Расширяемая, управляемая правилами оптимизация путем перезаписи запросов в Starburst
Хамид Пирамеш, Джозеф Хеллерстейн, Вакар Хасан
Перевод: Сергей Кузнецов
Оригинал: Hamid Pirahesh, Joseph M. Hellerstein, Waqar Hasan. Extensible/Rule Based Query Rewrite Optimization in Starburst. SIGMOD International Conference on Management of Data, 1992. Текст доступен здесь.
Содержание
- 1. Введение
- 1.1 Запросы с путевыми выражениями
- 2. Графовая модель запросов в Starburst
- 3. Набор правил перезаписи для гарантирования поглощения SELECT
- 4. Процессор правил
- 5. Заключение: процессор и правила
- 6. Благодарности
- Литература
- 5. Заключение: процессор и правила
Аннотация
В этой статье описывается средство перезаписи запросов (Query Rewrite) расширяемой системы баз данных Starburst. На использовании этого средства основывается новая фаза оптимизации запросов. Мы представляем набор правил перезаписи, используемых в Starburst для преобразования запросов в эквивалентные запросы для более быстрого выполнения, а также описываем процессор продукционных правил, который используется в Starburst для выбора и выполнения этих правил. Приводятся примеры, демонстрирующие, что преобразования, которые производит Query Rewrite, приводят к сокращению времени выполнения на порядки. Это говорит о том, что перезапись запросов вообще и эти правила перезаписи в частности являются существенным шагом вперед в оптимизации запросов в современных системах баз данных.
1. Введение
В традиционных системах баз данных оптимизация запросов обычно состоит в одной фазе обработки, во время которой выбираются методы доступа, порядки и методы соединений для обеспечения эффективного плана выполнения пользовательского декларативного запроса.
В Query Rewrite преследуются две цели:
- Сделать запросы как можно более декларативными: В языках баз данных, таких как SQL, часто возможны неудачно сформулированные запросы, являющиеся якобы декларативными, но навязывающие типичному оптимизатору планов выбор неоптимальных планов выполнения. Основная цель Query Rewrite состоит в том, чтобы преобразовать эти «процедурные» запросы в эквивалентные, но более декларативные запросы.
- Использовать естественные эвристики: В Query Rewrite могут применяться некоторые эвристики, которые расцениваются в литературе как значимые. Типичным примеров этого является «проталкивание предикатов» («predicate pushdown»), когда предикаты применяются в запросе как можно раньше (т.е. они «проталкиваются» из своих исходных позиций ближе к обращениям к таблицам, в подзапросы, представления и т.д.). Такие правила могут существенно сократить время выполнения запроса, и хотя некоторые из этих эвристик используются в типичных оптимизаторах планов, при использовании Query Rewrite они могут применяться гораздо более общим образом.
Хотя принятой доктриной является то, что языки запросов должны быть декларативными, в своих примерах мы покажем, что альтернативные, но эквивалентные формулировки запросов могут значительно изменять эффективность, часто на порядки. Отсюда происходит наше убеждение в том, что Query Rewrite является существенным шагом вперед в оптимизации запросов, поскольку этот компонент гаранирует отсутствие влияние исходной формулировки запроса на эффективность его выполнения.
1.1 Запросы с путевыми выражениями
Цели перезаписи запросов, разъясненные выше, являются даже более существенными в объектно-ориентированных приложениях, в которых обычно генерируются усложенные запросы с «путевыми выражениями», связывающими разнообразные коллекции объектов [BTA90, LLOW91, LLPS91]. В таких приложениях как сложность логики, так и объем данных гораздо больше, чем в тридиционных приложениях СУБД [HSS88]. В результате возрастает важность оптимизации запросов.
Ниже приводится пример запроса с путевым выражением, представленный в синтаксисе Object SQL [BTA90]1. Этот запрос является немного измененным примером, представленным в [BTA90]. База данных в примере содержит записи о пациентах. Медицинские записи являются множественными характеристиками пациентов. Все обращения к данным производятся через методы. Для заданной записи пациента медицинские записи возвращаются функцией get_medical_records. В примере выбираются записи о пациентах мужского пола, которым поставлен диагноз «малярия» (malaria) или «оспа» (smallpox) до '10/10/89'. В разделе FROM перечисляются пациенты, а в разделе WHERE пациенты ограничиваются до лиц мужского пола, и проверяется наличие диагнозов малярии или оспы, поставленных до указанной даты.
SELECT DISTINCT P
FROM Patient p IN Patient_Set
WHERE p.sex == 'male' &&
EXISTS ( SELECT r
FROM Medical_record r IN p.get_medical_record()
WHERE r.get_date() < '10/10/89' &&
(r.get_diagnosis() == 'Malaria' ||
r.get diagnosis() == 'Smallpox');
В подобных запросах существенным образом используются путевые выражения, в которых для данной записи родственная информация получается через путь (например, взятие медицинских записей пациента). Запросы с путевыми выражениями очень распространены в сложных приложениях, таких как CAD/CAM. В общем случае запрос может включать много путевых выражений, и длина каждого из них может быть больше единицы. Нахождение эффективного плана выполнения для таких путевых выражений является проблемой, очень похожей на проблему оптимизации (вложенных) подзапросов SQL. Приведенный выше запрос обычно выполняется путем перечисления пациентов мужского пола и проверки медицинских записей для каждого пациента, проверки предикатов по дате и диагнозу. Это равнозначно соединению с вложенным циклом, в котором порядок соединения диктуется пользователем – подзапрос обязательно является внутреннем циклом.
Однако, если имеется большое число пациентов мужского пола, это может оказаться очень неэффективно, поскольку большая часть выбираемых записей не фильтруется. В предположении, что и оспа, и малярия являются редкими болезнями, эффективность такого запроса можно повысить на несколько порядков, если сначала производить поиск медицинских записей по индексу на атрибуте диагнозов в медицинских записях, а затем находить соответствующих пациентов. Для этого в основном требуется по возможности преобразовывать такие запросы в соединения, которые могут выполняться по гораздо большему числу планов.
Изменение порядка соединения в приведенном примере значительно улучшают эффективность, но у него имеется нежелательный побочный эффект. У данного пациента могуть быть продиагностинованы и оспа, и малярия, и для каждого диагноза соответствующая запись пациента будет помещена в результат, что приведет к появлению в результате дублирующих записей пациентов. Это неправильно; например, это может привести к неверному результату запроса, в котором подсчитывается результирующее число записей.
Дубликаты могут появляться даже и без преобразований запросов. Записи-дубликаты часто появляются в базовых или промежуточных результатах в приложениях и имеют большое значение для запросов с агрегатными функциями, например, запросов, в которых требуется среднее значение некоторого столбца. Дубликаты входят в модель SQL [ISO91] и ОО-модели, такие как [LLOW91] (как «мультимножества объектов» («bags of objects»). Потребность и важность допущения дубликатов в реалистичных реализациях являются общепризнаными, особенно в реляционных СУБД (РСУБД). Поэтому важно аккуратно обращаться с дубликатами, и этот вопрос находится в центре работы, представленной в этой статье.
1.2 Замысел системы
Естественно, мы не предлагаем находить оптимальное представление запроса, как и традиционные «оптимизаторы» планов не находят оптимального плана выполнения запроса. Скорее, мы строим набор эвристик перезаписи запросов, выражаемых в виде продукционных правил, которые работают вместе для достижения двух указанных выше целей перезаписи. Эти правила продукции управляются процессором правил, написанном именно для этого и интегрированным в Starburst. Разработка системы правил способствовала проведению наших экспериментов с преобразованиями запросов в двух отношениях.
Во-первых, парадигма системы правил облегчила нам использование усложеннных инициирующих взаимодействий между правилами перезаписи, оградив нас от задачи явной трассировки потока управления между правилами. Часто это считают опасной сложностью систем правил ([ZH90], [Ras90], [HH91] и т.д.), но по нашему опыту система оказалась не только управляемой, но и действительно полезной. Во-вторых, система правил является отличной платформой для расширяемости, одной из ключевых целей Starburst. Эта расширяемость позволила нам написать и проверить за последние два года десятки преобразований запросов, включая те, которые представлены в этой статье, преобразования на основе магических множеств [MFPR90a, MPR90, MFPR90b] и многие другие.
Как мы увидем, правила, представленные в этой статье, демонстрируют, что перезапись запросов часто может на порядки ускорить выполнение запросов, наводя на мысль, что схемы преобразования запросов являются зрелой областью исследований. Наша расширяемая система Query Rewrite разрабатывается с учетом этого, и мы собирается продолжать добавлять к ней преобразования.
1.3 Родственные работы
Разработчики ранних РСУБД, таких как System R [ABC+ 76] и INGRES [SWK76] осознавали важность подстановки представлений и решали эту задачу для частных случаев. Несмотря на признанную важность таких преобразований, эти ранние схемы преобразований были применены лишь в немногих системах.
Ким [Kim82] первым задался вопросом о том, когда квантифицированные подзапросы можно заменить соединениями (или антисоединениями). Гански (Ganski) и Вонг (Wong) [GW87] и Дайал (Dayal) [Day87] проделали дополнительную работу по устранению вложенных подзапросов. В этих статьях признается важность поглощения подзапросов. В [Kim82, GW87] также решается проблема подзапросов, содержащих агрегацию. Мы описывали наш набор правил для работы с такими подзапросами в [MFPR90a, MPR90, MFPR90b].
В статье Гански иллюстрируется сложность перезаписи запросов, поскольку в описываемой работе ему пришлось исправлять некоторые предыдущие преобразования, которые были некоректными. Эта сложность поддерживает наш подход декомпозиции преобразований в расширяемый набор индивидуальных правил, таких что корректность каждого правила может быть показана отдельно.
Мы уделяем особое внимание ортогональности языка. Поэтому такие операции как UNION, INTERSECT и EXCEPT (эквивалент вычитания множеств в SQL) могут появляться в подзапросах, как этого и требует стандарт SQL [ISO91]. В упомянутых выше работах этим более сложным подзапросам внимание не уделяется. Кроме того, наши правила гарантируют поглощение конъюнктов подзапросов с кванторами существования, состоящих из ограничения, проекции и соединения. Частично это стало возможным благодаря нашему аккуратному обращению с дубликатами.
Анфиндсен (Anfindsen) [Anf89] также провел исследования преобразований подзапросов, используя РСУБД DB2 для измерений эффективности. Как и мы, Анфиндсен отмечает улучшение производительности на порядки. Однако автор ограничивается только преобразованиями, выдающими SQL-запрос, который может быть обработан DB2. В отличие от этого, наш подход является составной и интегральной частью РСУБД, что позволяет использовать более развитый внутренний язык и, следовательно, дает возможность производить большее число оптимизационных преобразований. Анфиндсен определяет понятие, близкое нашему условию-одного-кортежа (one-tuple-condition), поясняемому ниже, и приводит достаточные условия его удовлетворения.
К Starburst было добавлено много расширений [LLPS91], включая XNF, систему, поддерживающую запросы сложных объектов, в которой часто генерируются исключительно сложные SQL-запросы. Наша система выдержала испытание при использовании этими расширениями и в действительности именно она обеспечивает эффективную работу некоторых из них.
Работу, представленную в этой статье, не следует путать со средством перезаписи запросов в POSTGRES [SJGP90]. Перезапись запросов в POSTGRES является частью реализации для поддержки активной базы данных. В POSTGRES можно определить правило, говорящее о том, что поступающие запросы должны выполнять дополнительные или полностью другие действия по сравнению с теми, которые указал пользователь. В некоторых ситуациях POSTGRES реализует эту идею путем перезаписи запросов. Кстати, заметим, что преобразования запросов в POSTGRES направлены на изменение семантики запросов, а не эффективности. Например, перезапись в POSTGRES может использоваться для того, чтобы реализовать определяемую пользователями семантику обновлений представлений. В отличие от этого, мы делаем акцент на преобразовании в целях оптимизации выполнения запросов.
Ранняя версия системы правил Starburst Query Rewrite описана в [HP88].
1.4 Структура статьи
В разд. 2 описывается абстрактное представление запросов, используемое в правилах перезаписи. Сами правила приводятся в разд. 3. В разд. 4 описывается процессор правил, разработанный для Query Rewrite. В разд. 5 содержится сводка результатов и заключение.
2. Графовая модель запросов в Starburst
Запросы внутри системы представляются в графовой модели (Query Graph Model, QGM). Задача QGM состоит в обеспечении более мощного и концептуально более управляемого представления запросов для уменьшения сложности компиляции и оптимизации запросов. В QGM поддерживаются произвольные операции над таблицами, операндами и результатами которых являются таблицы. Примерами операций являются SELECT, GROUP BY, UNION, INTERSECT и EXCEPT. Операция SELECT является частью Starburst SQL, обрабатывающей ограничение, проецирование и соединение.
Мы представляем граф QGM на примере. Предположим, что имеется следующий SQL-запрос:
SELECT DISTINCT q1.partno, q1.descr, q2.suppno
FROM inventory q1, quotations q2
WHERE q1.partno = q2.partno AND q1.descr='engine'
AND q2.price ≤ ALL
(SELECT q3.price FROM quotations q3
WHERE q2.partno=q3.partno);
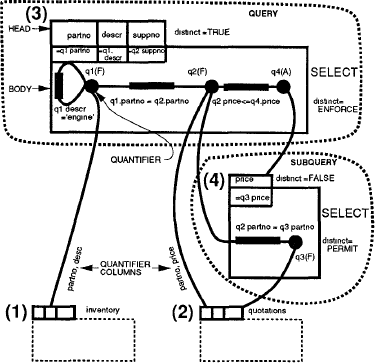
Рис. 1. Пример QGM-графа
Этот запрос выдает информацию о поставщиках и деталях, для которых цена данного поставщика меньше, чем у всех других поставщиков. На рис. 1 показана QGM для этого запроса. Граф состоит из четырех блоков. Блоки 1 и 2 ассоциированы с базовыми таблицами inventory и quotations. Блок 3 является блоком SELECT, ассоциированным с основной частью запроса, и блок 4 – это блок SELECT, ассоциированный с подзапросом. У каждого блока имеется заголовок и тело. Заголовок описывает результирующую таблицу, производимую блоком, а тело специфицирует операцию, требуемую для вычисления результирующей таблицы. Можно считать, что для базовых таблиц имеются пустые блоки, или что блоки для них не существуют.
Исследуем блок 3. В заголовке указаны столбцы результата partno, descr и suppno в соответствии со списком выборки запроса. Спецификация этих столбцов включает имена столбцов, типы и информацию об упорядоченности результата. В заголовке имеется булевский атрибут, называемый distinct, который указывает, содержит ли соответствующая таблица только различные кортежи (head.distinct = TRUE), или в ней содержатся дубликаты (head.distinct = FALSE).
Тело блока содержит граф. Вершины графа (черные круги в нашей диаграмме) представляют квантифицированные кортежные переменные, называемые квантификаторами. В блоке 3 имеются квантификаторы q1, q2 и q4. Областями определения квантификаторов q1 и q2 являются базовые таблицы inventory и quotations соответственно, и эти квантификаторы соответствуют ссылками на таблицы в разделе FROM SQL-запроса. Заметим, что узлы q1 и q2 связаны межблочными дугами с заголовками inventory и quotations. Дуга между q1 и q2 специфицирует предикат соединения. (Циклическая) дуга, присоединенная к q1, соответствует локальному предикату на q1.
В действительности, единственная межквантификаторная дуга представляет конъюнкт раздела WHERE в блоке запроса – конъюнкты представляются в диаграмме помеченным прямоугольником на дуге. Такие дуги также называются булевскими термами [SAC+79]. Квантификатор 3 является квантором всеобщности, ассоциированным с подзапросом ALL в разделе WHERE. Это выражает тот факт, что для всех кортежей, ассоциированных с q4, предикат, который представлен дугой между q2 и q4, является true.
В блоке 3 q1 и q2 участвуют в соединениях, и их столбцы используются в кортежах результата. Эти квантификаторы имеют тип F, поскольку они происходят из раздела FROM запроса. У квантификатора q4 тип A, представляющий квантор всебщности (ALL). Предикаты SQL EXISTS, IN, ANY и SOME принимают значение true, если, по крайней мере, один кортеж подзапроса удовлетворяет предикату. Следовательно, все эти предикаты являются экзистенциальными, и у квантификаторов, ассоциированных с такими подзапросами, имеется тип E. Каждый квантификатор помечается столбцами, которые ему требуются из таблицы, являющейся его областью определения.
Блок 4 представляет подзапрос. Он содержит F-квантификатор q3 над таблицей quotations, и в нем имеется предикат, ссылающийся на q2 и q3.
В теле каждого блока имеется атрибут, называемый distinct, который может иметь значения ENFORCE, PRESERVE или PERMIT. ENFORCE означает, что операция должна удалять дубликаты, чтобы обеспечивать head.distinct = TRUE. PRESERVE означает, что операция может сохранять численность дубликатов, которые она порождает. Так может быть потому, что head.distinct = FALSE, или потому, что head.distinct = TRUE, но никакие дубликаты не могут существовать в результате операции даже без удаления дубликатов. PERMIT означает, что операции разрешается удалять (или генерировать) дубликаты произвольным образом. Например, у атрибута distinct блока 4 может иметься значение PERMIT, потому что этот блок используется в кванторе всеобщности (q4 в блоке 3), а кванторы всеобщности нечувствительны к кортежам-дубликатам. Это рассматривается более подробно в разд. 3.
Как и у каждого тела блока, у каждого квантификатора имеется атрибут distinct со значениями ENFORCE, PRESERVE или PERMIT. ENFORCE означает, что для квантификатора требуется обеспечение удаления дубликатов из таблицы, являющейся его областью определения. PRESERVE означает, что в этой таблице должно быть сохранено точное число дубликатов, и PERMIT означает, что в ней может содержаться произвольное число дубликатов. У квантификаторов существования и всеобщности всегда может иметься distinct = PERMIT, поскольку они нечувствительны к дубликатам.
Для каждого выходного столбца в теле может иметься ассоциированное выражение, которое соответствует выражению, допустимому в списке SELECT. На рис. 1 все эти выражения просто идентифицируют функции над столбцам квантификаторов.
В SQL2 имеются табличные выражения, похожие на определения представлений, и их можно определять везде, где можно использовать таблицу. В Starburst у табличных выражений и представлений, как и у запросов и подзапросов, имеются QGM с одним или многими блоками, и они становятся частью QGM-графа запросов, ссылающихся на них.
Результат блока может использоваться несколько раз (например, представление можно использовать несколько раз в одном запросе), что создает общие подвыражения. Рекурсивные запросы создают циклы в QGM. По мере роста размеров графа возрастает и стоимость оптимизации. У запроса обычно обычно имеется 2-10 QGM-блоков. У существенно более сложных запросов, например, производимых XNF, это число составляет 10-100.
2.1 Среда для измерения эффективности
Обычно запросы не выполняются в течение часов или, тем более, дней. Query Rewrite может повысить эффективность на несколько порядков – во многих случаях превращая запрос, оставляемый для выполнения на ночь, в интерактивный. Мы продемонстрируем этот факт при обсуждении измерений влияния на эффективность наших правил перезаписи на различных запросах. В этом разделе мы представляем среду, используемую для этих измерений.
Для полной оценки производительности требуются определение тестовой базы данных и набор запросов для конкректной рабочей нагрузки. Мы ориентируемся на рабочую нагрузку сложных запросов (включающих подзапросы, представления и т.д.), а не на транзакционную рабочую нагрузку, где запросы относительно просты. Стандартная рабочая нагрузка сложных запросов отсутствует, хотя имеется несколько предложений ([TOB89, O'N89]). Для измерения воздействия на эффективность правил перезаписи мы используем вариант тестовой базы данных IBM DB2, описанной в [Loo86], объем которой увеличен в 10 раз.
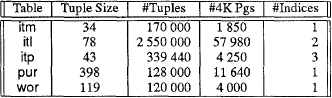
Таб. 1. Тестовая база данных
Тестовая база данных DB2 основана на приложении отслеживания запасов (inventory) и контроля их уровня. У рабочих центров (workcenter) имеются месторасположения (locations, locatn). Изделия (item, itm) обрабатываются в месторасположениях рабочих центров, и эта связь сохраняется в таблице itl. Запись об изделиях, которые обрабатываются конкретным служащим, сохраняется в таблице wor. Для каждого изделия могут иметься заказы (itp). Некоторые физические характеристики этой базы данных показаны в таб. 1.
Поскольку система Query Rewrite может производит SQL-представления своих результатов, мы можем легко измерять ее воздействие на широко используемые коммерческие СУБД. Это позволяет нам демонстрировать общую применимость перезаписи запросов для типичных СУБД, а не только для Starburst. Наши измерения производительности были проделаны для реляционной СУБД DB2. Мы измеряли использованное время (общее время, затраченное системой для выполнения запроса) и время ЦП (время занятости ЦП) для каждого запроса до и после применения правил перезаписи. Оба представления запроса проходили через обычный процесс компиляции запросов DB2, включая оптимизацию плана. Количественные показатели производительности приводятся в разд.3.
1) Этот язык предлагается в качестве стандартного объектно-ориентированного языка запросов и реализуется в некоторых коммерческих ООСУБД.