2010 г.
Преобразование запросов, основанное на стоимости
Рафи Ахмед, Эллисон Ли, Эндрю Витковски, Динеш Дас, Хонг Су, Мохамед Зэйд, Тьерри Крюейнс
Перевод Леонида Борчука
Под ред. Сергея Кузнецова
Оригинал: Cost-Based Query Transformation in Oracle / Rafi Ahmed, Allison Lee, Andrew Witkowski, Dinesh Das, Hong Su, Mohamed Zait, Thierry Cruanes // Proceedings of the 32nd international conference on Very large data base, 2006, pp. 1026 — 1036
Назад Содержание Вперёд
В преобразованиях, основанных на стоимости, логические преобразования и физическая оптимизация объединяются для генерации оптимального плана выполнения. Это поясняется на рис. 1.
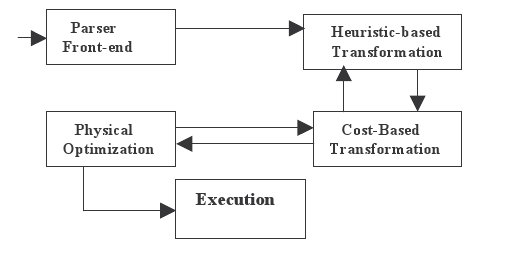
Рис. 1. Обработка запроса в Oracle
Можно считать, что логическое преобразование имеет два отдельных компонента: преобразования, основанные на эвристике и на стоимости. Инфраструктура (framework) преобразований, основанных на оценке стоимости, включает в себя следующее:
- алгоритмы преобразований, переводящие полное или частичное дерево запроса в семантически эквивалентную форму;
- пространство состояний различных преобразований;
- алгоритмы поиска в пространстве состояний;
- возможность глубокого копирования (deep copy) блоков запроса и их составных частей;
- техника оценки стоимости (физический оптимизатор);
- директивы преобразований и аннотации стоимости.
К разных элементам дерева запроса применяются разные преобразования. Например, к подзапросам и представлениям применяются устранение вложенности и слияние представлений соответственно, к узлам графа соединения применяется размещение группировки. К дорогостоящим предикатам применяется преобразование "вытягивание предиката".
Во время оптимизации дерево запроса обходится в восходящем стиле. Различные варианты использования одного или более преобразований элементов дерева запроса образуют различные состояния пространства состояний преобразования. Перед применением отдельного состояния и оценкой его стоимости путем вызова физического оптимизатора выполняется глубкое копирование (частичного) дерева запроса. Для применения каждого состояния обычно требуются различные копии (частичного) дерева запроса. Выбирается состояние преобразования, порождающее наиболее оптимальный план (т.е. наилучшее состояние), и директивы наилучшего состояния передаются исходному дереву запроса, которое преобразовывается в соответствии с этими директивами.
В Oracle преобразования обычно применяются последовательно, то есть каждое преобразование применяется ко всему дереву запроса, затем применяется другое преобразование, и так далее. Для некоторых преобразований соблюдается следующая последовательность их применения:
-
общая факторизация подвыражений (common sub-expression factorization),
-
слияние представлений "селекция-проекция-соединение" (SPJ view merging),
- устранение соединений (join elimination),
-
устранение вложенности подзапросов (subquery unnesting),
-
слияние представлений с группировкой (group-by (distinct) view merging),
-
упрощение группировки (group pruning),
-
перемещение предикатов (predicate move around),
-
преобразование операций над множествами в соединения (set operator into join),
-
размещение группировки (group-by placement),
-
вытягивание предиката (predicate pullup),
-
факторизация соединений (join factorization),
-
преобразование дизъюнкции в объединение (disjunction into union-all),
-
преобразование "звезда" (star transformation),
- и
проталкивание предикатов соединения (join predicate pushdown).
Однако имеются случаи, когда последовательность преобразований не соблюдается. Преобразования могут образовывать конструкции, которые могут повлечь за собой повторение других преобразований, например, преобразование операций над множествами в соединения может образовать SPJ-представление (селекция-проекция-соединение), и, следовательно, могут снова применяться слияние представлений SPJ и проталкивание предикатов фильтрации (filter predicate pushdown). Некоторые преобразования взаимодействуют друг с другом и должны рассматриваться вместе, чтобы можно было принять правильное решение, основанное на оценке стоимости; это обсуждается в подразделе 3.3.
Фундаментальный вопрос, связанный с преобразованиями, которые основаны на оценке стоимости, заключается в том, приведут ли эти преобразования к комбинаторно быстрому росту альтернатив, которые необходимо оценивать, и обеспечат ли они баланс между стоимостью оптимизации и стоимостью выполнения.
Источник многочисленных альтернатив — сами разнообразные преобразования, а также множество объектов (например, блоки запроса, таблицы, ребра соединений, предикаты и т.д.), к которым каждое преобразование может применяться. Если есть N объектов, к которым может применяться преобразование T, то применением T потенциально можно образовать 2N возможных альтернативных комбинаций. В общем случае, если есть M преобразований T1, T2, ..., TM, которые могут применяться к N объектам, то существует (1 + M)N возможных альтернативных комбинаций.
Например, для запроса Q1 нужно рассмотреть 4 альтернативы: без устранения вложенности, с устранением вложенности только первого подзапроса (QS1), с устранением вложенности только второго подзапроса (QS2) или с устранением вложенности обоих подзапросов. Мы обозначаем состояние как массив бит, где n-ый бит показывает, является ли n-ый объект (например, подзапрос) преобразованным (значение 1) или нет (значение 0). Например, состояние (0,1) говорит об устранении вложенности только второго подзапроса. Если есть M преобразований, применяемых к N объектам, состояние представляется матрицей из M×N бит.
Чтобы справиться с проблемой комбинаторно быстрого роста в случае перестановок соединения, было предложено использовать рандомизированные алгоритмы, такие как имитация отжига (Simulated Annealing), генетический поиск (Genetic Search), итерационное уточнение (Iterative Improvement), поиск с запретами (Tabu Search) [20], [21], [11]. Общая идея всех этих стратегий заключается в выполнении квазислучайных блужданий в пространстве поиска, начиная с исходного состояния и пытаясь достичь локального минимума низкой стоимости. Конечно, эти стратегии не гарантируют, что может быть достигнут глобальный минимум — наилучшее преобразование, так как во время блужданий посещается только малая часть пространства состояний. Тем не менее, они имеют практическую значимость, так как качество решения обычно улучшается с длительностью поиска.
Сложность преобразований, основанных на оценке стоимости, определяется количеством альтернативных комбинаций или пространством состояний, которое экспоненциально растет с количеством преобразуемых объектов. Если количество преобразуемых объектов мало, может стать осуществимой техника полного перебора преобразований с исчерпывающим поиском в пространстве состояний. Для ограничения потенциального роста времени оптимизации мы используем несколько различных методов перебора пространства состояний.
-
Исчерпывающий поиск (Exhaustive Search). При исчерпывающем поиске рассматриваются все возможные 2N состояний пространства состояний N объектов. Например, в запросе Q1 мы рассматриваем 4 состояния: (0,0), (0,1), (1,0) и (1,1). Этот поиск гарантирует нахождение наилучшего решения.
-
Итерационное уточнение (Iterative Improvement). Метод итерационного уточнения используется для сокращения пространства поиска. Главная идея этого метода состоит в том, что мы начинаем с некоторого исходного состояния и продвигаемся к следующему соседнему состоянию, используя некоторый метод, направленный на поиск локального минимума за счет постоянного выбора нисходящего направления движения; мы повторяем этот поиск локального минимума, начиная с другого исходного состояния в следующей итерации. Алгоритм останавливается, если новые состояния более не находятся, или было достигнуто некоторое условие завершения (например, максимальное количество состояний). Количество состояний, перебираемых этой техникой, лежит в пределах от N до 2N.
-
Линейный поиск (Linear Search). Основная идея этого метода поиска основана на подходе динамического программирования, в котором предполагается, что для запроса, состоящего из нескольких объектов, достаточно проанализировать на предмет преобразования только некоторый поднабор этих объектов, а затем расширить это дополнительными преобразованиями других объектов. Другими словами, если стоимость (1,0) меньше, чем стоимость (0,0), и стоимость (1,1) меньше, чем стоимость (1,0), то можно надежно предположить, что стоимость (1,1) — самая низкая для всевозможных преобразований, и, следовательно, нет необходимости оценивать стоимость (0,1). Как можно видеть, это может существенно сократить пространство поиска. Этот метод анализирует N + 1 состояний. Линейный поиск работает лучше всего, если преобразования различных элементов независимы одно от другого.
-
Двухпроходной поиск (Two-pass Search). Двухпроходный поиск — самый дешевый метод поиска, в котором анализируется 2 состояния. Сравниваем стоимость плана выполнения полностью непреобразованного запроса (т.е. состояние (0,0,...)) со стоимостью плана запроса, в котором преобразованы все объекты (т.е. состояние (1,1,...)).
Инфраструктура преобразований, основанных на оценке стоимости, автоматически решает, какой метод поиска следует использовать, основываясь на количестве объектов, которые преобразуются в блоке запроса, характеристиках преобразований и общей сложности запроса. Например, если в блоке запроса содержится небольшое число подзапросов, мы используем для устранения вложенности подзапросов исчерпывающий поиск, а если число подзапросов превышает некоторое фиксированное пороговое значение, мы используем линейный поиск. Если общее число элементов в запросе, подлежащих преобразованию (например, представлений с group-by, подзапросов, вложенность которых можно устранить) превышает некоторое пороговое значение, то мы используем для всех преобразований запроса двухпроходный поиск.
Если для одного объекта применяются два (или более) преобразования, основанные на стоимости, таких что одно преобразование применимо только после применения другого, то, чтобы оптимизатор выявил оптимальный план, эти преобразования должны чередоваться.
Например, в некоторых случаях должны чередоваться устранение вложенности подзапросов и слияние представлений, так как устранение могло бы повысить оценочную стоимость запроса; однако преобразование "слияние представлений", применяемое к представлению, образованному в процессе устранения вложенности, может привести к оптимальному плану Это означает, что для этого запроса следует выполнять устранение вложенности, а образованное таким образом представление должно сливаться. В запросе Q10 агрегатный подзапрос преобразуется устранением вложенности в представление с группировкой. Это преобразование может приводить к менее оптимальному плану (то есть, Q1 может быть дешевле, чем Q10). Однако когда в Q10 выполняется слияние представлений, это приводит к Q11, план выполнения которого может быть менее дорогим, чем планы запросов Q1 и Q10. При отсутствии чередования преобразований слияния представлений и устранения вложенности к Q1 не будет применено преобразование устранения вложенности, и будет выбран неоптимальный план.
Если два или более преобразования, основанные на стоимости, применяются к одному объекту таким образом, что это препятствуют их последовательному применению, они должны использоваться поодиночке, чтобы оптимизатор мог выявить наиболее оптимальный план. Это сравнение двух или более преобразований, основанных на стоимости, называется противопоставлением (juxtaposition).
Если к некоторому представлению могут применяться преобразования "слияние представлений" и "проталкивание предикатов соединения", то они должны противопоставляться друг другу, а оптимизатор должен выбирать один из трех вариантов. Рассмотрим пример проталкивания предикатов соединения, приведенный в Q13. Представление с distinct из Q12 может сливаться, что приведет к образованию следующего запроса:
Q18
SELECT DV.employee_name, DV.job_title,
DV.mgr_name
FROM
(SELECT DISTINCT e1.emp_id, e2.emp_id,
j.rowid,
e1.employee_name, j.job_title,
e2.employee_name as mgr_name
FROM employees e1, job_history j,
employees e2, departaments d,
locations l
WHERE d.loc_id = l.loc_id and
l.country_id in ('UK','US') and
e1.dept_id = d.dept_id and
e1.emp_id = j.emp_id and
j.start_date > '19980101' and
e1.mgr_id = e2.emp_id) DV;
Заметим, что в этом слиянии представления операция DISTINCT вытянута, и ключи внешних таблиц добавлены к новому представлению, которое содержит все таблицы исходного запроса Q12.
Будут оценены стоимости запросов Q12, Q13 и Q18, и наименьшая оценка определит, будет (если да, то какое из трех) или нет применяться преобразование к исходному запросу.
Чередование и противопоставление преобразований вызывают увеличение числа анализируемых состояний. В принципе, мы могли бы принимать во внимание дополнительное состояние для каждого подзапроса, который мы рассматриваем на предмет устранения вложенности. В некоторых случаях состояния, которые мы могли бы учесть, являются состояниями, которые мы могли бы обследовать позже даже без чередования или противопоставления. Если мы выбираем устранение вложенности подзапроса, поскольку оно приводит к более дешевому плану запроса, то нет необходимости чередовать его со слиянием представлений; мы проанализируем слияние представлений обычным последовательным способом. Подобным же образом, если мы выбираем не применять слияние представлений, поскольку оно приводит к более дорогому плану запроса, то нет необходимости противопоставлять его проталкиванию предикатов соединения; мы проанализируем проталкивание предикатов соединения позже обычным последовательным способом. Это частично смягчает последствия расширения пространства поиска по причине чередования и противопоставления.
Описанная техника преобразований, основанная на оценке стоимости, может быть дорогостоящей с точки зрения как времени оптимизации, так и потребления памяти оптимизатором. Копирование структур запроса приводит к постоянному потреблению памяти, а для оптимизации каждого преобразуемого запроса требуется время. Мы обсудим несколько методов снижения влияния преобразований, основанных на оценку стоимости, на производительность оптимизации.
При оценке любого состояния, если стоимость дерева запроса или любой его составной части превосходит стоимость наилучшего состояния, найденного к этому времени, физическая оптимизация этого состояния прекращается, и оптимизатор переходит к анализу следующего состояния.
Полная повторная оптимизация каждого преобразованного запроса является дорогостоящей и во многих случаях излишней. Каждое преобразование влияет на несколько известных блоков запроса, и только эти блоки запроса и блок запроса, содержащий их в дереве запроса, требуется повторно оптимизировать. Другими словами, мы можем повторно использовать результаты (которые мы называем аннотациями стоимости) оптимизации двух эквивалентных поддеревьев запроса. Для сложных запросов, содержащих несколько подзапросов или представлений, это может сэкономить значительную часть времени.
Рассмотрим запрос Q1. Используя стратегию исчерпывающего поиска в пространстве состояний, мы оптимизировали бы четыре варианта запроса. Каждый вариант содержит три блока запроса (два внутренних блока запроса и внешний блок запроса QO), так что в целом мы оптимизировали бы двенадцать блоков запроса. Этот процесс сведен в табл. 1. T(Q) обозначает преобразованную версию блока запроса Q.
Таблица 1. Повторное использование и пространство состояний
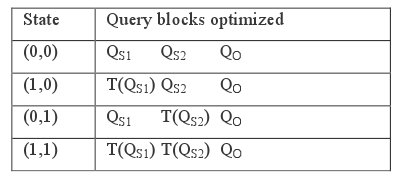
Заметим, что каждый из блоков запроса QS1, QS2, T(QS1) и T(QS2) оптимизируется дважды. Вместо повторной оптимизации каждого из них мы можем повторно использовать информацию о стоимости. Следовательно, мы можем избежать оптимизации четырех из двенадцати блоков запроса. Подзапросы и соответствующие встроенные представления сами могли бы содержать представления и вложенные подзапросы, что привело бы к еще более существенной экономии.
В Oracle структуры запроса и структуры оптимизатора, испольуемые для оценки стоимости и принятия решений, обычно не освобождаются до конца оптимизации. Для выполнения преобразований, основанных на оценке стоимости, создается много копий структур запроса, и для оптимизации вариантов преобразования запроса создается много структур оптимизатора. Следовательно, в инфраструктуре преобразований, основанных на стоимости, мы должны управлять памятью более разумно. Структуры запроса и структуры, используемые оптимизатором для принятия решений, освобождаются, когда принимается решение о выполнении каждого преобразования. Отметим, что память, занимаемая аннотациями стоимости оптимизатора, освобождаться не может, поскольку, как описывалось ранее, они использоваться повторно.
Некоторые расчеты оптимизатора являются очень дорогостоящими, и они могут быть повторно использоваться, даже если блок запроса изменяется некоторым преобразованием. Например, в Oracle для оценки мощности некоторых таблиц (в частности, для таблиц, для которых не была собрана статистика оптимизатора, и таблиц с несколькимим, возможно, коррелирующими, предикатами фильтрации) производится динамический отбор образцов (dynamic sampling). Соответствующие вычисления являются дорогостоящими, и если однотабличные предикаты не изменяются при преобразовании, результат может быть использован повторно. Результаты этого вычисления и других дорогостоящих вычислений оптимизатора сохраняются в кэше на протяжении нескольких вызовов оптимизатора.
Назад Содержание Вперёд



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС