2010 г.
Преобразование запросов, основанное на стоимости
Рафи Ахмед, Эллисон Ли, Эндрю Витковски, Динеш Дас, Хонг Су, Мохамед Зэйд, Тьерри Крюейнс
Перевод Леонида Борчука
Под ред. Сергея Кузнецова
Оригинал: Cost-Based Query Transformation in Oracle / Rafi Ahmed, Allison Lee, Andrew Witkowski, Dinesh Das, Hong Su, Mohamed Zait, Thierry Cruanes // Proceedings of the 32nd international conference on Very large data base, 2006, pp. 1026 — 1036
Назад Содержание
Мы провели эксперименты для изучения эффективности преобразований запросов, основанных на оценке стоимости. Чтобы опираться на реалистичную рабочую нагрузку, мы исследовали запросы, производимые Oracle Applications. Его схема содержит около 14 000 таблиц, представляющих приложения кадровой службы (human resources), финансовые приложения (financial), приложения приема заявок (order entry), CRM, управления цепочкой поставок (supply chain) и т.д. Базы данных большинства приложений имеют сильно нормализованные схемы.
Рабочая нагрузка (workload) содержала 241 000 запросов, произведенных Oracle Applications. Количество таблиц в запросах варьируется между 1 и 159, в среднем — 8 таблиц на запрос. Следует подчеркнуть, что большую часть запросов этой рабочей нагрузки составляют запросы типа SPJ. Так что только у малой части — около 8% — этих запросов имеются подзапросы, раздел GROUP BY, раздел SELECT DISTINCT или представления с UNION ALL, которые являются предметом преобразований, основанных на оценке стоимости, которые использовались в этих экспериментах.
В этом эксперименте мы использовали собственное инструментальное средство для изучения планов выполнения всех 241 000 запросов с выключенным и включенным преобразованием, основанным на оценке стоимости. Из них только для около 19 000 запросов были применимы преобразования, основанные на оценке стоимости. Если преобразования, основанные на оценке стоимости, были выключены, устранение вложенности подзапросов, слияние представлений с группировкой и проталкивание предикатов соединения применялись на основе эвристических правил; в подразделе 2.2. мы описали эвристические правила, используемые для устранения вложенности подзапросов.
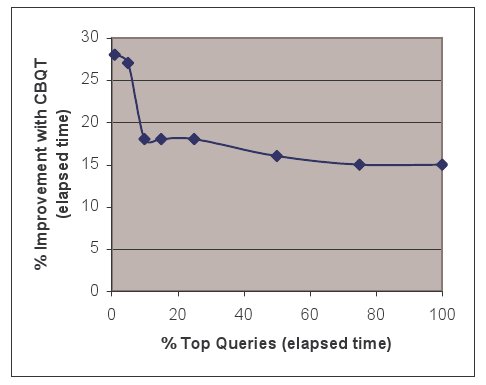
Рис. 2. Относительное повышение производительности за счет преобразований, основанных на оценке стоимости (Cost-Based Query Transformation, CBQT), как функция первых N% наиболее дорогостоящих запросов
Планы выполнения 5 910 запросов (т.е. 2,45% рабочей нагрузки) изменились; отметим, что для некоторых запросов, для которых не было обнаружено различий в плане выполнения, решения, основанные на оценке стоимости и эвристиках, могли быть одинаковы. Затем мы измеряли время оптимизации и выполнения запросов, для которых имелись различия в планах выполнения. В среднем при использовании преобразований, основанных на оценке стоимости, общее время исполнения (оптимизация + выполнение) этих запросов улучшилось на 20%. У небольшой части (18%) запросов, затронутых преобразованиями, производительность упала на 40%. На рис. 2 представлено повышение производительности после преобразований на основе оценки стоимости как функция от первых N наиболее долго выполняющихся запросов.
Первые N определяются как N наиболее долго выполняющихся запросов при отсутствии преобразований, основанных на оценке стоимости. Например, первые 5% наиболее долго выполняющихся запросов показали заметное повышение производительности на 27%; первые 25% показали повышение производительности на 18% и так далее. У первых 20 запросов за счет использования преобразований, основанных на оценке стоимости, производительность в среднем повысилась на 250%. Стоит заметить, что имелся один аномальный запрос, общее время исполнения которого после выполнении преобразований, основанных на оценке стоимости, уменьшилось в 214 раз. Этот запрос не учтен на рис. 2. Отметим, что преобразование, основанное на стоимости, в основном улучшает те запросы, которые являются более дорогостоящими (например, первые 5% из самых дорогостоящих выигрывают от преобразований больше, чем первые 25%).
Платой за сокращение времени выполнения запросов явилось время оптимизации, которое увеличилось на 40%.
Мы хотели оценить влияние двух преобразований запросов: устранение вложенности подзапросов (поскольку это преобразование активно исследовалось в литературе и применимо для запросов нашей рабочей нагрузки) и проталкивание предикатов соединения (так как это относительно новая техника, которая вносит корреляцию, и, следовательно, оказывает действие, противоположное действию первого преобразования).
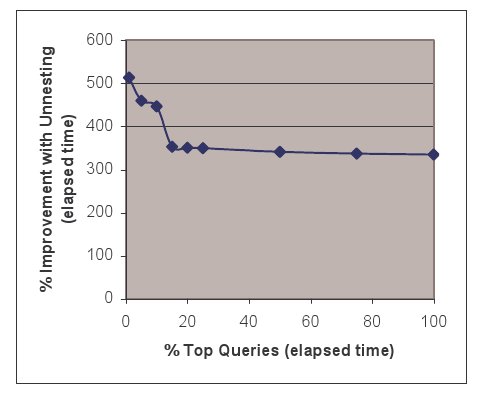
Рис. 3. Относительное повышение производительности за счет устранения вложенности подзапросов как функция первых N% наиболее дорогостоящих запросов
Мы провели эксперименты, в которых сравнили время выполнения запросов с полным отсутствием устранения вложенности со временем выполнения запросов, подвергнутых преобразованию устранения вложенности на основе оценки стоимости. Этот эксперимент затронул 12 279 запросов, то есть 5% всей рабочей нагрузки. В среднем использование преобразования устранение вложенности привело к повышению производительности примерно на 387%. Производительность небольшой части затронутых запросов (15%) ухудшилась на 50%. На рис. 3 представлены данные о повышении производительности после выполнения преобразования как функция от первых N наиболее долго выполняющихся запросов. Первые N определяются по-прежнему. Например, для первых 5% наиболее долго выполняющихся запросов было получено заметное повышение производительности на 460%. Для первых 25% повышение производительности составило 350%.
Платой за сокращение времени выполнения запросов явилось время оптимизации, которое увеличилось на 31%. Отметим, что от данного преобразования в большей степени выигрывают дорогостоящие запросы.
Мы провели третий набор экспериментов, в котором сравнили производительность запросов с полным отсутствием проталкивания предикатов соединения (Join Predicate Pushdown, JPPD) с производительностью запросов, для которых выполнялось это преобразование на основе оценок стоимости. Преобразование JPPD затронуло 1797 запросов, то есть 0,75% всей рабочей нагрузки.
В среднем использование преобразования JPPD повысило производительность примерно на 387%. Производительность небольшой части затронутых запросов (11%) снизилась на 15%. На рис. 4 представлены данные о повышении производительности после выполнения преобразования как функция от первых N наиболее долго выполняющихся запросов, где первые N определяются так же, как и ранее. Например, для первых 5% наиболее долго выполняющихся запросов было получено повышение производительности на 15%. Для первых 25% повышение производительности составило 23%. В этих экспериментах ухудшение производительности, наблюдавшееся у некоторых запросов, как правило, было связано с неправильной оценкой стоимости.
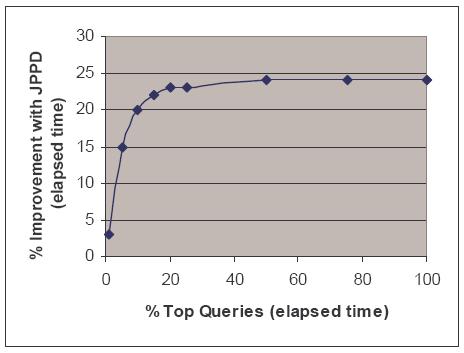
Рис. 4. Относительное повышение производительности за счет применения JPPD как функция первых N% наиболее дорогостоящих запросов
Заметим, что в отличие от преобразования устранения вложенности, от JPPD в большей степени выигрывают менее дорогостоящие запросы. Например, первые 80% наиболее дорогостоящих запросов выигрывают больше, чем первые 5%. Платой за сокращение времени выполнения запросов явилось время оптимизации, которое увеличилось на 7%.
В еще одном эксперименте на основе преобразования "размещение группировки" (Group-By Placement, GBP) мы сравнивали рабочую нагрузку с запросами, подвергнутыми и не подвергнутыми преобразованию GBP; в Oracle преобразование GBP никогда не применяется на основе эвристик. В этом эксперименте было затронуто более 2000 запросов. После применения GBP производительность в среднем повысилась на 21%. Хотя для некоторых запросов она ухудшилась, у 9 запросов повысилась более чем на 200% , а у двух запросов — более чем на 1000%.
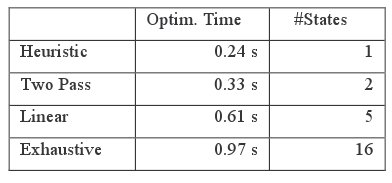
Одной из основных проблем преобразований, основанных на оценке стоимости, является увеличение времени оптимизации. Мы отмечали, что в экспериментах, описанных в предыдущих разделах, время оптимизации увеличивалось. В табл. 2 мы представили время оптимизации и число состояний для различных стратегий поиска в пространстве состояний (подраздел 3.2) для одного запроса, подвергавшегося преобразованию устранения вложенности. В этом запросе имелось 3 основных таблицы и 4 подзапроса, каждый из которых содержал 3 базовых таблицы и являлся подзапросом с NOT IN, EXISTS или NOT EXISTS. Для всех подзапросов допускалось преобразование устранения вложенности.
Увеличение времени оптимизации для различных стратегий поиска по сравнению с эвристическим режимом (то есть без преобразований, основанных на оценке стоимости) не является значительным из-за повторного использования аннотаций стоимости поддеревьев запроса.
Таблица 2. Увеличение времени оптимизации для различных методов поиска в пространстве состояний
В системе перезаписи запросов, основанной на правилах, можно исчерпывающим образом перебрать преобразования кустистого дерева [15] и оценить итоговые планы; это приводит к экспоненциальному росту количества планов и может быть непригодно для коммерческих оптимизаторов. В [19] была предпринята попытка объединения преобразований в двухфазную оптимизацию; во время генерации плана оптимизатор предлагает преобразование, пробует его применить, и переписанный запрос заново оптимизируется и оценивается. В [6] также предлагалось понятие перезаписи, чувствительной к стоимости. Однако в этих работах отсутствует систематическое применение различных возможных преобразований.
Как показано в [10], [22], [4] и [16], в запросах с подзапросами без агрегатов может быть устранена вложенность. В нашей системе поддерживаются почти все предлагавшиеся виды методов устранения вложенности. По нашему опыту, устранение вложенности подзапросов, которое приводит к порождению представления, не всегда обеспечивает более эффективный план.
Аналогично методам устранения вложенности SPJ-подзапросов, активно изучались и методы устранения подзапросов с агрегатами ([22], [7], [10] и [14]). В [22] представлена ранняя работа по преобразованиям, в которых агрегаты из вложенных подзапросов вытягиваются в дереве операций в позицию, предшествующую соединению. В ранних версиях нашей системы (версия 8.1) применялсяи аналогичный алгоритм. Преобразование инициировалось эвристическим образом на фазе преобразования запроса.
В [7], [1], [23] и [24] демонстрировались преобразования, в которых агрегаты проталкивались в позицию, предшествующую соединению. В [1] определяется жадная (greedy) и консервативная эвристика, применяемая во время перебора порядка соединений, в которой группировка помещается перед сканированием таблицы, если это приводит к более дешевому сканированию или соединению. В [2] определялось аналогичное преобразование вытягивания и проталкивания агрегатов, но, кроме того, демонстрировалось, как можно выполнять это преобразование на основе оценки стоимости; также обеспечивались две эвристики для контроля расширения пространства поиска. В нашей системе с самого начала использовались другие эвристики.
Методы проталкивания предикатов к одиночным отношениям сквозь представления с агрегатами и оконными функциями известны на протяжении долгого времени. В [9] предлагался метод, обобщающий эти подходы путем вытягивания предикатов вверх по дереву запроса, а затем проталкиванием их вниз, что приводит к тому, что при сканировании базовых таблиц становится возможно применить большее число однотабличных предикатов.
В [12] и [13] описывается преобразование магических множеств (magic set), которое добавляет новые представления к дорогостоящим блокам запроса с целью уменьшения объема обрабатываемых данных. В [19] эта работа расширяется методами выбора способа магической перезаписи на основе оценки стоимости. Предлагались два метода: первый (очень практичный) реализует преобразование в рамках существующего оптимизатора DB2, а второй основывается на алгебраических преобразованиях для оптимизации, основанной на правилах.
Внешние соединения некоммутативны с внутренними соединениями, и это ограничивает оптимизатор при выборе порядка соединений. Эта проблема изучается в [22], [18] и [3], где было показано, что для некоторых запросов внешнее соединение может коммутировать с внутренними соединениями за счет введения понятия обобщенного внешнего соединения. В [17] определяется каноническая абстракция внешнего соединения, которая позволяет оптимизатору использовать различные порядки соединений среди таблиц, соединяемых внешним и внутренним образом.
В этой статье описаны два основных результата.[5] Во-первых, предлагается применимое на практике решение для интеграции различных преобразований внутри инфраструктуры, основанной на оценке стоимости. У этой схемы имеется возможность моделировать большинство преобразований и их возможных взаимодействий, позволяя, тем самым, оптимизатору выбирать наиболее оптимальный вариант запроса. Второй результат состоит в том, что мы предлагаем алгоритмы поиска в пространстве состояний контролирования возможного комбинаторного взрыва преобразований, основанных на оценке стоимости. Мы также обсуждаем некоторые преобразования (например, проталкивание предикатов соединения и факторизация соединений), которые в литературе ранее не обсуждались.
Мы обнаружили, что для значительного числа разновидностей OLTP-запросов критичным является хорошо изученное преобразование устранения вложенности подзапросов. Общее время исполнения запросов, к которым применимо это преобразование, сокращается на 387%. Преобразование проталкивания предикатов соединения сокращает время исполнения на 23%. Для преобразования "расположение группировки" мы обнаружили сокращение времени исполнения на 21%. Что касается преобразований устранения вложенности подзапросов, слияния представлений с группировкой и проталкивания предикатов соединения, наши эксперименты показали, что преобразования, основанные на оценке стоимости, обеспечивают производительность, на 20% более высокую, чем преобразования, основанные на эвристиках.
Авторы хотели бы выразить признательность Вадиму Тропашко (Vadim Tropashko), оказавшему неоценимую помощь в проведении экспериментов по оценке производительности.
[1] Chaudhuri S., Shim K. Including Group-By in Query Optimization. In Proc. of VLDB. Santiago, 1994.
[2] Chaudhuri S., Shim K. Query Optimization with Aggregate Views. In Proc. of EDBT. Avignon, 1996.
[3] Galindo-Legaria C.A., et al. Outerjoin simplification and reordering for query optimization. TODS, 1997.
[4] Ganski R.A., Wong H.K.T. Optimization of Nested SQL Queries Revisited. Proc. of ACM SIGMOD, 1987.
[5] Garcia-Molina H., Ullman J.D., Widom J. Database System Implementation. Precent Hall, 2000.
[6] Graefe G., Mckenna W.J. The Volcano optimizer generator: Extensibility and Efficient Search. Proceedings of the 19 International Conf. on Data Engineering, 1993.
[7] Gupta A., Harinarayan V., Quass D. Aggregate-Query Processing in Data Warehousing Environments, In Proc. of 21 VLDB, 1995.
[8] Hellerstein J.M., Stonebraker M. Predicate migration: Optimizing Queries with Expensive Predicates. Proc. of ACM SIGMOD, Washington DC, 1993.
[9] Levy A.Y., Mumick I.S., Sagiv Y. Query Optimization by Predicate Move-Around. In Proc. of VLDB. Santiago, 1994.
[10] Kim W. On Optimizing an SQL-Like Nested Query. ACM TODS, 1982.
[11] Morzy T., Matysiak M., Salza S. Tabu Search Optimization of Large Join Queries. EDBT, 1994.
[12] Mumick I.S., Finkelstain S., Pirahesh H., Ramakrishnan R. Magic is Relevant. Proc. of ACM SIGMOD, 1990.
[13] Mumick I.S., Pirahesh H., Ramakrishnan R. Implementation of Magic Sets in Relational Database Systems. Proc. of ACM SIGMOD, 1994.
[14] Muralikrishna M. Improved Unnesting Algorithms for Join Aggregate SQL Queries. In Proc. of VLDB. Vancouver, 1992.
[15] Pellenkoft A., Galindo-Legaria C.A., Kersen M. The Complexity of the Transformation-Based Join Enumeration. In Proc. of VLDB. Athens, 1997.
[16] Rao J., Pirahesh J., Zuzarte C. Cannonical Abstractios for Outerjoin Optimization. Proc. of ACM SIGMOD, 2004.
[17] Pirahesh J., Hellerstein J.M., Hasan W. Extensible Rule Based Query Rewrite Optimizations in Starburst. Proc. of ACM SIGMOD, 1992.
[18] Rosenthal A., Cesar A., Galindo-Legaria C.A. Query Graphs, Implementing Trees, and Freely-reorderable Outerjoins. Proc. of ACM SIGMOD, 1990.
[19] Seshadri P., et al. Cost-Based Optimization for Magic Algebra and Implementation. Proc. of ACM SIGMOD, 1996.
[20] Swami A., Gupta A. Optimization of Large Join Queries. Proc. of ACM SIGMOD, 1988.
[21] Swami A. Optimization of Large Join Queries: Combining Heuristics and Combinatorial Techniques. Proc. of ACM SIGMOD, 1989.
[22] Dayal, U. Of Nests and Trees: A Unified Approach to Processing Queries That Contain Nested Subqueries, Aggregates and Quantifiers. In Proc. of VLDB, 1987.
[23] Yan W.P., Larson A.P. Performing Group By Before Join. IEEE ICDE, 1994.
[24] Yan, W.P., Larson A.P. Eager aggregation and lazy aggregation. In Proc. of VLDB Conference, Zurich, 1995.
[25] Witkowski A., et al. Spreadsheets in RDBMS for OLAP. Proc. of ACM SIGMOD, 2003.
[26] Witkowski A., et al. Spreadsheets in RDBMS for OLAP. ACM TODS, 2005.
Назад Содержание

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
