Поиск в Интернете: использование имён
Михаил Талантов, Центр Информационных Технологий
Опубликовано в журнале КомпьютерПресс #2 (2000)
Этой статьей мы продолжаем разговор о наиболее эффективных приемах поиска информации в сети Интернет, начатый в выпусках КомпьютерПресс N 7-9 за этот год. Сегодня усилиями разработчиков растет потенциал информационно-поисковых систем (ИПС). Среди прочего предоставляется и возможность искать по ключевым словам не только внутри документа, но и в пределах его сетевого адреса - URL, т.е. среди имен серверов, каталогов и конечных информационных файлов. Специфике, преимуществу и недостаткам такого поиска будет посвящена часть материала.
Кроме того, в поле URL, где используется латинский алфавит, нередко привносится лексика из языков, графика которых не совпадает с латинской. Это явление вполне характерно и для российского сектора Интернета и связано прежде всего с масштабным присутствием в Сети имен собственных, роль которых при решении поисковых задач крайне велика. Наша цель- попытаться осмыслить современную практику употребления имен в Интернете в широком поле видения проблемы- от стандартов транслитерации до стихийного сленга.
Внутритекстовый и URL- поиск
Как известно, местоположение в Сети конечного документа (файла), однозначно задается его адресной схемой - URL. Если документ размещен не в корневом каталоге сервера, то в URL между именами узла и самого файла появляются еще и названия соответствующих каталогов. Так, для гипотетической Web-страницы rasskazy.html, находящей в подкаталоге Tolstoy каталога proza на сервере www.literature.ru,
URL выглядел бы следующим образом:
URL: http://www.literature.ru/proza/Tolstoy/rasskazy.html
Если поисковая система зарегистрировала указанный выше документ и поддерживает полноценный поиск по элементам адреса, то выйти на данную страницу можно по любому из встретившихся слов, т. е. literature, proza, Tolstoy, rasskazy и даже по их фрагментам.
В зависимости от конкретной ИПС поиск в пределах URL может задаваться различными способами - либо с помощью специальных меню и окон поискового шаблона, как, например, на Рамблере и Northern Light (см. рис. 1 ), либо в режиме командной строки, как на AltaVista (напр., url:literature), Yahoo (u:literature) или Яндексе (url="www.literature*"). Некоторые поисковые машины, в частности HotBot и Рамблер, поддерживают оба альтернативных варианта.
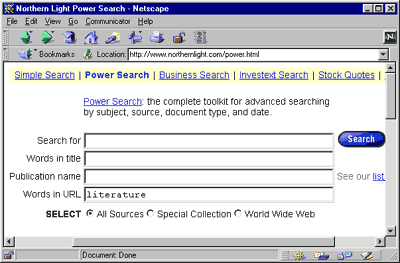
Рис.1. Элементы расширенной формы шаблона поисковых запросов на ИПС Northern Light (www.northernlight.com), поддерживающей поиск по URL (нижнее окно).
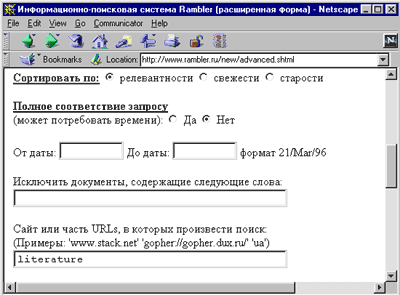
Рис.2. Элементы расширенного шаблона Рамблера (www.rambler.ru) со специальным окном для ввода терминов из URL (внизу), которые комбинируются в запросах с терминами из текстового поля.
Большинство систем допускает комбинирование URL- запроса с ключевыми словами, входящими в текст документа (рис. 2). В расширенном поиске AltaVista это может быть выполнено в виде: url:tolstoy AND "Охота пуще неволи" (вторым элементом запроса стоит фраза, являющаяся названием рассказа).
Для старейших в Сети ИПС, работающих с файловыми архивами FTP, поиск по ключевым словам, входящим в названия файлов и каталогов, всегда оставался основной функцией. Фактически поиск проводился по элементам адреса, представление которого после становления Паутины стало регламентироваться стандартом адресных схем URL. При этом достигалась универсальность индексирования: независимо от внутреннего содержимого файла, его формата - ИПС благополучно регистрировала ресурс. Ясно, что элементы адреса, несущие основную смысловую нагрузку, в то время выбирались с гораздо большей аккуратностью, чем сегодня. Размещать в Сети для свободного доступа файлы данных или программы с такими именами как 1.txt или gr12.exe было признаком дурного тона по отношению к окружающим. Однако по мере накопления объема информации пришлось столкнуться с очевидной проблемой - выйти на релевантный запросу ресурс с помощью скудного набора ключевых слов, входящих в его адрес, становилось все сложнее. Тогда были найдены решения, позволяющие сопровождать отдельные файлы дополнительным текстовым комментарием, который также индексировался, что должно было повысить контрастность отдельного ресурса в ИПС.
С приходом в Интернет Всемирной Паутины и ее основной информационной единицы - Web-страницы, для которой текстовая информация продолжает оставаться наиболее значимой, положение дел изменилось. В силу открытости формата Web-документа для свободного индексирования, началось бурное развитие поисковых машин WWW, делающих акцент теперь уже на внутритекстовом поиске. В то же самое время поиск по элементам URL многими поисковыми системами Паутины первоначально вообще не поддерживался. Тем не менее сегодня он присутствует на большинстве ИПС (см. КомпьютерПресс N 8) и заявлен в проекте стандарта SESP для поисковых систем 1999 года в качестве обязательного атрибута. На данный момент URL-поиск становится мощным, а в некоторых случаях и уникальным инструментом решения поисковых задач. Однако с его применением связан ряд особенностей.
Здоровое желание автора-разработчика узла сократить до разумного минимума длину адресов, сохранив при этом их информативность, заставляет его использовать в качестве названий каталогов и файлов короткие, но ёмкие и адекватные ресурсам имена. Вся файловая структура сервера обладает при этом большей стабильностью, чем содержимое отдельных документов, что в какой-то мере определяет область применимости и результативность URL-поиска.
Попробуем задуматься над тем, что для нас предпочтительнее, найти в Сети Web-страницу с 20-кратным употреблением в ее тексте слова games (игры) или каталог с таким же именем. Если вас интересуют действующие версии игр, то, видимо, каталог имеет большие перспективы быть полезным. Аналогично и найденный файл unix.html имеет гораздо больше шансов оказаться учебником по операционной системе Unix, чем документ с произвольным названием, в теле которого, пусть даже многократно, встречается то же ключевое слово.
Не секрет, что многие Web-мастера задают систему имен узла, делая ее полезной прежде всего для себя самих, а не для посетителей- отсюда в названиях непонятные цифры, сокращения и т.п. В этом отношении проблема разгадывания имен, предназначенных для "внутреннего пользования" нетривиальна и может показаться надуманной. Однако иногда начальных сведений о русурсе и данных о характере его традиционного представления в Сети бывает достаточно для эффективной работы с именами и в этом случае.
Подбор возможных элементов адреса путем перебора допустимых терминов, их сокращений и вариантов написания может успешно конкурировать с другими приемами поиска. На практике широко применяется поиск ресурсов на основе самого стабильного элемента URL - доменного имени сервера.
Доменные имена: реалии Сети
В первые годы становления Паутины доменное имя Web-сервера нередко отождествлялось с именем компании-провайдера, а основную смысловую нагрузку в адресной схеме URL несли названия подкаталогов, поскольку именно они были связаны с реальными поставщиками информации, арендующими дисковое пространство. В сегодняшней Сети стала обычной практика, когда даже не очень крупная компания может позволить себе содержание персонального сервера. Часто доменное имя нового узла регистрируется разработчиком под определенный проект.
Таким образом, если искомое ключевое слово входит в доменное имя сервера, то вероятность получить исчерпывающие сведения о предмете с такого "специализированного" под ваш интерес узла существенно возрастает.
В Интернете можно отыскать немало простеньких пособий 2-3-летней давности, обучающих тому, как сходу угадать имя нужного сервера на основе минимальных начальных данных. Сегодня эти материалы явно нуждаются в уточнении. Навыки игры в "угадайку" при наличии развитой системы поисковых сервисов могут показаться ненужными, однако это не так по двум причинам. Во-первых, если вам повезет, вы можете установить соединение с сервером, который не зарегистрирован ни в одной ИПС (о том, как происходит регистрация см. КомпьтерПресс N 5). Во-вторых, даже если приходится прибегать к URL-поиску на поисковой машине, то угадывание с самого начала хотя бы некоторых элементов адреса существенно сокращает время решения задачи. Начнем с несколько простых, но важных замечаний.
Односложные имена и домены верхнего уровня
Если компания или коммерческий проект, имеющие в "светской" жизни односложное название, реализуют в Сети свой сервер, то его имя с высокой вероятностью укладывается в формат www.name.com, а для российского сектора Интернета - www.name.ru, где name - имя компании или проекта.
Даже беглое знакомство с Сетью показывает, что в качестве названий фигурируют не только имена собственные (напр., www.disney.com - сервер У. Диснея; www.intel.ru -российский узел компании Intel), которые первоначально могут быть и неизвестны, но и те, которые в обычной языковой практике используются как нарицательные. Если смысловая нагрузка имен очевидна (напр., www.windows95.com - сайт с программами для Windows; www.gazeta.ru - от рус. "газета"), то их легко использовать при поиске.
Проблемы начинаются тогда, когда приходится разыскивать названия, воспринятые на слух. Отдельный случай - использование имен неанглоязычного происхождения, в частности русских, которые в строке URL должны быть прописаны средствами латинского алфавита, однако об этом - чуть ниже.
Тем не менее если даже предположить, что нам удалось верно восстановить "светское" имя проекта, точное попадание на узел вероятно лишь в случае сравнительно коротких имен, как в примерах выше. Длинные же имена, приходящие в Сеть, могут подвергаться сокращению с большой долей произвола, особенно это относится к сравнительно "старым" серверам государственных организаций. Наиболее употребимо сохранение нескольких первых букв имени с конечной согласной (www.mos.ru - мэрия Москвы, www.chel.su от г.Челябинск), затем идут сокращения с выборочным удалением букв из середины слова, чаще гласных (www.chg.ru - от г. Черноголовка; www.tmsk.ru от г. Томск).
Если имя первоисточника многосложное, но одно из слов доминирует по своему весу, то в имени сервера может остаться одна доминанта (узел "Новочеркасск-Он-Лайн" - www.novoch.ru; узел "Чертовы кулички" - www.kulichki.com )
Появление дополнительного домена в имени и отклонение от схемы с наличием элемента "www" делают точное угадывание затруднительным. Примеры - http://hope.nsk.su - узел клуба "Надежда" (от англ. hope) из г. Новосибирска (nsk). В этом случае разумнее обратиться к URL-поиску на ИПС.
Если есть основания полагать, что искомый узел базируется в домене определенного государства или является некоммерческим, то в тех схемах, о которых мы говорили выше, вместо com и ru следует подставить нужный домен. Всегда полезно иметь под рукой полный список доменов верхнего уровня по странам. Он опубликован на многих серверах Сети, один из адресов -http://www.uninett.no/navn/domreg.html
Двусложные и многосложные имена
Полное название организации или проекта, открывающих в Сети свое представительство, может состоять и из нескольких слов, которые находят свое отражение в доменном имени узла или, в более общем случае, в URL ресурса. При этом обычно в имени сервера используется соответствующая аббревиатура. Заметим, что формироваться она может по-разному: из первых букв слов названия, по одной из каждого (www.ndr.ru - от "Наш Дом - Россия"); при участии нескольких первых букв (www.amcyber.com от "American Cybernetics").
Двусложные названия стоят в этом ряду особняком - слов оказывается слишком мало для создания яркой, запоминающейся аббревиатуры. Кроме того свободных двухбуквенных имен в популярных доменах совсем немного.
Как показал недавний скандал с компанией General Motors и ее сервером www.gm.com, экономия на длине имени может слишком дорого обойтись солидной организации. Когда стороний разработчик зарегистрировал узел сомнительного содержания под именем www.general-motors.com, ему удалось добиться внушительной популярности сайта на волне ошибочных посещений, а авторитет крупной компании был подорван. Естественно, что двусложные имена сегодня стали часто встречаться без сокращений. Наиболее употребимы такие варианты как слияние двух слов в одно (www.webcrawler.com - от Web Crawler), а также написание их через дефис (www.biblio-globus.ru от Библио Глобус). Другие разделители встречаются гораздо реже. Применяются также и частичные аббревиатуры (www.cpress.com от КомпьютерПресс), и распределение имен по разным доменам (http://altavista.digital.com).
Именной сленг
Применение сленга всегда связано со стремлением к более яркой, живой лексике, однако есть и обратная сторона медали - сленг понятен не всем.
Одним из проявлений, которое следует отнести к сленгу, является присутсвие в Сети большого количества серверов, имена которых неадекватны содержимому узла, но звучат ярко и метафорично (напр., портал www.stars.ru. - от англ. stars - звезды с отнюдь не астрономической тематикой). Ставка разработчика на то, что оригинальность имени облегчит продвижение сайта и увеличит его видимость в Сети вполне понятна, однако URL-поиск таких узлов на ИПС может оказаться бесполезным. Скажем, если вы разыскиваете сетевой книжный (англ. book) магазин (shop, store), то один из вариантов запроса может иметь вид url:(book and shop), где для определенности использован синтакис команд расширенного поиска AltaVista.
При этом узел "Мистраль" (www.mistral.ru от англ. mistral - холодный сев. ветер на юге Франции), довольно известный подборкой компьютерной литературы, наверняка не попадет в поле вашего зрения. В этом проявляется ограниченность URL-поиска в чистом виде.
Часто в доменных именах наряду с буквами появляются и цифры (узел Тысяча мегагерц - www.1000Mhz.ru ). Речь здесь, разумеется не идет об IP- адресах, хотя цифровой состав последних вполне можно использовать при URL -поиске. Некоторые находки авторов оказываются трудно предсказуемыми. Так, цифрой 4 могут заменяться предлоги за и для (от англ. 4 - four, звучащего так же как и предлог for со значением за, для) в сочетаниях типа 4free (за бесплатно) и 4you (для вас). Цифра 2 применяется как эквивалент предлага to также из-за совпадения звучания (от 2 - two, произносимого как предлог to - в, к, по направлению), например, в сочетаниях типа death2life (c англ., от смерти к жизни). Иногда эту цифру можно встретить не в доменном имени узла, а в конечном файле - программе преобразования одного формата данных в другой (напр., bmp2gif.exe - от bmp к gif).
Известный сервер программного обеспечения "Two Cows" ("Две коровы") использует "ошибочное" (т.е. tu вместо two) написание своего имени - www.tucows.com (рис. 3).
Рис.3. Web-сайт "Two Cows" c "орфографической ошибкой" в доменном имени.
Имя почтового ящика популярной телепрограммы канала НТВ "Сегоднячко" имеет вид todayko (от англ. today - сегодня, плюс непереведенный русский уменьшительный суффикс ko). Один из серверов г. Магнитогорска называется www.magnitka.ru (от сленгового Магнитка) и т.п. Для таких ситуаций поисковый прием подсказывается сам собой- следует использовать в запросах те фрагменты слов, которые с малой вероятностью подверженны искажениям. Для примеров выше это cow, today и magnit.
Имена собственные. Русско-английская транслитерация.
Практика показывает, что большинство деловых поисковых задач в Интернете в той или иной степени связано с поиском имен собственных - названий компаний и организаций, всевозможных стандартов, оборудования и т.п. Любимые стихи и биографию эстрадной звезды также проще отыскать по личным именам. Во многих поисковых ситуациях, которые, казалось бы, не имеют прямого отношения к именам собственным, привлечение последних обеспечивает наибольшую результативность. Например, если вы решили разыскать в Сети фотодокументы, имеющие отношение к кометам и в целом к космической тематике, то применение термина NASA (аббревиатура Американского Национального Управление по Аэронавтике) как одного из элементов запроса, не только облегчит задачу, но и даст некоторые гарантии достоверности информации.
Многие наименования имеют национальное происхождение и появляются в тексте документа в оригинальном написании - с использованием символов соответствующих алфавитов - немецкого, французского, японского и др. Если такое имя попадает в URL ресурса, то разработчик вынужден прописать его средствами латинской графики. Сама по себе проблема транслитерации, т. е. точной передачи букв или сочетаний букв одного языка средствами алфавита другого языка, не нова. Трудно добиться взаимной однозначности такого перевода в прямом и обратном направлениях без разработки жестких стандартов. В мире хорошо известны ИСО (www.iso.ch)- стандарты по транслитерации языков всех континентов из одной графики в другую, которыми широко пользуются в алфавитных каталогах иностранной литературы. Однако имена в Интернете дают не специалисты библиотечного дела. Это и приводит к стихийному размыванию стандартов и появлению реальных проблем при поиске.
Если говорить о русских наименованиях в Сети, присутствующих в URL ресурсов, то от стандарта ISO-9-1986 -(E)/ISO/TC 46 по транслитерации знаков славянской кириллицы знаками латинского алфавита наблюдаются заметные отклонения. Существование нескольких русских кодировок типа translit для обмена почтовыми сообщениями, англоязычное происхождение самого Интернета, а также доминирование в образовательной системе России английского языка над другими определяют тенденции таких отклонений. В таблице 1 мы приводим обобщенную русско-латинскую систему транслитерации, фактически тяготеющую к русско-английской. Она составлена на основе анализа большого количества имен российской части Интернета и нескольких распространенных в Сети схем транслитерации.
| Буква или сочетание (рус.) | Варианты транслитерации (лат.) |
|---|---|
| а | a |
| б | b |
| в | v, w |
| г | g, h, gu |
| гв | gv, gw, gu |
| гз | gz, x |
| д | d |
| дж | dzh, j, g |
| е | e, ye, je, ie |
| ё | e, yo, io, ye, ie, jo,je |
| ж | zh, g, j |
| з | z, s |
| и | i, y |
| ия | ia, iya, ija |
| й | y, i |
| ий, ый | на конце слов y, iy, i, ii |
| к | k, c, ch |
| кс | ks, x |
| кв | kv, kw, qu |
| л | l, ll |
| м | m |
| н | n |
| о | o |
| п | p, pp |
| р | r , rr |
| с | s, c, ss |
| т | t, th |
| у | u |
| ф | f, ph |
| х | kh, h |
| ц | ts, tz |
| ч | ch |
| ш | sh, ch |
| щ | shch |
| ь | опуска-ется, "'" |
| ъ | опуска-ется, "'" |
| ы | y, i |
| э | e |
| ю | yu, u, ju, iu |
| я | ya, ia, a |
Таблица 1. Обобщенная система русско-латинской транслитерации, ориентированная на решение поисковых задач.
Особое внимание читателя обращаем на то, что наиболее вероятные варианты транслитерации приведены для каждой буквы или сочетания в числе первых, после чего следуют менее употребительные. Здесь было бы уместно обсудить несколько важных моментов, которые не слишком внятно отражены в таблице. Многозначность транслитерации при отсутствии признанного стандарта неизбежна. Так, русская буква в заменяется , как правило, литерой v (www.vladivostok.com от г. Владивосток), тогда как w встречается гораздо реже (www.rdw.ru. - от названия газеты Работа для вас).
Отдельно следует отметить случай употребления русских наименований, звучание или транслитерация которых близки или совпадают с англоязычным эквивалентом. Они создают некоторые проблемы при поиске узла. Например, русскоязычный сервер Кавказские Минеральные Воды, казалось бы, должен иметь имя www.kmv.ru, однако реальный адрес другой - www.cmw.ru - от англ. Caucasian Mineral Water; аналогично для сервера Альфа-Капитал -www.acapital.ru - от английского сapital, а не от русского кapital.
Очевидно, что таблицу транслитерации, ориентированную на реальные поисковые задачи, следует расширить не только соответствиями - в - v,w; к - k, c; но рядом других (см. табл.1.)
Тем не менее не все возможные варианты оказались учтены, поскольку нет смысла еще больше размывать систему транслитерации случаями, связанными c факторами чисто английского языкового происхождения. Если вам, скажем, понадобилась, компания известная под именем Мун, то имя узла www.mun.com вполне может оказаться неверным, если первоисточник подразумевал английское Moon (луна) со своим специфическим написанием. Варианты типа у-oo не включались в таблицу. В подобных ситуациях, требующих хорошего знания иностранного языка как такового и его звуко-графических соответствий, целесообразно прибегать к так называемым словарям "плохого произношения". В них обычно приводится все многообразие графических вариантов проблемно звучащей лексики.
На сегодня можно считать почти состоявшейся замену ранее активно используемой "пронемецкой" литеры j для передачи русских гласных (у - ju, ё -jo, я - ja,и реже е - je ) на "более английский" вариант - литеру y (yu, yo, ya, реже ye).
Русская буква е обычно заменяется латинской e, особенно после согласных (www.perm.ru - от г. Пермь). После гласной встречается как литера e (www.krylatskoe.msk.ru - от Крылатское), так и сочетание ye (Krylatskoye).
Букву й в середине слова чаще заменяет литера i (Doinov - фамилия Дойнов, далее сокр. ф.), а в конце слов после гласной - y ( Rushchay - ф. Рущай). Сочетания -ий и -ый на конце слов чаще передаются единственной буквой y (www.primorsky.ru - от Приморский край), но есть и другие варианты (www.mari.su - от республики Марий Эл). Для буквы я применяется также несколько способов ее передачи: ya - обычно появляется после согласной или в начале слова (www.bryansk.ru -от г. Брянск; www.yaroslavl.su - от г. Ярославль, но и www.krasnoyarsk.ru от г. Красноярск), a чаще встречается после гласной, особенно после i на конце слов (www.karelia.ru - от респ. Карелия)
Что касается мягкого и твердого знаков, то в URL они обычно никак не передаются (www.citynet.kharkov.ua - от г. Харьков), хотя в поле текста Web-страницы можно столкнуться с использованием апострофа (Solov'ev - ф. Соловьев ). Наконец, русская ы наиболее часто передается с помощью y (www.syzran.ru от Сызрань), i используется для этого гораздо реже.
Русские доменные имена
Отечественные разработчики активно эксплуатируют английскую и русскую лексику, давая имена Web-узлам. Если вы решили почерпнуть из Сети материалы по изучению английского языка, то пробный заход на www.language.ru (от англ. language - язык) оказался бы результативным.
Адрес сервера, связанного с языковым образованием, вряд ли мог иметь вид www.yazyk.ru - это выглядело бы скорее забавно, чем привлекательно.
Однако компании, реализующей на российском рынке сахар, которая открывает в Сети свой узел, есть над чем подумать - сервер с именем www.sakhar.ru (или www.sahar.ru) может оказаться чуть более видимым для потенциального клиента, чем www.sugar.ru (от англ. sugar - сахар).
Сайт телепрограммы Моя семья, претендующий на самую широкую российскую аудиторию вполне резонно именует себя www.moya-semya.ru, а не www.my-family.ru (c англ. my family - моя семья). Тем не менее понятно, что, даже ориентируясь на "прогрессивную" поблику, в некоторых случаях приходится отдавать дань традициям политической и культурной жизни государства. Например, большинство политических образований и движений России предпочитает поддерживать в качестве основных узлы в домене ru с соответствующими русскими названиями (напр. www.yabloko.ru - объединение "Яблоко").
Некоторые транслитерированные наименования едва заметно отличаются от английских эквивалентов, напр. literature (англ.) и literatura (рус.), что также требует аккуратного обращения.
В заключение отметим, что одной из целей этой статьи было привлечь внимание читателя к возможностям URL-поиска в Web-пространстве. Найденный узел или каталог - это почти всегда более емкое, чем единичный документ, собрание материалов. Особое предпочтение здесь следует отдать тем поисковым системам, которые позволяют комбинировать URL-запросы с внутритекстовым поиском, а также выборочно работать с фрагментами адреса - доменным именем узла, доменом верхнего уровня, именами каталогов и файлов. Другой важный аспект работы в Сети -это корректное применение имен собственных, которые способны стать опорными ключевыми словами для широко спектра поисковых задач и обеспечить высокую результативность поиска.