4. Синтаксический анализ
4.1 КС-грамматики и МП-автоматы
Пусть G = (N, T, P, S) - контекстно-свободная грамматика. Введем несколько важных понятий и определений.
Вывод, в
котором
в любой
сентенциальной
форме на
каждом шаге
делается
подстановка
самого
левого
нетерминала,
называется
левосторонним.
Если S 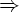 *u в
процессе
левостороннего
вывода, то
u - левая
сентенциальная
форма.
Аналогично
определяется
правосторонний
вывод. Будем
обозначать
шаги левого
(правого)
вывода
посредством
l (r).
*u в
процессе
левостороннего
вывода, то
u - левая
сентенциальная
форма.
Аналогично
определяется
правосторонний
вывод. Будем
обозначать
шаги левого
(правого)
вывода
посредством
l (r).
Упорядоченным графом называется пара (V, E), где V есть множество вершин, а E - множество линейно упорядоченных списков дуг, каждый элемент которого имеет вид ((v, v1), (v, v2), ..., (v, vn)). Этот элемент указывает, что из вершины v выходят n дуг, причем первой из них считается дуга, входящая в вершину v1, второй - дуга, входящая в вершину v2, и т.д.
Упорядоченным
помеченным
деревом
называется
упорядоченный
граф (V, E),
основой
которого
является
дерево и для
которого
определена
функция f : V  F
(функция
разметки) для
некоторого
множества
F.
F
(функция
разметки) для
некоторого
множества
F.
Упорядоченное помеченное дерево D называется деревом вывода (или деревом разбора) цепочки w в КС-грамматике G = (N, T, P, S), если выполнены следующие условия:
- корень дерева D помечен S;
- каждый
лист
помечен
либо a
 T,
либо e;
T,
либо e;
- каждая внутренняя
вершина помечена
нетерминалом
A N;
- если X - нетерминал,
которым помечена
внутренняя
вершина и
X1, ..., Xn - метки ее
прямых потомков
в указанном
порядке, то
X X1...Xk - правило
из множества
P;
- Цепочка, составленная из выписанных слева направо меток листьев, равна w.
Грамматика G называется неоднозначной, если существует цепочка w, для которой имеется два или более различных деревьев вывода в G.
Грамматика
G называется
леворекурсивной,
если в ней
имеется
нетерминал
A такой, что
существует
вывод A +A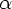 для
некоторой
цепочки .
для
некоторой
цепочки .
Автомат с
магазинной
памятью
(МП-автомат) -
это семерка
M = (Q, T, 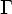 , D, q0, Z0, F), где
, D, q0, Z0, F), где
- Q - конечное множество состояний, представляющих всевозможные состояния управляющего устройства;
- T - конечный входной алфавит;
- - конечный
алфавит магазинных
символов;
- D - отображение
множества
QЧ(T
 {e})Ч в множество
конечных
подмножеств
QЧ*, называемое
функцией
переходов;
{e})Ч в множество
конечных
подмножеств
QЧ*, называемое
функцией
переходов;
- q0 Q - начальное
состояние
управляющего
устройства;
- Z0 - символ,
находящийся
в магазине
в начальный
момент (начальный
символ магазина);
- F
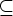 Q - множество
заключительных
состояний.
Q - множество
заключительных
состояний.
Конфигурацией МП-автомата называется тройка (q, w, u), где
- q Q - текущее
состояние
управляющего
устройства;
- w T* - непрочитанная
часть входной
цепочки; первый
символ цепочки
w находится
под входной
головкой;
если w = e, то считается,
что вся входная
лента прочитана;
- u * - содержимое
магазина;
самый левый
символ цепочки
u считается
верхним символом
магазина;
если u = e, то магазин
считается
пустым.
Такт работы
МП-автомата
M будем
представлять
в виде
бинарного
отношения 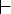 ,
определенного
на конфигурациях.
Будем писать
,
определенного
на конфигурациях.
Будем писать
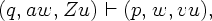 Q, a T {e}, w T*, Z и
u, v *.
Q, a T {e}, w T*, Z и
u, v *.
Начальной
конфигурацией
МП-автомата
M называется
конфигурация
вида (q0, w, Z0),
где w T*, т.е.
управляющее
устройство
находится в
начальном
состоянии,
входная
лента
содержит
цепочку,
которую
нужно
проанализировать,
а в магазине
находится
только
начальный
символ Z0.
Заключительная
конфигурация
- это
конфигурация
вида (q, e, u),
где q F, u *, т.е.
управляющее
устройство
находится
в одном из
заключительных
состояний,
а входная
цепочка
целиком
прочитана.
Введем
транзитивное
и рефлексивно-транзитивное
замыкание
отношения ,
а также его
степень k 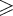 0
(обозначаемые
+, * и k соответственно).
0
(обозначаемые
+, * и k соответственно).
Говорят,
что цепочка w
допускается
МП-автоматом
M, если
(q0, w, Z0) *(q, e, u) для
некоторых
q F и u *.
Язык, допускаемый (распознаваемый, определяемый) автоматом M (обозначается L(M)) - это множество всех цепочек, допускаемых автоматом M.
Пример 4.1. Рассмотрим МП-автомат
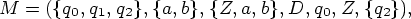
D(q0, a, Z) = {(q0, aZ)},
D(q0, b, Z) = {(q0, bZ)},
D(q0, a, a) = {(q0, aa), {q1, e)},
D(q0, a, b) = {(q0, ab)},
D(q0, b, a) = {(q0, ba)},
D(q0, b, b) = {(q0, bb), (q1, e)},
D(q1, a, a) = {(q1, e)},
D(q1, b, b) = {(q1, e)},
D(q1, e, Z) = {(q2, e)}.
Нетрудно
показать,
что L(M) = {wwR|w 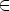 {a, b}+}, где wR
обозначает
обращение
(«переворачивание»)
цепочки w.
{a, b}+}, где wR
обозначает
обращение
(«переворачивание»)
цепочки w.
Иногда
допустимость
определяют
несколько
иначе:
цепочка w
допускается
МП-автоматом
M, если (q0, w, Z0) *(q, e, e) для
некоторого
q Q. В таком
случае
говорят,
что автомат
допускает
цепочку
опустошением
магазина. Эти
определения
эквивалентны,
ибо
справедлива
Теорема 4.1. Язык допускается магазинным автоматом тогда и только тогда, когда он допускается (некоторым другим автоматом) опустошением магазина.
Доказательство. Пусть L = L(M) для
некоторого
МП-автомата
M = (Q, T, , D, q0, Z0, F). Построим
новый
МП-автомат M',
допускающий
тот же язык
опустошением
магазина.
Пусть M' = (Q{q0', qe}, T, {Z0'}, D', q0', Z0', 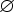 ),
где функция
переходов D'
определена
следующим
образом:
),
где функция
переходов D'
определена
следующим
образом:
- Если (r, u) D(q, a, Z),
то (r, u) D'(q, a, Z) для
всех q Q, a T {e} и
Z ;
- D'(q0', e, Z0') = {(q0, Z0Z0')};
- Для всех q
F и Z {Z0'} множество
D'(q, e, Z) содержит
(qe, e);
- D'(qe, e, Z) = {(qe, e)} для
всех Z {Z0'}.
Автомат
сначала
переходит в
конфигурацию
(q0, w, Z0Z0') в
соответствии
с
определением
D' в п.2, затем
в (q, e, Y 1...Y kZ0'), q F в
соответствии
с п.1, затем
в (qe, e, Y 1...Y kZ0'), q F в
соответствии
с п.3, затем в (qe, e, e) в
соответствии
с п.4. Нетрудно
показать по
индукции,
что (q0, w, Z0) +(q, e, u) (где q F)
выполняется
для автомата
M тогда и
только тогда,
когда (q0', w, Z0') +(qe, e, e)
выполняется
для автомата
M'. Поэтому L(M) = L',
где L' - язык,
допускаемый
автоматом M'
опустошением
магазина.
Обратно,
пусть M = (Q, T, , D, q0, Z0, ) -
МП-автомат,
допускающий
опустошением
магазина
язык L.
Построим
автомат M',
допускающий
тот же
язык по
заключительному
состоянию.
Пусть
M' = (Q{q0', qf}, T, {Z0}, D', q0', Z0', {qf}), где D'
определяется
следующим
образом:
- D'(q0', e, Z0') = {(q0, Z0Z0')} - переход в «режим M»;
- Для каждого
q Q, a T{e}, и Z определим
D'(q, a, Z) = D(q, a, Z) - работа
в «режиме
M»;
- Для всех q
Q, (qf, e) D'(q, e, Z0') - переход
в заключительное
состояние.
Нетрудно показать по индукции, что L = L(M'). __
Одним из важнейших результатов теории контекстно-свободных языков является доказательство эквивалентности МП-автоматов и КС-грамматик.
Теорема 4.2. Язык является контекстно-свободным тогда и только тогда, когда он допускается магазинным автоматом.
Доказательство. Пусть G = (N, T, P, S) - КС-грамматика. Построим МП-автомат M, допускающий язык L(G) опустошением магазина.
Пусть
M = ({q}, T, N T, D, q, S, ), где D
определяется
следующим
образом:
- Если A u P, то
(q, u) D(q, e, A);
- D(q, a, a) = {(q, e)} для
всех a T.
Фактически,
этот
МП-автомат
в точности
моделирует
все возможные
выводы в
грамматике
G. Нетрудно
показать по
индукции,
что для любой
цепочки w T*
вывод S +w в
грамматике
G существует
тогда и
только
тогда, когда
существует
последовательность
тактов (q, w, S) +(q, e, e)
автомата
M.
Обратно,
пусть M = (Q, T, , D, q0, Z0, ) -
МП-автомат,
допускающий
опустошением
магазина
язык L.
Построим
грамматику G,
порождающую
язык L.
Пусть G = ({ [qZr] | q, r Q, Z }{S}, T, P, S),
где P состоит
из правил
следующего
вида:
- Если (r, X1...Xk) D(q, a, Z), k 1,
то
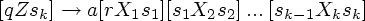
- Если (r, e) D(q, a, Z),
то [qZr] a P, a T {e};
- S [q0Z0q] P для
всех q Q.
Нетерминалы и правила вывода грамматики определены так, что работе автомата M при обработке цепочки w соответствует левосторонний вывод w в грамматике G.
Индукцией
по числу
шагов вывода
в G или числу
тактов M
нетрудно
показать,
что (q, w, A) +(p, e, e) тогда
и только
тогда, когда
[qAp] +w.
Тогда, если
w L(G), то S [q0Z0q] +w для
некоторого q Q.
Следовательно,
(q0, w, Z0) +(q, e, e) и поэтому
w L. Аналогично,
если w L, то (q0, w, Z0) +(q, e, e).
Значит, S [q0Z0q] +w,
и поэтому
w L(G).
__
МП-автомат M =
(Q, T, , D, q0, Z0, F) называется
детерминированным
(ДМП-автоматом),
если
выполнены
следующие
два условия:
- Множество
D(q, a, Z) содержит
не более одного
элемента
для любых
q Q, a T {e}, Z ;
- Если D(q, e, Z)
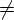 ,
то D(q, a, Z) = для
всех a T.
,
то D(q, a, Z) = для
всех a T.
Язык, допускаемый ДМП-автоматом, называется детерминированным КС-языком.
Так как функция переходов ДМП-автомата содержит не более одного элемента для любой тройки аргументов, мы будем пользоваться записью D(q, a, Z) = (p, u) для обозначения D(q, a, Z) = {(p, u)}.
Пример 4.2. Рассмотрим ДМП-автомат
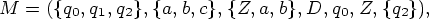
D(q0, X, Y ) = (q0, XY ), X {a, b}, Y {Z, a, b},
D(q0, c, Y ) = (q1, Y ), Y {a, b},
D(q1, X, X) = (q1, e), X {a, b},
D(q1, e, Z) = (q2, e).
Нетрудно
показать,
что этот
детерминированный
МП-автомат
допускает
язык L = {wcwR|w {a, b}+}.
К сожалению, ДМП-автоматы имеют меньшую распознавательную способность, чем МП-автоматы. Доказано, в частности, что существуют КС-языки, не являющиеся детерминированными КС-языками (таковым, например, является язык из примера 4.1).
Рассмотрим еще одну важную разновидность МП-автомата.
Расширенным
автоматом с
магазинной
памятью
назовем
семерку
M = (Q, T, , D, q0, Z0, F), где
смысл всех
символов
тот же,
что и для
обычного
МП-автомата,
кроме D,
представляющего
собой
отображение
конечного
подмножества
множества QЧ(T {e})Ч*
во множество
конечных
подмножеств
множества QЧ*.
Все остальные
определения
(конфигурации,
такта,
допустимости)
для
расширенного
МП-автомата
остаются
такими же,
как для
обычного.
Теорема 4.3. Пусть M = (Q, T, , D, q0, Z0, F) -
расширенный
МП-автомат.
Тогда
существует
такой
МП-автомат
M', что L(M') = L(M).
Расширенный
МП-автомат M = (Q, T, , D, q0, Z0, F)
называется
детерминированным,
если
выполнены
следующие
условия:
- Множество
D(q, a, u) содержит
не более одного
элемента
для любых
q Q, a T {e}, Z *;
- Если D(q, a, u)
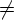 , D(q, a, v)
, D(q, a, v)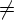 и
u
и
u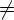 v, то не существует
цепочки x такой,
что u = vx или v =
ux;
v, то не существует
цепочки x такой,
что u = vx или v =
ux;
- Если D(q, a, u)
 , D(q, e, v)
, D(q, e, v) , то
не существует
цепочки x такой,
что u = vx или v =
ux.
, то
не существует
цепочки x такой,
что u = vx или v =
ux.
Теорема 4.4. Пусть M = (Q, T, , D, q0, Z0, F) -
расширенный
ДМП-автомат.
Тогда
существует
такой
ДМП-автомат
M', что L(M') = L(M).
ДМП-автомат и расширенный ДМП-автомат лежат в основе рассматриваемых далее в этой главе, соответственно, LL и LR-анализаторов.
4.2 Преобразования КС-грамматик
Рассмотрим ряд преобразований, позволяющих «улучшить» вид контекстно-свободной грамматики, без изменения порождаемого ею языка.
Назовем
символ X (N T)
недостижимым
в
КС-грамматике
G = (N, T, P, S), если X не
появляется
ни в одной
выводимой
цепочке этой
грамматики.
Иными
словами,
символ X
является
недостижимым,
если в G не
существует
вывода S *X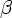 ни
для каких
, (N T)*.
ни
для каких
, (N T)*.
Алгоритм 4.1. Устранение недостижимых символов.
Вход. КС-грамматика G = (N, T, P, S).
Выход. КС-грамматика G' = (N', T', P', S) без недостижимых символов, такая, что L(G') = L(G).
Метод. Выполнить шаги 1-4:
- Положить V 0 = {S} и i = 1.
- Положить
V i = {X | в P есть A
X и A V i-1} V i-1.
- Если V i
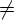 V i-1, положить
i = i+1 и перейти
к шагу 2. В противном
случае перейти
к шагу 4.
V i-1, положить
i = i+1 и перейти
к шагу 2. В противном
случае перейти
к шагу 4.
- Положить
N' = V i
 N, T' = V iT. Включить
в P' все правила
из P, содержащие
только символы
из V i.
N, T' = V iT. Включить
в P' все правила
из P, содержащие
только символы
из V i.
Назовем
символ X (N T)
бесполезным в
КС-грамматике
G = (N, T, P, S), если
в ней не
существует
вывода вида
S *xXy *xwy, где w, x, y
принадлежат
T*. Очевидно,
что каждый
недостижимый
символ
является
бесполезным.
Алгоритм 4.2. Устранение бесполезных символов.
Вход. КС-грамматика G = (N, T, P, S).
Выход. КС-грамматика G' = (N', T', P', S) без бесполезных символов, такая, что L(G') = L(G).
Метод. Выполнить шаги 1-5:
- Положить
N0 = и i = 1.
- Положить
Ni = {A|A P и (Ni-1 T)*} Ni-1.
- Если Ni
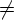 Ni-1, положить
i = i+1 и перейти
к шагу 2. В противном
случае положить
Ne = Ni и перейти
к шагу 4.
Ni-1, положить
i = i+1 и перейти
к шагу 2. В противном
случае положить
Ne = Ni и перейти
к шагу 4.
- Положить
G1 = ((NNe){S}, T, P1, S), где P1 состоит
из правил
множества
P, содержащих
только символы
из Ne T.
- Применив к G1 алгоритм 4.1, получить G' = (N', T', P', S).
КС-грамматика без бесполезных символов называется приведенной. Легко видеть, что для любой КС-грамматики существует эквивалентная приведенная. В дальнейшем будем предполагать, что все рассматривамые грамматики - приведенные.
4.3 Предсказывающий разбор сверху-вниз
4.3.1 Алгоритм разбора сверху-вниз
Пусть дана КС-грамматика G = (N, T, P, S). Рассмотрим предсказывающий разбор (или разбор сверху-вниз) для грамматики G.
Основная задача предсказывающего разбора - определение правила вывода, которое нужно применить к нетерминалу. Процесс предсказывающего разбора с точки зрения построения дерева разбора проиллюстрирован на рис. 4.1.
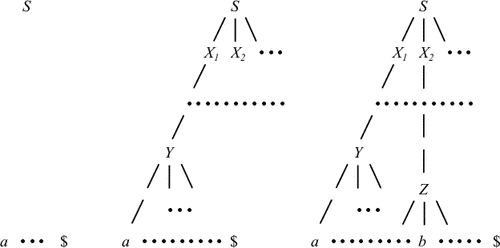
|
Фрагменты
недостроенного
дерева
соответствуют
сентенциальным
формам.
Вначале
дерево
состоит
только
из одной
вершины,
соответствующей
аксиоме S. В
этот момент
по первому
символу
входной
цепочки
предсказывающий
анализатор
должен
определить
правило S X1X2...
, которое
должно быть
применено
к S. Затем
необходимо
определить
правило,
которое
должно быть
применено
к X1, и т.д., до тех
пор, пока в
процессе
такого
построения
сентенциальной
формы,
соответствующей
левому
выводу,
не будет
применено
правило
Y a... . Этот
процесс
затем
применяется
для
следующего
самого
левого
нетерминального
символа
сентенциальной
формы.
На рис. 4.2 приведена структура предсказывающего анализатора, который определяет очередное правило с помощью таблицы. Такую таблицу можно построить непосредственно по грамматике.
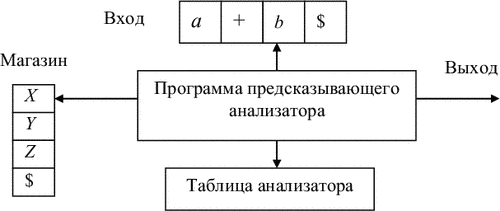
|
Таблично-управляемый предсказывающий анализатор имеет входную ленту, управляющее устройство (программу), таблицу анализа, магазин (стек) и выходную ленту.
Входная лента содержит анализируемую строку, заканчивающуюся символом $ - маркером конца строки. Выходная лента содержит последовательность примененных правил вывода.
Таблица анализа - это двумерный массив M[A, a], где A - нетерминал, и a - терминал или символ $. Значением M[A, a] может быть некоторое правило грамматики или элемент «ошибка».
Магазин может содержать последовательность символов грамматики с $ на дне. В начальный момент магазин содержит только начальный символ грамматики на верхушке и $ на дне.
Анализатор работает следующим образом. Вначале анализатор находится в конфигурации, в которой магазин содержит S$, на входной ленте w$ (w - анализируемая цепочка), выходная лента пуста. На каждом такте анализатор рассматривает X - символ на верхушке магазина и a - текущий входной символ. Эти два символа определяют действия анализатора. Имеются следующие возможности.
1. Если X = a = $, анализатор останавливается, сообщает об успешном окончании разбора и выдает содержимое выходной ленты.
2. Если X = a $,
анализатор
удаляет X из
магазина и
продвигает
указатель
входа на
следующий
входной
символ.
$,
анализатор
удаляет X из
магазина и
продвигает
указатель
входа на
следующий
входной
символ.
3. Если X -
терминал, и X a, то
анализатор
останавливается
и сообщает
о том, что
входная
цепочка не
принадлежит
языку.
a, то
анализатор
останавливается
и сообщает
о том, что
входная
цепочка не
принадлежит
языку.
4. Если X - нетерминал, анализатор заглядывает в таблицу M[X, a]. Возможны два случая:
- Значением M[X, a] является правило для X. В этом случае анализатор заменяет X на верхушке магазина на правую часть данного правила, а само правило помещает на выходную ленту. Указатель входа не передвигается.
- Значением M[X, a] является «ошибка». В этом случае анализатор останавливается и сообщает о том, что входная цепочка не принадлежит языку.
Работа анализатора может быть задана следующей программой:
do
{X=верхний символ магазина; if (X - терминал || X=="$") if (X==InSym) {удалить X из магазина; InSym=очередной символ; } else error(); else /*X - нетерминал*/ if (M[X,InSym]=="X->Y1Y2...Yk") {удалить X из магазина; поместить Yk,Yk-1,...Y1 в магазин (Y1 на верхушку); вывести правило X->Y1Y2...Yk; } else error(); /*вход таблицы M пуст*/ } while (X!=$) /*магазин пуст*/ |
Пример 4.3. Рассмотрим грамматику арифметических выражений G = ({E, E', T, T', F}, {id, +, *, (, )}, P, E) с правилами:
E  TE' TE' | T' *FT' |
||
E' +TE' | T' e |
||
E' e | F (E) |
||
T FT' | F id |
||
Таблица предсказывающего анализатора для этой грамматики приведена на рис. 4.3. Пустые клетки таблицы соответствуют элементу «ошибка».

|
При разборе входной цепочки id + id * id$ анализатор совершает последовательность шагов, изображенную на рис. 4.4. Заметим, что анализатор осуществляет в точности левый вывод. Если за уже просмотренными входными символами поместить символы грамматики в магазине, то можно получить в точности левые сентенциальные формы вывода. Дерево разбора для этой цепочки приведено на рис. 4.5.

|
|
4.3.2 Функции FIRST и FOLLOW
При построении таблицы предсказывающего анализатора нам потребуются две функции - FIRST и FOLLOW.
Пусть G = (N, T, P, S) -
КС-грамматика.
Для -
произвольной
цепочки,
состоящей
из символов
грамматики,
определим
FIRST() как
множество
терминалов,
с которых
начинаются
строки,
выводимые
из . Если *e,
то e также
принадлежит
FIRST().
Определим
FOLLOW(A) для
нетерминала A
как множество
терминалов
a, которые
могут
появиться
непосредственно
справа от A в
некоторой
сентенциальной
форме
грамматики,
т.е. множество
терминалов
a таких, что
существует
вывод
вида S *Aa для
некоторых
, (N T)*. Заметим,
что между A и
a в процессе
вывода могут
находиться
нетерминальные
символы,
из которых
выводится e.
Если A может
быть самым
правым
символом
некоторой
сентенциальной
формы, то
$ также
принадлежит
FOLLOW(A).
Рассмотрим алгоритмы вычисления функции FIRST.
Алгоритм 4.3. Вычисление FIRST для символов грамматики.
Вход. КС-грамматика G = (N, T, P, S).
Выход.
Множество FIRST(X)
для каждого
символа X (N T).
Метод. Выполнить шаги 1-3:
- Если X - терминал,
то положить
FIRST(X) = {X};
если X - нетерминал,
положить
FIRST(X) = .
- Если в P имеется
правило X
e, то добавить
e к FIRST(X).
- Пока ни к какому
множеству
FIRST(X) нельзя уже
будет добавить
новые элементы,
выполнять:
если X - нетерминал и имеется правило вывода X
Y 1Y 2...Y k, то включить
a в FIRST(X), если a FIRST(Y i)
для некоторого i,
1  i k, и e принадлежит
всем FIRST(Y 1), ..., FIRST(Y i-1), то
есть Y 1...Y i-1 *e. Если
e принадлежит
FIRST(Y j) для всех
j = 1, 2, ..., k, то добавить
e к FIRST(X).
i k, и e принадлежит
всем FIRST(Y 1), ..., FIRST(Y i-1), то
есть Y 1...Y i-1 *e. Если
e принадлежит
FIRST(Y j) для всех
j = 1, 2, ..., k, то добавить
e к FIRST(X).
Алгоритм 4.4. Вычисление FIRST для цепочки.
Вход. КС-грамматика G = (N, T, P, S).
Выход.
Множество
FIRST(X1X2...Xn), Xi (N T).
Метод. Выполнить шаги 1-3:
- При помощи
предыдущего
алгоритма
вычислить
FIRST(X) для каждого
X (N T).
- Положить
FIRST(X1X2...Xn) = .
- Добавить
к FIRST(X1X2...Xn) все не
e-элементы
из FIRST(X1). Добавить
к нему также
все не e-элементы
из FIRST(X2), если
e FIRST(X1), не e-элементы
из FIRST(X3), если
e принадлежит
как FIRST(X1), так
и FIRST(X2), и т.д. Наконец,
добавить
цепочку e к
FIRST(X1X2...Xn), если e FIRST(Xi)
для всех i.
Рассмотрим алгоритм вычисления функции FOLLOW.
Алгоритм 4.5. Вычисление FOLLOW для нетерминалов грамматики.
Вход. КС-грамматика G = (N, T, P, S).
Выход.
Множество FOLLOW(X)
для каждого
символа X N.
Метод. Выполнить шаги 1-4:
- Положить
FOLLOW(X) = для каждого
символа X
N.
- Добавить $ к FOLLOW(S).
- Если в P eсть
правило вывода
A B, где , (NT)* то
все элементы
из FIRST(), за исключением
e, добавить
к FOLLOW(B).
- Пока ничего
нельзя будет
добавить
ни к какому
множеству
FOLLOW(X), выполнять:
если в P есть правило A
B или A B, , (NT)*, где
FIRST() содержит
e (т.е. *e), то все
элементы
из FOLLOW(A) добавить
к FOLLOW(B).
Пример 4.4. Рассмотрим грамматику из примера 4.3. Для нее
FIRST(E) = FIRST(T) = FIRST(F) = {(, id} |
|
FIRST(E') = {+, e} |
|
FIRST(T') = {*, e} |
|
FOLLOW(E) = FOLLOW(E') = { ), $} |
|
FOLLOW(T) = FOLLOW(T') = {+, ), $} |
|
FOLLOW(F) = {+, *, ), $} |
|
Например, id и
левая скобка
добавляются
к FIRST(F) на шаге 3 при
i = 1, поскольку
FIRST(id) = {id} и FIRST(”(”) = {”(”} в
соответствии
с шагом 1. На
шаге 3 при i = 1, в
соответствии
с правилом
вывода T FT' к FIRST(T)
добавляются
также id и
левая скобка.
На шаге 2 в FIRST(E')
включается
e.
При
вычислении
множеств FOLLOW
на шаге 2 в FOLLOW(E)
включается
$. На шаге 3, на
основании
правила F (E), к FOLLOW(E)
добавляется
также правая
скобка.
На шаге 4,
примененном
к правилу E TE', в
FOLLOW(E') включаются
$ и правая
скобка.
Поскольку
E'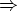 *e, они также
попадают и во
множество FOLLOW(T). В
соответствии
с правилом
вывода E TE',
на шаге 3 в FOLLOW(T)
включаются и
все элементы
из FIRST(E'), отличные
от e.
*e, они также
попадают и во
множество FOLLOW(T). В
соответствии
с правилом
вывода E TE',
на шаге 3 в FOLLOW(T)
включаются и
все элементы
из FIRST(E'), отличные
от e.
4.3.3 Конструирование таблицы предсказывающего анализатора
Для
конструирования
таблицы
предсказывающего
анализатора
по грамматике
G может быть
использован
алгоритм,
основанный
на следующей
идее.
Предположим,
что A -
правило
вывода
грамматики
и a FIRST(). Тогда
анализатор
делает
развертку
A по , если
входным
символом
является a.
Трудность
возникает,
когда = e или
*e. В этом
случае нужно
развернуть
A в , если
текущий
входной
символ
принадлежит
FOLLOW(A) или если
достигнут
$ и $ FOLLOW(A).
Алгоритм 4.6. Построение таблицы предсказывающего анализатора.
Вход. КС-грамматика G = (N, T, P, S).
Выход.
Таблица M[A, a]
предсказывающего
анализатора,
A N, a T {$}.
Метод. Для
каждого
правила
вывода A
грамматики
выполнить
шаги 1 и 2.
После этого
выполнить
шаг 3.
- Для каждого
терминала
a из FIRST() добавить
A к M[A, a].
- Если e FIRST(), добавить
A к M[A, b] для каждого
терминала
b из FOLLOW(A). Кроме
того, если
e FIRST() и $ FOLLOW(A), добавить
A к M[A, $].
- Положить все неопределенные входы равными «ошибка».
Пример 4.5. Применим
алгоритм 4.6 к
грамматике
из примера
4.3. Поскольку
FIRST(TE') = FIRST(T) = {(, id }, в
соответствии
с правилом
вывода E TE'
входы M[E, ( ] и M[E, id ]
становятся
равными E TE'.
В
соответствии
с правилом
вывода E' +TE'
значение
M[E', +] равно E' +TE'. В
соответствии
с правилом
вывода E' e
значения
M[E', )] и M[E', $] равны E' e,
поскольку
FOLLOW(E') = { ), $}.
Таблица анализа, построенная алгоритмом 4.6 для этой грамматики, приведена на рис. 4.3.
4.3.4 LL(1)-грамматики
Алгоритм 4.6 для построения таблицы предсказывающего анализатора может быть применен к любой КС-грамматике. Однако для некоторых грамматик построенная таблица может иметь неоднозначно определенные входы. Нетрудно доказать, например, что если грамматика леворекурсивна или неоднозначна, таблица будет иметь по крайней мере один неоднозначно определенный вход.
Грамматики, для которых таблица предсказывающего анализатора не имеет неоднозначно определенных входов, называются LL(1)-грамматиками. Предсказывающий анализатор, построенный для LL(1)-грамматики, называется LL(1)-анализатором. Первая буква L в названии связано с тем, что входная цепочка читается слева направо, вторая L означает, что строится левый вывод входной цепочки, 1 - что на каждом шаге для принятия решения используется один символ непрочитанной части входной цепочки.
Доказано, что алгоритм 4.6 для каждой LL(1)-грамматики G строит таблицу предсказывающего анализатора, распознающего все цепочки из L(G) и только эти цепочки. Нетрудно доказать также, что если G - LL(1)-грамматика, то L(G) - детерминированный КС-язык.
Справедлив
также
следующий
критерий
LL(1)-грамматики.
Грамматика
G = (N, T, P, S) является
LL(1)-грамматикой
тогда и
только
тогда, когда
для каждой
пары правил
A , A из P (т.е.
правил с
одинаковой
левой
частью)
выполняются
следующие
2 условия:
- FIRST() FIRST() = ;
- Если e FIRST(),
то FIRST() FOLLOW(A) = .
Язык, для которого существует порождающая его LL(1)-грамматика, называют LL(1)-языком. Доказано, что проблема определения того, порождает ли грамматика LL-язык, является алгоритмически неразрешимой.
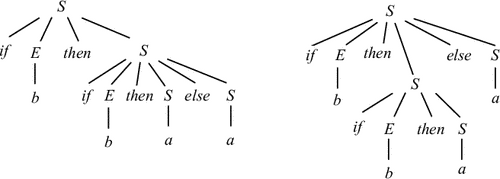
Пример 4.6. Неоднозначная грамматика не является LL(1). Примером может служить следующая грамматика G = ({S, E}, {if, then, else, a, b}, P, S) с правилами:
S if E then S | if E then S else S | a |
|
E b |
|
Эта грамматика является неоднозначной, что иллюстрируется на рис. 4.6.
|
4.3.5 Удаление левой рекурсии
Основная трудность при использовании предсказывающего анализа - это нахождение такой грамматики для входного языка, по которой можно построить таблицу анализа с однозначно определенными входами. Иногда с помощью некоторых простых преобразований грамматику, не являющуюся LL(1), можно привести к эквивалентной LL(1)-грамматике. Среди этих преобразований наиболее эффективными являются левая факторизация и удаление левой рекурсии. Здесь необходимо сделать два замечания. Во-первых, не всякая грамматика после этих преобразований становится LL(1), и, во-вторых, после таких преобразований получающаяся грамматика может стать менее понимаемой.
Непосредственную
левую
рекурсию,
т.е. рекурсию
вида A A, можно
удалить
следующим
способом.
Сначала
группируем
A-правила:
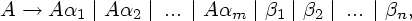 i не
начинается
с A. Затем
заменяем
этот набор
правил на
i не
начинается
с A. Затем
заменяем
этот набор
правил на
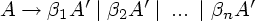
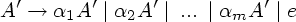
Алгоритм 4.7. Удаление левой рекурсии.
Вход.
КС-грамматика
G без e-правил
(правил
вида A e).
Выход. КС-грамматика G' без левой рекурсии, эквивалентная G.
Метод. Выполнить шаги 1 и 2.
- Упорядочить нетерминалы грамматики G в произвольном порядке.
- Выполнить
следующую
процедуру:
for (i=1;i<=n;i++){
for (j=1;j<=i-1;j++){
пусть Aj
1 | 2 | ... | k
- все текущие
правила
для Aj;
заменить все правила вида Ai
Aj
на правила Ai
1 | 2 | ... | k;
}
удалить правила вида Ai
Ai;
удалить непосредственную левую рекурсию в правилах для Ai;
}
После (i - 1)-й
итерации
внешнего
цикла на
шаге 2 для
любого
правила
вида Ak As, где k < i,
выполняется s > k.
В результате
на следующей
итерации (по
i) внутренний
цикл (по j)
последовательно
увеличивает
нижнюю
границу
по m в любом
правиле
Ai Am, пока не
будет m i.
Затем, после
удаления
непосредственной
левой
рекурсии
для Ai-правил, m
становится
больше i.
Алгоритм 4.7
применим,
если
грамматика
не имеет
e-правил
(правил вида
A e). Имеющиеся в
грамматике
e-правила
могут быть
удалены
предварительно.
Получающаяся
грамматика
без левой
рекурсии
может иметь
e-правила.
4.3.6 Левая факторизация
Oсновная идея левой факторизации в том, что в том случае, когда неясно, какую из двух альтернатив надо использовать для развертки нетерминала A, нужно изменить A-правила так, чтобы отложить решение до тех пор, пока не будет достаточно информации для принятия правильного решения.
Если A 1 | 2 - два
A-правила
и входная
цепочка
начинается
с непустой
строки,
выводимой из
, мы не знаем,
разворачивать
ли по первому
правилу или
по второму.
Можно
отложить
решение,
развернув A A'.
Тогда после
анализа
того, что
выводимо
из , можно
развернуть
по A' 1 или по A' 2.
Левофакторизованные
правила
принимают
вид
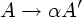
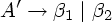
Алгоритм 4.8. Левая факторизация грамматики.
Вход. КС-грамматика G.
Выход. Левофакторизованная КС-грамматика G', эквивалентная G.
Метод. Для
каждого
нетерминала
A ищем самый
длинный
префикс ,
общий для
двух или
более его
альтернатив.
Если 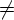 e, т.е.
существует
нетривиальный
общий
префикс,
заменяем
все A-правила
e, т.е.
существует
нетривиальный
общий
префикс,
заменяем
все A-правила
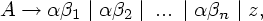 , на
, на
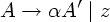
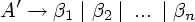
Пример 4.7. Рассмотрим вновь грамматику условных операторов из примера 4.6:
S if E then S | if E then S else S | a |
|
E b |
|
После левой факторизации грамматика принимает вид
S if E then SS'| a |
|
S' else S | e |
|
E b |
|
К сожалению, грамматика остается неоднозначной, а значит, и не LL(1).
4.3.7 Рекурсивный спуск
Выше был рассмотрен таблично-управляемый вариант предсказывающего анализа, когда магазин явно использовался в процессе работы анализатора. Можно предложить другой вариант предсказывающего анализа, в котором каждому нетерминалу сопоставляется процедура (вообще говоря, рекурсивная), и магазин образуется неявно при вызовах таких процедур. Процедуры рекурсивного спуска могут быть записаны, как показано ниже.
В процедуре
A для случая,
когда
имеется
правило A ui,
такое, что ui *e
(напомним,
что не может
быть больше
одного
правила, из
которого
выводится e),
приведены
два варианта
1.1 и 1.2. В варианте
1.1 делается
проверка,
принадлежит
ли следующий
входной
символ FOLLOW(A).
Если нет -
выдается
ошибка.
Во втором
варианте
этого не
делается,
так что
анализ
ошибки
откладывается
на процедуру,
вызвавшую
A.
void A(){ // A u1 | u2 | ...| uk
if (InSym FIRST(ui)) // только
одному!
if (parse(ui))
result("A ui");
else error();
else
//Вариант 1:
if (имеется
правило A ui
такое, что
ui *e)
//Вариант 1.1
if (InSym FOLLOW(A))
result("A ui");
else error();
//Конец варианта 1.1
//Вариант 1.2:
result("A ui");
//Конец варианта 1.2
//Конец варианта 1
//Вариант 2:
if (нет
правила
A ui такого,
что ui *e)
error();
//Конец варианта 2
}
boolean parse(u){ // из u не выводится e!
v = u;
while (v e){ // v = Xz
e){ // v = Xz
if (X - терминал a)
if (InSym a)
a)
return(false);
else InSym = getInsym();
else // X - нетерминал B
B();
v = z;
}
return(true);
}
4.3.8 Восстановление после синтаксических ошибок
В приведенных программах рекурсивного спуска использовалась процедура реакции на синтаксические ошибки error(). В простейшем случае эта процедура выдает диагностику и завершает работу анализатора. Но можно попытаться некоторым разумным образом продолжить работу. Для разбора сверху вниз можно предложить следующий простой алгоритм.
Если в момент обнаружения ошибки на верхушке магазина оказался нетерминальный символ A и для него нет правила, соответствующего входному символу, то сканируем вход до тех пор, пока не встретим символ либо из FIRST(A), либо из FOLLOW(A). В первом случае разворачиваем A по соответствующему правилу, во втором - удаляем A из магазина.
Если на верхушке магазина терминальный символ, то можно удалить все терминальные символы с верхушки магазина вплоть до первого (сверху) нетерминального символа и продолжать так, как это было описано выше.
4.4 Разбор снизу-вверх типа сдвиг-свертка
4.4.1 Основа
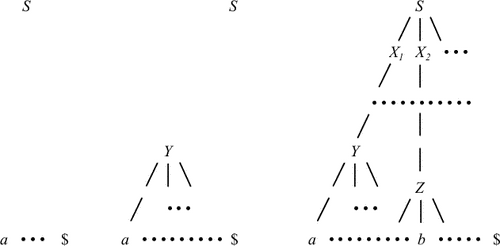
В процессе разбора снизу-вверх типа сдвиг-свертка строится дерево разбора входной цепочки, начиная с листьев (снизу) к корню (вверх). Этот процесс можно рассматривать как «свертку» цепочки w к начальному символу грамматики. На каждом шаге свертки подцепочка, которую можно сопоставить правой части некоторого правила вывода, заменяется символом левой части этого правила вывода, и если на каждом шаге выбирается правильная подцепочка, то в обратном порядке прослеживается правосторонний вывод (рис. 4.7). Здесь ко входной цепочке, так же как и при анализе LL(1)-грамматик, приписан концевой маркер $.
|
Подцепочка
сентенциальной
формы,
которая
может быть
сопоставлена
правой части
некоторого
правила
вывода,
свертка по
которому к
левой части
правила
соответствует
одному шагу
в обращении
правостороннего
вывода,
называется
основой
цепочки.
Самая левая
подцепочка,
которая
сопоставляется
правой части
некоторого
правила
вывода A  , не
обязательно
является
основой,
поскольку
свертка по
правилу A
может дать
цепочку,
которая не
может быть
сведена к
аксиоме.
, не
обязательно
является
основой,
поскольку
свертка по
правилу A
может дать
цепочку,
которая не
может быть
сведена к
аксиоме.
Формально,
основа
правой
сентенциальной
формы z - это
правило
вывода A и
позиция в z,
в которой
может быть
найдена
цепочка
такие, что в
результате
замены на A
получается
предыдущая
сентенциальная
форма в
правостороннем
выводе
z. Таким
образом,
если S r*A r, то A
в позиции,
следующей
за , это
основа
цепочки .
Подцепочка
справа
от основы
содержит
только
терминальные
символы.
Вообще
говоря,
грамматика
может быть
неоднозначной,
поэтому не
единственным
может быть
правосторонний
вывод и не
единственной
может быть
основа. Если
грамматика
однозначна,
то каждая
правая
сентенциальная
форма
грамматики
имеет в
точности
одну основу.
Замена
основы в
сентенциальной
форме на
нетерминал
левой части
называется
отсечением
основы.
Обращение
правостороннего
вывода
может быть
получено
с помощью
повторного
применения
отсечения
основы,
начиная с
исходной
цепочки
w. Если w -
слово в
рассматриваемой
грамматике,
то w = n, где n -
n-я правая
сентенциальная
форма еще
неизвестного
правого
вывода
S = 0 r1 r... rn-1 rn = w.
Чтобы
восстановить
этот вывод
в обратном
порядке,
выделяем
основу n в n и
заменяем n на
левую часть
некоторого
правила
вывода An n,
получая
(n - 1)-ю правую
сентенциальную
форму n-1. Затем
повторяем
этот процесс,
т.е. выделяем
основу n-1 в n-1 и
сворачиваем
эту основу,
получая
правую
сентенциальную
форму n-2. Если,
повторяя
этот процесс,
мы получаем
правую
сентенциальную
форму,
состоящую
только из
начального
символа S, то
останавливаемся
и сообщаем
об успешном
завершении
разбора.
Обращение
последовательности
правил,
использованных
в свертках,
есть правый
вывод
входной
строки.
Таким образом, главная задача анализатора типа сдвиг-свертка - это выделение и отсечение основы.
4.4.2 LR(1)-анализаторы
В названии LR(1) символ L указывает на то, что входная цепочка читается слева-направо, R - на то, что строится правый вывод, наконец, 1 указывает на то, что анализатор видит один символ непрочитанной части входной цепочки.
LR(1)-анализ привлекателен по нескольким причинам:
- LR(1)-анализ - наиболее мощный метод анализа без возвратов типа сдвиг-свертка;
- LR(1)-анализ может быть реализован довольно эффективно;
- LR(1)-анализаторы могут быть построены для практически всех конструкций языков программирования;
- класс грамматик, которые могут быть проанализированы LR(1)-методом, строго включает класс грамматик, которые могут быть проанализированы предсказывающими анализаторами (сверху-вниз типа LL(1)).
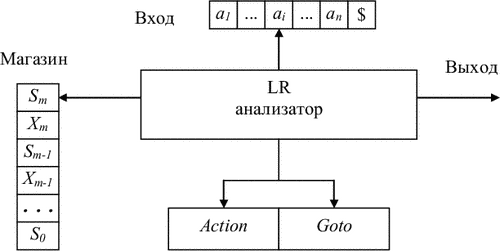
Схематически структура LR(1)-анализатора изображена на рис. 4.8. Анализатор состоит из входной ленты, выходной ленты, магазина, управляющей программы и таблицы анализа (LR(1)-таблицы), которая имеет две части - функцию действий (Action) и функцию переходов (Goto). Управляющая программа одна и та же для всех LR(1)-анализаторов, разные анализаторы отличаются только таблицами анализа.
Программа анализатора читает символы на входной ленте по одному за шаг. В процессе анализа используется магазин, в котором хранятся строки вида S0X1S1X2S2...XmSm (Sm - верхушка магазина). Каждый Xi - символ грамматики (терминальный или нетерминальный), а Si - символ состояния.
Заметим, что символы грамматики (либо символы состояний) не обязательно должны размещаться в магазине. Однако, их использование облегчает понимание поведения LR-анализатора.
|
Элемент
функции
действий Action[Sm, ai]
для символа
состояния
Sm и входа
ai T {$}, может
иметь одно
из четырех
значений:
- shift S (сдвиг), где S - символ состояния,
- reduce A (свертка
по правилу
грамматики
A ),
- accept (допуск),
- error (ошибка).
Элемент
функции
переходов Goto[Sm, A]
для символа
состояния
Sm и входа A N,
может иметь
одно из двух
значений:
- S, где S - символ состояния,
- error (ошибка).
Конфигурацией LR(1)-анализатора называется пара, первая компонента которой - содержимое магазина, а вторая - непросмотренный вход:
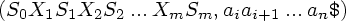
Эта конфигурация соответствует правой сентенциальной форме
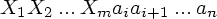
Префиксы правых сентенциальных форм, которые могут появиться в магазине анализатора, называются активными префиксами. Основа сентенциальной формы всегда располагается на верхушке магазина. Таким образом, активный префикс - это такой префикс правой сентенциальной формы, который не переходит правую границу основы этой формы.
В начале работы анализатора в магазине находится только символ начального состояния S0, на входной ленте - анализируемая цепочка с маркером конца.
Очередной шаг анализатора определяется текущим входным символом ai и символом состояния на верхушке магазина Sm следующим образом.
Пусть LR(1)-анализатор находится в конфигурации
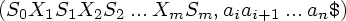
Анализатор может проделать один из следующих шагов:
- Если Action[Sm, ai] = shift S, то
анализатор
выполняет
сдвиг, переходя
в конфигурацию
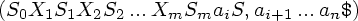
Таким образом, в магазин помещаются входной символ ai и символ состояния S, определяемый Action[Sm, ai]. Текущим входным символом становится ai+1.
- Если Action[Sm, ai] = reduce A ,
то анализатор
выполняет
свертку, переходя
в конфигурацию
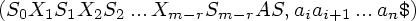 , правой
части правила
вывода.
, правой
части правила
вывода.
Анализатор сначала удаляет из магазина 2r символов (r символов состояния и r символов грамматики), так что на верхушке оказывается состояние Sm-r. Затем анализатор помещает в магазин A - левую часть правила вывода, и S - символ состояния, определяемый Goto[Sm-r, A]. На шаге свертки текущий входной символ не меняется. Для LR(1)-анализаторов Xm-r+1...Xm - последовательность символов грамматики, удаляемых из магазина, всегда соответствует
- правой части
правила вывода,
по которому
делается
свертка.
После осуществления шага свертки генерируется выход LR(1)-анализатора, т.е. исполняются семантические действия, связанные с правилом, по которому делается свертка, например, печатаются номера правил, по которым делается свертка.
Заметим, что функция Goto таблицы анализа, построенная по грамматике G, фактически представляет собой функцию переходов детерминированного конечного автомата, распознающего активные префиксы G.
- Если Action[Sm, ai] = accept, то разбор успешно завершен.
- Если Action[Sm, ai] = error, то анализатор обнаружил ошибку, и выполняются действия по диагностике и восстановлению.
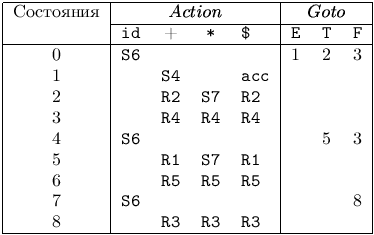
Пример 4.8. Рассмотрим грамматику арифметических выражений G = ({E, T, F}, {id, +, *}, P, E) с правилами:
(1) E E + T |
|
(2) E T |
|
(3) T T * F |
|
(4) T F |
|
(5) F id |
|
На рис. 4.9 изображены функции Action и Goto, образующие LR(1)-таблицу для этой грамматики. Для Элемент Si функции Action означает сдвиг и помещение в магазин состояния с номером i, Rj - свертку по правилу номер j, acc - допуск, пустая клетка - ошибку. Для функции Goto символ i означает помещение в магазин состояния с номером i, пустая клетка - ошибку.
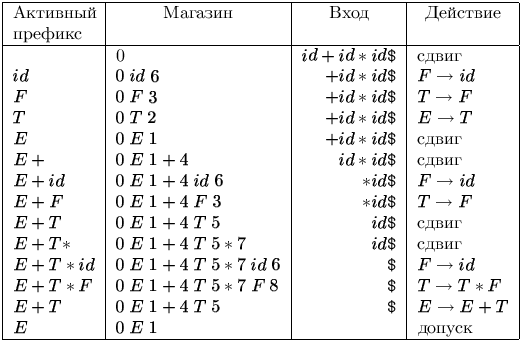
На входе id + id * id последовательность состояний магазина и входной ленты показаны на рис. 4.10. Например, в первой строке LR-анализатор находится в нулевом состоянии и «видит» первый входной символ id. Действие S6 в нулевой строке и столбце id в поле Action (рис. 4.9) означает сдвиг и помещение символа состояния 6 на верхушку магазина. Это и изображено во второй строке: первый символ id и символ состояния 6 помещаются в магазин, а id удаляется со входной ленты.
|
|
Текущим
входным
символом
становится +,
и действием
в состоянии
6 на вход +
является
свертка по F id.
Из магазина
удаляются
два символа
(один символ
состояния и
один символ
грамматики).
Затем
анализируется
нулевое
состояние.
Поскольку
Goto в нулевом
состоянии
по символу
F - это 3, F и 3
помещаются
в магазин.
Теперь имеем
конфигурацию,
соответствующую
третьей
строке.
Остальные шаги
определяются
аналогично.
4.4.3 Конструирование LR(1)-таблицы
Рассмотрим теперь алгоритм конструирования таблицы, управляющей LR(1)-анализатором.
Пусть G = (N, T, P, S) - КС-грамматика. Пополненной грамматикой для данной грамматики G называется КС-грамматика
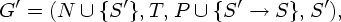 S.
S.
Это
дополнительное
правило
вводится для
того, чтобы
определить,
когда
анализатор
должен
остановить
разбор и
зафиксировать
допуск
входа. Таким
образом,
допуск
имеет место
тогда и
только
тогда, когда
анализатор
готов
осуществить
свертку по
правилу S' S.
LR(1)-ситуацией
называется
пара [A ., a], где
A - правило
грамматики,
a - терминал
или правый
концевой
маркер
$. Вторая
компонента
ситуации
называется
аванцепочкой.
Будем
говорить, что
LR(1)-ситуация [A ., a]
допустима для
активного
префикса
 , если
существует
вывод S r*Aw rw,
где = и либо
a - первый
символ w,
либо w = e и a = $.
, если
существует
вывод S r*Aw rw,
где = и либо
a - первый
символ w,
либо w = e и a = $.
Будем говорить, что ситуация допустима, если она допустима для какого-либо активного префикса.
Пример 4.9. Рассмотрим грамматику G = ({S, B}, {a, b}, P, S) с правилами
S BB |
|
B aB | b |
|
Существует
правосторонний
вывод S r*aaBab
raaaBab.
Легко видеть,
что ситуация
[B a.B, a] допустима
для активного
префикса
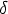 = aaa, если в
определении
выше положить
= aaa, если в
определении
выше положить
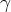 = aa, A = B, w = ab,
= aa, A = B, w = ab,  = a,
= a, 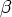 = B.
Существует
также
правосторонний
вывод S r*BaB
rBaaB.
Поэтому для
активного
префикса Baa
допустима
ситуация
[B a.B, $].
= B.
Существует
также
правосторонний
вывод S r*BaB
rBaaB.
Поэтому для
активного
префикса Baa
допустима
ситуация
[B a.B, $].
Центральная идея метода заключается в том, что по грамматике строится детерминированный конечный автомат, распознающий активные префиксы. Для этого ситуации группируются во множества, которые и образуют состояния автомата. Ситуации можно рассматривать как состояния недетерминированного конечного автомата, распознающего активные префиксы, а их группировка на самом деле есть процесс построения детерминированного конечного автомата из недетерминированного.
Анализатор, работающий слева-направо по типу сдвиг-свертка, должен уметь распознавать основы на верхушке магазина. Состояние автомата после прочтения содержимого магазина и текущий входной символ определяют очередное действие автомата. Функцией переходов этого конечного автомата является функция переходов LR-анализатора. Чтобы не просматривать магазин на каждом шаге анализа, на верхушке магазина всегда хранится то состояние, в котором должен оказаться этот конечный автомат после того, как он прочитал символы грамматики в магазине от дна к верхушке.
Рассмотрим
ситуацию
вида [A .B, a] из
множества
ситуаций,
допустимых
для
некоторого
активного
префикса
z. Тогда
существует
правосторонний
вывод
S r*yAax ryBax, где z = y.
Предположим,
что из ax
выводится
терминальная
строка bw.
Тогда для
некоторого
правила
вывода вида
B q имеется
вывод
S r*zBbw rzqbw. Таким
образом
[B .q, b] также
допустима
для z и
ситуация [A B., a]
допустима
для активного
префикса zB.
Здесь либо b
может быть
первым
терминалом,
выводимым
из , либо из
выводится
e в выводе
ax r*bw и тогда b
равно a. Т.е. b
принадлежит
FIRST(ax). Построение
всех таких
ситуаций
для данного
множества
ситуаций,
т.е. его
замыкание,
делает
приведенная
ниже функция
closure.
Система множеств допустимых LR(1)-ситуаций для всевозможных активных префиксов пополненной грамматики называется канонической системой множеств допустимых LR(1)-ситуаций. Алгоритм построения канонической системы множеств приведен ниже.
Алгоритм 4.9. Конструирование канонической системы множеств допустимых LR(1)-ситуаций.
Вход. КС-грамматика G = (N, T, P, S).
Выход. Каноническая система C множеств допустимых LR(1)-ситуаций для грамматики G.
Метод. Заключается в выполнении для пополненной грамматики G' процедуры items, которая использует функции closure и goto.
function closure(I){ /* I - множество ситуаций */
do{
for (каждой
ситуации
[A .B, a] из I,
каждого
правила
вывода B
из G',
каждого
терминала
b из FIRST(a),
такого,
что [B ., b] нет
в I)
добавить
[B ., b] к I;
}
while (к I можно добавить новую ситуацию);
return I;
}
function goto(I,X){ /* I - множество ситуаций;
X - символ грамматики */
Пусть
J = {[A X., a] | [A .X, a] I};
return closure(J);
}
procedure items(G'){ /* G' - пополненная грамматика */
I0 = closure({[S' .S, $]});
C = {I0};
do{
for (каждого множества ситуаций I из системы C,
каждого символа грамматики X такого,
что goto(I, X) не пусто и не принадлежит C)
добавить goto(I, X) к системе C;
}
while (к C можно добавить новое множество ситуаций);
Если I -
множество
ситуаций,
допустимых
для
некоторого
активного
префикса
, то goto(I, X) -
множество
ситуаций,
допустимых
для
активного
префикса
X.
Работа
алгоритма
построения
системы C
множеств
допустимых
LR(1)-ситуаций
начинается
с того, что в C
помещается
начальное
множество
ситуаций
I0 = closure({[S' .S, $]}). Затем
с помощью
функции goto
вычисляются
новые
множества
ситуаций и
включаются
в C. По-существу,
goto(I, X) - переход
конечного
автомата из
состояния I
по символу
X.
Рассмотрим теперь, как по системе множеств LR(1)-ситуаций строится LR(1)-таблица, т.е. функции действий и переходов LR(1)-анализатора.
Алгоритм 4.10. Построение LR(1)-таблицы.
Вход. Каноническая система C = {I0, I1, ..., In} множеств допустимых LR(1)-ситуаций для грамматики G.
Выход. Функции Action и Goto, составляющие LR(1)-таблицу для грамматики G.
Метод. Для каждого состояния i функции Action[i, a] и Goto[i, X] строятся по множеству ситуаций Ii:
- Значения
функции
действия
(Action) для состояния
i определяются
следующим
образом:
- если [A .a, b] Ii (a
- терминал)
и goto(Ii, a) = Ij, то полагаем
Action[i, a] = shift j;
- если [A ., a] Ii, причем
A
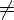 S', то полагаем
Action[i, a] = reduce A ;
S', то полагаем
Action[i, a] = reduce A ;
- если [S' S., $] Ii, то
полагаем
Action[i, $] = accept.
- если [A
- Значения функции переходов для состояния i определяются следующим образом: если goto(Ii, A) = Ij, то Goto[i, A] = j (здесь A - нетерминал).
- Все входы в Action и Goto, не определенные шагами 2 и 3, полагаем равными error.
- Начальное
состояние
анализатора
строится из
множества,
содержащего
ситуацию
[S' .S, $].
Таблица на основе функций Action и Goto, полученных в результате работы алгоритма 4.10, называется канонической LR(1)-таблицей. LR(1)-анализатор, работающий с этой таблицей, называется каноническим LR(1)-анализатором.
Пример 4.10. Рассмотрим следующую грамматику, являющуюся пополненной для грамматики из примера 4.8:
(0) E' E |
|
(1) E E + T |
|
(2) E T |
|
(3) T T * F |
|
(4) T F |
|
(5) F id |
|
Множества ситуаций и переходы по goto для этой грамматики приведены на рис. 4.11. LR(1)-таблица для этой грамматики приведена на рис. 4.9.
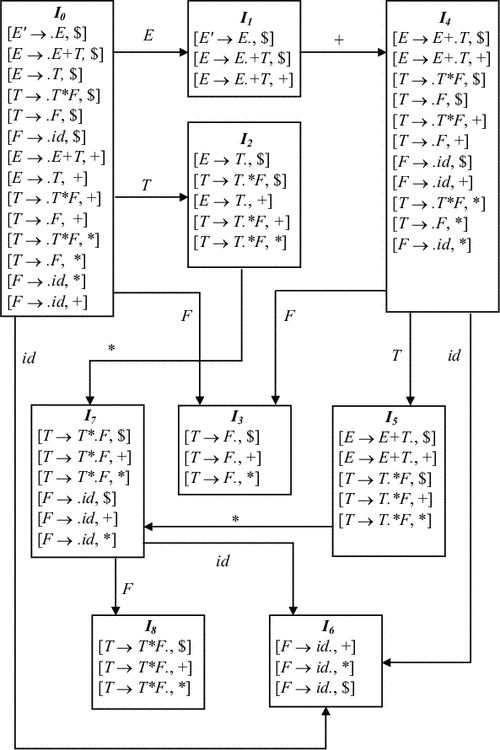
|
4.4.4 LR(1)-грамматики
Если для КС-грамматики G функция Action, полученная в результате работы алгоритма 4.10, не содержит неоднозначно определенных входов, то грамматика называется LR(1)-грамматикой.
Язык L называется LR(1)-языком, если он может быть порожден некоторой LR(1)-грамматикой.
Иногда используется другое определение LR(1)-грамматики. Грамматика называется LR(1), если из условий
1. S'r*uAw ruvw,
2. S'r*zBx ruvy,
3. FIRST(w) = FIRST(y)
следует, что uAy = zBx (т.е. u = z, A = B и x = y).
Согласно
этому
определению,
если uvw и uvy -
правовыводимые
цепочки
пополненной
грамматики,
у которых
FIRST(w) = FIRST(y) и A v -
последнее
правило,
использованное
в правом
выводе
цепочки uvw,
то правило
A v должно
применяться
и в правом
разборе
при свертке
uvy к uAy. Так
как A дает v
независимо
от w, то
LR(1)-условие
означает,
что в FIRST(w)
содержится
информация,
достаточная
для
определения
того, что uv
за один шаг
выводится
из uA. Поэтому
никогда
не может
возникнуть
сомнений
относительно
того, как
свернуть
очередную
правовыводимую
цепочку
пополненной
грамматики.
Можно доказать, что эти два определения эквивалентны.
Если грамматика не является LR(1), то анализатор типа сдвиг-свертка при анализе некоторой цепочки может достигнуть конфигурации, в которой он, зная содержимое магазина и следующий входной символ, не может решить, делать ли сдвиг или свертку (конфликт сдвиг/свертка), или не может решить, какую из нескольких сверток применить (конфликт свертка/свертка).
В частности, неоднозначная грамматика не может быть LR(1). Для доказательства рассмотрим два различных правых вывода
(1) S ru1 r... run rw, и
(2) S rv1 r... rvm rw.
Нетрудно
заметить,
что LR(1)-условие
(согласно
второму
определению
LR(1)-грамматики)
нарушается
для
наименьшего
из чисел i,
для которых
un-i vm-i.
vm-i.
Пример 4.11. Рассмотрим вновь грамматику условных операторов:
S if E then S | if E then S else S | a |
|
E b |
|
Если
анализатор
типа
сдвиг-свертка
находится в
конфигурации,
такой что
необработанная
часть
входной
цепочки
имеет вид else...$, а
в магазине
находится
...if E then S, то нельзя
определить,
является ли if E then S
основой, вне
зависимости
от того,
что лежит
в магазине
ниже. Это
конфликт
сдвиг/свертка.
В зависимости
от того, что
следует на
входе за else,
правильной
может быть
свертка по
S if E then S или сдвиг
else, а затем
разбор
другого S и
завершение
основы
if E then S else S. Таким
образом
нельзя
сказать,
нужно ли в
этом случае
делать
сдвиг или
свертку,
так что
грамматика
не является
LR(1).
Эта грамматика может быть преобразована к LR(1)-виду следующим образом:
S M | U |
|
M if E then M else M | a |
|
U if E then S | if E then M else U |
|
E b |
|
Справедливы также следующие утверждения [2].
Теорема 4.5. Каждый LR(1)-язык является детерминированным КС-языком.
Теорема 4.6. Если L - детерминированный КС-язык, то существует LR(1)-грамматика, порождающая L.
4.4.5 Восстановление после синтаксических ошибок
Одним из простейших методов восстановления после ошибки при LR(1)-анализе является следующий. При синтаксической ошибке просматриваем магазин от верхушки, пока не найдем состояние s с переходом на выделенный нетерминал A. Затем сканируются входные символы, пока не будет найден такой, который допустим после A. В этом случае на верхушку магазина помещается состояние Goto[s, A] и разбор продолжается. Для нетерминала A может иметься несколько таких вариантов. Обычно A - это нетерминал, представляющий одну из основных конструкций языка, например оператор.
При более детальной проработке реакции на ошибки можно в каждой пустой клетке анализатора поставить обращение к своей подпрограмме. Такая подпрограмма может вставлять или удалять входные символы или символы магазина, менять порядок входных символов.
4.4.6 Варианты LR-анализаторов
Часто построенные таблицы для LR(1)-анализатора оказываются довольно большими. Поэтому при практической реализации используются различные методы их сжатия. С другой стороны, часто оказывается, что при построении для языка синтаксического анализатора типа «сдвиг-свертка» достаточно более простых методов. Некоторые из этих методов базируются на основе LR(1)-анализаторов.
Одним из способов такого упрощения является LR(0)-анализ - частный случая LR-анализа, когда ни при построении таблиц, ни при анализе не учитывается аванцепочка.
Еще одним вариантом LR-анализа являются так называемые SLR(1)-анализаторы (Simple LR(1)). Они строятся следующим образом. Пусть C = {I0, I1, ..., In} - набор множеств допустимых LR(0)-ситуаций. Состояния анализатора соответствуют Ii. Функции действий и переходов анализатора определяются следующим образом.
- Если [A u.av] Ii и
goto(Ii, a) = Ij, то определим
Action[i, a] = shift j.
- Если [A u.] Ii, то
определим
Action[i, a] = reduce A u для всех
a FOLLOW(A), A
 S'.
S'.
- Если [S' S.] Ii, то
определим
Action[i, $] = accept.
- Если goto(Ii, A) = Ij, где
A N, то определим
Goto[i, A] = j.
- Остальные входы для функций Action и Goto определим как error.
- Начальное
состояние
соответствует
множеству
ситуаций,
содержащему
ситуацию
[S' .S].
Распространенным
вариантом
LR(1)-анализа
является
также
LALR(1)-анализ. Он
основан на
объединении
(слиянии)
некоторых
таблиц.
Назовем
ядром
множества
LR(1)-ситуаций
множество
их первых
компонент
(т.е. во
множестве
ситуаций не
учитываются
аванцепочки).
Объединим
все
множества
ситуаций с
одинаковыми
ядрами, а в
качестве
аванцепочек
возьмем
объединение
аванцепочек.
Функции Action и
Goto строятся
очевидным
образом.
Если
функция
Action таким
образом
построенного
анализатора
не имеет
конфликтов,
то он
называется
LALR(1)-анализатором
(LookAhead LR(1)).