Зачем нам нужен язык XML?
Павел Храмцов, Курчатовский научный центр,
Точка "отрыва".
В 2000 году исполнится 10 лет "Всемирной паутине". Internet и Web за это время стали синонимами. Уже мало кто помнит, что до Web эту глобальную сеть ассоциировали в первую очередь с системой телеконференций Usenet. Первые пять лет развития были посвящены творческому осмыслению технологии Web , ее адаптации к среде Internet и вычислительным ресурсам пользователей Сети. Следующее пятилетие ушло на совершенствование стандартов и спецификаций, а также на разработку новых предложений в виде языков программирования, объектных моделей и т.п. Постепенно в прошлое отходит время умельцев-энтузиастов, и наступает время профессионалов. Наступает эпоха индустрии Web. Она выдвигает новые требования к технологической основе "Паутины" и новые критерии качества и эффективности реализации Web-проектов.
Очень похоже на то, что в настоящий момент мы находимся на пороге рождения промышленных стандартов "Паутины", которые будут довольно серьезно отличаться от того, с чем мы привыкли до сих пор иметь дело. При этом внешне, видимо, мало что изменится. Может быть, появится вариабельность гипертекстовых ссылок, подстройка под историю посещения страниц, векторная графика, трехмерная графика или что-то в этом духе. Но внутренняя начинка претерпит серьезные изменения.
Можно даже со значительной долей уверенности утверждать, что мы все находимся в настоящее время в точке технологического отрыва. Профессионалы готовятся предоставить такие решение для производителей Web-содержания, в начинке которых не сразу разберется даже очень способный любитель. Кто из нас может сделать телевизор или видеомагнитофон? Кому под силу сделать автомобиль собственной конструкции? Кто готов сконструировать и произвести компьютер с процессором собственного производства или оригинальной системой хранения данных? Похоже, что аналогичный период развития технологии ожидает и Web.
Пока еще можно вручную разметить HTML-страницу, и дизайнеры с некоторым снобизмом поучают новичков, что FrontPage - это инструмент дилетанта, что создать профессионально выполненную страницу можно только вручную. Однако, ни у кого не вызывает сомнения тот факт, что векторную графику нужно делать в специализированном редакторе, а не руками набивать в том же NotePad-е.
В последнее время стало модным говорить об XML - расширяемом языке разметки (eXtensible Markup Language). Принято считать, что он сможет решить многие проблемы не только Web, но и других информационных технологий, например языков информационного поиска.
На самом деле переход на стек спецификаций XML позволяет:
- отдельно описывать структуру данных без привязки их к форме отображения,
- определять форму представления данных независимо от конкретного содержания,
- создавать метаданные,
- управлять доступом к данным,
- фильтровать данные по содержанию структуре и метаданным,
- преобразовывать содержание и структуру данных,
- согласовывать практику применения данных с национальным законодательством,
- описывать стандартные коммуникативные форматы данных, принятые в различных предметных областях,
- и многое другое.
Все эти возможности логичнее всего реализовывать в специализированных продуктах разработки Web-контента и его сопровождения. Флагманы индустрии Web, такие как IBM, Microsoft, Sun Microsystems, Software AG, Oracle, Netscape и др., активно разрабатывают эту ниву. Результатом усилий, сосредоточенных на этом направлении, будет переход индустрии разработки Web-контента и средств доступа к нему на эти продукты.
Отечественным производителям Web-контента, а о производителях программного обеспечения говорить вообще не приходится, т.к. не один из них не замечен в рабочих группах по выработке новых стандартов, остается только поприсутствовать в качестве наблюдателей на этом празднике жизни и заранее готовится к грядущим переменам.
Если уж отведена роль наблюдателей, то следует внимательно присмотреться ко всему, происходящему и вычленить основные вехи и тенденции развития. Как правило, эти вехи оформлены в виде стандартов и технических рекомендаций. Попробуем, анализируя рабочие материалы, рекомендации, стандарты ISO и W3C, осознать примерные пути развития Web-технологий.
Этапы большого пути.
Начнем свой анализ с 1995 года. Года во многом примечательного и поучительного. Года перелома для всего Internet. Сначала обратим свое внимание на материалы, которые были опубликованы W3C с 1995 по 1999 годы.
1995 год - это год Java. Несколько в тени JavaScript. Это и понятно Netscape использует рекламную компанию Sun. 1995 - это год, когда Microsoft бросается в погоню за лидерами Web. Первые попытки - неудачные. Расширения HTML не находят должного отклика у авторов HTML-страниц, а VBScript начисто проигрывает соревнование с JavaScript. 1995год - это год перелома в отношении бизнеса к Web. Резко изменяется контент. Некоммерческий сектор начинает быстро сокращаться (в процентном отношении). 1995 год - год, когда исчезает государственный патронаж Internet в США. Сеть отдается на откуп коммерческим провайдерам.
Конец года ознаменован началом сотрудничества W3C и Microsoft, а также появлением в ноябре документа "Giving Information About Other Resources in HTML"(Tim Berners-Lee, David Ragget).
Первое событие ознаменовывает постепенный перехват инициативы в разработке клиентских приложений компанией Microsoft, хотя в то время это еще не было столь очевидно. В конечном итоге, это дата конца для браузера компании Netscape, который, судя по всему, уже не поднимется до уровня Internet Explorer. Если что-то и появится новое, то это будет вне рамок Netscape Communicator. Слишком много упущено времени. (Недавно компания объявила о выпуске шестой версии Navigator --- связать с новостью ---. Посмотрим что это такое).
Второе событие указывает на главное направление развития спецификаций W3C - разработку стандартов описания форматов данных и их источников. Это направление является доминирующим в деятельности W3C по сей день.
В 1996 продолжаются работы по унификации формата журналов посещений на серверах, выпускается описание Proxy Caches, начинается внедряться объектно-ориентированный подход при разработке серверов (спецификация ILU от Xerox), анонсируется полностью написанный на Java сервер Jigsaw, продолжаются работы по расширению HTML за счет внесения в его SGML-DTD новых конструкций, предлагается спецификация описания встроенных в документ метаданных, предлагается расширить возможности CSS до описания фреймовой структуры, появляется формат обмена описателями ресурсов (Resource Description Messages) и, наконец, в декабре 1996 года выходит "HTTP-based Distributed Content Editing Scenarios".
Таким образом, в 1996 году продолжаются усилия по объединению информационных источников Web, только теперь это делается на уровне HTTP-протокола. Речь пока не идет о стандарте нового протокола, но тенденция развития, тем не менее, очевидна. При этом все больше осознается ограниченность HTML с точки зрения описания различных данных и его применения в бизнес-приложениях.
Такая картина получается, если анализировать сообщения (notes) W3C. А вот список рекомендации (recomendations) W3C завершается в 1996 году опубликованием спецификации PNG(Portable Network Graphics), двух документов по PICS и CSS1(Cascading Style Sheets Level 1). Последняя спецификация будет пересмотрена уже только в январе 1999 года. Если учесть, что 14 января 1997 года будет опубликован справочное руководство по HTML 3.2, то можно смело утверждать, что 1996 год - это подведение черты под классической Web-технологией со стандартной HTML-разметкой, вершиной которой являются CSS1 и переход к новым стандартам.
В 1997 году список сообщений начинается с "An Introduction to Amaya" и предложений "Web Collections using XML". Далее были предложены язык разметки портативных устройств, шла работа над стандартами для электронной коммерции и интерфейсами приложений, анализировался опыт и эффективность использования классических спецификаций (HTTP/1.1, CSS1 и PNG), но основное внимание было сосредоточено на моделях данных и описании контекста их применения. В этом ключе выполнены работы по описанию метаданных на XML (eXtended Markup Language), проанализированы способы применения гипертекстовых ссылок в HTML, предложены потенциальные улучшения в CSS, которые вылились в "A Proposals for XSL". Логическим завершением этой работы стало два документа: "W3C Data Formats" и "Introduction to RDF Metadata".
Первый документ совсем маленький - две странички. В нем Тим Бернерс Ли объясняет стратегию разработки стандартов языков W3C и политику миграции со старой платформы (SGML, HTML, CSS, PICS) на новую (XML, RDF, P3P и др.). Фактически, это программа развития Web-технологии, которая поворачивается лицом к требованиям процессов типа "business-to-business" и сложившимся технологиям обработки данных.
Второй документ объясняет, как, собственно, это будет происходить. Его основная тема метаданные, т.е. данные о данных. Сюда относятся описания структуры документа, схемы баз данных, схемы поисковых образов и т.п.. Начиная с этого момента, декларируется стековая архитектура языков данных Web, хотя по традиции это все продолжают называть языками разметки.
Характерно, что из рекомендаций в 1997 году в свет выходят только HTML 4.0 и PICSRules 1.1. Фактически и то, и другое закладывают только фундамент будущих стандартов.
В этой связи гораздо более интересны рабочие материалы W3C (Drafts). Они отражают степень готовности тех или иных идей для оформления в качестве рекомендаций. Достаточно вспомнить, что в качестве drafts долгое время находились вообще большинство спецификации Web вплоть до 1995 года.
В 1997 году в качестве рабочих материалов дискутируются вопросы безопасности, в частности электронные подписи и платежи, расширение CSS за счет учета носителя и позиционирования, загружаемые фонты и P3P. Т.е. состояние работ таково, что в 1998 году должны начать появляться стандарты новой серии, о которых писал в конце 1997 года Тим Бернерс Ли. И они не замедлили появиться.
В 1998 году W3C опубликовал сразу шесть рекомендаций, в три раза больше чем в 1997 году. Из них следует отметить в начале года первую версию спецификации XML, майский выпуск новой спецификации CSS2 и, в конце года, спецификацию Объектной Модели Документа. Таким образом, был заложен фундамент той схемы, которую нарисовал Тим Бернерс-Ли в 1997 году.
В рабочих материалах W3C в 1998 году особое внимание уделяется развитию XML в части описания гипертекстовых связей (Xpointer и Xlink), разработке спецификации стилей для XML (XSL), масштабируемой графике и, что характерно, основе Web-обмена - новому набору протоколов HTTP-NG.
Консорциум изменяет подход к разработке протоколов обмена, превращая унитарный протокол HTTP/1.1 в стек протоколов прикладного уровня. В это время формулируются краткосрочные и перспективные цели деятельности по разработке протоколов, разрабатывается модель стека, предложения по спецификациям интерфейсов и т.п..
В сообщениях W3C 1998 доминируют четыре основных темы: Графика и Web, распределенный контекст и его обработка, XML - как база построения различных языков, в том числе и поисковых и реализации объектной модели документа.
Поисковые языки на основе XML и его производных следует в этой связи отметить отдельно. Фактически речь идет об интеграции различных языков (информационно-поисковых, баз данных, манипулирования данными, обмена данными и т.п.) в единый язык Web. При этом все специалисты едины во мнении, что это должен быть декларативный язык, построенный на модели неполноструктурированных данных (semistructured). Документ "XML-QL: A Query Language for XML" был подготовлен к семинару W3C по поисковым языкам, который прошел в конце 1998 года и явился далеко не единственной попыткой обобщения такого рода.
Начало 1999 года стало продолжением рекомендательной деятельности W3C. Начинает обретать реальные очертания Resource Description Framework(RDF) - второй слой языковых спецификаций, который наращивается поверх XML. В этой связи следует отметить два основных документа по RDF и рекомендацию по областям действия имен XML, которая теснейшим образом связана с RDF.
В качестве рабочих материалов начала 1999 года следует отметить новую спецификацию DOM2 и начало разработки серии спецификаций по XHTML. Первое продолжает закладывать основы в разработку протоколов и приложений, построенных на этих протоколах. Второе переводит разговоры об основополагающей роли XML в практическое русло, т.к. задает правила описания HTML 4.0 в терминах XML. Это открывает дорогу написанию нового поколения браузеров, которые будут способны поддерживать как старые, так и новые стандарты и рекомендации W3C. Пока таких браузеров нет. Первая ласточка, которая способна учитывать новые модели, - IE 5.0, но и он скорее представляет собой прототип, чем реальный построенный на новых принципах программный продукт, уж больно много в нем внутренних противоречий и неточностей.
Сообщения W3C начала 1999 года посвящены развитию нового набора протоколов и спецификаций. Во-первых, следует отметить попытки отказаться от DTD - тяжелого наследства SGML. На этом поприще ведется деятельность по согласованию спецификации Document Definition Markup Language. Хотя сделать это будет не так просто, как кажется на первый взгляд. Во-вторых, довольно интенсивно продолжается обсуждение спецификаций Xpointer и Xlink - новых типов разметки гипертекстовых связей. В-третьих, продолжается развитие стека HTTP и приложений на его основе.
Таким образом, продолжается наполнение схемы Тима Бернерса-Ли реальным содержанием, которое в конечном итоге должно привести к коренным изменениям основ Web-технологии. При этом должна сохраниться преемственность доступа к существующим информационным ресурсам "Всемирной паутины".
Теперь рассмотрим усилия ISO (Internetional Organization for Standardization). На первый взгляд может показаться, что влияние спецификаций данной организации на процесс создания и совершенствования Web минимален в силу особенностей организации Internet, однако это не совсем так.
Во-первых, "дедушка" всех новых языков разметки, которые предлагает W3C - Standard Ggeneralized Markup Language. SGML. В свою очередь SGML: - это стандарт ISO 8879. Было бы странным, если бы ISO при такой популярности World Wide Web осталась в стороне от процесса стандартизации спецификаций Web. Тем более, что другие менее популярные национальные стандарты, например, Z39.50 получили свои ISO реализации.
Материалы ISO некорректно сравнивать с сообщениями W3C или его рабочими материалами. ISO рекомендации, в силу формата самой организации можно сравнивать, только с рекомендациями W3C. При таком сравнении можно отметить такой интересный факт. В 1996 году ISO выпускает документ ISO/IEC 10179. Это спецификация языка описания и семантики стилей документов. W3C в этом же году, как уже было отмечено, выпустил описание CSS1. Следует отметить, что DSSSL гораздо более продуманная и сложная спецификация, чем CSS1. Она практически покрывает многие возможности следующей спецификации CSS - CSS2, которая появится двумя годами позже. Справедливости ради следует отметить, что DSSSL не замахивается на описание контекста документа, т.е. не выполняет функции RDF, но трансформирование SGML документов для различных форм представления выполняет.
Раз речь пошла о различных формах представления, то должен быть язык, который бы описывал документы типа гипермедиа универсальным способом. В наборе документов ISO спецификация такого языка есть - ISO/IEC 10744 HyTime. Вторая редакция этого документа вышла в 1997 году. По своему функциональному назначению HyTime объединяет в себе XML и RDF. HyTime предназначен для описания динамических документов типа гипермедиа и интегрирован по модели данных с DSSSL. В обоих случаях используется объектный подход и древовидная модель вложенных классов объектов.
HyTime предлагает, кроме того, некоторые расширения SGML. Но при этом никто не посягает на роль SGML, как языка описания формальных спецификаций языков описания документов, структур документов и других метаданных.
При этом следует отметить, что стандарты ISO - это не только декларации. Для их апробации создано программное обеспечение. Оно не так популярно, как программы для Web, но при желании им можно воспользоваться.
Любопытно отметить, что и W3C, и ISO проповедуют примерно один и тот же подход к описанию, доступу и обмену гипертекстовой информацией. Он заключается в том, что основа всех языковых спецификаций - это SGML, сами документы их коллекции и базы данных - это объекты, каждый отдельный документ и их совокупность - дерево. При этом иерархия не строгая. В W3C информацию такого типа называют полуструктурированной (semistructured). При этом в обоих случаях для ее описания применяют неупорядоченные деревья (drove structure)
Очевидно, что работа ISO довольно сильно влияет и на активность W3C, В дальнейшем мы сосредоточимся на спецификациях W3C: с ними более плотно работает отрасль в лице основных производителей ПО
Стек спецификаций XML.
Вернемся к сообщению Тима Бернерса-Ли о структуре нового подхода W3C к разработке спецификаций Web. В статье просто и понятно объяснено, что было, и что предполагается сделать. Подход иллюстрируется довольно простой и понятной картинкой (Рис.1). В левой ее части расположены протоколы, которые составляют основу текущих спецификаций. В правой - новое семейство протоколов описания данных Web.
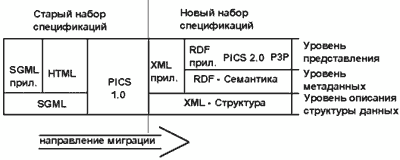
Рис.1 Структура спецификаций W3C на Октябрь 1997 года
Цель нового подхода W3C состоит в том, чтобы разработать набор спецификаций форматов данных, который бы позволил улучшить модульность и расширяемость номенклатуры форматов для любых видов приложений. При этом новый набор спецификаций должен обеспечить и преемственность.
Идея состоит в том, что все данные описываются в определенном порядке и, если следовать этому порядку, то спецификации будут представлять собой стек. Первый уровень такого стека - описание структуры данных. Второй уровень стека - описание семантики (смысла, содержания). Третий уровень стека - описание способа применения (отображения, преобразования и т.п.) данных.
В качестве основы представления данных в W3C выбран принцип контекстной разметки. Этот принцип заимствован из SGML - стандартного общего языка разметки. На SGML был определен HTML. В старом наборе спецификаций такое построение было единственным. Ни одна другая спецификация не строилась по принципу от "общего к частному".
Справедливости ради следует отметить, что HTML - это некий синтез различных спецификаций Web. В нем используются и URI в виде URL, HTTP в виде http-equiv модификации элемента разметки meta, фрагменты программного кода в виде элементов script, applet, embed и object, таблицы стилей в атрибутах элементов разметки и элементе style.
Как видно из этого перечисления надстраиваемый HTML - это прототип новой спецификации. Очевидно также, что этот прототип сковывает возможности развития спецификаций, т.к. предназначен в первую очередь для определения правил отображения и навигации, а вовсе не для работы, скажем с базами данных или информационно-поисковыми системами.
В этой связи следует отметить, что в схеме (рис 1.) отсутствует очень важная компонента современной Web-технологии - каскадные таблицы стилей (Cascading Style Sheets). Попытка ввести в HTML компоненты разметки, правила отображения которых не прописывались бы в документе, а определялись в сам момент отображения, делалась еще в HTML 1.0. Достаточно вспомнить стилевые элементы типа quota, em и т.п.. Однако, в то время шло начальное освоение технологии. Спецификации имели тенденцию к упрощению. Начинающие авторы предпочитали использовать b и i, т.к. это было понятнее и проще. В то время отказались от тэгов окончания в пустых элементах и смирились с пропусков тэгов, определяющих структуру самого документа.
Этот процесс деградации спецификаций под напором непрофессионалов завершился в 1995 году. Программирование на JavaScript заставило более строго описывать структуру документа. Смешивать элементы разметки оглавления документа и его тела стало непозволительной роскошью. Победить упрощенческий подход к разметке не удалось: bold и italic все равно понятнее emphased. Однако, удалось обобщить это упрощение. С внедрением CSS стало возможным управлять процессом отображения документа. При этом появился еще один важный момент - это описание можно хранить отдельно от документа и подгружать в нужный момент. Т.е. контент оказался отделенным от описания способов своего отображения. То, что программа отделена от данных, является нормой в программировании, поэтому хранение скриптов управления отображением страниц во внешних файлах - это соответствие данной норме. Хранение стилей отдельно от документа - это изменение технологии производства Web-узлов. Теперь стиль узла можно разрабатывать отдельно от наполнения узла содержанием. Собственно это и дало возможность долгосрочного существования независимых дизайнерских групп, которые могут не заниматься сопровождением, созданных ими Web-узлов.
Следует отметить декларативный характер спецификации CSS. Это провоцирует специалистов W3C перевести CSS в формат некоторого обобщенного языка разметки, в качестве которого на рисунке 1 выступает XML. Таким образом, появился на свет расширяемый язык описания стилей XSL (eXtansible Style Language).

Рис: 2. Структура W3C спецификаций на начало 1999 года
Отсутствие спецификации стилей в 1997 году объясняется, видимо, двумя причинами. Во-первых, на этот момент описание CSS1 только появилось. Стили еще не стали кровью и плотью Web. Во-вторых, как это стало известно широкой публике только в 1999 году, Microsoft в 1995 году подала заявку на патент для CSS. Аналогичная заявка подана и на XSL, но пока не удовлетворена. Видимо это и стало причиной отсутствия CSS в схеме основоположника Web. Косвенно на то, что о заявке знали, указывает и тот факт, что Netscape представила свою форму CSS, основанную на JavaScript-представлении. Следует в этой связи отметить, что здесь также возможны проблемы. JavaScript-схемы так или иначе упираются в DOM. А в этой сфере Microsoft удалось перехватить инициатаву у Netscape. Ее JScript - это вовсе не JavaScript от Netscape, хотя и совместим с ним. Кроме того, сейчас идет активная работа над ECMA - обобщением JavaScript и JScript. В этой работе лидерство Microsoft является бесспорным.
Вообще говоря, действия Microsoft способны серьезно повлиять на все Web-сообщество. Для этого достаточно контролировать поддержку CSS и тем самым задушить всех конкурентов. Поэтому сейчас развернулась компания, которую условно можно назвать "Microsoft, оставь стандарты Web открытыми". Что из всего этого получится пока не очень ясно. Раздел компании, если он произойдет, существенно на ситуацию не повлияет, т.к. подразделение, занятое разработкой приложений для Internet, никто делить не собирается.
Стрелочка на рис.2, которая связывает XML через XSL с XHTML, показывает, что XSL - это трансформация XML-структуры в XHTML-разметку, т.е. преобразование документов из одного формата в другой. Если быть более точным и учесть современные взгляды на документ как на структуру типа дерево (Document Object Model), то - это преобразование одного графа в другой.
XHTML (eXtansible Hypertext Markup Language - расширяемый язык гипертекстовой разметки) - это подмножество XML. С одной стороны он похож на HTML, а с другой - наследует все свойства XML.
RDF - это другая обширная ветвь работ, которая замыкается на то, что принято называть метаданными, т.е. информацией об информации. В W3C эти работы начались с борьбы за нравственность и авторское право (спецификация PICS). Но не менее важным является и другой способ применения метаданных - создание поиcковых образов страниц для информационно-поисковых систем.
Функциональное назначение новых спецификаций.
Рассмотрим коротко основное назначение компонентов нового стека в направлении "снизу вверх" и определим, на сколько они совместимы со старыми.
В основе всех спецификаций лежит XML(eXtasible Markup Language). Это значит, что и PICS 2.0, и XHTML - суть XML документы. XML - это расширяемый язык разметки. XML является одним из клонов SGML. XML не заменяет собой HTML. У этих двух языков совершенно разное назначение.
У XML две главных задачи: во-первых, обеспечить описание структуры данных, во-вторых, обеспечить общий синтаксис для всех других спецификаций. Таким образом, XML не указывает, как надо отображать документ, он только описывает его структуру и содержание. Сам термин документ не совсем уместен в этом контексте, но это уже наследство HTML и современной практики Web.
С точки зрения W3C следующей по значимости спецификацией является RDF(Resource Description Framework). Основное назначение RDF - описание XML-ресурсов с самых разных точек зрения. Другими словами - это форма метаданных.
Метаданные могут быть самые разные. Например, права собственности на данный документ или ресурс, или категория доступности данной информации, или реферат документа и т.п. Для каждого из этих типов метаинформации создается RDF - описание. При этом оно может быть интегрировано с текстом самого документа или существовать отдельно от него. RDF-описание может быть соотнесено с целым классом ресурсов или с конкретной коллекцией.
На том же уровне стека спецификаций, что и RDF находится XSL(eXtasible Style Language). Основное назначение XSL - описание формы представления данных на носителе. Пока речь идет главным образом о двух формах представления - отображение документа в рабочей области браузера и на листе бумаги. Но, как не трудно догадаться, номенклатура носителей может быть расширена. Если это произойдет, то XSL имеет все шансы пересечься с RDF по области применения.
XSL состоит из двух частей: спецификации преобразований (transformation) и спецификации форматируемых объектов (formating objects). Назначение первой - определить возможные способы преобразования XML-конструкций в форму, пригодную для отображения, а второй - обобщить свойства отображаемых объектов и отклассифицировать эти объекты.
Спецификация отображаемых (форматируемых) объектов - это отображение CSS в формат XML. Трансформации - это абсолютно новый подход для W3C. Дело в том, что до сих пор удавалась удержаться в рамках декларативного подхода к описанию языков. Т.е. языки предполагали что интерпретатор (parser) просто фильтрует через себя входной поток и, сопоставляя его с шаблоном, преобразует. XSLT(eXtansible Style Languge for Transformation) частично содержит инструкции преобразования, т.е. является чем-то средним между декларативным языком и процедурным. В нем есть даже конструкция function.
Продолжая тему трансформаций, обратим свое внимание на XHTML(eXtansible Hypertext Markup Language), который является результатом применения спецификации XSLT к XML-документу. Фактически это тот же HTML, только переложенный в синтаксис XML. Это означает, что на форму представления элементов разметки накладываются ограничения синтаксиса XML.
Жесткость и строгость правил разметки вытекает из двух свойств XML: документы должны быть синтаксически правильными(well-formed) и должны обеспечивать "достоверность"(validating). Первое требование вытекает из необходимости построения дерева объектов в соответствии с DOM, а второе - из возможности реализации подстановок, в том числе, и рекурсивных, как на стороне сервера, так и на стороне клиента. Кроме того, именно "достоверность" позволяет реализовать расширяемость XHTML за счет подключения определений типа документов (Document Type Definition -DTD).
В связи с этими требованиями возникает необходимость в особом синтаксисе для размещения таблиц стилей и скриптов внутри документов.
Любопытно, что некоторые запреты XML, как указывают авторы спецификации, нельзя реализовать в рамках XML. Для этой цели необходимо использовать механизм исключений SGML (exclusions).
Это тем более интересно, что даже на таком простом и насущном для использования в Web примере каким является преобразование HTML в XHTML, а, по сути своей в XML, происходит потеря качества спецификации. Организовать строгую (stricted) синтаксическую проверку документа без привлечения SGMLparser-а оказывается невозможно.
Следует отметить, что XHTML - это перенос на XML-синтаксис стандарта HTML 4.0. Это не совсем то, что реально используется в Web, но с точки зрения общего развития технологии XHTML хорош, как демонстрация общих принципов построения спецификаций нового поколения.
На рисунках 1 и 2 присутствуют еще несколько спецификаций, вокруг которых в W3C идет довольно оживленная дискуссия. Речь идет о спецификации контроля за доступом к ресурсам PICS и о правах собственности на ресурсы P3P. Российский сектор Web практически никак не реагирует на нее.
Platform for Internet Content Selection (PICS) - это спецификация меток, которые можно ассоциировать с содержанием документов. Первоначально она разрабатывалась как "помощь родителям и учителям в контроле за содержанием Internet-ресурсов, которые просматривают дети". Если рассматривать PICS в более широком контексте, то - это механизм, предназначенный для обеспечения ограничений, введенных законодательством страны или владельцем ресурса на распространение информации определенного содержания.
PICS позволяет реализовать систему фильтров между пользователем (читателем) и информационным ресурсом, который он просматривает. Фильтр может быть установлен: пользователем, владельцем ресурса или третьей стороной, например, провайдером для обеспечения требований национального законодательства.
Можно назвать пять основных компонентов PICS:
- Синтаксис для описания системы ранжирования информационных ресурсов.
- Синтаксис для описания меток. Каждая метка описывает отдельно взятый документ или набор документов. Метка может быть подписана или зашифрована.
- Механизм встраивание меток в документы.
- Расширение HTTP-протокола, для передачи меток.
- Синтаксис запросов к базе данных меток (a label bureau)
Для использования PICS на компьютере пользователя должно быть установлено программное обеспечение, которое поддерживало бы PICS-метки.
Существует три возможности настроки PICS-фильтров: на стороне клиента (реализованы в браузерах Microsoft и Netscape), в сети (сервисы типа SyberPatrol и SurfWatch) и на proxy-серверах.
PICS не определяет саму систему ранжирования и принципы ее функционирования. В PICS определен только формат меток. Вообще говоря, фильтры можно поставить на все, что угодно, а не только на информацию "для взрослых".
Ограничения PICS достаточно просты и понятны. Если нет программного обеспечения для обработки меток, или оно неправильно настроено, то никакой фильтрации не будет. Видимо, по этой причине в российском секторе сети к PICS не проявляют большого внимания. Следует, однако, заметить, что перевод PICS в формат XML (PICS 2.0) и внедрение его в системы Intranet может изменить это вялое отношение. Достаточно реализовать систему централизованной настройки и загрузки типа Nеtwork on Demand от IBM, которая предлагается для систем электронной коммерции, и отношение к PICS придется изменить.
Другое направление работ W3C связано с правами на информационный ресурс. До сих пор нет четкой ясности в том, как относиться к публикациям в сети. Является ли ссылка на Web-страницу равнозначной ссылке на печатную публикацию? Как может быть защищено право автора или издателя на электронную публикацию? На эти и другие вопросы призвана ответить спецификация Platform for Privacy Prference (P3P).
Идея P3P достаточно проста: сервер, на который приходит запрос от клиента, извещает последнего о практике применения прав на данном Web-узле. При этом он сообщает через URI ареал страниц, на которые распространяются права. Предложение сервера разбирается клиентом, например, браузером и сравнивается с настройками, заданным пользователем клиента. Если политика сервера соответствует политике пользователя, то клиент автоматически посылает на сервер подтверждение (fingerpoint), которое называют propID. В противном случае клиент уведомляет пользователя о несовпадении политик и предлагает ему решить эту коллизию.
Как показала практика последнего года, авторское право в Internet защищается не техническими "примочками", но законом об авторском праве. Это гораздо более эффективный способ, чем настройка программ.
Кроме рассмотренных предметно-ориентированных спецификаций, которые развиваются на базе XML-синтаксиса в W3C подготовлено еще несколько стандартов. Например, Xlink, Xpointer, DCD, MML и др. Часть из них надстраиваются непосредственно над XML, другие по верх спецификации RDF или XSL. Возможно появление и других расширений стека спецификаций XML.
Вместо заключения.
Разговоры о Web-экономики предполагают существование Web-промышленности. Промышленность строится на основе отраслевых стандартов и спецификаций. До сих пор Web представлял собой необъятное поле для экспериментов, как отдельных самоучек, так и целых творческих коллективов. Похоже, что это время кончается. Интернет-коммерция существенно меняет сами принцип функционирования "Всемирной паутины".
Все проблемы Интернет с точки зрения защищенности трафика, эффективности обмена данными, надежности отдельных узлов и серверов проистекают из-за "родимых пятен" его сугубо научной природы. Никто из создателей Сети не предполагал, что в нее хлынут частные инвестиции в таком объеме. Конструкцию машины под названием "Интернет" меняют на ходу. При такой модернизации возможны самые неожиданные сюрпризы.
Хакерские атаки и сумасшедшие прибыли сетевых компаний типа Amazon, как в прочем и потери при сбоях оборудования и в результате тех же атак, являются следствием трансформации сетевых технологий. Через пять лет мы будем иметь совсем другую Сеть. А пока будем пристально наблюдать за всем происходящим, а наиболее азартные из нас будут продолжать участвовать в этой увлекательной игре под названием "Интернет".