2010 г.
Дом на песке
Пэт Хелланд, Дейв Кэмпбел
Перевод: Сергей Кузнецов
Назад Содержание Вперёд
3. Сохранение прозрачности при разрастании системы
В этом разделе мы обсудим, как была реализована прозрачная отказоустойчивость в системе Tandem NonStop за счет использования синхронных контрольных точек на границе отказов. Сначала мы рассмотрим систему Tandem образца 1984-го г., когда стратегия установки контрольных точек предполагала пересылку состояния при выполнении каждой отдельной операции записи в базу данных. Эта стратегия была корректной, но приводила к некоторым проблемам производительности. Около 1985-го г. программное обеспечение было модифицировано применительно к новой стратегии, которая обеспечивала более высокую производительность. Поэтому далее мы проанализируем поведение систем Tandem образца 1986-го г., когда сохранение состояния производилось менее энергично, но этого хватало для обеспечения гарантированной прозрачности. Мы завершим разд. 3 обсуждением того соображения, что изменения в системе периода 1984-1986 гг. ослабляли семантику отказов, но эти ослабления являлись приемлемыми на практике.
3.1 Пример 1: Tandem NonStop образца 1984 г.
Система Tandem NonStop – это массивно-параллельная система без использования общих ресурсов со связью между компонентами на основе обмена сообщениями [5]. У каждого узла имеется свой центральный процессор, основная память, доступ к шинам передачи сообщений и контроллерам ввода-вывода. У каждого контроллера ввода-вывода имеются два порта, и к нему могут производить доступ любые два узла системы. Пары котроллеров ввода-вывода обеспечивали доступ к зеркальным дискам. Эта аппаратная архитектура вместе с операционной системой Guardian, монитором транзакций (Transaction Monitoring Facility, TMF) и дисковым процессом (Disk Process, DP) обеспечивала наилучшую в отрасли доступность для систем OLTP в 1980-е гг. и не утратила свое лидерство до сегодняшних дней.
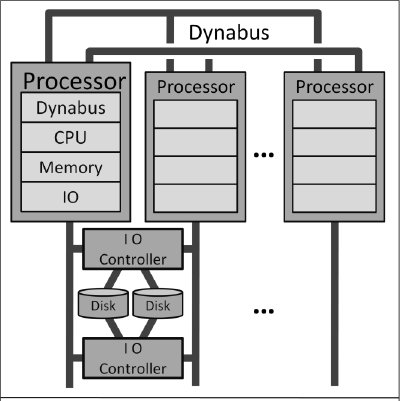
Рис. 2. Аппаратная архитектура Tandem NonStop. От 2-х до 16-ти процессоров (с основной памятью и портом ввода-вывода) объединяются двухпортовой шиной передачи сообщений Dynabus. Каждый контроллер ввода-вывода подсоединяется к двум процессорам. Зеркальные диски подключаются к избыточным контроллерам ввода-вывода. Такая архитектура позволяла выдержать любой одиночный отказ.
Для выполнения своей транзакционной работы приложение запускается в одном из процессов и посылает сообщения для чтения с дисков и записи на них дисковым процессам, которые управляют данными и формируют записи для журнала транзакций. При выполнении каждой операции записи выполняется установка контрольной точки2, чтобы резервный узел мог продолжить выполнение транзакции в случае отказа основного узла, обсуживающего диск. Во время фиксации транзакции от всех DP, выполнявших операции записи, требуется выталкивание их журналов в ценральный процесс дискового аудита (Audit Disk Process, ADP ).
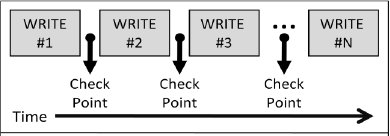
Рис. 3. В системе Tandem образца 1984 г. алгоритм каждой операция записи процесса DP является идемпотентным. Данные об этой операции посылаются основным дисковым процессом резервному процессу при установке контрольной точки.
Следует обратить внимание на то, какова гранулярность элементов в этом подходе к отказоустойчивости. В 1984 г. каждая операция записи являлась идемпотентной, и для нее устанавливалась контрольная точка в резервном DP [4]. Единицей гранулярности отказа был отдельный процесс или процессор. Гранулярность "идемпотентного подалгоритма" определялась одной операцией записи, которая приводила к установке контрольной точки. Отказы основного DP не обязательно вызывали аварийное завершение транзакции (рис. 4).
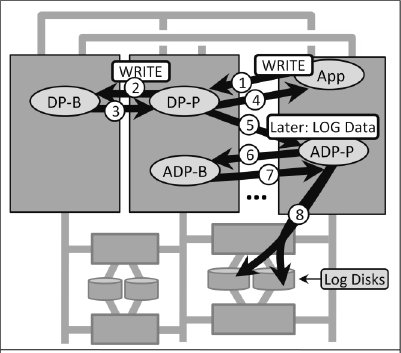
Рис. 4. В системе Tandem образца 1984 г. показаны процесс приложения, основной и резервный дисковые процессы (DP) и процесс дискового аудита, который записывает журнал на диск. В контрольной точке между основным и резервным DP содержатся данные об операции записи, лишь слабо коррелирующие с данными в журнале транзакций.
3.2 Пример 2: Tandem NonStop образца 1986 г.
В 1985 г. в составе нового выпуска операционной системы Tandem NonStop Guardian присутствовал новый дисковый процесс DP2. В этом выпуске имелся ряд изменений, включая динамическую оптимизацию стратегии отказоустойчивости [7].
В полностью переработанном дисковом процессе DB2 применялся совершенно новый подход к установке контрольных точек. Журнал транзакций, описывающий изменения состояния на диске, теперь использовался и для описания изменений, которые должны были стать известны резервному дисковому процессу. Другими словами, установка котрольных точек и журнализация транзакций объединялись в одном механизме. Журнал сначала отправлялся резервному процессу, а потом ADP, который записывал его на диск (рис. 5).
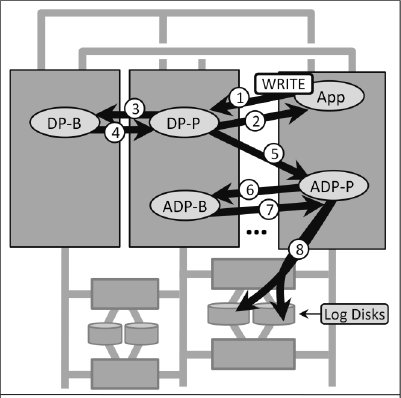
Рис. 5. В системе Tandem образца 1986 г. показаны процесс приложения, основной и резервный дисковые процессы (DP) и процесс дискового аудита, который записывает журнал на диск. Записи о контрольных точках DP такие же, что и содержимое журнала. Эти данные перетекают от основного DP к резервному, потом к ADP (основному и резервному) и затем записываются на диск. Заметим, что приложение получает подтверждение (2) до посылки этих данных процессом DP2 куда бы то ни было (даже пересылка данных о контрольной точке резевному DP производится асинхронно с ответом на запрос операции записи со стороны приложения).
Цель нового подхода состояла в том, чтобы позволить сохранять изменения, вызываемые транзакционной операцией записи, в транзакционном журнале в основной памяти основного дискового процесса DP2. Основной DB2 подтверждал приложению выполнение операции записи. Конечно, оставался открытым вопрос о корректности такого поведения, если в результате отказа основного DP2 терялись буферизованные изменения, произведенные незафиксированными (uncommitted) операциями записи. Как это могло быть корректным?
Корректность обеспечивалась за счет того, что при отказе основного DP система аварийно завершала все выполняемые транзакции, которые использовали этот процесс. Поскольку для всех зафиксированных транзакций система гарантировала выталкивание всех изменений в дисковую память, потеря содержимого основной памяти основного DP влияла только на незавершенные тразакции. Поскольку система при отказе основного DP автоматически аварийно завершала все соответствующие транзакции, корректность соблюдалась.
Эта схема означала, что отказ процессора мог привести к аварийному завершению большего числа транзакций. Это случалось очень редко и не противоречило общим правилам системы, допускающим аварийное завершение транзакций без повода с их стороны. Вполне возможно, что это изменение системы было почти незаметным для разработчиков приложений и пользователей.
Новая схема обеспечила громадный выигрыш в производительности. Операцию записи в DP2 стало можно выполнять без пересылки информации о контрольной точке резервному дисковому процессу. Это позволило существенно сократить расходы центрального процессора и в еще большей степени уменьшить задержки, поскольку приложению не требовалось ждать завершения операции установки контрольной точки для получения подтверждения выполнения своей операции записи. Буфер, содержащий журнальные записи, передавался резервному процессу (и ADP) лишь периодически. Это очень напоминает групповую фиксацию (group commit) [11]. Легко понять, откуда берется эффективность, если подумать о различии между индивидуальным автомобилем, раскатывающим по городу с одним водителем, и городским автобусом, через каждые пять минут высаживающим и всаживающим пассажиров. Как отмечалось в [11], в нормальных обстоятельствах ожидание участия в совместном использовании буферов записи может сократить задержку, поскольку уменьшается общий объем работы системы. Это сокращение объема работы может уменьшить коэффициент загруженности системы и более чем компенсировать возможные потери транзакций.
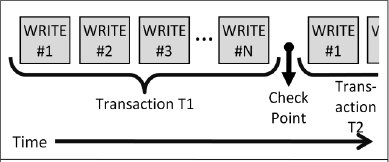
Рис. 6. В Tandem образца 1986 г. каждая операция записи локально буферизуется в основном DP. НЕ ГАРАНТИРУЕТСЯ, что данные об этой операции будут переданы резервному процессу, и отказ основного процесса приводит к аварийному завершению транзакции. Гарантируется выталкивание на диск журнала транзакции при ее фиксации. Теперь алгоритм операции записи не является идемпотентным, в качестве такого алгоритма теперь выступает транзакция.
Если вернуться к абстракции отказоустойчивости, то мы видим (рис. 6), что гранулярность идемпотентного алгоритма увеличилась от размера операции записи до размера транзакции. Гранулой отказа по-прежнему является процессор, и пользователь почти не ощущает изменения общего алгоритма.
3.3 Приемлемое ослабление поведения
В 1986 г. система Tandem демонстрировала существенно лучшую производительность, чем в 1984 г. Однако могли возникать отказы процессоров, приводящие к поведению системы, отличному от поведения предыдущего ее выпуска. Если возникал отказ процессора в середине выполнения некоторой транзакции, то в предыдущем релизе выполнение этой транзакции продолжалось. В 1986 г. отказ процессора мог привести к потере выполняемых транзакций.
Хотя с технической точки зрения поведение изменилось, имелись основания считать это изменение приемлемым. С самого начала правила системы позволяли ей аварийно завершать транзакции без (видимых) причин. К аварийному завершению транзакциии могли привести синхронизационные тупики, решения операторов, срабатывание таймаутов и т.д. Поэтому это ослабление поведения системы и было приемлемым.
В версии системы Tandem 1984 г. была реализована синхронная передача данных об операции записи в резервный процесс. До установки контрольной точки приложение не получало от основного DP подтверждения о выполнении операции записи. В 1986 г. записи стали асинхронными, но гарантировалось, что после фиксации транзаций отказы процессоров не вызовут потери ее данных в дисковой памяти.
4. Медленное наступление асинхронности
В этом разделе мы увидем первый пример подтверждения поступающего запроса ДО посылки соответствующих данных в резервную копию. Это асихронная установка контрольных точек с резервной копией.
Мы начнем с очень простого обсуждения "доставки журнала" (log-shipping), при которой журнал транзакций посылается в резервную систему иногда после подтверждения пользовательского запроса. Это принципиальное изменение, глубоко влияющее на гарантии, которые обеспечиваются для пользователей.
После обсуждения доставки журнала мы проанализируем семантику перехвата управления при применении этого подхода. Затем мы обсудим, какого пересмотра нашей абстракции отказоустойчивости требует появление этой асинхронности.
4.1 Пример 3: доставка журнала
Этот пример должен быть хорошо известен большинству пользователей. В классической системе баз данных имеется некоторый процесс, который читает журнал и доставляет его в резервный центр данных. При обычной реализации этого механизма транзакции фиксируются в основной системе (и пользователю подтверждается выполнение запроса фиксации), и журнал доставляется асинхронно. Резервная система баз данных воспроизводит журнал, постоянно нагоняя основную систему.
Обычно приложения и пользователи не обращают внимания на доставку журнала. Пока не возникают отказы, приложение и пользователь сыты, глупы и счастливы. Когда же отказ СЛУЧАЕТСЯ, некоторые недавно завершенные транзакции теряются, когда резервная система берет на себя управление.
Это означает, что абстракция отказоустойчивости, описанная в разд. 2, перестает работать, если состояние не становится немедленно известным резервной системе. Отказоустойчивость НЕ является прозрачной. ВОЗМОЖНА (с низкой вероятностью) полная утрата недавно завершенной работы.
Чтобы обеспечить прозрачную отказоустойчивость центра данных, алгоритм отправки журнала должен был бы притормозить отправку ответа приложению на запрос фиксации транзакции до тех пор, пока в основной системе не станет известно, что журнал действительно доставлен в резервную систему. В большинстве случаев такая задержка недопустима, и приходится работать при наличии небольшой вероятности утраты результатов недавно завершенной работы. Изменение синхронной передачи состояния на асинхронную передачу является интересным ослаблением нашей базовой абстракции, и это еще один пример ситуации, в которой стоимость поддержки "согласованности на некотором расстоянии" является слишком высокой, как если бы попытаться использовать протокол двухфазной фиксации для координации менеджеров ресурсов.
|
Доставка журнала: наш первый пример, в котором небольшое жертвование согласованностью приводит к значительному выигрышу в устойчивости и масштабировании!
|
4.2 Доставка журнала и семантика перехвата управления
Доставка журнала производится асинхронно с выдачей ответа приложению. Это, по сути, приводит к образованию окна во времени, когда выполнение работы подтверждается пользователю, но соответствующие данные еще не доставлены в резервную систему. Отказ основной системы, происходящий в течение этого промежутка времени, приведет к изоляции этой работы внутри первичной системы на неопределенное время. Резервная система будет двигаться вперед без информации об этой изолированной работе.
В большинстве случаев применения асинхронной доставки журнала это не учитывается при разработке приложений. Считается, что такое окно образуется редко, и не следует учитывать возможность отказа в этот промежуток времени. Если вдруг не повезет, то будут неприятности. К сожалению, в большинстве систем при перехвате управления требуется ручная подчистка работы, не переданной от основной системы резервной, или же эта работа просто теряется.
4.3 Еще раз про абстракцию
Итак, мы познакомились с базовой моделью отказоустойчивости и возможностью ее применения в нескольких разных системах. В первых двух примерах подверженным отказам компонентом являлся процессор, работающий в той же стойке, что и его резервный партнер. Тесная близость этих компонентов допускает практическое использование синхронного копирования состояния. В примере с доставкой журнала задержка на время передачи является недопустимой на практике, и состояние передается асинхронно. Это приводит к "отказам" механизма отказоустойчивости в центрах данных.
2Установка контрольной точки (checkpoint) – это описанный в [12] метод управления состоянием пары процессов. Два идентичных процесса выполняются на разных процессорах, один из процессов – основной (primary), а второй – резервный (backup). Установка контрольной точки состоит в посылке от основного процесса резервному сообщения, которое описывает состояние, требуемое для отказоустойчивого функционирования.
Назад Содержание Вперёд



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС