Конфигурирование сервера Oracle для сверхбольших баз данных
Carry V. Millsap, Oracle Corporation21 августа, 1996
4 Журнальные файлы
Сервер Oracle использует выделенный процесс, называемый (писателем журнальных файлов redo log writer, LGWR) для записи пакетов записей о транзакциях на диск. Работа LGWR позволяет серверу Oracle записывать подтвержденные измененные блоки на диск асинхронно по отношению к пользовательским запросам на подтверждение транзакций и поддерживать при этом целостность данных даже если сервер прервет свою работу в самый неподходящий момент. Выделенный фоновый процесс для последовательного упорядочивания и пакетной записи векторов изменений на диск — это основа высочайшей производительности сервера Oracle.Производительность процесса LGWR является критической для скорости работы OLTP-систем и процедур загрузки данных которые не используют возможность работы в режиме «без восстановления» (unrecoverable). В средах, где не выполняются интенсивные изменения в базе данных с помощью стандартных операторов SQL, LGWR не испытывает значительной нагрузки. Деградация производительности и/или увеличение времени простоя будут наблюдаться главным образом в высокоинтенсивных OLTP-системах; именно поэтому задача конфигурирования журнальных файлов является темой этого раздела.
4.1 Баланс производительности и доступности
Борьба между производительностью и надежностью особенно ярко проявляется на примере журнальных файлов. Для оптимизации производительности Вам необходимо конфигурировать LGWR и DBWR так, чтобы операции записи выполнялись как можно реже. Однако для минимизации времени, необходимого для выполнения доката данных (roll-forward) при восстановлении инстанции, Вам необходимо конфигурировать LGWR и DBWR так, чтобы операции записи производились как можно чаще. Решение этой проблемы заключается в достаточном понимании технологий для того, чтобы выбрать значение параметра log_checkpoint_interval, которое было бы и достаточно большим и достаточно малым для удовлетворения обоих требований.Понимание технологий, относящихся к конфигурированию журнальных файлов, лежит в осознании двух ключевых событий: контрольной точки сервера Oracle и восстановление инстанции сервера Oracle.
4.2 Контрольные точки сервера Oracle
Контрольная точка сервера Oracle — это событие, которое начинается в момент, когда LGWR оповещает DBWR о необходимости записи всех модифицированных блоков из кэша данных СУБД, включая как подтвержденные, так и не подтвержденные данные, в файлы данных [8, Concepts (1992), 23, 9-12]. Контрольные точки вызывают непродолжительные периоды высокой загрузки системы — эффект, который администратор базы данных стремится минимизировать с помощью настроек [7, Admin (1992), 24, 6-7]. Обычные контрольные точки, возникающие в процессе работы, появляется в следующих случаях:- Переключение журнального файла (log switch) — когда LGWR заполняет текущий журнальный файл и пытается переключиться на следующий в круговой очереди.
- Предопределенный интервал — LGWR будет порождать контрольную точку либо когда запишет число блоков операционной системы равное значению параметра log_checkpoint_interval, с момента последней контрольной точки, либо когда пройдет число секунд равное значению параметра log_checkpoint_timeout, с момента последней контрольной точки.
Размер журнального файла и параметры log_checkpoint_interval и log_checkpoint_timeout оказывают наиболее важное влияние на изменение производительности при обычной работе механизма контрольных точек. Многие администраторы БД отключают тайм-аут, устанавливая его в ноль и регулируют работу механизма контрольных точек только с помощью параметра log_checkpoint_interval. Некоторые администраторы деактивируют оба параметра и контрольные точки возникают лишь вследствие переключения журнальных файлов.
4.3 Восстановление инстанции сервера Oracle
Длительность времени, необходимая для выполнения восстановления инстанции сервера Oracle является важным параметром для архитектора VLDB, поскольку она определяет период, в течение которого приложение будет недоступно после возникновения следующих событий:- Отказ узла без кластера — отказ процессора, шины или памяти на незащищенном с помощью кластера узле.
- Отказ узла параллельного сервера Oracle — отказ одного или нескольких узлов в конфигурации с параллельным сервером Oracle будет причиной кратковременной недоступности всего кластера, которая оканчивается к моменту, когда «выжившие» узлы завершат восстановление нитей отказавших узлов.
Реализация отложенного, «по требованию», отката в Oracle 7.3 делает период недоступности кластера зависящим, в основном, от времени которое необходимо для реконструкции буферного кэша. Диаграмма, сравнивающая время восстановления после отказа в Oracle 7.3 и Oracle 7.2, приведена на рисунке 2.
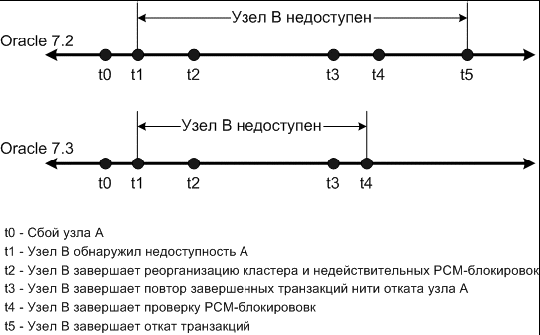
Рис. 2. Временная диаграмма восстановления после отказа для параллельного сервера Oracle 7.2 и 7.3. OPS 7.3 откладывает откат транзакций для минимизации периода недоступности кластера при отказе узла, что дает улучшение производительности восстановления по сравнению с OPS 7.2 или ниже. В OPS 7.3 время завершения отката инстанции не связано с доступностью приложений, поскольку все откаты запускаются «по требованию», на уровне транзакций.
Восстановление инстанции сервера Oracle — настраиваемый процесс, время выполнения которого, в основном, зависит от двух факторов [3, Maulik and Patkar (1995)]:
- Объем повторно-применяемой информации (redo-информации), которая была сгенерирована с момента последней контрольной точки (чем меньше, тем лучше), и
- Качество буферного кэша базы данных в течение выполнения восстановления (чем выше, тем лучше).
На первый фактор, в основном, влияет скорость генерации redo-информации и частота выполнения контрольных точек. Уменьшение объема генерируемой redo-информации является задачей разработчика приложения и связано с минимизацией «веса» транзакций, минимизацией числа транзакций, необходимых для достижения требований бизнеса и использованием там, где это допустимо, режима работы без восстановления. Уменьшение частоты выполнения контрольных точек достигается изменением параметра, определяющего интервал между контрольным точками или, возможно, увеличением размера журнального файла.
Улучшения, относящиеся ко второму фактору, Вы можете достичь с помощью увеличения размера буферного кэша базы данных и уменьшения, тем самым, вероятности промахов в буферном кэше в течение выполнения процедуры восстановления. Увеличение значение параметра db_block_buffers для работы процесса восстановления (ценой уменьшения значения параметра shared_pool_size, если необходимо) в общем, уменьшает число промахов в буферном кэше. В течение процедуры восстановления, при котором не требуется выполнения восстановления носителя, Вы не имеете других способов влиять на процент попаданий в буферный кэш, поскольку должна быть повторно применена вся информация, которая была сгенерирована с момента последней контрольной точки 11.
Меняя параметр log_checkpoint_interval в диапазоне от нескольких килобайт до нескольких сотен мегабайт (в блоках операционной системы) можно достичь приемлемого компромисса с производительностью в OLTP-среде. Скорость доката при восстановлении варьируется почти также как кардинально, как и требования к скорости доката 12. В средах с жестко заданными требованиями к производительности и надежности малое изменение log_checkpoint_interval может привести к значительному изменению времени восстановления инстанции. Вследствие этого поиск оптимального значения log_checkpoint_interval часто требует тестирования в среде эксплуатации.
4.4 Размещение журнальных файлов
В хорошей конфигурации VLDB высокоактивные, с точки зрения ввода/вывода, журнальные файлы должны быть изолированы от других файлов с высокой активностью ввода/вывода настолько, насколько это возможно. Физическая изоляция на выделенных дисках и контроллерах позволит Вам снизить до минимума шанс возникновения «узкого места» при выполнении операций ввода/вывода в журнальные файлы.Техника изолирования хорошо комбинируется с рассмотренным ранее желанием размещать журнальные файлы на дисковом массиве с малым размером сегмента чередования доступ к которому наиболее эффективен при работе однопоточного (с очень низким уровнем параллелизма) процесса.
В дополнение к отделению журнальных файлов от других файлов, фактически Вам необходимо физически отделить журнальные файлы друг от друга. В то время как LGWR-процесс пишет в журнальный файл с максимально возможной скоростью, процесс ARCH читает журнальный файл с максимально возможной скоростью (в любой момент времени он может читать один из журнальных файлов, кроме того, который открыт LGWR).
Одновременно ARCH пишет с максимально возможной скоростью в один архивный журнальный файл. Использование чередования с малым размером сегмента может свести к минимуму конкуренцию между LGWR и ARCH. Сервер Oracle позволяет, если Вы этого желаете, архивировать журнальные файлы непосредственно на ленточное устройство. Имеется несколько причин, из-за которых администраторы VLDB почти всегда выполняют архивирование на диск и лишь потом делают n копий файлов на ленточный накопитель.
- Надежность лучше — ленточный накопи тель существенно менее надежен, чем диск. Оставлять лишь одну копию критически важного файла на ленточном носителе является не очень хорошим решением.
- Пропускная способность лучше — вы должны помнить, что ARCH-процесс не является чисто потоковым процессом копирования, но выполняется лучше на устройствах с возможностью произвольного доступа (random I/O). Архивирование на диск выполняется намного быстрее чем на ленточный накопитель, что в свою очередь снижает вероятность возникновения ненужного «узкого места».
- Управление ошибками лучшее — управление дисковыми устройствами, при переполнении, много надежней, чем ленточными устройствами. Управление пространством для дисков может быть автоматизировано с помощью программного обеспечения, в то время как для ленточных устройств требуется вмешательство человека.
- Время восстановления быстрее — многие администраторы БД хранят максимально возможное число архивных журнальных файлов на дисках, которые могут быть необходимы для восстановления с момента последнего «горячего» копирования. Такая техника уменьшает продолжительность процесса восстановления на время необходимое для нахождения требуемой ленты, ее монтирования и чтения с нее архивных журнальных файлов на диск.
4.5 Размер журнального файла
Оптимальный размер журнального файла в системе зависит от объема генерируемой redoинформации и требований к продолжительности восстановления инстанции. Для расчета правильного интервала между контрольными точками и размера журнального файла для Вашей системы используйте следующий метод:- Определите требования к времени восстановления после краха. Обозначим это время, заданное в секундах, как t.
- Рассчитайте скорость, с которой система применяет redo-информацию при восстановлении инстанции. Обозначим эту скорость, заданную в байтах в секунду, как r.
- Установите значение параметра log_checkpoint_interval в r × t/b, где b — размер блока ввода/вывода в байтах в Вашей операционной системе.
- Создайте журнальные файлы размером f = k × r × t, для некоторого целого k (т.е. f кратно r × t).
- Если новые контрольные точки накапливаются без завершения предыдущих, то Вы должны увеличить значение log_checkpoint_interval. Вы можете определить частоту возникновения таких ситуаций сравнив значения статистик background_checkpoints_started и background_checkpoints_completed из v$sysstat. Если значения отличаются более чем на 1, значит контрольные точки не завершались к тому моменту, когда начинались новые.
- Установите log_buffer в l = 3×n×s, где n — число дисков в массиве, хранящем журнальные файлы и s — размер сегмента чередования массива в байтах. Наибольший размер операции записи, генерируемый LGWR, будет примерно равен l/3 = n × s 13.
Приведенный метод сводит задачу выбора оптимального размера журнальных файлов к задаче правильного выбора множителя k. Факторы, которые будут влиять на выбор большего значения, могут быть следующими:
- снижение частоты переключения журнальных файлов;
- упрощение процедуры размещения журнальных файлов;
- снижение сложности при полном восстановлении за счет снижения числа обрабатываемых файлов;
- снижение частоты возникновения событий ожидания контрольных точек и занятости процесса архивирования.
Факторы, которые будут влиять на выбор меньшего значения, могут быть следующими:
- снижение стоимости отказа, связанной с потерей всех копий активного журнального файла 14;
- улучшение гибкости в предотвращении ситуации переполнения файловой системы, хранящей архивные журнальные файлы;
- снижение потерь данных в конфигурациях с резервной (standby) БД.
Общим правилом при выборе размера журнального файла можно принять пожелание о том, что переключение журнальных файлов не должно происходить чаще, чем два раза в час.
4.6 Число журнальных файлов
Число оперативных журнальных файлов дает Вам возможность определить, будут ли контрольные точки и архивирование журнальных файлов причиной возникновения «узких мест» при обработке транзакций. Выбор правильного числа журнальных файлов поможет Вам снизить:- Ожидания занятой контрольной точки (checkpoint busy wait) — ожидание занятой контрольной точки возникает, когда LGWR пытается переключиться на журнальный файл до того, как связанная с этим журнальным файлом предыдущая контрольная точка была завершена.
- Ожидание занятого процесса архивирования (archiver busy wait) — ожидание занятого процесса архивирования возникает, когда LGWR пытается переключиться на журнальный файл, который еще не было скопирован в архивный журнальный файл процессом ARCH.
Ожидание занятой контрольной точки часто возникало в дни, когда в большинстве инсталляций сервера Oracle использовалось всего два журнальных файла, устанавливаемых по умолчанию при инсталляции. Вы можете использовать следующую процедуру для определения наличия и устранения ожиданий занятой контрольной точки:
- Проверьте событие log file switch (checkpoint incomplete) в v$session_wait. Если Вы установили параметр log_checkpoints_to_alert в значение true, то Вы можете определить возникновение этой ситуации с помощью текстового вхождения «cannot allocate» в файле alert.log.
- Снизить частоту возникновения события
ожидания контрольной точки Вы можете:
- увеличивая число оперативных журнальных файлов для снижения вероятности того, что LGWR сможет заполнить все файлы до того, как будет завершена контрольная точка; или
- добавляя DBWR процессы для увеличения скорости выполнения контрольной точки (только если Вы используете синхронную запись); или
- увеличивая значение параметра db_block_checkpoint_batch для увеличения скорости выполнения контрольной точки; или
- уменьшая значение параметра db_block_buffers для снижения объема работы в контрольной точке; или
- снижая число и размеры сегментов отката в базе данных (описанных в нижеследующем разделе)
Событие ожидания занятого процесса архивирования обычно возникает при генерации большого числа транзакций во время пакетной обработке, когда скорость записи redo-информации LGWR превышают возможности копирования процесса ARCH. Оно также служит причиной возникновения ожидания контрольной точки — ARCH становится «узким местом» для завершения всех транзакций в системе.
Следующие техники могут использоваться для смягчения проблемы:
- Чередование с малым размером сегмента — разместите Ваши архивные журнальные файлы на дисковом массиве с малым размером сегмента чередования для увеличения скорости обращения к файлам процессом ARCH.
- Большее число оперативных журнальных файлов — создайте достаточное число оперативных журнальных файлов с тем, чтобы LGWR не смог заполнить все журнальные файлы до того как процесс ARCH закончил копировать.
- Увеличение числа ARCH-процессов — используйте несколько ARCH-процессов с помощью команды сервера Oracle alter system archive log all to . . . . Консультанты службы поддержки Oracle подготовили несколько инструментов для автоматизации этого процесса.
| Получены важные результаты, относящиеся к восстановлению носителя сервера Oracle, когда повреждены несколько файлов данных. Рекомендуется сделать несколько циклов восстановление-файла/восстановление-инстанции для каждого файла данных. В этом случае может наблюдаться лучшее качество использования буферного кэша базы данных [3, Maulik and Patkar (1995)]. | |
| Администраторы СУБД Oracle дают большой разброс при оценке скорости доката. Я слышал как низкие оценки — 50KB/сек, так и высокие — до 1,750KB/сек. | |
| В OLTP-операциях, частые подтверждения транзакций будут порождать записи LGWR и LGWR будет делать очень много малых записей. В пакетных операциях, нечастые подтверждения транзакций будут порождать большие объемы не записанной в журнальный файл информации, расположенной в журнальном буфере. Если информация будет накапливаться быстрее, чем LGWR будет получать команды для записи, то заполненность буфера более чем на 1/3 будет основанием для начала записи до l байт, где l — размер журнального буфера, заданного с помощью log_buffer. | |
| Вы должны попытаться защитить себя от столь катастрофического события, используя n-кратное дублирование аппаратуры для хранения журнальных файлов. Если Вы не в состоянии позволить себе дублирование с помощью аппаратного решения, Oracle7 дает возможность введения зеркалирования с помощью программных средств, используя несколько членов журнальных файлов в группе журнальных файлов. |