3. Лексический анализ
Основная задача лексического анализа - разбить входной текст, состоящий из последовательности одиночных символов, на последовательность слов, или лексем, т.е. выделить эти слова из непрерывной последовательности символов. Все символы входной последовательности с этой точки зрения разделяются на символы, принадлежащие каким-либо лексемам, и символы, разделяющие лексемы (разделители). В некоторых случаях между лексемами может и не быть разделителей. С другой стороны, в некоторых языках лексемы могут содержать незначащие символы (например, символ пробела в Фортране). В Си разделительное значение символов-разделителей может блокироваться («\» в конце строки внутри "...").
Обычно все лексемы делятся на классы. Примерами таких классов являются числа (целые, восьмеричные, шестнадцатиричные, действительные и т.д.), идентификаторы, строки. Отдельно выделяются ключевые слова и символы пунктуации (иногда их называют символы-ограничители). Как правило, ключевые слова - это некоторое конечное подмножество идентификаторов. В некоторых языках (например, ПЛ/1) смысл лексемы может зависеть от ее контекста и невозможно провести лексический анализ в отрыве от синтаксического.
С точки зрения дальнейших фаз анализа лексический анализатор выдает информацию двух сортов: для синтаксического анализатора, работающего вслед за лексическим, существенна информация о последовательности классов лексем, ограничителей и ключевых слов, а для контекстного анализа, работающего вслед за синтаксическим, важна информация о конкретных значениях отдельных лексем (идентификаторов, чисел и т.д.).
Таким образом, общая схема работы лексического анализатора такова. Сначала выделяется отдельная лексема (возможно, используя символы-разделители). Ключевые слова распознаются либо явным выделением непосредственно из текста, либо сначала выделяется идентификатор, а затем делается проверка на принадлежность его множеству ключевых слов.
Если выделенная лексема является ограничителем, то он (точнее, некоторый его признак) выдается как результат лексического анализа. Если выделенная лексема является ключевым словом, то выдается признак соответствующего ключевого слова. Если выделенная лексема является идентификатором - выдается признак идентификатора, а сам идентификатор сохраняется отдельно. Наконец, если выделенная лексема принадлежит какому-либо из других классов лексем (например, лексема представляет собой число, строку и т.д.), то выдается признак соответствующего класса, а значение лексемы сохраняется отдельно.
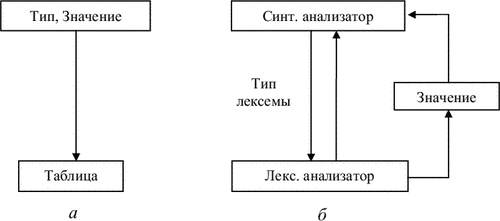
Лексический анализатор может быть как самостоятельной фазой трансляции, так и подпрограммой, работающей по принципу «дай лексему». В первом случае (рис. 3.1, а) выходом анализатора является файл лексем, во втором (рис. 3.1, б) лексема выдается при каждом обращении к анализатору (при этом, как правило, признак класса лексемы возвращается как результат функции «лексический анализатор», а значение лексемы передается через глобальную переменную). С точки зрения обработки значений лексем, анализатор может либо просто выдавать значение каждой лексемы, и в этом случае построение таблиц объектов (идентификаторов, строк, чисел и т.д.) переносится на более поздние фазы, либо он может самостоятельно строить таблицы объектов. В этом случае в качестве значения лексемы выдается указатель на вход в соответствующую таблицу.
|
Работа лексического анализатора задается некоторым конечным автоматом. Однако, непосредственное описание конечного автомата неудобно с практической точки зрения. Поэтому для задания лексического анализатора, как правило, используется либо регулярное выражение, либо праволинейная грамматика. Все три формализма (конечных автоматов, регулярных выражений и праволинейных грамматик) имеют одинаковую выразительную мощность. В частности, по регулярному выражению или праволинейной грамматике можно сконструировать конечный автомат, распознающий тот же язык.
3.1 Регулярные множества и выражения
Введем понятие регулярного множества, играющего важную роль в теории формальных языков.
Регулярное множество в алфавите T определяется рекурсивно следующим образом:
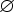 (пустое множество)
- регулярное
множество
в алфавите
T;
(пустое множество)
- регулярное
множество
в алфавите
T;
- {e} - регулярное множество в алфавите T (e - пустая цепочка);
- {a} - регулярное
множество
в алфавите
T для каждого
a
 T;
T;
- если P и Q - регулярные
множества
в алфавите
T, то регулярными
являются
и множества
- P
 Q (объединение),
Q (объединение),
- PQ (конкатенация,
т.е. множество
{pq|p P, q Q}),
- P* (итерация:
P* =
 n=0
n=0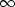 Pn);
Pn);
- P
- ничто другое не является регулярным множеством в алфавите T.
Итак,
множество
в алфавите
T регулярно
тогда и
только тогда,
когда оно
либо , либо
{e}, либо {a} для
некоторого
a T, либо его
можно
получить
из этих
множеств
применением
конечного
числа
операций
объединения,
конкатенации
и итерации.
Приведенное выше определение регулярного множества позволяет ввести следующую удобную форму его записи, называемую регулярным выражением.
Регулярное выражение в алфавите T и обозначаемое им регулярное множество в алфавите T определяются рекурсивно следующим образом:
- - регулярное
выражение,
обозначающее
множество ;
- e - регулярное выражение, обозначающее множество {e};
- a - регулярное выражение, обозначающее множество {a};
- если p и q - регулярные
выражения,
обозначающие
регулярные
множества
P и Q соответственно,
то
- (p|q) - регулярное
выражение,
обозначающее
регулярное
множество
P Q,
- (pq) - регулярное выражение, обозначающее регулярное множество PQ,
- (p*) - регулярное выражение, обозначающее регулярное множество P*;
- (p|q) - регулярное
выражение,
обозначающее
регулярное
множество
P
- ничто другое не является регулярным выражением в алфавите T.
Мы будем опускать лишние скобки в регулярных выражениях, договорившись о том, что операция итерации имеет наивысший приоритет, затем идет операции конкатенации, наконец, операция объединения имеет наименьший приоритет.
Кроме того, мы будем пользоваться записью p+ для обозначения pp*. Таким образом, запись (a|((ba)(a*))) эквивалентна a|ba+.
Наконец, мы будем использовать запись L(r) для регулярного множества, обозначаемого регулярным выражением r.
Пример 3.1. Несколько примеров регулярных выражений и обозначаемых ими регулярных множеств:
- a(e|a)|b - обозначает множество {a, b, aa};
- a(a|b)* - обозначает множество всевозможных цепочек, состоящих из a и b, начинающихся с a;
- (a|b)*(a|b)(a|b)* - обозначает множество всех непустых цепочек, состоящих из a и b, т.е. множество {a, b}+;
- ((0|1)(0|1)(0|1))* - обозначает множество всех цепочек, состоящих из нулей и единиц, длины которых делятся на 3.
Ясно, что для каждого регулярного множества можно найти регулярное выражение, обозначающее это множество, и наоборот. Более того, для каждого регулярного множества существует бесконечно много обозначающих его регулярных выражений.
Будем говорить, что регулярные выражения равны или эквивалентны (=), если они обозначают одно и то же регулярное множество.
Существует ряд алгебраических законов, позволяющих осуществлять эквивалентное преобразование регулярных выражений.
Лемма. Пусть p, q и r - регулярные выражения. Тогда справедливы следующие соотношения:
(1) | p|q = q|p; | (7) | pe = ep = p; |
|||
(2) | * = e; | (8) | p = p = ; |
|||
(3) | p|(q|r) = (p|q)|r; | (9) | p* = p|p*; |
|||
(4) | p(qr) = (pq)r; | (10) | (p*)* = p*; |
|||
(5) | p(q|r) = pq|pr; | (11) | p|p = p; |
|||
(6) | (p|q)r = pr|qr; | (12) | p| = p. |
|||
Следствие. Для любого
регулярного
выражения
существует
эквивалентное
регулярное
выражение,
которое
либо есть
, либо не
содержит
в своей
записи .
В дальнейшем
будем
рассматривать
только
регулярные
выражения, не
содержащие
в своей
записи .
При практическом описании лексических структур бывает полезно сопоставлять регулярным выражениям некоторые имена, и ссылаться на них по этим именам. Для определения таких имен мы будем использовать запись вида
d1 = r1 |
|
d2 = r2 |
|
... |
|
dn = rn |
|
где di -
различные
имена, а
каждое ri -
регулярное
выражение над
символами T{d1, d2, ..., di-1},
т.е. символами
основного
алфавита
и ранее
определенными
символами
(именами).
Таким
образом,
для любого
ri можно
построить
регулярное
выражение
над T, повторно
заменяя
имена
регулярных
выражений на
обозначаемые
ими
регулярные
выражения.
Пример 3.2. Использование имен для регулярных выражений.
- Регулярное
выражение
для множества
идентификаторов.
Letter = a|b|c|...|x|y|zDigit = 0|1|...|9Identifier = Letter(Letter|Digit)*
- Регулярное
выражение
для множества
чисел в десятичной
записи.
Digit = 0|1|...|9Integer = Digit+Fraction = .Integer|eExponent = (E(+|-|e)Integer)|eNumber = Integer Fraction Exponent
3.2 Конечные автоматы
Регулярные выражения, введенные ранее, служат для описания регулярных множеств. Для распознавания регулярных множеств служат конечные автоматы.
Недетерминированный конечный автомат (НКА) - это пятерка M = (Q, T, D, q0, F), где
- Q - конечное множество состояний;
- T - конечное множество допустимых входных символов (входной алфавит);
- D - функция
переходов
(отображающая
множество
QЧ(T{e}) во множество
подмножеств
множества
Q), определяющая
поведение
управляющего
устройства;
- q0 Q - начальное
состояние
управляющего
устройства;
- F
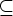 Q - множество
заключительных
состояний.
Q - множество
заключительных
состояний.
Работа конечного автомата представляет собой некоторую последовательность шагов, или тактов. Такт определяется текущим состоянием управляющего устройства и входным символом, обозреваемым в данный момент входной головкой. Сам шаг состоит из изменения состояния и, возможно, сдвига входной головки на одну ячейку вправо (рис. 3.2).
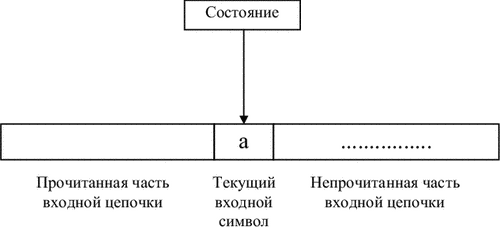
|
Недетерминизм автомата заключается в том, что, во-первых, находясь в некотором состоянии и обозревая текущий символ, автомат может перейти в одно из, вообще говоря, нескольких возможных состояний, и во-вторых, автомат может делать переходы по e.
Пусть
M = (Q, T, D, q0, F) - НКА.
Конфигурацией
автомата M
называется
пара (q, w) QЧT*, где q
- текущее
состояние
управляющего
устройства,
а w - цепочка
символов
на входной
ленте,
состоящая
из символа
под головкой
и всех
символов
справа
от него.
Конфигурация
(q0, w) называется
начальной, а
конфигурация
(q, e), где q F -
заключительной
(или
допускающей).
Пусть M = (Q, T, D, q0, F) -
НКА. Тактом
автомата M
называется
бинарное
отношение 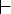 ,
определенное
на конфигурациях
M следующим
образом:
если p D(q, a), где
a T {e}, то (q, aw) (p, w) для
всех w T*.
,
определенное
на конфигурациях
M следующим
образом:
если p D(q, a), где
a T {e}, то (q, aw) (p, w) для
всех w T*.
Будем
обозначать
символом + (*)
транзитивное
(рефлексивно-
транзитивное)
замыкание
отношения
.
Говорят,
что автомат
M допускает
цепочку w,
если (q0, w) *(q, e) для
некоторого
q F. Языком,
допускаемым
(распознаваемым,
определяемым)
автоматом M,
(обозначается
L(M)), называется
множество
входных
цепочек,
допускаемых
автоматом M.
Т.е.
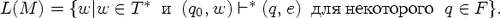
Важным частным случаем недетерминированного конечного автомата является детерминированный конечный автомат, который на каждом такте работы имеет возможность перейти не более чем в одно состояние и не может делать переходы по e.
Пусть M = (Q, T, D, q0, F) - НКА. Будем называть M детерминированным конечным автоматом (ДКА), если выполнены следующие два условия:
- D(q, e) = для
любого q Q,
и
- D(q, a) содержит
не более одного
элемента
для любых
q Q и a T.
Так как функция переходов ДКА содержит не более одного элемента для любой пары аргументов, для ДКА мы будем пользоваться записью D(q, a) = p вместо D(q, a) = {p}.
Конечный
автомат
может быть
изображен
графически
в виде
диаграммы,
представляющей
собой
ориентированный
граф, в
котором
каждому
состоянию
соответствует
вершина,
а дуга,
помеченная
символом a T {e},
соединяет
две вершины
p и q, если p D(q, a). На
диаграмме
выделяются
начальное и
заключительные
состояния
(в примерах
ниже,
соответственно,
входящей
стрелкой
и двойным
контуром).
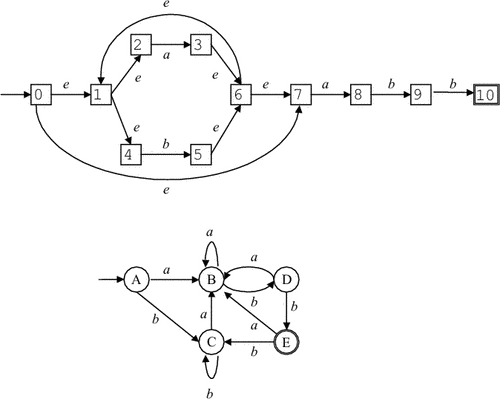
Пример 3.3. Пусть L = L(r), где r = (a|b)*a(a|b)(a|b).
- Недетерминированный
конечный автомат
M, допускающий
язык L:
M = {{1, 2, 3, 4}, {a, b}, D, 1, {4}},
где функция переходов D определяется так:
D(1, a) = {1, 2},D(3, a) = {4},D(2, a) = {3},D(3, b) = {4},D(2, b) = {3}.Диаграмма автомата приведена на рис. 3.3, а.
- Детерминированный
конечный автомат
M, допускающий
язык L:
M = {{1, 2, 3, 4, 5, 6, 7, 8}, {a, b}, D, 1, {3, 5, 6, 8}},
где функция переходов D определяется так:
D(1, a) = 2,D(5, a) = 8,D(1, b) = 1,D(5, b) = 6,D(2, a) = 4,D(6, a) = 2,D(2, b) = 7,D(6, b) = 1,D(3, a) = 3,D(7, a) = 8,D(3, b) = 5,D(7, b) = 6,D(4, a) = 3,D(8, a) = 4,D(4, b) = 5,D(8, b) = 7.Диаграмма автомата приведена на рис. 3.3, б.
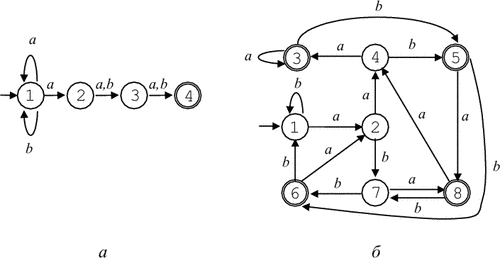
|
Пример 3.4. Диаграмма ДКА, допускающего множество чисел в десятичной записи, приведена на рис. 3.4.
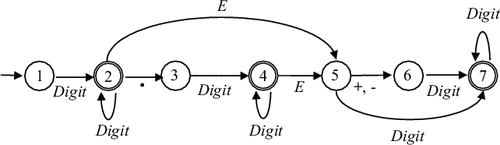
|
Пример 3.5. Анализ цепочек.
- При анализе
цепочки w = ababa
автомат из
примера 3.3, а,
может сделать
следующую
последовательность
тактов:
(1, ababa)
 (1, baba) (1, aba) (2, ba) (3, a) (4, e).
(1, baba) (1, aba) (2, ba) (3, a) (4, e).
Состояние 4 является заключительным, следовательно, цепочка w допускается этим автоматом.
- При анализе
цепочки w = ababab
автомат из
примера 3.3, б,
должен сделать
следующую
последовательность
тактов:
(1, ababab)
(2, babab) (7, abab) (8, bab) (7, ab) (8, b) (7, e).
Так как состояние 7 не является заключительным, цепочка w не допускается этим автоматом.
3.3 Алгоритмы построения конечных автоматов
3.3.1 Построение недетерминированного конечного автомата по регулярному выражению
Рассмотрим алгоритм построения по регулярному выражению недетерминированного конечного автомата, допускающего тот же язык.
Алгоритм 3.1. Построение недетерминированного конечного автомата по регулярному выражению.
Вход. Регулярное выражение r в алфавите T.
Выход. НКА M, такой что L(M) = L(r).
Метод. Автомат для выражения строится композицией из автоматов, соответствующих подвыражениям. На каждом шаге построения строящийся автомат имеет в точности одно заключительное состояние, в начальное состояние нет переходов из других состояний и нет переходов из заключительного состояния в другие.
- Для выражения
e строится
автомат
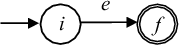
Рис. 3.5: 
Рис. 3.6: - Для выражения
s|t автомат
M(s|t) строится
как показано
на рис. 3.7. Здесь
i - новое начальное
состояние
и f - новое
заключительное
состояние.
Заметим,
что имеет
место переход
по e из i в начальные
состояния
M(s) и M(t) и переход
по e из заключительных
состояний
M(s) и M(t) в f. Начальное
и заключительное
состояния
автоматов
M(s) и M(t) не являются
таковыми
для автомата
M(s|t).
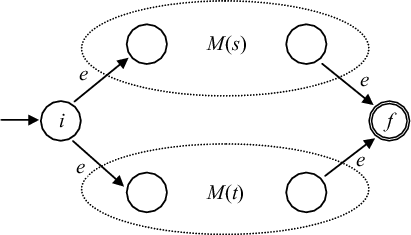
Рис. 3.7: 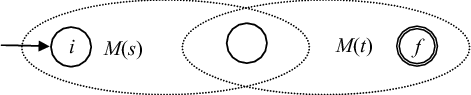
Рис. 3.8: Начальное состояние M(s) становится начальным для нового автомата, а заключительное состояние M(t) становится заключительным для нового автомата. Начальное состояние M(t) и заключительное состояние M(s) сливаются, т.е. все переходы из начального состояния M(t) становятся переходами из заключительного состояния M(s). В новом автомате это объединенное состояние не является ни начальным, ни заключительным.
- Для
выражения
s* автомат M(s*)
строится
следующим
образом:
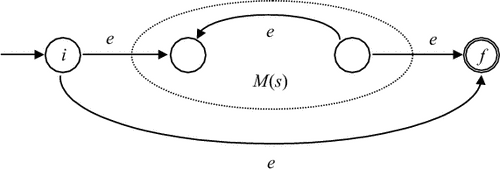
Рис. 3.9: Здесь i - новое начальное состояние, а f - новое заключительное состояние.
- Для выражения
s|t автомат
M(s|t) строится
как показано
на рис. 3.7. Здесь
i - новое начальное
состояние
и f - новое
заключительное
состояние.
Заметим,
что имеет
место переход
по e из i в начальные
состояния
M(s) и M(t) и переход
по e из заключительных
состояний
M(s) и M(t) в f. Начальное
и заключительное
состояния
автоматов
M(s) и M(t) не являются
таковыми
для автомата
M(s|t).
3.3.2 Построение детерминированного конечного автомата по недетерминированному
Рассмотрим алгоритм построения по недетерминированному конечному автомату детерминированного конечного автомата, допускающего тот же язык.
Алгоритм 3.2. Построение детерминированного конечного автомата по недетерминированному.
Вход. НКА M = (Q, T, D, q0, F).
Выход. ДКА M' = (Q', T, D', q0', F'), такой что L(M) = L(M').
Метод. Каждое состояние результирующего ДКА - это некоторое множество состояний исходного НКА.
В алгоритме будут использоваться следующие функции:
e-closure(R) (R Q) -
множество
состояний
НКА,
достижимых
из состояний,
входящих в R,
посредством
только
переходов
по e, т.е.
множество
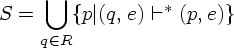
move(R, a) (R Q) -
множество
состояний
НКА, в которые
есть переход
на входе a для
состояний
из R, т.е.
множество
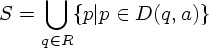
Вначале Q' и D' пусты. Выполнить шаги 1-4:
- Определить q0' = e-closure({q0}).
- Добавить q0' в Q' как непомеченное состояние.
- Выполнить
следующую
процедуру:
while (в Q' есть непомеченное состояние R){
пометить R;
for (каждого входного символа a
T){
S = e-closure(move(R, a));
if (S
 ){
){
if (S
 Q')
Q')
добавить S в Q' как непомеченное состояние;
определить D'(R, a) = S;
}
}
}
- Определить
F' = {S|S Q', S
 F
F }.
}.
Пример 3.6. Результат применения алгоритма 3.2 приведен на рис. 3.10.
|
3.3.3 Построение детерминированного конечного автомата по регулярному выражению
Приведем теперь алгоритм построения по регулярному выражению детерминированного конечного автомата, допускающего тот же язык [10].
Пусть дано регулярное выражение r в алфавите T. К регулярному выражению r добавим маркер конца: (r)#. Такое регулярное выражение будем называть пополненным. В процессе своей работы алгоритм будет использовать пополненное регулярное выражение.
Алгоритм
будет
оперировать с
синтаксическим
деревом для
пополненного
регулярного
выражения (r)# ,
каждый лист
которого
помечен
символом
a T {e, #}, а каждая
внутренняя
вершина
помечена
знаком
одной из
операций: .
(конкатенация),
| (объединение),
* (итерация).
Каждому листу дерева (кроме e-листьев) припишем уникальный номер, называемый позицией, и будем использовать его, с одной стороны, для ссылки на лист в дереве, и, с другой стороны, для ссылки на символ, соответствующий этому листу. Заметим, что если некоторый символ используется в регулярном выражении несколько раз, он имеет несколько позиций.
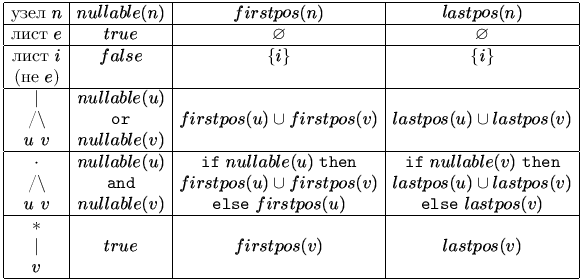
Теперь, обходя дерево T снизу-вверх слева-направо, вычислим четыре функции: nullable, firstpos, lastpos и followpos. Функции nullable, firstpos и lastpos определены на узлах дерева, а followpos - на множестве позиций. Значением всех функций, кроме nullable, является множество позиций. Функция followpos вычисляется через три остальные функции.
Функция firstpos(n) для каждого узла n синтаксического дерева регулярного выражения дает множество позиций, которые соответствуют первым символам в подцепочках, генерируемых подвыражением с вершиной в n. Аналогично, lastpos(n) дает множество позиций, которым соответствуют последние символы в подцепочках, генерируемых подвыражениями с вершиной n. Для узла n, поддеревья которого (т.е. деревья, у которых узел n является корнем) могут породить пустое слово, определим nullable(n) = true, а для остальных узлов nullable(n) = false.
Таблица для вычисления функций nullable, firstpos и lastpos приведена на рис. 3.11.
|
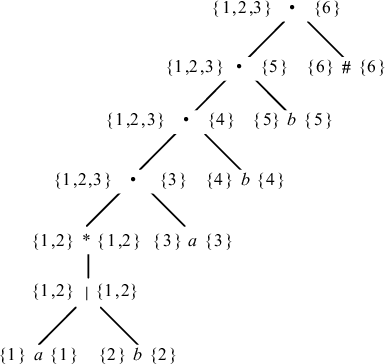
Пример 3.7. Синтаксическое дерево для пополненного регулярного выражения (a|b)*abb# с результатом вычисления функций firstpos и lastpos приведено на рис. 3.12. Слева от каждого узла расположено значение firstpos, справа от узла - значение lastpos. Заметим, что эти функции могут быть вычислены за один обход дерева.
|

|
Если i - позиция, то followpos(i) есть множество позиций j таких, что существует некоторая строка ...cd..., входящая в язык, описываемый регулярным выражением, такая, что позиция i соответствует этому вхождению c, а позиция j - вхождению d.
Функция followpos может быть вычислена также за один обход дерева снизу-вверх по следующим двум правилам.
1. Пусть n - внутренний узел с операцией . (конкатенация), u и v - его потомки. Тогда для каждой позиции i, входящей в lastpos(u), добавляем к множеству значений followpos(i) множество firstpos(v).
2. Пусть n - внутренний узел с операцией * (итерация), u - его потомок. Тогда для каждой позиции i, входящей в lastpos(u), добавляем к множеству значений followpos(i) множество firstpos(u).
Пример 3.8. Результат вычисления функции followpos для регулярного выражения из предыдущего примера приведен на рис. 3.13.
Алгоритм 3.3. Прямое построение ДКА по регулярному выражению.
Вход. Регулярное выражение r в алфавите T.
Выход. ДКА M = (Q, T, D, q0, F), такой что L(M) = L(r).
Метод. Состояния ДКА соответствуют множествам позиций.
Вначале Q и D пусты. Выполнить шаги 1-6:
- Построить синтаксическое дерево для пополненного регулярного выражения (r)#.
- Обходя синтаксическое дерево, вычислить значения функций nullable, firstpos, lastpos и followpos.
- Определить q0 = firstpos(root), где root - корень синтаксического дерева.
- Добавить q0 в Q как непомеченное состояние.
- Выполнить
следующую
процедуру:
while (в Q есть непомеченное состояние R){
пометить R;
for (каждого входного символа a
T , такого,
что
в R имеется позиция, которой соответствует a){
пусть символ a в R соответствует позициям
p1, ..., pn, и пусть S =
1<i<nfollowpos(pi);
if (S
 ){
){
if (S
 Q)
Q)
добавить S в Q как непомеченное состояние;
определить D(R, a) = S;
}
}
}
- Определить F как множество всех состояний из Q, содержащих позиции, связанные с символом #.
Пример 3.9. Результат применения алгоритма 3.3 для регулярного выражения (a|b)*abb приведен на рис. 3.14.
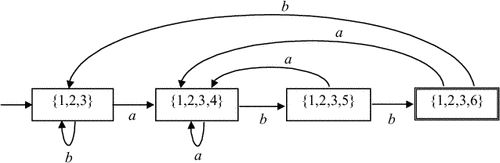
|
3.3.4 Построение детерминированного конечного автомата с минимальным числом состояний
Рассмотрим теперь алгоритм построения ДКА с минимальным числом состояний, эквивалентного данному ДКА [10].
Пусть M = (Q, T, D, q0, F) -
ДКА. Будем
называть
M всюду
определенным,
если D(q, a)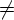 для
всех q Q и a T.
для
всех q Q и a T.
Лемма. Пусть M = (Q, T, D, q0, F)
- ДКА, не
являющийся
всюду
определенным.
Существует
всюду
определенный
ДКА M', такой
что L(M) = L(M').
Доказательство. Рассмотрим
автомат
M' = (Q {q'}, T, D', q0, F), где q'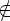 Q -
некоторое
новое
состояние,
а функция D'
определяется
следующим
образом:
Q -
некоторое
новое
состояние,
а функция D'
определяется
следующим
образом:
- Для всех q
Q и a T, таких что
D(q, a)
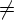 , определить
D'(q, a) = D(q, a).
, определить
D'(q, a) = D(q, a).
- Для всех q
Q и a T, таких что
D(q, a) = , определить
D'(q, a) = q'.
- Для всех a
T определить
D'(q', a) = q'.
Легко показать, что автомат M' допускает тот же язык, что и M. __
Приведенный ниже алгоритм получает на входе всюду определенный автомат. Если автомат не является всюду определенным, его можно сделать таковым на основании только что приведенной леммы.
Алгоритм 3.4. Построение ДКА с минимальным числом состояний.
Вход. Всюду определенный ДКА M = (Q, T, D, q0, F).
Выход. ДКА M' = (Q', T, D', q0', F'), такой что L(M) = L(M') и M' содержит наименьшее возможное число состояний.
Метод. Выполнить шаги 1-5:
- Построить
начальное
разбиение
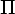 множества
состояний
из двух групп:
заключительные
состояния
Q и остальные
Q - F, т.е. = {F, Q - F}.
множества
состояний
из двух групп:
заключительные
состояния
Q и остальные
Q - F, т.е. = {F, Q - F}.
- Применить
к следующую
процедуру
и получить
новое разбиение
new:
for (каждой группы G в
){
разбить G на подгруппы так, чтобы
состояния s и t из G оказались
в одной подгруппе тогда и только тогда,
когда для каждого входного символа a
состояния s и t имеют переходы по a
в состояния из одной и той же группы в
;
заменить G в
new на множество
всех
полученных подгрупп;
}
- Если new = , полагаем
res = и переходим
к шагу 4, иначе
повторяем
шаг 2 с := new.
- Пусть res = {G1, ..., Gn}. Определим:
Q' = {G1, ..., Gn};
q0' = G, где группа G
Q' такова,
что q0 G;
F' = {G|G
Q' и G F };
};
D'(p', a) = q', если D(p, a) = q, где p
p' и q q'.
Таким образом, каждая группа в
res становится
состоянием
нового автомата
M'. Если группа
содержит
начальное
состояние
автомата
M, эта группа
становится
начальным
состоянием
автомата
M'. Если группа
содержит
заключительное
состояние
M, она становится
заключительным
состоянием
M'. Отметим,
что каждая
группа res либо
состоит только
из состояний
из F, либо не
имеет состояний
из F. Переходы
определяются
очевидным
образом.
- Если M' имеет «мертвое» состояние, т.е. состояние, которое не является допускающим и из которого нет путей в допускающие, удалить его и связанные с ним переходы из M'. Удалить из M' также все состояния, недостижимые из начального.
Пример 3.10. Результат применения алгоритма 3.4 приведен на рис. 3.15.
|
3.4 Регулярные множества и их представления
В разделе 3.3.3 приведен алгоритм построения детерминированного конечного автомата по регулярному выражению. Рассмотрим теперь как по описанию конечного автомата построить регулярное множество, совпадающее с языком, допускаемым конечным автоматом.
Теорема 3.1. Язык, допускаемый детерминированным конечным автоматом, является регулярным множеством.
Доказательство. Пусть
L - язык
допускаемый
детерминированным
конечным
автоматом
M = ({q1, ..., qn}, T, D, q1, F). Введем De -
расширенную
функцию
переходов
автомата M: De(q, w) = p,
где w T*, тогда
и только
тогда, когда
(q, w) *(p, e).
Обозначим
Rijk множество
всех слов x
таких, что
De(qi, x) = qj и если De(qi, y) = qs
для любой
цепочки y -
префикса x,
отличного
от x и e, то s  k.
k.
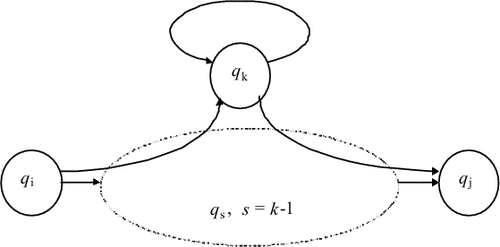
Иными словами, Rijk есть множество всех слов, которые переводят конечный автомат из состояния qi в состояние qj, не проходя ни через какое состояние qs для s > k. Однако, i и j могут быть больше k.
Rijk может быть определено рекурсивно следующим образом:
- Rij0 = {a|a T, D(qi, a) = qj},
- Rijk = Rijk-1
Rikk-1(Rkkk-1)*Rkjk-1, где
1 k n.
Таким образом, определение Rijk означает, что для входной цепочки w, переводящей M из qi в qj без перехода через состояния с номерами, большими k, справедливо ровно одно из следующих двух утверждений:
- Цепочка w принадлежит Rijk-1, т.е. при анализе цепочки w автомат никогда не достигает состояний с номерами, большими или равными k.
- Цепочка w может
быть представлена
в виде w = w1w2w3,
где w1 Rikk-1 (подцепочка
w1 переводит
M сначала в
qk),
w2 (Rkkk-1)* (подцепочка
w2 переводит
M из qk обратно
в qk, не проходя
через состояния
с номерами,
большими
или равными k),
и w3 Rkjk-1 (подцепочка
w3 переводит
M из состояния
qk в qj) - рис. 3.16.
|
Тогда L =
qj FR1jn.
Индукцией
по k можно
показать,
что это
множество
является
регулярным. __
FR1jn.
Индукцией
по k можно
показать,
что это
множество
является
регулярным. __
Таким образом, для всякого регулярного множества имеется конечный автомат, допускающий в точности это регулярное множество, и наоборот - язык, допускаемый конечным автоматом есть регулярное множество.
Рассмотрим теперь соотношение между языками, порождаемыми праволинейными грамматиками и допускаемыми конечными автоматами.
Праволинейная грамматика G = (N, T, P, S) называется регулярной, если
- каждое
ее
правило,
кроме S
 e,
имеет
вид либо
A aB, либо A a,
где A, B N, a T;
e,
имеет
вид либо
A aB, либо A a,
где A, B N, a T;
- в том случае,
когда S e P, начальный
символ S не
встречается
в правых частях
правил.
Лемма. Пусть G - праволинейная грамматика. Существует регулярная грамматика G' такая, что L(G) = L(G').
Доказательство. Предоставляется читателю в качестве упражнения. __
Теорема 3.2. Пусть G = (N, T, P, S) - праволинейная грамматика. Тогда существует конечный автомат M = (Q, T, D, q0, F) для которого L(M) = L(G).
Доказательство. На основании приведенной выше леммы, без ограничения общности можно считать, что G - регулярная грамматика.
Построим недетерминированный конечный автомат M следующим образом:
- состояниями
M будут нетерминалы
G плюс новое
состояние
R, не принадлежащее
N. Так что Q = N
{R};
- в качестве начального состояния M примем S, т.е. q0 = S;
- если P содержит
правило S
e, то F = {S, R}, иначе
F = {R}. Напомним,
что S не встречается
в правых частях
правил, если
S e P;
- состояние
R D(A, a), если A a P. Кроме
того, D(A, a) содержит
все B такие,
что A aB P. D(R, a) = для
каждого a
T.
M, читая вход w,
моделирует
вывод w в
грамматике
G. Покажем,
что L(M) = L(G). Пусть
w = a1a2...an L(G), n  1. Тогда
1. Тогда
 L(M),
поскольку
De(S, w) содержит
R, а R F. Если e L(G),
то S F, так что
e L(M).
L(M),
поскольку
De(S, w) содержит
R, а R F. Если e L(G),
то S F, так что
e L(M).
Аналогично,
если w = a1a2...an L(M), n 1, то
существует
последовательность
состояний
S, A1, A2, ..., An-1, R такая, что
D(S, a1) содержит A1,
D(A1, a2) содержит A2,
и т.д. Поэтому
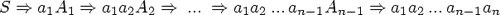 L(G). Если e L(M), то
S F, так что S e P
и e L(G). __
L(G). Если e L(M), то
S F, так что S e P
и e L(G). __
Теорема 3.3. Для каждого конечного автомата M = (Q, T, D, q0, F) существует праволинейная грамматика G = (N, T, P, S) такая, что L(G) = L(M).
Доказательство. Без потери общности можно считать, что автомат M - детерминированный. Определим грамматику G следующим образом:
- нетерминалами грамматики G будут состояния автомата M. Так что N = Q;
- в качестве начального символа грамматики G примем q0, т.е. S = q0;
- A aB P, если D(A, a) = B;
- A a P, если D(A, a) = B
и B F;
- S e P, если q0 F.
Доказательство
того, что
S  *w тогда и
только
тогда, когда
De(q0, w) F, аналогично
доказательству
теоремы 3.2. __
*w тогда и
только
тогда, когда
De(q0, w) F, аналогично
доказательству
теоремы 3.2. __
3.5 Программирование лексического анализа
Как уже отмечалось ранее, лексический анализатор (ЛА) может быть оформлен как подпрограмма. При обращении к ЛА, вырабатываются как минимум два результата: тип выбранной лексемы и ее значение (если оно есть).
Если ЛА сам формирует таблицы объектов, он выдает тип лексемы и указатель на соответствующий вход в таблице объектов. Если же ЛА не работает с таблицами объектов, он выдает тип лексемы, а ее значение передается, например, через некоторую глобальную переменную. Помимо значения лексемы, эта глобальная переменная может содержать некоторую дополнительную информацию: номер текущей строки, номер символа в строке и т.д. Эта информация может использоваться в различных целях, например, для диагностики.
В основе ЛА лежит диаграмма переходов соответствующего конечного автомата. Отдельная проблема здесь - анализ ключевых слов. Как правило, ключевые слова - это выделенные идентификаторы. Поэтому возможны два основных способа распознавания ключевых слов: либо очередная лексема сначала диагностируется на совпадение с каким-либо ключевым словом и в случае неуспеха делается попытка выделить лексему из какого-либо класса, либо, наоборот, после выборки лексемы идентификатора происходит обращение к таблице ключевых слов на предмет сравнения. Подробнее о механизмах поиска в таблицах будет сказано ниже (гл. 7), здесь отметим только, что поиск ключевых слов может вестись либо в основной таблице имен и в этом случае в нее до начала работы ЛА загружаются ключевые слова, либо в отдельной таблице. При первом способе все ключевые слова непосредственно встраиваются в конечный автомат лексического анализатора, во втором конечный автомат содержит только разбор идентификаторов.
В некоторых языках (например, ПЛ/1 или Фортран) ключевые слова могут использоваться в качестве обычных идентификаторов. В этом случае работа ЛА не может идти независимо от работы синтаксического анализатора. В Фортране возможны, например, следующие строки:
DO 10 I=1,25
|
DO 10 I=1.25
|
В первом случае строка - это заголовок цикла DO, во втором - оператор присваивания. Поэтому, прежде чем можно будет выделить лексему, лексический анализатор должен заглянуть довольно далеко.
Еще сложнее дело в ПЛ/1. Здесь возможны такие операторы:
IF ELSE THEN ELSE = THEN; ELSE THEN = ELSE;
|
или
DECLARE (A1, A2, ... , AN)
|
Рассмотрим несколько подробнее вопросы программирования ЛА. Основная операция лексического анализатора, на которую уходит большая часть времени его работы - это взятие очередного символа и проверка на принадлежность его некоторому диапазону. Например, основной цикл при выборке числа в простейшем случае может выглядеть следующим образом:
while (Insym<='9' && Insym>='0')
{ ... } |
Программу можно значительно улучшить следующим образом [4]. Пусть LETTER, DIGIT, BLANK - элементы перечислимого типа. Введем массив map, входами которого будут символы, значениями - типы символов. Инициализируем массив map следующим образом:
map['a']=LETTER;
........ map['z']=LETTER; map['0']=DIGIT; ........ map['9']=DIGIT; map[' ']=BLANK; ........ |
Тогда приведенный выше цикл примет следующую форму:
while (map[Insym]==DIGIT)
{ ... } |
Выделение ключевых слов может осуществляться после выделения идентификаторов. ЛА работает быстрее, если ключевые слова выделяются непосредственно.
Для этого строится конечный автомат, описывающий множество ключевых слов. На рис. 3.17 приведен фрагмент такого автомата. Рассмотрим пример программирования этого конечного автомата на языке Си, приведенный в [14]:
 |
Здесь cp - указатель текущего символа. В массиве map классы символов кодируются битами.
Поскольку ЛА анализирует каждый символ входного потока, его скорость существенно зависит от скорости выборки очередного символа входного потока. В свою очередь, эта скорость во многом определяется схемой буферизации. Рассмотрим возможные эффективные схемы буферизации.
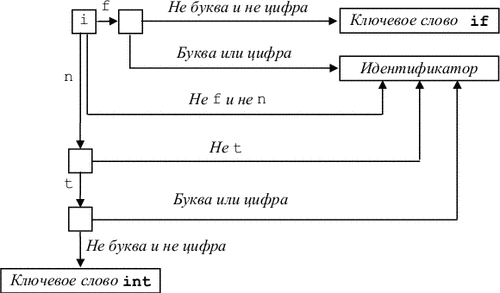
Будем использовать буфер, состоящий из двух одинаковых частей длины N (рис. 3.18, а), где N - размер блока обмена (например, 1024, 2048 и т.д.).
 |
Чтобы не читать каждый символ отдельно, в каждую из половин буфера поочередно одной командой чтения считывается N символов. Если на входе осталось меньше N символов, в буфер помещается специальный символ (eof). На буфер указывают два указателя: продвижение и начало. Между указателями размещается текущая лексема. Вначале они оба указывают на первый символ выделяемой лексемы. Один из них, продвижение, продвигается вперед, пока не будет выделена лексема, и устанавливается на ее конец. После обработки лексемы оба указателя устанавливаются на символ, следующий за лексемой. Если указатель продвижение переходит середину буфера, правая половина заполняется новыми N символами. Если указатель продвижение переходит правую границу буфера, левая половина заполняется N символами и указатель продвижение устанавливается на начало буфера.
При каждом продвижении указателя необходимо проверять, не достигли ли мы границы одной из половин буфера. Для всех символов, кроме лежащих в конце половин буфера, требуются две проверки. Число проверок можно свести к одной, если в конце каждой половины поместить дополнительный «сторожевой» символ, в качестве которого логично взять eof (рис. 3.18, б).
В этом случае почти для всех символов делается единственная проверка на совпадение с eof и только в случае совпадения нужно дополнительно проверить, достигли ли мы середины или правого конца.
3.6 Конструктор лексических анализаторов LEX
Для автоматизации разработки лексических анализаторов было разработано довольно много средств. Как правило, входным языком для них служат либо праволинейные грамматики, либо язык регулярных выражений. Одной из наиболее распространенных систем является LEX, работающий с расширенными регулярными выражениями. LEX-программа состоит из трех частей:
Объявления
%% Правила трансляции %% Вспомогательные подпрограммы |
Секция объявлений включает объявления переменных, констант и определения регулярных выражений. При определении регулярных выражений могут использоваться следующие конструкции:
| [abc] | - либо a, либо b, либо c; |
| [a-z] | - диапазон символов; |
| R* | - 0 или более повторений регулярного выражения R; |
| R+ | - 1 или более повторений регулярного выражения R; |
| R1/R2 | - R1, если за ним следует R2; |
| R1|R2 | - либо R1, либо R2; |
| R? | - если есть R, выбрать его; |
| R$ | - выбрать R, если оно последнее в строке; |
| ^R | - выбрать R, если оно первое в строке; |
| [^R] | - дополнение к R; |
| R{n,m} | - повторение R от n до m раз; |
| {имя} | - именованное регулярное выражение; |
| (R) | - группировка. |
Правила трансляции LEX программ имеют вид
p_1 { действие_1 }
p_2 { действие_2 } ................ p_n { действие_n } |
Третья секция содержит вспомогательные процедуры, необходимые для действий. Эти процедуры могут транслироваться раздельно и загружаться с лексическим анализатором.
Лексический анализатор, сгенерированный LEX, взаимодействует с синтаксическим анализатором следующим образом. При вызове его синтаксическим анализатором лексический анализатор посимвольно читает остаток входа, пока не находит самый длинный префикс, который может быть сопоставлен одному из регулярных выражений p_i. Затем он выполняет действие_i. Как правило, действие_i возвращает управление синтаксическому анализатору. Если это не так, т.е. в соответствующем действии нет возврата, то лексический анализатор продолжает поиск лексем до тех, пока действие не вернет управление синтаксическому анализатору. Повторный поиск лексем вплоть до явной передачи управления позволяет лексическому анализатору правильно обрабатывать пробелы и комментарии. Синтаксическому анализатору лексический анализатор возвращает единственное значение - тип лексемы. Для передачи информации о типе лексемы используется глобальная переменная yylval. Текстовое представление выделенной лексемы хранится в переменной yytext, а ее длина в переменной yylen.
Пример 3.11. LEX-программа для ЛА, обрабатывающего идентификаторы, числа, ключевые слова if, then, else и знаки логических операций.
%{ /*определения констант LT,LE,EQ,NE,GT,
GE,IF,THEN,ELSE,ID,NUMBER,RELOP, например, через DEFINE или скалярный тип*/ %} /*регулярные определения*/ delim [ \t\n] ws {delim}+ letter [A-Za-z] digit [0-9] id {letter}({letter}|{digit})* number {digit}+(\.{digit}+)?(E[+\-]?{digit}+)? %% {ws} {/* действий и возврата нет */} if {return(IF);} then {return(THEN);} else {return(ELSE);} {id} {yylval=install_id(); return(ID);} {number} {yylval=install_num(); return(NUMBER);} "<" {yylval=LT; return(RELOP);} "<=" {yylval=LE; return(RELOP);} "=" {yylval=EQ; return(RELOP);} "<>" {yylval=NE; return(RELOP);} ">" {yylval=GT; return(RELOP);} ">=" {yylval=GE; return(RELOP);} %% install_id() {/*подпрограмма, которая помещает лексему, на первый символ которой указывает yytext, длина которой равна yylen, в таблицу символов и возвращает указатель на нее*/ } install_num() {/*аналогичная подпрограмма для размещения лексемы числа*/ } |
В разделе объявлений, заключенном в скобки %{ и %}, перечислены константы, используемые правилами трансляции. Все, что заключено в эти скобки, непосредственно копируется в программу лексического анализатора lex.yy.c и не рассматривается как часть регулярных определений или правил трансляции. То же касается и вспомогательных подпрограмм третьей секции. В данном примере это подпрограммы install_id и install_num.
В секцию определений входят также некоторые регулярные определения. Каждое такое определение состоит из имени и регулярного выражения, обозначаемого этим именем. Например, первое определенное имя - это delim. Оно обозначает класс символов { \t\n\}, т.е. любой из трех символов: пробел, табуляция или новая строка. Второе определение - разделитель, обозначаемый именем ws. Разделитель - это любая последовательность одного или более символов-разделителей. Слово delim должно быть заключено в скобки, чтобы отличить его от образца, состоящего из пяти символов delim.
В определении letter используется класс символов. Сокращение [A-Za-z] означает любую из прописных букв от A до Z или строчных букв от a до z. В пятом определении для id для группировки используются скобки, являющиеся метасимволами LEX. Аналогично, вертикальная черта - метасимвол LEX, обозначающий объединение.
В последнем регулярном определении number символ «+» используется как метасимвол «одно или более вхождений», символ «?» как метасимвол «ноль или одно вхождение». Обратная черта используется для того, чтобы придать обычный смысл символу, использующемуся в LEX как метасимвол. В частности, десятичная точка в определении number обозначается как «\.», поскольку точка сама по себе представляет класс, состоящий из всех символов, за исключением символа новой строки. В классe символов [+\] обратная черта перед минусом стоит потому, что знак минус используется как символ диапазона, как в [A-Z].
Если символ имеет смысл метасимвола, то придать ему обычный смысл можно и по-другому, заключив его в кавычки. Так, в секции правил трансляции шесть операций отношения заключены в кавычки.
Рассмотрим правила трансляции, следующие за первым %%. Согласно первому правилу, если обнаружено ws, т.е. максимальная последовательность пробелов, табуляций и новых строк, никаких действий не производится. В частности, не осуществляется возврат в синтаксический анализатор.
Согласно второму правилу, если обнаружена последовательность букв «if», нужно вернуть значение IF, которое определено как целая константа, понимаемая синтаксическим анализатором как лексема «if». Аналогично обрабатываются ключевые слова «then» и «else» в двух следущих правилах.
В действии, связанном с правилом для id, два оператора. Переменной yylval присваивается значение, возвращаемое процедурой install_id. Переменная yylval определена в программе lex.yy.c, выходе LEX, и она доступна синтаксическому анализатору. yylval хранит возвращаемое лексическое значение, поскольку второй оператор в действии, return(ID), может только возвратить код класса лексем. Функция install_id заносит идентификаторы в таблицу символов.
Аналогично обрабатываются числа в следующем правиле. В последних шести правилах yylval используется для возврата кода операции отношения, возвращаемое же функцией значение - это код лексемы relop.
Если, например, в текущий момент лексический анализатор обрабатывает лексему «if», то этой лексеме соответствуют два образца: «if» и {id} и более длинной строки, соответствующей образцу, нет. Поскольку образец «if» предшествует образцу для идентификатора, конфликт разрешается в пользу ключевого слова. Такая стратегия разрешения конфликтов позволяет легко резервировать ключевые слова.
Если на входе встречается «<=», то первому символу соответствует образец «<», но это не самый длинный образец, который соответствует префиксу входа. Стратегия выбора самого длинного префикса легко разрешает такого рода конфликты.