уровня родства.
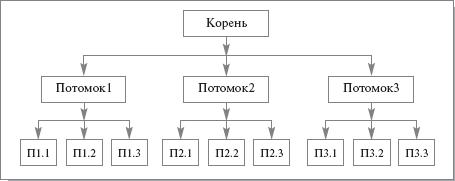
При обходе в ширину дерева, показанного на рис. 20.5, узлы будут обходиться в следующем порядке: Корень-Потомок1-Потомок2-Потомок3-П1.1-П1.2-П1.3-П2.1-П2.3-П3.1-П3.2-П3.3.
Обход дерева в глубину. При этом способе обхода на каждом шаге производится переход к самому левому текущему потомку. При обходе в глубину дерева с рис. 20.5 порядок обхода узлов будет следующим: Корень-Потомок1-П1.1-П1.2-П1.3-Потомок2-П2.1-П2.2-П2.3-Потомок3-П3.1-П3.2-П3.3.
Цикл в ориентированном графе. В теории графов ориентированный граф называется циклическим в том и только в том случае, когда хотя бы один узел графа одновременно является и предком, и потомком (т. е. для этого узла имеется и выходящая, и входящая дуги). В SQL:1999 узлами графа рекурсии являются строки, входящие в результат рекурсивного запроса, а дуги соответствуют способам обработки текущих строк, которые ведут к добавлению к результату новых строк. На рис. 20.6 показан простейший пример ориентированного графа с циклом.

Рис. 20.6. Пример графа с циклом
Прямая рекурсия. По определению, некоторый элемент использует прямую рекурсию в том и только в том случае, когда он обращается сам к себе без посредников. Пример, приведенный на рис. 20.6, демонстрирует (в графовой форме) прямую рекурсию. На рис. 20.7 показан графовый пример непрямой рекурсии.
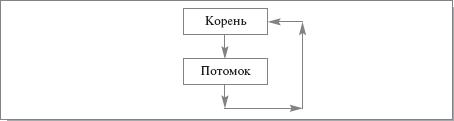
Рис. 20.7. Графовый пример непрямой рекурсии
Линейная рекурсия. При линейно рекурсивном вызове элемент прямо рекурсивно обращается сам к себе не более одного раза. В SQL:1999 в определении любой виртуальной таблицы с рекурсией допускается не более одной ссылки на саму себя (в разделе FROM и/или в подзапросах). На рис. 20.8 показан графовый пример рекурсии, не являющейся линейной.
Монотонность. Монотонной прогрессией называется последовательность неубывающих или невозрастающих значений. Например, последовательность натуральных чисел {1, 2, ... , n, ...} является монотонной. В SQL:1999 свойство монотонности поддерживается в том смысле, что число строк результата рекурсивного запроса не уменьшается на каждом шаге рекурсии.
Взаимная рекурсия. Элементы A и B связаны отношением взаимной рекурсии, если A прямо или косвенно вызывает B, и B прямо или косвенно вызывает A. На рис. 20.9 показан графовый пример взаимной рекурсии (элемент A вызывает элемент B через элемент C, а элемент B вызывает элемент A через элемент D).

Рис. 20.8. Графовый пример нелинейной рекурсии
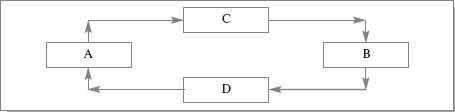
Рис. 20.9. Графовый пример взаимной рекурсии
Отрицание. В контексте SQL отрицанием называется любое действие, приводящее к уменьшению числа строк в результате запроса. Свойствами отрицания обладают операции над (мульти)множествами EXCEPT и INTERSECT, спецификация DISTINCT, условие NOT EXISTS и т.д. В стандарте SQL не запрещается использование отрицания в рекурсивных запросах. Возможной проблемы нарушения монотонности удается избежать за счет того, что отрицание разрешается применять только к тем таблицам, которые являются полностью известными (или вычисленными) к моменту применения отрицания. В процессе вычисления таблицы применение к ней отрицания не допускается.
Начальный источник рекурсии. При выполнении рекурсивных вычислений обычно (хотя и не всегда) имеется некоторое начальное значение. В SQL этим начальным источником рекурсии является одна или несколько строк, удовлетворяющих некоторым начальным условиям. На основе этих строк в процессе рекурсивного вычисления производятся дополнительные строки, образующие окончательный результат.
Стратификация. В SQL рекурсивный запрос обычно состоит из «рекурсивной» и «нерекурсивной» частей. В процессе стратификации («расслоения») запроса выполнение этих двух частей разделяется. В более сложных рекурсивных запросах может содержаться несколько рекурсивных частей и более одной нерекурсивной части. В этом случае в процессе стратификации будет обнаружено большее число слоев.
Семантика фиксированной точки. В контексте SQL:1999 семантика фиксированной точки означает, что решение о завершении рекурсивного запроса принимается тогда, когда становится невозможно добавить к результату какие-либо дополнительные строки.
20.3.2. Рекурсивные запросы с разделом WITH
В предыдущих лекциях мы уже говорили о разновидности спецификации ссылки на таблицу с использованием раздела WITH. Однако мы умышленно отложили обсуждение рекурсивных возможностей. Полный синтаксис раздела WITH выглядит следующим образом:
with_clause ::= WITH [ RECURSIVE ]
with_element_comma_list
with_element ::= query_name [ (column_name_list) ]
AS ( query_expression ) [ search_or_cycle_clause ]
search_or_cycle_clause ::= search_clause
| cycle_clause
| search_clause cycle_clause
search_clause ::= SEARCH recursive_search_order SET
sequence_column_name
recursive_search_order ::= DEPTH FIRST BY
order_item_commalist
| BREADTH FIRST BY order_item_commalist
cycle_clause ::= CYCLE cycle_column_name_comma_list
SET cycle_mark_column_name TO value_expression
DEFAULT value_expression
USING path_column_name
Для иллюстрации возможностей рекурсивных запросов с разделом WITH и пояснения смысла конструкций SEARCH и CYCLE воспользуемся классическим примером «разборки деталей» (в данном случае мы будем разбирать автомобиль). Предположим, что данные о конструктивных элементах автомобиля хранятся в таблице CAR, определенной следующим образом:
CREATE TABLE CAR (CONTAINING_PART VARCHAR (10),
CONTAINED_PART VARCHAR (10),
NUMBER_OF_PARTS INTEGER,
PART_COST DECIMAL (6,2));
У автомобиля имеется один конструктивный элемент верхнего уровня – полностью собранный автомобиль. Этот элемент не является составной частью какого-либо другого элемента, и для его строки значением столбца CONTAINING_PART является текстовая строка длины 0. В любой другой строке таблицы CAR, соответствующей некоторому неатомарному конструктивному элементу e, столбец CONTAINING_PART содержит идентификационный номер элемента e1, в который входит элемент e, столбец NUMBER_OF_PARTS – число экземпляров элемента e, входящих в e1, а столбец CONTAINED_PART – идентификационный номер самого элемента e. В любой строке таблицы CAR, соответствующей некоторому атомарному конструктивному элементу, значением столбца CONTAINED_PART является строка длины 0, а в столбце PART_COST сохраняется цена атомарного конструктивного элемента (для неатомарных элементов значение этого столбца равно нулю).
Предположим, что нам требуется разобрать автомобиль, начиная с элемента самого верхнего уровня, и для каждого конструктивного элемента получить его номер, общее число используемых экземпляров этого элемента, а также, если элемент является атомарным, общую стоимость используемых экземпляров. Вот возможная формулировка запроса (пример 20.3):
WITH RECURSIVE PARTS (PART_NUMBER,
NUMBER_OF_PARTS, COST) AS
(SELECT CONTAINED_PART, 1, 0.00 (a)
FROM CAR
WHERE CONTAINING_PART = ''
UNION ALL
SELECT CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS,
CAR.NUMBER_OF_PARTS * CAR.PART_COST
FROM CAR, PARTS
WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART)
SELECT PART_NUMBER, SUM(NUMBER_OF PARTS),
SUM(COST) (b)
FROM PARTS
GROUP BY PART_NUMBER;
Этот запрос будет выполняться следующим образом. При вычислении раздела FROM основного запроса (b) начнется выполнение рекурсивного выражения запросов (a), определенного в разделе WITH. На первом шаге рекурсии будет выполнена часть данного выражения, предшествующая операции UNION ALL и образующая начальный источник рекурсии. В результате будет произведено исходное состояние виртуальной таблицы PARTS, в котором, в нашем случае, появится единственная строка, соответствующая автомобилю целиком. На следующем шаге к таблице PARTS будут добавлены строки, соответствующие конструктивным элементам второго уровня (для автомобиля это, по-видимому, двигатель, колеса, шасси и т.д.). Этот процесс будет продолжаться до тех пор, пока мы не дойдем до атомарных конструктивных элементов и не достигнем, тем самым, фиксированной точки. Поскольку в рекурсивном запросе содержится операция UNION ALL, в результирующей таблице могут появляться строки-дубликаты. Наличие строки-дубликата вида <part_no, number, cost> означает, что элемент с номером part_no входит в одном и том же числе экземпляров в несколько конструктивных элементов более высокого уровня.
Раздел SEARCH
В приведенном выше примере не определялся порядок, в котором строки добавляются к частичному результату рекурсивного запроса. Однако иногда требуется, чтобы иерархия обходилась в глубину или в ширину. Соответствующая возможность обеспечивается конструкцией SEARCH. При указании требования обхода в глубину гарантируется, что каждый элемент-предок появится в результате раньше своих потомков и своих братьев справа. Если указывается требование обхода иерархии в ширину, в результате все братья одного уровня появляются раньше, чем какой-либо их потомок. Ниже показан вариант запроса, в котором содержится раздел SEARCH с требованием обхода иерархии элементов автомобиля в ширину (пример 20.4).
WITH RECURSIVE PARTS (ASSEMBLY, PART_NUMBER,
NUMBER_OF_PARTS, COST) AS
(SELECT CONTAINING_PART, CONTAINED_PART, 1, 0.00
FROM CAR
WHERE CONTAINING_PART = ''
UNION ALL
SELECT CAR.CONTAINING_PART, CAR.CONTAINED_PART,
CAR.NUMBER_OF_PARTS, CAR.NUMBER_OF_PARTS *
CAR.PART_COST
FROM CAR, PARTS
WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART)
SEARCH BREADTH FIRST
BY CONTAINING_PART, CONTAINED_PART
SET ORDER_COLUMN
SELECT PART_NUMBER, NUMBER_OF PARTS, COST
FROM PARTS
ORDER BY ORDER_COLUMN;
В списке столбцов сортировки раздела SEARCH должны указываться имена столбцов виртуальной таблицы, определенной в разделе WITH. Поскольку в данном случае мы хотим, чтобы в результате сначала появлялись все конструктивные элементы одного уровня (CONTAINING_PART), а затем все их подэлементы (CONTAINED_PART), в список выборки рекурсивного запроса PARTS добавлен столбец CONTAINING_PART, который не используется нигде, кроме раздела SEARCH. В разделе SET к результирующей таблице рекурсивного запроса добавлен столбец, который мы назвали ORDER_COLUMN. Название соответствует природе столбца, потому что при выполнении рекурсивного запроса в этот столбец автоматически заносятся значения, характеризующие порядок генерируемых строк в соответствии с выбранным способом обхода иерархии. Чтобы строки результата основного запроса появлялись в должном порядке, в этом запросе требуется наличие раздела ORDER BY с указанием столбца, определенного в разделе SET.
Раздел CYRCLE
Наконец, обсудим, для чего нужен раздел CYRCLE. Дело в том, что иногда сами данные, хранимые в таблицах базы данных, могут иметь циклическую природу. Представим себе, например, компанию, в которой существует совет директоров, являющийся высшим органом управления компанией. Обычным случаем является тот, когда по крайней мере один из членов совета директоров является простым служащим этой же компании (например, он может входить в совет директоров как представитель профсоюза). Назовем данного члена совета директоров EMP_DIR. Как член совета директоров, EMP_DIR «управляет» деятельностью президента компании. С другой стороны, как служащий компании, EMP_DIR находится в прямом или косвенном подчинении у президента компании. Такое положение может привести к зацикливанию выполнения рекурсивных запросов. Раздел CYRCLE обеспечивает некоторую возможность распознавать подобные ситуации. Если у пользователя имеется полная уверенность в отсутствии циклов в данных, к которым адресуется рекурсивный запрос, то использование раздела CYRCLE не требуется.
Подход к распознаванию зацикленных запросов, принятый в SQL, состоит в том, что распознаются данные, которые уже участвовали ранее в формировании результата рекурсивного запроса. При наличии раздела CYRCLE при добавлении к результату строк, удовлетворяющих условию запроса, такие строки помечаются указанным значением, которое означает, что эти строки уже вошли в результат. При попытке добавления к результату каждой новой строки проверяется, не находится ли она уже в результате, т. е. не помечена ли она этим указанным в разделе CYRCLE значением. Если это действительно так, то считается, что имеет место цикл, и дальнейшее выполнение рекурсивного запроса прекращается.
Обсудим все это более формально. Для удобства воспроизведем еще раз синтаксис раздела CYRCLE.
cycle_clause ::= CYCLE cycle_column_name_comma_list
SET cycle_mark_column_name TO value_expression_1
DEFAULT value_expression_2
USING path_column_name
В списке cycle_column_name_comma_list указываются имена одного или нескольких столбцов, которые используются для идентификации новых строк результата на основе строк, уже входящих в результат. Например, в примерах 16.3 и 16.4 столбец CONTAINED_PART связывает конструктивный элемент автомобиля с входящими в его состав подэлементами (через значения их столбцов CONTAINING_PART). Раздел SET приводит к образованию нового столбца результирующей таблицы. Для строк, которые попадают в результат первый раз, в столбец cycle_mark_column_name заносится значение выражения value_expression_2. В повторно заносимых строках значение столбца – value_expression_1. Типом данных этого столбца является тип символьных строк длины один, так что в качестве value_expression_1 и value_expression_2 разумно использовать константы '0' и '1' или 'Y' и 'N'.
Раздел USING приводит к образованию еще одного дополнительного столбца результата с именем path_column_name. Типом данных столбца является ARRAY, причем кардинальность этого типа предполагается достаточно большой, чтобы сохранить информацию обо всех строках, попавших в результат. Элементы массива имеют «строчный тип» (row type), содержащий столько столбцов, сколько их указано в списке раздела CYRCLE. Каждый элемент массива соответствует строке результата, и в его столбцах содержится копия значений соответствующих столбцов этой строки. Вот пример запроса, содержащего раздел CYRCLE (пример 20.5):
WITH RECURSIVE PARTS (PART_NUMBER,
NUMBER_OF_PARTS, COST) AS
(SELECT CONTAINED_PART, 1, 0.00
FROM CAR
WHERE CONTAINING_PART = ''
UNION ALL
SELECT CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS,
CAR.NUMBER_OF_PARTS * CAR.PART_COST
FROM CAR, PARTS
WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART)
CYRCLE CONTAINED_PART
SET CYCLEMARK TO 'Y' DEFAULT 'N'
USING CYRCLEPATH
SELECT PART_NUMBER, SUM(NUMBER_OF PARTS), SUM(COST)
FROM PARTS
ORDER BY PART_NUMBER;
Имена столбцов CYCLEMARK и CYRCLEPATH выбраны произвольным образом – требуется только, чтобы имена этих столбцов отличались от имен столбцов рекурсивного запроса. При выполнении запроса строки, удовлетворяющие его условию, накапливаются в результирующей таблице. Но, кроме того, эти строки «кэшируются» в столбце CYRCLEPATH. При попытке добавления к результату новой строки на основе текущего содержимого столбца CYRCLEPATH проверяется, не содержится ли она уже в результате. Если не содержится, то данные об этой строке добавляются к столбцу CYRCLEPATH (к массиву добавляется новый элемент), в столбец CYCLEMARK этой строки заносится значение 'N', и строка добавляется к результату. Иначе в столбец CYCLEMARK соответствующей строки результата заносится значение 'Y', означающее, что от этой строки начинается цикл.
20.3.3. Рекурсивные представления
Рекурсивным называется представление, в определяющем выражении запроса которого используется имя этого же представления. В представлениях может использоваться и прямая, и взаимная рекурсия. Синтаксис оператора определения рекурсивного запроса выглядит следующим образом:
CREATE RECURSIVE VIEW table_name [ column_name_comma_list ] AS query_expression
Хотя для того, чтобы представление было рекурсивным, требуется рекурсивность определяющего выражения запроса (т.е. в нем должна присутствовать спецификация RECURSIVE); наличие избыточного ключевого RECURSIVE в определении рекурсивного представления является обязательным. Как говорят авторы стандарта, это сделано для того, чтобы избежать случайного появления непредусмотренных рекурсивных представлений. Наконец, обратите внимание на то, что еще не обсуждавшийся нами необязательный раздел WITH CHECK OPTION не может присутствовать в определении рекурсивного представления (по той причине, что разработчики стандарта не смогли найти разумной интерпретации для комбинации RECURSIVE и WITH CHECK OPTION).
В заключение этого раздела могу сказать, что лично мне механизм рекурсии, предлагаемый в стандарте SQL, представляется громоздким и ограниченным. Кроме того, насколько мне известно, компании, поставляющие SQL-ориентированные СУБД, не спешат внедрять в свои продукты средства рекурсии в соответствии со стандартом SQL:1999 (или, по крайней мере, не слишком их афишируют).
20.4. Заключение
Если вернуться к синтаксическим определениям подраздела 17.2.1. «Общие синтаксические правила построения скалярных выражений» лекции 17, то можно убедиться, что в последних четырех лекциях мы рассмотрели все варианты организации оператора SELECT языка SQL (за исключением конструкций collection_derived_table и ONLY (table_or_query_name), относящихся к объектным расширениям языка SQL).
Для общего понимания языка на модельном уровне более важными являются предыдущие три лекции. Данная лекция включена в курс, скорее, с целью общего ознакомления читателей с новыми возможностями оператора выборки, чем с целью их подробного описания. С большой вероятностью средства формулировки аналитических и рекурсивных запросов языка SQL будут пересматриваться при подготовке следующих вариантов стандарта языка.