Обработка запросов в NonStop SQL
Альберт Чен, Юнг-Фенг Као, Майк Понг, Диана Шак, Сунил Шарма, Джей Вайшнав, Хансйорг Зеллер
Перевод: Сергей Кузнецов
Оригинал: Albert Chen, Yung-Feng Kao, Mike Pong, Diana Shak, Sunil Sharma, Jay Vaishnav, Hansjorg Zeller. Query Processing in NonStop SQL. IEEE Bulletin of the Technical Committee on Data Engineering, Vol. 16, # 4, December 1993. Текст доступен здесь.
Содержание
- 1. Введение
- 2. Query Optimization
- 3. Возможности обработки запросов
- 4. Группировка и агрегация
- 5. Влияние пользователей
- 6. Производительность
- 7. Заключение и перспективы
- Литература
- 5. Влияние пользователей
1. Введение
NonStop SQL – это отказоустойчивая, распределенная реализация языка запросов SQL для вычислительных систем Tandem NonStop [Tand87, Tand89].
Вычислительные системы Tandem NonStop являеются слабосвязанными (т.е. без общей памяти, non-shared-memory) мультипроцессорными системами. Система состоит из кластеров процессоров, и каждый кластер содержит до 224 процессоров. Система может инкрементно наращиваться по мере роста вычислительных требований. Процессоры взаимосвязаны через дуплексную оптоволоконную шину. Большинство устройств ввода-вывода, включая диски, являются дуплексными и могут подсоединяться к двум процессорам, чтобы обеспечить резервный путь доступа к устройству. Большая часть критичных системных процессов поддерживается в виде пар процессов, в которых один процесс действует как основной, а второй – как горячий резерв (hot standby). Таким образом, система может сохранить работоспособность при любом одиночном отказе без потери доступа к какому-либо программному или аппаратному ресурсу.
Операционная система Tandem NonStop Kernel основана на передаче сообщений. Доступ к устройствам ввода-вывода, включая диски, достигается путем посылки сообщений серверным процессам, управляющим конкретным устройством. Любой процесс в системе может получить доступ к любому устройству ввода-вывода в системе, послав сообщение соответствующему серверному процессу.
Приложения обычно разрабатываются с использованием модели «клиент-сервер». Обеспечивается монитор транзакций (PATHWAY) для управления серверами и коммуникациями между клиентами и серверами. Серверы приложений могут быть написаны на разнообразных языках (C, COBOL, Pascal, TAL) с использованием встроенного SQL для доступа к данным.
NonStop SQL строится над основанной на сообщениях, отказоустойчивой архитектурой вычислительных систем Tandem. В системе обеспечивается глобальное пространство имен, и программа может получить доступ к любой таблице во всей системе (при наличии требуемых прав доступа). Транзакции могут быть распределенными и могут иметь доступ к любой таблице во всей системе. Для координации фиксации транзакций используется двухфазный протокол фиксации. В NonStop SQL используется принцип автономности узлов: при выполнении запроса к горизонтально разделенной таблице допускается недоступность некоторых разделов, если данные из этих разделов не требуются. Автономность узлов обеспечивает то, что у пользователя всегда имеется доступ к локальным данным, независимо от того, доступны или нет удаленные разделы таблицы. Полная поддержка версионности позволяет сосуществовать в распределенной системе различным версиям программ, таблиц, каталогов и системного программного обеспечения.
1.1 Компоненты обработки запросов NonStop SQL
Система обработки запросов в NonStop SQL состоит из компилятора SQL, исполнителя SQL, файловой системы SQL, дисковых процессов и словаря SQL. Компилятор SQL компилирует статические и динамические операторы SQL. Он обращается к словарю SQL для выполнения связывания имен и выборки статистической информации о содержимом таблиц для сборки плана выполнения (называемого также планом доступа) для каждого оператора. В отличие от других реализаций РСУБД, планы выполнения для статических операторов SQL сохраняются в тех же файлах, что и объектный код, производимый компиляторами основных языков (3GL).
Исполнитель представляет собой набор системных библиотечных процедур, вызываемых приложением для выполнения оператора SQL. Для статического SQL исполнитель выбирает план выполнения из объектного файла, который содержит не только машинный код, произведенный компилятором основного языка, но также и план выполнения, произведенный компилятором SQL. Для динамических операторов SQL исполнитель собирает план выполнения путем вызова компилятора SQL во время выполнения. Исполнитель интерпретирует каждый план выполнения и использует файловую систему для доступа к конкретной таблице через конкретный путь доступа. Файловая система посылает сообщение соответствующему дисковому процессу для выборки данных. Каждый дисковый процесс обеспечивает доступ к объектам на конкретном диске. На рис. 1 проиллюстрирована процессная архитектура NonStop SQL.
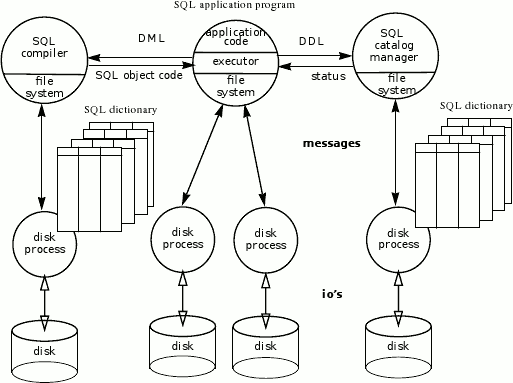
Рис. 1: Процессная архитектура NonStop SQL
2. Оптимизация запросов
В NonStop SQL имеется основанный на оценке стоимости оптимизатор [Seli79], выполняющий как оптимизацию запросов над одним отношением, так и оптимизацию соединений. Оптимизатор генерирует план выполнения с использованием стоимости, выражаемой в терминах эквивалентного числа операций ввода-вывода, выполняемых на некоторой аппаратной конфигурации, что составляет меру системных ресурсов, потребляемых каждой операцией [Pong88]. Потребляемыми ресурсами являются инструкции ЦП, операции ввода-вывода и сообщения. Целью представления стоимости в терминах эквивалентного числа операций ввода-вывода является сведение несравнимых единиц измерения в единое целое. Оптимизатор выбирает план выполнения с наименьшей стоимостью относительно других планов выполнения, генерируемых для данного запроса. В стоимости плана выполнения учитываются доступ к удаленным данным и стоимость выполнения сортировок.
2.1 Оценка селективности
Оптимизатор оценивает селективность предикатов, используя статистику уровня столбцов, сохраняемую в словаре данных. Важными статистическими данными являются SECONDLOWVALUE, SECONDHIGHVALUE и UNIQUEENTRYCOUNT. Они собираются и хранятся в словаре данных при выполнении пользователем команды UPDATE STATISTICS. Разность между вторым наибольшим значением и вторым наименьшим значением определяет диапазон значений столбца. В оптимизаторе предполагается, что значения равномерно распределены в этом диапазоне. Селективностью предиката сравнения по равенству является обратная величина числа вхождений данного значения. Селективность предиката проверки вхождения в диапазон оценивается с использованием интерполяции. Для предиката со сравнением на неравенство, содержащего параметр или переменную основной программы, назначается селективность 1/3.
Для оценки селективности соединения оптимизатор рассматривает транзитивные связи между предикатами эквисоединения. Например, если заданы предикаты A = B и B = C, то оптимизатор выводит A = C. В оптимизаторе поддерживается эквивалентность классов столбцов, принадлежащих предикатам эквисоединения, и они используются для оценки селективности соединений. После того, как таблица, которой принадлежит данный столбец, добавляется к композиции соединения, для столбца соединения синтезируется число вхождений уникальных значений. Мощность результирующей композиции используется как верхняя оценка числа вхождений уникального значения. Селективностью предиката эквисоединения считается обратная величина синтезированного числа вхождений уникального значения.
2.2 Генерация планов
Оптимизатор производит исчерпывающее перечисление планов выполнения запроса. Для каждой таблицы он генерирует план, в котором используется базовый путь доступа, а также по одному плану для каждого альтернативного пути доступа. Каждый план выполнения для одиночной таблицы служит основой для генерации планов соединения.
Оптимизатор строит дерево планов доступа, называемое деревом поиска для перечисляемых планов соединения. С логической точки зрения, рассматриваются все возможные планы. Однако пространство поиска сокращается путем использования следующих эвристик:
- Рассматриваются только праволинейные деревья соединений. Это означает, что соединение четырех таблиц
(ABCD)может быть реализовано как(((AB) C)D)или(((AC) B)D), но не как((AB)(CD)). - Рассматриваются три метода соединения, а именно, вложенные циклы, хэширование и сортировка со слиянием.
- Новая таблица может быть соединена с существующей композитной (соединенной) таблицей, если либо существует предикат эквисоединения, связывающий композитную и новую таблицы, либо ни для одной из оставшихся таблиц нет предиката эквисоединения, связывающего их с композитом.
- На каждом шаге к дереву поиска добавляется только один план, производящий декартово произведение. К дереву поиска добавляется наименьшая таблица, которая еще не принадлежит композиту, и для которой отсутствует предикат эквисоединения, связывающий ее с композитом. Этот план позволяет оптимизировать некоторые запросы (звездообразные запросы), которые выполняются наилучшим образом, если декартово произведение наименьших таблиц формируется раньше соединения результата с более крупными таблицами.
Каждый узел дерева поиска представляет путь доступа для соединенного набора таблиц. Он характеризуется следующим:
- набором содержащихся в нем таблиц;
- путем доступа для чтения из него строк;
- набором вычисленных предикатов;
- порядком сортировки;
- мощностью.
Важным является понятие порядка. Например, при сканировании таблицы с выборкой строк через индекс строки будут выдаваться в некотором порядке. От этого порядка зависит, можно ли избежать последующей сортировки (для ORDER BY или GROUP BY), или можно ли использовать предикат на ключе индекса, или следует ли выполнить сортировку со слиянием.
Оптимизатор может сокращать дерево поиска при добавлении нового композита. При наличии двух деревьев поиска с одинаковыми характеристиками оставляется дерево с меньшей стоимостью.
Оптимизатор вычисляет результаты всех подзапросов без корреляции на шаге инициализации. Подзапросы с корреляцией выполняются сразу, как только становятся доступными внешние значения.
2.2.1 Последовательные планы выполнения
При наличии двух таблиц (или составной и одиночной таблиц) оптимизатор генерирует все планы соединений вложенными циклами, которые можно сгенерировать в соответствии с описанными выше эвристиками. Планы соединений сортировкой со слиянием или хэшированием генерируются только в тех случаях, когда для двух таблиц имеется (по меньшей мере) один связывающий их предикат эквисоединения. Генерируются два плана соединения сортировкой со слиянием. В первом из них используется композит с наименьшей стоимостью, и добавляется стоимость сортировки, так что композит и таблица на фазе слияния будут выдавать строки в одном и том же порядке. Во втором плане используется композит, если такой существует, который выдает строки в том же порядке, что и таблица. В дополнение к этому, генерируются два плана соединения с хэшированием: план с простым хэшированием и план с гибридным хэшированием. Методы соединения хэшированием описываются в подразд. 3.4.
2.2.2 Планы параллельного выполнения
NonStop SQL может параллельно выполнять операторы SQL SELECT, INSERT, UPDATE, DELETE, соединения, группировку и агрегацию. Исчерпывающее обсуждение планов параллельного выполнения представлено в подразд 3.5. Целью использования параллельной схемы выполнения запросов является разделение рабочей нагрузки между несколькими ЦП и сокращение времени ответа за счет потребления дополнительных ресурсов. Параллельные планы выполнения генерируются оптимизатором, когда это разрешается пользователем.
Для определения стоимости параллельного выполнения запроса оптимизатор вычисляет число горизонтальных разделов (составной) таблицы, с которой будет работать данная операция. Он проходит по плану параллельного выполнения и подсчитывает его стоимость. Фиксированная стартовая стоимость приписывается старту каждого серверного процесса-исполнителя и коммуникационным расходам на инициализацию среды выполнения для каждой операции. Затем оптимизатор делит стоимость последовательного выполнения операции на число разделов, над которыми будет выполняться операция, и прибавляет результат к фиксированной стартовой стоимости. Это стоимость выполнения операции на раздел. Для плана на раздел суммируется общая стоимость.
Сначала оптимизатор выбирает самый дешевый план из всех планов параллельного выполнения. Если стоимость двух планов различается не более чем на 5%, применяются правила разрешения конфликтов. План выбирается в соответствие со следующей схемой предшествования:
- Выбор плана, соответствующего разделам, предшествует выбору любого другого параллельного плана.
- Выбор любого параллельного плана предшествует выбору плана с повторным хэш-разделением (hash-repartitioned plan).
- Выбор более дешевого из двух планов с повторным хэш-разделением.
Оптимизатор выбирает параллельный план выполнения, если его стоимость ниже стоимость наилучшего последовательного плана.
2.2.3 Доступ через несколько индексов
Если в запросе над одной таблицей предикаты раздела WHERE представлены в дизъюнктивной нормальной форме, и никакое дерево дизъюнкта не содержит в себе другой дизъюнкт, то оптимизатор пытается использовать план доступа через несколько индексов. В соответствии с этим планом, один или более индексов, принадлежащих одной и той же таблице, последовательно сканируются, и выполняется логическое объединение выбранных строк. Этот план конкурирует с другими планами на основе его стоимости.
2.3 Выбор наилучшего плана
После того как оптимизатор завершает перечисление планов выполнения, для каждого плана в дереве поиска имеется ассоциированная стоимость. Оптимизатор намеревается выбрать план выполнения с наименьшей стоимостью (такой план считается наилучшим). Часто в дереве поиска содержатся два или более планов выполнения, стоимости которых очень близки. Поэтому в оптимизаторе реализуется иерархия правил разрешения конфликтов для сравнения двух правил, стоимость которых отличается не более чем на 10%. Иерархия правил выглядит следующим образом:
- Выбор локального плана доступа, а не удаленного.
- Выбор плана, в котором в качестве пути доступа используется индекс, если для каждого столбца ключа индекса специфицирован предикат сравнения по равенству.
- Если имеются два плана, которые принадлежат типу, описанному в п.2, выбирается тот из них, который обеспечивает ключевой доступ к базовой таблице (таблица реализуется в ключевом-последовательном файле), а не альтернативный индексный путь доступа.
- Выбор плана с более низкой индексной селективностью.
- Выбор плана, в котором используется большее число предикатов на ключевых столбцах индекса.
- Выбор плана, в котором используется индекс с
UNIQUE. - При прочих равных условиях выбор плана, производящего прямой доступ к базовой таблице.