Книги: [Классика] [Базы данных] [Internet/WWW] [Сети] [Программирование] [UNIX] [Windows] [Безопасность] [Графика] [Software Engineering] [ERP-системы] [Hardware]
 |
Техника оптимизации
|
Часть 1
Профилировка программ
Профилировкой здесь и на протяжении всей книги мы будем называть измерение производительности как всей программы в целом, так и отдельных ее фрагментов, с целью нахождения "горячих" точек (Hot Spots), — тех участков программы, на выполнение которых расходуется наибольшее количество времени.
Согласно правилу "10/90", десять процентов кода "съедают" девяносто процентов производительности системы (равно как и десять процентов людей выпивают девяносто процентов всего пива). Если время, потраченное на выполнение каждой машинной инструкции, изобразить графически в порядке возрастания их линейных адресов, на полученной диаграмме мы обнаружим несколько высоченных пиков, горделиво возвышающихся над практически пустой равниной, усеянной множеством низеньких холмиков (пример показан далее на рисунке разд. " Практический сеанс профилировки с VTune в десяти шагах") Вот эти самые пики — "горячие" точки и есть.
Почему "температура" различных участков программы столь неодинакова? Причина в том, что подавляющее большинство вычислительных алгоритмов так или иначе сводятся к циклам, — т. е. многократным повторениям одного фрагмента кода, причем зачастую циклы обрабатываются не последовательно, а образуют более или менее глубокие иерархии, организованные по типу "матрешки". В результате, львиную долю всего времени выполнения, программа проводит в циклах с наибольшим уровнем вложения, и именно их оптимизация дает наилучший прирост производительности!
Громоздкие и тормозные, но редко вызываемые функции оптимизировать нет ни какой нужды, — это практически не увеличит быстродействия приложения (ну разве что только в том случае, если они совсем уж будут "криво" написаны).
Когда же алгоритм программы прост, а ее исходный текст свободно умещается в сотню–другую строк, то "горячие" точки нетрудно обнаружить и визуальным просмотром листинга. Но с увеличением объема кода это становится все сложнее и сложнее. В программе, состоящей из тысяч сложно взаимодействующих друг с другом функций (часть из которых это функции внешних библиотек и API — Application Programming Interface, интерфейс прикладного программирования — операционной системы) далеко не так очевидно: какая же именно из них в наибольшей степени ответственна за низкую производительность приложения. Естественный выход — прибегнуть к помощи специализированных программных средств.
Профилировщик (так же называемый "профайлером") — основной инструмент оптимизатора программ. Оптимизация "в слепую" редко дает хороший результат. Помните пословицу "самый медленный верблюд определяет скорость каравана"? Программный код ведет себя полностью аналогичным образом, и производительность приложения определяется самым узким его участком. Бывает, что виновницей оказывается одна–единственная машинная инструкция (например, инструкция деления, многократно выполняющаяся в глубоко вложенном цикле). Программист, затратив воистину титанические усилия на улучшение остального кода, окажется премного удивлен, что производительность приложения едва ли возросла процентов на десять–пятнадцать.
Правило номер один: ликвидация не самых "горячих" точек программы, практически не увеличивает ее быстродействия. Действительно, сколько не подгоняй второго сзади верблюда — от этого караван быстрее идти не будет (случай, когда предпоследней верблюд тормозит последнего — это уже тема другого разговора, требующего глубоких знаний техники профилировки, а потому и не рассматриваемая в настоящей книге).
Цели и задачи профилировки
Основная цель профилировки — исследовать характер поведения приложения во всех его точках. Под "точкой" в зависимости от степени детализации может подразумеваться как отдельная машинная команда, так целая конструкция языка высокого уровня (например: функция, цикл или одна–единственная строка исходного текста).
Большинство современных профилировщиков поддерживают следующий набор базовых операций:
- определение общего времени исполнения каждой точки программы (total [spots] timing);
- определение удельного времени исполнения каждой точки программы ([spots] timing);
- определение причины и/или источника конфликтов и пенальти (penalty information);
- определение количества вызовов той или иной точки программы ([spots] count);
- определение степени покрытия программы ([spots] covering).
Общее время исполнения
Сведения о времени, которое приложение тратит на выполнение каждой точки программы, позволяют выявить его наиболее "горячие" участки. Правда, здесь необходимо сделать одно уточнение. Непосредственный замер покажет, что, по крайней мере, 99,99% всего времени выполнения профилируемая программа проводит внутри функции main, но ведь очевидно, что "горячей" является отнюдь не сама main, а вызываемые ею функции! Чтобы не вызывать у программистов недоумения, профилировщики обычно вычитают время, потраченное на выполнение дочерних функций, из общего времени выполнения каждой функции программы.
Рассмотрим, например, результат профилировки некоторого приложения профилировщиком profile.exe, входящего в комплект поставки компилятора Microsoft Visual C++.
Листинг 1.1. Пример профилировки приложения профилировщиком profile.exe
Func Func+Child Hit
Time % Time % Count Function
---------------------------------------------------------
350,192 95,9 360,982 98,9 10000 _do_pswd (pswd_x.obj)
5,700 1,6 5,700 1,6 10000 _CalculateCRC (pswd_x.obj)
5,090 1,4 10,790 3,0 10000 _CheckCRC (pswd_x.obj)
2,841 0,8 363,824 99,6 1 _gen_pswd (pswd_x.obj)
1,226 0,3 365,148 100,0 1 _main (pswd_x.obj)
0,098 0,0 0,098 0,0 1 _print_dot (pswd_x.obj)
В средней колонке (Func+Child Time) приводится полное время исполнения каждой функции, львиная доля которого принадлежит функции main (ну этого и следовало ожидать), за ней с минимальным отрывом следует gen_pswd со своими 99,6%, далее идет do_pswd — 98,9% и, сильно отставая от нее, где-то там на отшибе плетется CheckCRC, оттягивая на себя всего лишь 3,0%. А функцией CalculateCRC, с ее робким показателем 1,6%, на первый взгляд можно и вовсе пренебречь! Итак, судя по всему, мы имеем три "горячих" точки: main, gen_pswd и do_pswd (рис. 1.1).
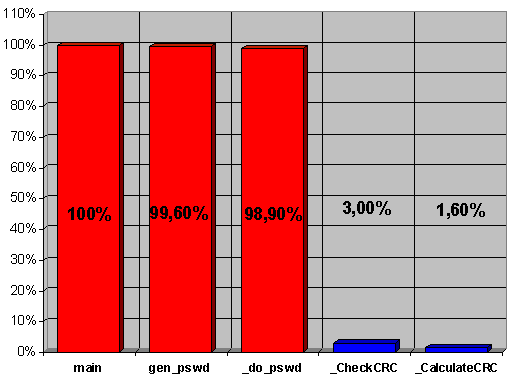
Рис. 1.1. Диаграмма, иллюстрирующая общее время выполнения каждой из функций. На первый взгляд, здесь три "горячих" точки, но на самом деле это не так
Впрочем, функцию main можно откинуть сразу. Она, понятное дело, ни в чем не "виновата". Остаются функции gen_pswd и do_pswd. Если бы это были абсолютно независимые функции, то "горячих" точек было бы и впрямь две, но в нашем случае это не так. И, если из полного времени выполнения функции gen_pswd, вычесть время выполнения ее дочерней функции do_pswd у "матери" останется всего лишь… 0,7%. Да! Меньше процента времени выполнения!
Обратимся к крайней левой колонке (листинг 1.1) таблицы профилировщика (Funct Time), чтобы подтвердить наши предположения. Действительно, в программе присутствует всего лишь одна "горячая" точка — do_pswd, и только ее оптимизация способна существенно увеличить быстродействие приложения (рис. 1.2).
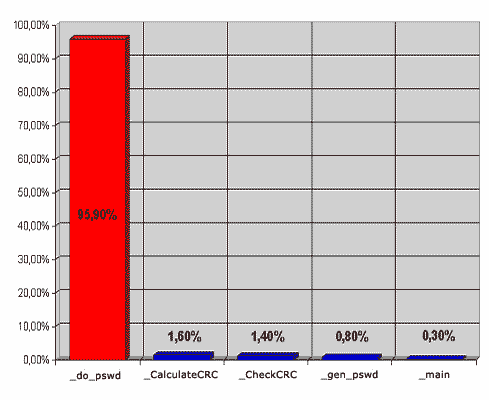
Рис. 1.2. Диаграмма, иллюстрирующая чистое время работы каждой из функций (т.е. с вычетом времени дочерних функций). Как видно, в программе есть одна, но чрезвычайно "горячая" точка
Хорошо, будем считать, что наиболее "горячая" функция определена и теперь мы горим желанием ее оптимизировать. А для этого недурно бы узнать картину распределения "температуры" внутри самой функции. К сожалению, профилировщик profile.exe (и другие подобные ему) не сможет ничем нам помочь, поскольку его разрешающая способность ограничивается именно функциями.
Но, на наше счастье существуют и более "продвинутые" профилировщики, уверенно различающие отдельные строки и даже машинные команды! К таким профилировщикам в частности относится VTune от Intel. Давайте запустим его и заглянем внутрь функции do_pswd (подробнее о технике работы с VTune см. "Практический сеанс профилировки с VTune").
Листинг 1.2. Карта распределения "температуры" внутри функции do_pswd, полученная с помощью профилировщика VTune
| Line | Clock ticks | Source | temperature |
| 105 | 729 | while((++pswd[p])>'z'){e | |
| 106 | 14 | pswd[p] = '!'; | |
| 107 | 1 | y = y | y << 8; | |
| 108 | 2 | x -= k; | |
| 109 | k = k << 8; | ||
| 110 | 3 | k += 0x59; | |
| 111 | 2 | p++; | |
| 112 | 1 | } |
Вот теперь совсем другое дело — сразу видно, что целесообразно оптимизировать, а что и без того уже "вылизано" по самые помидоры. "Горячие" точки главным образом сосредоточены вокруг конструкции pswd[p], — она очень медленно выполняется. Почему? Исходный текст не дает непосредственного ответа на поставленный вопрос и потому совсем не ясно: что конкретно следует сделать для понижения "температуры" "горячих" точек.
Приходится спускаться на уровень "голых" машинных команд (благо профилировщик VTune это позволяет). Вот, например, во что компилятор превратил безобидный на вид оператор присвоения pswd[p] = '!'
Листинг 1.3. Исследование температуры машинных команд внутри конструкции pswd[p] = '!'
| Line | Instructions | Cycles | Count | temperature |
| 107 | mov edx,DWORD PTR [ebp+0ch] | 143 | 11 | |
| 107 | ^ загрузить в регистр EDX указатель pswd | |||
| 107 | add edx, DWORD PTR [ebp-4] | 22 | 11 | |
| 107 | ^ сложить EDX с переменной p | |||
| 107 | mov BYTE PTR [edx], 021h | 33 | 11 | |
| 107 | ^ по полученному смещению записать значение 0х21 ('!') | |||
Смотрите! В одной строке исходного текста происходит целых три обращения к памяти! Сначала указатель pswd загружается в регистр EDX, затем он суммируется с переменной p, которая так же расположена в памяти, и лишь затем по рассчитанному смещению в память благополучно записывается константа '!' (021h).
Тем не менее, все равно остается не ясно, почему загрузка указателя pswd занимает столько времени? Может быть, кто-то постоянно вытесняет указатель pswd из кэша, заставляя процессор обращаться к медленной оперативной памяти? Так ведь нет! Программа работает с небольшим количеством переменных, заведомо умещающихся в кэше второго уровня.
Удельное время выполнения
Если время выполнения некоторой точки программы не постоянно, а варьируется в тех или иных пределах (например, в зависимости от рода обрабатываемых данных), то трактовка результатов профилировки становится неоднозначной, а сам результат — ненадежным. Для более достоверного анализа требуется: а) определить действительно ли в программе присутствуют подобные "плавающие" точки и, если да, то: б) определить время их исполнения в лучшем, худшем и среднем случаях.
Очень немногие профилировщики могут похвастаться способностью определять удельное время выполнения машинных команд (иначе называемое растактовкой). К счастью, профилировщик VTune это умеет! Обратимся к сгенерированному им протоколу динамического анализа. Быть может, он поможет нам разрешить загадку "неповоротливости" загрузки указателя pswd?
Листинг 1.4. Удельное время выполнения машинных команд внутри профилируемого фрагмента программы
| Line | Instructions | Dyn-Retirement | Cycles |
| 107 pswd[p] = '!'; | |||
| 107 | mov edx, DWORD PTR [ebp+0ch] | 13 | |
| 107; | ^ загрузить в регистр EDX указатель pswd | ||
| 107 | add edx,DWORD PTR [ebp-4] | 2 | |
| 107; | ^ сложить регистр EDX с переменной p | ||
| 107 | mov BYTE PTR [edx], 021h | 3 | |
| 107; | ^ записать в *(pswd+p) значение '!' | ||
| 109 y = y | y << 8; | |||
| 109 | mov eax,DWORD PTR [ebp-28] | 2 | |
| 109; | ^ загрузить в регистр EAX переменную y | ||
| 109 | shl eax, 08h | 1 | |
| 109; | ^ сдвинуть EAX на 8 позиций влево | ||
| 109 | mov ecx, DWORD PTR [ebp-28] | (0,7.3,80) | |
| 109; | ^ загрузить в регистр ECX переменную y | ||
| 109 | or ecx, eax | 1 | |
| 109; | ^ ECX = ECX | EAX (tmp = y | y) | ||
| 109 | mov DWORD PTR [ebp-28], ecx | 1 | |
| 109; | ^ записать полученный результат в y | ||
| 110 x -= k; | |||
| 110 | mov edx, DWORD PTR [ebp-24] | 0 | |
| 110; | ^ загрузить в регистр EDX переменную x | ||
| 110 | sub edx, DWORD PTR [ebp-36] | 1 | |
| 110; | ^ вычесть из регистра EDX переменную k | ||
| 110 | mov DWORD PTR [ebp-24], edx | 1 | |
| 110; | ^ записать полученный результат в x | ||
Ну, вот опять, — все команды, как команды, а загрузка указателя pswd "разлеглась" прямо как объевшаяся свинья, "сожравшая" целых тринадцать тактов, в то время как остальные свободно укладываются в один–два такта, а некоторые и вовсе занимают ноль, ухитряясь завершиться одновременно с предыдущей инструкций.
За исключением команды, загружающей содержимое переменной y в регистр ECX, время выполнения всех остальных команд строго постоянно и не меняется от случая к случаю. Наша же "подопечная" в зависимости от еще не выясненных обстоятельств, может "отъедать" даже восемьдесят тактов, что на время делает ее самой "горячей" точкой данного фрагмента программы. Восемьдесят тактов — это вообще полный беспредел! И пускай среднеарифметическое время ее выполнения составляет всего лишь семь тактов, а минимальное — и вовсе ноль, мы не успокоимся пока не выясним: на что и при каких именно обстоятельствах уходит такое количество тактов?
Информация о пенальти
Уже сам факт существования "горячей" точки говорит о том, что в программе что-то неправильно. Хорошо, если это чисто алгоритмическая ошибка, которую видно невооруженным глазом (например, наиболее узким местом приложения оказалась пузырьковая сортировка). Хуже, если процессорное время исчезает буквально на пустом месте без всяких видимых на то причин. Еще хуже, если "хищения" тактов происходят не систематически, а совершаются при строго определенном стечении каких-то неизвестных нам обстоятельств.
Возвратимся к предыдущему вопросу: почему указатель pswd загружается так долго? И при каких именно обстоятельствах загрузка переменной y "подскакивает" со своих обычных семи до восьмидесяти тактов? Судя по всему, процессору что-то не понравилось и он обложил эти две машинные команды "штрафом" (penalty), на время притормозив их исполнение. Можем ли мы узнать, когда и за какой "проступок" это произошло? Не прибегая к полной эмуляции процессора — вряд ли (хотя современные процессоры x86 с некоторыми ограничениями позволяют получить эту информацию и так).
Гранды компьютерной индустрии — Intel и AMD уже давно выпустили свои профилировщики, содержащие полноценные эмуляторы выпускаемых ими процессоров, позволяющие визуализировать нюансы выполнения каждой машинной инструкции.
Просто щелкните по строке mov ecx, DWORD PTR [ebp-28] и профилировщик VTune выдаст всю, имеющуюся у него информацию (листинг 1.5).
Листинг 1.5. Вывод профилировщиком VTune дополнительной информации о выполнении инструкции
decoder minimum clocks = 1 ; МИНИМАЛЬНОЕ ВРЕМЯ ДЕКОДИРОВАНИЯ – 1 ТАКТ
Decoder Average Clocks = 8.7 ; Эффективное время декодирования – 8,7 тактов
Decoder Maximum Clocks = 86 ; Максимальное время декодирования – 86 тактов
Retirement Minimum Clocks = 0, ; МИНИМАЛЬНОЕ ВРЕМЯ ЗАВЕРШЕНИЯ – 0 ТАКТОВ
Retirement Average Clocks = 7.3 ; Эффективное время завершения – 7,3 такта
Retirement Maximum Clocks = 80 ; Максимальное время завершения – 80 тактов
total cycles = 80 (00,65%) ; ВСЕГО ВРЕМЕНИ ИСПОЛНЕНИЯ – 80 ТАКТОВ
micro-ops for this instruction = 1 ; КОЛ-ВО МИКРООПЕРАЦИЙ В ИНСТРУКЦИИ – 1
The instruction had to wait 0 cycles for it's sources to be ready
("ИНСТРУКЦИЯ ЖДАЛА 0 ТАКТОВ ПОКА ПОДГОТАВЛИВАЛИСЬ ЕЕ ОПЕРАНДЫ, Т.Е. ПОПРОСТУ ОНА ИХ НЕ ЖДАЛА СОВСЕМ")
Dynamic Penalty: IC_miss
The instruction was not in the instruction cache, so the processor loads the instruction from the L2 cache or main memory.
("ИНСТРУКЦИЯ ОТСУТСТВОВАЛА В КОДОВОМ КЭШЕ, И ПРОЦЕССОР БЫЛ ВЫНУЖДЕН ЗАГРУЖАТЬ ЕЕ ИЗ КЭША ВТОРОГО УРОВНЯ ИЛИ ОСНОВНОЙ ОПЕРАТИВНОЙ ПАМЯТИ")
Occurances = 1 ; Такое случалось 1 раз
Dynamic Penalty: L2instr_miss
The instruction was not in the L2 cache, so the processor loads the instruction from main memory.
("ИНСТРУКЦИЯ ОТСУТСТВОВАЛА В КЭШЕ ВТОРОГО УРОВНЯ И ПРОЦЕССОР БЫЛ ВЫНУЖДЕН ЗАГРУЖАТЬ ЕЕ ИЗ ОСНОВНОЙ ОПЕРАТИВНОЙ ПАМЯТИ")
Occurances = 1 ; Такое случалось 1 раз
Dynamic Penalty: Store_addr_unknown
The load instruction stalls due to the address calculation of the previous store instruction.
("ЗАГРУЖАЮЩАЯ ИНСТРУКЦИЯ ПРОСТАИВАЛА ПО ТОЙ ПРИЧИНЕ, ЧТО АДРЕС ИСТОЧНИКА РАССЧИТЫВАЛСЯ ПРЕДЫДУЩЕЙ ИНСТРУКЦИЕЙ ЗАПИСИ")
Occurances = 10 ; Такое случалось 10 раз
Так, кажется, наше расследование превращается в самый настоящий детектив, еще более запутанный, чем у Агаты Кристи. Если приложить к полученному результату даже самый скромный арифметический аппарат, получится полная чепуха и полное расхождение "дебита с кредитом". Судите сами. Полное время выполнения инструкции — 80 тактов, причем, известно, что она выполнялась 11 раз (см. в листинге 1.3 колонку count отчета профилировщика). А наихудшее время выполнения инструкции составило… 80 тактов! А наихудшее время декодирования и вовсе — 86! То есть, худшее время декодирования инструкции превышает общее время ее исполнения и при этом в десяти итерациях она еще ухитряется простаивать как минимум один такт за каждую итерацию по причине занятости блока расчета адресов. Да… тут есть от чего "поехать крышей"!
Причина такого несоответствия заключается в относительности самого понятия времени. Вы думаете время относительно только у Эйнштейна? Отнюдь! В конвейерных процессорах (в частности процессорах Pentium и AMD K6/Athlon) понятие "времени выполнения инструкции" вообще не существует в принципе (см. подразд. " Конвейеризация или пропускная способность VS-латентность" гл. 1). В силу того, что несколько инструкций могут выполняться параллельно, простое алгебраическое суммирование времени их исполнения даст значительно больший результат, нежели исполнение занимает в действительности.
Ладно, оставим разборки с относительностью до более поздних времен, а пока обратим внимание на тот факт, что в силу отсутствия нашей инструкции в кэше (она как раз находится на границе двух кэш-линеек) и вытекающей отсюда необходимости загружать ее из основной памяти, в первой итерации цикла она выполняется значительно медленнее, чем во всех последующих. Отсюда, собственно, и берутся эти пресловутые восемьдесят тактов.
При большом количестве итераций (а при "живом" исполнении программы оно и впрямь велико) временем начальной загрузки можно и пренебречь, но… Стоп! Ведь профилировщик исполнил тело данного цикла всего 11 раз, в результате чего среднее время выполнения этой инструкции составило 7,3 тактов, что совершенно не соответствует реальной действительности!
Ой! Оказывается, это вовсе не "горячая" точка! И тут совершенного нечего оптимизировать. Если мы увеличим количество прогонов профилировщика хотя бы в четыре раза, среднее время выполнения нашей инструкции понизится до 1,8 тактов и она окажется одним из самых "холодных" мест программы! Точнее — это вообще абсолютный ноль, поскольку эффективное время исполнения данной инструкции — ноль тактов (т. е. она завершается одновременно с предыдущей машинной командой). Словом, мы "промахнулись" по полной программе.
Отсюда правило: прежде чем приступать к оптимизации, убедитесь, что количество прогонов программы достаточно велико для маскировки накладных расходов первоначальной загрузки.
Короткое лирическое отступление на тему: почему же все так произошло. По умолчанию VTune прогоняет профилируемый фрагмент 1.000 раз. Много? Не спешите с ответом. Наш хитрый цикл устроен так, что его тело получает управление лишь каждые 'z' - '!' = 0x59 итераций (см. листинг 1.2). Таким образом, за все время анализа тело цикла будет исполнено всего лишь 1.000/89 = 11 раз! Причем, ни в коем случае нельзя сказать, что это надуманный пример. Напротив! В программном коде такое встречается сплошь и рядом.
Листинг 1.6. Демонстрация кода, некоторые участки которого прогоняются профилировщиком относительно небольшое количество раз, что искажает результат профилировки
while((++pswd[p])>'z') // данный цикл прогоняется профилировщиком 1.000 раз
{
pswd[p] = '!'; // данная инструкция прогоняется всего 11 раз
…
}
Поэтому, обнаружив "горячую" точку в первую очередь убедитесь, что количество ее прогонов достаточно велико. В противном случае полученный результат с большой степенью вероятности окажется недостоверным. И тут мы плавно переходим к обсуждению подсчета числа вызовов каждой точки программы.
Впрочем нет, постойте. Нам еще предстоит разобраться со второй "горячей" точкой и на удивление медленной скоростью загрузки указателя pswd. Опытные программисты, вероятно, уже догадались в чем тут дело.
Действительно, — строка pswd[p] = '!' — это первая строка тела цикла, получающая управление каждые 0x59 итераций, что намного превосходит "проницательность" динамического алгоритма предсказания ветвлений, используемого процессором для предотвращения остановки вычислительного конвейера.
Следовательно, данное ветвление всегда предсказывается ошибочно и выполнение этой инструкции процессору приходится начинать с нуля. А процессорный конвейер — длинный. Пока он заполниться… Собственно, тут виновата вовсе не команда mov edx, dword ptr [ebp+0ch] — любая другая команда на ее месте исполнялась бы столь же непроизводительно! "Паяльная грелка, до красна нагревающая" эту точку программы, находится совсем в другом месте!
Поднимем курсор чуть выше, на инструкцию условного перехода предшествующую этой команде, и дважды щелкнем мышкой. Профилировщик VTune выдаст следующую информацию:
decoder minimum clocks = 0 ; МИНИМАЛЬНОЕ ВРЕМЯ ДЕКОДИРОВАНИЯ – 0 ТАКТОВ
Decoder Average Clocks = 0 ; Эффективное время декодирования – 0 тактов
Decoder Maximum Clocks = 4 ; Максимальное время декодирования – 4 такта
retirement average clocks = 1 ; ЭФФЕКТИВНОЕ ВРЕМЯ ЗАВЕРШЕНИЯ – 1 ТАКТ
total cycles = 1011 (08,20%) ; ВСЕГО ВРЕМЕНИ ИСПОЛНЕНИЯ – 1010 ТАКТОВ (8,2%)
micro-ops for this instruction = 1 ; КОЛ-ВО МИКРООПЕРАЦИЙ В ИНСТРУКЦИИ – 1
The instruction had to wait (8,11.1,113) cycles for it's sources to be ready
("ЭТА ИНСТРУКЦИЯ ЖДАЛА МИНИМАЛЬНО 8, МАКСИМАЛЬНО 113, А В ОСНОВНОМ 11,1 ТАКТОВ ПОКА ЕЕ ОПЕРАНДЫ НЕ БЫЛИ ГОТОВЫ")
Dynamic Penalty: BTB_Miss_Penalty ; ШТРАФ ТИПА btb_miss_penalty
This instruction stalls because the branch was mispredicted.
("ЭТА ИНСТРУКЦИЯ ПРОСТАИВАЛА ПОТОМУ ЧТО ВЕТВЛЕНИЕ НЕ БЫЛО ПРЕДСКАЗАНО")
Occurances = 13 ; Такое случалось 13 раз
Наша гипотеза полностью подтверждается. Это ветвление тринадцать раз предсказывалось неправильно, о чем VTune и свидетельствует! Постой, как тринадцать?! Ведь тело цикла исполняется только одиннадцать! Да, правильно, одиннадцать. Но ведь процессор наперед этого не знал, и дважды пытался передать на него управление, и лишь затем, "увидев", что ни одно из двух предсказаний не сбылось, "плюнул и поклялся", что никогда–никогда не поставит свои фишки на эту ветку.
ОК. Когда загадки разрешаются — это приятно. Но главный вопрос несколько в другом: как именно их разрешать? Хорошо, что в нашем случае непредсказуемый условный переход находился так близко к "горячей" точке, но ведь в некоторых (и не таких уж редких) случаях "виновник" бывает расположен даже в других модулях программы! Ну что на это сказать… Подходите к профилировке комплексно и всегда думайте головой. Пожалуй, ничего более действенного я не смогу посоветовать…
Определение количества вызовов
Как мы только что показали, определение количества вызовов профилируемой точки необходимо уже хотя бы для того, чтобы мы могли убедиться в достоверности изменений. К тому же, оценивать температуру точки можно не только по времени ее выполнения, но и частоте вызова.
Например, пусть у нас есть две "горячие" точки, в которых процессор проводит одинаковое время, но первая из них вызывается сто раз, а вторая — сто тысяч раз. Нетрудно догадаться, что, оптимизировав последнюю хотя бы на 1%, мы получим колоссальный выигрыш в производительности, в то время как, сократив время выполнения первой из них вдвое, мы ускорим нашу программу всего лишь на четверть.
Таким образом, часто вызываемые функции в большинстве случаев имеет смысл "инлайнить" (от английского in-line), т. е. непосредственно вставить их код в тело вызываемых функций, что сэкономит какое-то количество времени.
Определять количество вызовов умеют практически все профилировщики, и тут нет никаких проблем, заслуживающих нашего внимания.
Определение степени покрытия
Вообще-то говоря, определение степени покрытия не имеет никакого отношения к оптимизации приложений и это побочная функция профилировщиков. Но, поскольку она все-таки есть, мораль обязывает автора рассмотреть ее, хоть и кратко.
Итак, покрытие — это процент реально выполненного кода программы в процессе его профилировки. Кому нужна такая информация? Ну, в первую очередь, тестерам — должны же они убедиться, что весь код приложения протестирован целиком и в нем не осталось никаких "темных" мест.
С другой стороны, оптимизируя программу, очень важно знать, какие именно ее части были профилированы, а какие нет. В противном случае многих "горячих" точек можно просто не заметить только потому, что соответствующие им ветки программы вообще ни разу не получили управления!
Рассмотрим, например, как может выглядеть протокол покрытия функций, сгенерированный профилировщиком profile.exe для нашего тестового примера pswd.exe (о самом тестовом примере см. разд. "Практический сеанс профилировки с VTune в десяти шагах" гл. 2)
Листинг 1.7. Пример протокола покрытия функций, сгенерированный профилировщиком profile
program statistics ; СТАТИСТИКА ПО ПРОГРАММЕ
------------------
Command line at 2002 Aug 20 03:36: pswd ; КОМАНДНАЯ СТРОКА
call depth: 2 ; ГЛУБИНА ВЫЗОВОВ: 2
total functions: 5 ; ВСЕГО ФУНКЦИЙ: 5
Function coverage: 60,0% ; ПОКРЫТО ФУНКЦИЙ: 60%
Module Statistics for pswd.exe ; СТАТИСТИКА ПО МОДУЛЮ pswd
------------------------------
Functions in module: 5 ; ФУНКЦИЙ В МОДУЛЕ: 5
Module function coverage: 60,0% ; ФУНКЦИЙ ПРОКРЫТО: 60%
Covered Function ; ПОКРЫТЫЕ ФУНКЦИИ
----------------
. _DeCrypt (pswd.obj)
. __real@4@4008fa00000000000000 (pswd.obj)
* _gen_pswd (pswd.obj)
* _main (pswd.obj)
* _print_dot (pswd.obj)
Из листинга 1.7 следует, что лишь 60% функций получили управление, а остальные 40% не были вызваны ни разу! Разумно убедиться: а вызываются ли эти функции когда ни будь вообще или представляют собой "мертвый" код, который можно безболезненно удалить из программы, практически на половину уменьшив ее в размерах?
Если же эти функции при каких-то определенных обстоятельствах все же получают управление, нам необходимо проанализировать исходный код, чтобы разобраться: что же это за обстоятельства и воссоздать их, чтобы профилировщик смог пройти и остальные участки программы. Имена покрытых и непокрытых функций перечислены в секции Covered Function. Покрытые отмечаются знаком "*", а непокрытые — "."
Вообще же, для определения степени покрытия существует множество узкоспециализированных приложений (например, NuMega Code Coverage), изначально направленных на решение именно этой задачи и со своей работой они справляются намного лучше любого профилировщика.
Фундаментальные проблемы профилировки "в малом"
Профилировкой "в малом" мы будем называть измерение времени выполнения небольших фрагментов программы, а то и отдельных машинных команд.
Профилировке в малом присущ ряд серьезных и практически неустранимых проблем, незнание которых зачастую приводит к грубым ошибкам интерпретации результата профилировки и как следствие — впустую потраченному времени и гораздо худшему качеству оптимизации.
Конвейеризация или пропускная способность VS-латентность
Начнем с того, что в конвейерных системах такого понятия как "время выполнения одной команды" просто нет. Уместно провести такую аналогию. Допустим, некоторый приборостроительный завод выпускает шестьсот микросхем памяти в час. Ответьте: сколько времени занимает производство одной микросхемы? Шесть секунд? Ну конечно же нет! Полный технологический цикл составляет не секунды, и даже не дни, а месяцы! Мы не замечаем этого лишь благодаря конвейеризации производства, т. е. разбиении его на отдельные стадии, через которые в каждый момент времени проходит, по крайней мере, одна микросхема.
Количество продукции, сходящей с конвейера в единицу времени, называют его пропускной способностью. Легко показать, что пропускная способность в общем случае обратно пропорциональна длительности одной стадии, — действительно, чем короче каждая стадия, тем чаще продукция сходит с конвейера. При этом количество самих стадий (попросту говоря, длина конвейера) не играет абсолютно никакой роли. Кстати, обратите внимание, что практически на всех заводах каждая стадия представляет собой элементарную операцию, — вроде "накинуть ключ на гайку" или "стукнуть молотком". И не только потому, что человек лучше приспосабливается к однообразной монотонной работе (наоборот, он, в отличии от автоматов, ее терпеть не может!). Элементарные операции, занимая чрезвычайно короткое время, обеспечивают конвейеру максимальную пропускную способность.
Той же самой тактики придерживаются и производители процессоров, причем заметна ярко выраженная тенденция увеличения длины конвейера в каждой новой модели. Так, если в первых Pentium длина конвейера составляла всего пять стадий, то уже в Pentium-II она была увеличена до четырнадцати стадий, а в Pentium-4 — и вовсе до двадцати. Такая мера была вызвана чрезмерным наращиванием тактовой частоты ядра процессора и вытекающей отсюда необходимостью как-то заставить конвейер работать на этой частоте.
С одной стороны и хорошо, — конвейер крутится как угорелый, выполняя до 6 микроинструкций за такт и какое нам собственно дело до его длины? А вот какое! Вернемся к нашей аналоги с приборостроительным заводом. Допустим, захотелось нам запустить в производство новую модель. Вопрос: через какое время она сойдет с конвейера? (Бюрократическими проволочками можно пренебречь). Ни через шесть секунд, ни через час новая модель готова не будет и придется ждать пока весь технологический цикл не завершится целиком.
Латентность — т. е. полное время прохождения продукции по конвейеру, может быть и не критична для неповоротливого технологического процесса производства (действительно, новые модели микросхем не возникают каждый день), но весьма ощутимо влияет на быстродействие динамичного процессора, обрабатывающего неоднородный по своей природе код. Продвижение машинных инструкций по конвейеру сопряжено с рядом принципиальных трудностей, — то не готовы операнды, то занято исполнительное устройство, то встретился условный переход (что равносильно переориентации нашего приборостроительного завода на производство новой модели) и… вместо безостановочного вращения конвейера мы наблюдаем его длительные простои, лишь изредка прерываемые короткими рывками, а затем вновь покой и тишина.
В лучшем случае время выполнения одной инструкции определяется пропускной способностью конвейера, а в худшем — его латентностью. Поскольку пропускная способность и латентность различаются где-то на порядок или около того, бессмысленно говорить о среднем времени выполнения инструкции. Оно не будет соответствовать никакой физической действительности.
Малоприятным следствием становится невозможность определения реального времени исполнения компактного участка кода (если, конечно, не прибегать к эмуляции процессора). До тех пор, пока время выполнения участка кода не превысит латентность конвейера (30 тактов для P6), мы вообще ничего не сможем сказать ни о коде, ни о времени, ни о конвейере!
Неточность измерений
Одно из фундаментальных отличий цифровой от аналоговой техники заключается в том, что верхняя граница точности цифровых измерений определяется точностью измерительного инструмента (точность аналоговых измерительных инструментов, напротив, растет с увеличением количества замеров).
А чем можно измерять время работы отдельных участков программы? В персональных компьютерах семейства IBM PC AT имеются как минимум два таких механизма: системный таймер (штатная скорость: 18,2 тика в секунду, т. е. 55 мс, максимальная скорость — 1 193 180 тиков в секунду или 0,84 мкс), часы реального времени (скорость 1024 тика в секунду т. е. 0,98 мс). В дополнении к этому в процессорах семейства Pentium появился так называемый регистр счетчик – времени (Time Stamp Counter), увеличивающийся на единицу при каждом такте процессорного ядра.
Теперь разберемся со всем этим хозяйством подробнее. Системный таймер (с учетом времени, расходующегося на считывание показаний) обеспечивает точность порядка 5 мс, что составляет более двух десятков тысяч тактов даже в системе с частотой 500 МГц! Это — целая вечность для процессора. За это время он успевает перемолотить море данных, скажем, отсортировать сотни полторы чисел. Поэтому, системный таймер для профилирования отдельных функций непригоден. В частности, нечего и надеяться с его помощью найти узкие места функции quick sort! Да что там узкие места — при небольшом количестве обрабатываемых чисел он и общее время сортировки определяет весьма неуверенно.
Причем, прямого доступа к системному таймеру под нормальной операционной системой никто не даст, а минимальный временной интервал, еще засекаемый штатной Си-функций clock(), составляет всего лишь 1/100 сек, а это годиться разве что для измерения времени выполнения всей программы целиком.
Точность часов реального времени так же вообще не идет ни в какое сравнение с точность системного таймера (перепрограммированного, разумеется).
Остается надеяться лишь на Time Stamp Counter. Первое знакомство с ним вызывает просто бурю восторга и восхищения "ну наконец-то Intel подарила нам то, о чем мы так долго мечтали!". Судите сами: во-первых, операционные системы семейства Windows (в том числе и "драконическая" в этом плане NT) предоставляют беспрепятственный доступ к машинной команде RDTSC, читающий содержимое данного регистра. Во-вторых, поскольку он инкрементируется каждый такт, создается обманчивое впечатление, что с его помощью возможно точно определять время выполнения каждой команды процессора. Увы! На самом же деле это далеко не так!
Начнем с того, что в конвейерных системах, как мы уже помним, вообще нет такого понятия как время выполнения команды, и следует говорить либо о пропускной способности, либо латентности. Сразу же возникает вопрос: а что же все-таки команда RDTSC меряет? Документация Intel не дает прямого ответа, но судя по всему, RDTSC считывает содержимое регистра счетчика-времени в момент прохождения данной инструкции через соответствующее исполнительное устройство. Причем, RDTSC — это неупорядоченная команда, т. е. она может завешаться даже раньше предшествующих ей команд. Именно так и произойдет, если предшествующая ей команда простаивает в ожидании операндов.
Рассмотрим крайний случай, когда измеряется время выполнения минимальной порции кода (одна машинная команда уходит на то, чтобы сохранить считанное значение в первой итерации):
Листинг 1.8. Попытка замера времени выполнения одной машинной команды
rdtsc ; ЧИТАЕМ ЗНАЧЕНИЕ РЕГИСТРА ВРЕМЕНИ
; и помещаем его в регистры EDX и EAX
mov [clock], eax ; СОХРАНЯЕМ МЛАДШЕЕ ДВОЙНОЕ СЛОВО
; регистра времени в переменную clock
rdtsc ; ЧИТАЕМ РЕГИСТР ВРЕМЕНИ ЕЩЕ РАЗ
SUB EAX, [clock] ; ВЫЧИСЛЯЕМ РАЗНИЦУ ЗАМЕРОВ МЕЖДУ
; первым и вторым замером
При прогоне этого примера на P-III он выдаст 32 такта, вызывая тем самым риторический вопрос: "а почему, собственно, так много?" Хорошо, оставим выяснение обстоятельств "похищения процессорных тактов" до лучших времен, а сейчас попробуем измерять время выполнения какой-нибудь машинной команды, ну скажем, INC EAX, увеличивающей значение регистра EAX на единицу. Поместим ее между инструкциями RDTSC и перекомпилируем программу.
Вот это да! Прогон показывает все те же 32 такта. Странно! Добавим-ка мы еще одну INC EAX. Как это так — снова 32 такта?! Зато при добавлении сразу трех инструкций INC EAX контрольное время исполнения скачкообразно увеличивается на единицу, что составляет 33 такта. Четыре и пять инструкций INC EAX дадут аналогичный результат, а вот при добавлении шестой, результат изменений вновь возрастает на один такт.
Но ведь процессор Pentium, имея в наличии всего лишь одно арифметическое устройство, никак не может выполнять более одного сложения за такт одновременно! Полученное нами значение в три команды за такт — это скорость их декодирования, но отнюдь не исполнения! Чтобы убедиться в этом запустим на выполнение следующий цикл (листинг 1.9).
Листинг 1.9. Измерение времени выполнения 6х1000 машинных команд inc
mov ecx,1000 ; ПОМЕСТИТЬ В РЕГИСТР ecx ЗНАЧЕНИЕ 1000
@for: ; МЕТКА НАЧАЛА ЦИКЛА
inc eax ;\
inc eax ; +- ОДНА ГРУППА ПРОФИЛИРУЕМЫХ ИНСТРУКЦИЙ
inc eax ;/
INC EAX ;\
inc eax ; +- ВТОРАЯ ГРУППА ПРОФИЛИРУЕМЫХ ИНСТРУКЦИЙ
inc eax ;/
dec ecx ; УМЕНЬШИТЬ ЗНАЧЕНИЕ РЕГИСТРА ecx НА 1
; (здесь он используется в качестве
; счетчика цикла)
jnz @xxx ; ДО ТЕХ ПОР, ПОКА ecx НЕ ОБРАТИТСЯ В НОЛЬ
; перепрыгивать на метку @for
На P-III выполнение данного цикла займет отнюдь не ~2 000, а целых 6 781 тактов, что соответствует, по меньшей мере, одному такту, приходящемуся на каждую математическую инструкцию! Следовательно, в предыдущем случае, при измерении времени выполнения нескольких машинных команд, инструкция RDTSC "вперед батьки пролезла в пекло", сообщив нам совсем не тот результат, которого мы от нее ожидали!
Вот если бы существовал способ "притормозить" выполнение инструкции RDTSC до тех пор, пока полностью не будут завершены все предшествующие ей машинные инструкции… И такой способ есть! Достаточно поместить перед RDTSC одну из команд упорядоченного выполнения. Команды упорядоченного выполнения начинают обрабатываться только после схода с конвейера последней предшествующей ей неупорядоченной команды и, до тех пор пока команда упорядоченного выполнения не завершится, следующие за ней команды мирно дожидаются своей очереди, а не "лезут как толпа дикарей" вперед на конвейер.
Подавляющее большинство команд упорядоченного выполнения — это привилегированные команды (например, инструкции чтения/записи портов ввода-вывода) и лишь очень немногие из них доступны с прикладного уровня. В частности, к таковым принадлежит инструкция идентификации процессора CPUID.
Многие руководства (в частности и Ангер Фог в своем руководстве "How to optimize for the Pentium family of microprocessors" и технический документ "Using the RDTSC Instruction for Performance Monitoring" от корпорации Intel) предлагают использовать приблизительно такой код (листинг 1.10).
Листинг 1.10. Официально рекомендованный способ вызова инструкции RDTSC для измерения времени выполнения
xor eax,eax ; ВЫЗЫВАЕМ МАШИННУЮ КОМАНДУ cpuid,
CPUID ; после выполнения которой все
; предыдущие машинные инструкции
; гарантированно сошли к конвейера
; и потому никак не могут повлиять
; на результаты наших замеров
rdtsc ; ВЫЗЫВАЕМ ИНСТРУКЦИЮ rdtsc, КОТОРАЯ
; возвращает в регистре EAX младшее
; двойное слово текущего значения
; time stamp counter 'a
mov [clock],eax ; СОХРАНЯЕМ ПОЛУЧЕННОЕ ТОЛЬКО ЧТО
; значение в переменной clock
// … ;\
// ПРОФИЛИРУЕМЫЙ КОД ; +-ЗДЕСЬ ИСПОЛНЯЕТСЯ ПРОФИЛИРУЕМЫЙ КОД
// … ;/
xor eax,eax ; ЕЩЕ РАЗ ВЫПОЛНЯЕМ КОМАНДУ cpuid,
CPUID ; чтобы все предыдущие инструкции
; гарантированно успели покинуть
; конвейер
rdtsc ; ВЫЗЫВАЕМ ИНСТРУКЦИЮ rdtsc ДЛЯ ЧТЕНИЯ
; нового значение Time Stamp Count
sub eax,[clock] ; ВЫЧИСЛЯЕМ РАЗНОСТЬ ВТОРОГО И ПЕРВОГО
; замеров, тем самым определяя реальное
; время выполнения профилируемого
; ФРАГМЕНТА КОДА
К сожалению, даже этот, официально рекомендованный, код все равно не годится для измерения времени выполнения отдельных инструкций, поскольку полученный с его помощью результат представляет собой полное время выполнения инструкции, т. е. ее латентность, а отнюдь не пропускную способность, которая нас интересует больше всего.
(Кстати, и у Intel, и Ангера Фога есть одна грубая ошибка — в их варианте программы перед инструкцией CPUID отсутствует явное задание аргумента, который эта инструкция ожидает "увидеть" в регистре EAX. А, поскольку, время ее выполнения зависит от аргумента, то и время выполнения профилируемого фрагмента не постоянно, а зависит от состояния регистров на входе и выходе. В предлагаемом мною варианте инициализация EAX осуществляется явно, что страхует профилировщик от всяких там наведенных эффектов).
Имеется и другая проблема, еще более серьезная, чем первая. Вы помните постулат квантовой физики, сводящийся к тому, что всякое измерение свойств объекта неизбежно вносит в этот объект изменения, искажающие результат измерений? Причем, эти искажения невозможно устранить простой калибровкой, поскольку изменения могут носить не только количественный, но и качественный характер.
Если профилируемый код задействует те же самые узлы процессора, что и команды RDTSC/CPUID, время его выполнения окажется совсем иным нежели в действительности! Никаким ухищрениями нам не удастся достигнуть точности измерений до одного–двух тактов!
Поэтому, минимальный промежуток времени, которому еще можно верить, составляет, как показывает практика и личный опыт автора, по меньше мере пятьдесят–сто тактов.
Отсюда следствие: штатными средствами процессора измерять время выполнения отдельных команд невозможно.
Аппаратная оптимизация
На мгновение отвлечемся от компьютеров и зададимся вопросом: можно ли с помощью обычной ученической линейки измерить толщину листа принтерной бумаги? На первый взгляд, тут без штангенциркуля ну никак не обойтись… Но, если взять с полсотни листов бумаги и плотно сложить их друг с другом… вы уже поняли куда я клоню? Пусть погрешность измерения толщины образовавшегося "кирпича" бумаги составит ± 1 мм, тогда — точность определения толщины каждого отдельно взятого листа будет не хуже чем ± 0,02 мм, что вполне достаточно для большинства повседневных целей!
Почему бы ни применить эту технику для измерения времени выполнения машинных команд? В самом деле, время выполнения одной команды так мало, что просто ничем его не измерить (см. подразд. "Неточность измерений"), но если мы возьмем сто или даже сто тысяч таких команд, то… Но, увы! Машинные команды ведут себя совсем не так, как листы бумаги. Неоднородность конвейера приводит к тому, что зависимость между количеством и временем выполнения команд носит ярко выраженный нелинейный характер.
К тому же, современные процессоры слишком умны, чтобы воспринимать переданный им на выполнение код буквально. Нет! Они подходят к этому делу весьма творчески. Вот, допустим, встретится им последовательность команд MOV EAX, 1; MOV EAX, 1; MOV EAX, 1, каждая из которых помещает в регистр EAX значение "1". Думаете, процессор как полный недоумок, исполнит все три команды? Да как бы не так! Поскольку, результат двух первых присвоений никак не используется, процессор отбросит эти команды как ненужные, затратив время лишь на их декодирование, и ощутимо сэкономит на их выполнении!
Оптимизация программного кода, выполняемая процессором на аппаратном уровне, значительно увеличивает производительность системы, занижая тем самым фактическое время выполнения машинных команд. Да, мы можем точно измерять сколько тактов выполнялся блок из тысячи таких-то команд, но следует с большой осторожностью подходить к оценке времени выполнения одной такой команды.
Низкая "разрешающая способность"
Учитывая, что пропускная способность большинства инструкций составляет всего один такт, а минимальный промежуток времени, который еще можно измерять, находится в районе пятидесяти — ста тактов, предельная разрешающая способность не эмулирующих профилировщиков не превышает полста команд.
Под "разрешающей способностью" здесь и далее понимается протяженность "горячей" точки более или менее уверенно распознаваемой профилировщиком.
Строго говоря, не эмулирующие профилировщики показывают не саму "горячую" точку, а некоторую протяжную область, к которой эта "горячая" точка принадлежит.
Фундаментальные проблемы профилировки "в большом"
Профилировкой "в большом" мы будем называть измерение времени выполнения структурных единиц программы (функций, многократно выполняемых циклов и т.д.), а то и всей программы целиком.
Профилировке "в большом" присущи свои проблемы. Это и непостоянство времени выполнения, и проблема "второго прохода", и необходимость учета наведенных эффектов… Словом, здесь есть над чем поработать!
Непостоянства времени выполнения
Если вы профилировали приложения и раньше, то наверняка сталкивались с тем, что результаты измерений времени выполнения варьируются от прогона к прогону, порой отличаясь один от другого более чем значительно.
Причин такого непостоянства существует, по меньшей мере, две:
- программное непостоянство, связанное с тем, что в многозадачных операционных системах (в частности в Windows) профилируемая программа попадает под влияние чрезвычайно изменчивой окружающей среды;
- аппаратное непостоянство , вызванное внутренней "многозадачностью" самого железа.
В силу огромной их значимости для результатов профилировки, обе этих причины далее будут рассмотрены во всех подробностях.
Программное непостоянство
В многозадачной среде, коей и является популярнейшая на сегодняшний день операционная система Windows, никакая программа не владеет всеми ресурсами системы единолично и вынуждена делить их с остальными задачами. А это значит, что скорость выполнения профилируемой программы не постоянна и находится в тесной зависимости от "окружающей среды". На практике разброс результатов измерений может достигать 10%—15%, а то и больше, особенно, если параллельно с профилировкой исполняются интенсивно нагружающие систему задачи.
Тем не менее, особой проблемы в этом нет, — достаточно лишь в каждом сеансе профилировки делать несколько контрольных прогонов и затем… нет, не усреднять, а выбирать замер с наименьшим временем выполнения. Дело в том, что измерения производительности — это не совсем обычные инструментальные измерения и типовые правила метрологии здесь неуместны. Процессор никогда не ошибается и каждый полученный результат точен. Другое дело, что он в той или иной степени искажен побочными эффектами, но! Никакие побочные эффекты никогда не приводят к тому, что программа начинает исполняться быстрее, нежели она исполняется в действительности, а потому, прогон с минимальным временем исполнения и представляет собой измерение в минимальной степени испорченное побочными эффектами.
Кстати, во многих руководствах утверждается, что перед профилировкой целесообразно выходить из сети ("что бы машина не принимала пакеты"), завершать все-все приложения, кроме самого профилировщика и вообще лучше даже "на всякий случай" перегрузиться. Все это чистейшей воды бред! Автор частенько отлаживал программы параллельно с работой в Word, приемом корреспонденции, загрузкой нескольких файлов из Интернета и при этом точность профилировки всегда оставалась удовлетворительной! Конечно, без особой нужды не стоит так рисковать, и параллельно работающие приложения перед началом профилировки, действительно, лучше завершить, но не следует доводить ситуацию до абсурда, и пытаться обеспечить полную "стерильность" своей машине.
Аппаратное непостоянство
Возможно, это покажется удивительным, но на аппаратном уровне время выполнения одних и тех же операций не всегда постоянно и подвержено определенным разбросам, под час очень большим и значительно превосходящим программную погрешность. Но, если последнюю, хотя бы теоретически, возможно ликвидировать (ну, например, запустить программу в однозадачном режиме), то аппаратное непостоянство неустранимо принципиально.
Почему оно — аппаратное непостоянство — вообще возникает? Ну, тут много разных причин. Вот, например, одна из них: если частота системной шины не совпадает с частотой модулей оперативной памяти, чипсету придется каждый раз выжидать случайный промежуток времени до прихода следующего фронта тактового импульса. Исходя из того, что один цикл пакетного обмена в зависимости от типа установленных микросхем памяти занимает от 5 до 9 тактов, а синхронизовать приходится и его начало, и его конец, нетрудно подсчитать, что в худшем случае мы получаем неоднозначность в 25%—40%.
Самое интересное, что аппаратный разброс в чрезвычайно высокой степени разниться от системы к системе. Я, к сожалению, так и не смог определить, кто именно здесь виноват, но могу сказать, что, к примеру, на P-III 733/133/100/I815EP не смотря на разницу в частотах памяти и системной шины, аппаратный разброс весьма невелик и едва ли превышает 1%—2%, на что можно вообще закрыть глаза.
Вот AMD Athlon 1050/100/100/VIA KT133 — совсем другое дело! У него наблюдается просто ошеломляющее аппаратное непостоянство, в частности, в операциях с основной памятью доходящее аж до двух раз! Непонятно, как на такой системе вообще можно профилировать программы? В, частности, последовательные замеры времени копирования 16-мегабайтного блока памяти после предварительной обработки (т. е. после отбрасывания заведомо пограничных значений) могут выглядеть так:
ПРОГОН № 01: 84445103 ТАКТОВ
Прогон № 02: 83966665 тактов
Прогон № 03: 73795939 тактов
Прогон № 04: 80323626 тактов
Прогон № 05: 84381967 тактов
Прогон № 06: 85262076 тактов
Прогон № 07: 85151531 тактов
Прогон № 08: 91520360 тактов
Прогон № 09: 92603591 тактов
Прогон № 10: 100651353 тактов
Прогон № 11: 93811801 тактов
Прогон № 12: 84993464 тактов
Прогон № 13: 92927920 тактов
Смотрите, расхождение между минимальным и максимальным временем выполнения составляет не много, не мало — 36%! А это значит, что вы не сможете обнаруживать "горячие" точки меньшей величины. Более того, вы не сможете оценивать степень влияния тех или иных оптимизирующих алгоритмов, если только они не дают, по меньшей мере, двукратного прироста производительности!
Отсюда правила:
- Не всякая система пригодна для профилировки и оптимизации приложений .
- Если последовательные замеры дают значительный временной разброс, просто смените систему .
Под "системой" в данном случае подразумевается не операционная система, а аппаратное обеспечение.
Обработка результатов измерений
Непосредственные результаты замеров времени исполнения программы в "сыром" виде, как было показано выше, ни на что ни годны. Очевидно, перед использованием их следует обработать. Как минимум откинуть пограничные значения, вызванные нерегулярными наведенными эффектами (ну, например, в самый ответственный для профилировки момент, операционная система принялась что-то сбрасывать на диск), а затем… Затем перед нами встает Буриданова проблема. Мы будем должны либо выбрать результат с минимальным временем исполнения — как наименее подвергнувшийся пагубному влиянию многозадачности, либо же вычислить наиболее типичное время выполнения — как время выполнения в реальных, а не идеализированных "лабораторных" условиях.
Мной опробован и успешно применяется компромиссный вариант, комбинирующий оба этих метода. Фактически, я предлагаю вам отталкиваться от среднеминимального времени исполнения. Сам алгоритм в общих чертах выглядит так: мы выполняем N повторов программы, а затем отбрасываем N/3 максимальных и N/3 минимальных результатов замеров. Для оставшихся N/3 замеров мы находим среднее арифметическое, которое и берем за основной результат. Величина N варьируется в зависимости от конкретной ситуации, но обычно с лихвой хватает 9—12 повторов, т. к. большее количество уже не увеличивает точности результатов.
Одна из возможных реализаций данного алгоритма приведена ниже:
Листинг 1.11. Нахождение среднетипичного времени выполнения
unsigned int cycle_mid(unsigned int *buff, int nbuff)
{
int a,xa=0;
if (!nbuff) nbuff=A_NITER;
buff=buff+1; nbuff--; // ИСКЛЮЧАЕМ ПЕРВЫЙ ЭЛЕМЕНТ
if (getargv("$NoSort",0)==-1)
qsort(buff,nbuff,sizeof(int), \
(int (*)(const void *,const void*))(_compare));
for (a=nbuff/3;a<(2*nbuff/3);a++)
xa+=buff[a];
xa/=(nbuff/3);
return xa;
}
Проблема второго прохода
Для достижения приемлемой точности измерений профилируемое приложение следует выполнить, по крайней мере, 9—12 раз (см. предыдущий подразд. "Обработка результатов измерений"), причем каждый прогон должен осуществляться в идентичных условиях окружения. Увы! Без написания полноценного эмулятора всей системы это требование практически невыполнимо. Дисковый кэш, сверхоперативная память обоих уровней, буфера физических страниц и история переходов чрезвычайно затрудняют профилировку программ, поскольку при повторных прогонах время выполнения программы значительно сокращается.
Если мы профилируем многократно выполняемый цикл, то этим обстоятельством можно и пренебречь, поскольку время загрузка данных и/или кода в кэш практически не сказывается на общем времени выполнения цикла. К сожалению, так бывает далеко не всегда (такой случай как раз и был разобран в разд. "Информация о пенальти").
Да и можем же мы, наконец, захотеть оптимизировать именно инициализацию приложения?! Пускай, она выполняется всего лишь один раз за сеанс, но какому пользователю приятно, если запуск вашей программы растягивается на минуты а то и десятки минут? Конечно, можно просто перезагрузить систему, но… сколько же тогда профилировка займет времени?!
Хорошо. Очистить кэш данных — это вообще раз плюнуть. Достаточно считать очень большой блок памяти, намного превышающий его (кэша) емкость. Не лишнем будет и записать большой блок для выгрузки всех буферов записи (см. "Часть III. Подсистема кэш-памяти"). Это же, кстати, очистит и TLB (Translate Look aside Buffer) — буфер, хранящий атрибуты страниц памяти для быстрого обращения к ним (см. "предвыборка"). Аналогичным образом очищается и кэш/TLB от кода. Достаточно сгенерировать очень большую функцию, имеющую размер порядка 1—4 Мбайта, и при этом "ничего не делающую" (для определенности забьем ее машинными командами NOP — "нет операции"). Таким образом мы уменьшим пагубное влияние всех, перечисленных выше эффектов, хотя и не устраним его полностью. Увы! В этом мире есть вещи, не подвластные ни прямому, ни косвенному контролю (во всяком случае, на прикладном уровне).
С другой стороны, если мы оптимизируем одну, отдельно взятую функцию, (для определенности остановимся на функции реверса строк), то как раз таки ее первый прогон нам ничего и не даст, поскольку в данном случае основным фактором, определяющим производительность, окажется не эффективность кода/алгоритма самой функции, а накладные расходы на загрузку машинных инструкций в кэш, выделение и проецирование страниц операционной системой, загрузку обрабатываемых функцией данных в сверхоперативную память и т. д. В реальной же программе эти накладные расходы, как правило, уже устранены (даже если эта функция вызывается однократно).
Давайте проведем следующий эксперимент. Возьмем следующую функцию и десять раз подряд запустим ее на выполнение, замеряя время каждого прогона.
Листинг 1.12. Пример функции, однократно обращающийся к каждой загруженной в кэш ячейке
#define a (int *)((int)p + x)
A_BEGIN(0)
#define b (int *)((int)p + BLOCK_SIZE - x - sizeof(int))
for (x = 0; x < BLOCK_SIZE/2; x+=sizeof(int))
{
#ifdef __OVER_BRANCH__
if (x & 1)
#endif
*a = *a^*b; *b = *b^*a; *a = *a^*b;
}
A_END(0)
Для блоков памяти, полностью умещающихся в кэш-памяти первого уровня, на P-III 733/133/100/I815EP мы получим следующий ряд замеров:
__OVER_BRANCH__ not define __OVER_BRANCH__ is define
68586 63788
17629 18507
17573 18488
17573 18488
17573 18488
17573 18488
17573 18488
17573 18488
Обратите внимание, что время выполнения первого прогона функции (не путать с первой итерации цикла!) практически вчетверо превосходит все последующие! Причем, результаты замеров непредсказуемым образом колеблются от 62 190 до 91 873 тактов, что соответствует погрешности ~50%. Означает ли это, что, если данный цикл в реальной программе исполняется всего один раз, то оптимизировать его бессмысленно? Конечно же, нет! Давайте, для примера избавимся от этого чудачества с командой XOR и как нормальные люди обменяем два элемента массива через временную переменную. Оказывается, это сократит время первого прогона до 47 603—65 577 тактов, т. е. увеличит эффективность его выполнения на 20%—40%!
Тем не менее, устойчивая повторяемость результатов начинается лишь с третьего прогона! Почему так медленно выполняется первый прогон — это понятно (загрузка данных в кэш и прочее), но вот что не дает второму показать себя во всю мощь? Оказывается — ветвления. За первый прогон алгоритм динамического предсказания ветвлений еще не накопил достаточное количество информации и потому во втором прогоне еще давал ошибки, но, начиная с третьего, наконец-то "въехал" в ситуацию и понял, что от него ходят.
Убедиться, что виноваты именно ветвления, а не кто-нибудь другой, позволяет следующий эксперимент: давайте определим __OVER_BRANCH__ и посмотрим как это скажется на результат. Ага! Разница между вторым и третьим проходом сократилась с 0,3% до 0,1%. Естественно, будь наш алгоритм малость поветвистее (в том смысле, что содержит побольше ветвлений), и всех трех прогонов могло бы не хватить для накопления надежного статистического результата. С другой стороны, погрешность, вносимая переходами, крайне невелика и потому ей можно пренебречь. Кстати, обратите внимание, что постоянство времени выполнения функции на всех последних проходах соблюдается с точностью до одного такта!
Таким образом, при профилировании многократно выполняющихся функций, результаты первых двух–трех прогонов стоит вообще откинуть, и категорически не следует их арифметически усреднять.
Напротив, при профилировании функций, исполняющихся в реальной программе всего один раз, следует обращать внимание лишь на время первого прогона и отбрасывать все остальные, причем, при последующих запусках программы необходимо каким-либо образом очистить все кэши и все буфера, искажающие реальную производительность.
Проблема наведенных эффектов
Исправляя одни ошибки, мы всегда потенциально вносим другие и потому после любых, даже совсем незначительных модификаций кода программы, цикл профилировки следует повторять целиком.
Вот простой и очень типичный пример. Пусть в оптимизированной программе встретилась функция следующего вида:
Листинг 1.13. Фрагмент кода, демонстрирующий ситуацию, в которой удаление лишнего кода может обернуться существенным и труднообъясним падением производительности
ugly_func(int foo)
{
int a;
…
…
…
if (foo<1) return ERR_FOO_MUST_BE_POSITIVELY;
for(a=1; a <= foo; a++)
{
…
…
…
}
}
Очевидно, если попытаться передать функции ноль или отрицательное число, то цикл for_a не выполнится ни разу, а потому принудительная проверка значения аргумента (в тексте она выделена жирным шрифтом) бессмысленна! Конечно, при больших значениях foo накладные расходы на такую проверку относительно невелики, но в праве ли мы надеяться, что удаление этой строки, по крайней мере, не снизит скорость выполнения функции?
Постойте, это отнюдь не бредовый вопрос, относящийся к области теоретической абстракции! Очень может статься так, что удаление выделенной строки будет носить эффект прямо противоположный ожидаемому, и вместо того чтобы оптимизировать функцию, мы даже снизим скорость ее выполнения, причем, весьма значительно!
Как же такое может быть? Да очень просто! Если компилятор не выравнивает циклы в памяти (как, например, MS VC), то с довольно высокой степенью вероятности мы рискуем нарваться на кэш-конфликт (см. "Часть III. Подсистема кэш-памяти"), облагаемый штрафным пенальти. А можем и не нарваться! Это уж как фишка ляжет. Быть может, эта абсолютно бессмысленная (и, заметьте, однократно выполняемая) проверка аргументов как раз и спасала цикл от штрафных задержек, возникающих в каждой итерации.
Сказанное относится не только к удалению, но и вообще любой модификации кода, влекущий изменение его размеров. В ходе оптимизации производительность программы может меняться самым причудливым образом, то повышаясь, то понижаясь без всяких видимых на то причин. Самое неприятное, что подавляющее большинство компиляторов не позволяет управлять выравниванием кода и, если цикл лег по неудачным с точки зрения процессора адресам, все, что нам остается так это добавить в программу еще один кусок кода с таким расчетом, чтобы он вывел цикл из неблагоприятного состояния, либо же просто "перетасовать" код программы, подобрав самую удачную комбинацию.
"Идиотизм какой-то", — скажите вы и будете абсолютно правы. К счастью, тот же MS VC выравнивает адреса функций по адресам, кратным 0x20 (что соответствует размеру одной кэш-линейки на процессорах P6 и K6). Это исключает взаимное влияние функций друг на друга и ограничивает область тасования команд рамками всего "лишь" одной функции.
То же самое относится и к размеру обрабатываемых блоков данных, числу и типу переменных и т. д. Часто бывает так, что уменьшение количества потребляемой программой памяти приводит к конфликтам того или иного рода, в результате чего производительность естественно падает. Причем, при работе с глобальными и/или динамическими переменными мы уже не ограничивается рамками одной отдельно взятой функции, а косвенно воздействуем на всю программу целиком! (см. "Часть II. Конфликт DRAM банков").
Сформулируем три правила, которыми всегда следует руководствоваться при профилировке больших программ, особенно тех, что разрабатываются несколькими независимыми людьми. Представляете — в один "прекрасный" день вы обнаруживаете, что после последних внесенных вами "усовершенствований" производительность вверенного вам фрагмента неожиданно падает… Но, чтобы вы не делали, пусть даже выполнили "откат" к прежней версии, вернуть производительность на место вам никак не удавалось. А на завтра она вдруг — без всяких видимых причин! — сама восстанавливалась до прежнего уровня. Да, правильно, причина в том, что ваш коллега чуть-чуть изменил свой модуль, а это рикошетом ударило по вам!
Итак, обещанные правила:
- никогда–никогда не оптимизируйте программу "вслепую", полагаясь на "здравый смысл" и интуицию;
- каждое внесенное изменение проверяйте на "вшивость" профилировщиком и, если производительность неожиданно упадает, вместо того чтобы увеличиться, незамедлительно устраивайте серьезные "разборки": "кто виноват" и "чья тут собака порылась", анализируя весь, а не только свой собственный код;
- после завершения оптимизации локального фрагмента программы, выполните контрольную профилировку всей программы целиком на предмет обнаружения новых "горячих" точек, появившихся в самых неожиданных местах.
Проблемы оптимизации программ на отдельно взятой машине
Большинство программистов, особенно из тех, что "пасутся на вольных хлебах", имеют в своем распоряжении одну, ну максимум две машины, на которой и осуществляются все стадии создания программы: от проектирования до отладки и оптимизации. Между тем, как уже успел убедиться читатель "что русскому хорошо, то немцу — смерть".
Код, оптимальный для одной платформы, может оказаться совсем неоптимальным для другой. Планирование потоков данных (см. одноименную раздел части II) — яркое тому подтверждение. Ну, вспомните: особенности реализации предвыборки данных в чипсете VIA KT133 приводят к резкому падению производительности при параллельной обработке нескольких близко расположенных потоков. Об этом малоприятном факте умалчивает документация, он не может быть предварительно вычислен логически, — обнаружить его можно лишь экспериментально.
Совершенно недопустимо профилировать программу на одной-единственной машине, — это не позволит выявить все "узкие" места алгоритма. Следует, как минимум, охватить три-четыре типовые конфигурации, обращая внимания не только на модели процессоров, но и чипсетов. Этим вы более или менее застрахуете себя от "сюрпризов", подобных странностям чипсета VIA KT 133, описанным в данной книге.
Сложнее найти компромисс, наилучшим образом "вписывающийся" во все платформы. Вернее, не "сложнее", а вообще невозможно.
Краткий обзор современных профилировщиков
Существует не так уж и много профилировщиков, поэтому особой проблемы выбора у программистов и нет.
Если оптимизация — не ваш основной "хлеб", и эффективность для вас вообще не критична, то вам подойдет практически любой профилировщик, например тот, что уже включен в ваш компилятор. Более сложные профилировщики для вас окажутся лишь обузой, и вы все равно не разглядите заложенный в них потенциал, поскольку это требует глубоких знаний архитектуры процессора и всего компьютера в целом.
Если же вы всерьез озабоченны производительностью и качеством оптимизации ваших программ и планируете посвятить профилировке значительное время, то кроме Intel VTune и AMD Code Analyst вам ничто не поможет. Обратите внимание: не "Intel VTune или AMD Code Analyst", а именно "Intel VTune и AMD Code Analyst". Оба этих профилировщика поддерживают процессоры исключительно "своих" фирм и потому использование лишь одного из них — не позволит оптимизировать программу более чем наполовину.
Тем не менее, далеко не все читатели знакомы с этими продуктами и потому автор не может удержаться от соблазна, чтобы хотя бы кратко не описать их основные возможности.
Intel VTune
Бесспорно, что Vtune — это самый мощный из когда-либо существовавших профилировщиков, во всяком случае, на IBM PC (рис. 1.3). Собственно, его и профилировщиком язык то называть не поворачивается. VTune — это высокоинтеллектуальный инструмент, не только выявляющий "горячие" точки, но еще и дающий вполне конкретные советы по их устранению. В дополнении к этому, VTune содержит весьма не хилый оптимизатор кода, увеличивающий скорость программ, откомпилированных Microsoft Visual C++ 6.0 в среднем на 20%, – согласитесь, такая прибавка производительности никогда не бывает лишней!

Рис. 1.3. Логотип профилировщика VTune
В общем, у профилировщика VTune столько достоинств, что писать о них становится даже как-то и не интересно. Просто воспринимайте его как безальтернативный профилировщик и все! А в настоящем обзоре мы лучше поговорим о его недостатках (ну какая же программа обходится без недостатков?).
Основной недостаток VTune его чрезмерная "тяжелость" (дистрибьютив шестой версии — последней на момент написания этих строк — "весит" аж 150 Мбайт) и весьма впечатляющая стоимость, помноженная на тот факт, что, даже имея деньги, VTune не так-то просто приобрести в России. Правда, Intel предлагает бесплатную полнофункциональную версию, которая ни чем не уступает коммерческой, но работает всего лишь 30 дней. Скачивать такую "тяжесть" ради какого-то месяца работы? Извините, но это несерьезно! (Особенно, если у вас dial-up).
Другой минус — VTune не очень стабилен в работе и частенько "вешает" систему (например, у меня при попытке активизации некоторых счетчиков производительности он загоняет операционную систему в синий экран смерти с надписью "IRQL_NOT_LESS_OR_EQUAL" и хорошо если при этом еще не "грохает" активный Рабочий Стол!). Впрочем, если не лезть "куда не надо" и вообще перед выполнением каждого действия думать головой, то ужиться с VTune все-таки можно (а что делать — ведь достойной альтернативы все равно нет).
Еще VTune получает много нареканий за свою ужасающую сложность. Кажется, что вообще не возможно освоить его и досконально во всем разобраться. Один встроенный "хелп", занимающий свыше трех тысяч страниц формата A4 чего стоит! Попробуйте его прочесть (только прочесть) — даже если вы хорошо владеете английским, то это у вас отнимет, по меньшей мере, целый месяц! Но давайте рассмотрим проблему под другим углом. Вам нужен инструмент или бирюлька? Чем мощнее и гибче инструмент, — тем он сложнее по определению. С моей точки зрения VTune ничуть не сложнее чем тот же Visual C++ или Delphi и проблема заключается не в самой сложности, а в отсутствии литературы по профилировке вообще и данному продукту в частности. Поэтому, в данную книгу включен короткий самоучитель по VTune, который вы найдете в главе "Практический сеанс профилировки с VTune в десяти шагах", — надеюсь, это вам поможет.
AMD Code Analyst
Профилировщик AMD Code Analyst на два порядка уступает своему прямому конкуренту VTune, и я бы ни за что не порекомендовал использовать его в качестве вашего основного профилировщика (рис. 1.4).

Рис. 1.4. Логотип профилировщика AMD Code Analyst
Опасаясь быть побитым агрессивными поклонниками AMD, я все же позволю перечислить основные недостатки профилировщика Code Analyst:
- Во-первых, Code Analyst требует обязательно наличия отладочной информации в профилируемой программе. Программу без отладочной информации он просто откажется загружать! Компиляторы же, в подавляющем своем большинстве, никогда не помещают отладочную информацию в оптимизированные программы. Это объясняется тем, что оптимизация, внося значительные изменения в исходный код, уничтожает прямое соответствие между номерами строк программы и сгенерированными машинными инструкциями. Фактически, оптимизированная и не оптимизированная программа — это две разные программы, имеющие различные, пусть и пересекающиеся, подмножества "горячих" точек. Профилировка не оптимизированного варианта программы принципиально не позволяет найти и устранить все узкие места настоящего приложения. (При отключенной оптимизации узкие места могут быть найдены там, где их и нет).
- Во-вторых, разрешающая способность диаграмм профилировщика Code Analyst ограничивается строками исходного текста программы, но, увы, не машинными командами (как у VTune). И хотя в принципе Code Analyst позволяет определять время выполнения каждой инструкции, он не предоставляет никаких механизмов выделения "горячих" точек на этом уровне. Всю работу по выявлению "тяжеловесных" машинных команд приходится выполнять самостоятельно, "вручную" просматривая столбик цифр колонки CPI (Cycle per Instruction — Циклов на Инструкцию). Надо ли говорить, что даже в относительно небольшом участке программы количество машинных команд может достигать нескольких тысяч и подобный "кустарный" анализ их "температур" может растянуться черт знает на сколько времени.
- В-третьих, Code Analyst не дает никаких советов по ликвидации выявленных узких мест программы, что не очень-то обрадует программистов-новичков (а таковых, как показывает практика, большинство и лишь очень немногие из нас поднаторели в оптимизации).
- В-четвертых, профилировщик Code Analyst просто неудобен в работе. Неразвитая система контекстных меню, крайне не конфигурабельный и вообще аскетичный интерфейс, отсутствие возможности сохранения "хронологии" профилировки… все это придает ему черты незаконченной утилиты, написанной на скорую руку.
Тем не менее, Code Analyst весьма компактен (его последняя на данный момент версия 1.1.0 занимает всего 16 Мбайт, что на порядок меньше VTune), стабилен и устойчив в работе и главное — он содержит полноценный эмулятор процессоров K6-II, Athlon (с внешним и интегрированным кэшем), Duron, включая и их мобильные реализации. Причем, есть возможность вручную выбирать частоту шины и ядра. Это полезно хотя бы для оценки влияния частоты шины на производительность, что особенно актуально для приложений интенсивно работающих с основной оперативной памятью (жалко, но VTune лишен этой "вкусности"). Наконец, Code Analyst содержит толковую справку, сжато и внятно описывающую узкие места процессора. И — самое приятное — он, в отличие от VTune, абсолютно бесплатен (во всяком случае, пока…)!
В конечном счете, независимо от степени своих симпатий (антипатий) к этому профилировщику, правило хорошего тона программирования обязывают использовать его для оптимизации ваших приложений под процессор Athlon, который занимает весьма существенную долю рынка и этим фактом нельзя пренебрегать!
Microsoft profile.exe
Профилировщик Microsoft profile.exe настолько прост и незатейлив, что даже не имеет собственного имени и нам, на протяжении всей книги, придется называть его по имени исполняемого файла (рис. 1.5).
Рис. 1.5. "Визитная карточка" профилировщика Microsoft profile.exe
Profile.exe — чрезвычайно простой и минимально функциональный профилировщик, попадающий в этот обзор лишь потому, что он входит в штатную поставку компилятора Microsoft Visual C++ (редакции — Professional и Enterprise), а потому достается большинству из нас практически даром, в то время как остальные профилировщики приходится где-то искать, скачивать или покупать.
Пишем собственный профилировщик
Какой смыл разрабатывать свой собственный профилировщик, если практически с каждым компилятором уже поставляется готовый? А если возможностей штатного профилировщика окажется недостаточно, то — пожалуйста — к вашим услугам AMD Code Analyst и Intel VTune.
К сожалению, штатный профилировщик Microsoft Visual Studio (как и многие другие подобные ему профилировщики) использует для измерений времени системный таймер, "чувствительности" которого явно не хватает для большинства наших целей. Профилировщик Intel VTune слишком "тяжел" и, кроме того, не бесплатен, а AMD Code Analyst не слишком удобен в работе и нет ни каких гарантий, что завтра за него придется платить. Все это препятствует использованию перечисленных выше профилировщиков в качестве основных инструментов данной книги.
Предлагаемый автором DoCPU Clock, собственно, и профилировщиком язык назвать не поворачивается. Он не ищет "горячие" точки, не подсчитывает количество вызовов, более того, вообще не умеет работать с исполняемыми файлами. DoCPU Clock представляет собой более чем скромный набор макросов, предназначенных для непосредственно включения в исходный текст программы, и определяющих время выполнения профилируемых фрагментов. В рамках данной книги этих ограниченных возможностей оказывается вполне достаточно. Ведь все, что нам будет надо, так это оценить влияние тех или иных оптимизирующих алгоритмов на производительность.
Краткое описание профилировщика DoCPU Clock
Подробное описание профилировщика DoCPU Clock содержится в его исходном файле и по соображениям экономии места здесь не приводится.
Практический сеанс профилировки с VTune в десяти шагах
Любой, даже самый совершенный, инструмент бесполезен, если мастер не умеет держать его в руках. Профилировщик VTune не относится к категории интуитивно-понятных программных продуктов, которые легко осваиваются методом "тыка". VTune — это профессиональный инструмент, и грамотная работа с ним немыслима без специального обучения. В противном случае, большой пласт его функциональных возможностей так и останется незамеченным, заставляя разработчика удивленно пожимать плечами "и что только в этом VTune остальные нашли?".
Настоящая глава, на учебник не претендует, но автор все же надеется, что она поможет сделать вам в освоении VTune первые шаги и познакомиться с его основными функциональными возможностями и к тому же поможет вам решать: стоит ли использовать VTune или же лучше остановить свой выбор на более простом и легком в освоении профилировщике.
В качестве "подопытного кролика" для наших экспериментов с профилировкой и оптимизацией мы используем простой переборщик паролей. Почему именно переборщик? Во-первых, это наглядный и вполне реалистичный пример, а, во-вторых, в программах подобного рода требование к производительности превыше всего. Предвидя возможное негодование некоторых читателей, сразу же замечу, что ни о каком взломе настоящих шифров и паролей здесь речь не идет! Реализованный в программе криптоалгоритм не только нигде не используется в реальной жизни, но к тому же допускает эффективную атаку, раскалывающую зашифрованный текст практически мгновенно.
В первую очередь нас будет интересовать не сам взлом, а техника поиска "горячих" точек и возможные способы их ликвидации. Словом, ничуть не боясь оскорбить свою пуританскую мораль, набейте в редакторе исходный тест следующего содержания:
Листинг 1.14. [Profile/pdsw.cНе оптимизированный вариант парольного переборщика
//----------------------------------------------------------------------
// ЭТО ПРИМЕР ТОГО, КАК НЕ НУЖНО ПИСАТЬ ПРОГРАММЫ! ЗДЕСЬ ДОПУЩЕНО МНОЖЕСТВО
// ошибок, снижающих производительность. Профилировка позволяет найти их все
// ---------------------------------------------------------------------
// КОНФИГУРАЦИЯ
#define ITER 100000 // макс. итераций
#define MAX_CRYPT_LEN 200 // макс. длина шифротекста
// ПРОЦЕДУРА РАСШИФРОВКИ ШИФРОТЕКСТА НАЙДЕННЫМ ПАРОЛЕМ
decrypt(char *pswd, char *crypteddata)
{
int a;
int p = 0; // УКАЗАТЕЛЬ ТЕКУЩЕЙ ПОЗИЦИИ РАСШИФРОВЫВАЕМЫХ ДАННЫХ
// * * * ОСНОВНОЙ ЦИКЛ РАСШИФРОВКИ * * *
do {
// РАСШИФРОВЫВАЕМ ТЕКУЩИЙ СИМВОЛ
crypteddata[p] ^= pswd[p % strlen(pswd)];
// ПЕРЕХОДИМ К РАСШИФРОВКЕ СЛЕДУЮЩЕГО СИМВОЛА
} while(++p < strlen(crypteddata));
}
// ПРОЦЕДУРА ВЫЧИСЛЕНИЯ КОНТРОЛЬНОЙ СУММЫ ПАРОЛЯ
int calculatecrc(char *pswd)
{
int a;
int x = -1; // ОШИБКА ВЫЧИСЛЕНИЯ crc
// АЛГОРИТМ ВЫЧИСЛЕНИЯ crc, КОНЕЧНО, КРИВОЙ КАК БУМЕРАНГ, НО
// ногами чур его не пинать, - это делалось исключительно
// для того, чтобы продемонстрировать missaling
for (a = 0; a < strlen(pswd); a++) x += *(int *)((int)pswd + a);
return x;
}
// ПРОЦЕДУРА ПРОВЕРКИ КОНТРОЛЬНОЙ СУММЫ ПАРОЛЯ
int checkcrc(char *pswd, int validcrc)
{
if (CalculateCRC(pswd) == validCRC)
return validCRC;
// else
return 0;
}
// ПРОЦЕДУРА ОБРАБОТКИ ТЕКУЩЕГО ПАРОЛЯ
do_pswd(char *crypteddata, char *pswd, int validcrc, int progress)
{
char *buff;
// ВЫВОД ТЕКУЩЕГО СОСТОЯНИЯ НА ТЕРМИНАЛ
printf("current pswd : %10s [%d%%]\r",&pswd[0],progress);
// ПРОВЕРКА crc ПАРОЛЯ
if (checkcrc(pswd, validcrc))
{ // <- crc СОВПАЛО
// копируем шифроданные во временный буфер
buff = (char *) malloc(strlen(crypteddata));
strcpy(buff, crypteddata);
// РАСШИФРОВЫВАЕМ
decrypt(pswd, buff);
// ВЫВОДИМ РЕЗУЛЬТАТ РАСШИФРОВКИ НА ЭКРАН
printf("crc %8x: try to decrypt: \"%s\"\n",
CheckCRC(pswd, validCRC),buff);
}
}
// ПРОЦЕДУРА ПЕРЕБОРА ПАРОЛЕЙ
int gen_pswd(char *crypteddata, char *pswd, int max_iter, int validcrc)
{
int a;
int p = 0;
// ГЕНЕРИРОВАТЬ ПАРОЛИ
for(a = 0; a < max_iter; a++)
{
// ОБРАБОТАТЬ ТЕКУЩИЙ ПАРОЛЬ
do_pswd(crypteddata, pswd, validcrc, 100*a/max_iter);
// * ОСНОВНОЙ ЦИКЛ ГЕНЕРАЦИИ ПАРОЛЕЙ *
// по алгоритму "защелка" или "счетчик"
while((++pswd[p])>'z')
{
pswd[p] = '!';
p++; if (!pswd[p])
{
pswd[p]=' ';
pswd[p+1]=0;
}
} // end while(pswd)
// ВОЗВРАЩАЕМ УКАЗАТЕЛЬ НА МЕСТО
p = 0;
} // end for(a)
return 0;
}
// ФУНКЦИЯ ВЫВОДИТ ЧИСЛО, РАЗДЕЛЯЯ РАЗРЯДЫ ТОЧКАМИ
print_dot(float per)
{
// * * * КОНФИГУРАЦИЯ * * *
#define N 3 // отделять по три разряда
#define DOT_SIZE 1 // размер точки-разделителя
#define dot "." // РАЗДЕЛИТЕЛЬ
int a;
char buff[666];
sprintf(buff,"%0.0f", per);
for(a = strlen(buff) - N; a > 0; a -= N)
{
memmove(buff + a + DOT_SIZE, buff + a, 66);
if(buff[a]==' ') break;
else
memcpy(buff + a, DOT, DOT_SIZE);
}
// ВЫВОДИИМ НА ЭКРАН
printf("%s\n",buff);
}
main(int argc, char **argv)
{
// ПЕРЕМЕННЫЕ
FILE *f; // для чтения исходного файла (если есть)
char *buff; // для чтения данных исходного файла
char *pswd; // ТЕКУЩИЙ ТЕСТИРУЕМЫЙ ПАРОЛЬ (need by gen_pswd)
int validcrc; // ДЛЯ ХРАНЕНИЯ ОРИГИНАЛЬНОГО crc ПАРОЛЯ
unsigned int t; // для замера времени исполнения перебора
int iter = iter; // МАКС. КОЛ-ВО ПЕРЕБИРАЕМЫХ ПАРОЛЕЙ
char *crypteddata; // для хранения шифрованных
// build-in default crypt
// КТО ПРОЧТЕТ, ЧТО ЗДЕСЬ ЗАШИФРОВАНО, ТОТ ПОСТИГНЕТ ВЕЛИКУЮ ТАЙНУ
// Крис Касперски ;)
char _data_[] = "\x4b\x72\x69\x73\x20\x4b\x61\x73\x70\x65\x72\x73\x6b"\
"\x79\x20\x44\x65\x6D\x6F\x20\x43\x72\x79\x70\x74\x3A"\
"\xB9\x50\xE7\x73\x20\x39\x3D\x30\x4B\x42\x53\x3E\x22"\
"\x27\x32\x53\x56\x49\x3F\x3C\x3D\x2C\x73\x73\x0D\x0A";
// TITLE
printf( "= = = VTune profiling demo = = =\n"\
"==================================\n");
// HELP
if (argc==2)
{
printf("USAGE:\n\tpswd.exe [StartPassword MAX_ITER]\n");
return 0;
}
// ВЫДЕЛЕНИЕ ПАМЯТИ
printf("memory malloc\t\t");
buff = (char *) malloc(MAX_CRYPT_LEN);
if (buff) printf("+OK\n"); else {printf("-ERR\n"); return -1;}
// ПОЛУЧЕНИЕ ШИФРОТЕКСТА ДЛЯ РАСШИФРОВКИ
printf("get source from\t\t");
if (f=fopen("crypted.dat","r"))
{
printf("crypted.dat\n");
fgets(buff,MAX_CRYPT_LEN, f);
}
else
{
printf("build-in data\n");
buff=_DATA_;
}
// ВЫДЕЛЕНИЕ crc
validcrc=*(int *)((int) strstr(buff,":")+1);
printf("calculate CRC\t\t%X\n",validCRC);
if (!validCRC)
{
printf("-ERR: CRC is invalid\n");
return -1;
}
// ВЫДЕЛЕНИЕ ШИФРОВАННЫХ ДАННЫХ
crypteddata=strstr(buff,":") + 5;
//printf("cryptodata\t\t%s\n",crypteddata);
// ВЫДЕЛЕНИЕ ПАМЯТИ ДЛЯ ПАРОЛЬНОГО БУФЕРА
printf("memory malloc\t\t");
pswd = (char *) malloc(512*1024); pswd+=62;
/* ДЕМОНСТРАЦИЯ ПОСЛЕДСТВИЙ ^^^^^^^^^^^ НЕ ВЫРОВНЕННЫХ ДАННЫХ */
/* размер блока объясняется тем, что при запросе таких блоков */
/* malloc всегда выравнивает адрес на 64 Кб, что нам и надо */
memset(pswd,0,666); // <-- ИНИЦИАЛИЗАЦИЯ
if (pswd) printf("+OK\n"); else {printf("-ERR\n"); return -1;}
// РАЗБОР АРГУМЕНТОВ КОМАНДНОЙ СТРОКИ
// получение стартового пароля и макс. кол-ва итераций
printf("get arg from\t\t");
if (argc>2)
{
printf("command line\n");
if(atol(argv[2])>0) iter=atol(argv[2]);
strcpy(pswd,argv[1]);
}
else
{
printf("build-in default\n");
strcpy(pswd,"!");
}
printf("start password\t\t%s\nmax iter\t\t%d\n",pswd,iter);
// НАЧАЛО ПЕРЕБОРА ПАРОЛЕЙ
printf("==================================\ntry search... wait!\n");
t=clock();
gen_pswd(crypteddata,pswd,iter,validCRC);
t=clock()-t;
// ВЫВОД КОЛ-ВА ПЕРЕБИРАЕМЫХ ПАРОЛЕЙ ЗА СЕК
printf(" \rpassword per sec:\t");
print_dot(iter/(float)t*CLOCKS_PER_SEC);
return 0;
}
Откомпилировав этот пример с максимальной оптимизацией, запустим его на выполнение, чтобы убедиться насколько хорошо справился со своей работой машинный оптимизатор.
Прогон программы на P-III 733 даст скорость перебора всего лишь порядка 30 тысяч паролей в секунду! Да это меньше, чем совсем ничего и такими темпами зашифрованный текст будет "ломаться" ну очень долго! Куда же уходят такты процессора?
Для поиска узких мест программы мы воспользуемся профилировщиком Intel VTune. Запустим его (не забывая, что под Windows 2000/NT он требует для своей работы привилегий администратора) и, тем временем пока компьютер деловито шуршит винчестером, создадим таблицу символов (не путать с отладочной информацией!), без которой профилировщик ни за что не сможет определить какая часть исполняемого кода к какой функции относится. Для создания таблицы символов в командной строке компоновщика (линкера) достаточно указать ключ /profile. Например, это может выглядеть так: link /profile pswd.obj. Если все сделано правильно, образуется файл pswd.map приблизительно следующего содержания:
0001:00000000 _DeCrypt 00401000 f pswd.obj
0001:00000050 _CalculateCRC 00401050 f pswd.obj
0001:00000080 _CheckCRC 00401080 f pswd.obj
Ага, VTune уже готов к работе и терпеливо ждет наших дальнейших указаний, предлагая либо открыть существующий проект — "Open Existing Project" (но у нас нечего пока открывать), либо вызывать Мастера для создания нового проекта — "New Project Wizard" (вот это, в принципе, нам подходит, но сумеем ли мы разобраться в настойках Мастера?), либо же выполнить быстрый анализ производительности приложения — "Quick Performance Analyses", — выбираем последнее! В появившемся диалогом окне указываем путь к файлу pswd.exe и нажимаем кнопку "GO" (то есть "Иди").
VTune автоматически запускает профилируемое приложение и начинает собирать информацию о времени его выполнения в каждой точке программы, сопровождая этот процесс симпатичной змейкой — индикатором. Если нам повезет, и мы не "зависнем", то через секунду-другую VTune распахнет себя на весь экран и выведет несколько окон с полезной и не очень информацией. Рассмотрим их поближе (см. рис. 1.6). В левой части экрана находится Навигатор Проекта, позволяющий быстро перемещаться между различными его части. Нам он пока не нужен и потому сосредоточим все свое внимание в центр экрана, где расположены окна диаграмм.
Верхнее окно показывает сколько времени выполнялась каждая точка кода, позволяя тем самым обнаружить "горячие" точки (Hot Spots), т. е. те участки программы, на выполнение которых уходит наибольшее количество времени. В данном случае профилировщик обнаружил 187 "горячих" точек, о чем и уведомил нас в правой части окна. Обратите внимание на два пика, расположение чуть левее середины центра экрана. Это не просто "горячие", а прямо-таки "адски раскаленные" точечки, съедающие львиную долю быстродействия программы, и именно с их оптимизации и надо начинать!
Подведем курсор к самому высокому пику — VTune тут же сообщит, что оно принадлежит функции out. Постой! Какой out?! Мы ничего такого не вызывали! Кто же вызвал эту "нехорошую" функцию? (Несомненно, вы уже догадались, что это сделала функция printf, но давайте притворимся будто бы мы ничего не знаем, ведь в других случаях найти виновника не так просто).
Рис. 1.6. Содержимое окон VTune сразу же после анализа приложения. В первую очередь нас интересует верхнее окно, "картографирующее" "горячие" точки, расположенные согласно их адресам. Нижнее окно содержит информацию о относительном времени выполнении всех модулей системы. Обратите внимание, модуль pswd.exe (на диаграмме он отмечен стрелкой) занял далеко не первое место и основную долю производительности "съел" кто-то другой. Создается обманчивое впечатление, что оптимизировать модуль pswd.exe бессмысленно, но это не так…
Чтобы не рыскать бес толку по всему коду, воспользуемся другим инструментом профилировщика — "Call Graph", позволяющим в удобной для человека форме отобразить на экране иерархическую взаимосвязь различных функций (или классов, если вы пишите на Си++).
В меню Run выбираем пункт Win32* Call Graph Profiling Session и вновь идем перекурить, пока VTune профилирует приложение. По завершению профилировки на экране появится еще два окна. Верхнее, содержащее электронную таблицу, мы рассматривать не будем (оно понятно и без слов), а вот к нижнему присмотримся повнимательнее. Пастельно-желтый фон украшают всего два ядовито-красных прямоугольника с надписями "Thread 400" и "mainCRTStartup". Щелкнем по последнему из них два раза, — профилировщик VTune тут же выбросит целый веер дочерних функций, вызываемых стартовым кодом приложения. Находим среди них main (что будет очень просто, т. к. только main выделен красным цветом) и щелкаем по нему еще раз…. и будем действовать так до тех пор, пока не раскроем все дочерние функции процедуры main.
В результате выяснится, что функцию out действительно вызывает функция printf, а саму printf вызывает… do_pswd. Ну, да! Теперь мы "вспомнили", что использовали ее для вывода текущего тестируемого пароля на экран! Какая глупая идея! Вот оказывается куда ушла вся производительность!
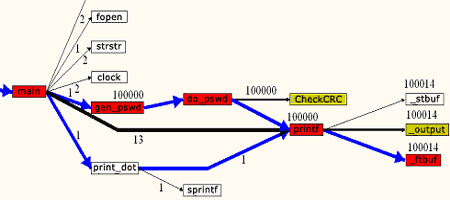
Рис. 1.7. Иерархия "горячих" функций, построенная Мастером Call Graph. Цвет символизирует "температуру" функции, а стоящее возле нее число указывает сколько именно она вызвалась раз
Шаг первый. Удаление printf
Конечно, полностью отказываться от вывода текущего состояния программы — глупо (пользователю ведь интересно знать сколько паролей уже перебрано, и потом надо ведь как-то контролировать машину — не "зависла" ли?), но можно ведь отображать не каждый перебираемый пароль, а скажем, каждый шестисотый, а еще лучше — каждый шеститысячный. При этом накладные расходы на вызов функции printf значительно упадут, а то и вовсе приблизятся к нулю.
Давайте перепишем фрагмент, ответственный за вывод текущего состояния следующим образом (листинг 1.15).
Листинг 1.15. Сокращение количества вызова функции printf
static int x=0;
// ВЫВОД ТЕКУЩЕГО СОСТОЯНИЯ НА ТЕРМИНАЛ
if (++x>6666)
{
x = 0;
printf("Current pswd : %10s [%d%%]\r",&pswd[0],progress);
}
Батюшки мои! После перекомпиляции мы получаем скорость перебора свыше полутора миллионов паролей в секунду! То есть скорость программы возросла более чем в пять раз! Программа выполняется так быстро, что "чувствительности" функции clock уже оказывается недостаточно для измерений и количество итераций приходится увеличивать раз в сто! И это, как мы убедимся в самом непосредственном будущем, еще отнюдь не предел быстродействия!
Шаг второй. Вынос strlen за тело цикла
Повторный запуск "обновленной" программы под профилировщиком показывает, что количество "горячих" точек в ней уменьшилось с 187 до 106. Конечно, это хорошо, но ведь "горячие" точки все еще есть! Кликнув в области Views, расположенной в правом верхнем углу диалогового окна HotSpots in module по переключателю Hotspots by Function (сортировать "горячие" точки по функциями), мы узнаем, что ~80% времени наша программа проводит в недрах функции Calculate CRC, затем с большим отрывом следует gen_pswd — ~12% и по ~3% делят функции Check CRС и do_pswd.
Ну это никуда не годится! Какая-то там жалкая функция Calculate CRC без зазрения совести поглощает практически все быстродействие программы! Эх, вот бы еще узнать, какая именно часть функции в наибольшей степени влияет на производительность. И профилировщик VTune позволяет это сделать!
Дважды кликнем по красному прямоугольнику, чтобы увеличить его на весь экран. Оказывается, внутри функции Calculate CRC насчитывается 18 "горячих" точек, три их которых наиболее "горячи" — ~30%, ~25% и ~10% соответственно (рис. 1.8). Вот с первой из них мы и начнем. Дважды кликнем по самому высокому из прямоугольников и, профилировщик VTune обижено пискнув, сообщит, что "No source found for offset 0x69 into F:\.OPTIMIZE\src\Profil\pswd.exe. Proceed with disassembly only?" ("Исходные тексты не найдены. Продолжать с отображением только дизассемблерного текста?"). Действительно, поскольку программа откомпилирована без отладочной информации, то профилировщик VTune не может знать, какой байт ассемблерного когда, какой строке соответствует, а компилятор не соглашается предоставить эту информацию в силу того, что в оптимизированной программе соответствие между исходным текстом и сгенерированным машинным кодом, в общем-то, не столь однозначно.
Конечно, можно профилировать и не оптимизированную программу, но какой в этом резон? Ведь это будет другая программа и с другими "горячими" точками! В любом случае, качественная оптимизация без знаний ассемблера невозможна, поэтому, прогнав все страхи прочь, смело нажмем на кнопку ОК, то есть "Да, мы соглашаемся работать без исходных текстов непосредственно с ассемблерным кодом".
Рис. 1.8. Распределение "температуры" внутри функции Calculate CRC (снимок сделан с высоким разрешением)
Профилировщик VTune тут же "тыкает нас носом" в инструкцию REPNE SCANB. Не нужно быть провидцем, чтобы распознать в ней ядро функции strlen. Использовали ли мы функцию strlen в исходном тексте программы? А то как же! Смотрим следующий листинг 1.16.
Листинг 1.16. Вызов функции strlen в заголовке цикла привел к тому, что компилятор, не распознав в ней инварианта, не вынес ее из цикла, "благодаря" чему длина одной и той же строки стала подсчитываться на каждой итерации
int calculatecrc(char *pswd)
{
int a;
int x = -1; // ОШИБКА ВЫЧИСЛЕНИЯ crc
for (a = 0; a < strlen(pswd); a++)
x += *(int *)((int)pswd + a);
return x;
}
Судя по всему, бестолковый компилятор не вынес вызов функции strlen за тело цикла, хотя ее аргумент — переменная pswd не модифицировалась в цикле! Хорошо, если гора не идет к Магомету, пойдем навстречу компилятору и перепишем этот участок кода так:
Листинг 1.17. Вынос функции strlen за пределы цикла
int length;
length=strlen(pswd);
for (a = 0; a < length; a++)
Перекомпилировав программу, мы с удовлетворением отметим, что теперь ее быстродействие возросло до трех с половиной миллионов паролей в секунду, т. е. практически в два с половиной раза больше, чем было в предыдущем случае.
Шаг третий. Выравнивание данных
Тем не менее, профилировка показывает, что количество "горячих" точек не только сократилось, но даже и возросло на одну! Почему? Так дело в том, что алгоритм подсчета "горячих" точек учитывает не абсолютное, а относительное быстродействие различных частей программы по отношению друг к другу. И по мере удаления самых больших пиков, на диаграмме появится более мелкая "рябь".
Несмотря на оптимизацию, функция Calculate CRC, по прежнему идет "впереди планеты всей", отхватывая более 50% всего времени исполнения программы. Но теперь самой "горячей" точной становится пара команд:
mov edi, dword ptr [eax+esi]
add edx, edi
Хм! Что же в них такого особенного? Ну да, тут налицо обращение к памяти (x += *(int *)((int)pswd + a)), но ведь тестируемый пароль по идее должен находится в кэше первого уровня, доступ к которому занимает один такт. Может быть, кто-то вытеснил эти данные из кэша? Или произошел какой-нибудь конфликт? Попробуй тут разберись! Можно бесконечно ломать голову, поскольку причина вовсе не в этом коде, а совсем в другой ветке программы.
Вот тут самое время прибегнуть к одному из мощнейших средств профилировщика Vtune, т. е. к динамическому анализу, позволяющему не только определить куда "уходят" такты, но и выяснить причины этого. Причем, динамический анализ выполняется отнюдь не на "живом" процессоре, а на его программном эмуляторе. Это здорово экономит ваши финансы! Для оптимизации вовсе не обязательно приобретать всю линейку процессоров — от Intel 486 до Pentium-4, – вполне достаточно приобрести один профилировщик VTune, и можете запросто оптимизировать свои программы под Pentium-4, имея в наличии всего лишь Pentium-II или Pentium-III.
Перед началом динамического анализа, вам требуется указать какую именно часть программы вы хотите профилировать. В частности, можно анализировать как одну "горячую" точку функции Calculate CRC, так и всю функцию целиком. Поскольку, наша подопечная функция содержит множество "горячих" точек, выберем последний вариант.
Прокручивая экран вверх, переместим курсор в строку с меткой Calculate CRC (метки отображаются в второй слева колонке экрана). Если же такой строки не окажется, найдем на панели инструментов кнопку, с голубым треугольником, направленным вверх (Scroll to Previous Portal) и нажмем ее. Теперь установим точку входа (Dynamic Analyses Entry Pont), которая задается кнопкой с желтой стрелкой, направленной вправо. Аналогичным образом задается и точка выхода (Dynamic Analyses Exit Pont) — прокручивая экран вниз, добираемся до последней строки Calculate CRC (она состоит всего из одной команды — ret) и, пометив ее курсором, нажимаем кнопку с желтой стрелкой, направленной налево. Теперь — "Run\Dynamic Analysis Session". В появившимся диалоговом окне выбираем эмулируемую модель процессора (в нашем случае — P-III) и нажимаем кнопку Start. Поехали!
Профилировщик вновь запустит программу и, погоняя ее минуту-другую, выдаст приблизительно следующее окно (рис. 1.9).
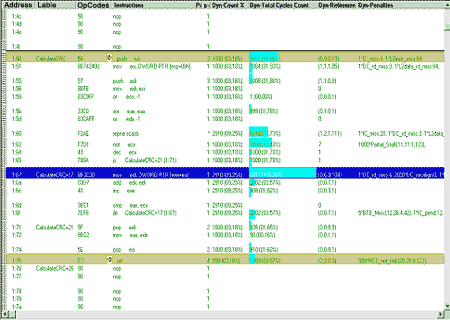
Рис. 1.9. Динамический анализ программы не только определяет "температуру" каждой машинной инструкции, но и объясняет причины ее "нагрева"
Ага! Вот она наша "горячая" точка (на рисунке она отмечена курсором). Двойной щелчок мыши вызывает информационный диалог, подробно описывающий проблему (листинг 1.18).
Листинг 1.18.
decoder minimum clocks = 0, ; // МИНИМАЛЬНОЕ ВРЕМЯ ДЕКОДИРОВАНИЯ 0 ТАКТОВ
Decoder Average Clocks = 0.7 ; // Среднее время декодирования 0.7 тактов
Decoder Maximum Clocks = 14 ; // Максимальное время декодирования 14 тактов
retirement minimum clocks = 0, ; // МИНИМАЛЬНОЕ ВРЕМЯ ЗАВЕРШЕНИЯ 0 ТАКТОВ
retirement average clocks = 6.9 ; // СРЕДНЕЕ ВРЕМЯ ЗАВЕРШЕНИЯ 6.9 ТАКТОВ
Retirement Maximum Clocks = 104 ; // Максимальное время завершения 104 такта
total cycles = 20117 (35,88%) ; // ПОЛНОЕ ВРЕМЯ ИСПОЛНЕНИЯ 20.117 ТАКТОВ (35,88%)
Micro-Ops for this instruction = 1 ; // ИНСТРУКЦИЯ ДЕКОДИРУЕТСЯ В ОДНУ МИКРООПЕРАЦИЮ
// ИНСТРУКЦИЯ ЖДАЛА (0, 0.1, 2) ЦИКЛА ПОКА ЕЕ ОПЕРАНДЫ НЕ БЫЛИ ГОТОВЫ
the instruction had to wait (0,0.1,2) cycles for it's sources to be ready
warnings: 3*decode_slow:0 ; // КОНФЛИКТОВ ДЕКОДЕРОВ – НЕТ
Dynamic Penalty: DC_rd_miss
The operand of this load instruction was not in the data cache. The instruction stalls while the processor loads the specified address location from the L2 cache or main memory.
(Операнд этой инструкции отсутствовал в кэше данных. Инструкция ожидала пока процессор загрузит соответствующие данные из кэша второго уровня или основной памяти).
occurrences = 1 ; // СЛУЧАЛОСЬ ОДИН РАЗ
Dynamic Penalty: DC_misalign
The instruction stalls because it accessed data that was split across two data-cache lines.
(Инструкция простаивала, потому что она обращалась к данным "расщепленным" через две кэш-линии)
Occurrences = 2000 ; // СЛУЧАЛОСЬ 2000 РАЗ
Dynamic Penalty: L2data_rd_miss
The operand of this load instruction was not in the L2 cache. The instruction stalls while the processor loads the specified address location from main memory.
(Операнд этой инструкции отсутствовал в кэше второго уровня. Инструкция ожидала пока процессор загрузит соответствующие данные из основной памяти).
occurrences = 1 ; // СЛУЧАЛОСЬ ОДИН РАЗ
Dynamic Penalty: No_BTB_info
The BTB does not contain information about this branch. The branch was predicted using the static branch prediction algorithm.
(BTB – Branch Target Buffer – буфер ветвлений не содержал информацию об этом ветвлении. Ветка была предсказана статическим алгоритмов предсказаний).
occurrences = 1 ; // СЛУЧАЛОСЬ ОДИН РАЗ
Какая богатая кладезь информации! Оказывается, кэш тут действительно не причем (кэш-промах произошел всего один раз), а основной виновник — доступ к не выровненным данным, который имел место аж 2000 раз, — именно столько, сколько и прогонялась программа. Таким образом, такое происшествие случалось на каждой итерации цикла — отсюда и "тормоза".
Смотрим, — где в программе инициализируется указатель pswd? Ага, вот фрагмент кода из тела функции main (надеюсь, теперь вам понятно, почему статический анализ функции Calculate CRC был неспособен что-либо дать?):
Листинг 1.19. Выравнивание парольного буфера для предотвращения штрафных санкций со стороны процессора
pswd = (char *) malloc(512*1024);
pswd+=62;
Убираем строку pswd += 62 и перекомпилируем программу. Теперь быстродействие соствило четыре с половиной миллиона паролей в секунду! Держи тигра за хвост!
Шаг четвертый. Избавление от функции strlen
Возвращаясь к рис. 1.9 отметим, что обращение к не выровненным данным — не единственная "горячая" точка функции Calculate CRC. С небольшим отрывом за ней следует инструкция PUSH, временно сохраняющая регистры в стеке и… опять та противная функция strlen с которой мы уже сталкивались.
Действительно, вычисление длины пароля вполне сопоставимо по времени с подсчетом его контрольной суммы. Вот если бы этого удалось избежать. А для чего собственно, вообще вычислять длину каждого пароля? Ведь пароли перебираются не хаотично, а генерируются по вполне упорядоченной схеме и приращение длины пароля на единицу происходит не так уж и часто. Так, может быть, лучше возложить эту задачу на функцию gen_pswd? Пусть при первом же вызове она определяет длину начального пароля, а затем при "растяжке" строки увеличивает глобальную переменную length на единицу. Сказано — сделано.
Теперь код функции gen_pswd выглядит так:
Листинг 1.20. Удаление функции strlen и "ручное" приращение длины пароля при его удлинении на один символ
int a;
int p = 0;
length = strlen(pswd); // ОПРЕДЕЛЕНИЕ ДЛИНЫ НАЧАЛЬНОГО ПАРОЛЯ
…
if (!pswd[p])
{
pswd[p]=' ';
pswd[p+1]=0;
length++; // "РУЧНОЕ" УВЕЛИЧЕНИЕ ДЛИНЫ ПАРОЛЯ
}
…
А код функции Calculate CRC так:
Листинг 1.21. Использование глобальной переменной для определения длины пароля
for (a = 0; a <= length; a++)
В результате этих нехитрых преобразований мы получаем скорость в восемь миллионов паролей в секунду. Много? Подождите! Самое интересное еще только начинается…
Шаг пятый. Удаление операции деления
Теперь на первое место вырывается функция gen_pswd, в которой процессор проводит более половины всего времени исполнения программы.
За gen_pswd с большим отрывом следуют функции Calculate CRC — ~21% и Check CRC — ~15%. Причем, ~40% от общего времени исполнения функции gen_pswd сосредоточено в одной–единственной "горячей" точке. Непорядок! Надо бы оптимизировать!
Двойной щелчок по высоченному прямоугольнику приводит нас к инструкции IDIV, выполняющий целочисленное деление. Постой, постой, а где у нас в gen_pswd целочисленное деление? А вот, уже нашли!
do_pswd(crypteddata, pswd, validCRC, 100*a/max_iter);
Здесь мы вычисляем процент проделанной работы. Забавно, но на это уходит приблизительно столько же времени, сколько и на саму работу! А раз так — ну все эти "градусники" к черту! Удаляем команду деления, подставляя вместо значения прогресса "0" или любое другое понравившееся вам число.
Перекомпилируем, и в результате получаем скорость в четырнадцать с половиной миллионов паролей в секунду!
Шаг шестой. Удаление мониторинга производительности
Несмотря на прямо-таки гигантскую скорость перебора, функция gen_pswd все еще оттягивает на себя ~22% времени исполнения программы, что не есть хорошо.
Двойной щелчок по ней показывает, что среди более или менее ровного ряда практически одинаковых по высоте диаграмм, возвышается всего лишь один красный прямоугольник. А ну-ка посмотрим что там!
Дизассемблирование позволяет установить, что за этой "горячей" точкой скрывается уже знакомая нам конструкция:
if (++x>66666)
{
x = 0;
printf("Current pswd : %10s [%d%%]\r",&pswd[0],progress);
}
Что ж! Во имя Ее Величества Производительности, мы решаемся полностью отказаться от мониторинга текущего состояния, и выбрасываем эти шесть строк напрочь.
В результате скорость перебора повышается еще на пять миллионов паролей в секунду. Хм, вообще-то не такая уж и большая прибавка, так что не факт, что такую оптимизацию следовало бы выполнять.
Шаг седьмой. Объединение функций
На этот раз самой "горячей" точкой становится сохранение регистра ESI где-то глубоко внутри функции Calculate CRC. Это компилятор "заботливо" бережет его содержимое от посторонних модификаций. Несмотря на то, что количество используемых переменных в программе довольно невелико и в принципе обращений к памяти можно было бы и избежать, разместив все переменные в регистрах, компилятор не в состоянии этого сделать, т. к. оптимизирует каждую функцию по отдельности.
Так давайте же, забыв про структурность, объединим все наиболее интенсивно используемые функции (gen_pswd, do_paswd, Check CRC и Calculate CRC) в одну "супер-функцию".
Ее реализация может выглядеть, например, так:
Листинг 1.22. Объединение функций gen_pswd, do_paswd, Check CRC и Calculate CRC в одну супер-функцию
int gen_pswd(char *crypteddata, char *pswd, int max_iter, int validcrc)
{
int a, b, x;
int p = 0;
char *buff;
int length = strlen(pswd);
for(a = 0; a < max_iter; a++)
{
x = -1; for (b = 0; b <= length; b++) x += *(int *)((int)pswd + b);
if (x==validCRC)
{
buff = (char *) malloc(strlen(crypteddata));
strcpy(buff, crypteddata); DeCrypt(pswd, buff);
printf("CRC %8X: try to decrypt: \"%s\"\n", validCRC,buff);
}
while((++pswd[p])>'z')
{
pswd[p] = '!'; p++; if (!pswd[p])
{
pswd[p]=' '; pswd[p+1]=0;length++;
}
}; p = 0;
}
return 0;
}
Компилируем, запускаем… ой! прямо не верим своим глазам — тридцать пять миллионов паролей в секунду! А ведь казалось, что резерв быстродействия уже исчерпан. Ну и кто теперь скажет, что Pentium — медленный процессор? Генерация очередного пароля, вычисление и проверка его контрольной суммы укладывается в каких-то двадцать тактов…
Двадцать тактов?! Хм! Тут еще есть над чем поработать!
Шаг восьмой. Сокращения операций обращение к памяти
Основная масса "горячих" точек теперь, как показывает профилировка, сосредоточена в цикле подсчета контрольной суммы пароля — на него приходится свыше 80% всего времени исполнения программы, из них 50% "съедает" условный переход, замыкающий цикл (Pentium-процессоры очень не любят коротких циклов и условных переходов), а остальные 50% расходуются на обращение к кэш-памяти. Тут уместно сделать небольшое пояснение.
Расхожее мнение утверждает, что чтение нерасщепленных данных, находящихся в кэш-памяти занимает всего один такт, — ровно столько же, сколько и чтение содержимого регистра. Это действительно так, но при более пристальном изучении проблемы выясняется, что "одна ячейка за такт", это пропускная способность кэш памяти, а полное время загрузки данных с учетом латентности составляет как минимум три такта. При чтении зависимых данных из кэша (как в нашем случае) полное время доступа к ячейке определяется не пропускной способностью, а его латентностью. К тому же, на процессорах семейства P6 установлено всего лишь одно устройство чтения данных и поэтому, даже при благоприятном стечении обстоятельств они могут загружать всего лишь одну ячейку за такт. Напротив, на данные, хранящиеся в регистрах, это ограничение не распространяется.
Таким образом, для увеличения производительности мы должны избавиться от цикла и до минимума сократить количество обращений к памяти. К сожалению, мы не можем эффективно развернуть цикл, поскольку нам заранее неизвестно количество его итераций. Аналогичная ситуация складывается и с переменными: программируя на ассемблере, мы запросто смогли бы разместить парольный буфер в регистрах общего назначения (благо 16-символьный пароль — самый длинный пароль, который реально найти перебором — размешается всего в четырех регистрах, а в остающихся трех регистрах располагаются все остальные переменные). Но для прикладных программистов, владеющих одним лишь языком высокого уровня, этот путь закрыт и им приходится искать другие решения.
И такие решения действительно есть! До сих пор мы увеличивали скорость выполнения программы за счет отказа от наиболее "тяжеловесных" операций, практически не меняя базовых вычислительных алгоритмов. Этот путь привел к колоссальному увеличению производительности, но сейчас он себя исчерпал и дальнейшая оптимизация возможна лишь на алгоритмическом уровне.
В алгоритмической же оптимизации нет и не может быть универсальных советов и общих решений, — каждый случай должен рассматриваться индивидуально, в контексте своего окружения. Возвращаясь к нашим баранам, задумаемся: а так ли необходимо считать контрольные суммы каждого нового пароля? В силу слабости используемого алгоритма подсчета CRC, его можно заменить другим, — более быстродействующим, но эквивалентным алгоритмом.
Действительно, поскольку младший байт пароля суммируется всего лишь один раз, то при переходе к следующему паролю его контрольная сумма в большинстве случаев увеличивается ровно на единицу. Именно "в большинстве" — потому, что при изменении второго и последующих байтов пароля, модифицируемый байт уже суммируется как минимум дважды, к тому же постоянно попадает то в один, то в другой разряд. Это немного усложняет наш алгоритм, но все же не оставляет его далеко впереди "тупой" методики постоянного подсчета контрольной суммы, используемой ранее.
Словом, финальная реализация улучшенного переборщика паролей может выглядеть так:
Листинг 1.23. Алгоритмическая оптимизация алгоритма просчета CRC

Какой результат дала алгоритмическая оптимизация? Ни за что не догадаетесь — восемьдесят три миллиона паролей в секунду или ~1/10 пароля за такт. Фантастика!
И это при том, что программа написана на чистом Си! И ведь самое забавное, что хороший резерв производительности по-прежнему есть!
Шаг девятый. VTune — ваш персональный тренер
А теперь мы обратимся к наименее известному средству профилировщика VTune — Инструктору (в оригинале Coach так же переводимое как "тренер" или "учитель").
Фактически Инструктор — это ни что иное как высококлассный интерактивный оптимизатор, поддерживающий целый ряд языков: C, C++, Fortran и Java. Он анализирует исходный текст программы на предмет поиска "слабых" мест, а, обнаружив такие, дает подробные рекомендации по их устранению.
Разумеется, интеллектуальность Инструктора не идет ни в какое сравнение с сообразительностью живого программиста и вообще, как мы увидим в дальнейшем, Инструктор скорее туп, чем умен… и все-таки рассмотреть его поближе будет небесполезно.
Несмотря на то, что Инструктор в первую очередь ориентирован на программистов-новичков (на что указывает полностью "разжеванный" стиль подсказок), и для профессионалов он под час оказывается не лишним, особенно когда приходится оптимизировать чужой код, в котором лень досконально разбираться.
Плохая новость (впрочем, ее и следовало ожидать) — при отсутствии отладочной информации в профилируемой программе инструктор не может работать с исходным текстом и опускается на уровень чистого ассемблера (см. разд. "Шаг десятый. Заключительный"). Тем не менее, это обстоятельство не доставляет непреодолимых неудобств, т. к. текст программы именно анализируется, а не профилируется. Поэтому, пусть вас не смущает, что включение в исполняемый файл отладочной информации приводит к автоматическому "вырубанию" всех оптимизирующих опций компилятора. Инструктор, работая с исходным текстом программы, вообще не будет касаться скомпилированного машинного кода!
Итак, перекомпилируем наш демонстрационный пример, добавив ключ /Zi в командную строку компилятора и ключ /DEBIG — в командную строку линковщика. Загрузим полученный файл в VTune и, дождавшись появления диаграммы "Hot Spots", дважды щелкнем мышкой по самому высокому прямоугольнику, соответствующему, как мы уже знаем, функции gen_pswd, в которой программа проводит большую часть своего времени.
Теперь, удерживая левую клавишу мыши, выделяем тот фрагмент, который мы хотим проанализировать (логичнее всего выделить всю функцию gen_pswd целиком) и отыскиваем на панели инструментов такую довольно затейливую кнопку с изображением учителя, облаченного в красную рубаху, и коричневой ученической доски на заднем фоне. Нажмем ее. Инструктор запросит сведения о файле, которым компилировалась данная программа. На выбор предоставляется make-файл, файл препроцессора и, конечно же, как и во всякой профессиональной программе, возможность ручного ввода. Поскольку никаких особенных опций компиляции мы не задавали, а make-файла у нас все равно нет, мы выбираем "Manual Entry" и нажимаем кнопку OK. Пропускаем появившееся на экран ругательство — "No source option were specified" ("Исходные опции не были заданы") и жмем кнопку OK еще раз.
Профилировщик VTune тут же начнет анализ и буквально через несколько секунд не без удовлетворения сообщит: "There are 9 recommendations identified for the selected code. Double-Click on any advice for additional information" ("В выделенном коде распознано девять “рекомендательных шаблонов”. Для получения дополнительной информации дважды щелкните по любому совету"). Оказывается, в нашей уже далеко "не хило" оптимизированной программе все еще присутствует, по меньшей мере, девять слабых мест! И не просто слабых, а настолько слабых, что они обнаруживаются тривиальным шаблонным поиском! Ну и мы и "молодцы", — нечего сказать!
Ладно, кончаем заниматься самобичеванием, а лучше посмотрим, что этот умник VTune тут нагородил. Рекомендации инструктора записаны прямо поверх кода программы и первое замечание, выглядит следующим образом:
84 for (b = 0; b <= length; b++)
85 x += *(int *)((int)pswd + b);
The loop at line 84 can be unrolled 4 times .
"Цикл в строке 84 может быть развернут четыре раза". Глупый VTune! Этот цикл исполняется всего лишь раз за весь прогон программы и особой "погоды" его оптимизация не сделает! Кстати, а что такое "развертка циклов" и как ее осуществить? Дважды щелкаем по выделенной строке, и Инструктор имеет честь сообщить нам следующее:
Loop unrolling
Examples: C, Fortran, Java*
The loop contains instructions that do not allow efficient instruction scheduling and pairing. The instructions are few or have dependencies that provide little scope for the compiler to schedule them in such a manner as to make optimal use of the processor's multiple pipelines. As a result, extra clock cycles are needed to execute these instructions.
Advice
Unroll the loop as suggested by the coach. Create a loop that contains more instructions, but is executed fewer times. If the unrolling factor suggested by the coach is not appropriate, use an unrolling factor that is more appropriate.
To unroll the loop, do the following:
– Replicate the body of the loop the recommended number of times.
– Adjust the index expressions to reference successive array elements.
–Adjust the loop control statements.
Result:
– Increases the number of machine instructions generated inside the loop.
– Provides more scope for the compiler to reorder and schedule instructions so that they pair and execute simultaneously in the processor's pipelines.
– Executes the loop fewer times.
Caution:
Be aware that increasing the number of instructions within the loop also increases the register pressure.
В переводе на русский язык все вышесказанное будет звучать приблизительно таким образом:
Разворачивание цикла:
Данный цикл содержит инструкции, которые не могут быть эффективно спланированы и распараллелены процессором, поскольку они малочисленны [то бишь кворума мы здесь не наберем – КК] или содержат зависимости, что сужает возможности компилятора в их группировке для достижения наиболее оптимального использования конвейеров процессора. В результате, на выполнение этих инструкций расходуется значительно большее количество циклов.
Совет:
Разверните цикл, согласно советам "Учителя". Создайте цикл, такой чтобы он содержал больше инструкций, но исполнялся меньшее количество раз. Если степень развертки, рекомендуемая "Учителем", кажется вам неподходящей, используйте более подходящую степень.
Для развертки цикла сделайте следующее:
– Продублируйте тело цикла соответствующее количество раз;
– Скорректируйте ссылки на продублированные элементы массива;
– Скорректируйте условие цикла.
Результат:
– Увеличивается количество машинных инструкций внутри цикла;
– Появляется место, где "развернуться" компилятору для переупорядочивания и планирования потока инструкций так, чтобы они спаривались и выполнялись параллельно в конвейерах процессора.
– Выполнение цикла занимает меньшее время.
Предостережение:
Знайте, что увеличение количества инструкций в теле цикла влечет за собой увеличение "регистрового давления".
Согласитесь, весьма исчерпывающее руководство по развертке циклов! Причем, если вам все равно не понятно как именно разворачиваются циклы, можно кликнуть по ссылке "Examples" (примеры) и увидеть конкретный пример "продразверстки" на Си, Java или Fortran. Давайте выберем язык Си и посмотрим, что нам еще посоветует профилировщик VTune:
Original Code Optimized Code
for(i=0; i<n; i++) for(i=0; i<n-(n%3); i+=3)
a[i] = c[i] ; {
a[i] = c[i] ;
a[i+1] = c[i+1];
a[i+2] = c[i+2];
}
for(i;i < n; i++)
a[i] = c[i];
Тем не менее, мы этот цикл разворачивать не будем и пойдем дальше.
Совет номер два вновь рекомендует развернуть тот же самый цикл, но уже находящийся внутри цикла while. Поскольку, этот цикл получает управление лишь при удлинении перебираемого пароля на один символ (что происходит прямо-таки скажем не часто) он, как и предыдущий, не оказывает практически никакого влияния на производительность, а потому рекомендацию по его развороту мы отправим в /dev/null.
Совет номер три придирается к с виду безобидной конструкции p++, увеличивающий переменную p на единицу:
114 p++;
115 if (!pswd[p])
116 {
117 pswd[p]='!';
118 pswd[p+1]=0;
119 length++;
120 x = -1;
121 for (b = 0; b <= length; b++)
122 x += *(int *)((int)pswd + b);
The loop whose index is incremented at line 114 should be interchanged with the loop whose index is incremented at line 121, for more efficient memory access
"Для достижения более эффективного доступа [к памяти] цикл, чей индекс увеличивается в строке 114, должен быть заменен циклом, чей индекс увеличивается в строке 121"?! Инструктор, судя по всему или "пьян", или от перегрева процессора слегка "спятил". Это вообще разные циклы. И индексы у них разные. И вообще они не имеют друг к другу никакого отношения, причем цикл, расположенный в строке 121, исполняется редко, так что совсем не понятно, что это профилировщик VTune к нему так пристал?!
Может быть, дополнительная информация от Инструктора все разъяснит? Дважды щелкаем по строке 114 и читаем:
Loop interchange:
Loops with index variables referencing a multi-dimensional array are nested. The order in which the index variables are incremented causes out-of-sequence array referencing, resulting in many data cache misses. This increases the loop execution time.
Advice:
Do the following:
– Change the sequence of the array dimensions in the array declaration.
– Interchange the loop control statements.
Result:
The order in which the array elements are referenced is more sequential. Fewer data cache misses occur, significantly reducing the loop execution time.
Перестановка циклов:
Здесь наблюдается вложенные циклы с индексными переменными, обращающимися к многомерным массивам, Порядок, в котором увеличиваются индексные переменные, приводит к несвоевременному обращению к массивам, и как следствие этого — множественным кэш-промахам. В результате увеличивается время выполнения цикла.
Совет:
Сделайте следующее:
– Измените последовательность измерений массивов в их объявлении;
– Поменяйте местами "измерения" управления цикла
[подразумевается: сделайте либо то, либо это, но ни в коем случае ни то и другое вместе — иначе "минус на минус даст плюс" и вы получите тот же самый результат — КК]
Результат:
Порядок, в котором обрабатываются элементы массива, станет более последовательным. Меньше кэш-промахов будет происходить, от чего время выполнения цикла значительно сократиться.
Какие многомерные массивы? Какие кэш-промахи? Здесь у нас и близко нет ни того, ни другого! Судя по всему, мы столкнулись с грубой ошибкой Инструктора (шаблонный поиск дает о себе знать!), но все же не поленимся, и заглянем в предлагаемый Инструктором пример, памятуя о том, что всегда в первую очередь следует искать ошибку у себя, а не у окружающих. Быть может, это мы чего-то недопонимаем…
|
Original Code |
Optimized Code |
|
|
int b[200][120]; void xmpl17(int *a) { int i, j;
for (i = 0; i < 120; i++) for (j = 0; j < 200; j++)
b[j][i]=b[j][i]+a[2*j];
} |
int b[200][120]; void ympl17(int *a) { int i, j; int atemp;
for (j = 0; j < 200; j++) for (i = 0; i < 120;i++)
b[j][i]=b[j][i]+a[2*j];
}
|
Ну вот, все правильно. Приводимый профилировщиком VTune фрагмент кода наглядно демонстрирует, что двухмерные массивы лучше обрабатывать по строкам, а не столбцам (см. "Часть III. Подсистема кэш-памяти"). Но ведь у нас нет двухмерных массивов, а — стало быть — и слушаться Инструктора в данном случае не надо.
Совет номер четыре и снова этот несчастный цикл подсчета контрольной суммы. Ну понравился он Инструктору — что поделаешь! Что же ему не понравилось на этот раз? Читаем…
121 for (b = 0; b <= length; b++)
122 x += *(int *)((int)pswd + b);
123 pswd[p]=' ';
124 y = 0;
125 }
126 } // end while(pswd)
Use the Intel C/C++ Compiler vectorizer to automatically generate highly optimized SIMD code. The statement on line 122 and others like it will be vectorized if the following program changes are made (double-click on any line for more information):
==> Simplify the pointer expression to indicate contiguous array accesses.
==> Restructure the loop to isolate the statement or construct that interferes with vectorization.
==> Try loop interchanging to obtain vector code in the innermost loop.
==> Simplify the pointer expression to indicate contiguous array accesses.
Используйте векторизатор компилятора Intel С/C++ для автоматической генерации высоко оптимизированного SIMD-кода. Оператор, находящийся в линии 122 и остальные подобные ему операторы, будут векторизованы при условии следующих изменений программы:
==> Упростите выражение указателя для индикации смежных доступов к массиву;
==> Реструктурируйте цикл для отделения выражения или логической конструкции, препятствующей векторизации;
==> Попытайтесь перестроить цикл для получения векторного кода во вложенном цикле;
==> Упростите выражение указателя для индикации смежных доступов к массиву;
Хорошие, однако, советы! А рекомендация упростить и без того примитивную форму адресации повторяется аж два раза! И это при том, что эффективно векторизовать данный цикл все равно не получится даже на Intel C/C++, а уж про все остальные компиляторы я и вовсе промолчу.
Тем не менее, все-таки заглянем за помощью — может быть, что-нибудь интересное скажут!?
Intel C++ Compiler Vectorizer
The coach has identified an assignment or expression that is a candidate for SIMD technology code generation using Intel C++ Compiler vectorizer.
Advice
Use the Intel C++ Compiler vectorizer to automatically generate highly optimized SIMD code wherever appropriate in your application. Use the following syntax to invoke the vectorizer from the command line: prompt> icl -O2 -QxW myprog.cpp.
The -QxW command enables vectorization of source code and provides access to other vectorization-related options.
Result
The Intel C++ Compiler vectorizer optimizes your application by processing data in parallel, using the Streaming SIMD Extensions of the Intel processors. Since the Streaming SIMD Extensions that the class library implements access and operate on 2, 4, 8, or 16 array elements at one time, the program executes much faster.
Векторизатор компилятора Intel C++
Инструктор идентифицировал присвоение или выражение, являющееся кандидатом для генерации кода по SIMD-технологии, используемой векторизатором компилятора Intel C++.
Совет:
Используйте векторизатор компилятора Intel C++ для автоматической генерации высоко оптимизированного SIMD-кода, подходящего к вашему приложению. Используйте следующий синтаксис для вызова векторизатора из командной строки: icl –O2 QxW myprog.cpp.
Ключ "-QxW" разрешает векторизацию исходного кода и предоставляет доступ к остальным векторным опциям.
Результат:
Векторизатор компилятора Intel C++ оптимизирует ваше приложение путем парализации обработки данных, с использованием поточного SIMD-расширения команд процессоров Intel. С тех пор как потоковые SIMD расширения библиотеки классов осуществляют доступ и обработку 2, 4, 8 или 16 элементов массива за один раз, скорость выполнения программы весьма значительно возрастает.
Бесспорно, векторизация — полезная штука, действительно позволяющая многократно увеличить скорость работы программы, но ее широкому внедрению в массы препятствует, по меньшей мере, два минуса: во-первых, подавляющее большинство x86-компиляторов не умеют векторизовать код, а переход на компилятор Intel не всегда приемлем. Во-вторых, векторизация будет по настоящему эффективна лишь в том случае, если программа изначально предназначалась под эту технологию. И хотя в мире "больших" машин векторизация кода известна уже давно, для x86-программистов это еще тот конек!
Совет номер пять или еще один просчет Инструктора. Так, посмотрим, что за перл выдал Инструктор на этот раз.
91 if (x==validcrc)
92 {
93 // КОПИРУЕМ ШИФРОДАННЫЕ ВО ВРЕМЕННЫЙ БУФЕР
94 buff = (char *) malloc(strlen(crypteddata));
95 strcpy(buff, crypteddata);
96
97 // РАСШИФРОВЫВАЕМ
98 decrypt(pswd, buff);
99
The argument list for the function call to _malloc on line 94 appears to be loop-invariant. If there are no conflicts with other variables in the loop, and if the function has no side effects and no external dependencies, move the call out of the loop.
(Список аргументов функции malloc, находящейся в строке 94, вероятно, инвариантен относительно цикла. Если это не вызовет конфликта с остальными переменными цикла, и если не будет иметь посторонних эффектов и внешних зависимостей, вынесите ее за пределы цикла).
Вообще-то, формально Инструктор прав. Вынос инвариантных функций из тела цикла — это хороший тон программирования, поскольку, находясь в теле цикла, функция вызывается множество раз, но, в силу своей независимости от параметров цикла, при каждом вызове она дает один и тот же результат. Действительно, не проще ли единожды выделив память при входе в функцию, просто сохранить возращенный указатель функции malloc в специальной переменной, а затем использовать его по мере необходимости?
Возражение номер один: ну и что мы в результате этого получим? Данная ветка вызывается лишь при совпадении контрольной суммы текущего перебираемого пароля с эталонной контрольной суммой, что происходит крайне редко — в лучшем случае несколько раз за все время выполнения программы.
Возражение номер два: перефразируя известный анекдот "я девушку кормил-поил, я ее и танцевать буду" можно сказать "та ветвь программы, которая выделила блок памяти, сама же его и освобождает, конечно, если это не приводит к неоправданному снижению производительности".
Таким образом, ничего за пределы цикла мы выносить не будем, что бы там нам не советовал Инструктор.
Совет номер шесть. Данный совет практически полностью повторяет предыдущий, однако, на этот раз, Инструктор посоветовал вынести за пределы цикла функцию De Crypt. Да, да! Счел ее инвариантом и посоветовал вынести куда подальше и это не смотря на то, что: а) код самой функции в принципе был в его распоряжении ("в принципе" потому, что мы приказали Инструктору анализировать только функцию gen_pswd). б) функции De Crypt передается указатель pswd, который явным образом изменяется в цикле! А раз так, то инвариантом функция De Crypt быть ну никак не может! И как только Инструктору не стыдно давать такие советы? Или все-таки стыдно — а вы думали почему он красный такой?
Совет номер семь. Сейчас Инструктор обращает наше внимание, на то, что: "The value returned by De Crypt() on line 98 is not used…" ("Значение, возвращаемое функцией De Crypt, расположенной в строке 98, не используется...") и дает следующий совет "If the return value is being ignored, write an alternate version of the function which returns void" ("Если возвращенное значение игнорируется, создайте альтернативную версию данной функции, возвращающей значение void").
В основе данного совета лежит допущение Инспектора, что функция, не возвращающая никакого значения, будет работать быстрее функции такое значение возвращающей. На самом же деле это более чем спорно. Возврат значения занимает не так уж много времени, и создание двух экземпляров одной функции реально обходится много дороже, чем накладные расходы на возврат никому не нужного значения.
Так что игнорируем этот совет и идем дальше.
Совет номер восемь. Теперь Инспектор принял за инвариант функцию printf, распечатывающую содержимое буфера buff, только что возвращенного функцией De Crypt. Мм… не ужели разработчикам профилировщика VTune было трудно заложить в "голову" Инспектора смысловое значение хотя бы основных библиотечных функций? Функция printf не зависимо от того является ли она инвариантом или нет, никогда не может быть вынесена за пределы цикла! И вряд ли стоит объяснять почему.
Совет номер девять. …Значение, возвращаемое функций printf не используется, поэтому…
Что ж! Результатами такого инструктажа трудно остаться удовлетворенным. Из девяти советов мы не воспользовались ни одним, поскольку это все равно бы не увеличило скорость выполнения программы. Тем не менее, Инструктора не стоит считать совсем уж никчемным чукчей. Во всяком случае, он рассказывает о действительно интересных и эффективных приемах оптимизации, не все из которых известны новичкам.
Возможно мне возразят, что такая непроходимая тупость Инструктора объясняется тем, что мы подсунули ему уже до предела оптимизированную программу и ему ничего не осталось, как придираться к второстепенным мелочам. Хорошо, давайте напустим Инструктора на самый первый вариант программы, заставив его проанализировать весь код целиком. Он сделает нам 33 замечания, из которых полезных по-прежнему не окажется ни одного!
Шаг десятый. Заключительный
Все оставшиеся 17 "горячих" точек представляют собой издержки обращения к кэш-памяти и… штрафные такты ожидания за неудачную с точки зрения процессора группировку команд. Ладно, оставим обращения к памяти в стороне, вернее отдадим эту задачу на откуп неутомимым читателям (задумайтесь: зачем вообще теперь генерировать пароли, если их контрольная сумма считается без обращения к ним?) и займемся оптимальным планированием потока команд.
Обратимся к другому мощному средству профилировщика VTune — автоматическому оптимизатору, по праву носящему гордое имя "Assembly Coach" (Ассемблерный Тренер, — не путайте его с Инструктором!). Выделим, удерживая левую клавишу мыши, все тело функции gen_pswd и найдем на панели инструментов кнопку с изображением учителя (почему-то ярко-красного цвета), держащим указку на перевес. Нажмем ее.
На выбор нам предоставляется три варианта оптимизации, выбираемые в раскрывающимся списке Mode Of Operation, расположенном в верхнем левом углу:
- Automatic Optimization (Автоматическая оптимизация);
- Single Step Optimization (Пошаговая оптимизация);
- Interactive Optimization (Интерактивная оптимизация).
Первые два режима не представляют особого интереса, а вот качество Интерактивной оптимизации — выше всяческих похвал. Итак, выбираем интерактивную оптимизацию и нажимаем кнопку Next расположенную чуть правее раскрывающегося списка.
Содержимое экрана тут же преобразится (рис. 1.10) и на левой панели будет показан исходный ассемблерный код, а на правой — оптимизируемый код. В нижнем правом углу экрана по ходу оптимизации будут отображаться так называемые "assumption" (буквально — допущения), за разрешением которых оптимизатор будет обращаться к программисту. На рисунке в этом окне выведено следующее допущение:
|
Accept |
Offset |
Offset2 |
Assumption Description |
|
V |
0x55 |
0x72 |
Instructions may reference the same memory |
(Инструкции со смещениями 0x55 и 0x72 обращаются к одной и той же области памяти). Смотрим: что за инструкции расположены по таким смещениям. Ага:
1:55 mov ebp, DWORD PTR [esp+018h]
1:72 mov DWORD PTR [esp+010h], ecx
Несмотря на кажущиеся различия в операндах, на самом деле они адресуют одну и ту же переменную, т. к. между ними расположены две машинные команды PUSH, уменьшающие значение регистра ESP на 8. Таким образом, это предположение верно и мы подтверждаем его нажатием кнопки Apply, находящейся в верхней левой части экрана.
Теперь обратим внимание на инструкции, залитые красным цветом (на рисунке они с наиболее темной заливкой) и отмеченные красным огоньком светофора слева. Это отвратительно спланированные инструкции, обложенные "штрафными" тактами процессора.
Рис. 1.10. Использование Ассемблерного Тренера для оптимизации планирования машинных команд
Давайте щелкнем по самому нижнему "светофору" и посмотрим, как профилировщик VTune перегруппирует наши команды… Ну вот, совсем другое дело! Теперь все инструкции залиты пастельным желтым цветом, что означает: никаких конфликтов и штрафных тактов нет. Что в оптимизированном коде изменилось? Ну, во-первых, теперь команды PUSH (заталкивающие регистры в стек) отделены от команды, модифицирующей регистр указатель вершины стека, что уничтожает паразитную зависимость по данным (действительно, нельзя заталкивать свежие данные в стек пока не известно положение его вершины).
Во-вторых, арифметические команды теперь равномерно перемешаны с командами записи/чтения регистров, поскольку вычислительное устройство (АЛУ — арифметико-логическое устройство) у процессоров Pentium всего одно, то эта мера практически удваивает производительность.
В-третьих, процессоры Pentium содержат только один полноценный x86 декодер и потому заявленная скорость декодирования три инструкции за такт достигается только при строго определенном следовании инструкцией. Инструкции, декодируемые только полноценным x86-декодером, следует размещать в начале каждого триплета, заполняя "хвост" триплета командами, которые "по зубам" остальным двум декодерам. Как легко убедиться, компилятор MS VC генерирует весьма неоптимальный с точки зрения Pentium-процессора код и профилировщик VTune перетасовывает его команды по-своему.
Листинг 1.24. Ассемблерный код, оптимизированный компилятором Microsoft Visual C++ 6.0 в режиме максимальной оптимизации (слева) и его усовершенствованный вариант, переработанный профилировщиком VTune (справа)
sub esp, 08h sub esp, 08h
push ebx or ecx, -1
push ebp push ebx
mov ebp, DWORD PTR [esp+018h] push ebp
push esi mov ebp, DWORD PTR [esp+018h]
push edi xor eax, eax
mov edi, ebp push esi
or ecx, -1 push edi
xor eax, eax xor ebx, ebx
xor ebx, ebx mov edx, -1
mov edx, -1 mov edi, ebp
repne scasb repne scasb
not ecx mov DWORD PTR [esp+020h], edx
dec ecx not ecx
mov DWORD PTR [esp+020h], edx dec ecx
mov DWORD PTR [esp+010h], ecx mov DWORD PTR [esp+010h], ecx
Нажимаем еще раз кнопку Next и переходим к анализу следующего блока инструкций. Теперь профилировщик VTune устраняет зависимость по данным, разделяя команды чтения и сложения регистра ESI командой увеличение регистра EAX:
mov esi, dword ptr [eax+ebp] mov esi, dword ptr [eax+ebp]
add edx, esi inc eax
inc eax add edx, esi
cmp eax, ecx cmp eax, ecx
Действуя таким образом, мы продолжаем до тех пор, пока весь код целиком не будет оптимизирован. И тут возникает новая проблема. Как это ни прискорбно, но профилировщик VTune не позволяет поместить оптимизированный код в исполняемый файл, видимо, полагая, что программист-ассемблерщик без труда перенаберет его с клавиатуры и вручную. Но мы то с вами не ассемблерщики! (В смысле: среди нас с вами есть и не ассемблерщики).
И потом — как прикажите "перебивать" код? Не резать же двоичный файл "в живую"? Конечно нет! Давайте поступим так (не самый лучший вариант, конечно, но ничего более умного мне в голову пока не пришло). Переместив курсор в панель оптимизированного кода в меню File, выберем пункт Print. В окне Field Selection (выбор полей) снимем флажки со всего, кроме Labels (метки) и Instructions (инструкции) и зададим печать в файл или буфер обмена.
Тем временем, подготовим ассемблерный листинг нашей программы, задав в командной строке компилятора ключ /FA (в других компиляторах этот ключ, разумеется, может быть и иным). В результате мы станем обладателями файла pswd.asm, который даже можно откомпилировать (ml /c /coff pswd.asm), слинковать (link /SUBSYSTEM:CONSLE pswd.obj LIBC.LIB) и запустить. Но что за черт! Мы получаем скорость всего ~65 миллионов паролей в секунду против 83 миллионов, которые получаются при оптимизации обычным путем. Оказывается, коварный MS VC просто не вставляет директивы выравнивания в ассемблерный текст! Это затрудняет оценку производительности качества оптимизации кода профилировщиком VTune. Ну да ладно, возьмем за основу данные 65 миллионов и посмотрим насколько VTune сможет улучшить этот результат.
Открываем файл, созданный профилировщиком и… еще одна проблема! Его синтаксис совершенно не совместим с синтаксисом популярных трансляторов ассемблера!
Листинг 1.25. Фрагмент ассемблерного файла, сгенерированного профилировщиком VTune
label instructions
gen_pswd sub esp, 08h
js gen_pswd+36 (1:86)
gen_pswd+28 mov esi, DWORD PTR [eax+ebp]
Во-первых, после меток не стоит знак двоеточия, во-вторых, в метках встречается запрещенный знак "плюс", в третьих, условные переходы содержат лишний адрес, заключенный в скобки на конце.
Словом нам предстоит много ручной работы, после которой "вычищенный" фрагмент программы будет выглядеть так:
Листинг 1.26. Исправленный фрагмент сгенерированного профилировщиком VTune файла стал пригоден к трансляции ассемблером TASM или MASM
label instructions
gen_pswd: sub esp, 08h
js gen_pswd+_36 (1:86)
gen_pswd+_28 mov esi, DWORD PTR [eax+ebp]
Остается заключить его в следующую "обвязку" и оттранслировать ассемблером TASM или MASM — это уже как вам больше нравится:
Листинг 1.27. "Обвязка" ассемблерного файла, в которую необходимо поместить оптимизированный код функции _gen_pswd, для его последующей трансляции
.386
.model FLAT
PUBLIC _gen_pswd
EXTERN _DeCrypt:PROC
EXTRN _printf:NEAR
EXTRN _malloc:NEAR
_DATA SEGMENT
my_string DB 'CRC %8X: try to decrypt: "%s"', 0aH, 00H
_DATA ENDS
_TEXT SEGMENT
_gen_pswd PROC NEAS
// КОД ФУНКЦИИ gen_pswd
_gen_pswd endp
_TEXT ENDS
END
А в самой программе pswd.c функцию gen_pswd объявить как внешнюю. Это можно сделать например так:
Листинг 1.28. Объявление внешней функции gen_pswd в Си-программе
extern int _gen_pswd(char *crypteddata,
char *pswd, int max_iter, int validCRC);
Теперь можно собирать наш проект воедино:
Листинг 1.29. Финальная сборка проекта pswd
ml /c /coff gen_pswd.asm
cl /Ox pswd.c /link gen_pswd.obj
Прогон оптимизированной программы показывает, что она выдает ~78 миллионов паролей в секунду, что на ~20% чем было до оптимизации. Что ж! Профилировщик VTune весьма не слабо оптимизирует код! Тем не менее, полученный результат все же не дотягивает до скорости, достигнутой на предыдущем шаге. Конечно, камень преткновения не в профилировщике, а в компиляторе, но разве от этого нам легче?
Впрочем, на оптимизацию собственных ассемблерных программ эта проблема никак не отражается.
Итоги и прогнозы
Теперь самое время подвести итоги. Если откинуть первый неудачный вариант программы с постоянным вызовом функции printf, можно сказать, что мы увеличили скорость оптимизируемой программы с полутора до восьмидесяти четырех миллионов паролей в секунду, то есть без малого на два порядка! И у нас есть все основания этим гордиться! Пускай, мы далеко от теоретического предела и до исчерпания резерва производительности еще далеко (вот скажем, можно перебирать несколько паролей одновременно, использовать векторные MMX-команды) профилировка приложений, несомненно, лучшее средство избежать неоправданного снижения производительности!
Любопытно, но каждый шаг оптимизации приводил к экспоненциальному росту производительности (рис. 1.11). Конечно, экспоненциальный рост наблюдается далеко не во всех случаях (можно сказать, что тут нам просто повезло), но, тем не менее, общая тенденция профилировки такова, что самые крупные "камни преткновения" по обыкновению находится "на глубине" и разглядеть их, не "окунувшись в воду" (в смысле в дебри кода) в общем-то, невозможно.
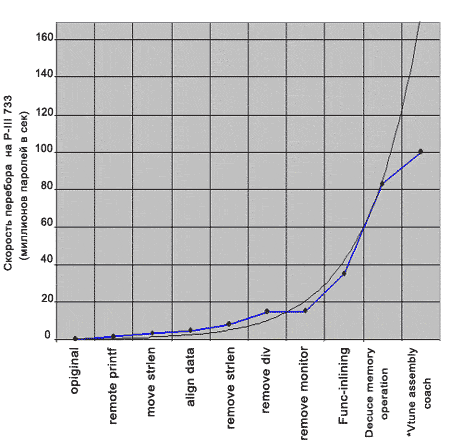
Рис. 1.11. Хронология оптимизация парольного переборщика
В этой главе мы рассмотрели лишь самые базовые средства профилировщика VTune (да и то мельком), но его возможности этим отнюдь не исчерпаются! Собственно это целый мир, содержащий помимо всего прочего собственный язык программирования и даже имеющий собственный интерфейс API, позволяющий вызывать функции VTune из своих программ (читай: "клепать" к профилировщику собственные плагины)…
Но, как бы то ни было, первый шаг в изучении профилировщика VTune уже сделан и в дальнейшем вы постепенно сможете осваивать его и самостоятельно. А напоследок рискну дать вам один совет. Пользоваться контекстовой помощью VTune крайне неудобно и множество разделов при этом так и остаются неохваченными. Поэтому, лучше воспользоваться любым help-декомпилятором и конвертировать hlp-файл в rtf, который затем можно открыть с помощью того же редактора Word и распечатать. Или, во всяком случае, — читать с экрана, ибо помощь занимает свыше трех тысяч страниц — бумаги не напасешься!
На этом вводную часть книги можно считать законченной.
Оглавление
Об авторе
Введение в книгу
Введение в оптимизацию
Профилировка программк
Оперативная память - из глубин времен до наших дней
Проблемы тестирования оперативной памяти
Принципы функционирования SRAM
Заказать книгу в магазине "Мистраль"