2004 г.
СЖАТИЕ ТАБЛИЦ В СУБД Oracle9i RELEASE 2: АНАЛИЗ ЭФФЕКТИВНОСТИ
Александр Соколов,
Виктор Сусойкин,
компания РДТЕХ
Источник: OracleWorld, San Francisco, California, 10-14 November 2002 (http://www.oracle.com/pls/oow/oow_user.show_public?p_event=13&p_type=session&p_session_id=38383 )
(Table Compression in Oracle9i Release 2: A Performance Analysis, By Meikel Poess, Oracle Corporation)
СодержаниеАнализ эффективности
В данном разделе исследуется влияние сжатых объектов на производительность выполнения запросов. Если данные хранятся в сжатых таблицах, производительность выполнения запросов к ним может существенно возрасти. Как было описано в разделе об экономии пространства, количество блоков, требуемое для хранения данных в сжатых таблицах, может быть существенно меньше чем в несжатых таблицах. Таким образом, запросы к сжатым таблицам читают меньше блоков базы данных, что непосредственно повышает производительность выполнения операций чтения в запросах.
Чтобы показать выгоды от сжатия данных для запросов в схеме типа "звезда", мы будем анализировать производительность выполнения 3 запросов типа "звезда", которые также были получены из пользовательской среды примера, рассмотренного в предыдущем разделе. Чтобы показать выгоды от сжатия данных для запросов в нормализованной схеме, мы будем анализировать запросы эталонного теста TPC-H, используя недавно опубликованные результаты теста "TPC-H 100 GB". Полное описание эталонного теста доступно на сайте TPC (www.tpc.org). Заметим, данные об общем затраченном времени "сжатых" прогонов теста извлекаются из опубликованных результатов эталонного теста TPC-H [1], а данные о "несжатых" прогонах получаются во время выполнения фазы настройки теста. В тесте TPC-H выполняется набор из 22 бизнес-запросов, спроектированных для демонстрации функциональных возможностей системы, в некотором смысле представляющих сложные приложения бизнес-анализа [2]. Обсуждение всех 22 запросов далеко выходит за рамки данной работы. Поэтому мы ограничимся обсуждением запросов 1, 6 и 15.
Примеры запросов типа "звезда"
В запросах к схеме типа "звезда" используется функциональное средство СУБД Oracle для преобразования запросов типа "звезда" (star transformation). Это преобразование является мощным методом оптимизации запросов типа "звезда", основанном на неявном переписывании исходного текста запроса. Оптимизатор по стоимости СУБД Oracle выбирает преобразование запросов типа "звезда", когда это целесообразно. Преобразование осуществляется с целью эффективного выполнения запросов. СУБД Oracle обрабатывает такие запросы, используя три фазы. Во время первой фазы Oracle обращается ко всем битовым индексам по измерениям, для которых в запросе заданы предикаты. Затем результирующие битовые вектора объединяется с помощью операций над множествами (AND или OR) в зависимости от логики запроса. В этот шаг входит преобразование окончательного битового вектора в идентификаторы строк. Во время второй фазы с помощью этого набора идентификаторов строк из таблицы фактов извлекаются точно те строки, которые необходимы, и выполняется соединение с первым измерением. Во время третьей фазы этот результирующий набор соединяется с таблицами измерений для извлечения детальных данных, необходимых для завершения запроса. Если базовая схема является схемой типа "снежинка" (snowflake schema), то во время этой фазы также выполняется соединение таблиц измерений. Важно отметить, что конечному пользователю никогда не нужно знать какие-либо детали преобразования запросов типа "звезда".
Запрос типа "звезда" номер 1
Первый запрос вычисляет итоговую сумму продаж конкретных продуктов за конкретные месяцы 1998 и 1999 годов по конкретным округам. Эти результаты группируются по годам, месяцам, типам округов и продуктам. Полный SQL-оператор можно найти в приложении; на рис. 7 показаны план выполнения оператора и время, затраченное на различных шагах процесса выполнения, как для несжатой таблицы фактов DAILY_SALES, так и для сжатой.
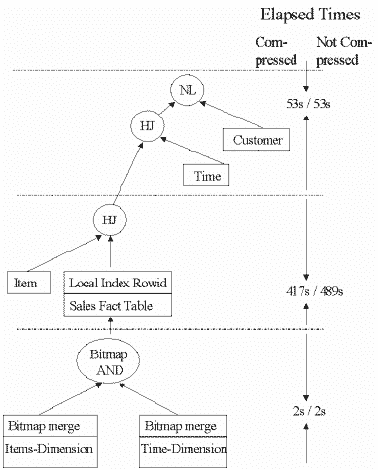
Рис. 7. План выполнения и время, затраченное на различных фазах выполнения запроса типа "звезда" номер 1
Надписи на рисунке:
- Elapsed Times - интервалы общего затраченного времени;
- Compressed - сжатая;
- Not Compressed - несжатая;
- NL - nested loop, соединение типа "вложенный цикл";
- HJ - hash join, хеш-соединение;
- Customer - клиент;
- Time - время;
- Item - продукт;
- Local Index Rowid - идентификатор строки из локального индекса;
- Sales Fact Table - таблица фактов по продажам;
- Bitmap AND - битовая операция AND;
- Bitmap merge - слияние битовых векторов;
- Items-Dimension - измерение Items (продукты);
- Time-Dimension - измерение Time (время) .
Оптимизатор СУБД Oracle распознает, что этот запрос - запроса типа "звезда" и преобразует его так, как это было описано выше. Доступ к таблице фактов осуществляется через путь доступа по битовому индексу, базирующемуся на битовой операции AND двух битовых индексов измерений TIME и ITEM. По этим битовым индексам Oracle может эффективно вычислить все квалифицированные идентификаторы строк таблицы DAILY_SALES. Поскольку в таблице фактов содержатся только ссылки на таблицы измерений, а не на их детальные данные, измерения нужно повторно соединять с таблицей фактов. (Прим. ред. Термин повторное соединение ("join back", "join-back", "joinback") определяется в техническом документе [7] следующим образом: "With the transformed SQL, this query is effectively processed in two main phases. In the first phase, all of the necessary rows are retrieved from the fact table using the bitmap indexes… In the second phase of the query (the 'join-back' phase), the dimension tables are joined back to the data set from the first phase." (После преобразования этого SQL-оператора обработка запроса эффективно разбивается на две основные фазы. Во время первой фазы из таблицы фактов с помощью битовых индексов извлекаются все необходимые строки… Во время второй фазы (фазы "повторного соединения") таблицы измерений повторно соединяются с набором данных, полученным в первой фазе.).) Это делается последующими операциями соединения с таблицами ITEM и TIME. В список выборки включены детальные данные из таблицы CUSTOMER, поэтому нам также нужно выполнить соединение с измерением CUSTOMER. Кроме того, в плане выполнения показано время, затраченное на определенных шагах процесса выполнения для сжатой и несжатой таблицы фактов соответственно.
Запрос типа "звезда" номер 2
Второй запрос вычисляет сумму объемов продаж, проведенных в первые пять месяцев 1998 и 1999 годов для всех клиентов из Чикаго в конкретных регионах продаж. Результирующий набор группируется по фамилиям клиентов, названиям округов, номерам регионов продаж, годам и месяцам. В отличие от запроса 1 в этом запросе используется материализованное представление WEEKLY_SALES в котором содержатся данные о продажах, агрегированные на уровне недель. Этот SQL-оператор можно найти в приложении. План выполнения запроса и время, затраченное на определенные операции, показаны на рис. 8.
Этот запрос также преобразовывается функциональным средством оптимизатора СУБД Oracle для преобразования запросов типа "звезда".
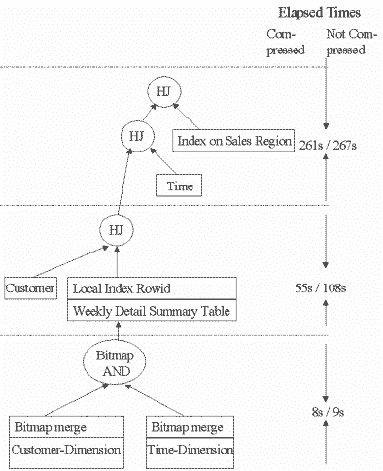
Рис. 8. План выполнения запроса типа "звезда" номер 2
Надписи на рисунке:
- Elapsed Times - интервалы общего затраченного времени;
- Compressed - сжатая ;
- Not Compressed - несжатая;
- HJ - hash join, хеш-соединение;
- Index on Sales Region - индекс по регионам продаж;
- Time - время;
- Customer - клиент;
- Local Index Rowid - идентификатор строки из локального индекса;
- Weekly Detail Summary Table - таблица итогов продаж по неделям;
- Bitmap AND - битовая операция AND;
- Bitmap merge - слияние битовых векторов;
- Customer-Dimension - измерение Items (продукты);
- Time-Dimension - измерение Time (время).
Запрос типа "звезда" номер 3
Третий запрос - вариант запроса номер 2. Вместо вычисления суммы объемов продаж, проведенных в первые пять месяцев 1998 и 1999 годов, он вычисляет объем продаж за полные два года, 1998 и 1999. План выполнения этого запроса совпадает с планом запроса 2 и явно не показан.
Обсуждение производительности выполнения запросов типа "звезда"
(Прим. ред. В данном разделе автор вводит два нетрадиционных для документации Oracle термина: probe table и build table. Происхождение этих терминов можно пояснить, например, следующей фразой из [8] "Hash join uses the smaller input to build a hash table and the larger to probe it" - в хеш-соединениях меньшие по объему данные используются для построения хеш-таблицы, а большие для ее зондирования. Мы будем переводить эти термины как первичная таблица [для построения хеш-таблицы] и вторичная таблица [хеш-соединения] соответственно.
Мы выполняли описанные выше запросы в несжатой схеме, а затем - в сжатой схеме. На рис. 9 показаны интервалы общего затраченного времени в секундах (Elapsed Time [s]) и коэффициенты повышения производительности для обоих прогонов всех трех запросов типа "звезда" (Q1, Q2 и Q3). Коэффициент повышения производительности вычисляется по следующей формуле:
где ElaрsedTimeSpeedup - коэффициент повышения производительности, elapsedTime_non_compressed - общее затраченное время в несжатой схеме, elapsedTime_compressed - общее затраченное время в сжатой схеме.
Каждая пара столбиков показывает интервалы общего затраченного времени для одного запроса. Первый столбик показывает общее затраченное время при выполнении данного запроса в несжатой (non-compressed) схеме, а второй - в сжатой (compressed) схеме. Коэффициент повышения производительности показан в процентах для каждой пары столбиков. Для запроса 1 общее затраченное время уменьшилось на 13%, для запроса 2 - на 15% и для запроса 3 - на 11%. Общее затраченное время на выполнение всех 17 пользовательских запросов уменьшилось на 16.5%.
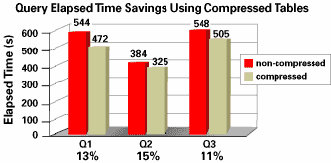
Рис. 9. Экономия общего затраченного времени при выполнении запросов к сжатым таблицам
Повышение производительности выполнения запросов типа "звезда" к сжатой схеме типа "звезда" происходит в результате ускорения доступа к таблицам фактов или таблицам итогов во время второй фазы выполнения запросов. Чем больше коэффициент сжатия, тем большим будет уменьшение общего затраченного времени. Тем не менее, по коэффициенту сжатия невозможно вычислить коэффициент повышения производительности, поскольку последний зависит от количества и заполненности блоков, обрабатываемых запросом. Более того, повышение производительности выполнения запросов зависит от быстродействия подсистемы ввода-вывода. Чем слабее подсистема ввода-вывода, тем больше будет выгод от сжатия.
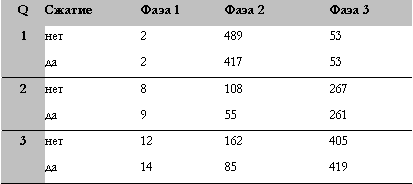
Рис. 10. Детальное распределение интервалов времени по различным фазам выполнения запросов типа "звезда"
На рис. 10 показано распределение интервалов общего затраченного времени выполнения по различным фазам выполнения запросов. Первая фаза выполнения запроса 1 включает в себя доступ к двум битовым индексам (по измерениям CUSTOMER и TIME) и объединение результатов доступа с помощью операции AND. Общее затраченное время выполнения этой фазы приблизительно равно двум секундам независимо от вида схемы, так как эти операции не обращаются к каким-либо сжатым таблицам. Во второй фазе таблица фактов DAILY_SALES соединяется с измерением ITEM (используется хеш-соединение). Большая часть времени выполнения этой фазы затрачивается на просмотр вторичной таблицы хеш-соединения DAILY_SALES, поскольку первичная таблица, используемая для построения хеш-таблицы, ITEM, имеет очень маленький размер. В третьей фазе результирующий набор, полученный во второй фазе, соединяется с двумя измерениями TIME и CUSTOMER. Так же как и в первой фазе, затраченное время выполнения этой фазы приблизительно равно 53 секундам независимо от вида схемы. Небольшие различия во временах выполнения фаз 1 и 3 для "сжатых" и "несжатых" запросов находятся в границах погрешности измерений. Для выполнения запроса 1 к сжатым таблицам требуется приблизительно 472 секунды, а к несжатым таблицам - 544 секунды, общее затраченное время выполнения уменьшилось на 72 секунды или на 13%.
В этом запросе единственным шагом, в котором используются сжатые таблицы, что приводит к изменению поведения во время исполнения, является обращение к таблице фактов DAILY_SALES. В запросах 2 и 3 - это обращение к таблице итогов WEEKLY_SALES. На рис. 10 для всех трех запросов показаны интервалы времени доступа к битовым индексам (фаза 1), первого повторного соединения (фаза 2), в котором происходит обращение к таблице фактов или таблице итогов, и оставшихся повторных соединений с измерениями (фаза 3).
Только при первом повторном соединении (соединении с таблицей фактов или таблицей итогов) постоянно видны различия в общем затраченном времени выполнения запросов в случае обращения к сжатым таблицам. В запросе 2, например, разница для этого соединения составляет приблизительно 53 секунды (17%), тогда как при выполнении повторных соединений с другими измерениями особых изменений общего затраченного времени не видно. К таблице фактов, как вторичной таблице в этом хеш-соединении, осуществляется индексный доступ для зондирования квалифицированных строк в измерении CUSTOMER (использованном как первичная таблица). Уменьшение общего затраченного времени для этого хеш-соединения за счет сжатия таблиц ограничивается преимущественно вторичной таблицей. В общем, за счет сжатия больше выгод от операций с большим временем ввода-вывода, чем от операций с небольшим временем ввода-вывода. Следовательно, чем менее ограничивающие предикаты по битовому индексу используются в первой фазе, тем больше квалифицируется строк таблицы фактов или таблицы итогов, что приводит к большей выгоде от сжатия.
С первого взгляда небольшое уменьшение общего затраченного времени, равное 11%, кажется несогласующимся с большим коэффициентом сжатия таблицы фактов, равным 2.9 (67% экономии пространства). Примите во внимание, что вторая фаза занимает примерно 90% времени выполнения запроса, а экономия пространства, равная 67%, должна была бы уменьшить общее затраченное время приблизительно на 60%. Действительно, это было бы так, если бы читаемые строки объединялись в последовательных блоках. Например, если операция обращается к 5 строкам в 5 разных блоках, размещенных в несжатой таблице с большими промежутками, то независимо от величины коэффициента сжатия, эти 5 строк при сжатии таблицы, вероятно не попадут в один и тот же блок. Следовательно, даже из сжатой таблицы этот запрос будет читать 5 блоков Вот почему операции, в которых не проявляется свойство локальности ссылок, получают меньше выгод от сжатия. Это можно показать, подсчитав количество блоков, необходимых для чтения из сжатой и несжатой таблиц. При доступе к таблице фактов DAILY_SALES запрос 1 читает примерно 92115 блоков в сжатом случае и 94137 блоков в несжатом, разница равна только 2022 блокам или приблизительно 8.15%. Это показывает, что строки, читаемые запросом 1, размещены в таблице с большими промежутками, то есть свойство локальности ссылок отсутствует и, следовательно от сжатия получается меньше выгод (аналогичное поведение наблюдается и у запросов 1 и 2).
Запросы в эталонном тесте TPC-H
В этом разделе кратко описаны три запроса в эталонном тесте TPC-H, которые мы будем анализировать в следующих разделах.
Запрос номер 1 в эталонном тесте TPC-H
В запросе номер 1 вычисляются множественные агрегированные и итоговые данные, при этом читается и обрабатывается свыше 95% строк самой большой таблицы базы данных. Сканируется только одна эта таблица и получается очень маленький результирующий набор. Поскольку этот запрос выполняет много функций агрегации данных, обычно он требует интенсивной работы процессора.
Запрос номер 6 в эталонном тесте TPC-H
Запрос номер 6 обращается только к большой таблице фактов (LINEITEM), выбирая из нее приблизительно 12% строк и возвращая один столбец ответа. Он выполняет совсем немного функций агрегации, что делает его хорошим кандидатом для создания нагрузки на подсистему ввода-вывода.
Запрос номер 15 в эталонном тесте TPC-H
Из этой таблицы (1/28 таблицы LINEITEM - данные за 3 месяца) осуществляется выборка по дате и агрегирование по поставщику (Supplier). В результирующем наборе после первого шага агрегирования содержатся данные почти о всех поставщиках. Сам запрос возвращает строку о поставщике, имеющем максимальный доход. Этот запрос возвращает одну строку.
Обсуждение производительности выполнения запросов в эталонном тесте TPC-H
На рис. 11 показаны интервалы общего затраченного времени в секундах (Elapsed Time [s]) и коэффициенты повышения производительности выполнения трех запросов к сжатым таблицам в эталонном тесте TPC-H (Q1, Q6 и Q15). Этот рисунок организован так же как и рис. 9. Он показывает, что запрос 1 к сжатой таблице LINEITEM выполняется с относительно небольшим замедлением, которое, вполне возможно, находится в границах погрешности измерений. С другой стороны, запросы 6 и 15 выполняются существенно быстрее. Запрос 6 ускоряется на 35%, а запрос 15 - на 38%.
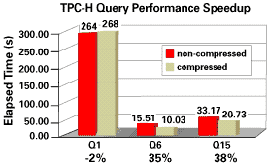
Рис. 11. Экономия общего затраченного времени при выполнении запросов к сжатым таблицам
Суммарный коэффициент повышения производительности вычисляется по следующей формуле:
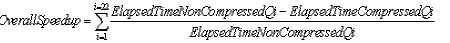
где OverallSpeedup - суммарный коэффициент повышения производительности, ElapsedTime_non_compressedQi - общее затраченное время для i-го запроса к несжатой схеме, ElapsedTime_compressedQi - общее затраченное время для i-го запроса к сжатой схеме.
Суммарный коэффициент повышения производительности выполнения всех 22 запросов к сжатым таблицам по сравнению с запросами к несжатым таблицам в эталонном тесте TPC-H равен приблизительно 10%. Общее затраченное время на тест вставки данных rf1 (Прим. ред. rf - refresh function (функция обновления данных), см. спецификацию стандарта TPC-H [9]) увеличилось приблизительно на 3.9%, тогда как общее затраченное время на тест удаления rf2 уменьшилось приблизительно на 17%. Основная метрика теста TPC-H, QphH@100GB (Прим. ред. QphH - Query-per-Hour Performance Metric, метрика количества запросов, обрабатываемых тестируемой системой в течение часа) увеличилась приблизительно на 10%. При выполнении некоторых запросов мы наблюдали незначительное увеличение потребляемого времени центрального процессора. Как было продемонстрировано в разделе об экономии пространства, данные теста TPC-H сжимаются с коэффициентом сжатия, равным только 1.2 для таблицы ORDERS и 1.6 для таблицы LINEITEM. Запросы же к сжатой базе данных выполняют на 27% меньше обращений к дискам.
Общее затраченное время выполнения запроса номер 1 увеличилось приблизительно на 2%. Это можно объяснить незначительным увеличением использования процессора, а также тем фактом, что этот запрос требует интенсивной работы процессора. Общие затраты при запросе к сжатым таблицам увеличиваются приблизительно на 2%. При выполнении запроса нет свободного времени процессора, поэтому общее затраченное время выполнения запроса увеличивается примерно на тот же объем времени, что и время процессора. Большое уменьшение использования диска, равное приблизительно 38%, очень мало влияет на этот запрос, так как для него дисковая подсистема не является узким местом.
Производительность выполнения запроса номер 6 увеличивается приблизительно на 35%. В этом запросе интенсивно выполняются операции ввода-вывода, поэтому доступное время процессора не используется. Следовательно, повышение нагрузки на процессор может быть легко компенсировано без деградации производительности системы.
Так же как и запрос номер 6, запрос номер 15 выгадывает от сжатия таблиц, показывая 38% повышения производительности. В этом запросе не используется некоторое доступное время процессора, что приводит к уменьшению общего затраченного времени выполнения запроса приблизительно на 8%. Этот запрос больше выгадывает от сжатия, читая из сжатой базы данных на 42% меньше данных по сравнению с несжатой базой данных.
Использование сжатых таблиц в тесте TPC-H в нашей системной конфигурации уменьшает общее затраченное время выполнения большинства запросов. Но повышает общее затраченное время выполнения оставшихся запросов. Запросы с интенсивными операциями ввода-вывода имеют прямую выгоду от сжатия, поскольку в них уменьшается среднее потребление ресурсов, которые ограничивают повышение производительности системы (то есть "узких мест"), а именно, дисковой подсистемы. Запросы с интенсивным потреблением времени процессора также получают выгоду от меньшей нагрузки на дисковую подсистему. Тем не менее, накладные расходы доступа к сжатым таблицам могут "вредить" общему затраченному времени выполнения этих запросов.
Лучшие практические методы
Сжатие таблиц лучше всего использовать в условиях рабочих нагрузок с интенсивным выполнением операций чтения, преобладающих в приложениях поддержки принятия решений. Рекомендуется сжимать большие таблицы, такие, как таблицы фактов и материализованные представления схем типа "звезда" и таблицы схем в третьей нормальной форме (3NF-схемы), в которых содержатся транзактные данные. Не рекомендуется сжимать небольшие таблицы, такие, как измерения схем типа "звезда", поскольку они незначительно влияют на общую экономию пространства.
Можно сжимать некоторые или все секции секционированных таблиц. Например, в больших хранилищах данных, в которых данные обычно секционированы, можно для максимизации использования пространства сжимать секции, к которым нет частого доступа. Если однако секция модифицируется ETL-процессом (Прим. ред. ETL - Extraction, Transmission, Loading - технология извлечения, преобразования и загрузки данных), то следует оценивать накладные расходы сжатия.
Для увеличения коэффициента сжатия данные таблиц перед их сжатием могут быть отсортированы. Тем не менее, во многих случаях, как обсуждалось ранее, данные приложений поддержки принятия решений кластеризуются естественным образом, следовательно, очень хорошие коэффициенты сжатия получаются без дополнительных усилий. Дополнительные рекомендации по использованию нового механизма сжатия в СУБД Oracle можно найти на веб-сайте Oracle Technology Network (http://otn.oracle.com).
Кроме того, в большинстве случаев большие размеры блоков повышают коэффициент сжатия таблицы базы данных, так как с одной и той же таблицей идентификаторов может быть связано больше значений столбцов.
Заключение
Стоимость дисковых подсистем может составлять очень большую часть стоимости создания и сопровождения больших хранилищ данных. СУБД Oracle9i Release 2 помогает уменьшить эту стоимость с помощью сжатия данных, хранимых в базе данных Oracle, и это делается без типичной проблемы выбора между экономией пространства и временем доступа к данным.
Коэффициент сжатия, которого можно достигнуть, зависит от данных и их распределения. В наших тестах, рассмотренных выше, были показаны коэффициенты сжатия от 1.2 до 4.0 (от 17% до 67% экономии пространства). Тем не менее, наблюдались и более высокие коэффициенты сжатия. Например, сжатие детализированных данных разговоров большой телекоммуникационной компании дало в результате коэффициент сжатия, равный 12 (92% экономии пространства). Среди результатов пользовательских тестов это был самый высокий достигнутый коэффициент сжатия. Коэффициент сжатия, равный 5 (80% экономии пространства) был достигнут на агрегированных данных о продажах различным клиентам в различных отраслях промышленности.
Анализируя запросы к схеме типа "звезда" и 3NF-схеме, мы показали, что сжатие таблицы может привести к значительному повышению производительности выполнения запроса. Более всего это характеризуется уменьшением дискового ввода-вывода и незначительным временем восстановления данных, требуемым для доступа к данным сжатых таблиц.
Выполнение запросов к схеме типа "звезда" и 3NF-схеме в значительной степени различается. В запросах к схеме типа "звезда" большая часть времени выполнения затрачивается на доступ к битовым индексам и последующее соединение квалифицированных строк таблицы фактов с таблицами измерений. Поэтому сжатие таблиц на доступ к битовым индексам не влияет. Наоборот, в запросах к 3NF-схеме интенсивно выполняются операции хеш-соединения возможно очень большой части базы данных. Эти операции получают очень большую выгоду, так как с диска читается меньше данных.
Пример запросов к схеме типа "звезда" показывает повышение производительности приблизительно на 12-16%, что приводит к общему повышению производительности выполнения всех 17 запросов приблизительно на 16.5%. С другой стороны, повышение производительности запросов в эталонном тесте TPC-H достигает 38%. Общее повышение производительности всех запросов в тесте TPC-H достигает 10%.
Сжатие таблиц в СУБД Oracle9i Release 2 существенно уменьшает потребности в дисковом пространстве и кеше буферов. Для этого не требуются какие-либо изменения в приложениях.
Ссылки
[1] TPC-H 100 GB published 07/15/02 by HP/Oracle on Alpha Server ES45 and Oracle 9iR2 Executive Summary:
http://www.tpc.org / results / individual_results / HP / es45_ 5578_es.pdf FDR
http://www.tpc.org / results / FDR / tpch / es45_5578_fdr.pdf.
[2] Oracle9i Data Warehousing Guide Release 2 (9.2) Part Number A96520-01.
[3] Date C.J. "An Introduction to Database Systems", Reading, Mass., Addision Wesley Verlag, 1981. (Прим. ред. Имеется русский перевод: Дейт К. "Введение в системы баз данных". 6-е изд. - М: Вильямс, 1999.
[4] Ziv J. and Lempel A. "A Universal Algorithm for Sequential Data Compression'', IEEE Transactions on Information Theory, Vol. 23, pp. 337--342, 1977.
Ссылки к примечаниям редакторов русского перевода
- [5] Ла Планте Брайан "Турбопривод для витрин данных" - Oracle Magazine/Russian Edition, #7/2000, http://www.olap.ru/basic/news/m001015886.asp.
- [6] Черняк Л. "Снова о тестах TPC" - Открытые системы, #11/2000, http://www.osp.ru/os/2000/11/034.htm.
- [7] Query Optimization in Oracle9i, An Oracle White Paper, February 2002, http://otn.oracle.com / products / bi / pdf / o9i_optimization_twp.pd.
- [8] Questions and Answers. SQL Optimization - http://www.ixora.com.au/q+a/sqlopt.htm.
- [9] "TPC BENCHMARK™H (Decision Support)", Standard Specification, Revision 2.0.0 - Transaction Processing Performance Council (TPC), http://www.tpc.org/tpch/spec/tpch2.0.0.pdf.
Приложение - SQL-запросы
Запрос типа "звезда" номер 1
SELECT T.year, T.month, C.district, I.name,
SUM(sales)
FROM customers C,
daily_sales S,
items I,
time T
WHERE S.item_nr=I.item_nr
AND S.addr_id=C.addr_id
AND S.date=T.date
AND T.year in (1998, 1999)
AND T.month in (1-05-1998, 1-06-1998, …
…, 1-03-1999)
AND C.district in ('CO', 'CA')
AND I.group = 'classic'
AND I.item = 'blue gravave'
GROUP BY T.year, T.month, C.district, I.name;
Запрос типа "звезда" номер 2
SELECT C.district, C.name,
T.year, T.month,
R.region_number,
SUM(sales)
FROM customers C,
time T
weekly_sales S,
sales_region R
WHERE S.region_id=R.region_id
AND S.addr_id=C.addr_id
AND S.date=T.date
AND T.year in (1998, 1999)
AND T.month in (1,2,3,4,5)
AND C_district = 'Chicago'
AND R.region_number in ('234','4565','111','1')
GROUP BY
C.district, C.name, T.year, T.month,
R.region_number;
Содержание