Базы данных. Вводный курс
Сергей Кузнецов20.2. Возможности формулирования аналитических запросов
Аналитическими запросами к базе данных принято называть запросы, сводные (агрегатные) результаты которых вычисляются над детальными данными, хранящимися в таблицах базы данных. В этом смысле любой запрос на языке SQL, результат которого основан на вычислении агрегатных функций, можно назвать аналитическим. Характерная особенность аналитических запросов состоит в том, что, как правило, они применяются к большим по объему базам данных, и выполнение таких запросов вызывает существенные накладные расходы СУБД.
В этом курсе мы не будем подробно обсуждать возможности языка SQL, предназначенные для поддержки оперативной аналитической обработки баз данных (OLAP – on-line analytical processing). Рассмотрим только самые основные средства, опираясь на простые примеры. Для этих примеров предположим, что таблица EMP содержит следующий набор строк (покажем содержимое только тех столбцов, которые потребуются в примерах, причем для простоты будем считать, что в столбце EMP_DATE содержится не полная дата, а только год рождения служащего):
EMP_NO | DEPT_NO | EMP_BDATE | EMP_SAL |
|---|---|---|---|
2440 | 1 | 1950 | 15000.00 |
2441 | 1 | 1950 | 16000.00 |
2442 | 1 | 1960 | 14000.00 |
2443 | 1 | 1960 | 19000.00 |
2444 | 2 | 1950 | 17000.00 |
2445 | 2 | 1950 | 16000.00 |
2446 | 2 | 1960 | 14000.00 |
2447 | 2 | 1960 | 20000.00 |
2448 | 3 | 1950 | 18000.00 |
2449 | 3 | 1950 | 13000.00 |
2450 | 3 | 1960 | 21000.00 |
2451 | 3 | 1960 | 22000.00 |
Представим себе, что для проведения анализа требуется узнать максимальный размер зарплаты на всем предприятии, максимальный размер зарплаты в каждом отделе и максимальный размер зарплаты служащих каждой возрастной категории каждого отдела. Если пользоваться стандартными средствами языка SQL, обсуждавшимися ранее в предложенном курсе, то для получения этих данных потребуется три запроса:
SELECT MAX (EMP_SAL) AS MAX_ENT_SAL
FROM EMP;
SELECT DEPT_NO, MAX (EMP_SAL) AS MAX_DEP_SAL
FROM EMP
GROUP BY DEPT_NO;
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL)
AS MAX_DEP_BDATE_SAL
FROM EMP
GROUP BY DEPT_NO, EMP_BDATE;
При выполнении запросов будут получены следующие результирующие таблицы:
MAX_ENT_SAL |
|---|
22000.00 |
DEPT_NO | MAX_DEP_SAL |
|---|---|
1 | 19000.00 |
2 | 20000.00 |
3 | 22000.00 |
DEPT_NO | EMP_BDATE | MAX_DEP_BDATE_SAL |
|---|---|---|
1 | 1950 | 16000.00 |
1 | 1960 | 19000.00 |
2 | 1950 | 17000.00 |
2 | 1960 | 20000.00 |
3 | 1950 | 18000.00 |
3 | 1960 | 22000.00 |
20.2.1. Раздел GROUP BY ROLLUP
Эти же результаты можно получить при выполнении единственного запроса, если в его формулировке использовать специальный вид группировки ROLLUP (пример 20.1):
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_SAL
FROM EMP
GROUP BY ROLLUP (DEPT_NO, EMP_BDATE);
Сначала покажем, как будет выглядеть результирующая таблица этого запроса, а потом приведем развернутое пояснение действия новой конструкции. В результате выполнения запроса будет получена таблица, показанная на рис. 20.1.
Как видно, в столбце MAX_SAL первой строки150) результирующей таблицы находится максимальное значение зарплаты служащих на всем предприятии. Столбцы DEPT_NO и EMP_BDATE в этой строке содержат неопределенное значение, поскольку значение MAX_SAL не привязано к каким-либо отделу и возрастной категории. В столбце MAX_SAL следующих трех строк находятся максимальные значения зарплаты служащих отделов с номерами 1, 2 и 3 соответственно, что показывают значения столбца DEPT_NO. Столбец EMP_BDATE в этих строках содержит неопределенное значение, поскольку значение MAX_SAL не привязано к какой-либо возрастной категории. Наконец, в столбце MAX_SAL в последних шести строках содержатся максимальные значения зарплаты служащих каждой возрастной категории каждого отдела, что показывают значения столбцов DEPT_NO и EMP_BDATE, которые теперь содержат соответствующий номер отдела и год рождения служащих.
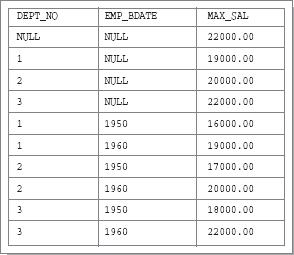
Рис. 20.1. Результат запроса с разделом GROUP BY ROLLUP
В общем случае пусть раздел группирn), где cnamei (i = 1, 2, ... , n) – имя столбца таблицы-результата раздела FROM запроса. Пусть в списке выборки используются вызовы агрегатных функций AGG1, AGG2, ... , AGGm над значениями столбцов, не входящих в список группировки, а также имена столбцов cname1, cname2, ... , cnamen. Тогда запрос выполняется следующим образом. Первая строка результата (первый набор строк результирующей таблицы) производится таким образом, как если бы в запросе вообще отсутствовал раздел GROUP BY, т.е. агрегатные функции AGG1, AGG2, ... , AGGm вычисляются над значениями всех строк таблицы. Значением столбцов cname1, cname2, ... , cnamen в этой строке является NULL. (i+1)-й набор строк результата формируется так, как если бы раздел группировки запроса имел вид GROUP BY (cname1, cname2, ... , cnamei) (1). Во всех этих строках значением столбцов ![]() i<n
i<ncname(i+1), ... , cnamen является NULL. Наконец, (n+1)-й набор строк результата формируется так, как если бы раздел группировки запроса имел вид GROUP BY (cname1, cname2, ... , cnamen).
Может показаться, что запросы, содержащие раздел GROUP BY ROLLUP, настолько сложны, что их выполнение будет занимать чрезмерно большое время. Это ощущение является ложным. В действительности, при выполнении запросов с обычной группировкой вида GROUP BY cname1, cname2, ... , cnamen, как правило, последовательно выполняется сортировка строк таблицы-результата раздела FROM в соответствии со значениями столбца cname1, затем – в соответствии со значениями столбца cname2 и т. д., и в заключение – сортировка в соответствии со значениями столбца cnamen. Во время выполнения каждой сортировки можно заодно вычислять значения агрегатных функций. Так что стоимость выполнения запроса, содержащего раздел GROUP BY ROLLUP, лишь незначительно отличается от стоимости выполнения запроса с обычной группировкой.
20.2.2. Агрегатная функция GROUPING
Обсудим теперь один более тонкий вопрос. Как говорилось в лекции 16, определение столбцов DEPT_NO и EMP_BDATE таблицы EMP допускает появление в этих столбцах неопределенных значений. Поэтому тело таблицы EMP могло бы иметь, например, следующий вид:
EMP_NO | DEPT_NO | EMP_BDATE | EMP_SAL |
|---|---|---|---|
2440 | 1 | 1950 | 15000.00 |
2441 | 1 | 1950 | 16000.00 |
2442 | 1 | 1960 | 14000.00 |
2443 | 1 | 1960 | 19000.00 |
2452 | 1 | NULL | 15000.00 |
2453 | 1 | NULL | 17000.00 |
2444 | 2 | 1950 | 17000.00 |
2445 | 2 | 1950 | 16000.00 |
2446 | 2 | 1960 | 14000.00 |
2447 | 2 | 1960 | 20000.00 |
2448 | 3 | 1950 | 18000.00 |
2449 | 3 | 1950 | 13000.00 |
2450 | 3 | 1960 | 21000.00 |
2451 | 3 | 1960 | 22000.00 |
2454 | NULL | 1950 | 13000.00 |
2455 | NULL | 1950 | 14000.00 |
2456 | NULL | NULL | 19000.00 |
Тогда результат запроса из примера 20.1 имел бы следующий вид151):
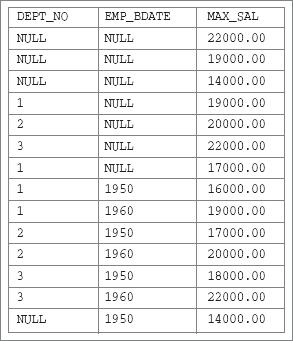
Рис. 20.2. Результат запроса с разделом GROUP BY ROLLUP к таблице с неопределенными значениями столбцов группировки
Очевидно, что, просматривая строки таблицы, показанной на рис. 20.2, невозможно установить, в какой из первых трех строк неопределенное значение столбцов DEPT_NO и EMP_BDATE означает то, что эта строка является сводной для всего предприятия, а не то, что она является сводной для всех служащих с неизвестными номером отдела и годом рождения или просто для всех служащих с неизвестным номером отдела. Аналогичным образом невозможно понять, какая строка в следующей далее паре строк является сводной для всех служащих отдела номер 1, а не для всех служащих отдела номер 1 с неизвестным годом рождения.
Для того чтобы всегда можно было разобраться в результатах запросов, включающих раздел GROUP BY ROLLUP, в язык SQL была введена специальная агрегатная функция GROUPING. Эта функция применяется к столбцу, входящему в список столбцов раздела GROUP BY ROLLUP, и принимает целое значение 1 в тех строках результирующей таблицы, в которых соответствующий столбец имеет значение NULL по той причине, что строка является сводной для более обобщенной группы. В противном случае функция GROUPING принимает значение 0.
Уточним формулировку запроса из примера 20.1 (пример 20.1.1):
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_SAL,
GROUPING (DEPT_NO) AS GDN, GROUPING (EMP_BDATE)
AS GEB
FROM EMP
GROUP BY ROLLUP (DEPT_NO, EMP_BDATE);
Результирующая таблица для этого запроса будет иметь следующий вид:
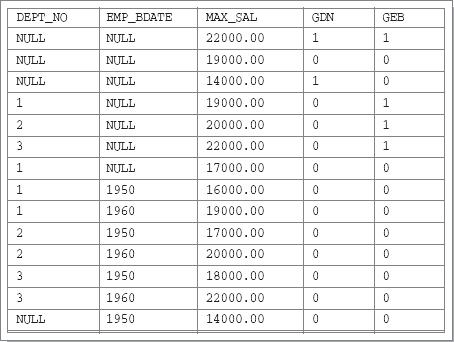
Рис. 20.3. Результат запроса с разделом GROUP BY ROLLUP и вызовами агрегатной функции GROUPING к таблице с неопределенными значениями столбцов группировки
Анализируя значения столбцов GDN и GEB в строках таблицы, показанной на рис. 20.3, можно убедиться, что значение столбца MAX_SAL в первой строке является максимальным значением зарплаты всех служащих предприятия, во второй строке – максимальным значением зарплаты служащих с неизвестными номером отдела и годом рождения, а в третьей строке – максимальным значением зарплаты всех служащих с неизвестным номером отдела. В следующих трех строках значения столбца MAX_SAL являются максимальными значениями зарплаты служащих с неизвестным годом рождения из отделов с номерами 1, 2 и 3 соответственно. Как видно, значения столбцов GDN и GEB являются своего рода индикаторами, указывающими на природу основных значений строки.
20.2.3. Раздел GROUP BY CUBE
Наконец, заметим, что, в отличие от запросов с традиционной группировкой, результат запроса, содержащего раздел GROUP BY ROLLUP, зависит от порядка столбцов в списке группировки. При выполнении запроса происходит движение по этому списку слева направо с повышением уровня детальности результирующих данных. Существует еще одна разновидность запроса с группировкой, основанная на использовании раздела GROUP BY CUBE.
Пусть раздел группировки запроса имеет вид GROUP BY CUBE (cname1, cname2, ... , cnamen), где cnamei (i = 1, 2, ... , n) – имя столбца таблицы-результата раздела FROM запроса. Обозначим через SGBC множество {cname1, cname2, ... , cnamen}. Пусть Si является произвольным подмножеством SGBC, т.е. Si представляет собой пустое множество или имеет вид {cnamei1, cnamei2, ... , cnameim}, где m, и каждое имя столбца ![]() n
ncnameij совпадает с одним и только одним именем столбца из списка столбцов раздела GROUP BY CUBE. Очевидно, что у множества SGBC существует 2n подмножеств различных вида Si. Тогда по определению результат этого запроса совпадает с объединением результатов 2n запросов с теми же разделами SELECT, FROM и WHERE, что и у запроса с GROUP BY CUBE, и с разделом группировки вида GROUP BY Si, причем во всех строках результата частичного запроса значением любого столбца cnamej такого, что cnamej и ![]() SGBC
SGBCcnamej , является ![]() Si
SiNULL. Запрос с разделом группировки вида GROUP BY S, где S – пустое множество, трактуется как запрос без раздела GROUP BY. Вот пример запроса, содержащего раздел GROUP BY CUBE.
Пример 20.2. Найти максимальный размер зарплаты во всем предприятии, максимальный размер зарплаты в каждом отделе, максимальный размер зарплаты служащих в каждой возрастной категории и максимальный размер зарплаты служащих каждой возрастной категории каждого отдела.
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL)AS MAX_SAL, GROUPING (DEPT_NO) AS GDN, GROUPING (EMP_BDATE) AS GEB FROM EMP GROUP BY CUBE (DEPT_NO, EMP_BDATE);
Результирующая таблица для этого запроса будет иметь следующий вид:
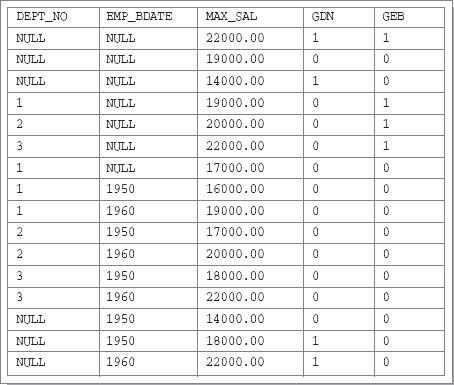
Рис. 20.4. Результат запроса с разделом GROUP BY CUBE и вызовами агрегатной функции GROUPING к таблице с неопределенными значениями столбцов группировки
Как видно, результат запроса из примера 20.2 совсем немного отличается от результата запроса из примера 20.1.1. Добавились две последние строки, показывающие максимальные значения зарплаты всех служащих предприятия, родившихся в 1950-м и 1960-м гг. соответственно.
Наш пример может навести на мысль, что и в общем случае запросы, содержащие раздел GROUP BY CUBE, не слишком отличаются от запросов с GROUP BY ROLLUP, и выполнение этих запросов тоже не слишком различается. Однако это совсем не так. Запрос, содержащий раздел GROUP BY CUBE, действительно вырождается в объединение результатов 2n запросов с обычным разделом GROUP BY. Соответственно, сложность выполнения такого запроса несравненно выше сложности выполнения похожего запроса с GROUP BY ROLLUP. В нашем примере все получилось так просто только по той причине, что в запросе имеются всего два столбца группировки.
150
Конечно, мы показали строки результирующей таблицы, расположенные в удобном для нас порядке только для упрощения объяснений. В действительности, строки результирующей таблицы (как обычно) будут расположены в порядке, определяемом системой. Чтобы добиться в точности такого порядка расположения строк, как это показано на рис. 20.1
, к формулировке запроса из примера 20.1
нужно добавить раздел ORDER BY DEPT_NO
, EMP_BDATE
.
151 Мы опять искусственным образом упорядочили результат запроса для удобства пояснений.