Обзор возможностей применения ведущих СУБД для построения хранилищ данных (DataWarehouse)
Сергей Кузнецов, Центр Информационных Технологий,Валерий Артемьев, ГЦИ ЦБ РФ
Основные понятия
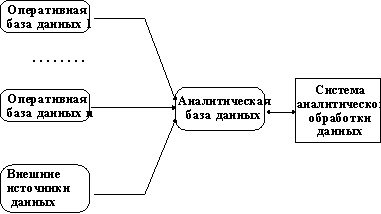
Сравнение оперативных и аналитических ИС с точки зрения обеспечения данными
- Основным источником информации, поступающей в оперативную БД является деятельность корпорации. Для проведения анализа данных требуется привлечение внешних источников информации (например, статистических отчетов). Хранилище данных должно включать как внутренние корпоративные данные, так и внешние данные.
- Для оперативной обработки требуются свежие данные за несколько последних месяцев, для проведения достоверных анализа и прогнозирования в хранилище данных нужно иметь информацию о деятельности корпорации и состоянии рынка на протяжении нескольких лет. Объем аналитических БД как минимум на порядок больше объема оперативных.
- Во многих крупных корпорациях одновременно существуют несколько оперативных ИС с собственными БД (по историческим причинам). Оперативные БД могут содержать семантически эквивалентную информацию, представленную в разных форматах, с разным указанием времени ее поступления, иногда даже противоречивую. Хранилище данных должно содержать единообразно представленную и согласованную информацию, максимально соответствующую содержанию оперативных БД. Необходима компонента для извлечения и "очистки" информации из разных источников.
- Оперативные ИС создаются в расчете на решение конкретных задач. Информация из БД выбирается часто и небольшими порциями. Обычно набор запросов к оперативной БД известен уже при проектировании. Набор запросов к аналитической базе данных предсказать невозможно. Хранилища данных существуют, чтобы отвечать на нерегламентированные (ad hoc) запросы аналитиков. Можно рассчитывать только на то, что запросы будут поступать не слишком часто и затрагивать большие объемы информации. Размеры аналитической БД стимулируют использование запросов с агрегатами (сумма, минимальное, максимальное, среднее значение и т.д.).
- Оперативные БД по своей природе являются сильно изменчивыми, что учитывается в используемых СУБД (нормализованная структура БД, строки хранятся неупорядоченно, B-деревья для индексации, транзакционность). При малой изменчивости аналитических БД (только при загрузке данных) оказываются разумными упорядоченность массивов, более быстрые методы индексации при массовой выборке, хранение заранее агрегированных данных.
- Для оперативных ИС обычно хватает защиты информации на уровне таблиц. Информация аналитических БД настолько критична для корпорации, что требуются большая грануляция защиты(индивидуальные права доступа к определенным строкам и/или столбцам таблицы).
Концепция хранилища данных
Хранилище данных - предметно-ориентированный, интегрированный, неизменчивый, поддерживающий хронологию набор данных, организованный для целей поддержки управления.
Подход построения хранилища данных для интеграции неоднородных источников данных принципиально отличается от подхода динамической интеграции разнородных БД. Реально строится новое крупномасштабное хранилище, управление данными в котором происходит по другим правилам, чем в исходных оперативных БД.
В основе концепции хранилища данных лежат две основные идеи:
(1) Интеграция разъединенных детализированных данных (детализированных в том смысле, что они описывают некоторые конкретные факты, свойства, события и т.д.) в едином хранилище. В процессе интеграции должно выполняться согласование рассогласованных детализированных данных и, возможно, их агрегация. Данные могут поступать из исторических архивов корпорации, оперативных баз данных, внешних источников.
(2) Разделение наборов данных и приложений, используемых для оперативной обработки и применяемых для решения задач анализа.
Общая архитектура аналитических ИС
Потоки данных в информационном хранилище
Свойства информационных хранилищ
Уильям Инмон, считающийся основателем нового направления развития технологии БД, дал классическое определение информационного хранилища в 1990 г. Он охарактеризовал его как специальным образом администрируемую базу данных, содержимое которой имеет следующие свойства:
Предметная ориентация
В отличие от БД в традиционных OLTP-системах, где данные подобраны в соответствии с конкретными приложениями, информация в DW ориентирована на задачи поддержки принятия решений.. Для системы поддержки принятия решений требуются "исторические" данные - факты продаж за определенные интервалы времени. Хорошо спроектированные структуры данных DW отражают развитие всех направлений бизнеса компании во времени.
Поскольку в DW-технологии объекты данных выходят на первый план, то особые требования предъявляются к структурам БД, используемым для создания информационных хранилищ.. Принципиально отличаются и структуры баз данных для OLTP- и DW-систем. Во втором случае в них помещается только та информация, которая может быть полезной для работы систем поддержки принятия решений (DSS).
Интегрированность данных
Данные в информационное хранилище поступают из различных источников, где они могут иметь разные имена, атрибуты, единицы измерения и способы кодировки. После загрузки в DW данные очищаются от индивидуальных признаков, т. е. как бы приводятся к общему знаменателю. С этого момента они представляются пользователю в виде единого информационного пространства.
Если в четырех разных приложениях пол клиента кодировался четырьмя различными способами, то в информационном хранилище будет использована единая для всех данных схема кодировки (например, f,m).
Инвариантность во времени
В OLTP-системах истинность данных гарантирована только в момент чтения, поскольку уже в следующее мгновение они могут измениться в результате очередной транзакции. Важным отличием DW от OLTP-систем является то, что данные в них сохраняют свою истинность в любой момент процесса чтения.
В OLTP-системах информация часто модифицируется как результат выполнения каких-либо транзакций. Временная инвариантность данных в DW достигается за счет введения полей с атрибутом "время" (день, неделя, месяц) в ключи таблиц. В результате записи в таблицах DW никогда не изменяются, представляя собой снимки данных, сделанные в определенные отрезки времени. В DW содержатся как бы моментальные снимки данных. Каждый элемент в своем ключе явно или косвенно хранит временной параметр, например день, месяц или год.
Неразрушаемость - cтабильность информации
В OLTP-системах записи могут регулярно добавляться, удаляться и редактироваться. В DW-системах, как следует из требования временной инвариантности, однажды загруженные данные теоретически никогда не меняются. По отношению к ним возможны только две операции: начальная загрузка и чтение (доступ). Это и определяет специфику проектирования структуры базы данных для DW. Если при создании OLTP-систем разработчики должны учитывать такие моменты, как откаты транзакций после сбоя сервера, борьба с взаимными блокировками процессов (deadlocks), сохранение целостности данных, то для DW данные проблемы не столь актуальны - перед разработчиками стоят другие задачи, связанные, например, с обеспечением высокой скорости доступа к данным.
Минимизация избыточности информации
Поскольку информация в DW загружается из OLTP-систем, возникает вопрос, не ведет ли это к чрезмерной избыточности данных? Нет, утверждает Билл Инмон. На самом деле избыточность минимальна (около 1%!), что объясняется следующими причинами:
Основные компоненты информационного хранилища
ПО промежуточного слоя
Обеспечивает сетевой доступ и доступ к базам данных. Сюда относятся сетевые и коммуникационные протоколы, драйверы, системы обмена сообщениями и пр.
Транзакционные БД и внешние источники информации
Базы данных OLTP-систем исторически предназначались для эффективной обработки структур данных в относительно небольшом числе четко определенных транзакций. Из-за ограниченной целевой направленности "учетных" систем применяемые в них структуры данных плохо подходят для систем поддержки принятия решений. Кроме того, возраст многих установленных OLTP-систем достигает 10 - 15 лет.
Уровень доступа к данным
Относящееся сюда ПО обеспечивает общение конечных пользователей с информационным хранилищем и загрузку требуемых данных из транзакционных систем. В настоящее время универсальным языком общения служит язык структурированных запросов (SQL).
Загрузка и предварительная обработка
Этот уровень включает в себя набор средств для загрузки данных из OLTP-систем и внешних источников. Выполняется, как правило, в сочетании с дополнительной обработкой: проверкой данных на чистоту, консолидацией, форматированием, фильтрацией и пр.
Информационное хранилище
Представляет собой ядро всей системы - один или несколько серверов БД.
Метаданные
Метаданные (репозиторий, "данные о данных"). Играют роль справочника, содержащего сведения об источниках первичных данных, алгоритмах обработки, которым исходные данные были подвергнуты, и т. д.
Уровень информационного доступа
Обеспечивает непосредственное общение пользователя с данным DW посредством стандартных систем манипулирования, анализа и предоставления данных типа MS Excel, MS Access, Lotus 1-2-3 и др.
Уровень управления (администрирования)
Отслеживает выполнение процедур, необходимых для обновления информационного хранилища или поддержания его состояния. Здесь программируются процедуры подкачки данных, перестройки индексов, выполнения итоговых (суммирующих) расчетов, репликации данных, построения отчетов, формирования сообщений пользователям, контроля целостности и др.
Проблемы интеграции данных
Остановимся на некоторых проблемах реализации хранилища данных:
Неоднородность программной среды
Хранилище данных практически никогда не создается на пустом месте. Почти всегда конечное решение будет разнородным, т.е. в нем будут использоваться автономно разработанные программные средства. Прежде всего это касается формирования интегрированного согласованного набора данных, которые могут поступать из разнородных баз данных, электронных архивов, публичных и коммерческих электронных каталогов, справочников, статистических сборников. При построении хранилища данных приходится решать задачу построения единой, согласованно функционирующей информационной системы на основе неоднородных программных средств и решений. При выборе средств реализации хранилища данных приходится учитывать множество факторов, включающих уровень совместимости различных программных компонентов, легкость их освоения и использования, эффективность функционирования и т.д.
Распределенный характер организации
В концепции хранилища данных предопределено то, что операционная аналитическая обработка может выполняться в любом узле сети независимо от места расположения основного хранилища. Хотя при аналитической обработке данные только читаются, и потребность в синхронизации отсутствует, для достижения эффективности необходимо поддерживать репликацию данных в разных узлах сети. (На самом деле, все не так просто. Одним из требований к хранилищам данных является то, чтобы свежая информация поступала в хранилище как можно быстрее. Т.е. потенциально любая модификация оперативной БД может инициировать добавление данных к хранилищу данных, а тогда потребуется обновить и все реплики, для чего синхронизация все-таки нужна.)
Повышение требований к безопасности данных
Собранная вместе согласованная информация об истории развития корпорации, ее успехах и неудачах, о взаимоотношениях с поставщиками и заказчиками, об истории и состоянии рынка дает возможность анализа прошлой и текущей деятельности корпорации и построения прогнозов для будущего. Эта информация настолько ценна для корпорации, что нельзя допустить возможности ее утечки (на самом деле, если хранилище данных одной корпорации попадет в руки аналитиков другой корпорации, то все аналитические прогнозы первой корпорации сразу станут неверными). В системах, основанных на хранилищах данных, оказывается недостаточной защита данных в стиле языка SQL, которую обеспечивают обычные коммерческие СУБД (этот уровень защиты соответствует классу C2 в соответствии с классификацией Оранжевой Книги Министерства обороны США). Для обеспечения должного уровня защиты доступ к данным должен контролироваться не только на уровне таблиц и их столбцов, но и на уровне отдельных строк (это уже соответствует классу B1 Оранжевой Книги). Приходится также решать вопросы аутентификации пользователей, защиты данных при их перемещении в хранилище данных из оперативных баз данных и внешних источников, защиты данных при их передаче по сети.
Необходимость наличия многоуровневых справочников метаданных
Если роль метаданных (обычно содержащихся в таблицах-каталогах) в оперативных информационных системах достаточно ограничена, то для OLAP-систем наличие развитых метаданных и средств их предоставления конечным пользователям является одним из основных условий успешной реализации. Например, прежде, чем менеджер корпорации задаст системе свой вопрос, он должен понять, какая информация имеется, насколько она актуальна, можно ли ей доверять, сколько времени может занять формирование ответа и т.д. Для пользователя OLAP-системы требуются метаданные, по крайней мере, следующих типов:
(1) Описания структур данных, их взаимосвязей.
(2) Информация о хранимых на хранилище данных и поддерживаемых им агрегатах данных.
(3) Информация об источниках данных и о степени их достоверности. Одна и та же информация могла попасть в хранилище данных из разных источников. Пользователь должен иметь возможность узнать, какой источник был выбран основным, и каким образом производились согласование и очистка данных.
(4) Информация о периодичности обновлений данных. Желательно знать не только то, какому моменту времени соответствуют интересующие его данные, но и когда они в следующий раз будут обновлены.
(5) Информация о владельцах данных. Пользователю OLAP-системы может оказаться полезной информация о наличии в системе данных, к которым он не имеет доступа, о владельцах этих данных и о действиях, которые он должен предпринять, чтобы получить доступ к данным.
(6) Статистические оценки времени выполнения запросов. До выполнения запроса полезно иметь хотя бы приблизительную оценку времени, которое потребуется для получения ответа, и объема этого ответа.
Потребность в эффективном хранении и обработке очень больших объемов Уже сейчас известны примеры хранилищ данных, содержащих терабайты информации. По данным консалтинговой компании Meta Group, около половины корпораций, использующих или планирующих использовать хранилища данных, предполагает довести их объем до сотен гигабайт. Проблемой таких больших хранилищ является то, что накладные расходы на внешнюю память возрастают нелинейно при возрастании объема хранилища. Исследования, проведенные на основе тестового набора TPC-D, показали, что для баз данных объемом в 100 гигабайт потребуется внешняя память объемом в 4.87 раза большая, чем нужно собственно для полезных данных. При дальнейшем росте баз данных этот коэффициент увеличивается.
Реализация хранилищ и витрин данных
Варианты реализации хранилищ данных
Виртуальное хранилище данных
В его основе - репозиторий метаданных, которые описывают источники информации (БД транзакционных систем, внешние файлы и др.), SQL-запросы для их считывания и процедуры обработки и предоставления информации. Непосредственный доступ к последним обеспечивает ПО промежуточного слоя. В этом случае избыточность данных нулевая. Конечные пользователи фактически работают с транзакционными системами напрямую со всеми вытекающими отсюда плюсами (доступ к "живым" данным в реальном времени) и минусами (интенсивный сетевой трафик, снижение производительности OLTP-систем и реальная угроза их работоспособности вследствие неудачных действий пользователей-аналитиков).
Витрина данных
Витрина данных (Data Mart) по своему исходному определению - это набор тематически связанных баз данных, которые содержат информацию, относящуюся к отдельным аспектам деятельности корпорации. По сути дела, витрина данных - это облегченный вариант хранилища данных, содержащий только тематически объединенные данные. Целевая база данных максимально приближена к конечному пользователю и может содержать тематически ориентированные агрегатные данные. Витрина данных, естественно, существенно меньше по объему, чем корпоративное хранилище данных, и для его реализации не требуется особо мощная вычислительная техника.
Глобальное хранилище данных
В последнее время все более популярной становится идея совместить концепции хранилища и витрины данных в одной реализации и использовать хранилище данных в качестве единственного источника интегрированных данных для всех витрин данных. Тогда естественной становится такая трехуровневая архитектура системы:
На первом уровне реализуется корпоративное хранилище данных на основе одной из развитых современных реляционных СУБД. Это хранилище интегрированных в основном детализированных данных. Реляционные СУБД обеспечивают эффективное хранение и управление данными очень большого объема, но не слишком хорошо соответствуют потребностям OLAP-систем, в частности, в связи с требованием многомерного представления данных.
На втором уровне поддерживаются витрины данных на основе многомерной системы управления базами данных (примером такой системы является Oracle Express Server). Такие СУБД почти идеально подходят для целей разработки OLAP-систем, но пока не позволяют хранить сверхбольшие объемы данных (предельный размер многомерной базы данных составляет 10-40 Гбайт). В данном случае это и не требуется, поскольку речь идет о витринах данных. Заметим, что витрина данных не обязательно должна быть полностью сформирована. Она может содержать ссылки на хранилище данных и добирать оттуда информацию по мере поступления запросов. Конечно, это несколько увеличивает время отклика, но зато снимает проблему ограниченного объема многомерной базы данных.
Наконец, на третьем уровне находятся клиентские рабочие места конечных пользователей, на которых устанавливаются средства оперативного анализа данных.
Подходы и имеющиеся решения
Компания IBM
Решение компании IBM называется A Data Warehouse Plus. Целью компании является обеспечение интегрированного набора программных продуктов и сервисов, основанных на единой архитектуре. Основой хранилищ данных является семейство СУБД DB2. Преимуществом IBM является то, что данные, которые нужно извлечь из оперативной базы данных и поместить в хранилище данных, находятся в системах IBM. Поэтому естественная тесная интеграция программных продуктов.
Предлагаются три решения для хранилищ данных:
(1) Изолированная витрина данных. Предназначен для решения отдельных задач вне связи с общим хранилищем корпорации.
(2) Зависимая витрина данных. Аналогичен изолированной витрине данных, но источники данных находятся под централизованным контролем.
(3) Глобальное хранилище данных. Корпоративное хранилище данных, которое полностью централизовано контролируется и управляется. Глобальное хранилище данных может храниться централизовано или состоять из нескольких распределенных в сети рынков данных.
Oracle
Решение компании Oracle в области хранилищ данных основывается на двух факторах: широкий ассортимент продуктов самой компании и деятельность партнеров в рамках программы Warehouse Technology Initiative. Возможности Oracle в области хранилищ данных базируются на следующих составляющих:
Hewlett Packard
Работы, связанные с хранилищами данных, выполняются в рамках программы OpenWarehouse. Выполнение этой программы должно обеспечить возможность построения хранилищ данных на основе мощных компьютеров HP, аппаратуры других производителей и программных компонентов. Основой подхода HP являются Unix-платформы и программный продукт Intelligent Warehouse, который предназначен для управления хранилищами данных. Основа построения хранилищ данных, предлагаемая HP, оставляет свободу выбора реляционной СУБД, средств реинжиниринга и т.д.
NCR
Решение компании направлено на решение проблем корпораций, у которых одинаково сильны потребности и в системах поддержки принятия решений, и в системах оперативной аналитической обработки данных. Предлагаемая архитектура называется Enterprise Information Factory и основывается на опыте использования системы управления базами данных Teradata и связанных с ней методах параллельной обработки.
Informix Software
Стратегия компании в отношение хранилищ данных направлена на расширение рынка для ее продукта On-Line Dinamic Parallel Server. Предлагаемая архитектура хранилища данных базируется на четырех технологиях: реляционные базы данных, программном обеспечении для управления хранилищем данных, средствах доступа к данным и платформе открытых систем. Три последние компонента разрабатываются партнерами компании. После выхода Универсального Сервера, основанного на объектно-реляционном подходе, можно ожидать, что и он будет использоваться для построения хранилищ данных.
SAS Institute
Компания считает себя поставщиком полного решения для организации хранилища данных. Подход основан на следующем:
Sybase
Стратегия компании в области хранилищ данных основывается на разработанной ей архитектуре Warehouse WORKS. В основе подхода находится реляционная СУБД Sybase System 11, средство для подключения и доступа к базам данных OmniCONNECT и средство разработки приложений PowerBuilder. Компания продолжает совершенствовать свою СУБД для лучшего удовлетворения потребностей хранилищ данных (например, введена побитная индексация).
Software AG
Деятельность компании в области хранилищ данных происходит в рамках программы Open Data Warehouse Initiative. Программа базируется на основных продуктах компании ADABAS и Natural 4GL, собственных и приобретенных средствах извлечения и анализа данных, средстве управления хранилищем данных SourcePoint. SourcePoint позволяет автоматизировать процесс извлечения и пересылки данных, а также их загрузки в хранилище данных.
Совместное применение новых информационных технологий:
позволит создать информационную инфраструктуру корпорации и упростить доступ к данным для оперативного анализа.
Центр Информационных Технологий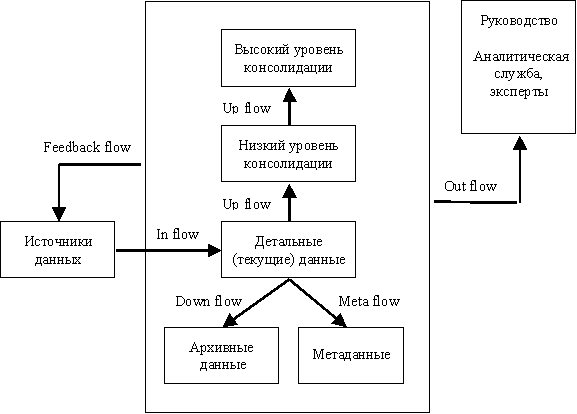
информации
Заключение
Москва, Ленинские горы, МГУ им. М.В. Ломоносова, 2-ой учебный корпус
Тел.: (095) 932-9212, 932-9213, 939-0783
Факс: 939-3670, 939-0805
E-mail: info@citmgu.ru
URL: http://www.citmgu.ru