Увеличение размера графа потока управления
Преобразования перестройки циклов заключаются в том, что в маскируемой функции выбираются подходящие гнёзда циклов и одиночные циклы и над ними выполняются преобразования пространства индексов. К таким преобразованиям относятся:
- Понижение размерности пространства итерирования.
- Повышение размерности пространства итерирования.
- Изменение порядка обхода пространства итерации.
- Аффинные преобразования пространства итерации.
- Частичная или полная развёртка цикла.
На этапе перестройки циклов просматриваются все циклы в теле функции. Для каждого цикла проверяются достаточные условия применимости каждого преобразования, определяя таким образом множество доступных преобразований. Затем для каждого цикла программы определяется какое преобразование будет к нему применено, и выполняются преобразования циклов.
На рис. 1 приведён пример применения преобразования понижения размерности индексного пространства к функции перемножения двух матриц. Преобразование позволило перейти от трёхкратного вложенного цикла к единственному циклу.
 |
 |
| (a) функция до преобразования | (b) функция после преобразования |
| Рис. 1. Пример преобразования понижения размерности | |
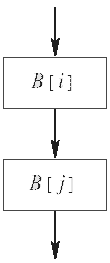
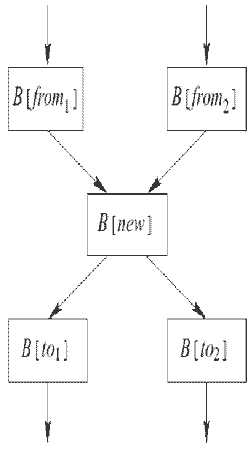
Преобразование клонирования базовых блоков заключается в замене последовательного выполнения двух базовых блоков (например, B[i] и B[j]) на оператор разветвления с выполнением копии базового блока B[j] на каждой из ветвей. Для этого базовый блок B[j] должен быть скопирован необходимое число раз. На рис. 2 приведена схема преобразования.
 |
 |
| (a) Исходный граф. | (b) Преобразованный граф |
| Рис. 2. Схема преобразования клонирования базовых блоков | |
На рис. 2 базовый блок B[j] был размножен дважды. Базовый блок B[cond] будет содержать инструкции, необходимые для того, чтобы каждая из трёх копий базового блока B[j] выполнялась примерно с одинаковой частотой. Базовые блоки B[new1], B[new2], B[new3] также могут содержать инструкции для поддержки равномерного распределения потока выполнения по трём альтернативам.
Уже на этапе клонирования базовых блоков начинается построение параллельной "холостой" функции, которая в дальнейшем будет объединена с основной функцией для получения результирующей замаскированной функции. Изначально холостая программа строится так,что содержит только типы данных, переменные и инструкции, необходимые для корректной работы программы с клонированными базовыми блоками. При создании параллельной функции одновременно строятся все структуры, содержащие результаты
анализа потока управления и потоков данных параллельной функции. Используются такие методы построения параллельной функции, при которых её семантические свойства заведомо известны.
Для клонирования выбирается базовый блок B[j], у которого дуга графа потока управления, выходящая из блока удовлетворяюет следующим условиям:
- Дуга не выходит из базового блока ENTRY и не входит в базовый блок EXIT.
- Дуга имеет высокую относительную частоту прохождения.
- Дуга является единственной дугой, выходящей из блока B[j].
Счётчики. Базовые блоки, полученные в результате клонирования, остаются полностью эквивалентными друг другу. Тем не менее, чтобы маскировка была более действенной, необходимо, чтобы все базовые блоки при работе замаскированной программы выполнялись, причём желательно, чтобы с примерно одинаковой частотой. Для этой цели используются так называемые недетерминированные счётчики (НС). Недетерминированные счётчики представляют собой абстрактный тип данных, над которым определены следующие операции:
- init: int, env -> counter
get: counter, env -> int
next: counter, env -> counter
Здесь env - это среда выполнения программы, поставляющая источник недетерминизма в счётчик. Операция init инициализирует счётчик. Первый параметр операции задаёт границу значений N, которые будет вырабатывать счётчик. Операция get вырабатывает целое значение в диапазоне от 0 до N-1, которое может использоваться для выбора одной из дуг для выполнения функции. Операция next модифицирует текущее состояние счётчика таким образом, чтобы при следующем выполнении операции get она выдавала бы другой результат. Операция next - это для каждого конкретного счётчика на самом деле семейство операций next1, next2 и т. д., реализации которых в замаскированной программе могут существенно отличаться друг от друга.
Типы данных реализации счётчиков, их переменные состояния и инструкции, соответствующие операциями над счётчиками, являются частью параллельной "холостой" функции. Переменная c, которая хранит состояние счётчика, может быть создана как на уровне локальных переменных маскируемой функции, так и вынесена в статические переменные всей единицы компиляции. Последнее позволяет разделять одну и ту же переменную состояния между разными счётчиками разных функций, что полезно ещё и тем, что создаёт в замаскированной программе межпроцедурные зависимости по данным.
В настоящее время в интегрированной среде Poirot реализованы некоторые простейшие виды счётчиков, которые описаны ниже.
- Счётчик по модулю. Это - простейший вид счётчика. Состояние счётчика хранится в переменной целого типа, которая размещается на уровне статических переменных единицы компиляции. Операция init заключается в записи в переменную счётчика произвольного числа, например, значения какого-либо параметра функции или глобальной переменной. Операция get заключается во взятии остатка от деления на k текущего значения переменной счётчика. Операция next заключается в прибавлении или вычитании произвольного числа, не кратного k, причём семейство операций next порождается различным выбором этого числа.
-
Линейный конгруэнтный счётчик. Этот вид счётчика реализует хорошо известный линейный конгруэнтный метод получения псевдослучайных чисел [5]. Операции init и get не изменяются, а операция next определяется как next(cntr)
 (C1*cntr+C2)modC3 , где C2 и C3 - взаимно простые числа. Можно также применять полиномиальные конгруэнтные счётчики, а также любой другой алгоритм получения псевдослучайных равномерно распределённых чисел [5].
(C1*cntr+C2)modC3 , где C2 и C3 - взаимно простые числа. Можно также применять полиномиальные конгруэнтные счётчики, а также любой другой алгоритм получения псевдослучайных равномерно распределённых чисел [5].
-
Криптографические хэш-функции. Для реализации счётчиков могут использоваться криптографические хэш-функции, например, MD5 или SHA [17], или симметричные криптосистемы. Тогда операция next может выглядеть следующим образом next(cntr)f(cntr
 x) . Здесь f - хэш-функция, а x - некоторые произвольные данные, например, значение какой-либо локальной переменной или параметра функции. Отметим, что алгоритмы вычисления криптографических хэш-функций имеют специфический вид (они состоят из побитовых операций с использованием табличныц), и поэтому могут быть достаточно легко опознаны при демаскировке.
x) . Здесь f - хэш-функция, а x - некоторые произвольные данные, например, значение какой-либо локальной переменной или параметра функции. Отметим, что алгоритмы вычисления криптографических хэш-функций имеют специфический вид (они состоят из побитовых операций с использованием табличныц), и поэтому могут быть достаточно легко опознаны при демаскировке.
- Динамические структуры данных. Например, может быть создан кольцевой список, который заполняется числами от 0 до k-1 в произвольном порядке. Операция get состоит в чтении значения текущего элемента списка, а операция next - в продвижении указателя на следующий элемент списка.
Дробление базовых блоков. Это преобразование заключается в том, что базовый блок достаточной длины разделяется на два или более меньших базовых блока. Дробление базовых блоков никак не отражается на коде функции и заключается в модификации вспомогательных структур, используемых для представления графа потока управления.
Разрушение структурности графа потока управления
Эта группа маскирующих преобразований включает зацепление дуг и создание псевдоциклов.
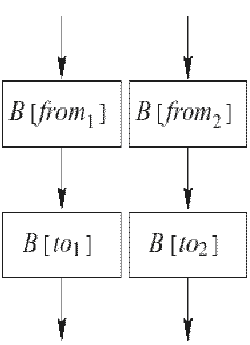
Зацепление дуг. Схема преобразования показана на рис. 3. Для преобразования выбираются две случайных дуги графа потока управления функции. При этом предпочтение отдаётся "далёким" друг от друга дугам, где расстояние измеряется как минимальное из длин двух кратчайших путей по графу от конца одной дуги к началу другой. Две выбранные дуги не должны иметь общее начало или общий конец. Ключевым для обеспечения надёжности зацепления дуг является предикат P, который в конце выполнения нового базового блока B[new] гарантирует возврат на "правильный" путь выполнения. Такой предикат мы назовём возвращающим.
До преобразования после выполнения базового блока B[from1] всегда выполнялся базовый блок B[to1], а после базового блока B[from2] всегда выполняется базовый блок B[to2]. В результате выполнения этого преобразования создаётся новый базовый блок B[new], который выполняется и после B[from1], и после B[from2]. Новый базовый блок завершается вычислением предиката P, в зависимости от которого управление передаётся либо на базовый блок B[to1], либо на базовый блок B[to2]. Предикат P должен гарантировать, что управление вернётся на ту ветвь, с которого оно пришло в блок B[new]. Методы генерации предикатов, удовлетворяющих этому требованию, будут рассмотрены ниже.
Интегрированная среда Poirot предусматривает гибкий интерфейс для подключения новых возвращающих предикатов. Добавление очередного возвращающего предиката при маскировке программы производится посредством интерфейса ReturnPredicateFactory. Интерфейс к методам генерации кода для возвращающих предикатов называется ReturnPredicateGenerator. Оба интерфейса приведены на рис. 4.
Реализованы некоторые простейшие виды возвращающих предикатов. Простейший вид возвращающего предиката - это обычная булевская переменная. Переменная может быть объявлена как на уровне локальных переменных, так и на уровне глобальных переменных.
Возвращающие предикаты могут быть построены на основе хэш-функций. Пусть хэш-функция f отображает целочисленный тип в булевский. Введём переменную v, которую будем использовать как аргумент f. Таким образом, предикат P равен f(v). Установка
 |
 |
| (a) Исходный граф. | (b) Преобразованный граф |
| Рис. 3. Схема преобразования зацепления дуг | |
public interface ReturnPredicateFactory
{
public String getReturnPredicateKindName();
public String getReturnPredicateKindDescription();
public boolean mayGenerateJumps();
public ReturnPredicateGenerator newInstance
(ObfuscationEnvironment env);
}
public interface ReturnPredicateGenerator
{
public ReturnPredicateFactory getFactory();
public MIFInstr emitType(MIFInstr p);
public MIFInstr emitGlobalDecl(MIFInstr p);
public MIFInstr emitLocalDecl(MIFInstr p);
public MIFInstr emitSetFalse(MIFInstr p);
public MIFInstr emitSetTrue(MIFInstr p);
public MIFInstr emitTest(MIFInstr p, MIFElem e,
MIFInstr d[]);
public Set getDepends();
public MIFInstr emitInit(MIFInstr p);
public MIFInstr emitFini(MIFInstr p);
}
Рис. 4 Интерфейсы для возвращающих предикатов
значения P в true эквивалентна присваиванию переменной v любого значения x, на котором f(x) = true. Такие значения x могут браться из массива Ptrue, который индексируется произвольным выражением e. Тогда установка значения предиката P в true выполняется присваиванием v < - Ptrue[e]. Установка значения предиката P в false выполняется аналогично.Для построения возвращающих предикатов могут быть использованы динамические структуры данных, аналогично тому, как они использовались для построения счётчиков.
 |
 |
| (a) Исходный граф. | (b) Преобразованный граф |
| Рис 5. Схема построения "псевдоцикла" | |
Размещение возвращающих предикатов обычно обладает существенным недостатком, снижающим степень его устойчивости. Все операции с возвращающим предикатом сконцентрированы в небольшой области графа потока управления. Используется два способа преодоления этого недостатка. Во-первых, инструкции установки значения возвращающего предиката помечаются как кандидаты на продвижение вверх в графе потока управления функции. На заключительном шаге перемешивания инструкций эти инструкции будут перемещены вверх как можно выше. Во-вторых, инструкции инициализации возвращающих предикатов могут быть размещены не в самих базовых блоках B[from1] или B[from2], а в базовых блоках, из которых управление может попасть только в нужный блок.
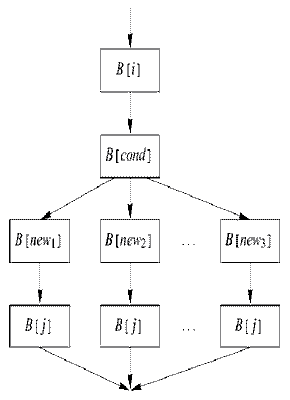
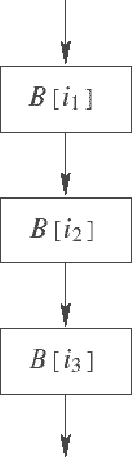
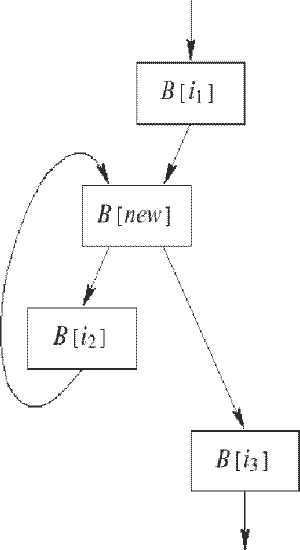
Создание псевдоциклов. Преобразование состоит во внесении в граф потока управления функции обратной дуги. При этом контролируется, чтобы тело полученного цикла выполнялось только один раз. Схема преобразования показана на рис. 5. Здесь сцепляются дуги B[i1]->B[i2] и B[i2]->B[i3]. Предикат P, находящийся в конце базового блока B[new], должен обеспечить однократное выполнение базового блока B[i2].
Устойчивость преобразования создания псевдоцикла к анализу определяется устойчивостью возвращающего предиката. В отличие от преобразования зацепления дуг, в котором инструкции установки значения возвращающего предиката P могут быть размещены достаточно "далеко" от точки зацепления дуг, преобразование создания псевдоцикла более ограничено. Установка значения предиката P, чтобы управление покинуло псевдоцикл, не может быть вынесено из блока B[i2].
Генерация несущественного кода
В маскируемую функцию добавляется большое количество несущественного кода. Несущественный код строится таким образом, что его свойства точно известны маскирующему компилятору. Например, в случае использования алиасов в несущественном коде при генерации кода одновременно строится и точное множество абстрактных ячеек памяти для каждого обращения по указателю.
Этап генерации несущественного кода состоит из следующих подэтапов:
- Генерация пула типов.
- Генерация пула переменных.
- Генерация несущественного кода.
Генерация пула типов. Подготавливаются определения типов, которые затем будут использоваться в холостом коде. Типы для холостого кода строятся одним из следующих способов:
- Непосредственно используются типы, определённые в маскируемой программе.
- Используются встроенные типы.
- Из встроенных типов и типов, определённых в маскируемой программе, путём встраивания в шаблонные типы маскирующего компилятора. Например, из типа t, определённого в маскируемой программе, могут быть построены типы массива элементов типа t, списки, деревья с элементами типа t.
- Модификацией структурных типов, определённых в маскируемой программе.
Для каждого типа, добавляемого в маскируемую программу, в маскирующем компиляторе строится класс-реализатор, на который возлагаются все функции по генерации инструкций для манипуляций с этим типом. Класс-реализатор должен удовлетворять интерфейсу TypeImplementer, который приведён на рис. 6.
Каждая несущественная переменная, добавленная в маскируемую функцию, в маскирующем компиляторе представлена классом, реализующим интерфейс VarImplementer, который показан на рис. 7.
Генерация пула переменных. Для генерации пула "холостых" переменных используются типы, построенные на предыдущей стадии. Переменные размещаются как на уровне локальных переменных функции, так и на уровне глобальных переменных.
Генерация несущественного кода. Для генерации несущественного кода используются множества операций, которые были получены с помощью методов getBinaryOps, getUnaryOps, getAssignOps интерфейса TypeImplementer. Инструкции несущественного кода размещаются в базовых блоках вперемешку с инструкциями исходной функции и управляющими инструкциями.
interface TypeImplementer
{
public boolean requiresGlobalInit();
public boolean isSimple();
public boolean isUsable();
public MIFInstr emitType(MIFInstr p);
public VarImplementer newVar();
public Set getBinaryOps();
public Set getUnaryOps();
public Set getAssignOps();
}
Рис. 6. Интерфейс для реализатора типов
interface VarImplementer
{
public TypeImplementer getType();
public MIFElem emitGlobalDecl(MIFElem p);
public MIFElem emitLocalDecl(MIFElem p);
public MIFElem emitInit(MIFElem p);
public MIFElem emitFini(MIFElem p);
}
Рис. 7 Интерфейс для реализатора переменных
"Перемешивание" управляющих инструкций. Управляющими инструкциями назовём инструкции функции, выполняющиеся при вычислении возвращающих предикатов и счётчиков, то есть инструкции, необходимые для того, чтобы расширенный граф потока управления замаскированной программы всегда выполнялся как граф потока управления исходной функции. На этом шаге все управляющие инструкции передвигаются на как можно большее расстояние от точки в программе, в которую они были изначально помещены. Границы, в пределах которых можно двигать инструкции, определяются зависимостями по данным управляющих инструкций друг от друга и зависимостями по управлению.
"Перемешивание" программ
На предыдущих этапах граф потока управления функции был значительно увеличен в размерах, затем в него было добавлено большое количество несущественного кода. И предикаты, добавленные в расширенный граф потока управления для моделирования исходного графа потока управления, и несущественный код используют множество переменных, не пересекающихся с основными переменными маскируемой функции. В результате функция может быть расслоена на существенную и несущественную часть, хотя это может быть и затруднено необходимостью проведения анализа указателей.
Чтобы затруднить отделение несущественной части замаскированной функции в неё добавляется большое количество искусственных зависимостей по данным между существенной и несущественной частью. Для этого в настоящее время используются булевские, теоретико-числовые и комбинаторные тождества, а также массивы и динамическе структуры данных.
Булевские тождества. Булевские тождества применяются для усложнения булевских выражений, которые определяют условные переходы. В отличие от других видов тождеств, булевские тождества произвольной сложности легко могут получаться автоматически. Рассмотрим в качестве примера основной метод получения булевских тождеств, реализованный в настоящее время.
Булевские тождества произвольной сложности могут быть получены из булевских тождеств относительно простой структуры при помощи набора эквивалентных преобразований. Пусть мы хотим составить булевское тождество с переменными v1, v2, ..., vk, среди которых есть как переменные исходной функции, так и несущественные переменные, внесённые при маскировке. Пусть e - выражение, подвергаемое усложнению. Тогда строится выражение 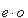 , где
, где 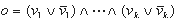 . Далее к получившемуся выражению применяются m шагов эквивалентных преобразований, которые можно найти, например, в [3]. В результате получается выражение e', эквивалентное e, которое используется для условного перехода в замаскированной программе.
. Далее к получившемуся выражению применяются m шагов эквивалентных преобразований, которые можно найти, например, в [3]. В результате получается выражение e', эквивалентное e, которое используется для условного перехода в замаскированной программе.
Такой метод получения булевских тождеств аналогичен методу получения непрозрачных предикатов, рассмотренному в работе [8], но в данном случае использование тождеств не приводит к появлению недостижимой дуги графа потока управления, которая достаточно легко может быть обнаружена. Поэтому использование булевских тождеств в нашем случае обнаруживается значительно сложнее.
Комбинаторные тождества. Все рассматриваемые далее тождества, как комбинаторные, так и теоретико-числовые взяты, в основном, из [3]. Рассмотрим в качестве примера следующее биномиальное тождество 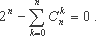 .
.
Тождество может использоваться следующим образом: в качестве n берётся несущественная переменная, принимающая целые значения в небольшом интервале (например, от 0 до 5). Генерируются инструкции, вычисляющие сумму биномиальных коэффициентов и помещающие результат во временную переменную, для определённости @1. Генерируется инструкция сдвига, вычисляющая 2n и помещающая результат в другую временную переменную, например @2. Далее в исходной функции выбирается аддитивное целое выражение, результат которого сохраняется в некоторой временной переменной, например, @3, и строится новое выражение @1 + @3 - @2. Это выражение всегда будет равно выражению @3, но содержит зависимость по данным от переменной n.
Некоторые другие тождества, которые могут использоваться аналогичным образом, приведены ниже.
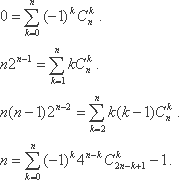
Теоретико-числовые тождества. В качестве примера рассмотрим известную малую теорему Ферма.
ap-11 (mod p)
для любого целого 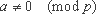 и простого p. При маскировке генерируется случайное простое число p. Далее генерируются инструкции для вычисления ap-1 mod p, причём возведение в степень вычисляется с помощью разложения p-1 в двоичную систему. Эти инструкции образуют достаточно длинную линейную последовательность, которая может быть распределена по базовым блокам маскируемой функции. Результат вычисления выражения добавляется как множитель в какое-либо мультипликативное выражение исходной программы, либо как множитель к переменной.
и простого p. При маскировке генерируется случайное простое число p. Далее генерируются инструкции для вычисления ap-1 mod p, причём возведение в степень вычисляется с помощью разложения p-1 в двоичную систему. Эти инструкции образуют достаточно длинную линейную последовательность, которая может быть распределена по базовым блокам маскируемой функции. Результат вычисления выражения добавляется как множитель в какое-либо мультипликативное выражение исходной программы, либо как множитель к переменной.
Другие теоретико-числовые тождества, которые также могут использоваться для внесения зависимостей по данным, приведены ниже. Обобщением малой теоремы Ферма является теорема Эйлера:
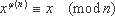
 - функция Эйлера, которая равна количеству взаимно простых с n целых чисел, меньших n.
- функция Эйлера, которая равна количеству взаимно простых с n целых чисел, меньших n.
(n-1)! -1 (mod n) (теорема Вилсона)
тогда и только тогда, когда n - простое число.
Использование массивов и динамических структур данных. Динамические структуры данных могут использоваться и для создания искусственных зависимостей по данным. Главный расчёт здесь делается на то, что в настоящее время не существует удовлетворительного алгоритма анализа алиасов, возникающих при использовании указателей и индексов массивов.
В качестве простейшего способа можно предложить размещение всех локальных переменных одного типа в массиве. В тексте функции вместо имени переменной теперь будет использоваться индекс массива. Даже случаев, когда индекс всегда представляет собой литеральную константу, будет достаточно, чтобы поставить в тупик простейшие алгоритмы анализа алиасов, которые рассматривают массив как единое целое.
В момент маскировки программы известно, какие элементы массива заняты существенными, а какие - несущественными переменными. Более того, распределение несущественных переменных по массиву может выбираться произвольным образом. Это может использоваться для построения зависимостей по данным. Пусть f - функция, ставящая в соответствие произвольному целому значению некоторый индекс в массиве, по которому находится несущественная переменная. Тогда искусственные зависимости по данным строятся с помощью выражений вида vars[f(e1)] = e2 или vars[f(e1)] = vars[f(e2)]. Здесь vars - это массив переменных, e1, e2 - выражения, которые включают в себя как существенные, так и несущественные переменные.
Один из простых способов использования динамических структур данных для внесения зависимостей по данным заключается в том, что все значения переменных всех типов хранятся в списке, размещаемом в динамической памяти. Для доступа к переменным вместо их имени используется разыменование специальных указателей. Кроме того, указатели на несущественные переменные время от времени меняют своё положение в списке. В результате окажется, что все обращения к бывшим локальным переменным функции обращаются к объектам в области динамической памяти. Для разделения существенных и несущественных переменных потребуется анализ алиасов в динамической памяти, способный работать с динамическими структурами данных произвольной глубины. В настоящее время не существует такого метода статического анализа алиасов.
Этот подход проиллюстрирован на рис. 8, На котором функция содержит четыре переменных a, b, c и d. Пусть, для определённости, переменные a и b - существенные, а c и d - несущественные. В замаскированной функции вместо этих локальных переменных вводятся переменные p1 и p2, указывающие на звенья списка, размещённого в динамической памяти. Переменная a доступна как p1->prev или как p2->next, а переменная c - как p1->next или как p2->prev.
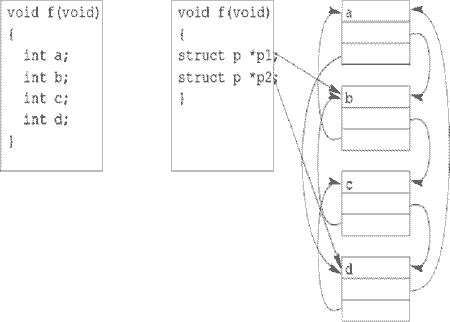
Рис. 8. Использование списков для внесения зависимостей по данным
В начало Дальше