Дом на песке
Пэт Хелланд, Дейв Кэмпбел
Перевод: Сергей Кузнецов
Оригинал: Pat Helland, Dave Campbell. Building on Quicksand. Proceedings of the Fourth Biennial Conference on Innovative Data Systems Research (CIDR 2009), January 4-7, 2009, Asilomar, Pacific Grove, CA USA
Содержание
- От переводчика, или Ежели где чего убудет, то в другом месте это всяко присовокупится
- Аннотация
- 1. Введение
- 2. Абстракция отказоустойчивости
- Аннотация
- 3. Сохранение прозрачности при разрастании системы
- 4. Медленное наступление асинхронности
- 5. Ослабление абстракции
- 5.1 Асинхронность и истинность
- 5.2 Вероятностные бизнес-правила
- 5.3 Коммутативность и бизнес-правила
- 5.4 Идемпотентность и разделяемые потоки работ
- 5.5 Насколько вы склонны к риску?
- 5.6 Волнения и жалобы (но не слишком частые)
- 5.7 Запоминания, предположения и извинения
- 5.8 Синхронные контрольные точки ИЛИ извинения!
- 5.2 Вероятностные бизнес-правила
- 5.1 Асинхронность и истинность
- 6. Дзэн и искусство согласованности "рано или поздно"4
- 7. Управление ресурсами с применением асинхронности
- 8. CAP и ACID2.0
- 9. Предстоящая работа
- 10. Заключение
- 11. Благодарности
- 12. Литература
- 10. Заключение
От переводчика, или
Ежели где чего убудет, то в другом месте это всяко присовокупится
На самом деле, в контексте этой статьи нужно было бы толковать закон Ломоносова-Лавуазье с точностью до наоборот: "ежели где чего присовокупится, то в другом месте это всяко убудет", поскольку основной смысл статьи (как я его понимаю) состоит в том, что, в соответствии с теоремой CAP Эрика Брювера (Eric Brewer) [13], в одной и той же системе нельзя одновременно поддерживать свойства согласованности, доступности и распределенности. Притом, что для многих современных приложений на первом месте стоят требования доступности и распределенности, для них приходится жертвовать согласованностью (в понимании ACID-транзакционности).
Мне кажется, что в силу интуитивной доходчивости упомянутого закона этот факт сам по себе вполне воспринимается широкими кругами компьютерной общественности, но гораздо менее понятным вопросом является то, какие же распределенные и высоко доступные приложения приложения можно строить на основе систем управления данными, не поддерживающих ACID-транзакционность. И хотя бы частичный ответ на этот вопрос дает статья Хелланда и Кэмпбелла. Грубо говоря, этот ответ можно сформулировать следующим образом: отсутствие ACID-транзакционности почти всегда повышает риск того, что в некоторых ситуациях приложение не оправдает ожидания своих пользователей.
Но, с другой стороны, почти всегда такой риск имеется и при поддержке ACID-транзакционности. Любой бизнес должен быть готов к тому, что клиентам придется принести извинения. Дело разработчиков приложения – соразмерить преимущества, которые получат бизнес и его клиенты из-за повышенной доступности соответствующих услуг, и риски, возникающие из-за отсутствия ACID-транзакционности. В ряде ситуаций (и авторы приводят их примеры) эти новые риски вполне допустимы.
Отчасти статья помогает разобраться с той заменой ACID-транзакционности, которая обозначается модным в последнее время термином eventual consistency (согласованность "рано или поздно"). Наверное, наиболее важно то, что это понятие возникло не вчера и даже не позавчера. По всей видимости, его ввел в обиход Эндрю Таненбаум (Andrew Tanenbaum), и о нем говорилось уже в изданной в 1995 г. книге Distributed Operating Systems (Prentice Hall, Englewood Cliffs, N.J., 1995). Просто теперь (в особенности, в связи с появлением "облачных вычислений" (cloud computing)) распределенность и доступность приложений стали настолько востребованными, что практически необходимо применять ослабленные модели транзакционности и согласованности.
Кстати, интересно, что и сама статья Хелланда и Кэмпбелла написана в очень неформальном, "ослабленном" стиле, вообще говоря, не свойственном большинству статей и книг, посвященных проблемам управления классическими транзакциями. Возможно, это связано с личными предпочтениями авторов, а может быть, ослабление требований к предмету исследований влечет ослабление требований к изложению результатов этих исследований. В любом случае, должен сказать, что мне этот "ослабленный" стиль не очень по душе, и я прошу прощения читателей за его сохранение в переводе (в любом бизнесе возможны извинения!). Но надеюсь, что фактическая содержательность статьи перевешивает возможные недостатки изложения.
Аннотация
Надежные системы всегда основывались на ненадежных компонентах [1]. Раньше компоненты были небольшими, такими как "зеркальные" диски (mirrored disk) или основная память с поддержкой кодов, исправляющих ошибки (Error Correcting Codes, ECC). Тогда системы разрабатывались таким образом, чтобы сбои этих небольших компонентов оставались незаметными для приложений. Потом размер ненадежных компонентов стал увеличиваться, и приложениям пришлось столкнуться с семантическимим проблемами, возникающими в результате сбоев этих компонентов.
Отказоустойчивые алгоритмы состоят из набора идемпотентных подалгоритмов. Эти идемпотентные подалгоритмы пересылают один другому состояние на границах отказов ненадежных компонентов. Тогда можно обеспечить устойчивость системы к отказу ненадежного компонента за счет перехвата управления резервным компонентом, в котором используется последнее известное состояние, и продвижение вперед происходит с помощью повторного выполнения соответствующего идемпотентного подалгоритма. Классически это делалось линейным, пошаговым образом.
По мере увеличения размеров ненадежных компонентов (от масштаба зеркального диска до масштаба системы или даже центра данных) задержки, требуемые для восстановления их состояния, становятся неприемлемыми. Это приводит к потребности в ослабленной модели отказоустойчивости. В этой модели основная система подтверждает получение заявки на выполнение работы и выполнение соответствующих действий, не дожидаясь оповещения резервной системы. В результате повышается реактивность системы, поскольку пользователи не ощущают замедления работы из-за взаимодействия основной системы с резервной.
Асинхронная поддержка состояния системы подразумевает следующее.
- Все обязательства основной системы являются вероятностными. Всегда имеется ненулевая вероятность того, что вскоре после подтверждения системой некоторого требования пользователя произойдет отказ, в результате которого в резервной системе будет отсутствовать информация о соответствующем обязательстве. Следовательно, ничто не гарантируется!
- Приложения должны обеспечивать согласованность "рано или поздно" (eventual consistency) [20]. Поскольку выполнение работы из-за отказа основной системы может застопориться и возобновиться позже, порядок выполнения работ не может гарантироваться.
Разработчики платформ, основанных на этой модели, стараются облегчить жизнь разработчикам приложений. Появляющиеся паттерны согласованности "рано или позно" и вероятностного выполнения скоро смогут предоставить разработчикам приложений способ представления требований к "ослабленной" согласованности, обеспечивая при этом доступность приложений даже при возникновении крупных сбоев. В статье также демонстрируется, что эти паттерны применимы и к периодически связываемым приложениям.
В статье описываются этапы развития этих тенденций, демонстрируются соответствующие паттерны и обсуждаются направления дальнейших исследований в области "строительства на песке".
1. Введение
Имеется интересная связь между отказоустойчивостью, возможностью систем работать в автономном режиме (offlineable system) и согласованностью "рано или поздно" на основе приложений. Когда мы пытаемся выполнять крупномасштабное приложение, опирающееся на использование многих систем, мы не можем допустить задержки из-за ожидания синхронизации резервной системы с системой, действительно выполняющей работу. Это приводит к тому, что серверные системы становятся похожими на автономные клиентские приложения, поскольку им неизвестно истинное положение вещей. В свою очередь, эти основанные на использовании серверов приложения разрабатываются таким образом, что их намерения регистрируются, и работа разделяется между репликами. В правильно разработанном приложении это приводит к поведению системы, приемлемому для бизнеса, но при этом устойчивому к возрастающему числу отказов.
Эта статья начинается с анализа понятий отказоустойчивости. Вводится абстракция отказоустойчивой системы. В разд. 3 обсуждается, каким образом отказоустойчивые системы ранее обеспечивали возможность выживания приложений после отказов без каких-либо специальных действий со стороны приложений за счет синхронной установки контрольных точек, когда состояние приложения передавалось резервной системе. В разд. 4 мы начинаем рассматривать, что произойдет, если мы не сможем допустить наличие задержек, связанных с синхронной установкой контрольных точек с передачей состояния резервной системе, а вместо этого сделаем операцию установки контрольной точки асинхронной. В разд. 5 более глубоко обсуждаются способы модификации приложений с сохранением их семантики, так что допускается асихронная установка контрольных точек с пересылкой состояния приложения резервной копии. В разд. 6 приводится несколько примеров приложений, демонстрирующих корректное поведение, при котором допускаются откладывание (т.е. асинхронность) при установке контрольных точек с резервной системой. В разд. 7 обсуждается управление ресурсами в ситуации, когда порядок операций может изменяться по причине асинхронности. В разд. 8 изучается связь между этой разновидностью согласованости "рано или поздно" и теорией CAP (Consistency, Availability, and Partition-tolerance – согласованность, доступность и устойчивость к разделению). Наконец, в разд. 9 мы рассматриваем некоторые направления будущих исследований.
2. Абстракция отказоустойчивости
В этом разделе мы обсуждаем общие идеи, на которых основывается построение отказоустойчивых систем. Мы начнем с описания внешнего поведения рассматриваемых систем. Затем описывается, что означают обеспечение этими системами прозрачности отказоустойчивости и отсутствие специальных требований к поведению приложений в случае сбоя. После этого мы кратко рассмотрим проблемы, связанные с масштабируемостью таких систем. В заключение раздела мы кратко обсудим роль транзакций при формировании этих отказоустойчивых систем.
2.1 Моделирование "системы"
При анализе взаимодействий с отказоустойчивой "системой" нам желательно рассматривать ее поведение в виде "черного ящка". В систему извне посылаются запросы для обработки. В прошлом эти запросы вводились пользователями с их терминалов и передавались в систему в блочном режиме. Теперь они обычно принимают форму XML, SOAP и других запросов в стиле Web.
Для обеспечения надежности эти исходящие запросы повторяются своим источником. В классическом режиме подается запрос, и если в течение установленного промежутка времени от системы не поступает ответ, то этот запрос подается повторно. Отказоустойчивая серверная система должна сделать обработку запросов пользователя идемпотентной, поскольку иначе повторяющиеся запросы временами приводили бы к повторению уже выполненной работы. На практике системы становятся идемпотентными постепенно, по мере того так разработчики начинают осознавать суть проблемы и вносят в систему соответствующие изменения.
Для поддержки этой потребности в идемпотентности либо каждый запрос сопровождается некоторым уникальным идентификатором ("uniquifier"), обеспечивающим запросам уникальность (и позволяющим связать с исходным запросом все его повторения), ЛИБО для обеспечения того же эффекта применяется какая-нибудь хитрость на стороне сервера. Примером такой хитрости является хэширование всего исходного запроса по алгоритму MD5. С исключительно высокой вероятностью значение полученной свертки будет соответствовать одному и только одному исходному запросу.
Итак, отказоустойчивая система обрабатывает последовательность запросов, поступающих от внешнего партнера. Запросы (и ответы на них) служат для решения одной или нескольких бизнес-задач.
2.2 Прозрачная отказоустойчивость
Отказоустойчивые системы состоят из многих компонентов, и целью разработки такой системы является поддержка продолжения ее функционирования при отказе одного компонента (а иногда и нескольких компонентов). В этом обсуждении мы не касаемся "византийских отказов" [6], когда некоторый компонент может вести себя ошибочным образом (а в задаче византийских генералов – потенциально злоумышленно). Здесь имеется в виду "быстрое проявление сбоев" ("fail fast") [8], когда компонент либо функционирует корректно, либо просто перестает работать В сценариях быстрого выявления сбоев не учитывается возможность неправильно работающих компонентов. Кроме того, не ставится вопрос о том, что случится, если какой-либо компонент станет работать настолько медленно, что посеет хаос в системе. В этом обсуждении мы будем обсуждать проблемы, возникающие даже при упрощающих предположениях о быстром проявлении сбоев.
Мы обнаружили, что в ряде случаев отказоустойчивый алгоритм разбивается на идемпотентные подалгоритмы (рис. 1). Собирая достаточную информацию между идемпотентными шагами и посылая ее на границах отказов, алгоритм в целом может сохранить рабоспособность системы в случае отказов ее компонентов.
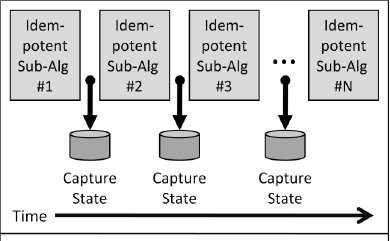
Рис. 1. Разбиение отказоустойчивого алгоритма на несколько подалгоритмов, каждый из которых является идемпотентным. За счет фиксации состояния подалгоритмов и обеспечения доступа к нему после сбоев основной алгоритм выдерживает отказы.
Это напоминает переправу через реку вброд, когда человек шагает с одного камня на другой, всегда удерживая одну ногу на надежной опоре. Важно добиться такой линейной последовательности шагов, которая привела бы, в конце концов, на другой берег реки (т.е. позволила бы выполнить требуемую работу).
Оказывается, во многих отказоустойчивых системах именно этот метод используется, чтобы сделать отказы прозрачными для приложений и пользователей. Мы рассмотрим некоторые примеры таких систем.
2.3 Масштабирование и идемпотентные алгоритмы
В работе [15] один из авторов (Хелланд) утверждает, что особого внимания заслуживают масштабируемые и распределенные приложения, создаваемые без использования распределенных транзакций. Распределенные транзакции (в особенности те, в которых используется двухфазный протокол фиксации [3]) делают системы нестабильными и снижают их уровень доступности. По этой причине они редко применяются в производственных системах, особенно в тех случаях, когда мененджеры ресурсов выходят за границы доверия и полномочности. В упомянутой выше статье предлагается, чтобы в масштабируемых приложениях всегда применялась некоторая дисциплина разделения данных на порции (чанки, chunk), которые всегда остаются в одном узле, даже если происходит переразделение данных. У каждого чанка имеется уникальный ключ.
При разработке отказоустойчивых систем идемотентные подалгоритмы часто рассеиваются распределенным образом по сети. В одном из наблюдаемых паттернов размещение всех этих идемпотентных подалгоритмов следует подобной дисциплине. Данные и поведение компонентов системы, управляемых такими подалгоритмами, сосредотачиваются в единственном узле, даже если требуется переразделение. Совокупные данные каждого подалгоритма идентифицируются некоторым уникальным идентификатором (называемым в [15] "ключом"), что обеспечивает возможность их сохранения в каждый момент времени в точности в одном узле1.
2.4 Транзакции и идемпотентность
Транзакции ОБЛЕГЧАЮТ построение идемпотентных подалгоритмов. Атомарные транзакции... атомарны и не раскрывают частичные результаты. За счет использования транзакций снимаются многие (но не все) проблемы обеспечения идемпотентного поведения. Остается всего лишь обеспечить либо чтобы выполнение одной работы никогда не производилось более одного раза, либо чтобы при второй попытке выявлялось наличие первой успешной попытки, и никакие действия не производились. Некоторые примеры будут приведены позже.
1Более точно, данные содержатся в точности на одном узле, если мы игнорируем потребность в репликации на уровне ниже уровня разделения... более подробно об этом см. ниже.