Обработка запросов в NonStop SQL
Альберт Чен, Юнг-Фенг Као, Майк Понг, Диана Шак, Сунил Шарма, Джей Вайшнав, Хансйорг Зеллер
Перевод: Сергей Кузнецов
Оригинал: Albert Chen, Yung-Feng Kao, Mike Pong, Diana Shak, Sunil Sharma, Jay Vaishnav, Hansjorg Zeller. Query Processing in NonStop SQL. IEEE Bulletin of the Technical Committee on Data Engineering, Vol. 16, # 4, December 1993. Текст доступен здесь.
3. Возможности обработки запросов
В этом разделе описываются некоторые возможности, позволяющие NonStop SQL очень быстро обрабатывать большие объемы данных и сложные запросы.
3.1 Операции, ориентированные на множества, в дисковом процессе
Дисковый процесс обеспечивает однотабличный, ориентированный на множества доступ к таблицам [Borr88]. Множество определяется путем задания выражения ограничения и списка атрибутов для проецирования. В запросе (сообщении) от файловой системы данные, подлежащие выборке, описываются в терминах множества (т.е. начальный и конечный ключи, выражение ограничения и атрибуты для проецирования). В ответ дисковый процесс может выдать один или более буферов с данными, соответствующими спецификации множества.
Ориентированные на множества обновления оптимизируются путем посылки в дисковый процесс выражения обновления (в добавок к начальному и конечному ключам и предикатам, определяющим множество). Последовательные вставки оптимизируются путем буферизации вставок в буфере файловой системы. Ориентированные на множества удаления оптимизируются путем посылки дисковому процессу в одном сообщении начального и конечного ключей и предикатов (определяющих множество, подлежащее удалению). Если данные в некоторых столбцах таблицы уже упорядочены в соответствии с разделом GROUP BY, то группировка и агрегация поручаются дисковому процессу.
В дисковом процессе также поддерживается упреждающее чтение нескольких блоков и отложенная запись обновленных блоков. Эти средства сокращают число сообщений между приложением (файловой системой) и дисковым процессом.
3.2 Горизонтальное разделение
Таблица или индекс могут быть горизонтально разделены путем указания диапазонов ключа каждого раздела. Разделенная таблица выглядит как одна таблица, файловая система перенаправляет любые SQL-запросы SELECT, INSERT, DELETE и UPDATE в нужный раздел в зависимости от диапазона ключа, указанного в операторе.
Пользователи могут обязать систему открывать разделы, только если они реально требуются. Это средство повышает эффективность запросов путем сокращения числа открытых файлов: открываются только те файлы, которые действительно нужны. Это является основой паралельной обработки запросов.
3.3 Комбинирование и устранение сортировок
Сортировка может выполняться либо для устранения дублирующих значений, либо для упорядочивания данных. Оптимизатор рассматривает SELECT DISTINCT, агрегатную функцию, содержащую DISTINCT, раздел GROUP BY и раздел ORDER BY как запросы сортировки данных. Поскольку сортировка является одной из наиболее трудоемких операций при выполнении запроса, оптимизатор комбинирует сортировки при возникновении следующих условий:
- список выборки оператора
SELECT DISTINCTявляется подмножеством списка столбцов упорядочивания разделаORDER BYили списка столбцов группировки разделаGROUP BY; - столбцы группировки раздела
GROUP BYобразуют подмножество столбцов упорядочивания разделаORDER BY; столбцы группировки образуют префикс столбцов упорядочивания; - столбцы упорядочивания раздела
ORDER BYобразуют подмножество списка выборки оператораSELECT DISTINCTили столбцов группировки разделаGROUP BY.
Кроме того, оптимизатор устраняет сортировку, когда можно использовать индекс, в следующих случаях:
- Индекс обеспечивает порядок данных, требуемый разделами
GROUP BYилиORDER BY. - Столбцы группировки или весь список выборки
SELECT DISTINCTобразуют префикс ключа уникального индекса.
3.4 Соединения на основе хэширования
Во множестве прототипных реализаций и академических статей было показано, что алгоритмы соединений на основе хэширования [DeWi85, Schn89] являются предпочтительными при наличии достаточного объема основной памяти и отсутствии индекса, органичивающего число проб на внутренней таблице. Обычно достаточным размером памяти считается квадрат размера внутренней таблицы (в блоках).
Для использование премуществ большого объема основной памяти, распространенной в современных системах, в NonStop SQL поддерживаются алгоритмы соединения на основе хэширования вдобавок к традиционным алгоритмам вложенных циклов и сортировки со слиянием. Используемый в NonStop SQL адаптивный алгоритм соединения на основе хэширования (Adaptive Hash Join algorithm) [Zell90b] является разовидностью хорошо известного гибридного алгоритма соединения с использованием хэширования (Hybrid Hash Join), разработанного в проекте параллельной машины баз данных GAMMA в University of Wisconsin [DeWi85].
Гибридный алгоритм соединения с использованием хэширования в NonStop SQL усовершенствован: он стал более устойчивым к ошибкам оценки размера внутреннего отношения и объему доступной памяти. Это позволяет оптимизатору выбирать соединение хэшированием даже в тех случаях, когда реальные значения этих параметров заранее неизвестны. При выборе алгоритма соединения оптимизатор принимает во внимание, среди прочих, следующий факторы:
- оценку размера входных отношений и
- оценку объема памяти, доступной для соединения.
Эти оценки используются для определения стоимости различных алгоритмов соединения. Выбирается алоритм с наименьшей стоимостью. Соединения методами вложенных циклов и сортировки со слиянием не испытывают деградации эффективности, если реальные значения размеров входных отношений и размера памяти отличаются от оценок оптимизатора. Это связано с тем, что их планы выполнения не зависят от размера таблиц и доступной памяти. Однако для выполнения соединения хэшированием некоторые параметры, такие как число хэш-классов и объем информации, поддерживаемой в основной памяти, являются предопределенными. Изменение условий среды может вызвать деградацию производительности или даже отказ выполнения соединения. В адаптивном алгоритме соединения с хэшированием используется несколько методов, делающих его более надежным и производительным в большом диапазоне размеров основной памяти:
- обмены с дисками порциями переменного размера;
- динамический своппинг частей хэш-таблицы в дисковые файлы;
- алгоритм «hash loop» для случаев предельного переполнения.
Следовательно, адаптивный алгоритм соединения хэшированием может настаиваться на различное потребление памяти в разных точках своего выполнения. Подробности описывются в [Zell90b].
3.5 Параллельное выполнение
Параллельное выполнение в NonStop SQL является прозрачным для приложения. Это означает, что для параллельного выполнения запроса его не требуется формулировать специальным образом. Оптимизатор рассматривает и последовательные, и параллельные планы как обычную часть генерации планов выполнения, оценивает стоимость каждого из них и выбирает план с наменьшей стоимостью. План, выбранный в конце концов для выполнения, является наилучшим среди рассмотренных планов. Оценка стоимости позволяет оптимизатору методично выбирать конкретный тип плана параллельного выполнения, обеспечивающий наилучшую эффективность для данного запроса.
Для внесения параллелизма в реляционные операции в систему внедрен компонент, называемый серверным процессом-исполнителем (Executor Server Process, ESP). Таким образом, между приложением (master executor) и процессами ESP имеется отношение «главный-подчиненный» («master-slave»). Каждый ESP состоит из небольшой основной программы и файловой системы. Исполнитель приложения взаимодействует с серверными исполнителями через сообщения. На рис. 2 показано, что для выполнения запросов главный исполнитель, в дополнение к использованию связанной с ним файловой системы, использует серверные исполнители.
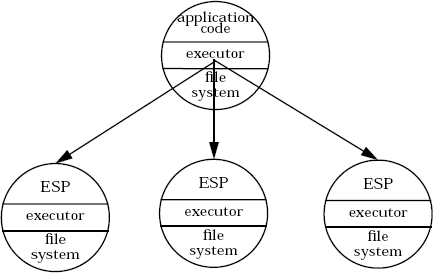
Рис.2. Процессы серверного исполнителя
В этой архитектуре допускается широкое разнообразие параллельных планов выполнения, в которых для запросов над одной таблицей параллелизм может обеспечиваться файловой системой, а для всех типов реляционных операций – исполнителем. Файловая система всегда производит доступ к разделенным таблицам последовательно. ESP используются для параллельного выполнения операторов SQL SELECT, INSERT, DELETE и UPDATE над разделенными файлами. Однако, если у таблицы имеются индексы, размещенные на разных дисках, то обновление записи базовой таблицы и соответствующих индексных данных производится параллельно файловой системой. Поскольку стоимость запуска ESP может быть значительной, эти процессы разделяются между операторами SQL и остаются существовать вне границ транзакций.
3.5.1 Параллелизм без повторного разделения
Параллельное выполнение плана запроса является естественным способом оперирования на горизонтально разделенной таблицей NonStop SQL. Индекс может быть горизонтально разделен, чтобы избегать узкого места при обработке разделов GROUP BY и ORDER BY. Для операторов SQL SELECT, INSERT, DELETE и UPDATE могут параллельно обрабатываться два или более разделов. Число ESP, используемых для запросов над единственной таблицей, всегда равно числу разделов таблицы. Для агрератных запросов каждый ESP вычисляет локальный агрегат и возвращает его значение главному-исполнителю. Именно он вычисляет результат запроса на финальном шаге.
3.5.2 Динамическое повторное разделение
В NonStop SQL имеется возможность параллельного выполнения эквисоединений и других операций, требующих переработки большого количества данных, таких как удаление дубликатов или группировка, даже если таблицы не являются разделенными. Это делается путем чтения неразделенной таблицы и использования основанного на хэшировании механизма разделения для построения временной разделенной таблицы.
3.5.3 Параллельные планы выполнения соединений
В NonStop SQL предлагаются три параллельных плана для выполнения соединений. В планах могут использоваться один или более методов вложенных циклов, хэширования и сортировки со слиянием. На рис. 3 иллюстрируются эти планы. Они описываются следующим образом.
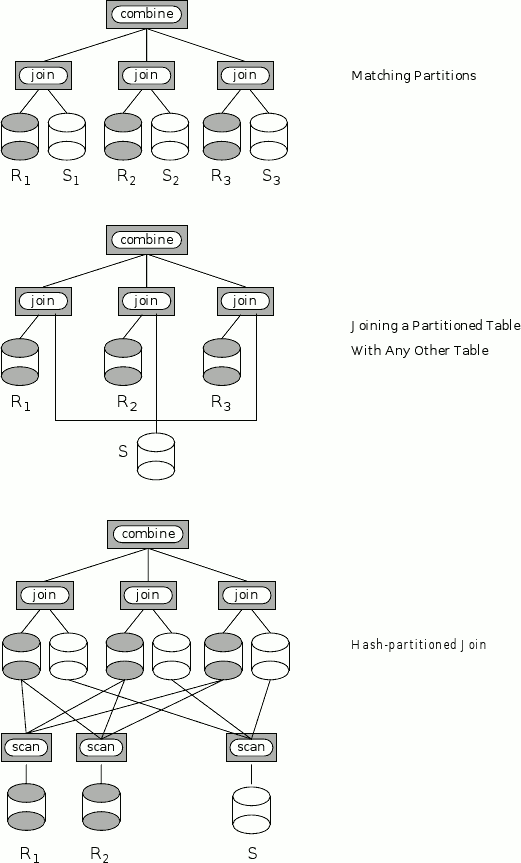
Рис. 3: Параллельные планы выполнения соединений
Соединение таблиц с соответствующими разделами: Если две таблицы являются разделенными таким образом, что может быть произведено соединение пар отдельных разделов, оптимизатор оценивает эффективность параллельного соединения каждой такой пары. Например, рассмотрим банковское приложение, в котором используются следующие таблицы:
Account(Branch, AccountNo, Owner, CreditLimit)
и
Deposits(Branch, AccountNo, Date, Amount)
Обе таблицы являются разделенными по диапазонам ключа-атрибута Branch. Следовательно, соединение по предикату Account.Branch = Deposits.Branch AND Account.AccountNo = Deposits.AccountNo обнаружит все соединяемые строки в соответствующих разделах. Поэтому оказывается возможно соединять каждую пару соответствующих кортежей независимо и в параллель. Оптимизатор распознает этот особый, но, тем не менее, распространенный случай и генерирует соответствующий план выполнения. Разработка базы данных таким образом, чтобы были возможны соединения соответствующих разделов, является распространенным и простым средством достижения параллелизма.
Соединение разделенной таблицы с какой-либо другой таблицей: Для этого плана параллелизм достигается за счет чтения каждого раздела разделенной таблицы R в параллель. Каждый раздел R параллельно с другими разделами последовательно соединяется со всей таблицей S. В этом плане используются либо вложенные циклы, либо сортировка хэшированием. Соединение вложенными циклами выбирается, только если для таблицы S существует индексный путь доступа. Чтобы для достигался высокий уровень параллелизма, требуется чтобы либо таблица S была разделенной и имелся индекс на столбце соединения, либо таблица S была очень небольшой по сравнению со соимостью чтения таблицы R.
Если в этом плане выполняется соединение хэшированием, то вся таблица S (после применения локального предиката выборки) посылается каждому ESP, который обрабатывает раздел внешней таблицы R (фрагментировать и реплицировать). Затем каждый ESP строит из S хэш-таблицу и выполняет соединение хэшированием. Соединения хэшированием работают для этого плана очень хорошо в тех случаях, когда таблица S относительно невелика. В отличие от планов этого типа с соединением вложенными циклами, план с соединением хэшированием позволяет избежать конкуренции по внутренней таблице и достичь высокого уровня параллелизма.
Соединение с хэш-разделением: В отличие от двух описанных ранее планов параллельного выполнения соединения, план соединения с хэш-разделением не ограничивается конкретной схемой разделения базовых таблиц. Однако он применим только для эквисоединений. На рис. 3 показаны две базовых таблицы с одним и двумя разделами соответственно соединяются тремя параллельными процессами соединения. Вообще говоря, может использоваться произвольное число процессов соединения. В текущей версии NonStop SQL число процессов соединения равно числу ЦП в системе.
Этот план работает в две фазы. На первой фазе каждая из двух таблиц, подлежащих соединению, подвергается повторному разделению, как описано в разд. 3.5.2. Повторное разделение реализуется путем применения той же хэш-функции к значениям, соедержащимся в столбцах соединения каждой из таблиц. Это обеспечивает то, что строки из внутренней и внешней таблиц, соответствующие предикату соединения, будут сохранены в соответствующих разделах. Вторая фаза соединения с хэш-разделением идентична параллельному соединению с заранее соответствующими разделами. Выполняется попарное соединение разделов, построенных на первой фазе. Заметим, что алгоритм соединения с хэш-разделением гарантирует, что соответствующие строки хранятся в соответствующих разделах.
4. Группировка и агрегация
Поскольку группировка и агрегация очень распространены в запросах поддержки принятия решений, в NonStop SQL используется несколько методов, позволяющих эффективно выполнять группировку и агрегацию.
Если операнд агреатных функций MIN или MAX является столбцом, входящим в ключ индекса, и запрос содержит предикаты сравнения по равенству на других столбцах ключа, предшествующих данному, то NonStop SQL вычисляет агрегат, позиционируясь на первую или последнюю запись заданного диапазона ключа для индекса. Соответствующие строки всегда содержит минимальное и максимальное значение соответственно для этого столбца индекса. Исполнитель просто читает первую строку, возвращаемую файловой системой, и возвращает приложению MIN или MAX.
Как описывалось в разд. 3, NonStop SQL также выполняет группировку и агрегацию в параллель. Этим методом для заданного запроса могут быть вычислены любые агрегатные функции SQL. Оптимизатор автоматически выбирается эту стратегию для запросов с единственной переменной, а также в тех случаях, когда агрегатная функция ссылается на наиболее внутреннюю таблицу последовательности соединений. Эта оптимизация сокращает число сообщений, которыми обменивается файловая система SQL с дисковым процессом, а также снижает сетевой трафик. Она также используется для группировки, если строки читаемые с диска, находятся в порядке группировки, т.е. если столбцы группировки образуют префикс ключа индекса.
В третьем выпуске системы в исполнителе поддерживаются новые алгоритмы выполнения группировки и агрегации с использованием хэширования, а не сортировки. Это метод эффективнее сортировки и менее трудоемкий. Если сгруппированные данные помещаются в основную память, то группировка выполняется за один проход над необработанными данными. Если сгруппированные данные не помещаются в основной памяти, то необработанные данные переписываются на диск с использованием крупных пересылок, соответствующих хэш-значению столбцов группировки. Впоследствии секции необработанных данных последовательно считываются в соответствии с их последовательными хэш-значениями. Группировка и агрегация выполняются после повторного считывания необработанных данных.
Этот метод гарантирует, что необработанные данные считываются не более двух раз. Метод используется как в последовательных, так и в параллельных планах выполнения. Когда этот метод используется в ESP, каждый подчиненный ESP хэширует и группирует данные, принадлежащие к локальному разделу. После удаления дубликатов результирующие группы и частичные агрегаты посылаются master-исполнителю, который производит окончательный результат. Метод сокращает сетевой трафик за счет локального выполнения сортировки и агрегации и сокращает межсетевую передачу данных.
5. Влияние пользователей
Оптимизатор разрабатывался в расчете на оптимизацию общего времени ответа на заданный SQL-запрос. Для приложений поддержки принятия решения часто требуется быстро получить несколько строк, например, отобразить первые 10 строк на экране. Таких пользователей не беспокоит общее время возврата всего результата запроса. Поэтому в NonStop SQL обеспечивается директива для воздействия на оптимизатор, чтобы он выбирал план, который направлен на быстрый возврат первых нескольких строк, что обычно делается путем чтения через индекс. В этом случае оптимизатор по мере возможности избегает операций сортировки.
Для искушенных пользователей в NonStop SQL обеспечивается механизм, принуждающий использовать в плане выполнения конкретный индекс, предписанную пользователем последовательность соединений и даже указанный метод соединения. Этот механизм позволяет пользователю навязывать некоторый план выполнения в тех случаях, когда оптимизатор не может сгенерировать план, желаемый пользователем.
6. Производительность
В массивно-параллельной среде для СУБД очень важно демонстрировать линейную масштабируемость в терминах увеличения быстродействия и увеличения масштаба. Ускорение быстродействия – это мера того, насколько быстро параллельная вычислительная систем решает проблему фиксированного размера. Другими словами, при использовании NonStop SQL пользователи могут повышать скорость выполнения запроса почти линейно путем добавления к своей системе процесоров и дисковых устройств. Увеличение масштаба – это мера того, насколько хорошо параллельная вычислительная система справляется с ростом базы данных. Другими словами, когда возрастает размер пакетного задания, пользователи могут удерживать константное время обработки путем добавления к системе большего оборудования. NonStop SQL демонстрировал близкие к линейным ускорение производительности и увеличение масштабности для приложений тестового набора с аудитом Codd and Date Consulting Group. Этот тестовый набор документирован в [Engl89, Engl 90].
Мы приведем несколько результатов некоторых тестов производительности, которые прогонялись при тестировании нашего программного обеспечения. Заметим, что эти результаты не были официально подтверждены независимым аудитором. Они представлены здесь просто для того, чтобы подчеркнуть выгоду от поддержки более эффективных алгоритмов при обычной обработке запросов.
Улучшение производительности в диапазоне от 12 до 60 процентов наблюдалась при использовании для запросов из Wisconsin benchmark метода соединения хэшированием вместо вложенных циклов и сортировки со слиянием. При выполнении группировки и агрегации с использованием метода на основе хэширования вместо метода на основе сортировки для запросов из того же тестового набора наблюдалось повышение производительности до 60%. Когда агрегация выполнялась дисковым процессом, применявшим агрегатную функцию к лидирующим столбцами ключа таблицы из 1000 строк, реализованной в ключовом-последовательном файле, рост производительности составил 75%. Когда та же таблица соедаржала 100000 строк, на том же запросе был показан рост производительности в 230%. В обоих случаях размер строк составлял 208 байт.
7. Заключение и перспективы
NonStop SQL – это надежная распределенная СУБД, достигающая высокой эффективности за счет низкоуровневой интеграции реляционных функций и использования параллелизма, свойственного архитектуре Tandem. Система включает стоимостной оптимизатор, оптимизирующий как последовательные, так и параллельные планы выполнения запросов как для простых, так и для сложных запросов. Возможности обработки запросов – параллельные планы выполнения, соединения на основе хэширования, основанные на хэшировании группировка и агрегация – позволяют очень эффективно обрабатывать большой объем данных.
Имеется пробуждающийся интерес к использованию массивно-параллельной обработки на очень больших базах данных для коммерческих приложений. Архитектура обработки запросов NonStop SQL и демонстрируемая системой линейная масштабируемость делают ее идеально подходящей для таких приложений. В добавление к этому, в продукт встроен набор высокопроизводительных утилит для управления крупных локальных и распределенных баз данных. В них тоже поддерживаются возможности параллельной обработки. Высокая степень управляемости, предлагаемой в продукте NonStop SQL, является важной причиной его коммереского успеха наряду с его возможностями обработки запросов. К тому же, архитектура обработки запросов NonStop SQL такова, что NonStop SQL может легко использоваться в качестве сервера данных для большого числа клиентских приложений, выполняемых на рабочих станциях. Мы полагаем, что NonStop SQL является отличным решением для нового класса клиент-серверных приложений, а также для тех приложений, которые будут разработаны для коммерческого использования массивно-параллельной обработки.
Литература
[Borr88] A. Borr, F. Putzolu, High Performance SQL Through Low-level System Integration, Proc. ACM SIGMOD 1988, pp. 342-349.
[DeWi85] D. DeWitt, R. Gerber, Multiprocessor Hash-based Join Algorithms, Proc. 1985 VLDB, pp. 151-164.
[Engl89] S. Englert, J. Gray, T. Kocher, P. Shah, A Benchmark of NonStop SQL Release 2 Demonstrating Nearlinear Speedup and Scaleup on Large Databases, Tandem Computers, Technical Report 89.4, May 1989, Part No. 27469.
[Engl90] S. Englert, J. Gray, T. Kocher, P. Shah, NonStop SQL Release 2 Benchmark, Tandem Systems Review 6, 2 (1990), pp. 24-35, Tandem Computers, Part No. 46987.
[Engl91] S. Englert, Load Balancing Batch and Interactive Queries in a Highly Parallel Environment, Proc. IEEE Spring COMPCON 1991, pp. 110-112.
[Lesl91] Harry Leslie, Optimizing Parallel Query Plans and Execution, Proc. IEEE Spring COMPCON 1991, pp. 105-109.
[Moor90] M. Moore, A. Sodhi, Parallelism in NonStop SQL, Tandem Systems Review 6, 2 (1990), pp. 36-51, Tandem Computers, Part No 46987.
[Pong88] Mike Pong, NonStop SQL Optimizer: Query Optimization and User Influence, Tandem Systems Review 4,2 (1988), pp. 22-38, Tandem Computers, Part No. 13693.
[Schn89] D. Schneider, D. DeWitt, A Performance Evaluation of Four Parallel Join Algorithms in a Sharednothing Multiprocessor Environment, Proc. ACM SIGMOD 1989, pp. 110-121.
[Seli79] P. Selinger et. al., Access Path Selection in a Relational Database Management System, Proc. ACM SIGMOD Conference 1979, pp. 23-34. Есть перевод на русский язык: П. Селинджер, М. Астрахан, Д. Чемберлин, Р. Лури, Т. Прайс. Выбор пути доступа в реляционной системе управления базами данных.
[Tand87] The Tandem Database Group, NonStop SQL:A Distributed, High-performance, High-availability Implementation of SQL, Proc. 2nd Int. Workshop on High Performance Transaction Systems, Springer Lecture Notes in Computer Science No. 359.
[Tand88] The Tandem Performance Group, A Benchmark of NonStop SQL on the Debit Credit Transaction, Proc. ACM SIGMOD 1988, pp. 337-341.
[Tand89] The Tandem Database Group, NonStop SQL:A Distributed, High-performance, High-availability Relational DBMS, Proc. First Annual Distributed Database Event, The Relational Institute, 2099 Gateway Place #220, San Jose, CA 95110.
[Zell90a] H. Zeller, Parallel Query Execution in NonStop SQL, Proc. IEEE Spring COMPCON 1990, pp. 484-487.
[Zell90b] H. Zeller, J. Gray, An Adaptive Hash Join Algorithm for Multiuser Environments, Proc. 16. VLDB, 1990, pp. 186-197.