Базы данных. Вводный курс
Сергей КузнецовЛекция 2. Понятие модели данных. Обзор разновидностей моделей данных
2.1. Введение
Историю технологии БД принято отсчитывать с начала 1960-х гг., когда появились первые попытки создания специальных программных средств управления базами данных. За прошедшие десятилетия возникали и использовались различные подходы к организации баз данных. Для описания и сравнения некоторых из них мы воспользуемся понятием модели данных, предложенным в 1969 г. Эдгаром Коддом [2.1]. Кодд ввел это понятие для описания конкретного реляционного подхода к организации БД. Соответственно, он говорил о реляционной модели данных, различным теоретическим и реализационным аспектам которой в основном посвящен этот курс. Однако понятие модели данных оказалось удобным не только для описания реляционного подхода и сравнения реализаций реляционных СУБД, но и для реализационно-независимого представления и сопоставления других подходов к организации баз данных.
2.2. Модель данных
В модели данных описывается некоторый набор родовых понятий и признаков, которыми должны обладать все конкретные СУБД и управляемые ими базы данных, если они основываются на этой модели. Наличие модели данных позволяет сравнивать конкретные реализации, используя один общий язык.
Хотя понятие модели данных было введено Коддом, наиболее распространенная трактовка модели данных, по-видимому, принадлежит Кристоферу Дейту, который воспроизводит ее (с различными уточнениями) применительно к реляционным БД практически во всех своих книгах (см., например, [1.3]). Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
В структурной части модели данных фиксируются основные логические структуры данных, которые могут применяться на уровне пользователя при организации БД, соответствующих данной модели. Например, в модели данных SQL основным видом структур базы данных являются таблицы, а в объектной модели данных – объекты ранее определенных типов.
Манипуляционная часть модели данных содержит спецификацию одного или нескольких языков, предназначенных для написания запросов к БД. Эти языки могут быть абстрактными, не обладающими точно проработанным синтаксисом (что свойственно языками реляционной алгебры и реляционного исчисления, используемым в реляционной модели данных), или законченными производственными языками (как в случае модели данных SQL). Основное назначение манипуляционной части модели данных – обеспечить эталонный «модельный» язык БД, уровень выразительности которого должен поддерживаться в реализациях СУБД, соответствующих данной модели.
Наконец, в целостной части модели данных (которая явно выделяется не во всех известных моделях) специфицируются механизмы ограничений целостности, которые обязательно должны поддерживаться во всех реализациях СУБД, соответствующих данной модели. Например, в целостной части реляционной модели данных категорически требуется поддержка ограничения первичного ключа в любой переменной отношения, а аналогичное требование к таблицам в модели данных SQL отсутствует.
В этой лекции мы применим понятие модели данных для обзора как подходов, предшествовавших появлению реляционных баз данных, так и подходов, которые возникли позже. Мы не будем касаться особенностей каких-либо конкретных систем; это привело бы к изложению многих технических деталей, которые, хотя и интересны, но находятся несколько в стороне от основной цели курса.
2.3. Ранние модели данных
Начнем с рассмотрения общих подходов к организации трех типов ранних систем, а именно, систем, основанных на инвертированных списках, иерархических и сетевых систем управления базами данных. В целом ранние системы можно охарактеризовать следующим образом1):
- Эти системы активно использовались в течение многих лет, задолго до появления работоспособных реляционных СУБД. На самом деле некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование этих систем совместно с современными.
- Все ранние системы не основывались на каких-либо абстрактных моделях. Как мы упоминали, понятие модели данных фактически вошло в обиход специалистов в области БД только вместе с реляционным подходом. Абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков у различных конкретных систем.
- В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путем создания соответствующих прикладных программ с собственным интерфейсом.
- Можно считать, что уровень средств ранних СУБД соотносится с уровнем файловых систем примерно так же, как уровень языка Cobol соотносится с уровнем языков ассемблера. Заметим, что при таком взгляде уровень реляционных систем соответствует уровню языков Ада или APL.
- Навигационная природа ранних систем и доступ к данным на уровне записей заставляли пользователей самих производить всю оптимизацию доступа к БД, без какой-либо поддержки системы.
- После появления реляционных систем большинство ранних систем было оснащено «реляционными» интерфейсами. Однако в большинстве случаев это не сделало их по-настоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме.
2.3.1. Модель данных инвертированных таблиц
К числу наиболее известных и типичных представителей систем, в основе которых лежит эта модель данных, относятся СУБД Datacom/DB, выведенная на рынок в конце 1960-х гг. компанией Applied Data Research, Inc. (ADR) и принадлежащая в настоящее время компании Computer Associates, и Adabas (ADAptable DAtabase System), которая была разработана компанией Software AG в 1971 г. и до сих пор является ее основным продуктом.
Организация доступа к данным на основе инвертированных таблиц используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным таблицам (индексам). Кстати, когда мы будем рассматривать внутренние интерфейсы реляционных СУБД, можно будет увидеть, что они очень близки к пользовательским интерфейсам систем, основанных на инвертированных таблицах.
Структуры данных
База данных в модели инвертированных таблиц похожа на БД в модели SQL, но с тем отличием, что пользователям видны и хранимые таблицы, и пути доступа к ним. При этом:
- Строки таблиц упорядочиваются системой в некоторой физической, видимой пользователям последовательности.
- Физическая упорядоченность строк всех таблиц может определяться и для всей БД (так делается, например, в Datacom/DB).
- Для каждой таблицы можно определить произвольное число ключей поиска, для которых строятся индексы. Эти индексы автоматически поддерживаются системой, но явно видны пользователям.
Манипулирование данными
Поддерживаются два класса операций:
- Операции, устанавливающие адрес записи и
разбиваемые на два подкласса:
- прямые поисковые операторы (например, установить адрес первой записи таблицы по некоторому пути доступа);
- операторы, устанавливающие адрес записи при указании относительной позиции от предыдущей записи по некоторому пути доступа.
- Операции над адресуемыми записями.
Вот типичный набор операций:
LOCATE FIRST– найти первую запись таблицыTв физическом порядке; возвращается адрес записи;LOCATE FIRST WITH SEARCH KEY EQUAL– найти первую запись таблицыTс заданным значением ключа поискаk; возвращается адрес записи;LOCATE NEXT– найти первую запись, следующую за записью с заданным адресом в заданном пути доступа; возвращается адрес записи;LOCATE NEXT WITH SEARCH KEY EQUAL– найти cледующую запись таблицыTв порядке пути поиска с заданным значениемk; должно быть соответствие между используемым способом сканирования и ключомk; возвращается адрес записи;LOCATE FIRST WITH SEARCH KEY GREATER– найти первую запись таблицыTв порядке ключа поискаkcо значением ключевого поля, большим заданного значенияk; возвращается адрес записи;RETRIVE– выбрать запись с указанным адресом;UPDATE– обновить запись с указанным адресом;DELETE– удалить запись с указанным адресом;STORE– включить запись в указанную таблицу; операция генерирует и возвращает адрес записи.
Ограничения целостности
Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном вся поддержка целостности данных возлагается на прикладную программу.
2.3.2. Иерархическая модель данных
Типичным представителем (наиболее известным и распространенным) является СУБД IMS (Information Management System) компании IBM. Первая версия системы появилась в 1968 г.
Иерархические структуры данных
Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева. Тип дерева состоит из одного «корневого» типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи.
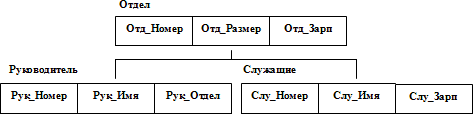
На рис. 2.1 показан пример типа дерева (схемы
иерархической БД). Здесь тип
записи Отдел
является предком для типов записи Руководитель
и Служащие,
а Руководитель
и Служащие
– потомки типа записи Отдел.
Смысл полей типов записей в основном должен быть понятен по их
именам. Поле Рук_Отдел
типа записи Руководитель
содержит номер отдела, в котором работает
служащий, являющийся данным руководителем (предполагается, что он
работает не обязательно в том же отделе, которым руководит). Между
типами записи поддерживаются связи (правильнее сказать, типы
связей, поскольку реальные связи появляются
в экземплярах типа дерева).
База данных с такой схемой могла бы выглядеть так, как показано на рис. 2.2 (мы показываем один экземпляр дерева).
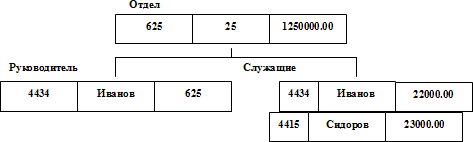
Рис. 2.2. Пример иерархической базы данных
Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для иерархической базы данных определяется полный порядок обхода дерева: сверху-вниз, слева-направо. Заметим, что в терминологии IMS вместо термина запись использовался термин сегмент, а под записью базы данных понималось все дерево сегментов.
Манипулирование данными
Примерами типичных операций манипулирования иерархически организованными данными могут быть следующие:
- найти указанный экземпляр типа дерева БД (например, отдел 310);
- перейти от одного экземпляра типа дерева к другому;
- перейти от экземпляра одного типа записи к экземпляру другого типа записи внутри дерева (например, перейти от отдела к первому сотруднику);
- перейти от одной записи к другой в порядке обхода иерархии;
- вставить новую запись в указанную позицию;
- удалить текущую запись.
Ограничения целостности
В иерархической модели данных автоматически
поддерживается целостность ссылок между предками и потомками.
Основное правило: никакой
потомок не может существовать без своего родителя.
Заметим, что аналогичная поддержка целостности по ссылкам между
записями без связи «предок-потомок», не обеспечивается.
Примером такой «внешней» ссылки является содержимое поля
Рук_Отдел
в экземпляре типа записи Руководитель.
2.3.3. Сетевая модель данных
Типичным представителем систем, основанных на сетевой модели данных, является СУБД IDMS (Integrated Database Management System), разработанная компанией Cullinet Software, Inc. и изначально ориентированная на использования на мейнфреймах компании IBM. Архитектура системы основана на предложениях Data Base Task Group (DBTG) организации CODASYL (COnference on DAta SYstems Languages), которая отвечала за определение языка программирования COBOL. Отчет DBTG был опубликован в 1971 г., и вскоре после этого появилось несколько систем, поддерживающих архитектуру CODASYL, среди которых присутствовала и СУБД IDMS. В настоящее время IDMS принадлежит компании Computer Associates.
Сетевые структуры данных
Сетевой подход к организации данных является расширением иерархического подхода. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных у потомка может иметься любое число предков.
Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи.
Тип связи определяется для двух типов записи:
предка и потомка. Экземпляр типа связи состоит из одного экземпляра
типа записи предка и упорядоченного набора экземпляров типа записи
потомка. Для данного типа связи L
с типом записи предка P
и типом записи потомка C
должны выполняться следующие два условия:
- каждый экземпляр типа записи
Pявляется предком только в одном экземпляре типа связиL; - каждый экземпляр типа записи
Cявляется потомком не более чем в одном экземпляре типа связиL.
На формирование типов связи не накладываются особые ограничения; возможны, например, следующие ситуации:
- тип записи потомка в одном типе связи
L1может быть типом записи предка в другом типе связиL2(как в иерархии); - данный тип записи
Pможет быть типом записи предка в любом числе типов связи; - данный тип записи
Pможет быть типом записи потомка в любом числе типов связи; - может существовать любое число типов связи с одним
и тем же типом записи предка и одним и тем же типом записи потомка;
и если
L1иL2- два типа связи с одним и тем же типом записи предкаPи одним и тем же типом записи потомкаC, то правила, по которым образуется родство, в разных связях могут различаться; -
типы записи
XиYмогут быть предком и потомком в одной связи и потомком и предком – в другой; - предок и потомок могут быть одного типа записи.
На рис. 2.3 показан простой пример схемы сетевой
БД. На этом рисунке показаны три типа записи: Отдел,
Служащие
и Руководитель и
три типа связи: Состоит из
служащих, Имеет
руководителя и Является
служащим. В
типе связи Состоит из
служащих типом записи-предком является
Отдел,
а типом записи-потомком – Служащие
(экземпляр этого типа связи связывает экземпляр типа записи Отдел
со многими экземплярами типа записи
Служащие, соответствующими всем служащим
данного отдела). В типе связи Имеет
руководителя типом записи-предком
является Отдел,
а типом записи-потомком – Руководитель
(экземпляр этого типа связи связывает экземпляр типа записи Отдел
с одним экземпляром типа записи
Руководитель, соответствующим
руководителю данного отдела). Наконец, в типе связи Является
служащим типом записи-предком является
Руководитель,
а типом записи-потомком – Служащие
(экземпляр этого типа связи связывает экземпляр типа записи
Руководитель с
одним экземпляром типа записи
Служащие, соответствующим тому служащему,
которым является данный руководитель).
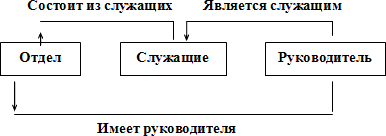
Рис. 2.3. Пример схемы сетевой базы данных
Манипулирование данными
Вот примерный набор операций манипулирования данными:
- найти конкретную запись в наборе однотипных записей (например, служащего с именем Иванов);
- перейти от предка к первому потомку по некоторой связи (например, к первому служащему отдела 625);
- перейти к следующему потомку в некоторой связи (например, от Иванова к Сидорову);
- перейти от потомка к предку по некоторой связи (например, найти отдел, в котором работает Сидоров);
- создать новую запись;
- уничтожить запись;
- модифицировать запись;
- включить в связь;
- исключить из связи;
- переставить в другую связь и т.д.
Ограничения целостности
Имеется (необязательная) возможность потребовать для конкретного типа связи отсутствие потомков, не участвующих ни в одном экземпляре этого типа связи (как в иерархической модели).
1 Заметим, что перечисляемые ниже характеристики в полной мере относятся и к другим не реляционным подходам к организации баз данных, которые возникли до появления реляционного подхода или почти одновременно с ним. В частности, подобными свойствами обладают системы, основанные на подходах MUMPS (наиболее известной в России является реализация этого подхода в СУБД Cache компании Intersystems) и Pick (этот подход реализован во многих СУБД, в частности, в СУБД UniVerse и UniData семейства U2 компании IBM).