2008 г.
Базы данных. Вводный курс
Сергей Кузнецов
Назад Содержание Вперёд
2.4. Неформальное введение в реляционную модель данных
Как уже говорилось в начале этой лекции, основные
идеи реляционной модели данных были предложены Эдгаром Коддом в 1969
г. [2.1]. Следует заметить, что, несмотря на общепризнанную значимость
этой и последующих работ Кодда, посвященных реляционной модели
данных, эти работы писались на идейном уровне, не были (по
теперешним меркам) глубоко технически проработанными, во многих
важных местах допускали неоднозначное толкование, и поэтому эти
работы невозможно было использовать как непосредственное руководство
для реализации СУБД, поддерживающей реляционную модель.
За прошедшие десятилетия реляционная модель
развивалась в двух направлениях. Первое направление заложил
знаменитый экспериментальный проект компании IBM
System
R
(см. лекцию 12). В этом проекте возник язык SQL,
изначально основанный на идеях Кодда (который также работал в IBM),
но нарушающий некоторые принципиальные предписания реляционной
модели. К настоящему времени в действующем стандарте языка SQL,
по сути, специфицирована некоторая собственная, законченная модель
данных, обзор
которой мы приведем в следующем разделе этой лекции, а более
подробно обсудим в лекциях 15-23.
Второе направление, начиная с 1990-х гг.,
возглавляет Кристофер Дейт, к которому позже примкнул Хью Дарвен.
Оба этих ученых также работали в компании IBM
и до 1990-х гг. внесли большой вклад в развитие языка SQL.
Однако в 1990-е гг. Дейт и Дарвен пришли к выводу, что искажения
реляционной модели данных, свойственные языку SQL,
достигли настолько высокого уровня, что пришло время предложить
альтернативу, опирающуюся на неискаженные идеи Эдгара Кодда и
обеспечивающую все возможности как SQL,
так и объектно-ориентированного подхода к организации баз данных и
СУБД (обзор
объектно-ориентированной модели данных приводится в следующем
разделе).
Новые идеи Дейта и Дарвена были впервые изложены в
их Третьем манифесте [2.8],
а позже на основе этих идей была специфицирована модель данных [1.5].
Авторы считают, что в [1.5], на самом деле, приводится всего лишь
современная и полная интерпретация идей Кодда. С этим можно
соглашаться или спорить, но бесспорен один факт – Кодд не
участвовал в написании этих материалов и никогда не писал ничего
подобного. В следующих лекциях, тем не менее, при обсуждении
реляционной модели мы будем использовать, в основном, интерпретацию
Дейта и Дарвена.
В этой же лекции мы сначала приведем в данном
разделе краткий и неформальный обзор основных идей реляционной
модели в том виде, в котором она была предложена Коддом, а в
следующем разделе также кратко и
неформально обсудим предложения Дейта и Дарвена. Более строгое и
формальное описание реляционной модели данных приводится в лекциях
3-6.
2.4.1. Реляционные структуры данных
Основная идея Кодда состояла в том, чтобы выбрать в
качестве родовой логической структуры хранения данных структуру,
которая, с одной стороны, была бы достаточно удобной для большинства
приложений и, с другой стороны, допускала бы возможность выполнения
над базой данных ненавигационных операций. Иерархические и, в
особенности, сетевые структуры данных являются навигационными по
своей природе. Ненавигационному использованию таблиц мешает
упорядоченность их столбцов и, в особенности, строк.
По сути, Кодд предложил использовать в качестве
родовой структуры БД «таблицы», в которых и столбцы, и
строки не являются упорядоченными. Легко видеть, что такая «таблица»
со множеством столбцов {A1,
A2,
…, An},
в которой каждый столбец Ai
может содержать значения из
множества Ti
= {vi1,
vi2,
…, vim}
(все множества конечны), в математическом
смысле представляет собой отношение над множествами {T1,
T2,
…, Tn}.
Напомню, что в математике отношением над множествами {T1,
T2,
…, Tn}
называется подмножество декартова
произведения этих множеств, т.е. некоторое множество кортежей {{v1,
v2,
…, vn}},
где vi

Ti.
Поэтому для обозначения родовой структуры Кодд стал использовать
термин отношение (relation),
а для обозначения элементов отношения – термин кортеж.
Соответственно, модель данных получила название реляционной
модели.
Схема БД в реляционной модели данных – это
набор именованных заголовков отношений
вида Hi
= {<Ai1,
Ti1>,
< Ai2,
Ti2>,
…, <
Aini,
Tini>}.
Ti
называется доменом атрибута
Ai.
По Кодду, каждый домен Ti
является подмножеством значений некоторого базового типа данных Ti+,
а значит, к его элементам применимы все операции этого базового типа
(в конце 1960-х гг. базовыми типами данных считались типы данных
распространенных тогда языков программирования; в IBM
наиболее популярными языками были PL1
и COBOL).
Реляционная база данных в каждый момент времени
представляет собой набор именованных отношений, каждое из которых
обладает заголовком, таким как он определен в схеме БД, и телом. Имя
отношения Ri
совпадает с именем заголовка
этого отношения HRi.
Тело отношения BRi
– это множество кортежей вида {<Ai1,
Ti1,
vi1>,
< Ai2,
Ti2,
vi2>,
…, <
Aini,
Tini,
vini>},
где tijTij2).
Во время жизни БД тела отношений могут изменяться, но все
содержащиеся в них кортежи должны соответствовать заголовкам
соответствующих отношений.
2.4.2. Манипулирование реляционными данными
Поскольку в реляционной модели данных заголовок и
тело любого отношения представляют собой множества, к отношениям,
вообще говоря, применимы обычные теоретико-множественные операции:
объединение, пересечение, вычитание, взятие декартова произведения.
Напомним, что для двух множеств S1
{s1}
и S2
{s2}
результатом операции объединения этих
двух множеств S1
UNION
S2
является множество S{s}
такое, что s
S1
или s
S2.
Результатом операции пересечения S1
INTERSECT
S2
является множество S{s}
такое, что s
S1
и s
S2.
Результатом операции вычитания S1
MINUS
S2
является множество S{s}
такое, что s
S1
и s

S23).
На рис. 2.4 эти операции проиллюстрированы в интуитивной графической
форме. Про операцию взятия декартова произведения уже говорилось
выше.
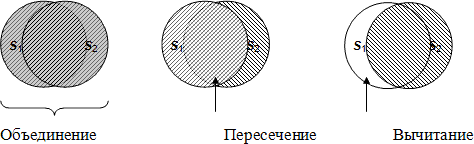
Рис. 2.4. Иллюстрация результатов теоретико-множественных операций
Понятно, что эти операции применимы к любым телам
отношений, но результатом не будет являться отношение, если у
отношений-операндов не совпадают заголовки. Кодд предложил в
качестве средства манипулирования реляционными базами данных
специальный набор операций, которые гарантированно производят
отношения. Этот набор операций принято называть реляционной
алгеброй Кодда, хотя он и не является
алгеброй в
математическом смысле этого термина, поскольку некоторые бинарные
операции этого набора применимы не к произвольным парам отношений.
В алгебре Кодда имеется деcять
операций: объединение (UNION),
пересечение (INTERSECT),
вычитание (MINUS),
взятие расширенного декартова произведения (TIMES),
переименование атрибутов (RENAME),
проекция (PROJECT),
ограничение (WHERE),
соединение (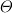
-JOIN),
деление (DIVIDE
BY)
и присваивание. Если не вдаваться в некоторые тонкости, которые мы
рассмотрим в лекции 4, то почти все операции предложенного выше
набора обладают очевидной и простой интерпретацией.
- При выполнении операции объединения
(
UNION)
двух отношений с одинаковыми заголовками производится отношение,
включающее все кортежи, входящие хотя бы в одно из
отношений-операндов.
- Операция пересечения
(
INTERSECT)
двух отношений с одинаковыми заголовками производит отношение,
включающее все кортежи, входящие в оба отношения-операнда.
- Отношение, являющееся разностью
(
MINUS)
двух отношений с одинаковыми заголовками, включает все кортежи,
входящие в отношение-первый операнд, такие, что ни один из них не
входит в отношение, являющееся вторым операндом.
- При выполнении декартова
произведения (
TIMES)
двух отношений, пересечение заголовков которых пусто, производится
отношение, кортежи которого производятся путем объединения кортежей
первого и второго операндов.
- Операция переименования
(
RENAME)
производит отношение, тело которого совпадает с телом операнда, но
имена атрибутов изменены; эта операция позволяет выполнять первые
три операции над отношениями с «почти» совпадающими
заголовками (совпадающими во всем, кроме имен атрибутов) и выполнять
операцию TIMES
над отношениями, пересечение заголовков которых не является пустым. -
Результатом ограничения
(
WHERE)
отношения по некоторому условию является отношение, включающее
кортежи отношения-операнда, удовлетворяющее этому условию.
- При выполнении проекции
(
PROJECT)
отношения на заданное подмножество множества его атрибутов
производится отношение, кортежи которого являются соответствующими
подмножествами кортежей отношения-операнда.
- При
-соединении
(-JOIN)
двух отношений по некоторому условию ()
образуется результирующее отношение,
кортежи которого производятся путем объединения кортежей первого и
второго отношений и удовлетворяют этому условию.
- У операции реляционного
деления (
DIVIDE
BY)
два операнда – бинарное и унарное отношения. Результирующее
отношение состоит из унарных кортежей, включающих значения первого
атрибута кортежей первого операнда таких, что множество значений
второго атрибута (при фиксированном значении первого атрибута)
включает множество значений второго операнда.
- Операция присваивания
(
:=)
позволяет сохранить результат вычисления реляционного выражения в
существующем отношении БД.
2.4.3. Целостность в реляционной модели данных
Кодд предложил два декларативных механизма
поддержки целостности реляционных баз данных, которые затверждены в
реляционной модели данных и должны поддерживаться в любой
реализующей ее СУБД: ограничение целостности
сущности, или ограничение
первичного ключа и ограничение
ссылочной целостности, или ограничение
внешнего ключа. Мы снова оставим подробности
и формализмы на лекцию 3 и приведем здесь только изложение общих
идей.
Ограничение целостности сущности звучит
следующим образом: для заголовка любого отношения базы данных должен
быть явно или неявно определен первичный
ключ, являющийся таким минимальным
подмножеством заголовка отношения, что в любом теле этого отношения,
которое может появиться в базе данных, значение первичного ключа в
любом кортеже этого тела является уникальным, т.е. отличается от
значения первичного ключа в любом другом кортеже. Под минимальностью
первичного ключа понимается то, что если из множества атрибутов
первичного ключа удалить хотя бы один атрибут, то ограничение
целостности изменится, т.е. в БД смогут появляться тела отношений,
которые не допускались исходным первичным ключом.
Если первичный ключ не объявляется явно, то в
качестве первичного ключа отношения принимается весь его заголовок.
Понятно, что поскольку по определению любое тело отношения с
заданным заголовком является множеством, следовательно, в нем
отсутствуют дубликаты, и первичный ключ, совпадающий с заголовком
отношения, всегда обладает свойством уникальности. Должно быть
понятно, что в этом случае определение первичного ключа не задает
никакого ограничения целостности.
Чтобы пояснить смысл ограничения
ссылочной целостности, нужно сначала ввести
понятие внешнего ключа.
В принципе при использовании реляционной модели данных можно хранить
все данные, соответствующие предметной области в одной таблице.
Пример такой базы данных демонстрировался в лекции 1 на рис. 1.6
, где в одном файле (интуитивном аналоге
отношения) хранилась информация и о служащих, и об отделах, в
которых они работают. Как было показано в лекции 1, такой подход
приводит к избыточности хранения (данные об отделе повторяются в
каждой записи о служащем этого отдела) и усложняет выполнение
некоторых операций.
На рис.
1.7
для хранения информации о служащих и отделах использовалось два
файла, в одном из которых хранились данные, индивидуальные для
каждого служащего, а во втором – данные об отделах. Для
возможности получения полной информации о служащих и отделах, в
которых они работают, в файле СЛУЖАЩИЕ
содержалось поле СЛУ_ОТД_НОМЕР,
содержащее для каждого служащего его уникальный номер отдела. В то
же время, в файле ОТДЕЛЫ
имелось поле ОТД_НОМЕР,
являющееся уникальным ключом этого файла. На самом деле, введя файлы
СЛУЖАЩИЕ
и ОТДЕЛЫ,
а также обеспечив связь между ними с помощью полей СЛУ_ОТД_НОМЕР
и ОТД_НОМЕР,
мы смогли обеспечить табличное представление иерархии
ОТДЕЛ-СЛУЖАЩИЕ.
Если говорить в терминах реляционной модели данных, то в отношении
ОТДЕЛЫ
поле ОТД_НОМЕР
является первичным
ключом, а в
отношении СЛУЖАЩИЕ
поле СЛУ_ОТД_НОМЕР
является внешним
ключом,
ссылающимся на отношение ОТДЕЛЫ.
Более точно, внешним ключом
отношения R1,
ссылающимся на отношение
R2,
называется подмножество заголовка HR1,
которое совпадает с первичным ключом отношения R2
(с точностью до имен атрибутов). Тогда ограничение
ссылочной целостности реляционной модели
данных можно сформулировать следующим образом: в любом теле
отношения R1,
которое может появиться в базе данных, для «не пустого»4)
значения внешнего ключа, ссылающегося на
отношение R2,
в любом кортеже этого тела должен найтись кортеж в теле отношения
R2,
которое содержится в базе данных, с совпадающим значением первичного
ключа. Легко заметить, что это почти то же самое ограничение, о
котором говорилось в подразделе 2.3.2. Иерархическая модель данных:
никакой потомок не может существовать без своего родителя,
но немного уточненное – ссылки на
родителя должны быть корректными.
2 Обозначение s
S
означает, что элемент s
принадлежит множеству S.



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС