2007 г.
История и актуальные проблемы темпоральных баз данных
Б.Б. Костенко, Московский Государственный Университет им. М.В. Ломоносова
С.Д. Кузнецов,
Институт системного программирования РАН
Страницы: назад 1 2 3 4 вперед
Реляционная модель данных оказалась очень подходящей для хранения данных, обработки и представления результатов запросов, и поэтому темпоральные базы данных с самого начала предполагалось основывать на существующей реляционной модели11, так как темпоральное расширение является лишь одним из дополнительных признаков хранимых данных.
5.1. Создание темпоральной СУБД
Исследователи темпоральных баз данных рассматривали несколько способов создания темпоральной СУБД. Вначале рассматривалась возможность создания темпоральных СУБД «с нуля», то есть самостоятельная реализация некоторой темпоральной модели. Однако реляционные СУБД быстро прогрессировали, расширялась их функциональность, поэтому создание «урезанной» темпоральной СУБД было нецелесообразным, а ресурсов и возможности повторной реализации всех средств реляционной СУБД (при создании темпоральной СУБД) просто не было. Отсутствовала и соответствующая потребность со стороны пользователей. Поэтому вскоре разработчики стали рассматривать различные способы дополнения и расширения обычных реляционных СУБД поддержкой темпоральной модели данных12. Почти все такие способы сводились к созданию некоторого функционального блока, отвечающего за разбор темпоральных запросов, подмену их некоторыми реляционными вычислениями, а потом обратное преобразование в требуемое темпоральное представление для возвращения результатов пользователю. Основным отличием был уровень «вмешательства» в реляционную СУБД, а также степень интеллектуальности данного блока темпоральных преобразований (рис. 7). Сравнение различных вариантов реализации промежуточного слоя представлено, например, в [TJS98].
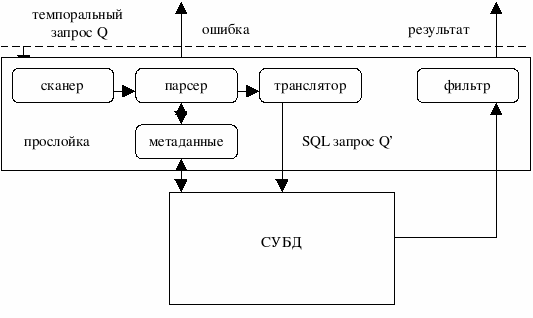
Рис. 7. Общий вид многоуровневой архитектуры темпоральной СУБД
Рассмотрим три крайних случая: преобразование на уровне ядра реляционной СУБД, преобразование на уровне пользовательского приложения и использование независимого промежуточного proxy-уровня. Первый способ предоставляет максимум возможностей по расширению синтаксиса языка баз данных, обеспечению различных проверок, а также оптимизации. Он также обеспечивает полную прозрачность для всех пользовательских приложений, а возможно, и для администратора БД. Однако он доступен только разработчикам СУБД.
В отличие от простого использования приложением реляционной СУБД для работы с темпоральными данными второй способ предполагает выделение некоторых модулей или библиотеки (в пользовательском приложении), отвечающих за преобразование именно темпоральных запросов. То есть основное приложение использует некоторую темпоральную абстракцию, а не реляционную БД в чистом виде, а потом интерпретирует результаты запросов. Подобная абстракция (пусть и на уровне приложения) позволяет сократить число ошибок и отделить бизнес-логику приложения от технической составляющей хранения данных13. В [Sno99] подробно описано, как можно создавать темпоральные приложения в рамках реляционной СУБД.
Третий способ подразумевает создание между пользовательским приложением и СУБД некоторого промежуточного «черного ящика» (будем называть его proxy-уровнем), который может быть реализован в виде драйвера, сервиса, внешней библиотеки и т.п. Для пользовательского приложения этот proxy-уровень должен работать как темпоральная СУБД. С другой стороны, для СУБД этот proxy-уровень является обычным реляционным приложением. Поэтому proxy-уровень оказывается прозрачным как для пользовательского приложения, так и для СУБД, а также не требует внесения изменений в их исходный код. Исходя из того, что между proxy-уровнем и СУБД интенсивность обмена данными может оказаться на порядок выше, чем между proxy-уровнем и приложением (с учетом различных дополнительных оптимизаций), предпочтительно размещать его как можно ближе к СУБД.
Рассмотрим преимущества и недостатки представленных способов. Основным недостатком первых двух подходов является необходимость в изменении кода СУБД или приложения, и поэтому они доступны, в первую очередь, самим разработчикам. Одним из недостатков второго и третьего способа является невозможность сильно влиять на внутреннее представление и хранение информации в СУБД, оптимизацию доступа к ней и т.п. Одним из значительных преимуществ всех трех способов является возможность использовать уже существующие в СУБД модули интерпретации и обработки, лишь дополняя их разбором и преобразованием только темпоральных конструкций и элементов. Дополнительным преимуществом третьего способа можно назвать относительную независимость от конкретной СУБД, если не используются какие-либо специфические особенности и конструкции. В большинстве случаев на работоспособность proxy-уровня не влияет обновление версии СУБД, так как синтаксис SQL-запросов останется прежним.
5.2. Язык запросов к темпоральной базе данных
Для работы с темпоральными базами данных необходимо было разработать язык запросов к ним, который должен был бы стать расширением языка запросов SQL к реляционным базам данных. Рассмотрение языка запросов начнем с конструкций выборки, предложенных авторами языка TSQL2 (SQL/Temporal).
Выше говорилось о темпоральных базах данных, однако реляционная модель предполагает, что данные хранятся в таблицах, и база данных состоит из набора таких таблиц. Поэтому уточним понятия. Во-первых, поскольку практически любая база данных содержит данные, связанные с промежутками времени, ее можно было бы назвать темпоральной. Однако, говоря о темпоральной СУБД, подразумевают, что интерпретацией подобных данных занимается сама система, и поэтому принято считать, что темпоральная база данных – это база данных, содержащая связанные со временем данные, интерпретацией которых занимается СУБД, являющаяся, таким образом, темпоральной СУБД14. С другой стороны, под управлением темпоральной СУБД вполне может находиться обычная реляционная база данных. Более того, для части таблиц темпоральная поддержка может быть включена, а для других таблиц – нет15. Поэтому далее будем рассматривать отдельную таблицу, на время забывая о возможных ее связях с другими таблицами.
При построении модели языка запросов к темпоральной базе данных ставились следующие цели. Во-первых, при переходе к темпоральной модели желательно расширить все три компонента модели данных: структуру данных, операции и ограничения целостности. Во-вторых, любая корректная конструкция в исходном языке запросов должна остаться корректной в новом языке, и семантика этих конcтрукций должна остаться прежней; например, результат, возвращаемый запросом, должен быть таким же. То есть необходимо обеспечить восходящую совместимость языка запросов и базы данных. Кроме того, желательно обеспечить темпоральную восходящую совместимость: необходимо, чтобы после добавления в систему темпоральной поддержки все унаследованные конструкции продолжали работать так же, как и раньше. Из этого следует, что все существующие приложения не должны почувствовать переход от обычной реляционной СУБД к темпоральной СУБД ([BBJ+97]). Более того, последующее добавление темпоральной поддержки в какую-нибудь конкретную таблицу не должно отразиться на корректности выполнения запросов. С другой стороны, подобное добавление должно позволить использовать темпоральные запросы в новых программах, заметно облегчая работу программистам и администраторам системы.
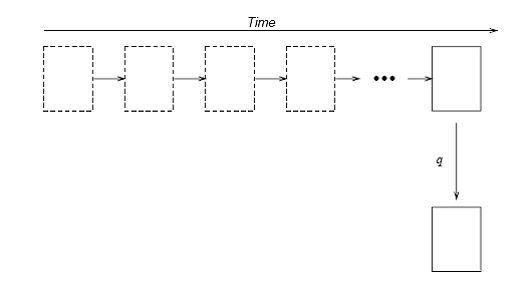
Рис. 8. Работа с таблицей без темпоральной поддержки
Рассмотрим таблицу, содержащую информацию о заработной плате сотрудников. До добавления темпоральной поддержки таблица содержала только актуальную информацию (на текущий момент времени)16. В таком случае у приложения имеется возможность узнать текущее значение любых элементов данных, но предыдущее значение будет потеряно после любого изменения. После удаления записи вообще невозможно будет сказать, например, сколько получал данный сотрудник перед увольнением. Такая ситуация существует при использовании традиционной реляционной модели (рис. 8). Предположим, что позже было принято решение о необходимости хранить историю значений заработной платы сотрудников. Решить это можно было бы несколькими путями. Во-первых, можно создать специальную таблицу с историей зарплаты, но это могло бы быть достаточно странным, так как уже есть таблица «заработных плат». Более того, пришлось бы модифицировать код приложения, чтобы при удалении и изменении значений происходило автоматическое обновление данных и во второй таблице. Второй способ – добавление специальных столбцов, отражающих интервал актуальности конкретной записи, но при этом также потребуется доработка приложения, и логика многих запросов может стать не слишком очевидной. Наиболее естественным было бы добавить для данной конкретной таблицы темпоральную поддержку. В этом случае все ранее разработанные запросы будут корректно работать (с текущим состоянием), но можно сформулировать новые темпоральные запросы, которые позволят узнать историю изменений (рис. 9).
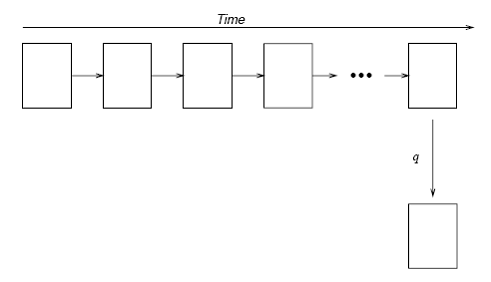
Рис. 9. Работа реляционных приложений с темпоральной таблицей
Какие же запросы могут быть сформулированы к таблице с темпоральной поддержкой? Во-первых, это запрос значений на какой-нибудь момент времени в прошлом, то есть создание среза истинности фактов на произвольную дату. Например, для обычного реляционного запроса «какую зарплату сейчас получает каждый из сотрудников?» можно легко сформулировать его темпорального двойника «какую зарплату получал каждый из сотрудников в указанную дату?» В этом случае результат запроса останется в рамках реляционного представления. С другой стороны, вполне естественным оказывается запрос «когда и какую зарплату получал каждый из сотрудников?». Здесь уже в результатах запроса появляется линия времени. Один из традиционных способов представления подобных результатов опирается на интервальное действительное время, то есть к обычному реляционному представлению результатов добавляется еще один столбец, содержащий интервалы истинности фактов. Алгоритм формирования результатов подобных запросов можно упрощенно представить следующим образом: для каждого момента времени17 вычисляется реляционный подзапрос «какую зарплату получает каждый из сотрудников», после чего к общему результату добавляются результаты этих подзапросов с учетом интервалов истинности. Подобная семантика «последовательной» интерпретации реляционных запросов называется последовательной (sequenced valid semantics), см. рис. 10.
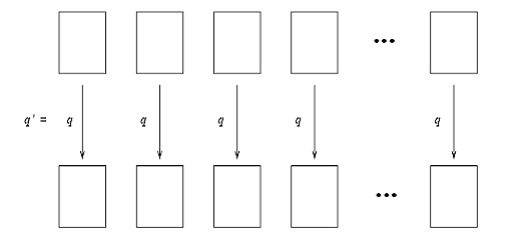
Рис. 10. Обработка "последовательных" запросов к темпоральной таблице
Однако на основе этой семантики невозможно сформировать запрос, который требует «сравнения» нескольких последовательных моментов времени. К таким запросам относится большинство запросов, включающих агрегационные функции «во времени», например, «вывести среднюю заработную плату сотрудника за все периоды времени» (отметим, что результат будет представлен обычной реляционной таблицей) или «вывести периоды, когда на оплату труда сотрудников уходила максимальная сумма». Предусмотреть все подобные типы запросов невозможно, и также нельзя ограничивать выразительные возможности языка, поэтому была предложена конструкция запросов произвольного доступа к темпоральным данным (Non-Sequenced Queries), которые предоставляют возможность самостоятельно сформулировать необходимый запрос, накладывая ограничения на системный темпоральный столбец18. См. рис. 11.
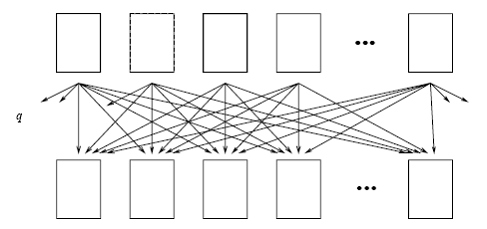
Рис. 11. Обработка "произвольных" запросов к темпоральной таблице
Таким образом, при наличии темпоральной поддержки в системе можно выделить четыре уровня использования запросов (для конкретной таблицы): 1 – темпоральная поддержка для таблицы отсутствует, 2 – использование реляционных запросов к таблице с темпоральной поддержкой, 3 – использование последовательных запросов и 4 – использование произвольных темпоральных запросов. Подобная классификация верна как для таблиц с поддержкой действительного времени, так и для тех, для которых поддерживается транзакционное время. Поскольку эти линии времени являются ортогональными и независимыми, в системе с темпоральной поддержкой получается шестнадцать вариантов использования запросов на выборку.
На основе запросов на выборку можно формулировать темпоральные ограничения целостности, которые будут проверяться при операциях обновления базы данных. Для операций модификации и удаления записей можно накладывать аналогичные ограничения в их разделах WHERE. С другой стороны, обработка запросов на обновление для транзакционного и действительного времени будет принципиально отличаться. Например, в разделе SET невозможно задавать системные поля транзакционного времени. Поэтому полностью корректная реализация поддержки транзакционного времени возможна только при реализации темпоральных операций внутри ядра СУБД.
5.3. Представление результатов темпоральных запросов
Выше уже упоминались два подхода к представлению информации в темпоральной базе данных: интервальный, когда принимается во внимание период истинности факта, и точечный, когда для каждого отдельного момента времени рассматриваются все факты, истинные в этот момент. При реализации темпоральной СУБД и проектировании языка запросов требуется выбрать один из этих вариантов представлений. При хранении данных в базе данных наиболее компактным является интервальное представление. При представлении результатов запросов также многое говорит в пользу интервального представления19. Но при формулировке многих запросов удобнее сравнивать моменты времени, а не оперировать интервалами истинности отдельных фактов, поэтому точечное представление получает значительное преимущество.
Операции над множествами очень удобны для теоретических выкладок и формализации, но трудно реализуемы в системе при значительном объеме данных. Поэтому интервалы времени принято разделять на такие подинтервалы, чтобы для каждого факта они не пересекались, но дополняли друг друга до исходного интервала, а любые два интервала разных фактов либо не пересекались, либо совпадали. При таком представлении истинность фактов не будет меняться ни для одного из получившихся интервалов, что, например, позволит корректно использовать полный вложенный перебор по интервалам и фактам при получении результата запросов. После получения результата в виде набора интервалов истинности для каждого факта необходимо выполнить обратную процедуру – объединение пересекающихся или примыкающих друг к другу интервалов. Два данных преобразования называются распаковкой и упаковкой. Эти операции могут применяться и во время промежуточных вычислений. Фактически, перед каждой операцией над темпоральными данными можно выполнять распаковку, а потом – упаковку.
5.4. Специальное значение «сейчас»
Слово «сейчас» означает «в настоящее время, в данный момент». В запросах на языке SQL довольно часто используются конструкции CURRENT_TIMESTAMP, CURRENT_DATE и CURRENT_TIME, которые заменяются соответствующими константами в момент выполнения запросов, поэтому в самой базе данных хранятся лишь конкретные значения дат и времени. Так как язык запросов к темпоральной базе данных является расширением языка SQL, данные конструкции в нем также могут использоваться как синонимы «динамических» констант. Однако для работы с фактами, которые истинны в настоящий момент, но могут меняться с течением времени, необходимо использовать дополнительное специальное значение СЕЙЧАС. Оно используется при задании верхней границы интервала истинности факта, хранимого в таблице с темпоральной поддержкой ([CDI+97]).
Пусть в базе данных хранится информация о периоде работы сотрудника в компании. Тогда до 2 апреля для сотрудника, пришедшего на работу 1 апреля, промежутком времени его работы в компании является один день 1 апреля. На следующий день промежуток его работы в компании изменится на интервал с 1 по 2 апреля. Через день интервал примет вид 1 – 3 апреля и так далее. Одним из путей решения подобной проблемы могло бы быть ежедневное обновление базы данных, изменяющее верхнюю границу интервала на корректное значение, но это нереальный вариант. Поэтому при выполнении запросов можно использовать подобную динамическую подстановку20. Для этого можно хранить динамическую константу СЕЙЧАС, обозначающую зависимость факта от текущего времени. В приведенном примере это бы означало, что человек работает в компании с 1 апреля по СЕЙЧАС.
В качестве представления СЕЙЧАС можно использовать одно из значений домена TIMESTAMP или пустое значение NULL. При выборе значения для представления СЕЙЧАС необходимо гарантировать, чтобы это значение не использовалось с каким-либо иным смыслом. Фактически, требуется сделать выбор из значения NULL и максимального или минимального значения типа TIMESTAMP. При использовании СЕЙЧАС в запросах необходимо принимать во внимание, что его следует заменять текущим временем на этапе выполнения. При работе над системой TimeDB [Tim07] исследовалась производительность системы для различных вариантов представлений. Было продемонстрировано, что представление СЕЙЧАС с помощью минимального значения типа TIMESTAMP всегда самое медленное. Представление в виде NULL было наиболее эффективным при большем проценте пересечений с текущим временем. Однако представление в виде NULL-значения всегда приводило к максимальному количеству чтений диска. На основе этого анализа был сделан выбор в пользу максимального значения типа TIMESTAMP.
Использование некоторого специального значения СЕЙЧАС не является единственно возможным решением. Например, можно разделить все факты на два класса, в одном из которых хранятся факты, для которых интервал уже точно известен, а в другом – те, у которых верхняя граница еще не известна. Если хранить эти факты в разных таблицах, то не потребуется вводить специальное значение СЕЙЧАС, однако несколько усложнится выборка, а таблицы с поддержкой и транзакционного, и действительного времени придется разбивать на четыре подтаблицы.
Выше речь шла о представлении значения СЕЙЧАС в системе, однако важна и его интерпретация. Например, тот факт, что сотрудник работает с 1 апреля по СЕЙЧАС, не подтверждает, но и не опровергает, что на следующей неделе он также будет работать. Но для другого сотрудника может быть известно, что он работает только до конца этой недели, и поэтому в отчетах за данную неделю о сотрудниках, которые будут работать на следующей неделе, второй сотрудник фигурировать не должен, а про первого сказать ничего нельзя. Поэтому корректная интерпретация значения СЕЙЧАС возможна лишь для прошлого. При работе с событиями будущего необходимо проявлять осторожность и точно понимать, что и каким образом должно быть получено в качестве результата задаваемого запроса.
5.5. Разрежение таблиц с темпоральной поддержкой
Если говорить о таблицах с темпоральной поддержкой, то причиной снижения производительности может стать постоянно возрастающий объем хранимых данных. Это, в первую очередь, относится к таблицам с темпоральной поддержкой транзакционного времени, так как в таких таблицах данные физически не удаляются из системы, а лишь добавляются (в том числе и при модификации записей). С другой стороны, через определенный промежуток времени оказывается, что часть данных устарела, и поэтому их было бы желательно физически удалить из системы, так как они не только занимают место, но и снижают производительность при выборках. Но подобное физическое удаление подвергает риску общую целостность хранящихся данных.
Поэтому фундаментальным требованием является возможность контролирования физическое удаление данных, что приводит к операции, которая называется разрежением (vacuuming) таблиц с темпоральной поддержкой. Для обеспечения корректности выполнения разрежения необходимо иметь возможность указывать в запросе данные, которые должны быть удалены, и те, которые должны быть оставлены. Очевидно, что все «активные» строки должны остаться в таблице при любом ее разрежении. В простейшем случае отбрасываются все те кортежи, которые были удалены21 до определенного момента времени – происходит срез истории.
Но подобное разрежение является не совсем корректной операцией. Например, пусть мы хотим сделать выборку состояния на какой-нибудь момент времени A, предшествующий аргументу среза B (A < B), когда в таблице находились некоторые строки X и Y, первая из которых была удалена до момента времени B, а вторая – нет. Тогда в качестве результата запроса будет выдана строка Y, но не X. Многие запросы могут начать неправильно работать, и к ним, скорее всего, будут относиться все запросы, использующие агрегатные функции.
Чтобы обезопасить себя от части подобных проблем, можно предложить специальный вариант среза, когда нижняя граница интервала транзакционного времени для всех строк становится равной моменту времени среза, если этот момент принадлежал исходному интервалу. Но и в этом случае искажается информация о времени истинного появления строки в системе. Поэтому разрежение темпоральных таблиц не является однозначным решением, и в каждом конкретном случае необходимо отдельно рассматривать все плюсы и минусы.
Отметим, что с точки зрения работы с системой и формулировки запросов нет необходимости в разрежении, однако переполнение базы данных «устаревшими» сведениями может негативно сказываться на производительности. От негативных последствий проблемы зависимости поведения приложений при проведении разрежения можно частично избавиться, если вместо реального удаления данных выполнить их перенос на другой доступный носитель. Например, данные из одной базы переносятся в другую, расположенную на другом сервере, причем в исходной базе остается информация об этом переносе. В этом случае при необходимости обращения к истории запрос может быть перенаправлен или объединен с результатом выборки из другой базы данных.
Проблема с «разрежением» таблиц относится к транзакционному времени, но она также рассматривается и с точки зрения действительного времени. Например, если речь идет о хранении некоторых промежуточных версий какого-либо документа, то может оказаться, что интерес представляет лишь окончательная версия за январь прошлого года, а все промежуточные версии можно удалить. В этом случае можно также воспользоваться разрежением, но выбор доступных методов гораздо шире, например, можно оставить каждый третий документ или не больше одного документа в месяц, а само разрежение применить к документам прошлого года.
5.6. Проектирование темпоральных баз данных
В настоящее время существуют проверенные методы и инструментарий, используемые при проектировании реляционных баз данных. При работе с темпоральными базами данных необходимо учитывать темпоральную специфику и использовать соответствующие средства. Рассмотрим простой вопрос: сколько в базе данных должно быть таблиц с темпоральной поддержкой? Если для действительного времени ответ на данный вопрос достаточно прост (количество таблиц определяется потребностью приложений), то при наличии транзакционного времени он становится нетривиальным, так как от ответа от него зависит объем накапливаемой истории. При этом не всегда требуется именно поддержка транзакционного времени, а вполне может подойти и простой журнал, реализованный вне базы данных. При проектировании таблиц с поддержкой действительного времени можно использовать обычные инструменты, дополняя таблицы интервалами (парой значений) времени, однако в этом случае количество связей между таблицами заметно увеличивается. Более того, невозможно корректно описать работу со специальным значением СЕЙЧАС. При проектировании темпоральной базы данных следует также помнить, что все «обычные» реляционные ключи таблиц будут неявно расширяться верхней границей интервала транзакционного и/или действительного времени. Ограничения целостности также должны формулироваться с учетом этих обстоятельств ([JT95]).
Если темпоральная поддержка используется не для всех таблиц, то возникает вопрос, связанный с выборкой данных из нескольких таблиц на какой-либо момент прошлого: что делать с совместными выборками из таблицы с поддержкой транзакционного времени и из таблицы без подобной поддержки? Вполне возможно, что результат выборки будет неверен, так как информация из обычной таблицы могла быть уже удалена или изменена, а в соответствующей темпоральной таблице остались внешние связи. Таким образом, если разрешить подобные выборки, то могут возвращаться некорректные результаты. Если же такие выборки запретить, то становится непонятно, как работать с потенциально константными данными, например, названиями дней недели, которые могут храниться в таблице без темпоральной поддержки. Принудительное добавление темпоральной поддержки для всех таблиц также не является лучшим выходом, так как усложняет алгоритм работы СУБД и требует дополнительных ресурсов.
5.7. ACID-свойства темпоральных транзакций
Основными свойствами традиционных транзакций, поддерживаемыми в реляционных СУБД, являются ACID (атомарность, целостность, изолированность и продолжительность). При создании темпоральной СУБД чрезвычайно важно перенести подобные свойства и на темпоральные транзакции. ACID-свойства темпоральных SQL-транзакций могут быть сохранены за счет отображения каждой темпоральной транзакции в одиночную реляционную SQL транзакцию. Альтернативные реализации темпоральных транзакций, при которых proxy-уровень отображает темпоральную SQL-транзакцию в несколько обычных SQL-транзакций, могут привести к неразрешимым проблемам, если во время выполнения получится так, что одна из реляционных SQL-транзакций будет зафиксирована, а вторая – нет, что должно означать неудачу всей темпоральной SQL-транзакции, а не отдельной ее части. Выполнить же откат транзакции, зафиксированной в базе данных, может оказаться просто невозможно, так как изменения уже могут быть использованы параллельно работающими транзакциями. Поэтому для поддержки параллельно работающих темпоральных транзакций необходимо реализовывать их в виде одиночных SQL-транзакций, иначе не удастся обеспечить поддержку ACID-свойств22.
Кроме этого, недостаточно требовать только то, чтобы каждая темпоральная SQL транзакция отображалась в одну SQL-транзакцию. Для каждой транзакции необходимо обеспечить, чтобы в ее пределах транзакционное время было константно, но тогда встает вопрос, как его выбирать, ведь условия на специальное значение СЕЙЧАС должны проверяться с тем же значением константы. Здесь возможны два основных варианта: транзакционное время выбирается в самом начале или в самом конце выполнения транзакции. Первый вариант являеется некорректным, так как параллельная транзакция может внести изменения в таблицы, которые еще только понадобятся данной транзакции. Поэтому наиболее удачным выбором является момент времени непосредственно перед фиксацией транзакции, после того, как получены блокировки на все затрагиваемые объекты. Но и здесь возможны проблемы, если транзакция получит одно значение транзакционного времени, а будет зафиксирована чуть позже, так что между этими двумя моментами будет благополучно выполнена некорректная выборка. Подобная проблема может возникнуть и при параллельном выполнении двух различных транзакций.
Один из способов, который сможет гарантировать корректную поддержку ACID-свойств темпоральных транзакций, состоит в реализации дополнительного механизма блокировок на proxy-уровне. Отметим, что восстановление базы данных, которое является важной частью работы СУБД, является прозрачным для конечного пользователя. При использовании многоуровневой архитектуры для конечного пользователя промежуточный слой ничем не отличается от СУБД, поэтому при проектировании прослойки можно полностью положиться на механизмы восстановления, реализованные в СУБД. Также нет причин, по которым они стали бы работать быстрее или медленнее.
5.8. Эффективность при работе с темпоральной СУБД
Одним из наиболее важных вопросов при использовании баз данных является эффективность работы приложений с соответствующей СУБД. Для повышения скорости обработки запросов в реляционных СУБД традиционно применяются индексы для выборки данных из таблиц, а также статистики и различные эвристики при выборе алгоритма соединения данных из нескольких таблиц ([GJS+05]). При разработке темпоральных СУБД значительное внимание уделялось именно вопросам производительности, так как в общем случае небольшая доля «активных» данных из постоянно растущего объема информации в базе данных приводила к резкому спаду производительности при интенсивном использовании и/или недостаточном внимании при разработке приложения.
Наиболее очевидным, а также доступным способом оптимизации темпоральных приложений является использование индексов. Например, при добавлении дополнительных специальных столбцов для интервалов транзакционного времени необходимо включить верхний предел во все уникальные индексы. С другой стороны, необходимость постоянно разделять данные на «активные» и «устаревшие» требует их разделения на ранней стадии обработки, что также может быть обеспечено с помощью индексов. Аналогичная ситуация возникает при соединении темпоральных таблиц, так как оно часто проводится именно по специальным темпоральным столбцам.
Однако встает вопрос: должны ли темпоральные столбцы располагаться до или после остальных столбцов (обычного реляционного) индекса? Если они будут идти после всех обычных столбцов, то система получится почти «реляционной», так как большинство операций вначале будет выполняться именно на основе реляционных условий, а лишь затем будет применяться ограничение по времени, а значит, все проблемы с огромным объемом информации ложатся на традиционное реляционное ядро СУБД. Если же темпоральные столбцы будут располагаться перед обычными, то объем обрабатываемых данных будет напрямую зависеть лишь от наличия ограничений на темпоральные столбцы; например, при попытке получить историю отдельного кортежа при отсутствии темпоральых ограничений системе придется просмотреть историю всех кортежей (точнее, полностью весь индекс). Кроме того, подобный индекс будет довольно часто перестраиваться при изменениях данных темпоральных столбцов. С другой стороны, единственным изменением кортежа в таблице с темпоральной поддержкой транзакционного времени является установка вместо СЕЙЧАС точной верхней границы интервала (в момент удаления или изменения кортежа).
Описанные выше проблемы касались выборок из одной темпоральной таблицы. Наибольший же интерес представляют выборки из нескольких таблиц и соответствующее соединение результатов. До сих пор разрабатываются различные алгоритмы и предлагаются эвристики для решения задачи эффективного соединения нескольких таблиц в традиционной реляционной СУБД. Частично они позволяют решить проблему производительности при соединении таблиц, но вся оптимизация возлагается на СУБД. Одновременно с этим следует помнить, что данные хранятся в интервальном представлении, поэтому соединение будет либо строиться на нестрогих неравенствах, либо алгоритм будет выполняться темпоральным ядром СУБД с учетом упаковки и распаковки темпоральных интервалов. Отсюда следует, что доступным путем является оптимизация преобразований различных темпоральных запросов в реляционные запросы и обратно с учетом построенных индексов. С другой стороны, в большинстве случаев разработчики приложений не смогут получить значительный выигрыш в эффективности, если будут сами формулировать реляционные запросы, а не пользоваться автоматическими преобразованиями, но первый путь сложнее и чреват появлением ошибок.
Таким образом, у создателей прототипов темпоральных СУБД не было широкого выбора методов оптимизации, а единственным действенным способом являлось расширение индексов или использование промежуточных алгоритмов, но за счет увеличения потока данных между proxy-уровнем и реляционной СУБД. При этом исследователи предлагали различные расширения стандартных подходов к индексированию реляционных баз данных и хранению данных.
11 В данной статье основное внимание уделяется именно реляционным темпоральным базам данных. О других вариациях будет упомянуто в разд. 6.
12 Фактически, именно этот факт приводит к «реляционности» большинства темпоральных моделей.
13 Возможна ситуация, когда информация, относящаяся к различным периодам времени, будет храниться на различных носителях.
14 Данное определение не противоречит определениям, приведенным ранее, но вполне конкретизирует пару «темпоральная база данных и соответствующая СУБД».
15 Это имеет решающее значение при проектировании базы данных, а также при построении запросов с использованием соединений или программировании вложенных циклов.
16 Можно возразить, что в системе с самого начала должна была бы храниться вся история изменений заработной платы сотрудника, а таблица только с актуальными показателями малопригодна. Но это лишь подчеркивает, что при разработке приходится учитывать неявную темпоральную составляющую.
17 Достаточно рассматривать только те моменты времени, когда происходит изменение истинности одного из фактов, хранящихся в базе данных.
18 Фактически, система позволяет только формулировать ограничения и отношения между интервалами и отдельными моментами времени, а все остальное отдается на откуп пользователю.
19 Точечное представление может быть более удобно при ограниченности (и дискретности) возвращаемых моментов времени и их последующем использовании при программной обработке.
20 Если подстановка для CURRENT_TIMESTAMP, CURRENT_DATE и CURRENT_TIME выполняется для данных запроса, то здесь подстановка выполняется для информации, хранимой в базе данных.
21 В терминах транзакционного времени.
22 Если, конечно, не реализовывать на proxy-уровне собственный механизм управления транзакциями над механизмом управления транзакциями базовой СУБД.
Страницы: назад 1 2 3 4 вперед
[an error occurred while processing this directive]

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС