Расширенная оптимизация подзапросов в Oracle
Срикант Белламконда, Рафи Ахмед, Анжела Амор, Мохамед Зэйд
Перевод Леонида Борчука
Под ред. Сергея Кузнецова
Оригинал: Enhanced Subquery Optimizations in Oracle / Srikanth Bellamkonda, Rafi Ahmed, Andrew Witkowski, Angela Amor, Mohamed Zait, Chun-Chieh Lin // Proceedings of the 35th international conference on Very large data base, 2009, pp. 1366 — 1377
2. Сращивание подзапросов
Сращивание подзапросов (subquaery coalescing) — это метод, при применении которого при определенных условиях два подзапроса могут быть срощены в один подзапрос, что позволяет вместо выполнения нескольких операций сканирования таблиц и соединения ограничиться единственным сканированием таблицы и единственным соединением. Хотя сращивание подзапросов определяется как бинарная операция, она может последовательно применяться к любому числу подзапросов. Сращивание подзапросов оказывается возможным, поскольку подзапрос действует как предикат фильтрации таблиц внешнего запроса.Говорят, что два блока запроса семантически эквивалентны, если они производят одинаковые мультимножественные результаты. Эквивалентность двух блоков запроса может также обосновываться их структурной или синтаксической идентичностью.
Говорят, что блок запроса X включает другой блок запроса Y, если результат Y является подмножеством (не обязательно собственным) результата X. X называется включающим (container) блоком запроса, а Y — включаемым (contained) блоком запроса. Другими словами, X и Y отвечают свойству включения (containment), если Y содержит некоторые конъюнктивные предикаты фильтрации P, и X и Y становятся эквивалентными, если P не влияют на обоснование их эквивалентности.
Включение — это важное свойство, которое позволяет включить поведение обоих подзапросов в срощенный подзапрос. Если для двух конъюнктивных подзапросов нарушается свойство включения, то их предикаты фильтрации невозможно конъюнктивно объединить в одном подзапросе, поскольку этот подзапрос будет возвращать только пересечение результирующих множеств строк исходных подзапросов.
В настоящее время в Oracle выполняются различные типы
сращивания подзапросов, когда два подзапроса с [NOT] EXISTS предстают в
конъюнкции или дизъюнкции. Поскольку подзапросы с ANY и ALL могут быть
преобразованы в подзапросы c EXISTS и NOT EXISTS соответственно, мы не обсуждаем здесь сращивание подзапросов с ANY/ALL. В тривиальном случае наличия двух
подзапросов, которые являются эквивалентными и имеют один и тот же тип (например,
либо EXISTS, либо NOT EXISTS), сращивание подзапросов заключается в
удалении одного из них. Если у эквивалентных подзапросов имеются разные
типы, то сращивание приводит к удалению обоих подзапроса и их замене предикатом
FALSE/TRUE в зависимости от того, соединены ли эти подзапросы конъюнкцией или дизъюнкцией.
2.1. Сращивание подзапросов одинакового типа
Если два конъюнктивных подзапроса с EXISTS или два дизъюнктивных подзапроса с NOT EXISTS
отвечают свойству включения, то они могут быть срощены в один
подзапрос путем сохранения включаемого подзапроса и удаления включающего подзапроса. Для случая дизъюнктивных подзапросов с EXISTS или конъюнктивных подзапросов с NOT EXISTS сращивание может быть выполнено
путем сохранения включающего подзапроса и удаления включаемого подзапроса.
Подзапросы, не отвечающие свойству совместимости,
также могут быть срощены, если они являются почти эквивалентными, не считая наличия некоторого
конъюнктивного фильтра и коррелированных предикатов. Например, два
дизъюнктивных подзапроса с EXISTS, различающихся
конъюнктивными предикатами фильтрации и коррелированными предикатами, но в
остальном эквивалентные, могут быть срощены в один подзапрос с EXISTS, содержащий дизъюнкцию дополнительных (или различающимихся) предикатов исходных подзапросов. Конъюнктивные подзапросы с NOT EXISTS могут быть
срощены аналогичным образом.
Рассмотрим запрос Q2 с двумя дизъюнктивными подзапросами
с EXISTS; подзапросы содержат один и тот же коррелированный предикат, но разные
конъюнктивные предикаты фильтрации:
Q2
SELECT o_orderpriority, COUNT(*)
FROM orders
WHERE o_orderdate >= '1993-07-01' AND
EXISTS (SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey AND
l_returnflag = 'R') OR
EXISTS (SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey AND
l_receipt_date > l_commitdate)
GROUP BY o_orderpriority;
Сращивание подзапросов объединяет два подзапроса с EXISTS в один подзапрос с EXISTS
с дизъюнкцией предикатов фильтрации, что приводит к получению запроса Q3.
Q3
SELECT o_orderpriority, COUNT(*)
FROM orders
WHERE o_orderdate >= '1993-07-01' AND
EXISTS (SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey AND
(l_returnflag = 'R' OR
l_receipt_date > l_commitdate))
GROUP BY o_orderpriority;
2.2. Сращивание подзапросов разных типов
Для сращивание двух конъюнктивных подзапросов, удовлетворяющих свойству включения и имеющих разные типы, требуется применение другого метода. Рассмотрим запрос Q4, который является несколько упрощенным вариантом запроса 21 из TPC-H.
Q4
SELECT s_name
FROM supplier, lineitem L1
WHERE s_suppkey = l_suppkey AND
EXISTS (SELECT *
FROM lineitem L2
WHERE l_orderkey = L1.l_orderkey
AND l_suppkey <> L1.l_suppkey)
AND NOT EXISTS
(SELECT *
FROM lineitem L3
WHERE l_orderkey = L1.l_orderkey AND
l_suppkey <> L1.l_suppkey AND
l_receiptdate > l_commitdate);
Два подзапроса в Q4 отличаются только своими типами и
тем, что в подзапросе с NOT EXISTS имеется дополнительный предикат
фильтрации l_receipt_date > l_commitdate. Сращивание подзапросов
приводит к запросу Q5 с единственным подзапросом с EXISTS, в результате чего устраняется один экземпляр таблицы lineitem.
Q5
SELECT s_name
FROM supplier, lineitem L1
WHERE s_suppkey = l_suppkey AND
EXISTS (SELECT 1
FROM lineitem L2
WHERE l_orderkey = L1.l_orderkey AND
l_suppkey <> L1.l_suppkey)
HAVING SUM(CASE WHEN l_receiptdate >
l_commitdate
THEN 1 ELSE 0 END) = 0);
Агрегатная функция раздела HAVING возвращает общее
количество строк, удовлетворяющих предикату подзапроса. Раздел
HAVING, включенный в срощенный подзапрос,
является новым предикатом фильтрации, который проверяет, удовлетворяет ли
какая-либо строка предикату подзапроса, тем самым имитируя поведение удаленного
подзапроса с NOT EXISTS.
Для каждого набора корреляционных значений подзапросы в Q4 могут находиться в одном из трех состояний:
-
Если подзапрос
EXISTSне возвращает строк (т.е. вычисляется вFALSE), то результатом конъюнкции двух подзапросов являетсяFALSE. В Q5 разделHAVINGприменяется к пустому множеству, и срощенный подзапрос сEXISTSтакже вычисляется вFALSE. -
Если подзапрос с
EXISTSвозвращает несколько строк (т.е. вычисляется вTRUE), и подзапросNOT EXISTSтоже возвращает несколько строк (т.е. вычисляется вFALSE), то результатом конъюнкции двух подзапросов являетсяFALSE. В Q5 разделHAVINGприменяется к непустому множеству строк, для которыхl_receiptdate > l_commitdate, и потому вычисляется вFALSE; таким образом, срощенный подзапрос вычисляется вFALSE. -
Если подзапрос с
EXISTSвозвращает несколько строк, а подзапрос сNOT EXISTSне возвращает строк из-за дополнительных предикатов фильтрации, то результатом конъюнкции двух подзапросов являетсяTRUE. В Q5 разделHAVINGприменяется к непустому множеству строк, для которых неверно, чтоl_receiptdate > l_commitdate, и потому вычисляется вTRUE; таким образом, срощенный подзапрос вычисляется вTRUE.
Приведенное обсуждение обосновывает эквивалентность запросов Q4 и Q5.
В том случае, когда подзапрос с NOT EXISTS является включающим запросом, а
конъюнктивный подзапрос с EXISTS – включаемым запросом, сращивание состоит в удалении обоих подзапросов и замене их предикатом FALSE. Условия,
при наличии которых подзапрос с EXISTS возвращает несколько строк
(т.е. вычисляется в TRUE), гарантируют, что подзапрос с NOT EXISTS
также вернет несколько строк (т.е. будет вычислен в FALSE). В том случае,
когда подзапрос с NOT EXISTS не возвращает строк,
подзапрос с EXISTS также не вернет строк.
Следовательно, результатом конъюнкции двух подзапросов всегда будет FALSE.
Аналогичная аргументация может быть произведена, и
аналогичное сращивание может
быть выполнено в том случае, когда имеется дизъюнкции подзапросов с EXISTS и NOT EXISTS, и удовлетворяется свойство включения.
2.3. Сращивание и другие преобразования
В [8] мы обсуждали, как различные преобразования взаимодействуют друг с другом, и как инфраструктура преобразований, основанных на оценке стоимости, управляет возможными взаимодействиями. Сращивание подзапросов не является исключением, так как срощенный подзапрос стать предметом других преобразований. Подзапрос из Q5 может быть подвергнут преобразованию устранения вложенности, что приведет к запросу Q6, который содержит встроенное представление (производную таблицу) V:
Q6
SELECT s_name
FROM supplier, lineitem L1,
(SELECT LX.rowid xrowid
FROM lineitem L2, lineitem LX
WHERE L2.l_orderkey = LX.l_orderkey AND
L2.l_suppkey <> LX.l_suppkey
GROUP BY LX.rowid
HAVING SUM(CASE WHEN L2.l_receiptdate >
L2.l_commitdate
THEN 1 ELSE 0 END) = 0) V
WHERE s_suppkey = L1.l_suppkey AND
L1.rowid = V.xrowid;
После слияния представления из Q6 получается запрос Q7, в котором таблица LX оказывается избыточной, так как в слитом блоке
запроса LX и L1 соединяются по столбцу rowid, обладающему свойством уникальности. Поэтому LX
удаляется, а все ссылки на нее заменяются ссылками на L1.
Q7
SELECT s_name
FROM supplier S, lineitem L1, lineitem L2
WHERE s_suppkey = L1.l_suppkey AND
L1.l_orderkey = L2.l_orderkey
GROUP BY L1.rowid, S.rowid, S.s_name
HAVING SUM(CASE WHEN L2.l_receiptdate >
L2.l_commitdate
THEN 1 ELSE 0 END) = 0);
Здесь мы имеем уже, как минимум, четыре альтернативных формулировки запроса. В большинстве случаев неясно, какая из четырех альтернатив является оптимальным выбором. Для поддержки принятия решения может быть использована инфраструктура преобразований Oracle, основанных на оценке стоимости, которая обсуждалась в подразделе 1.1.
2.4. Расширение возможностей выполнения запросов
В запросе Q7 предикат раздела HAVING отфильтровывает
группы, имеющие, по крайней мере, одну запись с датой прихода (receipt date),
большей даты завершения (commit date).
Неудовлетворение этого и других предикатов, таких как MIN(l_receiptdate) > '18-FEB-2001', COUNT(*) <= 10, SUM(amount_sold) < 20002, немедленно делает группу
неприемлемой (т.е. исключают ее из кандидатов в результирующий набор данных), и такие предикаты могут быть вытолкнуты в раздел GROUP BY для ускорения процесса агрегирования
этой группы. Это приводит к эффективному выполнению.
Например, в Q7 входная запись с l_receiptdate > l_commitdate делает равным единице
значение агрегата SUM для соответствующей группы, исключая, таким образом, группу из списка кандидатов.
Аналогично, если в качестве предиката используется SUM(amount_sold) < 2000, и в базе данных имеется ограничение, указывающее, что значение amount_sold должно быть положительным, то группа
исключается из списка кандидатов, как только значение SUM для нее превысит 2000. Раздел GROUP BY в подобных случаях позволяет не производить агрегацию для групп, исключенных из списка кандидатов.
Использование таких предикатов также приносит пользу при выполнении параллельной группировки,
снижая трафик передачи данных. В Oracle применяется метод параллельного проталкивания группировки (group-by pushdown, GPD) на основе оценки стоимости, который проталкивает выполнение группировки в процессы, производящие данные (подчиненные процессы-производители, producer slave), с целью сокращения коммуникационных расходов и повышения уровня масштабируемости группировки.
Процессы, производящие данные, распределяет локально агрегированные данные между другими процессами (подчиненными
процессами-потребители, consumer slave) на основе хеширования или диапазонов значений ключей группировки. Затем
подчиненные процессы-потребители завершают выполнение
группировки и производят результаты. План
параллельного выполнения запроса Q7 с GPD представлен на рис. 1. Сокращение трафика достигается, если подчиненные процессы-производители P1, ..., PN во время выполнения группировки
отфильтровывают группы, основываясь на предикатах раздела HAVING.
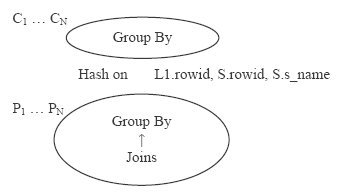
Рис.1. Проталкивание в параллельной группировке
Аналогичным образом, предикаты, удовлетворение которых приводит к немедленному включению групп
в список кандидатов в результирующий набор данных, также могут быть вытолкнуты
в обработку группировки. Обработку
агрегации групп, не входящих в результирующий набор, можно пропустить, как
только найдется группа, являющаяся кандидатом. Примеры таких предикатов: MIN(l_receiptdate) < '18-FEB-2001', COUNT(*) > 10,
SUM(amount_sold) > 2000, если известно, что
amount_sold положительно.
3. Исключение представлений с группировкой
В этом разделе мы обсудим метод преобразования, называемый исключением фильтрующей таблицы (filtering table elimination) и основанный на идее фильтрующих соединений. Фильтрующее соединение (filtering join) — это либо полусоединение, либо внутреннее эквисоединение, в котором один из столбцов соединения обладает свойством уникальности.
Здесь мы будем обозначать столбец, обладающий свойством уникальности, подчеркивая его имя, а для эквиполусоединения будем использовать нестандартную нотацию 0=. Пусть R — это некоторая таблица, а T1 и T2 — два экземпляра одной и той же базовой или производной таблицы T. В T1 и T2 либо имеется один и тот же набор предикатов фильтрации (если они вообще присутствуют), либо предикаты фильтрации T1 являются более ограничительными, чем предикаты фильтрации T2. В следующих случаях T2 и фильтрующее соединение могут быть исключены:
R.X = T1.Y and R.X = T2.Y ≡ R.X = T1.Y R.X = T1.Y and R.X 0= T2.Y ≡ R.X = T1.Y R.X 0= T1.Y and R.X 0= T2.Y ≡ R.X 0= T1.Y
Предположим, что первым выполняется
нефильтрующее соединение, если таковое имеется. В таком случае фильтрующее соединение сохраняет все результирующие строки R, поскольку
фильтрующее соединение может только отфильтровать строки R
в отличие от внутреннего соединения, которое
может как отфильтровать, так и продублировать строки. В фильтрующем
соединении таблица T2 оказывается избыточной, и поэтому она может быть
удалена. Хотя этот
метод очень похож на
сращивание конъюнктивных подзапросов с EXISTS, далее мы представим другое его применение.
3.1. Исключение представлений
Рассмотрим запрос Q8, являющийся упрощенным вариантом запроса 18 тестового набора TPC-H.
Q8
SELECT o_orderkey, c_custkey, SUM(l_quantity)
FROM orders, lineitem L1, customers
WHERE o_orderkey = l_orderkey AND
c_custkey = o_custkey AND
o_orderkey IN
(SELECT l_orderkey
FROM lineitem L2
GROUP BY l_orderkey
HAVING SUM(l_quantity) > 30)
GROUP BY o_orderkey, c_custkey;
Подзапрос Q8 подвергается преобразованию устранения вложенности, что приводит к порождению запроса Q9. К встроенному представлению (производной таблице) V2, появившемуся в в Q9 из-за устранения вложенности, не требуется применять полусоединение, так как здесь имеется эквисоединение, и столбцы соединения V2 обладают свойством уникальности, поскольку являются единственными столбцами группировки в V2.
Q9
SELECT o_orderkey, c_custkey, SUM(l_quantity)
FROM orders, lineitem L1, customers,
(SELECT l_orderkey
FROM lineitem L2
GROUP BY l_orderkey
HAVING SUM(l_quantity) > 30) V2
WHERE o_orderkey = V2.l_orderkey AND
o_orderkey = L1.l_orderkey AND
c_custkey = o_custkey
GROUP BY o_orderkey, c_custkey;
Как показывает запрос Q10, с использованием перестановки группировки и соединения (т.е. размещения группировки, group-by placement) [5], [6], [8] можно получить еще одно представление V1, содержащее таблицу
L1; в список выборки раздела SELECT представления V2 добавляется
SUM(l_quantity), что не изменяет семантику Q9.
Q10
SELECT o_orderkey, c_custkey, SUM(V1.qty)
FROM orders, customers,
(SELECT l_orderkey, SUM(l_quantity) qty
FROM lineitem L2
GROUP BY l_orderkey
HAVING SUM(l_quantity) > 30) V2,
(SELECT l_orderkey, SUM(l_quantity) qty
FROM lineitem L1
GROUP BY l_orderkey) V1
WHERE o_orderkey = V2.l_orderkey AND
o_orderkey = V1.l_orderkey AND
c_custkey = o_custkey
GROUP BY o_orderkey, c_custkey;
Как можно видеть, V1 и V2 — это разные экземпляры одного
и того же представления, за исключением того, что предикаты фильтрации в V2 являются
более ограничительными, чем в V1, из-за наличия в V2 раздела HAVING. Кроме того,
эквисоединения V1 и V2 с таблицей
orders производятся по столбцу o_orderkey, обладающему свойством уникальности, так как это единственный столбец группировки в этих представлениях; таким образом, эти два соединения являются фильтрующими соединениями. Следовательно, представление
V1 можно исключить, а ссылки на V1 можно заменить ссылками на V2.
Исключение фильтрующего представления из Q10 приводит к запросу Q11.
Q11
SELECT o_orderkey, c_custkey, SUM(V2.qty)
FROM orders, customers,
(SELECT o_orderkey, SUM(l_quantity)
FROM lineitem
GROUP BY l_orderkey
HAVING SUM(l_quantity) > 30) V2
WHERE o_orderkey = V2.l_orderkey AND
c_custkey = o_custkey
GROUP BY o_orderkey, c_custkey;
Если бы представление V2 в запросе Q9 подвергалось слиянию, то могла бы быть приведена другая аргументация использования фильтрующего соединения с тем же результатом исключения таблицы lineitem
из внешнего запроса.
2 Если известно, что amount_sold положительно; например, в случае ограничения целостности базы данных типа RELY