Специализированные языки
Майк Шапиро
Перевод Сергея Кузнецова
Оригинал: Mike Shapiro. Purpose-Built Languages, ACM Queue, Vol. 7, No. 1, January 2009
В компьютерной лаборатории моего колледжа в перерывах еженощных бдений над кодированием и отладкой обсуждались две вечные темы: «что лучше, emacs или vi?» и «какой язык программирования самый хороший?». Позже, когда я начал работать в индустрии, я заметил, что споры вокруг языков программирования продолжались и в кампусах Кремниевой Долины. Это было в 1990-е гг., и многие в Sun ожидали, что Java завоюет значительную популярность среди разработчиков, особенно тех, которые до этого использовали C или C++.
Я всегда считал, что понятие наилучшего языка является слишком субъективным и слишком зависимым от природы текущей программистской задачи. Однако в течение своей карьеры я потратил много времени на обдумывание двух связанных с этим вопросов, которые кажутся мне более принципиальными. Во-первых, не сокращается ли со временем число языков, используемых при разработке программного обеспечения в целом? Другими словами, не сужается ли множество компьютерных языков? Во-вторых, из-за чего некоторый конкретный язык оказывается более пригодным, или более полезным, или быстрее осваиваемым при решении некоторой частной задачи?
При размышлении над этими вопросами я пришел к заключению, что интереснее наблюдать не за битвой тяжеловесов, а за их менее изученными отпрысками – специализированными (purpose-built) языками. Эти языки вырастают как сорняки на обочине основного пути развития языков, и их свойства и история заставляют пересмотреть интуитивные ответы на принципиальные вопросы относительно языков программирования. С учетом специализированных языков оказывается, что разработка языков программирования вовсе не сокращается, а их полезность определяется вовсе не улучшенной структурой или более развитыми свойствами с традиционных позиций конструирования языков. В специализированных языках даже игнорируется строгое определение, являющееся нормой для разработчиков компиляторов:
- они как-то «меньше» полнофункциональных языков программирования;
- часто они не являются полными по Тьюрингу;
- у них может отсутствовать формальная грамматика (и парсеры);
- иногда они используются автономно, но часто входят в более сложную среду или объемлющую программу;
- часто, но не всегда они интерпретируются;
- обычно они разрабатываются для какой-либо одной цели, но часто (непредумышленно) способы их использования изменяются.
И у некоторых таких языков даже отсутствует название.
Наиболее важно то, что на использовании специализированных языков часто основывается значительная часть разработки крупных программных систем, таких как операционные системы. Они либо служат инструментами разработки, либо позволяют «склеивать» различные части более крупной среды. Поэтому особенно интересно «раскопать» некоторые малоизвестные подобные творения и взглянуть на их связи с нашими общими представлениями о языках программирования. В течение своей карьеры, работая над несколькими коммерческими операционными системами и крупными программными компонентами, я пришел к выводу, что постоянная разработка новых языков является неотъемлемой частью процесса развития и сопровождения широкомасштабных программных систем
Среда Unix с ее философией поддержки многочисленных легко связываемых мелких инструментальных средств была идеальной оранжереей для взращивания специализированных языков. Поверхностный просмотр руководств по ОС Unix начала 1980-х гг. показывает, что в это время активно использовалось более 20 мелких языков разного вида (см. рис. 1).
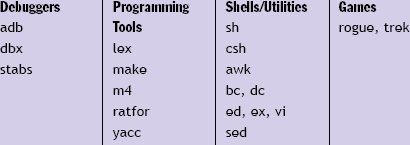

Рис. 1. Небольшие языки в Unix в начале 1980-х гг.
В состав этих языков входили полные языки программирования (sh), препроцессоры (yacc), командные языки (adb) для представления конечных автоматов и структур данных (регулярных выражений, отладочных «заглушек»). Двадцать лет спустя, когда Sun выпустила современную Unix-систему Solaris 10, почти для всех новых существенных средств операционной системы потребовалось введение новых специализированных языков:
- для трассировки запросов в отладочном программном обеспечении
DTraceбыл разработан языкD; - система
Fault Managementвключала язык для описания распространения ошибок; - в средствах управления зонами и службами использовались основанные на XML языковые средства описания конфигураций и новые командные интерпретаторы.
История одного из этих небольших языков из мира Unix, а именно, того, который используется в отладчике adb, особенно хорошо иллюстрирует стихийное развитие и одновременную закоснелость мелкого языкового средства, полезного в крупной системе.
Развитие без отчетливой цели
Ранняя разработка Unix происходила на системах PDP компании DEC, на которых имелся очень простой отладчик ODT (Octal Debugging Technique). В программах ODT поддерживался совершенно примитивный синтаксис: каждая команда состояла из восьмеричного адреса слова физической памяти, за которым следовал одиночный символ («B» для установки точки прерывания или слеш («/») для чтения и, возможно, записи содержимого в эту ячейку памяти) (см. рис. 2A).

Рис. 2. Синтаксис отладчика ODT-8, примерно 1967 г.
Итак, появился небольшой язык. Синтаксис ODT, очевидно, повлиял на вид первого отладчика новой системы Unix, разрабатывавшейся на PDP. Этот отладчик назвали просто db. Ко времени Unix V3 в 1971 г. в командном синтаксисе db были заимствованы основные черты языка ODT, который начал расширяться за счет использования дополнительных символов для определения режимов адресации и вариантов форматирования вывода, как показано на рис. 2B.
К 1980 г. db был заменен на adb, который был включен в описание AT&T SVR3 Unix. За это время в языке появилось несколько новых отладочных команд. Теперь поддерживались не только простые адреса, но и арифметические выражения (например, допустимой конструкцией стала «123+456 /»). Кроме того, символ после «/» теперь обозначал формат, а символ после «$» – действие. Синтаксис adb показан на рис. 2C.
Особенно интересной была конструкция «$<» для чтения внешнего командного файла, поскольку она обеспечила возможность разработки примитивных adb-программ, или макросов, в которых выполнялись последовательности команд, отображающих содержимое структур данных языка C по заданным адресам памяти. Т.е. для отображения структуры данных ядра proc нужно было взять ее адрес и затем ввести $ для выполнения предопределенной последовательности команд, отображающих содержимое памяти, в которой располагалась структура данных языка C, описывающая соответствующий процесс. Вид макроса proc в SunOS 4 образца 1984 г. показан на рис. 3. Для облегчения понимания вывода теперь стало позволяться дописывать к команде «/» в кавычках символы перехода на новую строку («n») и табуляции («16t»), которые включались в выводимые данные макроса. Переменная «.» содержала адрес, указанный при вызове макроса, а переменная «+» – этот исходный адрес, увеличенный на число байт, которые занимали все предшествующие символы форматирования. Такие макросы поддерживались вместе с исходным кодом ядра.

Рис. 3. Отладка структуры proc в SunOS 4, около 1984 г.
Более чем на 10 лет позже, в 1997 г. я работал в Sun над системой, которая стала Solaris 7. Это было наше первое 64-разрядное ядро, но для отладки ядра был доступен только все тот же adb, что и в 1984 г., и в нашей базе исходных кодов теперь содержались сотни полезных файлов с макросами. К сожалению, было практически невозможно портировать adb с 32-разрядной на 64-разрядную архитектуру, так что казалось, что пришло время для разработки нового, более современного отладчика с многими более развитыми возможностями.
Когда я размышлял, как лучше подойти к решению этой проблемы, мне пришло в голову, что, несмотря наличие у adb машинно-зависимого, неструктурированного кода, ключевой особенностью этого отладчика является его синтаксис, который глубоко проник в умы и стиль работы всех наших наиболее опытных и эффективных инженеров. (Как кто-то метко заметил в то время, «он на кончиках наших пальцев».) Поэтому я предложил создать новый модульный отладчик (mdb), поддерживающий API для развитой отладки ядра и другие современные возможности, но сохраняющий точную обратную совместимость с существующим синтаксисов и макросами. Усложненные новые конструкции добавлялись путем введения нового префикса («::»), так что они не подрывали существующий синтаксис (например, появилась конструкция «::findleaks» для проверки отсутствия утечки памяти в ядре). Полный синтаксис был должным образом закодирован как парсер yacc. От использования файлов-макросов постепенно отказались в пользу отладочной информации, генерируемой компиляторами, но синтаксис «$<» был оставлен в качестве алиаса. Десять лет спустя mdb остается стандартным инструментом «посмертной» отладки ядра OpenSolaris и расширяется сотнями программистов.
Эта история об отладчиках иллюстрирует ту мысль, что небольшие встраиваемые специализированные языки могут развиваться, по существу, случайным образом, без наличия отчетливой цели, согласованной грамматики или парсера и даже названия, и, тем не менее, выживать и разрастаться в средах производственных операционных систем в течение более чем 40 лет. За этот же период времени возникли и ушли в небытие многие массовые языки (Algol, Ada, Pascal, Cobol и т.д.). По сути дела, этот язык отладчиков выжил по одной причине: он позволял точно кодировать задачу, выполнение которой требовалось пользователям, и поэтому был им близок. Взять адрес, получить содержимое соответствующей ячейки памяти, найти следующий адрес, перейти к следующей интересующей ячейке, получить ее содержимое и т.д. Для специализированных языков глубокая связь с некоторой задачей и соответствующим сообществом пользователей часто является более ценной, чем отчетливая цель и элегантный синтаксис.
Мутация и гибридизация
При разработке специализированных встроенных языков часто играет важную роль мутация, иногда случайная, а иногда намеренная. Один из распространенных видов мутации состоит в добавлении к одному языку некоторого подмножества синтаксических конструкций другого языка (например, регулярных выражений). Этот тип мутации может реализовываться путем использования препроцессора, преобразующего одни высокоуровневые конструкции в другие или переплетающего синтаксис добавляемых конструкций с синтаксисом целевого языка. Мутации могут зайти настолько далеко, что в результате образуется новый гибридный язык. Наиболее известные примеры полностью гибридных языков представляют инструментальные средства построения синтаксических анализаторов yacc и bison. Грамматика целевого языка определяется в виде набора правил синтаксического разбора, переплетенных с кодом на языке С, который выполняется под управлением этих правил. В результате работы этих инструментальных средств порождается C-программа, включающая код для правил и код автомата синтаксического разбора на основе заданной грамматики.
Еще одним примером этого типа мутации в среде ранних вариантов Unix являлся препроцессор Ratfor (Rational Fortran), разработанный Брайаном Керниганом (Brian Kernighan). В программах на языке Ratfor позволялось писать Fortran-код с использованием выражений и логических блоков языка C. Препроцессор транслировал такую программу в программу на чистом языке Fortran с номерами строк и операторами goto, как это показано на рис. 4.

Рис. 4. Fortran и Ratfor, примерно 1975 г.
Еще более странным мутантным языком был гибрид языков C и Algol, реализованный с использованием препроцессора для языка C и применявшийся в коде adb. По-видимому, Стив Борн (Steve Bourne), автор алголоподобного синтаксиса shell, хотел, чтобы в будущих языках сохранялась часть генома языка Algol. Примерный код показан на рис. 5.

Рис. 5. Мутант C и Algol из раннего варианта adb
Увы, для облегчения сопровождения более поздние версии этого кода пропускались через препроцессор и сохранялись уже в преобразованном виде. Во многих дальнейших языках имелась более четкая гибридизация, облегчающая переход от одной среды к другой. Вслед за широким распространением языка C синтаксис его выражений стал использоваться в огромном числе новых языков, больших и маленьких, включая Awk, C++, Java, JavaScript, D, Ruby и многие другие. Аналогично, вслед за успехом языка Perl во многих других скриптовых языках были переняты его полезные расширения синтаксиса регулярных выражений как новая каноническая форма. Базовые концепции, такие как синтаксис выражений, часто образуют основную часть небольшого языка, и заимствования из какой-либо общепринятой модели позволяют быстро его реализовать и внедрить в практическое использование.
Симбиоз
При разработке крупных программных систем небольшие языки часто находятся в симбиотическом партнерстве с основным языком разработки или с самой системой. Описанный выше макроязык adb не выжил бы вне базы исходных кодов своего родителя – системы Unix. Другим примером является макроязык любимых многими электронных таблиц: он существует для обеспечения удобного способа манипулировать видимыми пользователями абстракциями содержащего их программного приложения.
В мире операционных систем моим любимым примером симбиоза является объединение языка Forth с языком ассемблера SPARC, созданное в Sun в ходе работы над встроенным программным обеспечением OpenBoot. Идея состояла в том, чтобы создать небольшой интерпретатор, используемый в качестве среды начальной загрузки рабочих станций SPARC. Для среды начальной загрузки был выбран язык Forth, поскольку ядро этого языка является крошечным и может быть моментально перенесено на новые процессор и платформу. Кроме того, с использованием словарей Forth в интерпретаторе можно «на лету» определять новые команды для отладки. Поскольку в языке Forth допускается, чтобы его словари подменяли определения слов (лексем) в интерпретаторе, возникла оригинальная идея использования интерпретатора как макроассемблера для аппаратуры. Был создан набор словарей для переопределения всех кодов операций SPARC (ld, move, add и т.д.) кодами Forth, которые вычисляли бинарное представление ассемблируемых команд и сохраняли его в памяти. Тем самым, все низкоуровневые функции можно было писать на языке, который выглядел как язык ассемблера, сопровождаемый Forth-заголовками. Текст вводился в крошечный интерпретатор, который ассемблировал его в объектный код в основной памяти по мере разбора лексем и выполнял результирующую подпрограмму.
В последние годы плодородной почвой для мутации и симбиоза стали Web-браузеры. Центральными фигурами в современной Web-разработке являются интерпретируемые JavaScript и XML. (XML является синтаксической основой для разнообразных других языков и богатым источников гибридных языков и мутаций.) В распространенной модели программирования Ajax объекты JavaScript могут сериализоваться в форме XML, и XML-кодировки могут использоваться для передачи на сервер обратных вызовов удаленных процедур. В одной из таких кодировок, XML-RPC, обеспечивается стандартное расширение multicall, позволяющее браузеру на стороне клиента вызывать несколько процедур на стороне сервера за одну передачу данных по сети. Ниже показан пример одиночного вызова метода x.foo, за которым следует последовательность вызовов того же метода с использованием multicall:
x.foo( { bar: 123, baz: 456 } ) ;
system.multicall (
{ methodName: ‘x.foo’,
params: [ { bar: 123, baz: 456 } ] },
{ methodName: ‘x.foo’,
params: [ { bar: 789, baz: 654 } ] },
{ methodName: ‘x.foo’,
params: [ { bar: 222, baz: 333 } ] }
)
При разработке кода пользовательского интерфейса Ajax для новой линейки продуктов хранения данных группа Fishworks компании Sun хотела обеспечить способ минимизации числа взаимодействий клиента и сервера. Сначала было придумано понятие множественного вызова, в котором параметр являлся результатом другого вызова. В следующем примере метод x.foo вызывается над результатом вызова x.bar при одном взаимодействии XML-RPC:
system.multicall (
{ methodName: ‘x.foo’, methodParams: [
{ methodName: ‘x.bar’, params: [ 1, 2, 3 ] }
] } ,
...
)
Хитрость здесь состоит в том, что новый член структуры methodParams указывает, что следующие члены являются не статическими параметрами, а требуется рекурсивно вызывать другие методы, записывая в стек результаты этих вызовов. Поскольку требовалось поддерживать стек, единственным естественным путем было использование операций из какого-нибудь языка, основанного на стеке, с формированием полностью нового интерпретируемого языка, программа на котором объявляется как данные в JavaScript, посылается серверу с использованием существующей сериализации XML-RPC и исполняется расширениями нашего интерпретатора XML-RPC. Некоторые операции, реализованные нами в Sun, показаны ниже:
system.multicall (
{ foreach: [ [ 2, 4, 6 ], [
{ methodName: ‘x.foo’, params: [] },
{ push: [ ] },
{ div: [ { pop: [] }, 2 ] }
] ] }
...
)
Этот пример показывает, что симбиотическая связь с JavaScript, по существу, позволяет существовать нашему языку без потребности в наличии собственного лексического или синтаксического анализатора и в основном служит целям переноса кода, критичного для производительности, из JavaScript на наш сервер и минимизации числа взаимодействий клиента и сервера. В индустрии видеоигр аналогичный симбиоз (без гибридного синтаксиса) был разработан между Lua и C/C++. Скриптовый язык Lua поддерживает распространенный способ написания кода игровых движков, не критичного для производительности, а конструкция интерпретатора Lua облегчает связывание с C-кодом.
Если в крупной программной системе взаимодействуют два или большее число языков, естественно образовать вокруг них экосистему инструментальных средств (возможно, путем соединения небольших языков на основе гибридного синтаксиса) для облегчения поддержки, развития и отладки системы в целом. Чем богаче экосистема, развивающаяся вокруг языков полной программной системы, как небольших, так и крупных, как специализированных, так и универсальных, тем дольше будет процветать среда в целом, и тем дольше будут успешно использоваться ее элементы. Поэтому, чем выше становятся наши башни программных абстракций, тем большее, а не меньшее число языков нам придется видеть и знать.