Компиляция программ для современных архитектур
А. Белеванцев, Д. Журихин, Д. Мельник
Труды Института системного программирования РАН
Аннотация. Настоящая статья посвящена обзору некоторых работ по оптимизации программ для современных вычислительных архитектур, проводимых в отделе компиляторных технологий Института системного программирования РАН. Работы включают в себя выявление параллелизма на уровне команд для архитектуры Intel Itanium, исследование и разработку энергосберегающих оптимизаций для архитектуры ARM, а также исследования по динамическим оптимизациям для языков общего назначения, выполняемым на машине пользователя. Большинство приведенных работ выполнялось в рамках компилятора GCC с открытыми исходными кодами, являющегося стандартным компилятором для Unix-подобных систем.
Содержание
- 1. Введение
- 2. Компиляция для архитектур с явно выраженным параллелизмом команд
- 3. Оптимизации энергопотребления встраиваемых систем, управляемые компилятором
- 4. Динамические оптимизации для языков общего назначения
- 5. Заключение
- Литература
- 5. Заключение
1. Введение
Развитие вычислительной техники за последние годы приводит к появлению большого количества процессорных архитектур, для использования возможностей которых необходимы новые технологии компиляции. Например, архитектуры с явно выраженным параллелизмом команд требуют от компилятора наличия оптимизаций, направленных на выявление и использование такого параллелизма, а именно – агрессивного планирования команд и конвейеризации циклов. Популярность встраиваемых архитектур, повсеместно использующихся в мобильных устройствах самого разнообразного назначения, влечет необходимость разработки компиляторных технологий, обеспечивающих не только высокую производительность программ, но и небольшой размер исполняемых файлов, а также низкое энергопотребление системы. Многоядерные архитектуры и гетерогенные архитектуры с несколькими акселераторами, получившие широкое распространение, нуждаются в разработке новых методов компиляции, позволяющих программисту в полуавтоматическом режиме указать желаемое распределение вычислений и потоков данных по компонентам таких архитектур. Наконец, актуальной является задача об оптимизации программы для конкретной реализации некоторой архитектуры, а также для конкретных наборов входных данных пользователя. Эта задача частично решена для динамических языков типа Java, но не для языков общего назначения.
Настоящая статья посвящена обзору некоторых работ, проводимых по этим направлениям в отделе компиляторных технологий Института системного программирования РАН. Работы включают в себя выявление параллелизма на уровне команд для архитектуры Intel Itanium, исследование и разработку энергосберегающих оптимизаций для архитектуры ARM, а также исследования по динамическим оптимизациям для языков общего назначения, выполняемым на машине пользователя. Большинство приведенных работ выполнялось в рамках компилятора GCC [5] с открытыми исходными кодами, являющегося де-факто стандартом для UNIX-систем и поддерживающего широкий набор входных языков (Cи/Си++, Фортран, Java, Ада) и целевых архитектур (x86, PowerPC, SPARC, ARM, Itanium и множество других). Каждой из этих работ далее посвящена один раздел, включающий обзор существующих исследований по соответствующему направлению, описание работ, выполненных в ИСП РАН, полученные результаты и планы на ближайшие годы. Наконец, в заключение статьи приводятся и обсуждаются выводы из проведенных исследований.
2. Компиляция для архитектур с явно выраженным параллелизмом команд
Современные процессорные архитектуры обладают большим количеством параллельно работающих конвейерных функциональных устройств. Для достижения высокой производительности на этих архитектурах требуется обеспечить непрерывную загрузку этих функциональных устройств, максимально используя параллелизм на уровне команд, имеющийся в программе. Основным способом в выявлении такого параллелизма является переупорядочивание команд, выполняемое при планировании команд либо конвейеризации циклов.
Суперскалярные архитектуры (x86, PowerPC) планируют команды аппаратно во время выполнения программы, т.е. порядок выдачи команд на выполнение может отличаться от порядка, диктуемого программой. Архитектуры с явным параллелизмом команд (EPIC) требуют, чтобы окончательный порядок выполнения команд определялся при компиляции: сама архитектура точно следует заданному порядку, не выполняя никакого динамического переупорядочивания. Это позволяет отказаться от аппаратных устройств, реализующих это переупорядочивание, в пользу других свойств, предоставляющих компилятору больше возможностей по выявлению параллелизма на уровне команд. Рассмотрим кратко наиболее важные из этих свойств, реализованных в архитектуре Itanium.
2.1. Особенности архитектур с явно выраженным параллелизмом
Опережающее выполнение команд прежде, чем становится известно, что их выполнение необходимо, принято называть спекулятивным выполнением (speculative execution). В суперскалярной архитектуре поддержка спекулятивного выполнения, необходимая для предсказания переходов, обеспечивается специальным буфером переупорядочивания, хранящим промежуточные результаты выполнившихся спекулятивно команд, а также раздельными механизмами фиксации и выдачи спекулятивных и обычных команд. В EPIC-архитектуре компилятор обязан выбрать команду для спекулятивного выполнения, переместить её в новое место и пометить, как спекулятивную. При этом для корректной обработки исключений архитектура обеспечивает их подавление при выполнении спекулятивной команды и выброс исключения на специальной команде проверки, также вставляемой компилятором. Пример спекулятивного выполнения команд на архитектуре Itanium показан на рис. 1.

Рис. 1. Спекулятивное выполнение на процессоре Itanium:
а) – первоначальный код, б) – измененный компилятором
Другим примером особенности, направленной на выявление параллелизма на уровне команд, является поддержка условного выполнения через предикатные регистры. При условном выполнении практически любую команду можно аннотировать одним из предикатных регистров, при этом команда выполняется только в том случае, если значение предикатного регистра равно единице. Это позволяет выражать достаточно длинные ветвления без переходов, но лишь командами сравнения и командами с условным выполнением, что в свою очередь уменьшает количество зависимостей по управлению, мешающих выявлению параллелизма.
Рассмотрим пример реализации условного выполнения в процессорах Itanium. Предикатные регистры в Itanium хранятся в 64-битном слове, при этом команды сравнения устанавливают пару соседних предикатных регистров в противоположные значения; таким образом, можно одновременно хранить результат 31 сравнения (значение нулевого предикатного регистра фиксировано и равно логической единице). В коде каждой команды есть 6-битное поле, в котором записан номер предикатного регистра, контролирующего её выполнение (наличие всегда установленного в единицу предикатного регистра позволяет единообразно записывать условно и безусловно выполняющиеся команды). Условные переходы записываются как безусловные переходы, защищённые соответствующим предикатом. На рис. 2 показан пример вычисления минимума из двух целых чисел на ассемблере x86 (без использования команды условной пересылки) и на ассемблере Itanium с применением условного выполнения.
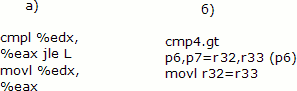
Рис. 2. Вычисление минимума двух чисел на ассемблере x86 (а) и с помощью условного выполнения на процессоре Itanium (б).
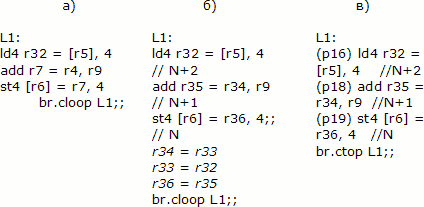
Рис. 3. Исходный цикл (а) и ядро конвейеризованного цикла c использованием явных пересылок между регистрами (б) и вращающихся регистров (в).
Наконец, последним рассмотрим поддержку в EPIC-архитектуре вращающихся регистров. Важной оптимизацией для выявления параллелизма на уровне команд является программная конвейеризация циклов, целью которой является такое планирование команд тела цикла, что итерации цикла выстраиваются в «конвейер», образуя пролог цикла, ядро из команд с различных итераций, и эпилог. В том случае, когда в ядре перекрываются сразу несколько итераций, часто необходимо выполнять переименование регистров, чтобы устранить ложные зависимости по регистрам между итерациями. Такое переименование обычно требует дополнительных операций пересылок между регистрами (см. рисунок 3(б), где такие пересылки показаны курсивом), причем если результат, записанный на предыдущей итерации в копируемый регистр, еще не готов, то обращение к этому регистру вызовет останов конвейера до завершения вычисления этого результата.
Избавиться от лишних пересылок регистров помогает механизм вращающихся регистров, представляющий из себя аппаратно поддерживаемое переименование регистров. Команды цикла используют виртуальные номера регистров, r32-r127, а команда br.ctop выполняет сдвиг окна отображения виртуальных регистров в физические таким образом, что происходит циклическое переименование: r[i]=r[i-1], i=1..N-1, r[0]=r[N-1], где N – размер вращающегося регистрового окна. Никаких физических пересылок значений между регистрами при этом не происходит. Более того, за счет использования вращающихся предикатных регистров автоматически генерируется пролог и эпилог цикла (см. рис. 3 (в)).
2.2. Алгоритм планирования команд и конвейеризации циклов для Intel Itanium
В ИСП РАН было выполнено несколько работ по улучшению производительности компилятора GCC для платформы Intel Itanium, в ходе которых разрабатывалась и реализовывалась поддержка в GCC рассмотренных выше свойств этой архитектуры. Первыми были закончены работы по добавлению поддержки спекулятивного выполнения в планировщик команд компилятора GCC, описанные в [5]. По результатам тестирования реализации на пакете тестов SPEC CPU 2000 [5] было получено ускорение в 2.5%, а на отдельных тестах – до 20%. Это позволило включить реализованную поддержку в официальные релизы компилятора GCC, начиная с версии 4.2.0. Кроме этого, были выполнены работы по улучшению точности низкоуровневого анализа алиасов, используемого в компиляторе GCC, и использованию более точных данных при планировании команд.
По результатам изначальных исследований по улучшению планирования команд было принято решение о разработке и реализации нового планировщика команд и конвейеризации циклов для EPIC-архитектур, основанного на подходе селективного планирования [5]. Алгоритм селективного планирования был разработан для архитектур с очень длинным командным словом и хорошо подходит для экспериментов по увеличению производительности для EPIC-архитектур. Он поддерживает ряд полезных преобразований команд, позволяющих избавляться от части зависимостей по данным (переименование регистров, подстановка через копии), а также делает простым добавление новых преобразований.
2.2.1. Базовый алгоритм селективного планирования
Селективный планировщик является классическим итеративным планировщиком, обходящим регион планирования сверху вниз. Обрабатываются произвольные ациклические регионы графа потока управления программы, возможно, с несколькими входами. Поддерживается несколько точек планирования, к которым собираются доступные команды, называемых барьерами. Каждая итерация планировщика четко делится на этап сбора доступных команд, этап выбора лучшей команды для планирования и этап перемещения выбранной команды, при этом корректность программы обеспечивается этапом сбора и перемещения, а получаемая производительность полностью зависит от этапа выбора лучшей команды, который обычно является набором эвристик. После того, как на текущем цикле планирования для данного барьера невозможно выполнить больше команд, либо нет доступных для выполнения команд, обрабатывается следующий барьер. После обработки всех барьеров происходит передвижение барьеров через запланированные команды, и цикл планирования повторяется. Планировщик останавливается по достижении конца региона.
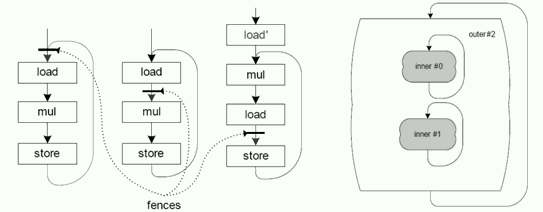
Рис. 4. Конвейеризация циклов в селективном планировании:
продвижение барьеров во внутреннем цикле (слева),
образование регионов для всего гнезда циклов (справа).
При сборе команд для планирования регион обходится в обратном топологическом порядке; при этом текущее множество собранных команд «протаскивается» через обрабатываемую команду на пути «наверх», и все команды, имеющие неустранимые зависимости по управлению либо по данным с обрабатываемой, удаляются из множества. Все преобразования команд, ведущие к устранению зависимостей, могут быть реализованы на этом этапе. В точках разделения потока управления текущее множество доступных команд предварительно получается как объединение всех множеств, доступных на потомках обрабатываемой команды. Дополнительно в процессе сбора могут быть вычислены некоторые атрибуты команд (доступность вдоль разных путей, вероятность выполнения и т.п.), которые могут использоваться в дальнейшем при выборе лучшей команды для планирования. Промежуточные множества доступных команд сохраняются в начале каждого базового блока.
На этапе перемещения выбранной команды регион обходится аналогичным образом сверху вниз в поиске команд, которые могли быть преобразованы в выбранную, при этом используются сохраненные множества доступных команд – если искомая команда не содержится в сохраненном множестве, то её нет смысла искать ниже текущего места региона. Если команда найдена, то она удаляется из региона, а на обратном пути вверх обновляются сохраненные множества доступных команд и в точках слияния потока управления на путях, не лежащих на текущем пути обхода, создаются компенсационные копии выбранной команды. После окончания перемещения выбранная команда в преобразованном виде добавляется в поток команд в точке планирования, а все промежуточные множества доступных команд оказываются верными, что значительно ускоряет этап сбора команд для следующей итерации планирования.
Важным достоинством селективного планировщика является возможность конвейеризации циклов, вытекающая из поддержки перемещений команд с созданием компенсационных копий и из того, что перемещение команд через барьер запрещено. При планировании внутреннего цикла из гнезда циклов текущим регионом считается ациклический регион, получающийся из цикла разрывом тех дуг, на которых в данный момент стоят барьеры. В начале планирования разрывается обратная дуга цикла. На этапе сбора команд разрешается собирать уже запланированные команды – при планировании обычного региона такая ситуация запрещена. При перемещении уже запланированной команды вдоль обратной дуги на входе в цикл наблюдается слияние потока управления, и поэтому на дуге перед циклом будет создана компенсационная копия, образующая пролог конвейеризованного цикла (см. рис. 4). При планировании внешнего цикла пролог внутреннего цикла добавляется к региону планирования, а тело внутреннего цикла обрабатывается как «черный ящик», при этом перемещения команд через него запрещены.
2.2.2. Усовершенствования базового алгоритма
После реализации вышеописанного базового алгоритма для компилятора GCC и первоначальных экспериментов нами был разработан и реализован ряд усовершенствований, улучшивших как показатели производительности алгоритма, так и время его работы. Во-первых, нами были реализованы дополнительные преобразования команд: спекулятивное выполнение команд и условное выполнение команд. Для поддержки обоих преобразований необходимо модифицировать этап сбора доступных команд, а также поиск и перемещение выбранной команды наверх к точке планирования. Спекулятивные команды для Intel Itanium создаются при протаскивании команды загрузки наверх либо через условный или безусловный переход (спекулятивность по управлению), либо через возможно зависимую команду записи в память (спекулятивность по данным). Для спекулятивных команд отслеживается вероятность выполнения зависимостей (одной или нескольких), нарушенных при превращении команды в спекулятивную форму. При обнаружении команды загрузки, породившей спекулятивную форму, помимо ее удаления создается команда проверки результата спекулятивного выполнения и код восстановления, а при создании компенсационной копии такой команды эта копия обязательно преобразуется в спекулятивную форму. Более детально поддержка спекулятивного выполнения в нашем планировщике команд описана в работах [5, 5, 5].
Команды для условного выполнения создаются при слиянии промежуточных множеств доступных команд в точке разделения потока управления: в зависимости от направления, с которого поступила команда, если она еще не была аннотирована предикатным регистром, то она аннотируется либо регистром, контролирующим условный переход в точке разделения потока, либо его отрицанием. При поиске выбранной в условной форме команды необходимо преобразовать эту команду в обычную форму ровно на том условном переходе, на котором к команде был добавлен предикат при сборе команд. Остальные этапы алгоритма, в том числе создание компенсационных копий, при обработке команд в условной форме не меняются.
Во-вторых, был выполнен ряд улучшений этапа выбора лучшей команды. В первую очередь, для выбора стал использоваться существующий механизм компилятора GCC, заключающийся в отслеживании конфликтов конвейера процессора через конечный автомат, описывающий функциональные устройства процессора [5]. Интерфейс автомата позволяет узнать необходимую задержку в тактах для выдачи данной команды в данном состоянии автомата. С помощью этого интерфейса в GCC реализован механизм локального перебора команд из множества готовых к выдаче на данном такте для поиска такой команды, выдача которой позволит выдать на данном такте наибольшее количество других готовых команд. Данный механизм был адаптирован нами для работы с вычисленным планировщиком множеством готовых команд.
Далее, в ходе этапа сбора доступных команд также вычисляется полезность команды, отражающая вероятностей выполнения тех путей графа потока управления, вдоль которых доступна эта команда. Полезность команды в промежуточном множестве доступных команд умножается на вероятность перехода по дуге при протаскивании команды вверх вдоль этой дуги, а при объединении множеств в точке слияния потока управления полезности одинаковых команд, пришедших в эту точку по разным путям, складываются. Полезность готовой команды используется при сортировке готовых команд для выделения более приоритетных. Другими эвристиками при этой сортировке являются длина критического пути, начинающегося от команды, ее спекулятивность, а также вероятность выполнения зависимостей, нарушенных ее перемещением, если она спекулятивна. Кроме того, незапланированные команды предпочитаются запланированным, чтобы гарантировать окончание алгоритма при конвейеризации циклов.
Наконец, было выполнено большое количество исправлений реализации планировщика и кодогенератора GCC (более 30), которые явились результатом анализа производительности скомпилированных программ из пакета тестов SPEC CPU 2000. Приведем наиболее важные примеры. Переименование регистров применялось только к тем инструкциям, чья латентность превышает время выполнения инструкции копирования регистра в регистр. Это отсекает переименования, которые никогда не дадут выигрыша. Другим улучшением является запрет на применение преобразования переименования регистров (и спекулятивного выполнения команд по управлению) в тех случаях, когда результирующая инструкция будет запланирована на последнем такте цикла, и можно показать, что такое преобразование будет невыгодным. Далее, перепланирование конвейеризованного кода для достижения более плотного расписания в тех местах кода, из которых были перемещены инструкции, позволило нам улучшить ряд тестов SPEC на 0.5-1%. Этот дополнительный проход особенно полезен для маленьких циклов, в которых создаваемые конвейеризацией «дырки» имеют значение.
В-третьих, алгоритм планирования был ускорен по сравнению с базовым. Из основных улучшений, приведших к уменьшению времени работы алгоритма, можно перечислить следующие:
- кэширование результатов проноса команды через другую команду;
- сохранение полной «истории» преобразований, которым подверглась команда при проносе наверх, для быстрого «отката» этих изменений;
- применение переименования регистров только к самым приоритетным инструкциям;
- ограничение количества обновлений множества доступных команд так, чтобы множества обновлялись только после планирования нескольких команд на данном барьере;
- ограничение длины «окна» команд, которое просматривает планировщик в поисках кандидатов на выдачу, для прохода, на котором выполняется перепланирование кода после конвейеризации.
По результатам тестирования усовершенствованного алгоритма планирования на платформе Intel Itanium было получено среднее ускорение в 3-4% на пакете тестов SPEC CPU FP 2000 (для разного набора базовых опций получено разное ускорение), а на отдельных тестах – до 10%. Часть результатов представлена в таблице 1. Мелким шрифтом выделен тест, который работает некорректно с текущей реализацией поддержки условного выполнения.
| База | Сел | Сел +Усл |
Сел +Зав |
Сел+Зав +Усл |
|
| 168.wupwise | 553 | -2,35% | -2,35% | 1,27% | 1,45% |
| 171.swim | 754 | 1,46% | 4,91% | 0,93% | 5,04% |
| 172.mgrid | 574 | 3,66% | 3,83% | 7,49% | 8,01% |
| 173.applu | 531 | 3,95% | 3,95% | 3,77% | 4,33% |
| 177.mesa | 774 | 1,42% | 1,42% | 2,58% | 1,42% |
| 178.galgel | 856 | 2,45% | 2,22% | 3,50% | 3,50% |
| 179.art | 2025 | 1,14% | 6,17% | 1,23% | 6,22% |
| 183.equake | 509 | 8,64% | 8,64% | 6,88% | 7,07% |
| 187.facerec | 959 | -0,31% | 0,52% | 0,00% | 0,42% |
| 188.ammp | 739 | 3,79% | 4,19% | 3,79% | 4,19% |
| 189.lucas | 898 | 0,33% | -0,33% | -0,11% | 0,00% |
| 191.fma3d | 549 | -1,28% | -1,28% | 0,55% | 0,00% |
| 200.sixtrack | 325 | 0,00% | 1,23% | 8,92% | 8,92% |
| 301.apsi | 538 | 1,30% | 2,04% | 4,65% | 5,02% |
| SPEC FP Geo Mean |
687,7963 | 1,70% | 2,47% | 3,21% | 3,93% |
Таблица 1. Результаты тестов SPEC FP для планировщика команд.
Исходные коды реализованного алгоритма планирования команд и конвейеризации циклов был включен в специальную ветвь компилятора GCC, доступную с официального сайта разработчиков. Кроме того, по результатам настройки алгоритм планирования был включен в основную ветвь разработки компилятора GCC, как планировщик по умолчанию для платформы Itanium, и будет доступен в следующем релизе компилятора версии 4.4.0.
Мы продолжаем работы над улучшением алгоритма, в первую очередь – над добавлением поддержки полного графа зависимостей по данным, что позволит как ускорить сам алгоритм, так и реализовать более эффективные эвристики для этапа выбора наилучшей команды. Также будут вестись работы над настройкой реализованного алгоритма на другие архитектуры, в частности, IBM Power6.